LRU Cache
Description
Design a data structure that implements a Least Recently Used (LRU) cache.
An LRU cache stores a fixed number of key-value pairs. When the cache reaches its maximum capacity and a new key needs to be inserted, the least recently used key is evicted to make room. A key becomes "recently used" whenever it is accessed via get or updated/inserted via put.
Implement the LRUCache class with the following methods:
LRUCache(int capacity)— Initialize the cache with a positive integercapacity.int get(int key)— Return the value associated withkeyif it exists in the cache. Otherwise, return-1. Accessing a key marks it as most recently used.void put(int key, int value)— Ifkeyalready exists, update its value. Otherwise, insert the new key-value pair. If inserting causes the cache size to exceedcapacity, evict the least recently used key before inserting.
Both get and put must run in O(1) average time complexity.
Examples
Example 1
Input:
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
Output: [null, null, null, 1, null, -1, null, -1, 3, 4]
Explanation:
LRUCache(2)— Create cache with capacity 2.put(1, 1)— Cache: {1=1}.put(2, 2)— Cache: {1=1, 2=2}. Cache is now full.get(1)— Key 1 exists, return 1. Key 1 is now the most recently used.put(3, 3)— Cache is full. Key 2 is the least recently used (key 1 was just accessed). Evict key 2. Cache: {1=1, 3=3}.get(2)— Key 2 was evicted. Return -1.put(4, 4)— Cache full. Key 1 is now the LRU (key 3 was just inserted). Evict key 1. Cache: {3=3, 4=4}.get(1)— Key 1 was evicted. Return -1.get(3)— Key 3 exists. Return 3.get(4)— Key 4 exists. Return 4.
Example 2
Input:
["LRUCache", "put", "put", "get", "get"]
[[1], [1, 42], [2, 99], [1], [2]]
Output: [null, null, null, -1, 99]
Explanation:
LRUCache(1)— Create cache with capacity 1. Only one key-value pair can be stored.put(1, 42)— Cache: {1=42}.put(2, 99)— Cache is full. Evict key 1 (the only and therefore least recently used key). Cache: {2=99}.get(1)— Key 1 was evicted. Return -1.get(2)— Key 2 exists. Return 99.
Constraints
- 1 ≤ capacity ≤ 3000
- 0 ≤ key ≤ 10^4
- 0 ≤ value ≤ 10^5
- At most 2 × 10^5 calls will be made to
getandput
Editorial
Brute Force — List-Based Cache
Intuition
The most straightforward way to build an LRU cache is to use a simple list (or array) where position encodes recency. The front of the list holds the least recently used item, and the back holds the most recently used.
When we get a key, we scan the list to find it. If found, we move it to the back (marking it as recently used) and return its value. If not found, we return -1.
When we put a key, we first scan the list to see if the key already exists. If it does, we update the value and move it to the back. If it doesn't exist and the cache is full, we remove the front element (the LRU item) and then add the new entry to the back.
Think of it like a stack of papers on a desk. Every time you use a document, you pull it out and place it on top. When the desk is full and you need space for a new document, you throw away the one at the very bottom — the one you haven't touched in the longest time.
Step-by-Step Explanation
Let's trace through Example 1 with capacity = 2:
Step 1: Initialize empty list. Front = LRU, Back = MRU.
Step 2: put(1, 1): Scan list for key 1 — not found. Add (1, 1) to back. Cache: [(1,1)].
Step 3: put(2, 2): Scan list for key 2 — not found. Add (2, 2) to back. Cache: [(1,1), (2,2)]. Cache full.
Step 4: get(1): Scan list from front. Found (1, 1) at index 0. Move it to back (mark as MRU). Cache: [(2,2), (1,1)]. Return 1.
Step 5: put(3, 3): Scan for key 3 — not found. Cache full. Remove front (2, 2) — it is the LRU since key 1 was just accessed. Add (3, 3) to back. Cache: [(1,1), (3,3)].
Step 6: get(2): Scan entire list. Neither entry has key 2 (evicted in step 5). Return -1.
