Construct Binary Tree from Inorder and Postorder Traversal
Description
Given two integer arrays inorder and postorder where inorder is the inorder traversal of a binary tree and postorder is the postorder traversal of the same tree, construct and return the binary tree.
Recall the traversal orders:
- Inorder: Left subtree → Root → Right subtree
- Postorder: Left subtree → Right subtree → Root
You are guaranteed that:
- All values are unique.
- The inorder and postorder sequences are valid traversals of the same binary tree.
- A unique binary tree always exists for a valid inorder + postorder pair.
Examples
Example 1
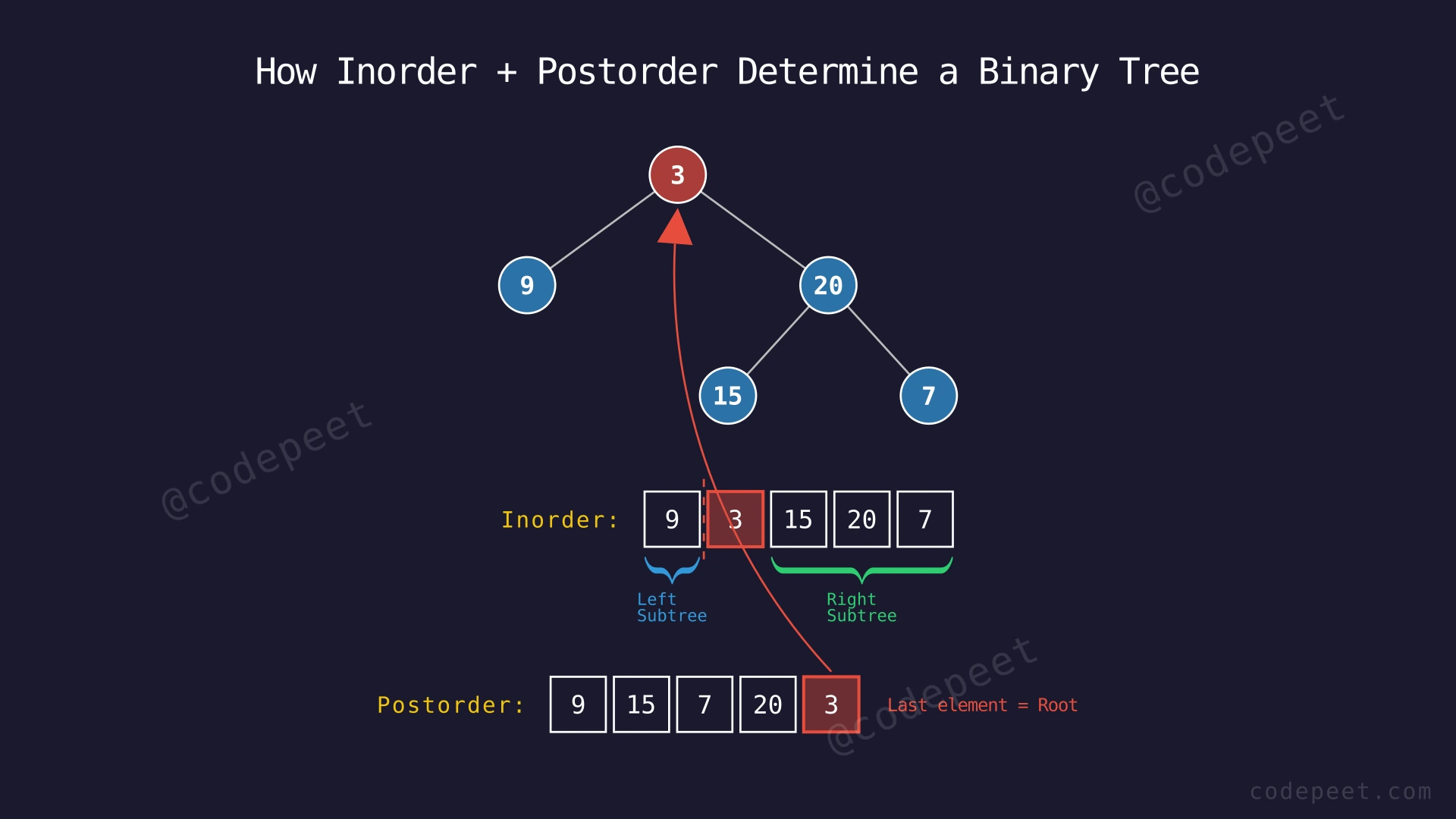
Input: inorder = [9, 3, 15, 20, 7], postorder = [9, 15, 7, 20, 3]
Output: [3, 9, 20, null, null, 15, 7]
Explanation: The last element of postorder is 3 — this is the root. Finding 3 in inorder at index 1 splits the tree: inorder[0..0] = [9] forms the left subtree (just node 9), and inorder[2..4] = [15, 20, 7] forms the right subtree. Recursively applying the same logic builds:
3
/ \
9 20
/ \
15 7
Example 2
Input: inorder = [-1], postorder = [-1]
Output: [-1]
Explanation: Both arrays contain a single element, -1. The tree consists of just one node with value -1 and no children. This is the simplest possible case — the root is the only node.
