Enhanced Trie with Count
Description
Design and implement an enhanced version of the Trie (prefix tree) data structure that supports not only basic insertion and search, but also counting how many times a word has been inserted and how many stored words share a given prefix.
You need to implement the following operations:
- Trie() — Initialize an empty Trie object.
- insert(word) — Insert the string
wordinto the Trie. The same word may be inserted multiple times, and each insertion should be tracked. - countWordsEqualTo(word) — Return how many times the exact string
wordhas been inserted into the Trie. - countWordsStartingWith(prefix) — Return the total count of all inserted words that have
prefixas a prefix. If a word was inserted multiple times, each insertion counts separately. - erase(word) — Remove exactly one occurrence of the string
wordfrom the Trie. It is guaranteed that the word exists in the Trie when this operation is called.
Examples
Example 1
Input:
["Trie", "insert", "insert", "insert", "countWordsEqualTo", "countWordsStartingWith", "erase", "countWordsEqualTo", "countWordsStartingWith"]
[[], ["apple"], ["apple"], ["app"], ["apple"], ["app"], ["apple"], ["apple"], ["app"]]
Output: [null, null, null, null, 2, 3, null, 1, 2]
Explanation:
Trie()— Create an empty Trie.insert("apple")— Insert "apple" into the Trie (1st time).insert("apple")— Insert "apple" again (2nd time).insert("app")— Insert "app" into the Trie.countWordsEqualTo("apple")— The word "apple" was inserted 2 times, so return 2.countWordsStartingWith("app")— Three insertions have the prefix "app": two instances of "apple" and one instance of "app". Return 3.erase("apple")— Remove one occurrence of "apple". Now "apple" has been inserted 1 time.countWordsEqualTo("apple")— Only 1 occurrence of "apple" remains, return 1.countWordsStartingWith("app")— Two insertions remain with prefix "app": one "apple" and one "app". Return 2.
Example 2
Input:
["Trie", "insert", "insert", "insert", "erase", "countWordsEqualTo", "countWordsStartingWith"]
[[], ["bat"], ["ball"], ["bat"], ["bat"], ["bat"], ["ba"]]
Output: [null, null, null, null, null, 1, 2]
Explanation:
- Insert "bat", "ball", and "bat" ("bat" is inserted twice).
- Erase one occurrence of "bat". Now "bat" exists once.
countWordsEqualTo("bat")returns 1 (one remaining occurrence).countWordsStartingWith("ba")returns 2 (one "bat" + one "ball" share prefix "ba").
Example 3
Input:
["Trie", "insert", "countWordsEqualTo", "countWordsStartingWith", "erase", "countWordsEqualTo"]
[[], ["a"], ["a"], ["a"], ["a"], ["a"]]
Output: [null, null, 1, 1, null, 0]
Explanation:
- Insert "a" once.
countWordsEqualTo("a")returns 1.countWordsStartingWith("a")returns 1. - After erasing "a",
countWordsEqualTo("a")returns 0 because no occurrences remain.
Constraints
- 1 ≤ number of operations ≤ 10^4
- 1 ≤ |word|, |prefix| ≤ 1000
wordandprefixconsist of lowercase English letters only ('a'to'z')erase(word)is called only when at least one occurrence ofwordexists in the Trie- At most 10^4 calls will be made in total to
insert,countWordsEqualTo,countWordsStartingWith, anderase
Editorial
Brute Force
Intuition
The simplest way to implement this data structure is to store every inserted word in a plain list (array). When a word is inserted twice, it appears twice in the list.
Think of it like maintaining a physical notebook where you write down every word someone tells you. To count how many times "apple" was written, you flip through every page and tally the matches. To find words starting with "app", you check every entry one by one.
This approach requires no clever data structures — just a list and linear scanning. It directly satisfies every operation requirement, but at the cost of scanning the entire list for each query.
Step-by-Step Explanation
Let's trace through a sequence of operations using a list:
Operations: insert("cat"), insert("cat"), insert("car"), countWordsStartingWith("ca")
Step 1: Initialize an empty list: words = []
Step 2: insert("cat") — Append "cat" to the list.
- words = ["cat"]
Step 3: insert("cat") — Append "cat" again.
- words = ["cat", "cat"]
Step 4: insert("car") — Append "car".
- words = ["cat", "cat", "car"]
Step 5: countWordsStartingWith("ca") — Scan every word in the list.
