Kahn's Algorithm (BFS Topo Sort)
Description
Given a Directed Acyclic Graph (DAG) with V vertices (numbered 0 to V-1) and E edges, find any valid topological ordering of the graph.
A topological ordering is a linear arrangement of the vertices such that for every directed edge u → v, vertex u appears before vertex v in the ordering.
The graph is represented as an adjacency list where adj[i] contains all vertices that vertex i has a directed edge to.
Topological sorting is only possible for DAGs — graphs that are directed and contain no cycles. If the graph were cyclic, no valid ordering could exist because at least one vertex would need to appear both before and after another vertex.
Examples
Example 1
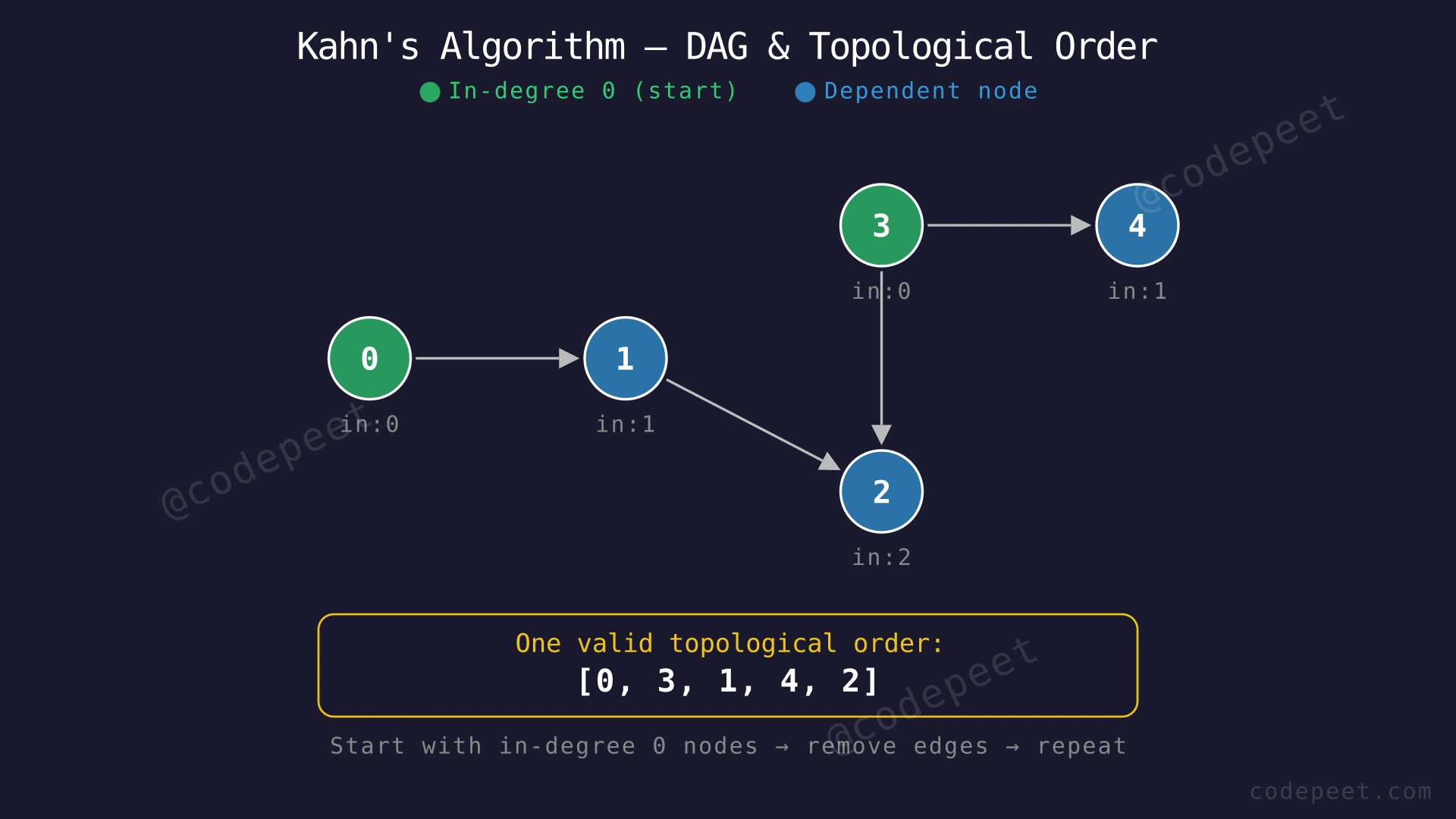
Input: V = 5, adj = [[1], [2], [], [2, 4], []]
Output: [0, 3, 1, 4, 2]
Explanation: The graph has edges 0→1, 1→2, 3→2, and 3→4. In the ordering [0, 3, 1, 4, 2], every directed edge is respected: 0 appears before 1, 1 appears before 2, 3 appears before both 2 and 4. Vertices 0 and 3 have no incoming edges, so they can appear first in any order. Other valid orderings include [3, 0, 4, 1, 2] and [3, 4, 0, 1, 2].
