Connected Components in Grid
Description
Given an undirected graph represented by an adjacency list adj[][], where adj[i] is the list of vertices directly connected to vertex i, find all the connected components in the graph.
A connected component is a maximal set of vertices such that there is a path between every pair of vertices in the set. The graph may be disconnected, meaning it can contain multiple connected components.
Return a list of lists, where each inner list contains the vertices belonging to one connected component. The components can be returned in any order, and the vertices within each component can be in any order.
Examples
Example 1
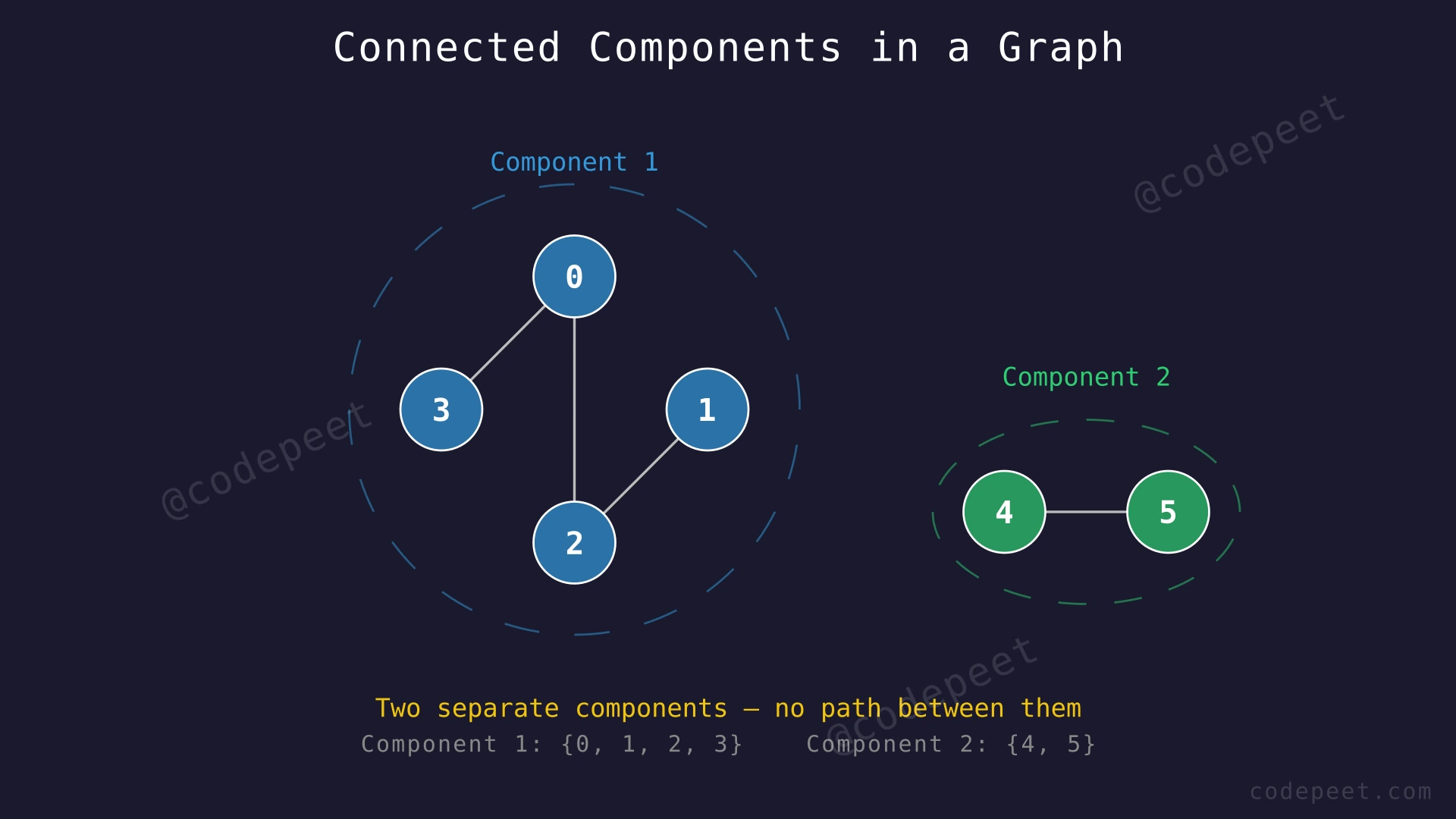
Input: adj = [[2, 3], [2], [0, 1], [0], [5], [4]]
Output: [[0, 2, 1, 3], [4, 5]]
Explanation: The graph has 6 vertices (0 through 5). Vertex 0 connects to vertices 2 and 3. Vertex 1 connects to vertex 2. Vertex 2 connects to vertices 0 and 1. Vertex 3 connects to vertex 0. These four vertices (0, 1, 2, 3) are all reachable from each other, forming one connected component. Vertices 4 and 5 connect only to each other, forming a second connected component. Total: 2 components.
