Topological Sort
Description
Given a Directed Acyclic Graph (DAG) with V vertices (labeled 0 to V - 1) and E edges, find any topological sorting of the graph.
Topological sorting for a DAG is a linear ordering of vertices such that for every directed edge u → v, vertex u comes before vertex v in the ordering.
Key observations:
-
DAG requirement: Topological sort is only possible for Directed Acyclic Graphs. If the graph has a cycle (e.g.,
u → v → w → u), no valid ordering exists — you would needubeforev,vbeforew, andwbeforeu, which is impossible. -
Non-uniqueness: A graph can have multiple valid topological orderings. Any ordering that respects all edge directions is correct. For example, if nodes 4 and 5 both have no incoming edges, either can come first.
-
Real-world analogy: Think of university course prerequisites. If Course A is a prerequisite for Course B, then A must appear before B in your schedule. Topological sort gives you any valid schedule.
Note: Since multiple topological orders exist, you may return any valid one. If your returned order is correct, the output will be true.
Examples
Example 1
Input: V = 4, E = 3, edges = [[3,0], [1,0], [2,0]]
Output: true (one valid order: [3, 2, 1, 0])
Explanation: The adjacency list is: 0→[], 1→[0], 2→[0], 3→[0].
- Nodes 1, 2, and 3 all have edges pointing to node 0.
- Node 0 has in-degree 3 (three incoming edges) and must appear after nodes 1, 2, and 3.
- Nodes 1, 2, 3 have in-degree 0, so they can appear in any relative order.
- Valid topological orders: [3, 2, 1, 0], [1, 2, 3, 0], [2, 3, 1, 0], etc.
Example 2
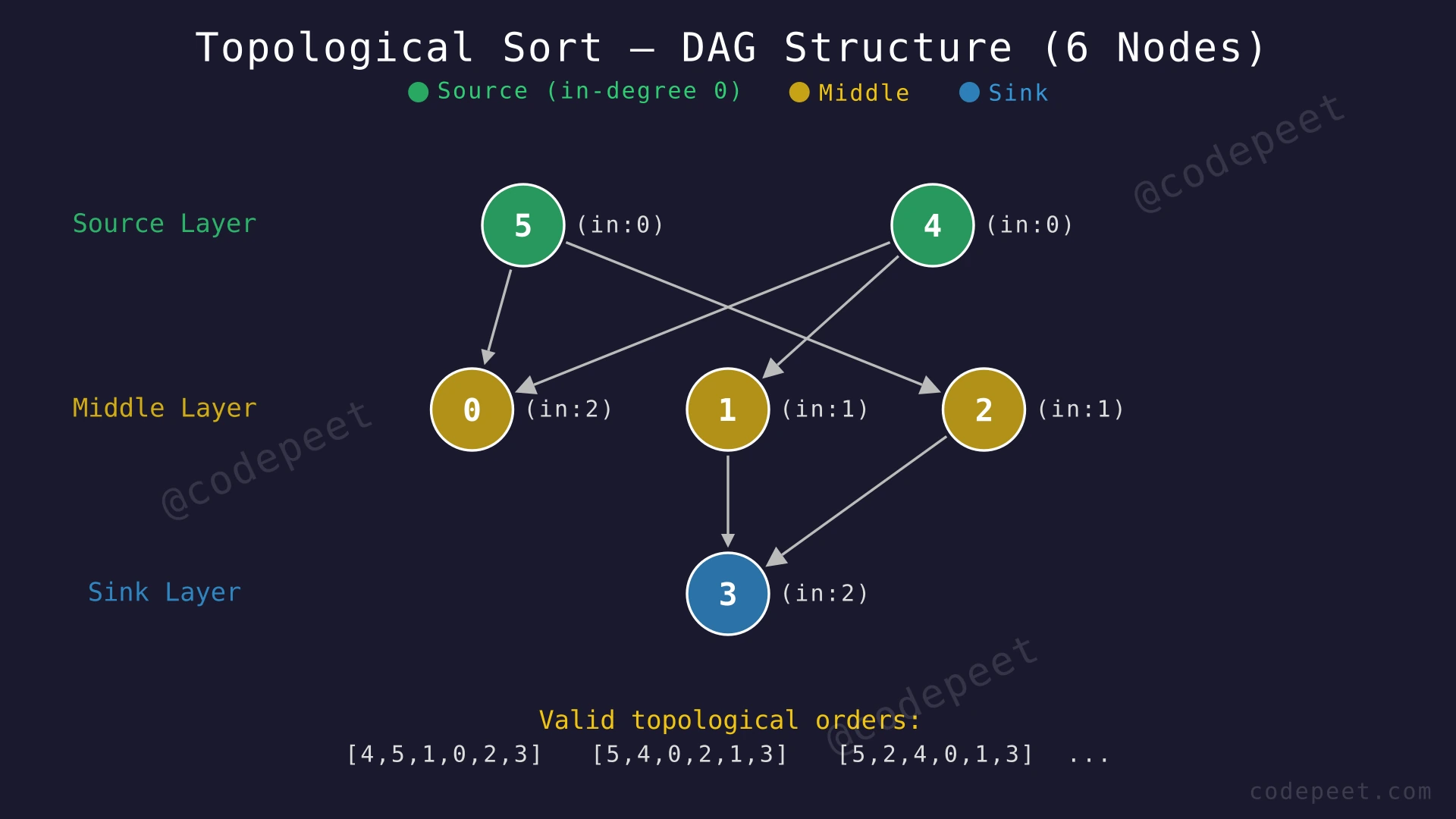
Input: V = 6, E = 6, edges = [[1,3], [2,3], [4,1], [4,0], [5,0], [5,2]]
Output: true (one valid order: [4, 5, 0, 1, 2, 3])
Explanation: The adjacency list is: 0→[], 1→[3], 2→[3], 3→[], 4→[0,1], 5→[0,2].
- In-degrees: node 0 = 2, node 1 = 1, node 2 = 1, node 3 = 2, node 4 = 0, node 5 = 0.
- Nodes 4 and 5 have in-degree 0 — they are source nodes and can appear first.
