Word Ladder II
Description
A transformation sequence from word beginWord to word endWord using a dictionary wordList is a sequence of words beginWord -> s1 -> s2 -> ... -> sk such that:
- Every adjacent pair of words differs by exactly one letter.
- Every
sifor1 <= i <= kis present inwordList. Note thatbeginWorddoes not need to be inwordList. sk == endWord
Given two words, beginWord and endWord, and a dictionary wordList, return all the shortest transformation sequences from beginWord to endWord, or an empty list if no such sequence exists. Each sequence should be returned as a list of the words [beginWord, s1, s2, ..., sk].
In other words, you need to find every possible way to transform beginWord into endWord by changing one letter at a time (using only words from the dictionary), and return only those paths that use the fewest steps.
Examples
Example 1
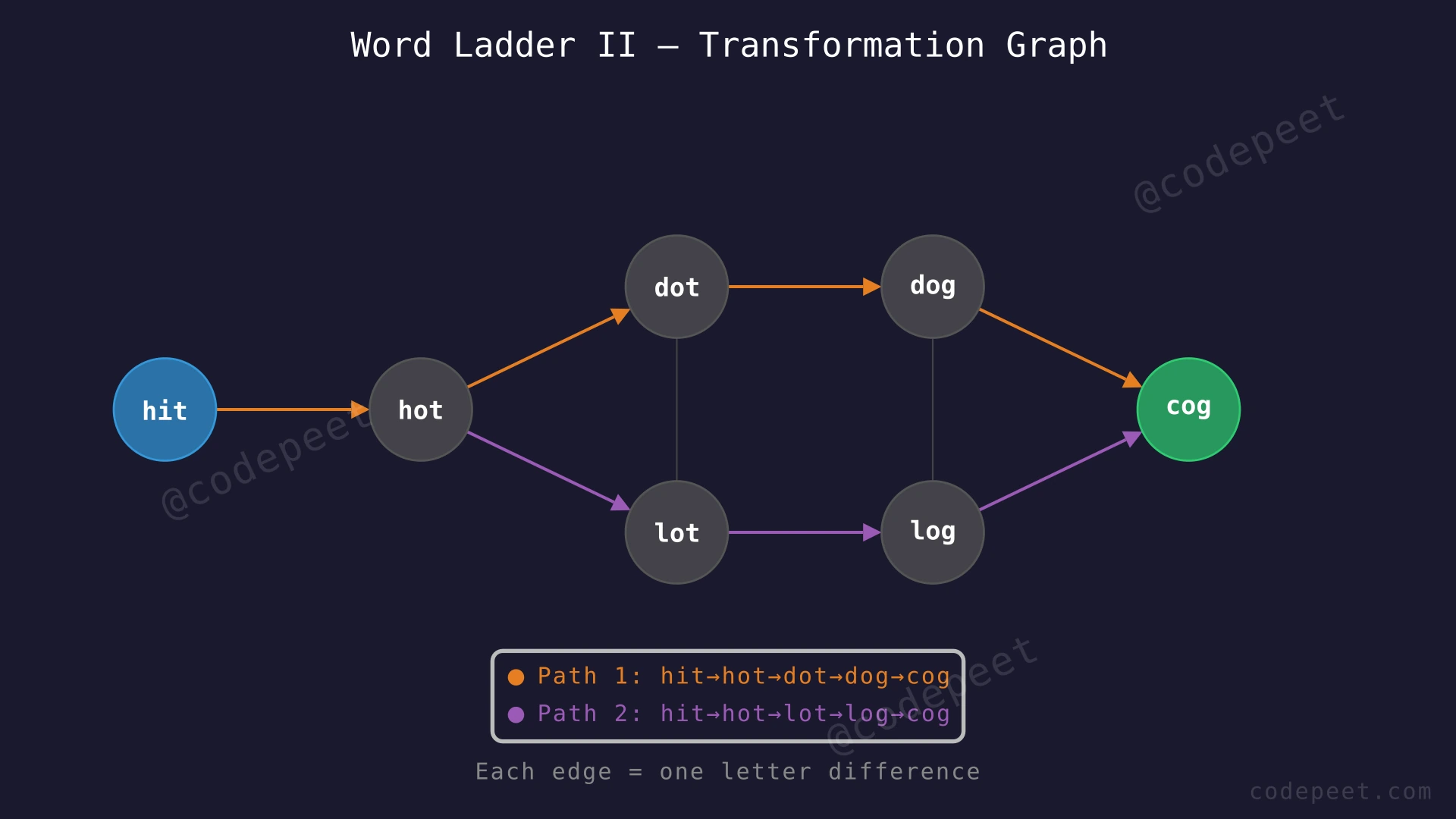
Input: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
Output: [["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]]
Explanation: There are two shortest transformation sequences, both of length 5:
- "hit" → "hot" → "dot" → "dog" → "cog" (change i→o, h→d, t→g, d→c)
- "hit" → "hot" → "lot" → "log" → "cog" (change i→o, h→l, t→g, l→c)
Both paths change exactly one letter at each step, every intermediate word exists in the dictionary, and no shorter path exists.
