Accounts Merge
Description
You are given a list of accounts where each element accounts[i] is a list of strings. The first string accounts[i][0] is a person's name, and the remaining strings are email addresses belonging to that account.
Your task is to merge accounts that belong to the same person. Two accounts belong to the same person if they share at least one common email address. Importantly, even if two accounts have the same name, they may belong to different people — names are not unique identifiers. Only shared emails prove that accounts belong to the same person.
The merging is transitive: if account A shares an email with account B, and account B shares a different email with account C, then all three accounts belong to the same person and should be merged.
Return the merged accounts where each result contains the person's name followed by all their unique email addresses in sorted order. The accounts themselves can be returned in any order.
Examples
Example 1
Input: accounts = [["John","johnsmith@mail.com","john_newyork@mail.com"],["John","johnsmith@mail.com","john00@mail.com"],["Mary","mary@mail.com"],["John","johnnybravo@mail.com"]]
Output: [["John","john00@mail.com","john_newyork@mail.com","johnsmith@mail.com"],["Mary","mary@mail.com"],["John","johnnybravo@mail.com"]]
Explanation: Accounts 0 and 1 both contain the email "johnsmith@mail.com", so they belong to the same John and are merged. The third account (Mary) shares no emails with anyone, so it stays separate. The fourth account (John with "johnnybravo@mail.com") has a unique email — this is a different John. The merged John's emails are sorted alphabetically.
Example 2
Input: accounts = [["Gabe","Gabe0@m.co","Gabe3@m.co","Gabe1@m.co"],["Kevin","Kevin3@m.co","Kevin5@m.co","Kevin0@m.co"],["Ethan","Ethan5@m.co","Ethan4@m.co","Ethan0@m.co"],["Hanzo","Hanzo3@m.co","Hanzo1@m.co","Hanzo0@m.co"],["Fern","Fern5@m.co","Fern1@m.co","Fern0@m.co"]]
Output: [["Ethan","Ethan0@m.co","Ethan4@m.co","Ethan5@m.co"],["Gabe","Gabe0@m.co","Gabe1@m.co","Gabe3@m.co"],["Hanzo","Hanzo0@m.co","Hanzo1@m.co","Hanzo3@m.co"],["Kevin","Kevin0@m.co","Kevin3@m.co","Kevin5@m.co"],["Fern","Fern0@m.co","Fern1@m.co","Fern5@m.co"]]
Explanation: No accounts share any email addresses, so no merging occurs. Each account remains independent. The emails within each account are sorted alphabetically in the output.
Constraints
- 1 ≤ accounts.length ≤ 1000
- 2 ≤ accounts[i].length ≤ 10
- 1 ≤ accounts[i][j].length ≤ 30
- accounts[i][0] consists of English letters (the name)
- accounts[i][j] (for j > 0) is a valid email address
Editorial
Brute Force
Intuition
The most straightforward way to merge accounts is to repeatedly scan all pairs of accounts, check if they share any email, and merge them if they do. We keep repeating this process until no more merges happen in a full pass.
Imagine you have a stack of business cards on a table. You pick up the first card, then compare it with every other card. If two cards share a phone number, you staple them together. After one full pass, you might have created some merged piles. But here is the catch: merging pile A with pile B might reveal that pile B now shares a number with pile C (transitivity). So you need to repeat the scanning until no new merges occur.
This is simple to understand but wasteful — we compare every pair of accounts multiple times, even when most pairs have no connection.
Step-by-Step Explanation
Let's trace through Example 1: accounts = [["John","johnsmith@mail.com","john_newyork@mail.com"],["John","johnsmith@mail.com","john00@mail.com"],["Mary","mary@mail.com"],["John","johnnybravo@mail.com"]]
Step 1: Convert each account's emails to a set for fast comparison.
- Set 0: {johnsmith, john_newyork}
- Set 1: {johnsmith, john00}
- Set 2: {mary}
- Set 3: {johnnybravo}
Step 2: Pass 1 — Compare all pairs:
- (0, 1): Sets share "johnsmith"! Merge set 1 into set 0.