Step 7: put(4, 4): Scan for key 4 — not found. Cache full. Remove front (1, 1) = LRU. Add (4, 4). Cache: [(3,3), (4,4)].
Step 8: Each get and put scanned the entire list to find or confirm the absence of a key, making every operation O(capacity).
List-Based LRU Cache — Linear Scan Operations — Watch how each get and put operation requires scanning the entire list. The front element is always the LRU candidate for eviction, and accessed items move to the back.
Algorithm
Data structure: A list of (key, value) pairs ordered by recency (front = LRU, back = MRU).
get(key):
- Scan the list from front to back looking for
key - If found at index
i:- Remove element at index
i - Append it to the back (mark as MRU)
- Return its value
- Remove element at index
- If not found, return -1
put(key, value):
- Scan the list for
key - If found, remove it from its current position
- If not found and list size equals capacity, remove the front element (LRU eviction)
- Append (key, value) to the back
Code
#include <vector>
using namespace std;
class LRUCache {
int capacity;
vector<pair<int, int>> cache;
public:
LRUCache(int capacity) : capacity(capacity) {}
int get(int key) {
for (int i = 0; i < cache.size(); i++) {
if (cache[i].first == key) {
int val = cache[i].second;
cache.erase(cache.begin() + i);
cache.push_back({key, val});
return val;
}
}
return -1;
}
void put(int key, int value) {
for (int i = 0; i < cache.size(); i++) {
if (cache[i].first == key) {
cache.erase(cache.begin() + i);
cache.push_back({key, value});
return;
}
}
if (cache.size() == capacity) {
cache.erase(cache.begin());
}
cache.push_back({key, value});
}
};class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.cache = [] # List of (key, value) tuples
def get(self, key: int) -> int:
for i, (k, v) in enumerate(self.cache):
if k == key:
self.cache.pop(i)
self.cache.append((key, v))
return v
return -1
def put(self, key: int, value: int) -> None:
for i, (k, v) in enumerate(self.cache):
if k == key:
self.cache.pop(i)
self.cache.append((key, value))
return
if len(self.cache) == self.capacity:
self.cache.pop(0) # Remove LRU (front)
self.cache.append((key, value))import java.util.ArrayList;
import java.util.List;
class LRUCache {
private int capacity;
private List<int[]> cache; // Each entry: {key, value}
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new ArrayList<>();
}
public int get(int key) {
for (int i = 0; i < cache.size(); i++) {
if (cache.get(i)[0] == key) {
int val = cache.get(i)[1];
cache.remove(i);
cache.add(new int[]{key, val});
return val;
}
}
return -1;
}
public void put(int key, int value) {
for (int i = 0; i < cache.size(); i++) {
if (cache.get(i)[0] == key) {
cache.remove(i);
cache.add(new int[]{key, value});
return;
}
}
if (cache.size() == capacity) {
cache.remove(0);
}
cache.add(new int[]{key, value});
}
}Complexity Analysis
Time Complexity: O(n) per operation, where n is the cache capacity
Both get and put perform a linear scan through the list to find or confirm the absence of a key. In the worst case, we scan all capacity elements. Additionally, removing an element from the middle of a list (via erase or pop) is O(n) because subsequent elements must shift. Total per operation: O(n).
Space Complexity: O(capacity)
The list stores at most capacity key-value pairs. No additional data structures are used.
Why This Approach Is Not Efficient
The list-based approach performs a linear scan for every get and put call. With cache capacity up to 3000 and up to 2 × 10^5 total operations, the worst case is 3000 × 200,000 = 6 × 10^8 comparisons. This is borderline — and the constant factor from array shifting (removing from the middle and re-inserting) makes it even slower in practice.
The fundamental problem has two parts:
-
Finding a key is O(n): We scan the entire list because there's no index structure mapping keys to their positions. A hash map would give O(1) lookup.
-
Reordering is O(n): When we find a key and move it to the back, we remove it from the middle of an array (O(n) shift) and append it. A doubly linked list would make both removal and insertion O(1) via pointer manipulation.