Example 2
Input: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
Output: []
Explanation: The endWord "cog" is not in the wordList, so there is no valid transformation sequence. Every intermediate and final word must be present in the dictionary for a path to be valid.
Example 3
Input: beginWord = "a", endWord = "c", wordList = ["a","b","c"]
Output: [["a","c"]]
Explanation: Changing 'a' to 'c' is a single-letter transformation (the word has length 1). Since "c" is in the dictionary and equals endWord, the shortest path has just 2 words.
Constraints
- 1 ≤ beginWord.length ≤ 5
- endWord.length == beginWord.length
- 1 ≤ wordList.length ≤ 500
- wordList[i].length == beginWord.length
beginWord,endWord, andwordList[i]consist of lowercase English letters- beginWord ≠ endWord
- All the words in
wordListare unique - The sum of all shortest transformation sequences does not exceed 10^5
Editorial
Brute Force
Intuition
The most natural first instinct is to try every possible path from beginWord to endWord and keep only the shortest ones.
Imagine standing at an intersection in a maze. You pick a direction, walk until you hit a dead end or the exit, then retrace your steps and try another direction. You write down every route that reaches the exit, then compare their lengths and keep only the shortest.
This is exactly what DFS (Depth-First Search) with backtracking does:
- Start at
beginWord. - At each word, try changing every character to every other letter (a–z).
- If the new word is in the dictionary and hasn't been visited on the current path, recurse deeper.
- If we reach
endWord, record the path and its length. - Backtrack (undo the choice) and try the next possibility.
- After exploring everything, return only paths whose length equals the shortest found.
To avoid exploring paths that are already longer than our best answer, we maintain a minLen variable and prune any path that exceeds it. This helps in practice but doesn't change the worst-case exponential running time.
Step-by-Step Explanation
Let's trace with beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]:
Step 1: Start DFS from "hit". path = ["hit"], visited = {"hit"}, minLen = ∞.
Step 2: "hit" has one valid neighbor: "hot" (change 'i' → 'o'). Recurse into dfs("hot").
path = ["hit","hot"], visited = {"hit","hot"}.
Step 3: "hot" has two neighbors: "dot" and "lot". Try "dot" first.
path = ["hit","hot","dot"], visited = {"hit","hot","dot"}.
Step 4: "dot" has neighbor "dog" (change 't' → 'g'). Recurse deeper.
path = ["hit","hot","dot","dog"], visited = {"hit","hot","dot","dog"}.
Step 5: "dog" reaches "cog" (change 'd' → 'c'). Recurse into dfs("cog").
path = ["hit","hot","dot","dog","cog"].
Step 6: "cog" equals endWord! Record Path 1: [hit,hot,dot,dog,cog], length = 5. Set minLen = 5.
Step 7: Backtrack from "cog" → "dog" → "dot" → "hot". Now try "hot"'s second neighbor: "lot".
path = ["hit","hot","lot"], visited = {"hit","hot","lot"}.
Step 8: "lot" has neighbor "log" (change 't' → 'g'). Recurse.
path = ["hit","hot","lot","log"].