Example 2
Input: adj = [[1, 2], [0, 2], [0, 1, 3, 4], [2], [2]]
Output: [[0, 1, 2, 3, 4]]
Explanation: Every vertex is reachable from every other vertex. Vertex 0 connects to 1 and 2. Vertex 2 connects to 0, 1, 3, and 4. Through vertex 2, all vertices are connected. The entire graph is one single connected component.
Example 3
Input: adj = [[], [], [], []]
Output: [[0], [1], [2], [3]]
Explanation: No vertex is connected to any other vertex. Each vertex is completely isolated, so each one forms its own connected component. There are 4 components in total.
Constraints
- 1 ≤ V ≤ 10^5 (number of vertices)
- 0 ≤ E ≤ 10^5 (number of edges)
- The graph is undirected: if
jis inadj[i], theniis inadj[j] - No self-loops or parallel edges
Editorial
Brute Force
Intuition
Think of the graph as a network of roads between towns. A connected component is a group of towns where you can travel between any two towns using roads, without needing to fly or teleport.
The simplest way to find all connected components is to use Depth-First Search (DFS). The idea is straightforward:
- Start with any town you haven't visited yet.
- Travel through every road you can find, visiting all reachable towns. Mark each town as visited and record it.
- Once you run out of roads to follow (you have visited every reachable town), all the towns you visited form one connected component.
- Look for another unvisited town and repeat.
Each time you start a new DFS from an unvisited vertex, you are discovering a new connected component. DFS works like walking through a maze — you follow one path as far as you can go, then backtrack and try another path, until you have explored everything reachable.
Step-by-Step Explanation
Let's trace through with adj = [[2, 3], [2], [0, 1], [0], [5], [4]] (6 vertices):
Step 1: Initialize visited = [false, false, false, false, false, false]. Create an empty result list.
Step 2: Start at vertex 0 (first unvisited). Begin a new component. Start DFS from vertex 0.
Step 3: DFS(0): Mark visited[0] = true, add 0 to current component. Neighbors of 0 are [2, 3]. Visit neighbor 2 first (unvisited).
Step 4: DFS(2): Mark visited[2] = true, add 2 to current component. Neighbors of 2 are [0, 1]. Vertex 0 is visited (skip). Vertex 1 is unvisited — visit it.
Step 5: DFS(1): Mark visited[1] = true, add 1 to current component. Neighbors of 1 are [2]. Vertex 2 is visited (skip). No more unvisited neighbors. Backtrack to DFS(2).
Step 6: Back in DFS(2): All neighbors checked. Backtrack to DFS(0).
Step 7: Back in DFS(0): Next neighbor is 3 (unvisited). Visit it.
Step 8: DFS(3): Mark visited[3] = true, add 3 to current component. Neighbors of 3 are [0]. Vertex 0 is visited (skip). Backtrack.
Step 9: Back in DFS(0): All neighbors processed. DFS from 0 is complete. Component 1 = [0, 2, 1, 3].
Step 10: Main loop continues: vertex 1, 2, 3 all visited. Vertex 4 is unvisited — start new component.
Step 11: DFS(4): Mark visited[4] = true, add 4 to component. Neighbors of 4: [5]. Vertex 5 is unvisited.
Step 12: DFS(5): Mark visited[5] = true, add 5 to component. Neighbors of 5: [4]. Vertex 4 is visited (skip). Backtrack.
Step 13: DFS(4) complete. Component 2 = [4, 5].
Step 14: All vertices visited. Return [[0, 2, 1, 3], [4, 5]].
DFS Connected Components — Exploring Reachable Vertices — Watch DFS systematically explore each connected component, marking vertices visited and collecting them into separate groups.
