Lowest Common Ancestor of a Binary Tree
Description
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes p and q in the tree.
The lowest common ancestor is defined as the deepest node in the tree that has both p and q as descendants. A key detail: a node is allowed to be a descendant of itself. This means if p is an ancestor of q, then p itself is their LCA.
Both nodes p and q are guaranteed to exist in the tree, and all node values are unique.
Examples
Example 1
Input: root = [3, 5, 1, 6, 2, 0, 8, null, null, 7, 4], p = 5, q = 1
3
/ \
5 1
/ \ \
6 2 8
/ \
7 4
Output: 3
Explanation: Node 5 is in the left subtree of 3, and node 1 is in the right subtree of 3. Since they are on different sides of node 3, node 3 is the deepest node that is an ancestor of both — making it the LCA.
Example 2
Input: root = [3, 5, 1, 6, 2, 0, 8, null, null, 7, 4], p = 5, q = 4
Output: 5
Explanation: Node 4 is a descendant of node 5 (it sits in 5's right subtree under node 2). Since a node can be a descendant of itself, node 5 is both an ancestor of itself and an ancestor of node 4 — making 5 the LCA.
Example 3
Input: root = [1, 2], p = 1, q = 2
Output: 1
Explanation: The tree has only two nodes: root 1 and its left child 2. Node 1 is the parent of node 2, and since a node is its own descendant, node 1 is the LCA.
Constraints
- The number of nodes in the tree is in the range [2, 10^5]
- -10^9 ≤ Node.val ≤ 10^9
- All Node.val are unique
- p ≠ q
- p and q will exist in the tree
Editorial
Brute Force - Store and Compare Paths
Intuition
The most intuitive way to find the lowest common ancestor is to think about what "ancestor" means literally: it is a node that lies on the path from the root down to a given node.
If we find the complete path from the root to p and the complete path from the root to q, then the LCA is simply the last node that appears in both paths before they diverge. It is like two hikers starting from the same trailhead — they walk together for a while, then at some fork one goes left and the other goes right. The fork point is the LCA.
So the plan is:
- Use DFS with backtracking to find the path from root to
p - Use a second DFS to find the path from root to
q - Walk both paths from the beginning and return the last matching node
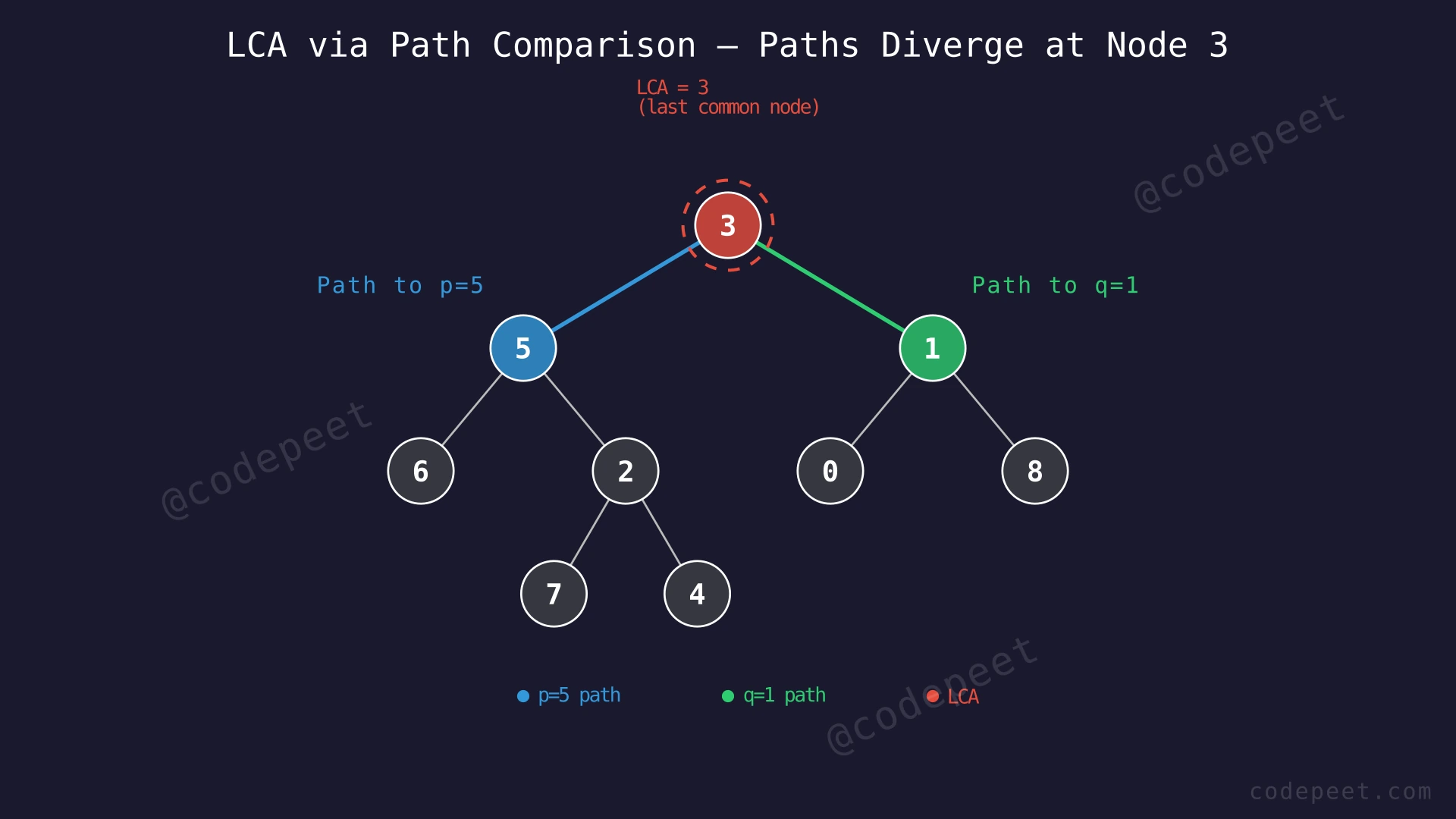
Step-by-Step Explanation
Let's trace through with root = [3, 5, 1, 6, 2, 0, 8, null, null, 7, 4], p = 5, q = 1:
Step 1: Find path from root to p=5. Start DFS at root node 3.