Step 9: "log" reaches "cog" (change 'l' → 'c'). Recurse into dfs("cog").
path = ["hit","hot","lot","log","cog"].
Step 10: "cog" equals endWord! Path length = 5 = minLen. Record Path 2: [hit,hot,lot,log,cog].
Step 11: Backtrack fully. No more unvisited neighbors. DFS complete.
Result: [["hit","hot","dot","dog","cog"], ["hit","hot","lot","log","cog"]]
DFS Backtracking — Exploring All Transformation Paths — Watch the DFS explore every possible path through the word transformation graph, backtracking when hitting dead ends or exceeding the minimum path length.
Algorithm
- Convert
wordListto a set for O(1) lookup. IfendWordis not in the set, return empty. - Initialize
minLen = ∞and an empty result list. - Start DFS from
beginWordwithpath = [beginWord]andvisited = {beginWord}. - At each recursive call:
- If
path.length > minLen, prune (return immediately). - If current word equals
endWord, updateminLenif shorter, clear old results if strictly shorter, and add path to results. - Otherwise, try changing each character (positions 0 to M-1) to each letter a–z.
- If the new word is in the dictionary and not in
visited, add it tovisitedandpath, recurse, then backtrack (remove from both).
- If
- Return the result list.
Code
class Solution {
public:
vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> wordSet(wordList.begin(), wordList.end());
if (!wordSet.count(endWord)) return {};
vector<vector<string>> result;
int minLen = INT_MAX;
function<void(const string&, vector<string>&, unordered_set<string>&)> dfs;
dfs = [&](const string& word, vector<string>& path, unordered_set<string>& visited) {
if ((int)path.size() > minLen) return;
if (word == endWord) {
if ((int)path.size() < minLen) {
minLen = path.size();
result.clear();
}
if ((int)path.size() == minLen) {
result.push_back(path);
}
return;
}
string temp = word;
for (int i = 0; i < (int)temp.size(); i++) {
char orig = temp[i];
for (char c = 'a'; c <= 'z'; c++) {
if (c == orig) continue;
temp[i] = c;
if (wordSet.count(temp) && !visited.count(temp)) {
visited.insert(temp);
path.push_back(temp);
dfs(temp, path, visited);
path.pop_back();
visited.erase(temp);
}
}
temp[i] = orig;
}
};
unordered_set<string> visited = {beginWord};
vector<string> path = {beginWord};
dfs(beginWord, path, visited);
return result;
}
};class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: list[str]) -> list[list[str]]:
word_set = set(wordList)
if endWord not in word_set:
return []
result = []
min_len = float('inf')
def dfs(word, path, visited):
nonlocal min_len
if len(path) > min_len:
return
if word == endWord:
if len(path) < min_len:
min_len = len(path)
result.clear()
if len(path) == min_len:
result.append(list(path))
return
for i in range(len(word)):
for c in 'abcdefghijklmnopqrstuvwxyz':
if c == word[i]:
continue
new_word = word[:i] + c + word[i+1:]
if new_word in word_set and new_word not in visited:
visited.add(new_word)
path.append(new_word)
dfs(new_word, path, visited)
path.pop()
visited.remove(new_word)
dfs(beginWord, [beginWord], {beginWord})
return resultclass Solution {
List<List<String>> result = new ArrayList<>();
int minLen = Integer.MAX_VALUE;
public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {
Set<String> wordSet = new HashSet<>(wordList);
if (!wordSet.contains(endWord)) return result;
List<String> path = new ArrayList<>();
path.add(beginWord);
Set<String> visited = new HashSet<>();
visited.add(beginWord);
dfs(beginWord, endWord, wordSet, path, visited);
return result;
}
private void dfs(String word, String endWord, Set<String> wordSet,
List<String> path, Set<String> visited) {
if (path.size() > minLen) return;
if (word.equals(endWord)) {
if (path.size() < minLen) {
minLen = path.size();
result.clear();
}
if (path.size() == minLen) {
result.add(new ArrayList<>(path));
}
return;
}
char[] chars = word.toCharArray();
for (int i = 0; i < chars.length; i++) {
char orig = chars[i];
for (char c = 'a'; c <= 'z'; c++) {
if (c == orig) continue;
chars[i] = c;
String newWord = new String(chars);
if (wordSet.contains(newWord) && !visited.contains(newWord)) {
visited.add(newWord);
path.add(newWord);
dfs(newWord, endWord, wordSet, path, visited);
path.remove(path.size() - 1);
visited.remove(newWord);
}
}
chars[i] = orig;
}
}
}Complexity Analysis
Time Complexity: O(N! × M × 26) in the worst case
At each step, we potentially try N remaining dictionary words (via M × 26 character substitutions). In the worst case, the DFS explores all permutations of dictionary words, giving a factorial blowup. The pruning by minLen helps in practice but doesn't reduce the worst-case bound.