Algorithm
- Create a
visitedboolean array of sizeV, all set tofalse - Create an empty result list
components - For each vertex
ifrom0toV-1:- If
visited[i]isfalse:- Create a new empty list
component - Call DFS(i, component)
- Add
componenttocomponents
- Create a new empty list
- If
- DFS(v, component):
- Mark
visited[v] = true - Add
vtocomponent - For each neighbor
uinadj[v]:- If
visited[u]isfalse:- Call DFS(u, component)
- If
- Mark
- Return
components
Code
#include <vector>
using namespace std;
class Solution {
public:
void dfs(vector<vector<int>>& adj, vector<bool>& visited, int v, vector<int>& component) {
visited[v] = true;
component.push_back(v);
for (int u : adj[v]) {
if (!visited[u]) {
dfs(adj, visited, u, component);
}
}
}
vector<vector<int>> getComponents(vector<vector<int>>& adj) {
int V = adj.size();
vector<bool> visited(V, false);
vector<vector<int>> components;
for (int i = 0; i < V; i++) {
if (!visited[i]) {
vector<int> component;
dfs(adj, visited, i, component);
components.push_back(component);
}
}
return components;
}
};class Solution:
def getComponents(self, adj: list[list[int]]) -> list[list[int]]:
V = len(adj)
visited = [False] * V
components = []
def dfs(v: int, component: list[int]) -> None:
visited[v] = True
component.append(v)
for u in adj[v]:
if not visited[u]:
dfs(u, component)
for i in range(V):
if not visited[i]:
component = []
dfs(i, component)
components.append(component)
return componentsimport java.util.*;
class Solution {
public List<List<Integer>> getComponents(List<List<Integer>> adj) {
int V = adj.size();
boolean[] visited = new boolean[V];
List<List<Integer>> components = new ArrayList<>();
for (int i = 0; i < V; i++) {
if (!visited[i]) {
List<Integer> component = new ArrayList<>();
dfs(adj, visited, i, component);
components.add(component);
}
}
return components;
}
private void dfs(List<List<Integer>> adj, boolean[] visited, int v, List<Integer> component) {
visited[v] = true;
component.add(v);
for (int u : adj.get(v)) {
if (!visited[u]) {
dfs(adj, visited, u, component);
}
}
}
}Complexity Analysis
Time Complexity: O(V + E)
Each vertex is visited exactly once by DFS (we check visited[v] before recursing). Each edge is examined exactly twice (once from each endpoint in an undirected graph). The outer loop runs V times but does actual work only for unvisited vertices. Total: O(V + E).
Space Complexity: O(V + E)
The visited array takes O(V) space. The DFS recursion stack can go up to O(V) deep in the worst case (a linear chain graph). The output stores all V vertices across all components. The adjacency list input itself takes O(V + E). Total auxiliary space: O(V).
Why This Approach Is Not Efficient
The DFS approach is actually optimal in terms of time complexity — O(V + E) is the best we can achieve since we must examine every vertex and every edge at least once.
However, DFS uses recursion, which means the call stack can grow as deep as the number of vertices. For a graph with 100,000 vertices arranged in a long chain (0→1→2→...→99999), the recursion depth would be 100,000, which can cause a stack overflow in most programming languages with default stack sizes.
BFS solves this by using an explicit queue instead of the call stack, keeping the space usage more predictable and avoiding stack overflow risk. Both have the same time complexity, but BFS is more robust for large graphs with deep connected components.
Better Approach - BFS
Intuition
Instead of diving deep into one path like DFS, BFS explores layer by layer. Starting from a vertex, it first visits all direct neighbors (distance 1), then all neighbors of those neighbors (distance 2), and so on.
Imagine dropping a stone into a pond — ripples spread outward in concentric circles. BFS explores a graph the same way: from the source, it reaches all vertices at distance 1, then distance 2, and so on.
For finding connected components, BFS works exactly like DFS — start from an unvisited vertex, explore everything reachable, collect into a component. The only difference is the traversal order: BFS uses a queue (FIFO) while DFS uses a stack (either implicit recursion or explicit). The result is the same set of components.
The key advantage of BFS is that it uses an explicit queue, so there is no risk of stack overflow for deep graphs.
Step-by-Step Explanation
Let's trace through with adj = [[2, 3], [2], [0, 1], [0], [5], [4]] (6 vertices):
Step 1: Initialize visited = [false, false, false, false, false, false]. Result = [].
Step 2: Vertex 0 is unvisited. Start new component. Enqueue 0, mark visited[0] = true.
Step 3: Dequeue 0, add to component. Check neighbors [2, 3]. Vertex 2 unvisited → enqueue, mark visited. Vertex 3 unvisited → enqueue, mark visited. Queue: [2, 3].
Step 4: Dequeue 2, add to component. Check neighbors [0, 1]. Vertex 0 visited (skip). Vertex 1 unvisited → enqueue, mark visited. Queue: [3, 1].
Step 5: Dequeue 3, add to component. Check neighbors [0]. Vertex 0 visited (skip). Queue: [1].
Step 6: Dequeue 1, add to component. Check neighbors [2]. Vertex 2 visited (skip). Queue: []. BFS complete.