Example 3
Input: inorder = [2, 1, 3], postorder = [2, 3, 1]
Output: [1, 2, 3]
Explanation: Postorder's last element is 1 — the root. In inorder, 1 is at index 1. Left partition [2] becomes the left child, right partition [3] becomes the right child. The resulting tree is:
1
/ \
2 3
Constraints
- 1 ≤ inorder.length ≤ 3000
- postorder.length == inorder.length
- -3000 ≤ inorder[i], postorder[i] ≤ 3000
- inorder and postorder consist of unique values
- Each value of postorder also appears in inorder
- inorder is guaranteed to be the inorder traversal of the tree
- postorder is guaranteed to be the postorder traversal of the tree
Editorial
Brute Force
Intuition
The key observation is that postorder traversal visits the root last within any subtree. So the last element of the postorder array is always the root of the entire tree. Similarly, within any subtree's portion of the postorder array, the last element is that subtree's root.
Once we know the root, we use the inorder array to split nodes into left and right subtrees. In inorder traversal (Left → Root → Right), all elements to the left of the root belong to the left subtree, and all elements to the right belong to the right subtree.
The brute force approach combines these observations with a simple linear search: for each root identified from postorder, we scan through the inorder array to find its position and determine the split point.
One crucial detail: when processing postorder in reverse (right to left), we must build the right subtree before the left subtree. This is because postorder stores nodes as Left → Right → Root. Reading backwards gives Root → Right → Left. So after taking the root, the next elements belong to the right subtree, not the left.
Step-by-Step Explanation
Let's trace through with inorder = [9, 3, 15, 20, 7], postorder = [9, 15, 7, 20, 3]:
Step 1: Initialize postIndex = 4 (pointing to the last element of postorder). We will decrement this index each time we create a new node.
Step 2: Take postorder[4] = 3. Create root node with value 3. Decrement postIndex to 3.
Step 3: Linear search for 3 in inorder[0..4]: check index 0 (value 9 ≠ 3), check index 1 (value 3 = 3). Found at index 1 after 2 comparisons. Left partition: inorder[0..0] = [9]. Right partition: inorder[2..4] = [15, 20, 7]. Process right subtree first.
Step 4: Right subtree of root 3. Take postorder[3] = 20. Create node 20 as right child of 3. postIndex = 2.
Step 5: Linear search for 20 in inorder[2..4]: check index 2 (15 ≠ 20), check index 3 (20 = 20). Found at index 3 after 2 comparisons. Left: [15]. Right: [7]. Go right first.
Step 6: Take postorder[2] = 7. Create node 7. Inorder[4..4] = [7] — single element, so it is a leaf. Place as right child of 20. postIndex = 1.
Step 7: Take postorder[1] = 15. Create node 15. Inorder[2..2] = [15] — single element, leaf. Place as left child of 20. postIndex = 0. Right subtree of root 3 is complete.
Step 8: Back to left subtree of root 3. Take postorder[0] = 9. Create node 9. Inorder[0..0] = [9] — single element, leaf. Place as left child of 3. postIndex = -1.
Step 9: All postorder elements processed. Tree fully constructed:
3
/ \
9 20
/ \
15 7
Brute Force — Recursive Construction with Linear Search — Watch how we pick roots from postorder (right to left) and use linear search in inorder to split nodes into left and right subtrees at each recursive step.
Algorithm
- Initialize postIndex = postorder.length - 1 (pointing to the last element)
- Define recursive function build(inStart, inEnd):
a. Base case: if inStart > inEnd, return null (empty subtree)
b. Take postorder[postIndex] as the root value. Decrement postIndex.
c. Create a new tree node with this value.
d. Linear search for root value in inorder[inStart..inEnd] to find index inIdx.
e. Right first: root.right = build(inIdx + 1, inEnd)
f. Left second: root.left = build(inStart, inIdx - 1)
g. Return root. - Call build(0, n - 1) and return the result.