- N = number of words in the dictionary (up to 500)
- M = length of each word (up to 5)
- For each word, we try M × 26 character changes, each requiring O(M) string operations
Space Complexity: O(N × L)
- O(N) for the visited set and recursion stack depth (path can be at most N words long)
- O(L) per stored result path, where L is the path length
- The result itself can contain up to O(N!) paths in the worst case
Why This Approach Is Not Efficient
The brute force DFS has two critical problems:
1. No guarantee of finding shortest paths first. DFS explores deeply before broadly. It might discover a path of length 10 first, then later find one of length 5. Meanwhile, it wasted time exploring all length-6, 7, 8, 9 paths from the first branch before backtracking. The minLen pruning helps only AFTER finding an initial answer — and the first answer might not be shortest.
2. Exponential time complexity. With N = 500 words, the DFS can explore an astronomical number of paths. Even with pruning, the worst case is factorial: O(N!). For moderate dictionary sizes, this leads to Time Limit Exceeded.
The core insight for improvement: we need BFS, not DFS. BFS explores all paths of length k before exploring any path of length k+1. This guarantees that the FIRST time we reach endWord, we've found the shortest distance. We can then collect ALL paths of that shortest distance without ever exploring longer ones.
Better Approach - BFS with Path Storage
Intuition
Instead of DFS (which dives deep first), we use BFS (Breadth-First Search) which explores all words at the same distance before moving to the next distance. This is like ripples spreading from a stone dropped in water — the wavefront reaches nearby words first.
The key advantage: BFS guarantees that when we first encounter endWord, we're at the shortest possible distance. We process the entire BFS level where endWord appears, collecting ALL shortest paths, then stop.
The approach stores complete paths in the BFS queue. Each queue entry is not just a word, but the entire sequence of words from beginWord to the current word. When we dequeue a path and its last word transforms to endWord, we've found a complete shortest path.
To handle the subtlety of multiple paths reaching the same word: we use a levelVisited set. Words discovered at the current level are not added to the main visited set until the entire level is processed. This allows multiple paths from the same level to discover the same next-level word independently.
Step-by-Step Explanation
Let's trace with beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]:
Step 1: Initialize. Queue = [["hit"]], visited = {"hit"}.
Step 2: Level 0 — process ["hit"]. Transform "hit": find "hot". Enqueue ["hit","hot"]. levelVisited = {"hot"}.
Step 3: Level 0 complete. visited = {"hit","hot"}. Queue = [["hit","hot"]].
Step 4: Level 1 — process ["hit","hot"]. Transform "hot": find "dot" and "lot". Enqueue ["hit","hot","dot"] and ["hit","hot","lot"]. levelVisited = {"dot","lot"}.
Step 5: Level 1 complete. visited = {"hit","hot","dot","lot"}. Queue has 2 paths.
Step 6: Level 2 — process ["hit","hot","dot"]. Transform "dot": find "dog". Enqueue ["hit","hot","dot","dog"]. levelVisited = {"dog"}.
Step 7: Process ["hit","hot","lot"]. Transform "lot": find "log". Enqueue ["hit","hot","lot","log"]. levelVisited = {"dog","log"}.
Step 8: Level 2 complete. visited updated. Queue has 2 paths.
Step 9: Level 3 — process ["hit","hot","dot","dog"]. Transform "dog": find "cog" = endWord! Path 1: ["hit","hot","dot","dog","cog"]. Set found = true.