- Check index 0: "cat" starts with "ca"? Yes → count = 1
Step 6: Check index 1: "cat" starts with "ca"? Yes → count = 2
Step 7: Check index 2: "car" starts with "ca"? Yes → count = 3
Step 8: All words checked. Return 3.
Brute Force — Scanning a Word List — Watch how every query requires scanning through the entire word list, checking each stored word one by one.
Algorithm
- Maintain a list (dynamic array) of all inserted words
- insert(word): Append
wordto the list - countWordsEqualTo(word): Iterate through the list, count entries that exactly match
word - countWordsStartingWith(prefix): Iterate through the list, count entries whose beginning matches
prefix - erase(word): Find the first occurrence of
wordin the list and remove it
Code
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
class Trie {
private:
vector<string> words;
public:
Trie() {}
void insert(string word) {
words.push_back(word);
}
int countWordsEqualTo(string word) {
int count = 0;
for (const string& w : words) {
if (w == word) count++;
}
return count;
}
int countWordsStartingWith(string prefix) {
int count = 0;
for (const string& w : words) {
if (w.size() >= prefix.size() &&
w.substr(0, prefix.size()) == prefix) {
count++;
}
}
return count;
}
void erase(string word) {
for (int i = 0; i < words.size(); i++) {
if (words[i] == word) {
words.erase(words.begin() + i);
return;
}
}
}
};class Trie:
def __init__(self):
self.words = []
def insert(self, word: str) -> None:
self.words.append(word)
def countWordsEqualTo(self, word: str) -> int:
count = 0
for w in self.words:
if w == word:
count += 1
return count
def countWordsStartingWith(self, prefix: str) -> int:
count = 0
for w in self.words:
if w.startswith(prefix):
count += 1
return count
def erase(self, word: str) -> None:
for i in range(len(self.words)):
if self.words[i] == word:
self.words.pop(i)
returnimport java.util.ArrayList;
import java.util.List;
class Trie {
private List<String> words;
public Trie() {
words = new ArrayList<>();
}
public void insert(String word) {
words.add(word);
}
public int countWordsEqualTo(String word) {
int count = 0;
for (String w : words) {
if (w.equals(word)) count++;
}
return count;
}
public int countWordsStartingWith(String prefix) {
int count = 0;
for (String w : words) {
if (w.startsWith(prefix)) count++;
}
return count;
}
public void erase(String word) {
for (int i = 0; i < words.size(); i++) {
if (words.get(i).equals(word)) {
words.remove(i);
return;
}
}
}
}Complexity Analysis
Time Complexity:
insert(word): O(1) amortized — appending to a dynamic array.countWordsEqualTo(word): O(N × M) — scanning all N stored words, each comparison takes up to M characters where M is the word length.countWordsStartingWith(prefix): O(N × M) — same linear scan, checking prefix match for each word.erase(word): O(N × M) — finding and removing the first match requires scanning plus shifting elements.
Where N is the total number of insertions and M is the maximum word length.
Space Complexity: O(N × M)
We store every inserted word in full. With N insertions of words up to length M, total storage is O(N × M).
Why This Approach Is Not Efficient
The brute force approach scans the entire word list for every query. With up to 10^4 operations and words up to length 1000, the worst case involves:
- 10^4 insertions, making the list 10^4 entries long
- Each subsequent
countWordsStartingWithquery scans all 10^4 words, comparing up to 1000 characters each - That is up to 10^4 × 10^4 × 1000 = 10^11 character comparisons — far too slow
The core problem is that we gain no benefit from the structure of the words. The word "apple" and "application" both start with "app", but we check them independently. We need a data structure that exploits shared prefixes to avoid redundant comparisons.
A first improvement would be to use a hash map to at least make exact-word queries fast. But can we also make prefix queries efficient?
Better Approach - Hash Map
Intuition
Instead of storing every copy of a word separately, we can use a hash map (dictionary) that maps each word to its count. Inserting "apple" twice means the map holds {"apple": 2} rather than a list with two copies.
This immediately solves three of the four operations efficiently:
- insert: Increment the count for the word — O(M) for hashing.
- countWordsEqualTo: Look up the word in the map — O(M).
- erase: Decrement the count (and remove if zero) — O(M).
However, countWordsStartingWith remains problematic. A hash map is designed for exact-key lookups, not prefix searches. To find all words starting with "ca", we must iterate through every key in the map and check whether it starts with the given prefix. This is still O(N × M) in the worst case.
Think of it like a phone book sorted by full name: finding the exact entry for "Smith, John" is fast, but finding everyone whose name starts with "Sm" still requires browsing through many entries.