- Set 0 becomes: {johnsmith, john_newyork, john00}
- Set 1 becomes: {} (empty, merged)
- (0, 2): No overlap. Skip.
- (0, 3): No overlap. Skip.
- (2, 3): No overlap. Skip.
- A merge happened, so we need another pass.
Step 3: Pass 2 — Compare all remaining pairs:
- (0, 2): No overlap. Skip.
- (0, 3): No overlap. Skip.
- (2, 3): No overlap. Skip.
- No merges in this pass. Algorithm terminates.
Step 4: Build result from non-empty sets:
- Account 0 (John): [john00, john_newyork, johnsmith] (sorted)
- Account 2 (Mary): [mary]
- Account 3 (John): [johnnybravo]
Result: [["John","john00@mail.com","john_newyork@mail.com","johnsmith@mail.com"],["Mary","mary@mail.com"],["John","johnnybravo@mail.com"]]
Algorithm
- Convert each account's emails into a set for O(1) membership testing
- Repeat until no merges occur in a full pass:
a. For each pair of accounts (i, j) where i < j:- If their email sets share any element (intersection is non-empty)
- Merge set j into set i (union), clear set j
- Mark that a merge happened
- For each non-empty set, output [name] + sorted(emails)
Code
class Solution {
public:
vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {
int n = accounts.size();
vector<set<string>> emailSets(n);
for (int i = 0; i < n; i++)
for (int j = 1; j < (int)accounts[i].size(); j++)
emailSets[i].insert(accounts[i][j]);
bool changed = true;
while (changed) {
changed = false;
for (int i = 0; i < n; i++) {
if (emailSets[i].empty()) continue;
for (int j = i + 1; j < n; j++) {
if (emailSets[j].empty()) continue;
bool overlap = false;
for (auto& e : emailSets[j]) {
if (emailSets[i].count(e)) { overlap = true; break; }
}
if (overlap) {
emailSets[i].insert(emailSets[j].begin(), emailSets[j].end());
emailSets[j].clear();
changed = true;
}
}
}
}
vector<vector<string>> result;
for (int i = 0; i < n; i++) {
if (emailSets[i].empty()) continue;
vector<string> merged = {accounts[i][0]};
merged.insert(merged.end(), emailSets[i].begin(), emailSets[i].end());
result.push_back(merged);
}
return result;
}
};class Solution:
def accountsMerge(self, accounts: list[list[str]]) -> list[list[str]]:
email_sets = [set(acc[1:]) for acc in accounts]
names = [acc[0] for acc in accounts]
changed = True
while changed:
changed = False
for i in range(len(email_sets)):
if not email_sets[i]:
continue
for j in range(i + 1, len(email_sets)):
if not email_sets[j]:
continue
if email_sets[i] & email_sets[j]:
email_sets[i] |= email_sets[j]
email_sets[j] = set()
changed = True
result = []
for i in range(len(email_sets)):
if email_sets[i]:
result.append([names[i]] + sorted(email_sets[i]))
return resultclass Solution {
public List<List<String>> accountsMerge(List<List<String>> accounts) {
int n = accounts.size();
List<Set<String>> emailSets = new ArrayList<>();
for (List<String> acc : accounts) {
emailSets.add(new HashSet<>(acc.subList(1, acc.size())));
}
boolean changed = true;
while (changed) {
changed = false;
for (int i = 0; i < n; i++) {
if (emailSets.get(i).isEmpty()) continue;
for (int j = i + 1; j < n; j++) {
if (emailSets.get(j).isEmpty()) continue;
boolean overlap = false;
for (String e : emailSets.get(j)) {
if (emailSets.get(i).contains(e)) { overlap = true; break; }
}
if (overlap) {
emailSets.get(i).addAll(emailSets.get(j));
emailSets.get(j).clear();
changed = true;
}
}
}
}
List<List<String>> result = new ArrayList<>();
for (int i = 0; i < n; i++) {
if (emailSets.get(i).isEmpty()) continue;
List<String> merged = new ArrayList<>(emailSets.get(i));
Collections.sort(merged);
merged.add(0, accounts.get(i).get(0));
result.add(merged);
}
return result;
}
}Complexity Analysis
Time Complexity: O(n³ × k)
Each pass compares all O(n²) pairs of accounts, and checking for shared emails takes O(k) per pair (where k is the maximum emails per account). In the worst case, only one merge happens per pass, requiring up to n passes. This gives O(n³ × k). With n up to 1,000 and k up to 10, the worst case is 10^10 — far too slow.