Step 2: From root 3, go left to node 5. Check: is 5 == p? Yes! Path to p found: [3, 5].
Step 3: Now find path from root to q=1. Start a fresh DFS at root node 3.
Step 4: From root 3, go left to node 5. Node 5 ≠ q(1). Explore 5's entire subtree: visit nodes 6, 2, 7, 4 — none match q=1. Backtrack all the way to root. Left subtree does not contain q.
Step 5: From root 3, go right to node 1. Check: is 1 == q? Yes! Path to q found: [3, 1].
Step 6: Compare both paths element by element. Index 0: path_to_p[0] = 3 and path_to_q[0] = 3. They match! Record node 3 as the current common ancestor.
Step 7: Index 1: path_to_p[1] = 5 and path_to_q[1] = 1. They differ! The paths diverge here. Stop comparing.
Step 8: The last matching node was node 3 (at index 0). Therefore, LCA(5, 1) = 3.
Store and Compare Paths — Finding the Fork Point — Watch how we find the path from root to each target node separately, then compare both paths to identify the last common node before they diverge.
Algorithm
- Define a
findPathhelper that performs DFS with backtracking:
a. If the current node is null, return false
b. Append the current node to the path list
c. If the current node is the target, return true
d. Recurse on the left child; if it returns true, return true
e. Recurse on the right child; if it returns true, return true
f. Neither child found the target — pop the current node from path and return false - Call
findPath(root, p)to get path_to_p - Call
findPath(root, q)to get path_to_q - Walk both paths from index 0. While the nodes match, record the last match
- Return the last matching node — that is the LCA
Code
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
vector<TreeNode*> pathP, pathQ;
findPath(root, p, pathP);
findPath(root, q, pathQ);
TreeNode* lca = nullptr;
for (int i = 0; i < min(pathP.size(), pathQ.size()); i++) {
if (pathP[i] == pathQ[i]) {
lca = pathP[i];
} else {
break;
}
}
return lca;
}
private:
bool findPath(TreeNode* root, TreeNode* target, vector<TreeNode*>& path) {
if (!root) return false;
path.push_back(root);
if (root == target) return true;
if (findPath(root->left, target, path) || findPath(root->right, target, path)) {
return true;
}
path.pop_back();
return false;
}
};class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
def find_path(node, target, path):
if not node:
return False
path.append(node)
if node == target:
return True
if find_path(node.left, target, path) or find_path(node.right, target, path):
return True
path.pop()
return False
path_p, path_q = [], []
find_path(root, p, path_p)
find_path(root, q, path_q)
lca = None
for i in range(min(len(path_p), len(path_q))):
if path_p[i] == path_q[i]:
lca = path_p[i]
else:
break
return lcaclass Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
List<TreeNode> pathP = new ArrayList<>();
List<TreeNode> pathQ = new ArrayList<>();
findPath(root, p, pathP);
findPath(root, q, pathQ);
TreeNode lca = null;
for (int i = 0; i < Math.min(pathP.size(), pathQ.size()); i++) {
if (pathP.get(i) == pathQ.get(i)) {
lca = pathP.get(i);
} else {
break;
}
}
return lca;
}
private boolean findPath(TreeNode root, TreeNode target, List<TreeNode> path) {
if (root == null) return false;
path.add(root);
if (root == target) return true;
if (findPath(root.left, target, path) || findPath(root.right, target, path)) {
return true;
}
path.remove(path.size() - 1);
return false;
}
}Complexity Analysis
Time Complexity: O(n)
Each call to findPath performs a single DFS that visits at most n nodes. We call it twice (once for p, once for q), so the total DFS work is O(2n) = O(n). The path comparison loop runs at most h times (where h is the shorter path length), which is at most O(n). Overall: O(n).
Space Complexity: O(n)
We store two paths, each of which can be up to O(h) long where h is the height of the tree. In the worst case (skewed tree), h = n, so each path takes O(n) space. The recursion stack also uses O(h) space. Total: O(n).