Step 10: Process ["hit","hot","lot","log"]. Transform "log": find "cog" = endWord! Path 2: ["hit","hot","lot","log","cog"].
Step 11: Level 3 complete. found = true. Stop BFS.
Result: [["hit","hot","dot","dog","cog"], ["hit","hot","lot","log","cog"]]
BFS with Path Storage — Level-by-Level Exploration — BFS explores all words at the same distance before moving deeper. Each complete path is stored in the queue, guaranteeing we find all shortest paths.
Algorithm
- Convert
wordListto a set. IfendWordis not in it, return empty. - Initialize a BFS queue with
[[beginWord]](a queue of paths). Setvisited = {beginWord}. - While queue is not empty and
foundis false:
a. RecordlevelSize = queue.size(). InitializelevelVisited = {}.
b. Process exactlylevelSizepaths (current level):- Dequeue a path. Get the last word.
- For each character position, try all 26 letters.
- If new word equals
endWord: addpath + [endWord]to results, setfound = true. - Else if new word is in dictionary and not in
visited: enqueuepath + [newWord], add tolevelVisited.
c. After the level:visited |= levelVisited.
- Return results.
Code
class Solution {
public:
vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> wordSet(wordList.begin(), wordList.end());
if (!wordSet.count(endWord)) return {};
vector<vector<string>> result;
queue<vector<string>> q;
q.push({beginWord});
unordered_set<string> visited = {beginWord};
bool found = false;
while (!q.empty() && !found) {
int levelSize = q.size();
unordered_set<string> levelVisited;
for (int i = 0; i < levelSize; i++) {
vector<string> path = q.front();
q.pop();
string word = path.back();
string temp = word;
for (int j = 0; j < (int)temp.size(); j++) {
char orig = temp[j];
for (char c = 'a'; c <= 'z'; c++) {
if (c == orig) continue;
temp[j] = c;
if (temp == endWord) {
vector<string> newPath = path;
newPath.push_back(temp);
result.push_back(newPath);
found = true;
} else if (wordSet.count(temp) && !visited.count(temp)) {
vector<string> newPath = path;
newPath.push_back(temp);
q.push(newPath);
levelVisited.insert(temp);
}
}
temp[j] = orig;
}
}
for (const string& w : levelVisited) visited.insert(w);
}
return result;
}
};from collections import deque
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: list[str]) -> list[list[str]]:
word_set = set(wordList)
if endWord not in word_set:
return []
result = []
queue = deque([[beginWord]])
visited = {beginWord}
found = False
while queue and not found:
level_size = len(queue)
level_visited = set()
for _ in range(level_size):
path = queue.popleft()
word = path[-1]
for i in range(len(word)):
for c in 'abcdefghijklmnopqrstuvwxyz':
if c == word[i]:
continue
new_word = word[:i] + c + word[i+1:]
if new_word == endWord:
result.append(path + [new_word])
found = True
elif new_word in word_set and new_word not in visited:
queue.append(path + [new_word])
level_visited.add(new_word)
visited |= level_visited
return resultclass Solution {
public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {
Set<String> wordSet = new HashSet<>(wordList);
List<List<String>> result = new ArrayList<>();
if (!wordSet.contains(endWord)) return result;
Queue<List<String>> queue = new LinkedList<>();
queue.add(new ArrayList<>(Arrays.asList(beginWord)));
Set<String> visited = new HashSet<>();
visited.add(beginWord);
boolean found = false;
while (!queue.isEmpty() && !found) {
int levelSize = queue.size();
Set<String> levelVisited = new HashSet<>();
for (int i = 0; i < levelSize; i++) {
List<String> path = queue.poll();
String word = path.get(path.size() - 1);
char[] chars = word.toCharArray();
for (int j = 0; j < chars.length; j++) {
char orig = chars[j];
for (char c = 'a'; c <= 'z'; c++) {
if (c == orig) continue;
chars[j] = c;
String newWord = new String(chars);
if (newWord.equals(endWord)) {
List<String> newPath = new ArrayList<>(path);
newPath.add(newWord);
result.add(newPath);
found = true;
} else if (wordSet.contains(newWord) && !visited.contains(newWord)) {
List<String> newPath = new ArrayList<>(path);
newPath.add(newWord);
queue.add(newPath);
levelVisited.add(newWord);
}
}
chars[j] = orig;
}
}
visited.addAll(levelVisited);
}
return result;
}
}Complexity Analysis
Time Complexity: O(N × M × 26) for the BFS traversal
- N = number of words in the dictionary (up to 500)
- M = length of each word (up to 5)
- For each word dequeued, we try M positions × 26 letters = 130 transformations
- Each transformation involves creating a new string in O(M) time
- In the worst case, all N words are visited, giving O(N × M × 26 × M) = O(N × M² × 26)
However, the BFS also copies full paths when enqueuing. If P paths exist at a given level, each of length L, the copy cost is O(P × L × M). This makes the effective cost O(N × M² × 26 + P × L × M).