Step-by-Step Explanation
Let's trace the same operations with a hash map:
Operations: insert("cat"), insert("cat"), insert("car"), countWordsStartingWith("ca")
Step 1: Initialize an empty hash map: map = {}
Step 2: insert("cat") — "cat" not in map, add it with count 1.
- map = {"cat": 1}
Step 3: insert("cat") — "cat" already in map, increment count.
- map = {"cat": 2}
Step 4: insert("car") — "car" not in map, add with count 1.
- map = {"cat": 2, "car": 1}
Step 5: countWordsStartingWith("ca") — Must scan all keys.
- Check key "cat": starts with "ca"? Yes → add count 2 to total.
Step 6: Check key "car": starts with "ca"? Yes → add count 1 to total.
- Running total = 2 + 1 = 3
Step 7: All keys checked. Return 3.
Hash Map — Fast Exact Lookup, Slow Prefix Search — Watch how the hash map handles inserts efficiently by updating counts, but still requires scanning all keys for prefix queries.
Algorithm
- Maintain a hash map where keys are words and values are their insertion counts
- insert(word): If
wordexists in map, increment its count. Otherwise, add it with count 1. - countWordsEqualTo(word): Return
map[word]if it exists, otherwise 0. - countWordsStartingWith(prefix): Iterate all keys in the map. For each key that starts with
prefix, add its count to the total. Return the total. - erase(word): Decrement
map[word]by 1. If the count reaches 0, remove the key.
Code
#include <unordered_map>
#include <string>
using namespace std;
class Trie {
private:
unordered_map<string, int> wordCount;
public:
Trie() {}
void insert(string word) {
wordCount[word]++;
}
int countWordsEqualTo(string word) {
if (wordCount.find(word) != wordCount.end()) {
return wordCount[word];
}
return 0;
}
int countWordsStartingWith(string prefix) {
int count = 0;
for (auto& [key, val] : wordCount) {
if (key.size() >= prefix.size() &&
key.substr(0, prefix.size()) == prefix) {
count += val;
}
}
return count;
}
void erase(string word) {
wordCount[word]--;
if (wordCount[word] == 0) {
wordCount.erase(word);
}
}
};class Trie:
def __init__(self):
self.word_count = {}
def insert(self, word: str) -> None:
self.word_count[word] = self.word_count.get(word, 0) + 1
def countWordsEqualTo(self, word: str) -> int:
return self.word_count.get(word, 0)
def countWordsStartingWith(self, prefix: str) -> int:
total = 0
for key, count in self.word_count.items():
if key.startswith(prefix):
total += count
return total
def erase(self, word: str) -> None:
self.word_count[word] -= 1
if self.word_count[word] == 0:
del self.word_count[word]import java.util.HashMap;
import java.util.Map;
class Trie {
private Map<String, Integer> wordCount;
public Trie() {
wordCount = new HashMap<>();
}
public void insert(String word) {
wordCount.put(word, wordCount.getOrDefault(word, 0) + 1);
}
public int countWordsEqualTo(String word) {
return wordCount.getOrDefault(word, 0);
}
public int countWordsStartingWith(String prefix) {
int total = 0;
for (Map.Entry<String, Integer> entry : wordCount.entrySet()) {
if (entry.getKey().startsWith(prefix)) {
total += entry.getValue();
}
}
return total;
}
public void erase(String word) {
int count = wordCount.get(word);
if (count == 1) {
wordCount.remove(word);
} else {
wordCount.put(word, count - 1);
}
}
}Complexity Analysis
Time Complexity:
insert(word): O(M) — hashing the word takes O(M) where M is the word length.countWordsEqualTo(word): O(M) — single hash lookup.countWordsStartingWith(prefix): O(K × M) — where K is the number of distinct keys in the map. We must iterate all keys and check each one for the prefix match.erase(word): O(M) — hash lookup and update.
Space Complexity: O(K × M)
Where K is the number of distinct words stored and M is the average word length. This is better than brute force when many duplicates exist (we store each distinct word only once).
Why This Approach Is Not Efficient
The hash map approach fixes three operations — insert, countWordsEqualTo, and erase are all O(M). However, the critical countWordsStartingWith operation remains slow.
With up to 10^4 distinct words of length up to 1000, each prefix query scans all keys:
- 10^4 keys × 1000 characters = 10^7 character comparisons per query
- Across 10^4 prefix queries = 10^11 total comparisons — still too slow
The fundamental issue is that a hash map treats each key as an opaque blob. It cannot exploit the fact that "cat" and "car" share the prefix "ca". When we ask for all words starting with "ca", the map has no way to jump directly to the matching entries.