Example 2
Input: V = 6, adj = [[1], [2], [3], [], [5], [1, 2]]
Output: [0, 4, 5, 1, 2, 3]
Explanation: The graph has edges 0→1, 1→2, 2→3, 4→5, 5→1, and 5→2. In the ordering [0, 4, 5, 1, 2, 3], every dependency is satisfied: 0 comes before 1, 4 comes before 5, 5 comes before both 1 and 2, 1 comes before 2, and 2 comes before 3. Another valid ordering is [4, 5, 0, 1, 2, 3].
Example 3
Input: V = 4, adj = [[1], [2], [3], []]
Output: [0, 1, 2, 3]
Explanation: This is a simple linear chain: 0→1→2→3. There is only one valid topological ordering since every vertex depends on the one before it. Vertex 0 must come first (no incoming edges), then 1, then 2, and finally 3.
Constraints
- 2 ≤ V ≤ 10^4
- 0 ≤ E ≤ min(V × (V - 1) / 2, 10^5)
- The graph is a Directed Acyclic Graph (DAG)
- The graph is represented as an adjacency list
- There are no self-loops or duplicate edges
Editorial
Brute Force
Intuition
The most straightforward way to find a topological ordering is to try every possible arrangement of the vertices and check which ones satisfy all the edge constraints.
Imagine you have a set of tasks with dependencies. If you had no clever strategy, you could write down every possible order of doing the tasks, then go through each order and check: does this order respect every single dependency? The first valid order you find is your answer.
For each permutation of the V vertices, we iterate over all E edges and verify that for every edge u→v, vertex u appears before vertex v in that permutation. If all edges pass, the permutation is a valid topological order.
Step-by-Step Explanation
Let's trace through with V = 4, adj = [[1], [2], [3], []] (chain 0→1→2→3):
Step 1: Generate all 4! = 24 permutations of [0, 1, 2, 3].
Step 2: Take the first permutation [0, 1, 2, 3]. Check each edge:
- Edge 0→1: Is 0 before 1? Yes (index 0 < index 1). ✓
- Edge 1→2: Is 1 before 2? Yes (index 1 < index 2). ✓
- Edge 2→3: Is 2 before 3? Yes (index 2 < index 3). ✓
- All edges satisfied! This is a valid topological order.
Step 3: Return [0, 1, 2, 3].
But consider a non-chain graph where we might need many attempts:
Step 4: Take permutation [3, 2, 1, 0]. Check edge 0→1: Is 0 before 1? No — 0 is at index 3 and 1 is at index 2. ✗ Invalid. Discard.
Step 5: Take permutation [1, 0, 2, 3]. Check edge 0→1: Is 0 before 1? No — 0 is at index 1 and 1 is at index 0. ✗ Invalid. Discard.
Step 6: We may need to try many permutations before finding a valid one in the general case. With V = 4, there are 24 permutations. With V = 10, there are 3,628,800 permutations. With V = 20, the number exceeds 10^18.