Key insight: We need TWO capabilities simultaneously:
- O(1) key lookup → Hash Map
- O(1) insertion/removal/reordering → Doubly Linked List
Combining a hash map with a doubly linked list gives us both — each operation becomes O(1).
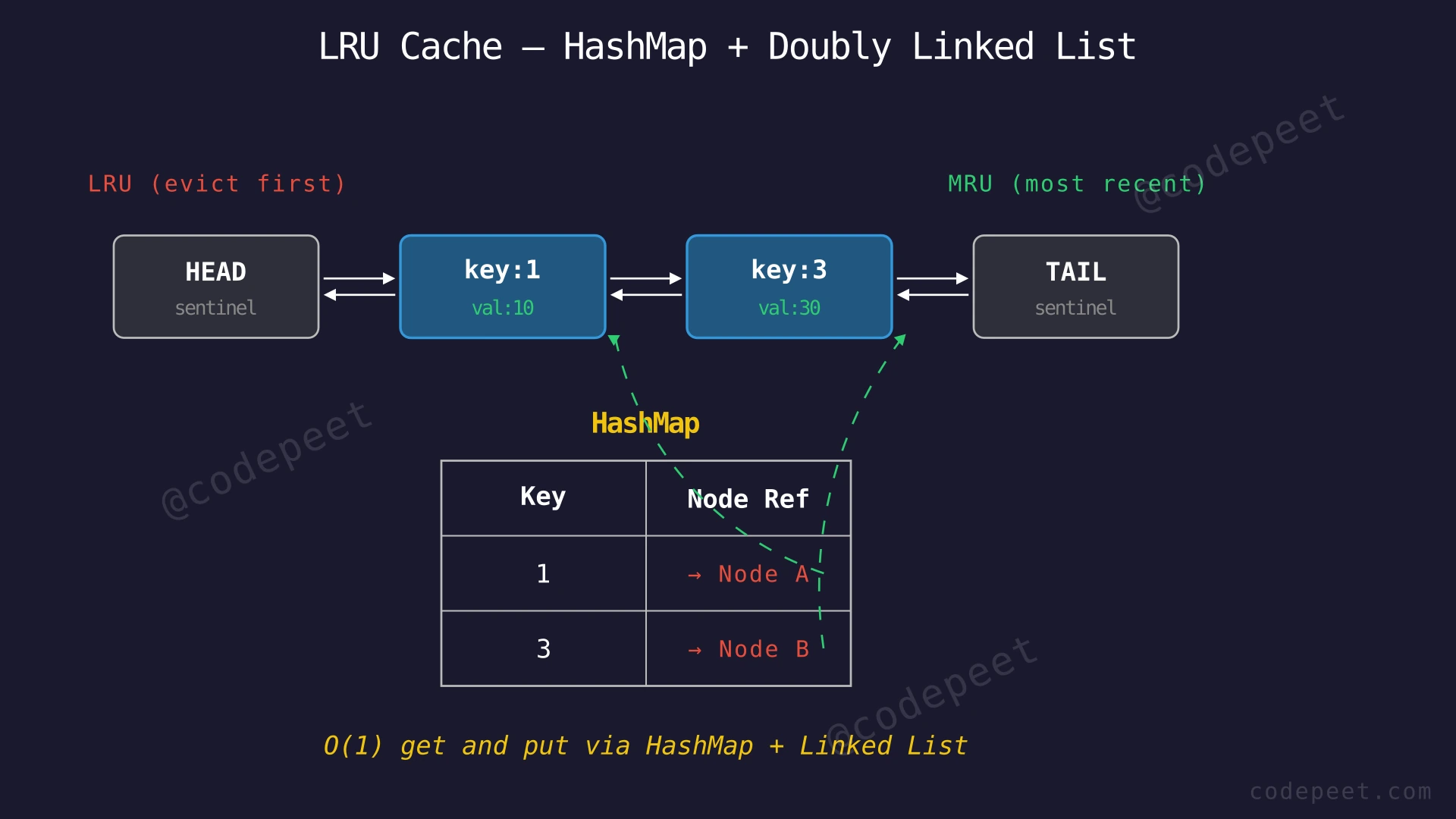
Optimal Approach — HashMap + Doubly Linked List
Intuition
The key insight is that we need two things at once: fast lookup by key and fast reordering by recency. No single data structure provides both, but we can combine two:
-
Hash Map (dictionary): Maps each key to its corresponding node in the linked list. This gives O(1) lookup — we instantly know whether a key exists and where its data lives.