We need a data structure that organizes words by their character structure — one that groups words sharing common prefixes together. This is exactly what a Trie does. In a Trie, "cat" and "car" share nodes for 'c' and 'a', and we can count all words under that shared path without examining unrelated words like "dog" or "bat".
Optimal Approach - Trie with Dual Counters
Intuition
A Trie (prefix tree) stores strings character by character in a tree structure. Each node represents a single character, and paths from the root to nodes spell out prefixes of stored words. Words sharing a common prefix share the same path in the tree.
The key innovation for this enhanced version is maintaining two counters at every node:
-
prefixCount (pv) — How many inserted words pass through this node. This directly answers
countWordsStartingWith. When we traverse to the node where a prefix ends, its prefixCount tells us how many total words have that prefix. -
wordCount (wc) — How many inserted words end exactly at this node. This directly answers
countWordsEqualTo. The node where the last character of a word lands stores how many times that exact word was inserted.
Imagine a library where books are organized on shelves by their titles, letter by letter. The "C" shelf leads to sub-shelves for "CA", "CO", etc. A sign at each sub-shelf says "47 books pass through here" (prefixCount) and "3 books have exactly this title" (wordCount). To count all books starting with "CA", you walk to the "CA" sub-shelf and read the sign — no need to inspect individual books.
Why this solves the prefix problem: Instead of scanning every word, we traverse at most M characters (the prefix length) down the trie and read the prefixCount at the destination node. This is O(M), regardless of how many words are stored.
Step-by-Step Explanation
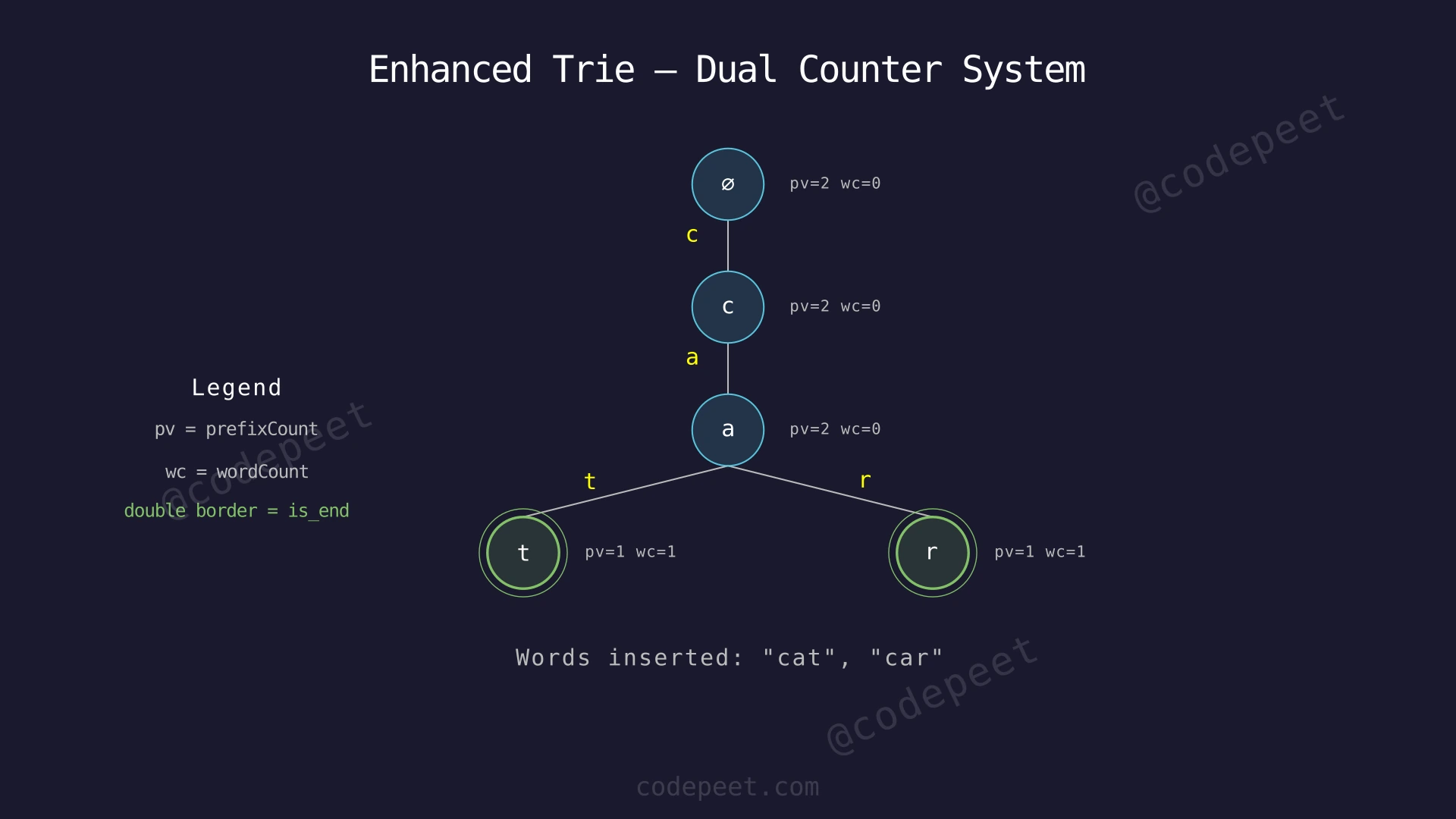
Let's trace: insert("cat"), insert("cat"), insert("car"), countWordsStartingWith("ca"), countWordsEqualTo("cat"), erase("cat"), countWordsStartingWith("ca")
Step 1: Initialize an empty Trie with a root node.