Step 7: Component 1 = [0, 2, 3, 1]. Save it.
Step 8: Vertices 1, 2, 3 visited. Vertex 4 unvisited — start new component. Enqueue 4, mark visited.
Step 9: Dequeue 4, add to component. Check neighbors [5]. Vertex 5 unvisited → enqueue, mark visited. Queue: [5].
Step 10: Dequeue 5, add to component. Check neighbors [4]. Vertex 4 visited (skip). Queue empty.
Step 11: Component 2 = [4, 5]. All vertices visited. Return [[0, 2, 3, 1], [4, 5]].
BFS Connected Components — Layer-by-Layer Discovery — Watch BFS explore each connected component using a queue, visiting vertices in order of distance from the starting vertex.
Algorithm
- Create a
visitedboolean array of sizeV, allfalse - Create an empty result list
components - For each vertex
ifrom0toV-1:- If
visited[i]isfalse:- Create a new
componentlist - Create a queue, enqueue
i, markvisited[i] = true - While queue is not empty:
- Dequeue vertex
curr - Add
currtocomponent - For each neighbor
uinadj[curr]:- If
visited[u]isfalse:- Mark
visited[u] = true - Enqueue
u
- Mark
- If
- Dequeue vertex
- Add
componenttocomponents
- Create a new
- If
- Return
components
Code
#include <vector>
#include <queue>
using namespace std;
class Solution {
public:
vector<vector<int>> getComponents(vector<vector<int>>& adj) {
int V = adj.size();
vector<bool> visited(V, false);
vector<vector<int>> components;
for (int i = 0; i < V; i++) {
if (!visited[i]) {
vector<int> component;
queue<int> q;
q.push(i);
visited[i] = true;
while (!q.empty()) {
int curr = q.front();
q.pop();
component.push_back(curr);
for (int u : adj[curr]) {
if (!visited[u]) {
visited[u] = true;
q.push(u);
}
}
}
components.push_back(component);
}
}
return components;
}
};from collections import deque
class Solution:
def getComponents(self, adj: list[list[int]]) -> list[list[int]]:
V = len(adj)
visited = [False] * V
components = []
for i in range(V):
if not visited[i]:
component = []
queue = deque([i])
visited[i] = True
while queue:
curr = queue.popleft()
component.append(curr)
for u in adj[curr]:
if not visited[u]:
visited[u] = True
queue.append(u)
components.append(component)
return componentsimport java.util.*;
class Solution {
public List<List<Integer>> getComponents(List<List<Integer>> adj) {
int V = adj.size();
boolean[] visited = new boolean[V];
List<List<Integer>> components = new ArrayList<>();
for (int i = 0; i < V; i++) {
if (!visited[i]) {
List<Integer> component = new ArrayList<>();
Queue<Integer> queue = new LinkedList<>();
queue.offer(i);
visited[i] = true;
while (!queue.isEmpty()) {
int curr = queue.poll();
component.add(curr);
for (int u : adj.get(curr)) {
if (!visited[u]) {
visited[u] = true;
queue.offer(u);
}
}
}
components.add(component);
}
}
return components;
}
}Complexity Analysis
Time Complexity: O(V + E)
Identical to DFS. Each vertex is enqueued and dequeued exactly once. Each edge is examined exactly twice (once from each endpoint). The main loop runs V times but actual BFS work only happens for unvisited vertices. Total: O(V + E).
Space Complexity: O(V)
The visited array takes O(V). The queue holds at most O(V) vertices at any time (in a star graph where one central vertex connects to all others, all V-1 neighbors get enqueued at once). Unlike DFS, there is no recursion stack — the queue is the only auxiliary data structure. Total: O(V).
Why This Approach Is Not Efficient
BFS runs in O(V + E) time, which is optimal for this problem. However, if the graph changes dynamically — new edges are added or removed, and we need to recompute connected components after each change — both BFS and DFS must re-traverse the entire graph from scratch.
The Union-Find (Disjoint Set Union) data structure handles this more gracefully. It can process edges incrementally: as each edge is added, it unions the two endpoints. Finding which component a vertex belongs to takes nearly O(1) amortized time (with path compression and union by rank). This makes Union-Find the preferred approach when building the graph edge by edge, or when the graph is given as an edge list rather than an adjacency list.
Optimal Approach - Union-Find (Disjoint Set Union)
Intuition
Union-Find treats each vertex as a member of a group. Initially, every vertex is in its own group (its own connected component). As we process each edge, we merge the groups of the two vertices connected by that edge.