- Node 0 depends on 4 and 5. Node 1 depends on 4. Node 2 depends on 5. Node 3 depends on 1 and 2.
- The ordering [4, 5, 0, 1, 2, 3] is valid: every edge u→v has u before v.
- Another valid ordering: [5, 2, 4, 0, 1, 3].
Example 3
Input: V = 4, E = 3, edges = [[0,1], [1,2], [2,3]]
Output: true (only valid order: [0, 1, 2, 3])
Explanation: The graph is a simple chain: 0→1→2→3.
- Each node has exactly one incoming edge (except node 0) and one outgoing edge (except node 3).
- In-degrees: node 0 = 0, node 1 = 1, node 2 = 1, node 3 = 1.
- There is only one valid topological ordering: [0, 1, 2, 3]. This happens because the graph forms a linear chain — each node has a unique predecessor and successor. When a DAG has this property, the topological sort is unique.
Constraints
- 2 ≤ V ≤ 5 × 10^3
- 1 ≤ E ≤ min(10^5, V × (V - 1) / 2)
- 0 ≤ edges[i][0], edges[i][1] < V
- The graph is guaranteed to be a DAG (Directed Acyclic Graph) — no cycles exist
- There may be multiple valid topological orderings; any one is accepted
Editorial
Brute Force
Intuition
The most straightforward approach: generate all possible orderings of the V vertices and check each one to see if it satisfies the topological sort condition.
Imagine you have V cards, each labeled with a node number. You shuffle them into every possible arrangement. For each arrangement, you verify: "Does every directed edge u→v have u appearing before v in this arrangement?" The first valid arrangement you find is a valid topological sort.
Since there are V! (V factorial) possible permutations and each check requires examining all E edges, this approach is astronomically expensive. For V = 10, that's 3.6 million permutations. For V = 20, it's over 2.4 × 10^18 — utterly impractical.
This approach is conceptually valuable because it clearly defines what we are looking for, but it is far too slow for any meaningful input size.
Step-by-Step Explanation
Let's trace with a small example: V = 4, adj = [[], [0], [0], [0]]
Edges: 1→0, 2→0, 3→0.