Space Complexity: O(n × k)
We store n email sets, each with up to k emails. The total storage is bounded by the total number of emails across all accounts.
Why This Approach Is Not Efficient
The brute force has two critical problems:
1. Quadratic pair checking: Comparing all n² pairs of accounts in every pass is wasteful. Most pairs will never share emails, yet we check them repeatedly.
2. Multiple passes for transitivity: When account A merges with B, and B later merges with C, the brute force needs another full O(n²) pass to propagate the connection. A chain of n accounts requires n passes, leading to O(n³) total comparisons.
The fundamental insight is that this is a graph connectivity problem. If we model emails as nodes in a graph and connect emails that belong to the same account, then finding all emails of the same person becomes finding connected components — a well-solved problem with O(V + E) DFS or near-O(1) amortized Union-Find operations.
Better Approach - DFS on Email Graph
Intuition
Instead of comparing accounts pairwise, we can reframe the problem as a graph connectivity problem.
Build an undirected graph where each email is a node. For every account, connect all emails in that account to each other (in practice, connecting each email to the first email in the account suffices — this creates a star pattern that keeps them all connected). If two accounts share an email, their email clusters automatically become part of the same connected component.
Then finding which emails belong to the same person is exactly finding connected components in this graph — a single DFS or BFS traversal.
