Subsets II
Description
Given an integer array nums that may contain duplicate elements, return all possible subsets (the power set) of the array.
A subset is any selection of elements from the array where you choose to include or exclude each element. The power set is the collection of every such possible selection, including the empty subset and the full array itself.
The solution set must not contain duplicate subsets. Even though the input may have repeated values, each unique subset should appear only once in the output. You can return the subsets in any order.
Examples
Example 1
Input: nums = [1, 2, 2]
Output: [[], [1], [1, 2], [1, 2, 2], [2], [2, 2]]
Explanation: Although there are two 2's in the input, the subset [1, 2] should appear only once. Likewise, [2] appears once despite there being two copies of 2. The six unique subsets listed above form the complete power set without duplicates.
Example 2
Input: nums = [0]
Output: [[], [0]]
Explanation: A single-element array has exactly two subsets: the empty set and the set containing that element.
Constraints
- 1 ≤ nums.length ≤ 10
- -10 ≤ nums[i] ≤ 10
Editorial
Brute Force - Generate All and Deduplicate
Intuition
The simplest way to handle duplicates is to pretend they do not exist at first. Generate every possible subset the same way you would for an array of distinct elements — for each element, choose to include it or skip it. This produces all 2^n subsets, some of which may be identical when the input contains repeated values.
Once you have the full list, sort each individual subset and collect them into a set structure that automatically removes duplicates. Whatever remains is the answer.
Think of it like writing down every combination of toppings for a pizza, even if you accidentally list the same combination twice because two pepperoni slices look different to you. At the end you just cross off the repeats.
Step-by-Step Explanation
Let's trace through with nums = [1, 2, 2].
We use bit masking: each number from 0 to 2^n - 1 represents a subset, where a set bit at position j means "include nums[j]".
Step 1: mask = 0 (binary 000). No bits set → subset = []. Sort it → [].
Step 2: mask = 1 (binary 001). Bit 0 set → include nums[0]=1 → subset = [1]. Sort → [1].
Step 3: mask = 2 (binary 010). Bit 1 set → include nums[1]=2 → subset = [2]. Sort → [2].
Step 4: mask = 3 (binary 011). Bits 0,1 set → include nums[0]=1, nums[1]=2 → subset = [1,2]. Sort → [1,2].
Step 5: mask = 4 (binary 100). Bit 2 set → include nums[2]=2 → subset = [2]. Sort → [2]. This duplicates Step 3!
Step 6: mask = 5 (binary 101). Bits 0,2 set → include nums[0]=1, nums[2]=2 → subset = [1,2]. Sort → [1,2]. This duplicates Step 4!
Step 7: mask = 6 (binary 110). Bits 1,2 set → include nums[1]=2, nums[2]=2 → subset = [2,2]. Sort → [2,2].
Step 8: mask = 7 (binary 111). All bits set → include all → subset = [1,2,2]. Sort → [1,2,2].
After deduplication the unique subsets are: [], [1], [2], [1,2], [2,2], [1,2,2] — 6 unique subsets from 8 generated.
Brute Force — Generating All Subsets via Bitmask — Watch how every bitmask from 0 to 7 selects elements from the sorted array, and how duplicate subsets appear when duplicate values exist.