All permutations of [0, 1, 2, 3]:
-
[0, 1, 2, 3]: Check edge 1→0. Position of 1 is index 1, position of 0 is index 0. But 1 must come BEFORE 0, and here 0 is at index 0, 1 at index 1 → 1 is AFTER 0. ❌ Invalid.
-
[0, 1, 3, 2]: Same problem — 0 is first, but 1→0 requires 1 before 0. ❌ Invalid.
-
[0, 2, 1, 3]: Same issue. ❌ Invalid.
-
[0, 2, 3, 1]: ❌ Invalid (0 still first).
-
[0, 3, 1, 2]: ❌ Invalid.
-
[0, 3, 2, 1]: ❌ Invalid.
-
[1, 0, 2, 3]: Check 1→0: pos(1)=0 < pos(0)=1 ✅. Check 2→0: pos(2)=2 > pos(0)=1? No, 2 IS after 0... wait, we need 2 BEFORE 0. pos(2)=2, pos(0)=1. 2 > 1 means 2 comes after 0. ❌ Invalid.
...(many more invalid permutations)...
[1, 2, 3, 0]: Check 1→0: pos(1)=0 < pos(0)=3 ✅. Check 2→0: pos(2)=1 < pos(0)=3 ✅. Check 3→0: pos(3)=2 < pos(0)=3 ✅. All edges satisfied! ✅ Valid topological order found!
We had to check many permutations before finding a valid one. For larger graphs, this becomes impossibly slow.
Algorithm
- Generate all V! permutations of vertices [0, 1, ..., V-1]
- For each permutation
perm:
a. Computepos[v]= index of vertex v in the permutation
b. For every directed edgeu → vin the graph:- If
pos[u] > pos[v], this permutation is invalid (u appears after v). Break.
c. If all edges are satisfied, return this permutation as the topological sort
- If
- Return the first valid permutation found
Code
#include <algorithm>
#include <numeric>
#include <vector>
using namespace std;
vector<int> topoSort(vector<vector<int>>& adj) {
int V = adj.size();
vector<int> perm(V);
iota(perm.begin(), perm.end(), 0); // [0, 1, ..., V-1]
do {
// Build position map for current permutation
vector<int> pos(V);
for (int i = 0; i < V; i++) pos[perm[i]] = i;
// Verify: for every edge u->v, pos[u] < pos[v]
bool valid = true;
for (int u = 0; u < V && valid; u++) {
for (int v : adj[u]) {
if (pos[u] > pos[v]) {
valid = false;
break;
}
}
}
if (valid) return perm;
} while (next_permutation(perm.begin(), perm.end()));
return {}; // Should never reach here for a valid DAG
}from itertools import permutations
def topoSort(adj):
V = len(adj)
for perm in permutations(range(V)):
# Build position map
pos = {v: i for i, v in enumerate(perm)}
# Verify: for every edge u->v, pos[u] < pos[v]
valid = True
for u in range(V):
for v in adj[u]:
if pos[u] > pos[v]:
valid = False
break
if not valid:
break
if valid:
return list(perm)
return [] # Should never reach here for a valid DAGimport java.util.*;
class Solution {
public int[] topoSort(ArrayList<ArrayList<Integer>> adj) {
int V = adj.size();
int[] perm = new int[V];
for (int i = 0; i < V; i++) perm[i] = i;
do {
// Build position map
int[] pos = new int[V];
for (int i = 0; i < V; i++) pos[perm[i]] = i;
// Verify: for every edge u->v, pos[u] < pos[v]
boolean valid = true;
for (int u = 0; u < V && valid; u++) {
for (int v : adj.get(u)) {
if (pos[u] > pos[v]) {
valid = false;
break;
}
}
}
if (valid) return perm.clone();
} while (nextPermutation(perm));
return new int[0];
}
private boolean nextPermutation(int[] arr) {
int n = arr.length, i = n - 2;
while (i >= 0 && arr[i] >= arr[i + 1]) i--;
if (i < 0) return false;
int j = n - 1;
while (arr[j] <= arr[i]) j--;
int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;
for (int l = i + 1, r = n - 1; l < r; l++, r--) {
tmp = arr[l]; arr[l] = arr[r]; arr[r] = tmp;
}
return true;
}
}Complexity Analysis
Time Complexity: O(V! × E)
There are V! possible permutations. For each permutation, we check all E edges to verify the ordering is valid. In the absolute worst case (the valid ordering is the last permutation), we examine all V! permutations.