Think of it like a social network: each account creates friendship links between its emails. If email A and email B are in the same account, they are friends. If email B and email C are in another account, they are also friends. Through transitivity, A, B, and C all end up in the same friend group. DFS simply walks through the friend graph to discover entire groups.
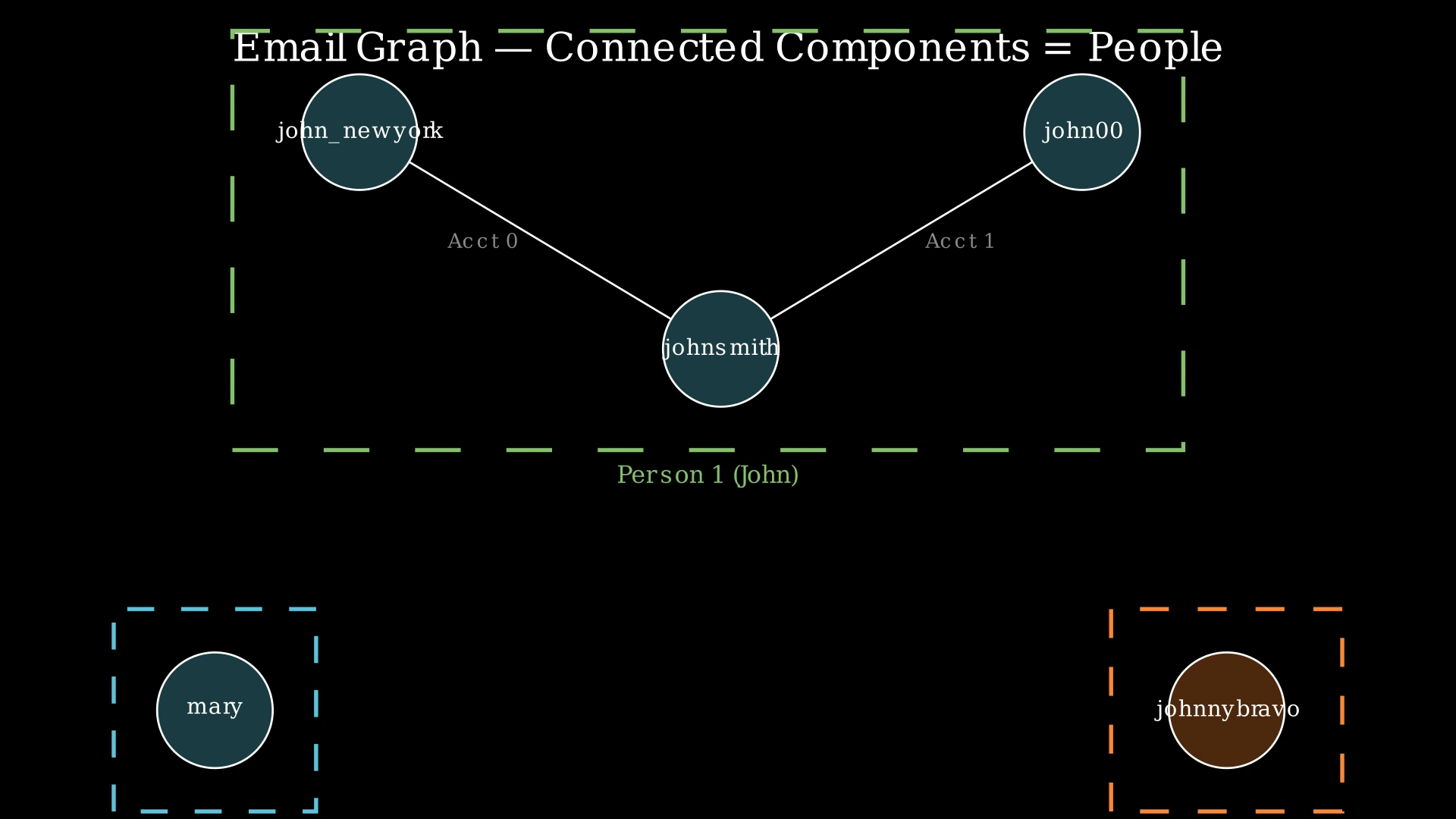
Step-by-Step Explanation
Let's trace Example 1 with the DFS approach. We assign each unique email a numeric ID:
- 0: johnsmith@mail.com
- 1: john_newyork@mail.com
- 2: john00@mail.com
- 3: mary@mail.com
- 4: johnnybravo@mail.com
Step 1: Build the email graph. For each account, connect all emails to the first email:
- Account 0: connect 0↔1 (johnsmith — john_newyork)
- Account 1: connect 0↔2 (johnsmith — john00)
- Account 2: node 3 alone (only email: mary)
- Account 3: node 4 alone (only email: johnnybravo)
Step 2: DFS from node 0 (johnsmith, unvisited). Visit 0, then neighbor 1, then back to 0, then neighbor 2. Component = {0, 1, 2}.
Step 3: DFS from node 3 (mary, unvisited). No neighbors. Component = {3}.
Step 4: DFS from node 4 (johnnybravo, unvisited). No neighbors. Component = {4}.
Step 5: Map components back to emails and sort:
- Component {0,1,2} → name: John → [john00, john_newyork, johnsmith]
- Component {3} → name: Mary → [mary]
- Component {4} → name: John → [johnnybravo]
Result: [["John","john00@mail.com","john_newyork@mail.com","johnsmith@mail.com"],["Mary","mary@mail.com"],["John","johnnybravo@mail.com"]]
DFS on Email Graph — Finding Connected Components — Watch as DFS traverses the email graph, discovering that emails connected through shared accounts form a single person's complete email set.