Algorithm
- Generate all V! permutations of the vertex set {0, 1, ..., V-1}
- For each permutation:
a. For every directed edge u→v in the graph, check whether u appears before v in this permutation
b. If all edges are satisfied, return this permutation as a valid topological order
c. If any edge fails, discard this permutation and try the next - Return the first valid permutation found
Code
#include <vector>
#include <algorithm>
#include <numeric>
using namespace std;
class Solution {
public:
vector<int> topoSort(vector<vector<int>>& adj) {
int V = adj.size();
vector<int> perm(V);
iota(perm.begin(), perm.end(), 0);
do {
// Build position map for O(1) lookup
vector<int> pos(V);
for (int i = 0; i < V; i++) {
pos[perm[i]] = i;
}
bool valid = true;
for (int u = 0; u < V && valid; u++) {
for (int v : adj[u]) {
if (pos[u] > pos[v]) {
valid = false;
}
}
}
if (valid) return perm;
} while (next_permutation(perm.begin(), perm.end()));
return {};
}
};from itertools import permutations
class Solution:
def topoSort(self, adj):
V = len(adj)
for perm in permutations(range(V)):
# Build position map for quick lookup
pos = {node: idx for idx, node in enumerate(perm)}
valid = True
for u in range(V):
for v in adj[u]:
if pos[u] > pos[v]:
valid = False
break
if not valid:
break
if valid:
return list(perm)
return []import java.util.*;
class Solution {
public int[] topoSort(List<List<Integer>> adj) {
int V = adj.size();
int[] perm = new int[V];
for (int i = 0; i < V; i++) perm[i] = i;
do {
int[] pos = new int[V];
for (int i = 0; i < V; i++) {
pos[perm[i]] = i;
}
boolean valid = true;
for (int u = 0; u < V && valid; u++) {
for (int v : adj.get(u)) {
if (pos[u] > pos[v]) {
valid = false;
}
}
}
if (valid) return perm.clone();
} while (nextPermutation(perm));
return new int[]{};
}
private boolean nextPermutation(int[] arr) {
int n = arr.length, i = n - 2;
while (i >= 0 && arr[i] >= arr[i + 1]) i--;
if (i < 0) return false;
int j = n - 1;
while (arr[j] <= arr[i]) j--;
int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;
for (int l = i + 1, r = n - 1; l < r; l++, r--) {
tmp = arr[l]; arr[l] = arr[r]; arr[r] = tmp;
}
return true;
}
}Complexity Analysis
Time Complexity: O(V! × (V + E))
In the worst case, we generate all V! permutations. For each permutation, we build a position map in O(V) and then check all E edges, each in O(1) using the position map. Total per permutation is O(V + E). Combined: O(V! × (V + E)), which is astronomically large for even modest values of V.
Space Complexity: O(V)
We store the current permutation and the position array, each of size V.
Why This Approach Is Not Efficient
The brute force approach has factorial time complexity O(V!), which grows unimaginably fast. For V = 10, there are 3.6 million permutations. For V = 15, there are over 1.3 trillion permutations. For V = 20, the number exceeds 2.4 × 10^18 — more than a computer can process in a human lifetime.
With the constraint V ≤ 10^4, this approach is completely infeasible. The fundamental flaw is that we are blindly generating orderings without using the graph structure. We know that a vertex with no incoming edges can safely go first, and we know that removing a processed vertex changes the dependency landscape — but the brute force ignores all of this.
The key insight for improvement: instead of guessing orderings, we can build the ordering one vertex at a time by following the dependency structure of the graph. Graph traversal algorithms (DFS or BFS) can systematically determine which vertices can come next, reducing the problem from factorial to linear time.
Better Approach - DFS with Stack
Intuition
Instead of trying random orderings, we can exploit a key property of topological sort: a vertex should appear in the ordering only after all vertices it leads to have been placed. This is exactly what post-order DFS gives us.
Think of it like finishing homework assignments with dependencies. You pick one assignment and follow its dependency chain all the way to the deepest requirement — the assignment that depends on nothing else. That deepest one finishes first, so it goes to the bottom of your "done" stack. As you backtrack, each completed assignment gets pushed onto the stack. When you flip the stack over, you get a valid order to do the work.
Concretely, we run DFS from each unvisited vertex. When a vertex's DFS finishes (all its descendants have been fully explored), we push it onto a stack. After all vertices are processed, we reverse the stack to get the topological order. The reversal is needed because the first vertex to finish DFS is the one with no outgoing paths left — it should come last in the topological order.
Step-by-Step Explanation
Let's trace through with V = 6, adj = [[1], [2], [3], [], [5], [1, 2]]:
Edges: 0→1, 1→2, 2→3, 4→5, 5→1, 5→2
Step 1: Initialize an empty visited set and an empty stack. Start iterating through all vertices.
Step 2: Vertex 0 is unvisited. Begin DFS(0). Mark 0 as visited.
Step 3: DFS(0) explores neighbor 1. Vertex 1 is unvisited. Recurse: DFS(1). Mark 1 as visited.