Space Complexity: O(P × L × M)
- The queue stores complete paths. If there are P paths at the widest level, each of length L, and each word has M characters, the queue uses O(P × L × M) memory.
- In the worst case, the number of paths can be exponential in N (e.g., a dense transformation graph), making the memory usage the bottleneck.
- The visited set uses O(N × M) space.
Why This Approach Is Not Efficient
While BFS with path storage correctly finds all shortest paths and is much better than DFS brute force, it has a critical memory problem:
The queue stores complete paths, not just words. If 100 paths pass through the same word "dog" at distance 3, the queue holds 100 copies of paths up to "dog". Each path is a list of strings. For a dictionary of 500 words with paths of length 10, the queue can hold millions of string copies.
The redundancy is clear: all 100 paths share the same prefix structure dictated by the BFS tree, yet we store 100 independent copies.
Key insight for the optimal approach: Instead of storing full paths during BFS, store only a predecessor map — for each word, record which words can lead to it at the shortest distance. This map uses O(N²) space in the worst case (each word has at most N predecessors). After BFS completes, reconstruct all paths by DFS backtracking through the predecessor map. This separates the "find shortest distances" phase (BFS, lightweight) from the "enumerate paths" phase (DFS, on-demand).
Optimal Approach - BFS Predecessor Map with DFS Reconstruction
Intuition
The optimal solution splits the work into two clean phases:
Phase 1 — BFS to build a predecessor map:
Run BFS from beginWord, but instead of storing paths in the queue, store only individual words. For each word we discover, record ALL the words that can lead to it at the shortest distance. This creates a directed acyclic graph (DAG) of predecessors.
The key subtlety: when processing a BFS level, a word might be reachable from multiple words at the same level. We must record ALL of these as predecessors — not just the first one found. To achieve this, we mark all current-level words as visited BEFORE processing them, preventing same-level self-references, but we allow multiple different current-level words to independently discover the same next-level word.
Phase 2 — DFS to reconstruct paths:
Starting from endWord, follow the predecessor links backward to beginWord. Each time we reach beginWord, we've found a complete shortest path (reversed). The DFS naturally enumerates all possible paths through the predecessor DAG.
This is like building a family tree (Phase 1: record who is whose parent) and then tracing ancestry (Phase 2: walk backward from a descendant to find all ancestral lines).
Step-by-Step Explanation
Let's trace with beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]:
Phase 1: BFS — Building the Predecessor Map
Step 1: Initialize. currentLevel = {"hit"}, visited = {"hit"}, predecessors = {}.
Step 2: Process level 0: "hit". Mark "hit" as visited. Change characters: find "hot". predecessors["hot"] = {"hit"}. nextLevel = {"hot"}.
Step 3: Process level 1: "hot". Mark "hot" as visited. Find neighbors "dot" and "lot". predecessors["dot"] = {"hot"}, predecessors["lot"] = {"hot"}. nextLevel = {"dot","lot"}.
Step 4: Process level 2: "dot" and "lot". Mark both as visited.
- From "dot": find "dog" → predecessors["dog"] = {"dot"}.
- From "lot": find "log" → predecessors["log"] = {"lot"}.
- nextLevel = {"dog","log"}.
Step 5: Process level 3: "dog" and "log". Mark both as visited.