Algorithm
- Build an undirected email graph:
- For each account, connect every email to the first email in that account
- Also record email → name mapping
- Initialize a visited set
- For each unvisited email node:
a. Run DFS/BFS to discover the entire connected component
b. Collect all emails in this component - For each component, output [name] + sorted(emails)
Code
class Solution {
public:
vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {
unordered_map<string, unordered_set<string>> graph;
unordered_map<string, string> emailToName;
for (auto& acc : accounts) {
string name = acc[0];
for (int i = 1; i < (int)acc.size(); i++) {
graph[acc[i]].insert(acc[1]);
graph[acc[1]].insert(acc[i]);
emailToName[acc[i]] = name;
}
}
unordered_set<string> visited;
vector<vector<string>> result;
for (auto& [email, _] : emailToName) {
if (visited.count(email)) continue;
vector<string> component;
stack<string> stk;
stk.push(email);
while (!stk.empty()) {
string node = stk.top();
stk.pop();
if (visited.count(node)) continue;
visited.insert(node);
component.push_back(node);
for (auto& neighbor : graph[node]) {
if (!visited.count(neighbor)) stk.push(neighbor);
}
}
sort(component.begin(), component.end());
component.insert(component.begin(), emailToName[email]);
result.push_back(component);
}
return result;
}
};from collections import defaultdict
class Solution:
def accountsMerge(self, accounts: list[list[str]]) -> list[list[str]]:
graph = defaultdict(set)
email_to_name = {}
for acc in accounts:
name = acc[0]
first_email = acc[1]
for email in acc[1:]:
graph[email].add(first_email)
graph[first_email].add(email)
email_to_name[email] = name
visited = set()
result = []
for email in email_to_name:
if email in visited:
continue
component = []
stack = [email]
while stack:
node = stack.pop()
if node in visited:
continue
visited.add(node)
component.append(node)
for neighbor in graph[node]:
if neighbor not in visited:
stack.append(neighbor)
result.append([email_to_name[email]] + sorted(component))
return resultclass Solution {
public List<List<String>> accountsMerge(List<List<String>> accounts) {
Map<String, Set<String>> graph = new HashMap<>();
Map<String, String> emailToName = new HashMap<>();
for (List<String> acc : accounts) {
String name = acc.get(0);
String first = acc.get(1);
for (int i = 1; i < acc.size(); i++) {
graph.computeIfAbsent(acc.get(i), k -> new HashSet<>()).add(first);
graph.computeIfAbsent(first, k -> new HashSet<>()).add(acc.get(i));
emailToName.put(acc.get(i), name);
}
}
Set<String> visited = new HashSet<>();
List<List<String>> result = new ArrayList<>();
for (String email : emailToName.keySet()) {
if (visited.contains(email)) continue;
List<String> component = new ArrayList<>();
Deque<String> stack = new ArrayDeque<>();
stack.push(email);
while (!stack.isEmpty()) {
String node = stack.pop();
if (visited.contains(node)) continue;
visited.add(node);
component.add(node);
for (String nei : graph.get(node)) {
if (!visited.contains(nei)) stack.push(nei);
}
}
Collections.sort(component);
component.add(0, emailToName.get(email));
result.add(component);
}
return result;
}
}Complexity Analysis
Time Complexity: O(E × log E)
Building the email graph takes O(E) where E is the total number of emails across all accounts. Each email is processed once during graph construction. DFS visits each node and edge once: O(V + E) where V is the number of unique emails. Sorting emails within each component takes O(E × log E) in the worst case (when all emails belong to one person). The sorting step dominates.
Space Complexity: O(E)
The email graph stores each email as a node and each connection as an edge. The adjacency list, visited set, and component storage all use O(E) space. This is a significant improvement over the brute force — we store edges between emails rather than comparing entire accounts.
Why This Approach Is Not Efficient
The DFS approach is a major improvement over brute force — it solves the problem in a single traversal rather than repeated passes. However, it requires two separate phases: first build an explicit graph (adjacency list), then traverse it to find components.
Building the graph requires creating and storing adjacency sets for every email, which involves significant overhead in hash set operations and memory allocation. The DFS traversal then requires maintaining a separate visited set and a stack.