Step 4: DFS(1) explores neighbor 2. Vertex 2 is unvisited. Recurse: DFS(2). Mark 2 as visited.
Step 5: DFS(2) explores neighbor 3. Vertex 3 is unvisited. Recurse: DFS(3). Mark 3 as visited.
Step 6: DFS(3) has no outgoing edges. All neighbors explored. Push 3 onto stack. Stack: [3].
Step 7: Return to DFS(2). All neighbors of 2 explored. Push 2 onto stack. Stack: [3, 2].
Step 8: Return to DFS(1). All neighbors of 1 explored. Push 1 onto stack. Stack: [3, 2, 1].
Step 9: Return to DFS(0). All neighbors of 0 explored. Push 0 onto stack. Stack: [3, 2, 1, 0].
Step 10: Continue main loop. Vertices 1, 2, 3 are already visited. Vertex 4 is unvisited. Begin DFS(4). Mark 4 as visited.
Step 11: DFS(4) explores neighbor 5. Vertex 5 is unvisited. Recurse: DFS(5). Mark 5 as visited.
Step 12: DFS(5) explores neighbors 1 and 2 — both already visited. All neighbors explored. Push 5 onto stack. Stack: [3, 2, 1, 0, 5].
Step 13: Return to DFS(4). All neighbors of 4 explored. Push 4 onto stack. Stack: [3, 2, 1, 0, 5, 4].
Step 14: All vertices visited. Reverse the stack to get topological order: [4, 5, 0, 1, 2, 3].
DFS with Stack — Post-Order Topological Sort — Watch how DFS explores the deepest dependency chains first, pushing each vertex onto a stack only after all its descendants are fully explored. Reversing the stack yields the topological order.
Algorithm
- Initialize a visited boolean array of size V (all false) and an empty stack
- For each vertex i from 0 to V-1:
- If vertex i is not visited, call DFS(i)
- DFS(u):
a. Mark u as visited
b. For each neighbor v of u:- If v is not visited, call DFS(v)
c. After all neighbors are explored, push u onto the stack
- If v is not visited, call DFS(v)
- After all DFS calls complete, pop elements from the stack into the result array
- Return the result array (this is the reversed stack, giving the topological order)
Code
#include <vector>
#include <stack>
using namespace std;
class Solution {
public:
void dfs(int u, vector<vector<int>>& adj, vector<bool>& visited, stack<int>& st) {
visited[u] = true;
for (int v : adj[u]) {
if (!visited[v]) {
dfs(v, adj, visited, st);
}
}
st.push(u);
}
vector<int> topoSort(vector<vector<int>>& adj) {
int V = adj.size();
vector<bool> visited(V, false);
stack<int> st;
for (int i = 0; i < V; i++) {
if (!visited[i]) {
dfs(i, adj, visited, st);
}
}
vector<int> result;
while (!st.empty()) {
result.push_back(st.top());
st.pop();
}
return result;
}
};class Solution:
def topoSort(self, adj):
V = len(adj)
visited = [False] * V
stack = []
def dfs(u):
visited[u] = True
for v in adj[u]:
if not visited[v]:
dfs(v)
stack.append(u)
for i in range(V):
if not visited[i]:
dfs(i)
return stack[::-1]import java.util.*;
class Solution {
private void dfs(int u, List<List<Integer>> adj, boolean[] visited, Deque<Integer> stack) {
visited[u] = true;
for (int v : adj.get(u)) {
if (!visited[v]) {
dfs(v, adj, visited, stack);
}
}
stack.push(u);
}
public int[] topoSort(List<List<Integer>> adj) {
int V = adj.size();
boolean[] visited = new boolean[V];
Deque<Integer> stack = new ArrayDeque<>();
for (int i = 0; i < V; i++) {
if (!visited[i]) {
dfs(i, adj, visited, stack);
}
}
int[] result = new int[V];
for (int i = 0; i < V; i++) {
result[i] = stack.pop();
}
return result;
}
}Complexity Analysis
Time Complexity: O(V + E)
We visit every vertex exactly once (the visited check ensures no re-processing), and for each vertex we examine all its outgoing edges. Across all vertices, we look at each edge exactly once. Therefore, the total time is O(V + E).
Space Complexity: O(V)
The visited array takes O(V) space. The recursion stack in the worst case (a linear chain of V vertices) can go V levels deep, consuming O(V) stack frames. The result stack also holds V elements. Total auxiliary space: O(V).