For V = 10: 10! × E ≈ 3.6M × E operations.
For V = 20: 20! ≈ 2.4 × 10^18 — completely infeasible.
Space Complexity: O(V)
We store the current permutation (O(V)) and the position array (O(V)). No additional data structures needed.
Why This Approach Is Not Efficient
The brute force generates all V! permutations and checks each, which is factorial time — the slowest common complexity class.
-
Explosive growth: V! grows faster than exponential. For V = 5000 (the constraint upper bound), V! is an astronomically large number with over 16,000 digits. There is zero chance of iterating through this many permutations.
-
No structural insight: The brute force treats the graph as a black box and ignores its structure. It doesn't exploit the fact that edges directly tell us ordering constraints. A smarter approach would use the graph's structure (edges, in-degrees, DFS traversal) to construct the answer directly rather than searching for it.
-
Redundant work: Most permutations are clearly invalid from the first few positions. For example, if edge 4→0 exists, any permutation starting with 0 is immediately invalid if 4 hasn't appeared yet. The brute force doesn't prune these early.
Key insight for improvement: Instead of searching for a valid ordering among all permutations, we can build one directly. DFS naturally visits dependencies before dependents — if we record the order nodes finish their DFS (post-order), reversing it gives a valid topological sort in O(V + E) time.
Better Approach - DFS with Stack (Post-Order DFS)
Intuition
Instead of searching through permutations, let's build the topological order directly using DFS.
The key insight: in a DFS traversal, when we finish processing a node (i.e., all its descendants have been fully explored), we know that all nodes reachable from it have already been visited. If we push each node onto a stack after finishing it, then popping the stack gives us a valid topological order.
Why does post-order DFS work?
Consider an edge u → v. During DFS:
- If we visit u first, we'll recurse into v (and its descendants) before finishing u. So v gets pushed to the stack BEFORE u. When we pop, u comes out BEFORE v. ✅
- If we visit v first (from a different DFS root), v finishes and gets pushed. Later when we DFS from u, v is already visited, so we skip it. u then finishes and gets pushed ON TOP of v. When we pop, u comes out BEFORE v. ✅
In both cases, u appears before v in the final ordering — exactly what topological sort requires!
Analogy: Think of it like getting dressed. You can't put on shoes before socks. DFS explores "what must come after this item" recursively, and pushing on finish means items are stacked with dependencies on top. Popping gives the correct wear-order.
Step-by-Step Explanation
Let's trace with V = 6, adj = [[], [3], [3], [], [0,1], [0,2]].
Edges: 4→0, 4→1, 5→0, 5→2, 1→3, 2→3.
Step 1: Initialize visited = [F,F,F,F,F,F], stack = []. Start iterating from node 0.
Step 2: DFS(0). adj[0] = [] (no neighbors). Node 0 is a "leaf" in terms of outgoing edges — push 0 to stack.
- Stack: [0]. visited = [T,F,F,F,F,F]
Step 3: DFS(1). Mark 1 as visited. Explore neighbor 3.
Step 4: DFS(3). adj[3] = [] (no neighbors). Push 3 to stack. Backtrack to node 1.
- Stack: [0, 3]. visited = [T,T,F,T,F,F]
Step 5: Back at node 1. All neighbors of 1 are visited. Push 1 to stack.
- Stack: [0, 3, 1]. Notice: 1 is pushed AFTER 3 — so when we pop, 1 comes before 3. This respects edge 1→3. ✅
Step 6: DFS(2). Explore neighbor 3 — already visited, skip. Push 2 to stack.
- Stack: [0, 3, 1, 2]. visited = [T,T,T,T,F,F]
Step 7: DFS(4). Explore neighbors [0, 1] — both already visited, skip. Push 4.
- Stack: [0, 3, 1, 2, 4]. visited = [T,T,T,T,T,F]
Step 8: DFS(5). Explore neighbors [0, 2] — both already visited, skip. Push 5.