- From "dog": find "cog" = endWord → predecessors["cog"] = {"dog"}. found = true.
- From "log": find "cog" = endWord → add "log" to predecessors: predecessors["cog"] = {"dog","log"}.
- BFS complete. Level 3 fully processed.
Final predecessor map:
- hot ← {hit}
- dot ← {hot}
- lot ← {hot}
- dog ← {dot}
- log ← {lot}
- cog ← {dog, log}
Phase 2: DFS — Reconstructing All Paths from endWord
Step 6: Start DFS from "cog". path = ["cog"]. predecessors["cog"] = {"dog","log"}.
Step 7: Follow "cog" → "dog". path = ["cog","dog"]. predecessors["dog"] = {"dot"}.
Step 8: Follow "dog" → "dot" → "hot" → "hit". path = ["cog","dog","dot","hot","hit"]. "hit" = beginWord! Reverse to get Path 1: ["hit","hot","dot","dog","cog"].
Step 9: Backtrack to "cog". Follow "cog" → "log". path = ["cog","log"]. predecessors["log"] = {"lot"}.
Step 10: Follow "log" → "lot" → "hot" → "hit". "hit" = beginWord! Reverse to get Path 2: ["hit","hot","lot","log","cog"].
Result: [["hit","hot","dot","dog","cog"], ["hit","hot","lot","log","cog"]]
BFS Predecessor Map + DFS Path Reconstruction — Phase 1: BFS builds a lightweight predecessor map storing only which words lead to which. Phase 2: DFS backtracks from endWord through predecessors to reconstruct all shortest paths.
Algorithm
Phase 1: BFS — Build Predecessor Map
- Convert
wordListto a set. IfendWordis absent, return empty. - Initialize
currentLevel = {beginWord},visited = {beginWord},predecessors = {}. - While
currentLevelis not empty andfoundis false:
a. Add allcurrentLevelwords tovisited(prevents same-level self-discovery).
b. InitializenextLevel = {}.
c. For eachwordincurrentLevel:- For each character position, try all 26 letters.
- If new word equals
endWord: addwordtopredecessors[endWord], setfound = true. - Else if new word is in dictionary and not in
visited: add tonextLevel, addwordtopredecessors[newWord].
d. SetcurrentLevel = nextLevel.
Phase 2: DFS — Reconstruct All Paths
- Start DFS from
endWordwithpath = [endWord]. - At each word, if it equals
beginWord, reversepathand add to results. - Otherwise, for each predecessor, append it to
path, recurse, then backtrack (pop). - Return results.
Code
class Solution {
public:
vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> wordSet(wordList.begin(), wordList.end());
if (!wordSet.count(endWord)) return {};
// Phase 1: BFS to build predecessor map
unordered_map<string, unordered_set<string>> predecessors;
unordered_set<string> currentLevel = {beginWord};
unordered_set<string> visited = {beginWord};
bool found = false;
while (!currentLevel.empty() && !found) {
// Mark current level as visited before processing
for (const string& w : currentLevel) visited.insert(w);
unordered_set<string> nextLevel;
for (const string& word : currentLevel) {
string temp = word;
for (int i = 0; i < (int)temp.size(); i++) {
char orig = temp[i];
for (char c = 'a'; c <= 'z'; c++) {
if (c == orig) continue;
temp[i] = c;
if (temp == endWord) {
predecessors[temp].insert(word);
found = true;
} else if (wordSet.count(temp) && !visited.count(temp)) {
nextLevel.insert(temp);
predecessors[temp].insert(word);
}
}
temp[i] = orig;
}
}
currentLevel = nextLevel;
}
if (!found) return {};
// Phase 2: DFS backtracking from endWord
vector<vector<string>> result;
vector<string> path = {endWord};
function<void(const string&)> dfs = [&](const string& word) {
if (word == beginWord) {
result.push_back(vector<string>(path.rbegin(), path.rend()));
return;
}
for (const string& pred : predecessors[word]) {
path.push_back(pred);
dfs(pred);
path.pop_back();
}
};
dfs(endWord);
return result;
}
};from collections import defaultdict
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: list[str]) -> list[list[str]]:
word_set = set(wordList)
if endWord not in word_set:
return []
# Phase 1: BFS to build predecessor map
predecessors = defaultdict(set)