Code
class Solution {
public:
int postIdx;
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
postIdx = postorder.size() - 1;
return build(inorder, postorder, 0, inorder.size() - 1);
}
TreeNode* build(vector<int>& inorder, vector<int>& postorder,
int inStart, int inEnd) {
if (inStart > inEnd) return nullptr;
int rootVal = postorder[postIdx--];
TreeNode* root = new TreeNode(rootVal);
// Linear search for root position in inorder
int inIdx = inStart;
for (int i = inStart; i <= inEnd; i++) {
if (inorder[i] == rootVal) {
inIdx = i;
break;
}
}
// Build right subtree FIRST, then left
// (postorder in reverse: Root -> Right -> Left)
root->right = build(inorder, postorder, inIdx + 1, inEnd);
root->left = build(inorder, postorder, inStart, inIdx - 1);
return root;
}
};class Solution:
def buildTree(self, inorder: list[int], postorder: list[int]) -> Optional[TreeNode]:
self.post_idx = len(postorder) - 1
def build(in_start, in_end):
if in_start > in_end:
return None
root_val = postorder[self.post_idx]
self.post_idx -= 1
root = TreeNode(root_val)
# Linear search for root in inorder
in_idx = in_start
for i in range(in_start, in_end + 1):
if inorder[i] == root_val:
in_idx = i
break
# Build right subtree FIRST, then left
root.right = build(in_idx + 1, in_end)
root.left = build(in_start, in_idx - 1)
return root
return build(0, len(inorder) - 1)class Solution {
private int postIdx;
public TreeNode buildTree(int[] inorder, int[] postorder) {
postIdx = postorder.length - 1;
return build(inorder, postorder, 0, inorder.length - 1);
}
private TreeNode build(int[] inorder, int[] postorder,
int inStart, int inEnd) {
if (inStart > inEnd) return null;
int rootVal = postorder[postIdx--];
TreeNode root = new TreeNode(rootVal);
// Linear search for root position in inorder
int inIdx = inStart;
for (int i = inStart; i <= inEnd; i++) {
if (inorder[i] == rootVal) {
inIdx = i;
break;
}
}
// Build right subtree FIRST, then left
root.right = build(inorder, postorder, inIdx + 1, inEnd);
root.left = build(inorder, postorder, inStart, inIdx - 1);
return root;
}
}Complexity Analysis
Time Complexity: O(n²)
For each of the n nodes, we perform a linear search in the inorder array to find the root's position. In the worst case (a completely skewed tree — all nodes in the left subtree or all in the right subtree), each search scans up to n elements. This gives n nodes × O(n) search per node = O(n²) total.
In the average case (balanced tree), the search range halves at each level, giving roughly O(n log n). But the worst case remains O(n²).
Space Complexity: O(n)
The recursion stack depth equals the height of the tree. In the worst case (skewed tree), the height is n, so the stack uses O(n) space. In the average case (balanced tree), it uses O(log n).
Why This Approach Is Not Efficient
The brute force approach performs a linear search through the inorder array for every node to find its position and determine the left-right split. In the worst case (a completely left-skewed or right-skewed tree), this search takes O(n) time per node, leading to O(n²) total time.
With n up to 3000, this means up to 9 × 10⁶ operations in the worst case — which may be acceptable for this constraint but is clearly inefficient and wasteful.
The bottleneck is obvious: we keep searching the same inorder array repeatedly. For each of the n nodes, we scan a portion of the inorder array to find where the current root sits. The values in the inorder array never change, yet we re-scan them over and over.
This is exactly the kind of redundant repeated lookup that a hash map is designed to eliminate. If we precompute the position of every inorder value in a dictionary before starting the recursion, each lookup becomes O(1) instead of O(n), reducing the total time from O(n²) to O(n).
Optimal Approach - Hash Map Indexed Construction
Intuition
The recursive structure of our solution is already correct — the brute force correctly identifies roots from postorder and splits subtrees using inorder. The only inefficiency is the linear search for each root in the inorder array.
The fix is straightforward: before starting the recursion, build a hash map that maps every inorder value to its index. Since all values are unique (guaranteed by the constraints), each value maps to exactly one index.
With this hash map:
- Finding the root's position in inorder goes from O(n) to O(1)
- The rest of the algorithm stays exactly the same
- Total time drops from O(n²) to O(n)
Think of it like having an index at the back of a textbook. Instead of flipping through every page to find a topic (linear search), you look up the page number in the index (hash map lookup) and go directly there.
Step-by-Step Explanation
Let's trace with inorder = [9, 3, 15, 20, 7], postorder = [9, 15, 7, 20, 3]:
Step 1: Build hash map from inorder: {9→0, 3→1, 15→2, 20→3, 7→4}. This one-time O(n) preprocessing eliminates all future linear searches. Set postIndex = 4.
Step 2: Take postorder[4] = 3 as root. Hash map lookup: map[3] = 1 — found in O(1). Create root node 3. Decrement postIndex to 3.