- Stack: [0, 3, 1, 2, 4, 5]. visited = [T,T,T,T,T,T]
Step 9: All nodes visited. Pop stack to get result: [5, 4, 2, 1, 3, 0].
Verification: 4→0: pos(4)=1 < pos(0)=5 ✅. 4→1: pos(4)=1 < pos(1)=3 ✅. 5→0: pos(5)=0 < pos(0)=5 ✅. 5→2: pos(5)=0 < pos(2)=2 ✅. 1→3: pos(1)=3 < pos(3)=4 ✅. 2→3: pos(2)=2 < pos(3)=4 ✅. All edges respected!
DFS Post-Order Topological Sort — Watch how DFS explores each node, and pushes it to the result stack only AFTER all its descendants are fully processed. The stack reversal produces a valid topological ordering.
Algorithm
- Create a
visitedboolean array of size V (all false) and an emptystack - For each node
ifrom 0 to V-1:
a. Ifiis not visited, calldfs(i, visited, adj, stack) - In
dfs(node, visited, adj, stack):
a. Marknodeas visited
b. For each neighbornextinadj[node]:- If
nextis not visited, recursively calldfs(next, visited, adj, stack)
c. After all neighbors are processed, pushnodeonto thestack
- If
- Pop all elements from the stack into a result list — this is the topological order
- Return the result list
Code
#include <vector>
#include <stack>
using namespace std;
void dfs(int node, vector<bool>& visited,
vector<vector<int>>& adj, stack<int>& st) {
visited[node] = true;
for (int next : adj[node]) {
if (!visited[next]) {
dfs(next, visited, adj, st);
}
}
// Push AFTER all descendants are fully processed
st.push(node);
}
vector<int> topoSort(vector<vector<int>>& adj) {
int V = adj.size();
vector<bool> visited(V, false);
stack<int> st;
for (int i = 0; i < V; i++) {
if (!visited[i]) {
dfs(i, visited, adj, st);
}
}
vector<int> result;
while (!st.empty()) {
result.push_back(st.top());
st.pop();
}
return result;
}def topoSort(adj):
V = len(adj)
visited = [False] * V
stack = []
def dfs(node):
visited[node] = True
for next_node in adj[node]:
if not visited[next_node]:
dfs(next_node)
# Push after all descendants are processed
stack.append(node)
for i in range(V):
if not visited[i]:
dfs(i)
# Reverse the stack to get topological order
return stack[::-1]import java.util.*;
class Solution {
private void dfs(int node, boolean[] visited,
ArrayList<ArrayList<Integer>> adj,
Stack<Integer> stack) {
visited[node] = true;
for (int next : adj.get(node)) {
if (!visited[next]) {
dfs(next, visited, adj, stack);
}
}
// Push after all descendants are processed
stack.push(node);
}
public int[] topoSort(ArrayList<ArrayList<Integer>> adj) {
int V = adj.size();
boolean[] visited = new boolean[V];
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < V; i++) {
if (!visited[i]) {
dfs(i, visited, adj, stack);
}
}
int[] result = new int[V];
for (int i = 0; i < V; i++) {
result[i] = stack.pop();
}
return result;
}
}Complexity Analysis
Time Complexity: O(V + E)
Each vertex is visited exactly once (DFS marks it visited and never revisits). Each edge is examined exactly once (when its source node processes its neighbor list). The stack operations (push/pop) are O(1) each. Total: O(V + E).
Space Complexity: O(V)
visitedarray: O(V)- Result stack: O(V)
- DFS recursion stack: O(V) in the worst case (linear chain graph like 0→1→2→...→V-1)
- Total: O(V)
Why This Approach Is Not Efficient
While the DFS approach achieves optimal O(V + E) time complexity, it has several practical limitations:
-
Recursion stack overflow: For large graphs (V up to 5000) with long chains, the DFS recursion depth can reach V. Each recursive call adds a frame to the system call stack. In languages like Java (default stack ~512KB) or Python (default recursion limit 1000), this can cause a stack overflow or recursion limit error.
-
No built-in cycle detection: The basic DFS topological sort assumes the input is a DAG. If the graph has a cycle, the DFS will still produce an output — but it will be WRONG (not a valid topological order). Detecting this silently-wrong behavior requires additional logic (e.g., three-color marking for back-edge detection).