Why This Approach Is Not Efficient
While the DFS approach achieves optimal O(V + E) time complexity, it has several practical limitations that make it less suitable for production use:
1. Recursion Stack Overflow: DFS uses recursion, and for deep graphs (e.g., a linear chain of V = 10^4 vertices), the call stack can grow to V frames deep. Many languages and environments have limited stack sizes (typically 1-8 MB), and deep recursion can cause stack overflow errors.
2. No Built-in Cycle Detection: If the graph accidentally contains a cycle (violating the DAG assumption), the DFS-based approach silently produces an incorrect ordering. It does not raise an error or indicate the failure. Detecting cycles in DFS requires additional bookkeeping (tracking recursion stack membership), making the algorithm more complex.
3. Less Intuitive Reasoning: The DFS approach relies on post-order traversal with stack reversal, which is conceptually harder to explain and verify. The "push after all descendants are explored, then reverse" logic can be confusing for learners and prone to implementation bugs.
Key insight for improvement: Instead of exploring deep first and reversing later, we could process vertices in topological order directly — starting from vertices that have zero dependencies (no incoming edges) and peeling them away layer by layer. This is the foundation of Kahn's Algorithm.
Optimal Approach - Kahn's Algorithm (BFS with Indegree)
Intuition
Kahn's Algorithm takes a fundamentally different approach to topological sorting. Instead of diving deep with DFS and reconstructing the order afterward, it builds the ordering directly by asking a simple, repeating question: which vertices have no remaining dependencies right now?
Imagine a university course registration system. Some courses have prerequisites: you cannot take "Data Structures" until you complete "Introduction to Programming". To figure out a valid enrollment order, you start with all courses that have zero prerequisites — these can be taken immediately. Once you "complete" those courses, other courses that only depended on them now have all their prerequisites met. You add those newly unlocked courses to your plan, and repeat until all courses are scheduled.
Formally, the algorithm works as follows:
- Compute in-degree for every vertex — the in-degree of a vertex is the number of edges pointing into it, representing how many prerequisites it has.
- Enqueue all vertices with in-degree 0 — these have no dependencies and can safely appear first.
- Process the queue: Dequeue a vertex, add it to the result, and for each of its neighbors, reduce their in-degree by 1 (since one of their prerequisites is now fulfilled). If any neighbor's in-degree drops to 0, enqueue it.
- Repeat until the queue is empty.
The beauty of this approach is that it naturally produces the topological order without any post-processing (no stack reversal), and it can detect cycles: if the queue empties before all vertices are processed, the graph contains a cycle.
Step-by-Step Explanation
Let's trace through with V = 6, adj = [[1], [2], [3], [], [5], [1, 2]]:
Edges: 0→1, 1→2, 2→3, 4→5, 5→1, 5→2
Step 1: Compute in-degree for each vertex by counting incoming edges:
- Vertex 0: 0 incoming edges → indegree = 0
- Vertex 1: edges from 0 and 5 → indegree = 2
- Vertex 2: edges from 1 and 5 → indegree = 2
- Vertex 3: edge from 2 → indegree = 1
- Vertex 4: 0 incoming edges → indegree = 0
- Vertex 5: edge from 4 → indegree = 1
Step 2: Find all vertices with indegree 0: vertices 0 and 4. Add them to the BFS queue. Queue: [0, 4]. Result: [].
Step 3: Dequeue vertex 0. Add 0 to result. Process edge 0→1: decrease indegree of vertex 1 from 2 to 1. Vertex 1 still has dependencies, so it stays out of the queue. Queue: [4]. Result: [0].
Step 4: Dequeue vertex 4. Add 4 to result. Process edge 4→5: decrease indegree of vertex 5 from 1 to 0. Vertex 5's indegree is now 0 — all its prerequisites are met! Enqueue vertex 5. Queue: [5]. Result: [0, 4].
Step 5: Dequeue vertex 5. Add 5 to result. Process edge 5→1: decrease indegree of vertex 1 from 1 to 0. Enqueue vertex 1. Process edge 5→2: decrease indegree of vertex 2 from 2 to 1. Vertex 2 still has a dependency. Queue: [1]. Result: [0, 4, 5].
Step 6: Dequeue vertex 1. Add 1 to result. Process edge 1→2: decrease indegree of vertex 2 from 1 to 0. Enqueue vertex 2. Queue: [2]. Result: [0, 4, 5, 1].