Step 3: Split inorder at index 1. Left: inorder[0..0] = [9] (1 node). Right: inorder[2..4] = [15, 20, 7] (3 nodes). Process right subtree first.
Step 4: Right subtree of root 3. Take postorder[3] = 20. Hash lookup: map[20] = 3 — O(1). Create node 20 as right child. postIndex = 2.
Step 5: Split at index 3. Left: [15] (1 node). Right: [7] (1 node). Both are single elements — leaf nodes.
Step 6: Take postorder[2] = 7. Hash lookup: map[7] = 4. Single element → leaf. Place as right child of 20. postIndex = 1.
Step 7: Take postorder[1] = 15. Hash lookup: map[15] = 2. Single element → leaf. Place as left child of 20. postIndex = 0. Right subtree of root complete.
Step 8: Left subtree of root 3. Take postorder[0] = 9. Hash lookup: map[9] = 0. Single element → leaf. Place as left child of root 3. postIndex = -1.
Step 9: All nodes placed. Tree fully constructed. Each of the 5 lookups was O(1) via hash map — total O(n) time.
3
/ \
9 20
/ \
15 7
Optimal — Hash Map Indexed Tree Construction — Watch how preprocessing inorder values into a hash map turns every root lookup from O(n) linear scan into O(1) instant access, building the tree in linear time.
Algorithm
- Preprocessing: Build a hash map mapping each inorder value to its index.
- Initialize postIndex = postorder.length - 1.
- Define recursive function build(inStart, inEnd):
a. Base case: if inStart > inEnd, return null.
b. Take postorder[postIndex] as root value. Decrement postIndex.
c. Create new tree node.
d. Hash map lookup: inIdx = map[rootValue] — O(1).
e. Right first: root.right = build(inIdx + 1, inEnd).
f. Left second: root.left = build(inStart, inIdx - 1).
g. Return root. - Call build(0, n - 1) and return the result.
Code
class Solution {
public:
int postIdx;
unordered_map<int, int> inMap;
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
// Preprocessing: map each inorder value to its index
for (int i = 0; i < inorder.size(); i++) {
inMap[inorder[i]] = i;
}
postIdx = postorder.size() - 1;
return build(postorder, 0, inorder.size() - 1);
}
TreeNode* build(vector<int>& postorder, int inStart, int inEnd) {
if (inStart > inEnd) return nullptr;
int rootVal = postorder[postIdx--];
TreeNode* root = new TreeNode(rootVal);
int inIdx = inMap[rootVal]; // O(1) hash map lookup
// Build right subtree FIRST, then left
root->right = build(postorder, inIdx + 1, inEnd);
root->left = build(postorder, inStart, inIdx - 1);
return root;
}
};class Solution:
def buildTree(self, inorder: list[int], postorder: list[int]) -> Optional[TreeNode]:
# Preprocessing: map each inorder value to its index
in_map = {val: idx for idx, val in enumerate(inorder)}
self.post_idx = len(postorder) - 1
def build(in_start, in_end):
if in_start > in_end:
return None
root_val = postorder[self.post_idx]
self.post_idx -= 1
root = TreeNode(root_val)
in_idx = in_map[root_val] # O(1) hash map lookup
# Build right subtree FIRST, then left
root.right = build(in_idx + 1, in_end)
root.left = build(in_start, in_idx - 1)
return root
return build(0, len(inorder) - 1)class Solution {
private int postIdx;
private Map<Integer, Integer> inMap = new HashMap<>();
public TreeNode buildTree(int[] inorder, int[] postorder) {
// Preprocessing: map each inorder value to its index
for (int i = 0; i < inorder.length; i++) {
inMap.put(inorder[i], i);
}
postIdx = postorder.length - 1;
return build(postorder, 0, inorder.length - 1);
}
private TreeNode build(int[] postorder, int inStart, int inEnd) {
if (inStart > inEnd) return null;
int rootVal = postorder[postIdx--];
TreeNode root = new TreeNode(rootVal);
int inIdx = inMap.get(rootVal); // O(1) hash map lookup
// Build right subtree FIRST, then left
root.right = build(postorder, inIdx + 1, inEnd);
root.left = build(postorder, inStart, inIdx - 1);
return root;
}
}Complexity Analysis
Time Complexity: O(n)
Building the hash map takes O(n) — one pass through the inorder array. The recursive construction visits each node exactly once, and each visit performs a single O(1) hash map lookup plus O(1) node creation. Total: O(n) preprocessing + O(n) construction = O(n).
Compared to the brute force O(n²), this is a significant improvement — especially for skewed trees where the brute force degrades most.
Space Complexity: O(n)
The hash map stores n key-value pairs → O(n) space. The recursion stack depth equals the tree height — O(n) in the worst case (skewed tree), O(log n) for balanced. Combined: O(n).