Algorithm
- Sort the input array so duplicate values sit next to each other
- For each bitmask from 0 to 2^n - 1:
a. Build a subset by including nums[j] whenever bit j is set
b. Sort the subset (already sorted because array is sorted)
c. Insert the subset into a set (automatically rejects duplicates) - Return all subsets from the set
Code
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
int n = nums.size();
set<vector<int>> uniqueSubsets;
for (int mask = 0; mask < (1 << n); mask++) {
vector<int> subset;
for (int j = 0; j < n; j++) {
if (mask & (1 << j)) {
subset.push_back(nums[j]);
}
}
uniqueSubsets.insert(subset);
}
return vector<vector<int>>(uniqueSubsets.begin(), uniqueSubsets.end());
}
};class Solution:
def subsetsWithDup(self, nums: list[int]) -> list[list[int]]:
nums.sort()
n = len(nums)
unique_subsets = set()
for mask in range(1 << n):
subset = []
for j in range(n):
if mask & (1 << j):
subset.append(nums[j])
unique_subsets.add(tuple(subset))
return [list(s) for s in unique_subsets]import java.util.*;
class Solution {
public List<List<Integer>> subsetsWithDup(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
Set<List<Integer>> uniqueSubsets = new HashSet<>();
for (int mask = 0; mask < (1 << n); mask++) {
List<Integer> subset = new ArrayList<>();
for (int j = 0; j < n; j++) {
if ((mask & (1 << j)) != 0) {
subset.add(nums[j]);
}
}
uniqueSubsets.add(subset);
}
return new ArrayList<>(uniqueSubsets);
}
}Complexity Analysis
Time Complexity: O(2^n × n)
We iterate through all 2^n bitmasks. For each mask, we scan n bits to build the subset. Inserting into a set of vectors also takes O(n) for comparison. Total: O(2^n × n).
Space Complexity: O(2^n × n)
In the worst case (all distinct elements), the set stores 2^n subsets, each up to length n. The set itself uses O(2^n × n) space, on top of the output.
Why This Approach Is Not Efficient
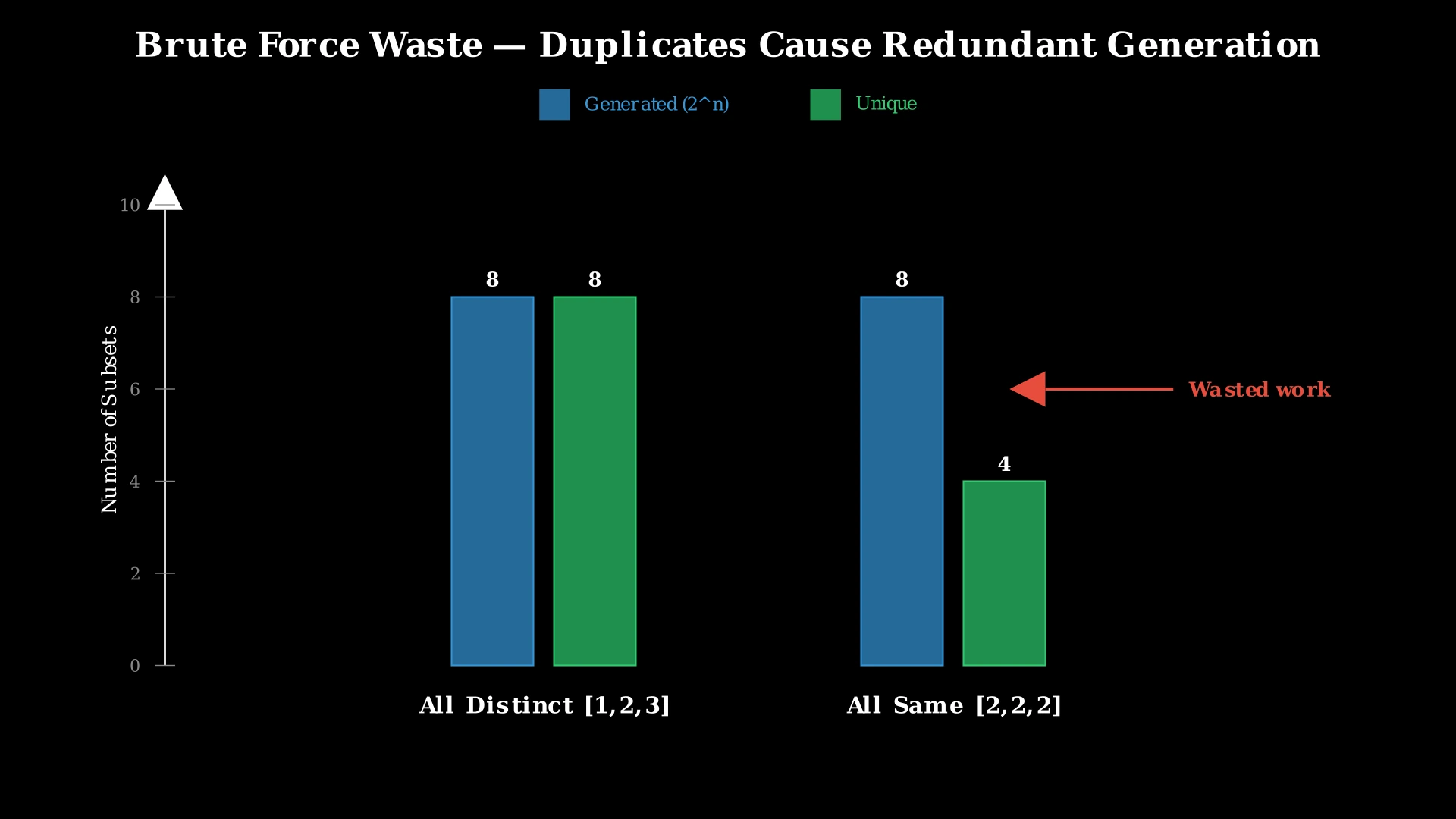
The brute force always generates all 2^n subsets regardless of how many duplicates exist. When the array is [2, 2, 2, 2, 2], there are only 6 unique subsets (choosing 0, 1, 2, 3, 4, or 5 copies of 2), but the bitmask approach generates 2^5 = 32 subsets and then discards 26 of them.
The deduplication step itself is expensive: inserting a vector of length n into a balanced-tree set costs O(n log(2^n)) = O(n²) per insertion, making the true worst-case O(2^n × n²).