Why This Approach Is Not Efficient
While the time complexity is O(n), this approach has two practical inefficiencies:
1. Two separate traversals: We perform two complete DFS passes over the tree — one to find p and one to find q. In the worst case, both searches visit nearly all n nodes before finding their targets.
2. Extra O(n) space for storing paths: We explicitly store the entire root-to-node path for both targets. For a deep tree, each path can consume O(n) memory.
Key insight: we do not actually need to store the paths at all. If we think about it from the bottom up (using recursion), we can determine the LCA in a single traversal without storing any path. The trick is to let each subtree "report back" whether it contains p, q, both, or neither — and the first node where both sides report finding a target must be the LCA.
This eliminates both the second traversal and the path storage.
Optimal Approach - Single Recursive DFS
Intuition
Instead of explicitly finding paths, we can use a clever recursive strategy that solves the problem in a single pass.
The idea is to traverse the tree with DFS, and at each node, ask both subtrees a simple question: "Do you contain p or q?" Each recursive call returns one of three things:
- null: neither p nor q was found in this subtree
- a node (p or q): one of the targets was found
- the LCA itself: the answer was already determined deeper in the tree
The magic happens at the decision point. When both the left and right recursive calls return a non-null value, it means p is in one subtree and q is in the other — the current node is where the paths split, so it must be the LCA.
If only one side returns non-null, we propagate that result upward — either the LCA was already found deeper, or we are carrying one target upward hoping to find the other.
There is one elegant shortcut: if the current node itself is p or q, we return it immediately without exploring its subtree. Why? Because the other target is guaranteed to exist somewhere in the tree. If it is in this node's subtree, then this node is the LCA (a node is its own descendant). If it is elsewhere, a higher node will be the LCA and will receive this node as one of its left/right results.
Step-by-Step Explanation
Let's trace through with root = [3, 5, 1, 6, 2, 0, 8, null, null, 7, 4], p = 5, q = 4:
Step 1: Start at root node 3. Check: is root null? No. Is root == p(5)? No. Is root == q(4)? No. Must search both subtrees.
Step 2: Recurse into left subtree: visit node 5. Check: is 5 == p(5)? Yes! Return node 5 immediately. We skip exploring 5's children — if q=4 is below 5, then 5 is the LCA anyway.
Step 3: Back at root 3. Left subtree returned node 5 (non-null, meaning p was found). Now recurse into right subtree: visit node 1.
Step 4: At node 1. Not null, not p, not q. Recurse into its left child: visit node 0.
Step 5: At node 0. Not null, not p(5), not q(4). Node 0 has no children. Left call returns null, right call returns null. Both null — return null. Dead end.
Step 6: Back at node 1. Left child returned null. Recurse into right child: visit node 8.
Step 7: At node 8. Not null, not p, not q. No children. Both return null → return null. Another dead end.
Step 8: Back at node 1. Left = null, right = null. Neither p nor q exists in node 1's subtree. Return null.
Step 9: Back at root 3. Left returned node 5 (non-null), right returned null. Only the left side found something.
Step 10: Since only left is non-null, return the left result: node 5. LCA(5, 4) = 5. This works because p=5 was found first, and since q=4 must exist in the tree but was not found in the right subtree, it must be in 5's subtree — making 5 the deepest common ancestor.
Single Recursive DFS — Bottom-Up Discovery with Misses — Watch how each subtree reports whether it found p or q. The algorithm efficiently prunes the search: finding p=5 early, then searching the right subtree fruitlessly, before concluding that p=5 must also be the LCA.
Algorithm
- Base case: If the current node is null, return null. If the current node is p or q, return the current node.
- Recurse: Recursively call on the left child to get
left_result, and on the right child to getright_result. - Decision:
- If both
left_resultandright_resultare non-null: p is in one subtree and q is in the other. The current node is the LCA — return it. - If only one is non-null: return that non-null result. It is either one of the targets being propagated upward, or the LCA already found deeper.
- If both are null: return null (neither target exists in this subtree).
- If both
Code
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (!root || root == p || root == q) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left && right) return root;
return left ? left : right;
}
};class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if not root or root == p or root == q:
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if left and right:
return root
return left if left else rightclass Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null || root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
if (left != null && right != null) return root;
return left != null ? left : right;
}
}Complexity Analysis
Time Complexity: O(n)
In the worst case, we visit every node in the tree exactly once. Each node performs a constant amount of work: one comparison (is it p or q?) and two recursive calls. The total number of operations is proportional to the number of nodes n.
Importantly, the algorithm often terminates early. When it finds p or q, it returns immediately without exploring that node's subtrees. In the best case (e.g., p is the root), the algorithm can return in O(1). But worst-case remains O(n) when both targets are deep leaves.
Space Complexity: O(h)
The only space used is the recursion call stack, which has depth equal to the height h of the tree. In a balanced tree, h = O(log n). In the worst case (skewed tree), h = O(n). Unlike the path comparison approach, we store no auxiliary data structures — no paths, no lists, no maps. The recursion stack itself carries all the information we need through return values.