-
Doubly Linked List (DLL): Maintains the recency order. The node right after the HEAD sentinel is the LRU (least recently used), and the node right before the TAIL sentinel is the MRU (most recently used). Because every node has both
prevandnextpointers, we can remove any node or insert at the tail in O(1) — just rewire 4 pointers.
We use sentinel nodes (dummy HEAD and TAIL) to avoid edge cases. The sentinel nodes never hold real data — they just serve as fixed anchors so we never have to check for null when unlinking or relinking.
When we get(key), we look up the key in the hash map (O(1)), then move the found node to before TAIL (O(1) pointer rewiring). When we put(key, value), we either update an existing node and move it, or create a new node, add it before TAIL, and if we're over capacity, remove HEAD.next (the LRU) — all O(1).
Step-by-Step Explanation
Let's trace through Example 1 with capacity = 2. We use a DLL with sentinel HEAD and TAIL nodes, plus a hash map:
Step 1: Initialize. DLL: HEAD ↔ TAIL. Hash map: empty.
Step 2: put(1, 1): Key 1 not in map. Create node (1,1), insert before TAIL. DLL: HEAD ↔ (1,1) ↔ TAIL. Map: {1 → node}.
Step 3: put(2, 2): Key 2 not in map. Insert before TAIL. DLL: HEAD ↔ (1,1) ↔ (2,2) ↔ TAIL. Map: {1, 2}. Cache full.
Step 4: get(1): Look up key 1 in hash map — found instantly (O(1)). Unlink node (1,1) from between HEAD and (2,2), then relink it before TAIL. DLL: HEAD ↔ (2,2) ↔ (1,1) ↔ TAIL. Return 1.
Step 5: put(3, 3): Key 3 not in map. Cache full — evict LRU. LRU = HEAD.next = (2,2). Unlink (2,2), remove key 2 from map. Insert node (3,3) before TAIL. DLL: HEAD ↔ (1,1) ↔ (3,3) ↔ TAIL.
Step 6: get(2): Hash map lookup for key 2 — not found (O(1)). Return -1. No pointer changes needed.
Step 7: put(4, 4): Key 4 not in map. Evict LRU = HEAD.next = (1,1). Remove from DLL and map. Insert (4,4) before TAIL. DLL: HEAD ↔ (3,3) ↔ (4,4) ↔ TAIL.
Step 8: Every operation was O(1). The hash map eliminated scanning, and the DLL made insertion, removal, and reordering instant through pointer rewiring.
HashMap + Doubly Linked List — O(1) LRU Operations — Watch how the hash map provides instant key lookup and the doubly linked list enables O(1) node removal, insertion, and reordering. Every operation touches only a constant number of pointers.