The core problem is that the algorithm is blind to duplicates — it treats every element as unique and cleans up afterward. A smarter approach would avoid generating duplicates in the first place by recognizing when two identical elements lead to the same branch.
Optimal Approach - Backtracking with Duplicate Skipping
Intuition
Instead of generating everything and filtering, we can avoid creating duplicates in the first place. The key insight comes from sorting the array first so that identical values sit next to each other, then making decisions at the group level rather than the individual element level.
At each position in the sorted array we face a binary choice: include this element or exclude it. If we include it, we move to the next position as usual. But if we exclude it, we must skip past all consecutive copies of the same value — not just this one copy.
Why? Because if we decide not to include a 2 at this decision point, then including any later copy of 2 at the same depth would produce a subset we have already generated through the "include" branch. By skipping the entire group of duplicates when excluding, we guarantee each unique subset is generated exactly once.
Think of it like choosing toppings from a menu where "extra cheese" appears three times. If you decide against cheese, you cross off all three entries — checking each one separately would just waste time and give the same result.
![Decision tree for backtracking on [1,2,2] showing how the skip-duplicates branch prunes redundant paths](https://pub-a1b3030acfb94e84ba8a89fb182c53bc.r2.dev/public/90/backtrack_tree_v1.webp)
Step-by-Step Explanation
Let's trace through with nums = [1, 2, 2] (already sorted).
We use a recursive function dfs(i) that builds subsets by deciding include/exclude for each index i. The current subset is stored in a temporary list t.
Step 1: Call dfs(0). t = []. We are at index 0 with value 1. Choose to include it. t becomes [1].
Step 2: Call dfs(1). t = [1]. We are at index 1 with value 2. Choose to include it. t becomes [1, 2].
Step 3: Call dfs(2). t = [1, 2]. We are at index 2 with value 2. Choose to include it. t becomes [1, 2, 2].
Step 4: Call dfs(3). i == n, so we reached the end. Record subset [1, 2, 2] in results.
Step 5: Backtrack from dfs(3). Back at dfs(2) with t = [1, 2]. Now we choose to exclude nums[2]=2. Pop the 2 we added. t = [1, 2]. No more duplicates to skip after index 2. Call dfs(3). Record subset [1, 2].