The Union-Find (Disjoint Set Union) data structure offers a more elegant alternative. It unifies graph construction and component discovery into a single pass: as you scan each email, you simultaneously record its ownership and merge accounts that share it. There is no separate graph to build and no separate traversal to perform. Union-Find operations (find and union) run in nearly O(1) amortized time with path compression and union by rank, making the approach both simpler to implement and slightly more efficient in practice.
Optimal Approach - Union-Find (Disjoint Set Union)
Intuition
Union-Find is a data structure designed for exactly this kind of problem: grouping items into sets and efficiently merging sets when connections are discovered.
The idea is beautifully simple. We assign each account an index (0, 1, 2, ...) and maintain a parent array where parent[i] tracks which group account i belongs to. Initially, every account is its own group.
As we scan through each email in each account, we check: have we seen this email before? If yes, the current account and the previous account that owned this email must belong to the same person — so we union (merge) their groups. If no, we simply record this email's ownership.
Think of it like a detective investigating identity fraud. The detective maintains a case board with suspect groups. Every time a new email address is found that links two suspect files, the detective merges those files into one case. By the time all evidence (emails) is processed, each case on the board represents one real person — no matter how many aliases they used.
The key advantage over DFS: Union-Find processes everything in a single scan. There is no separate graph-building step and no separate traversal step. Each email is touched exactly once, and each union/find operation takes nearly constant time.
Step-by-Step Explanation
Let's trace Example 1 with Union-Find.
Accounts: 0=["John","johnsmith","john_newyork"], 1=["John","johnsmith","john00"], 2=["Mary","mary"], 3=["John","johnnybravo"]
Step 1: Initialize: parent = [0, 1, 2, 3], email_map = {}
Step 2: Process Account 0, email "johnsmith@mail.com".
- Not in email_map → store johnsmith → account 0. email_map = {johnsmith: 0}
Step 3: Process Account 0, email "john_newyork@mail.com".
- Not in email_map → store john_newyork → account 0. email_map = {johnsmith: 0, john_newyork: 0}
Step 4: Process Account 1, email "johnsmith@mail.com".
- FOUND in email_map at account 0! Accounts 1 and 0 share this email.
- Union(1, 0): set parent[1] = 0. parent = [0, 0, 2, 3]
Step 5: Process Account 1, email "john00@mail.com".
- Not in email_map → store john00 → account 1. email_map = {..., john00: 1}
Step 6: Process Account 2, email "mary@mail.com".
- Not in email_map → store mary → account 2. No merge.
Step 7: Process Account 3, email "johnnybravo@mail.com".
- Not in email_map → store johnnybravo → account 3. No merge.
Step 8: Group by root: find(0)=0, find(1)=0, find(2)=2, find(3)=3.
- Group 0 (root=0): emails from accounts 0 and 1 → {johnsmith, john_newyork, john00}
- Group 2: {mary}
- Group 3: {johnnybravo}
Step 9: Sort emails, attach names, output.
Union-Find — Email-to-Account Mapping with Live Merging — Watch how each email is looked up in the map: new emails are recorded, and duplicate emails trigger a union operation that merges account groups in near-constant time.