Algorithm
Data structures:
- Doubly linked list (DLL) with sentinel HEAD and TAIL nodes
- Hash map: key → DLL node reference
Helper: removeNode(node) — Unlink node from DLL:
node.prev.next = node.nextnode.next.prev = node.prev
Helper: addBeforeTail(node) — Insert node as MRU:
node.prev = tail.prevnode.next = tailtail.prev.next = nodetail.prev = node
get(key):
- If key not in map, return -1
- Get node from map
removeNode(node)thenaddBeforeTail(node)(move to MRU)- Return
node.value
put(key, value):
- If key exists in map:
- Update
node.value removeNode(node)thenaddBeforeTail(node)
- Update
- Else:
- If map size == capacity:
lru = head.next(least recently used)removeNode(lru), removelru.keyfrom map
- Create new node,
addBeforeTail(newNode), add to map
- If map size == capacity:
Code
#include <unordered_map>
using namespace std;
class LRUCache {
struct Node {
int key, val;
Node* prev;
Node* next;
Node(int k, int v) : key(k), val(v), prev(nullptr), next(nullptr) {}
};
int capacity;
unordered_map<int, Node*> map;
Node* head;
Node* tail;
void removeNode(Node* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
void addBeforeTail(Node* node) {
node->prev = tail->prev;
node->next = tail;
tail->prev->next = node;
tail->prev = node;
}
public:
LRUCache(int capacity) : capacity(capacity) {
head = new Node(0, 0);
tail = new Node(0, 0);
head->next = tail;
tail->prev = head;
}
int get(int key) {
if (map.find(key) == map.end()) return -1;
Node* node = map[key];
removeNode(node);
addBeforeTail(node);
return node->val;
}
void put(int key, int value) {
if (map.find(key) != map.end()) {
Node* node = map[key];
node->val = value;
removeNode(node);
addBeforeTail(node);
} else {
if ((int)map.size() == capacity) {
Node* lru = head->next;
removeNode(lru);
map.erase(lru->key);
delete lru;
}
Node* newNode = new Node(key, value);
addBeforeTail(newNode);
map[key] = newNode;
}
}
};class Node:
def __init__(self, key=0, val=0):
self.key = key
self.val = val
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.map = {}
self.head = Node() # Sentinel
self.tail = Node() # Sentinel
self.head.next = self.tail
self.tail.prev = self.head
def _remove(self, node):
node.prev.next = node.next
node.next.prev = node.prev
def _add_before_tail(self, node):
node.prev = self.tail.prev
node.next = self.tail
self.tail.prev.next = node
self.tail.prev = node
def get(self, key: int) -> int:
if key not in self.map:
return -1
node = self.map[key]
self._remove(node)
self._add_before_tail(node)
return node.val
def put(self, key: int, value: int) -> None:
if key in self.map:
node = self.map[key]
node.val = value
self._remove(node)
self._add_before_tail(node)
else:
if len(self.map) == self.capacity:
lru = self.head.next
self._remove(lru)
del self.map[lru.key]
new_node = Node(key, value)
self._add_before_tail(new_node)
self.map[key] = new_nodeimport java.util.HashMap;
import java.util.Map;
class LRUCache {
class Node {
int key, val;
Node prev, next;
Node(int key, int val) {
this.key = key;
this.val = val;
}
}
private int capacity;
private Map<Integer, Node> map;
private Node head, tail;
public LRUCache(int capacity) {
this.capacity = capacity;
map = new HashMap<>();
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
}
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addBeforeTail(Node node) {
node.prev = tail.prev;
node.next = tail;
tail.prev.next = node;
tail.prev = node;
}
public int get(int key) {
if (!map.containsKey(key)) return -1;
Node node = map.get(key);
removeNode(node);
addBeforeTail(node);
return node.val;
}
public void put(int key, int value) {
if (map.containsKey(key)) {
Node node = map.get(key);
node.val = value;
removeNode(node);
addBeforeTail(node);
} else {
if (map.size() == capacity) {
Node lru = head.next;
removeNode(lru);
map.remove(lru.key);
}
Node newNode = new Node(key, value);
addBeforeTail(newNode);
map.put(key, newNode);
}
}
}Complexity Analysis
Time Complexity: O(1) per operation (amortized)
get: Hash map lookup is O(1). Removing a node from the DLL and re-inserting before TAIL involves rewiring a fixed number of pointers (4 pointer assignments for remove, 4 for insert) — O(1).put: Hash map lookup/insert/delete is O(1) amortized. DLL node removal and insertion are O(1). Eviction accesses HEAD.next directly — no searching.
Every operation performs a constant number of hash map operations and pointer manipulations, regardless of cache size.
Space Complexity: O(capacity)
The hash map stores at most capacity entries. The DLL stores at most capacity data nodes plus 2 sentinel nodes. Total space: O(capacity).