Step 6: Backtrack to dfs(1) with t = [1]. Now exclude nums[1]=2. Pop the 2. t = [1]. Check: nums[2]=2 equals the popped value 2, so skip index 2 as well. Jump to dfs(3). Record subset [1].
Step 7: Backtrack to dfs(0) with t = []. Now exclude nums[0]=1. Pop the 1. t = []. No duplicates of 1 to skip. Call dfs(1).
Step 8: Call dfs(1) with t = []. Include nums[1]=2. t = [2]. Call dfs(2).
Step 9: Call dfs(2) with t = [2]. Include nums[2]=2. t = [2, 2]. Call dfs(3). Record [2, 2].
Step 10: Backtrack to dfs(2) with t = [2]. Exclude nums[2]=2. Pop → t = [2]. Call dfs(3). Record [2].
Step 11: Backtrack to dfs(1) with t = []. Exclude nums[1]=2. Pop → t = []. Skip duplicate at index 2. Call dfs(3). Record [].
Final result: [1,2,2], [1,2], [1], [2,2], [2], [] — exactly 6 unique subsets with zero duplicates generated.
Backtracking with Duplicate Skipping on [1, 2, 2] — Watch how the algorithm builds subsets by including or excluding elements, and how it skips entire groups of duplicates when choosing to exclude.
Algorithm
- Sort the input array to group duplicate values together
- Initialize an empty result list and an empty temporary list t
- Define recursive function dfs(i):
a. Base case: if i == n, add a copy of t to results and return
b. Include branch: append nums[i] to t, call dfs(i+1)
c. Exclude branch: pop the last element from t. While the next element equals the popped value, increment i (skip duplicates). Call dfs(i+1) - Call dfs(0) and return results
Code
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<vector<int>> result;
vector<int> current;
dfs(nums, 0, current, result);
return result;
}
private:
void dfs(vector<int>& nums, int i, vector<int>& current, vector<vector<int>>& result) {
if (i == nums.size()) {
result.push_back(current);
return;
}
// Include nums[i]
current.push_back(nums[i]);
dfs(nums, i + 1, current, result);
// Exclude nums[i] and skip all duplicates
current.pop_back();
while (i + 1 < nums.size() && nums[i + 1] == nums[i]) {
i++;
}
dfs(nums, i + 1, current, result);
}
};class Solution:
def subsetsWithDup(self, nums: list[int]) -> list[list[int]]:
nums.sort()
result = []
current = []
def dfs(i: int) -> None:
if i == len(nums):
result.append(current[:])
return
# Include nums[i]
current.append(nums[i])
dfs(i + 1)
# Exclude nums[i] and skip all duplicates
current.pop()
while i + 1 < len(nums) and nums[i + 1] == nums[i]:
i += 1
dfs(i + 1)
dfs(0)
return resultimport java.util.*;
class Solution {
public List<List<Integer>> subsetsWithDup(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> result = new ArrayList<>();
List<Integer> current = new ArrayList<>();
dfs(nums, 0, current, result);
return result;
}
private void dfs(int[] nums, int i, List<Integer> current, List<List<Integer>> result) {
if (i == nums.length) {
result.add(new ArrayList<>(current));
return;
}
// Include nums[i]
current.add(nums[i]);
dfs(nums, i + 1, current, result);
// Exclude nums[i] and skip all duplicates
int removed = current.remove(current.size() - 1);
while (i + 1 < nums.length && nums[i + 1] == removed) {
i++;
}
dfs(nums, i + 1, current, result);
}
}Complexity Analysis
Time Complexity: O(n × 2^n)
In the worst case (all distinct elements), the algorithm generates exactly 2^n subsets, which is the same as the brute force. However, when duplicates exist, entire subtrees are pruned by the skip logic, so the actual number of recursive calls is smaller. Each subset takes O(n) time to copy into the result. Total: O(n × 2^n).
Space Complexity: O(n)
The recursion stack can go at most n levels deep (one decision per element). The temporary list t holds at most n elements. Together they use O(n) auxiliary space, not counting the output.