-
Reverse step required: The DFS produces nodes in reverse topological order (post-order). We need an extra stack or list reversal to get the correct order. While O(V), this adds conceptual complexity.
Key insight for improvement: Kahn's Algorithm (BFS-based) solves all three issues:
- Iterative (no recursion, no stack overflow)
- Built-in cycle detection (if result size ≠ V, a cycle exists)
- Direct order (nodes are added to result in correct topological order, no reversal needed)
Optimal Approach - Kahn's Algorithm (BFS with In-Degree)
Intuition
Kahn's Algorithm takes a completely different perspective: instead of exploring depth-first and recording finish times, it asks: "Which nodes have no dependencies right now?" and processes them first.
The in-degree of a node is the number of incoming edges — i.e., how many prerequisites it has. A node with in-degree 0 has no prerequisites and can be placed at the current position in the topological order.
The algorithm works like a domino chain:
- Find all nodes with in-degree 0 (no prerequisites). Place them in a queue.
- Pick a node from the queue, add it to the result, and "remove" it from the graph by decrementing the in-degree of all its neighbors.
- If any neighbor's in-degree drops to 0, it means all its prerequisites are now satisfied — add it to the queue.
- Repeat until the queue is empty.
Real-world analogy: Imagine a university registration system. Courses with no prerequisites (in-degree 0) can be taken immediately. After completing those courses, some new courses become unlocked (their prerequisites are now met). You keep taking available courses until your schedule is complete.
Bonus — cycle detection: If the graph has a cycle, some nodes will always have in-degree > 0 (they depend on each other in a circular way). The queue will empty before all nodes are processed. If the result has fewer than V nodes, a cycle exists!
Step-by-Step Explanation
Let's trace with V = 6, adj = [[], [3], [3], [], [0,1], [0,2]].
Edges: 4→0, 4→1, 5→0, 5→2, 1→3, 2→3.
Step 1: Compute in-degrees.
For each edge u→v, increment in-degree[v].
- 4→0: in-degree[0]++. 4→1: in-degree[1]++. 5→0: in-degree[0]++. 5→2: in-degree[2]++. 1→3: in-degree[3]++. 2→3: in-degree[3]++.
- In-degrees: [2, 1, 1, 2, 0, 0]
Step 2: Initialize queue with in-degree 0 nodes.
Nodes 4 and 5 have in-degree 0. Queue = [4, 5].
Step 3: Dequeue 4. Add to result. Process neighbors [0, 1].
- in-degree[0]: 2→1. Not zero yet.
- in-degree[1]: 1→0. Enqueue 1! Queue = [5, 1].
- result = [4]
Step 4: Dequeue 5. Add to result. Process neighbors [0, 2].
- in-degree[0]: 1→0. Enqueue 0! Queue = [1, 0].
- in-degree[2]: 1→0. Enqueue 2! Queue = [1, 0, 2].
- result = [4, 5]
Step 5: Dequeue 1. Add to result. Process neighbors [3].
- in-degree[3]: 2→1. Not zero yet.
- Queue = [0, 2].
- result = [4, 5, 1]
Step 6: Dequeue 0. Add to result. adj[0] = [] — no neighbors.
- Queue = [2].
- result = [4, 5, 1, 0]
Step 7: Dequeue 2. Add to result. Process neighbors [3].
- in-degree[3]: 1→0. Enqueue 3! Queue = [3].
- result = [4, 5, 1, 0, 2]
Step 8: Dequeue 3. Add to result. adj[3] = [] — no neighbors.
- Queue = []. result = [4, 5, 1, 0, 2, 3]
Step 9: Queue empty. Result has 6 nodes = V. No cycle!
Final result: [4, 5, 1, 0, 2, 3]
Verify: 4→0 ✅, 4→1 ✅, 5→0 ✅, 5→2 ✅, 1→3 ✅, 2→3 ✅.
Kahn's Algorithm — BFS Topological Sort — Watch how nodes with in-degree 0 are processed first, and their removal 'unlocks' dependent nodes whose in-degrees drop to 0.