Algorithm
- Initialize Union-Find with n accounts (parent[i] = i, rank[i] = 0)
- Create an empty hash map: email → account index
- For each account i, for each email in account i:
- If email already exists in the map at some account j: union(i, j)
- Otherwise: store email → i in the map
- Create groups: for each (email, account_index) in the map:
- Find the root of account_index
- Add email to that root's group
- For each group: output [name_of_root_account] + sorted(emails)
Code
class Solution {
vector<int> parent, rnk;
int find(int x) {
while (parent[x] != x) {
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
void unite(int a, int b) {
int ra = find(a), rb = find(b);
if (ra == rb) return;
if (rnk[ra] < rnk[rb]) swap(ra, rb);
parent[rb] = ra;
if (rnk[ra] == rnk[rb]) rnk[ra]++;
}
public:
vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {
int n = accounts.size();
parent.resize(n);
rnk.resize(n, 0);
iota(parent.begin(), parent.end(), 0);
unordered_map<string, int> emailToId;
for (int i = 0; i < n; i++) {
for (int j = 1; j < (int)accounts[i].size(); j++) {
string& email = accounts[i][j];
if (emailToId.count(email)) {
unite(i, emailToId[email]);
} else {
emailToId[email] = i;
}
}
}
unordered_map<int, vector<string>> groups;
for (auto& [email, idx] : emailToId) {
groups[find(idx)].push_back(email);
}
vector<vector<string>> result;
for (auto& [root, emails] : groups) {
sort(emails.begin(), emails.end());
emails.insert(emails.begin(), accounts[root][0]);
result.push_back(emails);
}
return result;
}
};from collections import defaultdict
class Solution:
def accountsMerge(self, accounts: list[list[str]]) -> list[list[str]]:
n = len(accounts)
parent = list(range(n))
rank = [0] * n
def find(x):
while parent[x] != x:
parent[x] = parent[parent[x]]
x = parent[x]
return x
def union(a, b):
ra, rb = find(a), find(b)
if ra == rb:
return
if rank[ra] < rank[rb]:
ra, rb = rb, ra
parent[rb] = ra
if rank[ra] == rank[rb]:
rank[ra] += 1
email_to_id = {}
for i, acc in enumerate(accounts):
for email in acc[1:]:
if email in email_to_id:
union(i, email_to_id[email])
else:
email_to_id[email] = i
groups = defaultdict(list)
for email, idx in email_to_id.items():
groups[find(idx)].append(email)
return [[accounts[root][0]] + sorted(emails)
for root, emails in groups.items()]class Solution {
int[] parent, rank;
int find(int x) {
while (parent[x] != x) {
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
void union(int a, int b) {
int ra = find(a), rb = find(b);
if (ra == rb) return;
if (rank[ra] < rank[rb]) { int t = ra; ra = rb; rb = t; }
parent[rb] = ra;
if (rank[ra] == rank[rb]) rank[ra]++;
}
public List<List<String>> accountsMerge(List<List<String>> accounts) {
int n = accounts.size();
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) parent[i] = i;
Map<String, Integer> emailToId = new HashMap<>();
for (int i = 0; i < n; i++) {
List<String> acc = accounts.get(i);
for (int j = 1; j < acc.size(); j++) {
String email = acc.get(j);
if (emailToId.containsKey(email)) {
union(i, emailToId.get(email));
} else {
emailToId.put(email, i);
}
}
}
Map<Integer, List<String>> groups = new HashMap<>();
for (Map.Entry<String, Integer> entry : emailToId.entrySet()) {
int root = find(entry.getValue());
groups.computeIfAbsent(root, k -> new ArrayList<>()).add(entry.getKey());
}
List<List<String>> result = new ArrayList<>();
for (Map.Entry<Integer, List<String>> entry : groups.entrySet()) {
List<String> emails = entry.getValue();
Collections.sort(emails);
emails.add(0, accounts.get(entry.getKey()).get(0));
result.add(emails);
}
return result;
}
}Complexity Analysis
Time Complexity: O(E × α(n) + E × log E)
Processing all emails takes O(E) iterations, where E is the total number of emails. Each find/union operation takes O(α(n)) amortized time, where α is the inverse Ackermann function — effectively constant for any practical input (α(n) ≤ 4 for n up to 10^80). So the union-find phase is O(E × α(n)) ≈ O(E).
The grouping phase iterates through all E emails once: O(E). Sorting emails within each group costs O(E × log E) in the worst case (when all emails merge into one group). The sorting step dominates the overall complexity.
Space Complexity: O(E + n)
The email-to-account hash map stores up to E entries. The Union-Find parent and rank arrays use O(n) space. The output groups store all E emails. Total: O(E + n).
Compared to the brute force's O(n³ × k) time, Union-Find's O(E × log E) is dramatically faster. With E ≤ 10,000 (1000 accounts × 10 emails), sorting takes at most ~130,000 operations — versus the brute force's potential 10^10.