Step 7: Dequeue vertex 2. Add 2 to result. Process edge 2→3: decrease indegree of vertex 3 from 1 to 0. Enqueue vertex 3. Queue: [3]. Result: [0, 4, 5, 1, 2].
Step 8: Dequeue vertex 3. Add 3 to result. Vertex 3 has no outgoing edges. Queue is empty. Result: [0, 4, 5, 1, 2, 3].
Step 9: Queue is empty and all 6 vertices are in the result. The topological order is [0, 4, 5, 1, 2, 3]. Every edge u→v has u before v. Done!
Kahn's Algorithm — BFS Indegree-Based Topological Sort — Watch how Kahn's algorithm peels away vertices layer by layer: starting with zero-dependency vertices, processing them removes dependencies for their neighbors, unlocking the next layer.
Algorithm
- Create an array
indegreeof size V, initialized to 0 - For each vertex u from 0 to V-1:
- For each neighbor v of u: increment indegree[v] by 1
- Create an empty queue. For each vertex i: if indegree[i] == 0, enqueue i
- Create an empty result list
- While the queue is not empty:
a. Dequeue vertex u from the front
b. Append u to the result list
c. For each neighbor v of u:- Decrease indegree[v] by 1
- If indegree[v] becomes 0, enqueue v
- Return the result list (this is the topological order)
- Optional cycle check: if the result list has fewer than V elements, the graph contains a cycle
Code
#include <vector>
#include <queue>
using namespace std;
class Solution {
public:
vector<int> topoSort(vector<vector<int>>& adj) {
int V = adj.size();
vector<int> indegree(V, 0);
// Step 1: Compute in-degrees
for (int u = 0; u < V; u++) {
for (int v : adj[u]) {
indegree[v]++;
}
}
// Step 2: Enqueue all vertices with in-degree 0
queue<int> q;
for (int i = 0; i < V; i++) {
if (indegree[i] == 0) {
q.push(i);
}
}
// Step 3: BFS — process layer by layer
vector<int> result;
while (!q.empty()) {
int u = q.front();
q.pop();
result.push_back(u);
for (int v : adj[u]) {
indegree[v]--;
if (indegree[v] == 0) {
q.push(v);
}
}
}
return result;
}
};from collections import deque
class Solution:
def topoSort(self, adj):
V = len(adj)
indegree = [0] * V
# Step 1: Compute in-degrees
for u in range(V):
for v in adj[u]:
indegree[v] += 1
# Step 2: Enqueue all vertices with in-degree 0
queue = deque()
for i in range(V):
if indegree[i] == 0:
queue.append(i)
# Step 3: BFS — process layer by layer
result = []
while queue:
u = queue.popleft()
result.append(u)
for v in adj[u]:
indegree[v] -= 1
if indegree[v] == 0:
queue.append(v)
return resultimport java.util.*;
class Solution {
public int[] topoSort(List<List<Integer>> adj) {
int V = adj.size();
int[] indegree = new int[V];
// Step 1: Compute in-degrees
for (int u = 0; u < V; u++) {
for (int v : adj.get(u)) {
indegree[v]++;
}
}
// Step 2: Enqueue all vertices with in-degree 0
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < V; i++) {
if (indegree[i] == 0) {
queue.offer(i);
}
}
// Step 3: BFS — process layer by layer
int[] result = new int[V];
int idx = 0;
while (!queue.isEmpty()) {
int u = queue.poll();
result[idx++] = u;
for (int v : adj.get(u)) {
indegree[v]--;
if (indegree[v] == 0) {
queue.offer(v);
}
}
}
return result;
}
}Complexity Analysis
Time Complexity: O(V + E)
Computing in-degrees requires iterating over all edges once: O(V + E). Finding all zero-indegree vertices is a single pass over V vertices: O(V). The BFS loop processes each vertex exactly once (each vertex enters and leaves the queue at most once), and for each vertex, we examine all its outgoing edges. Across all vertices, this sums to O(E) edge examinations. Total: O(V + E).
Space Complexity: O(V)
The in-degree array takes O(V) space. The queue can hold at most V vertices at any point. The result array stores V vertices. Total auxiliary space: O(V). Importantly, unlike the DFS approach, Kahn's algorithm is fully iterative — it uses no recursion and therefore has no risk of stack overflow, regardless of graph depth.