Step 2: insert("cat") — Process character 'c':
- Root has no child 'c'. Create a new node for 'c'.
- Increment 'c' node's prefixCount to 1 (one word passes through 'c').
Step 3: Continue insert("cat") — Process character 'a':
- Node 'c' has no child 'a'. Create a new node for 'a'.
- Increment 'a' node's prefixCount to 1.
Step 4: Continue insert("cat") — Process character 't':
- Node 'a' has no child 't'. Create a new node for 't'.
- Increment 't' node's prefixCount to 1.
- This is the last character of "cat", so also increment wordCount to 1.
- Trie state: root→c(pv=1)→a(pv=1)→t(pv=1, wc=1)
Step 5: insert("cat") again — Process 'c':
- Node 'c' already exists. Just traverse to it and increment prefixCount to 2.
Step 6: Continue — Process 'a': traverse, increment prefixCount to 2.
Step 7: Continue — Process 't': traverse, increment prefixCount to 2, increment wordCount to 2.
- Trie state: root→c(pv=2)→a(pv=2)→t(pv=2, wc=2)
Step 8: insert("car") — Process 'c': already exists, increment prefixCount to 3.
Step 9: Continue — Process 'a': already exists, increment prefixCount to 3.
Step 10: Continue — Process 'r': node 'a' has no child 'r'. Create it. Set prefixCount=1, wordCount=1.
- Trie state: root→c(pv=3)→a(pv=3)→t(pv=2, wc=2) and a→r(pv=1, wc=1)
Step 11: countWordsStartingWith("ca") — Traverse to 'c', then to 'a'. Read prefixCount at 'a' = 3.
- Return 3. Done in 2 character traversals, regardless of how many words exist.
Step 12: countWordsEqualTo("cat") — Traverse to 'c', 'a', 't'. Read wordCount at 't' = 2.
- Return 2.
Step 13: erase("cat") — Traverse path c→a→t, decrement prefixCount at each node, decrement wordCount at 't'.
- After erase: c(pv=2)→a(pv=2)→t(pv=1, wc=1), r(pv=1, wc=1)
Step 14: countWordsStartingWith("ca") — Traverse to 'a'. Read prefixCount = 2.
- Return 2 (one "cat" + one "car").
Trie with Dual Counters — Insert, Query, and Erase — Watch how the trie builds shared paths for words with common prefixes, and how prefixCount/wordCount enable O(M) queries without scanning all words.