current_level = {beginWord}
visited = {beginWord}
found = False
while current_level and not found:
visited |= current_level
next_level = set()
for word in current_level:
for i in range(len(word)):
for c in 'abcdefghijklmnopqrstuvwxyz':
if c == word[i]:
continue
new_word = word[:i] + c + word[i+1:]
if new_word == endWord:
predecessors[new_word].add(word)
found = True
elif new_word in word_set and new_word not in visited:
next_level.add(new_word)
predecessors[new_word].add(word)
current_level = next_level
if not found:
return []
# Phase 2: DFS backtracking from endWord
result = []
def dfs(word, path):
if word == beginWord:
result.append(path[::-1])
return
for pred in predecessors[word]:
path.append(pred)
dfs(pred, path)
path.pop()
dfs(endWord, [endWord])
return resultclass Solution {
public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {
Set<String> wordSet = new HashSet<>(wordList);
List<List<String>> result = new ArrayList<>();
if (!wordSet.contains(endWord)) return result;
// Phase 1: BFS to build predecessor map
Map<String, Set<String>> predecessors = new HashMap<>();
Set<String> currentLevel = new HashSet<>();
currentLevel.add(beginWord);
Set<String> visited = new HashSet<>();
visited.add(beginWord);
boolean found = false;
while (!currentLevel.isEmpty() && !found) {
visited.addAll(currentLevel);
Set<String> nextLevel = new HashSet<>();
for (String word : currentLevel) {
char[] chars = word.toCharArray();
for (int i = 0; i < chars.length; i++) {
char orig = chars[i];
for (char c = 'a'; c <= 'z'; c++) {
if (c == orig) continue;
chars[i] = c;
String newWord = new String(chars);
if (newWord.equals(endWord)) {
predecessors.computeIfAbsent(newWord, k -> new HashSet<>()).add(word);
found = true;
} else if (wordSet.contains(newWord) && !visited.contains(newWord)) {
nextLevel.add(newWord);
predecessors.computeIfAbsent(newWord, k -> new HashSet<>()).add(word);
}
}
chars[i] = orig;
}
}
currentLevel = nextLevel;
}
if (!found) return result;
// Phase 2: DFS backtracking from endWord
List<String> path = new ArrayList<>();
path.add(endWord);
buildPaths(endWord, beginWord, predecessors, path, result);
return result;
}
private void buildPaths(String word, String beginWord,
Map<String, Set<String>> predecessors,
List<String> path, List<List<String>> result) {
if (word.equals(beginWord)) {
List<String> reversed = new ArrayList<>(path);
Collections.reverse(reversed);
result.add(reversed);
return;
}
if (!predecessors.containsKey(word)) return;
for (String pred : predecessors.get(word)) {
path.add(pred);
buildPaths(pred, beginWord, predecessors, path, result);
path.remove(path.size() - 1);
}
}
}Complexity Analysis
Time Complexity: O(N × M × 26 + P × L)
- Phase 1 (BFS): Each of the N words is processed at most once. For each word, we try M × 26 character substitutions. Each substitution creates a new string in O(M) time. Total: O(N × M² × 26).
- Phase 2 (DFS): We traverse P paths, each of length L. The DFS visits each predecessor edge once per path. Total: O(P × L).
- Combined: O(N × M² × 26 + P × L). The constraint guarantees that the sum of all path lengths (P × L) does not exceed 10^5.
Space Complexity: O(N × M + N²)
- The
visitedset andcurrentLevelsets hold up to N words of length M: O(N × M). - The predecessor map can have up to N entries. In the worst case, each word can have up to N predecessors (in a dense graph), giving O(N²) for the map.
- The DFS recursion stack has depth at most L (the path length).
- The result stores P paths of length L, contributing O(P × L × M).
This is a major improvement over the BFS-with-path-storage approach: the BFS phase uses only O(N × M) memory (one word per queue entry), and the predecessor map compactly encodes all shortest-path information in O(N²) space. Paths are reconstructed on demand rather than stored in the queue.