Algorithm
- Compute in-degrees: For each node, count the number of incoming edges.
- Initialize
inDegree[i] = 0for all i - For each edge
u → v, incrementinDegree[v]
- Initialize
- Initialize BFS queue: Enqueue all nodes with
inDegree[i] == 0(no prerequisites) - Process BFS:
- While queue is not empty:
a. Dequeue a nodeu, add it to the result list
b. For each neighborvofu:- Decrement
inDegree[v]by 1 - If
inDegree[v] == 0, enqueuev
- Decrement
- While queue is not empty:
- Return result: The result list is a valid topological ordering
- (Optional cycle check: if result.size() < V, graph has a cycle)
Code
#include <vector>
#include <queue>
using namespace std;
vector<int> topoSort(vector<vector<int>>& adj) {
int V = adj.size();
vector<int> inDegree(V, 0);
// Step 1: Compute in-degrees
for (int i = 0; i < V; i++) {
for (int next : adj[i]) {
inDegree[next]++;
}
}
// Step 2: Enqueue all nodes with in-degree 0
queue<int> q;
for (int i = 0; i < V; i++) {
if (inDegree[i] == 0) {
q.push(i);
}
}
// Step 3: BFS — process nodes layer by layer
vector<int> result;
while (!q.empty()) {
int node = q.front();
q.pop();
result.push_back(node);
for (int next : adj[node]) {
inDegree[next]--;
if (inDegree[next] == 0) {
q.push(next);
}
}
}
return result;
}from collections import deque
def topoSort(adj):
V = len(adj)
in_degree = [0] * V
# Step 1: Compute in-degrees
for i in range(V):
for next_node in adj[i]:
in_degree[next_node] += 1
# Step 2: Enqueue all nodes with in-degree 0
queue = deque(i for i in range(V) if in_degree[i] == 0)
# Step 3: BFS — process nodes layer by layer
result = []
while queue:
node = queue.popleft()
result.append(node)
for next_node in adj[node]:
in_degree[next_node] -= 1
if in_degree[next_node] == 0:
queue.append(next_node)
return resultimport java.util.*;
class Solution {
public int[] topoSort(ArrayList<ArrayList<Integer>> adj) {
int V = adj.size();
int[] inDegree = new int[V];
// Step 1: Compute in-degrees
for (int i = 0; i < V; i++) {
for (int next : adj.get(i)) {
inDegree[next]++;
}
}
// Step 2: Enqueue all nodes with in-degree 0
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < V; i++) {
if (inDegree[i] == 0) {
queue.add(i);
}
}
// Step 3: BFS — process nodes layer by layer
int[] result = new int[V];
int idx = 0;
while (!queue.isEmpty()) {
int node = queue.poll();
result[idx++] = node;
for (int next : adj.get(node)) {
inDegree[next]--;
if (inDegree[next] == 0) {
queue.add(next);
}
}
}
return result;
}
}Complexity Analysis
Time Complexity: O(V + E)
- Computing in-degrees: iterate through all V nodes and E edges → O(V + E)
- Initializing the queue: scan all V nodes → O(V)
- BFS processing: each node is dequeued exactly once → O(V). Each edge is examined exactly once (when its source is dequeued) → O(E)
- Total: O(V + E)
Space Complexity: O(V)
- In-degree array: O(V)
- BFS queue: at most V nodes at any time → O(V)
- Result array: O(V)
- Total: O(V)
Comparison of all three approaches:
| Approach | Time | Space | Recursion | Cycle Detection | Order |
|---|---|---|---|---|---|
| Brute Force (Permutations) | O(V! × E) | O(V) | No | No | Direct |
| DFS with Stack | O(V + E) | O(V) | Yes | No (needs extra logic) | Reversed (needs stack) |
| Kahn's Algorithm (BFS) | O(V + E) | O(V) | No | Yes (built-in) | Direct |
Kahn's Algorithm is the most practical:
- Iterative — no risk of stack overflow for deep graphs
- Built-in cycle detection — if result size < V, the graph has a cycle
- Direct ordering — nodes are added to result in correct order, no reversal needed
- Same asymptotic complexity as DFS, but more robust and versatile in practice