Algorithm
TrieNode structure: Each node contains:
children[26]— array of pointers to child nodes (one per lowercase letter)prefixCount— number of inserted words that pass through this nodewordCount— number of inserted words that end exactly at this node
Operations:
-
insert(word):
- Start at root. For each character in
word:- If no child exists for this character, create a new TrieNode
- Move to the child node
- Increment its
prefixCountby 1
- After processing all characters, increment
wordCountat the final node by 1
- Start at root. For each character in
-
countWordsEqualTo(word):
- Traverse the trie along the characters of
word - If any character's node is missing, return 0
- Otherwise, return
wordCountat the final node
- Traverse the trie along the characters of
-
countWordsStartingWith(prefix):
- Traverse the trie along the characters of
prefix - If any character's node is missing, return 0
- Otherwise, return
prefixCountat the final node
- Traverse the trie along the characters of
-
erase(word):
- Traverse the trie along the characters of
word - At each node, decrement
prefixCountby 1 - At the final node, also decrement
wordCountby 1
- Traverse the trie along the characters of
Code
class TrieNode {
public:
TrieNode* children[26];
int prefixCount;
int wordCount;
TrieNode() {
prefixCount = 0;
wordCount = 0;
for (int i = 0; i < 26; i++) {
children[i] = nullptr;
}
}
};
class Trie {
private:
TrieNode* root;
TrieNode* searchNode(const string& word) {
TrieNode* node = root;
for (char c : word) {
int idx = c - 'a';
if (node->children[idx] == nullptr) {
return nullptr;
}
node = node->children[idx];
}
return node;
}
public:
Trie() {
root = new TrieNode();
}
void insert(string word) {
TrieNode* node = root;
for (char c : word) {
int idx = c - 'a';
if (node->children[idx] == nullptr) {
node->children[idx] = new TrieNode();
}
node = node->children[idx];
node->prefixCount++;
}
node->wordCount++;
}
int countWordsEqualTo(string word) {
TrieNode* node = searchNode(word);
return node == nullptr ? 0 : node->wordCount;
}
int countWordsStartingWith(string prefix) {
TrieNode* node = searchNode(prefix);
return node == nullptr ? 0 : node->prefixCount;
}
void erase(string word) {
TrieNode* node = root;
for (char c : word) {
int idx = c - 'a';
node = node->children[idx];
node->prefixCount--;
}
node->wordCount--;
}
};class TrieNode:
def __init__(self):
self.children = [None] * 26
self.prefix_count = 0
self.word_count = 0
class Trie:
def __init__(self):
self.root = TrieNode()
def _search_node(self, word: str):
node = self.root
for char in word:
idx = ord(char) - ord('a')
if node.children[idx] is None:
return None
node = node.children[idx]
return node
def insert(self, word: str) -> None:
node = self.root
for char in word:
idx = ord(char) - ord('a')
if node.children[idx] is None:
node.children[idx] = TrieNode()
node = node.children[idx]
node.prefix_count += 1
node.word_count += 1
def countWordsEqualTo(self, word: str) -> int:
node = self._search_node(word)
return 0 if node is None else node.word_count
def countWordsStartingWith(self, prefix: str) -> int:
node = self._search_node(prefix)
return 0 if node is None else node.prefix_count
def erase(self, word: str) -> None:
node = self.root
for char in word:
idx = ord(char) - ord('a')
node = node.children[idx]
node.prefix_count -= 1
node.word_count -= 1class TrieNode {
TrieNode[] children;
int prefixCount;
int wordCount;
public TrieNode() {
children = new TrieNode[26];
prefixCount = 0;
wordCount = 0;
}
}
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
private TrieNode searchNode(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
return null;
}
node = node.children[idx];
}
return node;
}
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
node.prefixCount++;
}
node.wordCount++;
}
public int countWordsEqualTo(String word) {
TrieNode node = searchNode(word);
return node == null ? 0 : node.wordCount;
}
public int countWordsStartingWith(String prefix) {
TrieNode node = searchNode(prefix);
return node == null ? 0 : node.prefixCount;
}
public void erase(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
node = node.children[idx];
node.prefixCount--;
}
node.wordCount--;
}
}Complexity Analysis
Time Complexity:
insert(word): O(M) — We traverse M characters (word length), doing O(1) work at each node (array access + counter increment).countWordsEqualTo(word): O(M) — Traverse M characters, return the wordCount at the final node.countWordsStartingWith(prefix): O(M) — Traverse M characters (prefix length), return the prefixCount. This is the massive improvement over brute force and hash map approaches, which required scanning all stored words.erase(word): O(M) — Traverse M characters, decrement counters along the path.
All operations run in O(M) time where M is the length of the input word/prefix. Crucially, the time does not depend on the number of words stored (N).
Space Complexity: O(N × M × 26) in the worst case
Each node stores an array of 26 child pointers. In the worst case (all words are completely different with no shared prefixes), we create N × M nodes, each holding 26 pointers. In practice, trie space is much smaller because words share common prefix paths — this is the whole point of the data structure.
With the given constraints (N ≤ 10^4, M ≤ 1000), the worst-case space is about 10^7 nodes × 26 pointers, which is manageable.