Think of it like assigning team captains. At the start, every player is their own captain. When two players are on the same team (connected by an edge), one captain absorbs the other. To check if two players are on the same team, you just look up who their ultimate captain is.
Two critical optimizations make Union-Find incredibly fast:
-
Path compression: When finding a vertex's root (captain), we make every vertex on the path point directly to the root. Future lookups become instant.
-
Union by rank: When merging two trees, we attach the shorter one under the taller one, keeping the tree balanced.
With both optimizations, each find and union operation runs in O(α(n)) amortized time, where α is the inverse Ackermann function — essentially constant for all practical purposes.
After processing all edges, we group vertices by their root to form the final connected components.
Step-by-Step Explanation
Let's trace with adj = [[2, 3], [2], [0, 1], [0], [5], [4]] (6 vertices).
First, extract edges from adjacency list (each undirected edge appears twice, process each once): (0,2), (0,3), (1,2), (4,5).
Step 1: Initialize parent = [0, 1, 2, 3, 4, 5], rank = [0, 0, 0, 0, 0, 0]. Each vertex is its own root.
Step 2: Process edge (0, 2). Find(0) = 0, Find(2) = 2. Different roots → union. parent[2] = 0, rank[0] = 1. Now vertices 0 and 2 share root 0.
Step 3: Process edge (0, 3). Find(0) = 0, Find(3) = 3. Different roots → union. parent[3] = 0, rank[0] stays 1. Now 0, 2, 3 share root 0.
Step 4: Process edge (1, 2). Find(1) = 1, Find(2) → parent[2] = 0, root is 0. Different roots → union. parent[1] = 0. Now 0, 1, 2, 3 all share root 0.
Step 5: Process edge (4, 5). Find(4) = 4, Find(5) = 5. Different roots → union. parent[5] = 4, rank[4] = 1.
Step 6: All edges processed. Group vertices by root: root 0 → {0, 1, 2, 3}, root 4 → {4, 5}.
Step 7: Return [[0, 1, 2, 3], [4, 5]].
Union-Find — Merging Vertices Into Components — Watch Union-Find start with each vertex as its own component and merge them as edges are processed, using path compression for efficiency.
Algorithm
- Initialize Union-Find:
parent[i] = ifor all verticesrank[i] = 0for all vertices
- For each vertex
vand each neighboruinadj[v](wherev < uto avoid duplicate edges):- Call
union(v, u)
- Call
- After all edges processed, group vertices by their root:
- For each vertex
i, find its rootr = find(i) - Add
ito the group for rootr
- For each vertex
- Return all groups as the list of connected components
Find with path compression:
- If
parent[x] != x, setparent[x] = find(parent[x]) - Return
parent[x]
Union by rank:
- Find roots of both vertices
- If same root, return (already connected)
- Attach shorter tree under taller tree
- If same rank, pick one as root and increment its rank
Code
#include <vector>
#include <unordered_map>
using namespace std;
class Solution {
public:
vector<int> parent, rnk;
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rnk[rootX] < rnk[rootY]) {
parent[rootX] = rootY;
} else if (rnk[rootX] > rnk[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rnk[rootX]++;
}
}
vector<vector<int>> getComponents(vector<vector<int>>& adj) {
int V = adj.size();
parent.resize(V);
rnk.resize(V, 0);
for (int i = 0; i < V; i++) parent[i] = i;
for (int v = 0; v < V; v++) {
for (int u : adj[v]) {
if (v < u) {
unite(v, u);
}
}
}
unordered_map<int, vector<int>> groups;
for (int i = 0; i < V; i++) {
groups[find(i)].push_back(i);
}
vector<vector<int>> components;
for (auto& [root, members] : groups) {
components.push_back(members);
}
return components;
}
};from collections import defaultdict
class Solution:
def getComponents(self, adj: list[list[int]]) -> list[list[int]]:
V = len(adj)
parent = list(range(V))
rank = [0] * V
def find(x: int) -> int:
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def unite(x: int, y: int) -> None:
root_x = find(x)
root_y = find(y)
if root_x == root_y:
return
if rank[root_x] < rank[root_y]:
parent[root_x] = root_y
elif rank[root_x] > rank[root_y]:
parent[root_y] = root_x
else:
parent[root_y] = root_x
rank[root_x] += 1
for v in range(V):
for u in adj[v]:
if v < u:
unite(v, u)
groups = defaultdict(list)
for i in range(V):
groups[find(i)].append(i)
return list(groups.values())import java.util.*;
class Solution {
private int[] parent;
private int[] rank;
private int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
private void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
public List<List<Integer>> getComponents(List<List<Integer>> adj) {
int V = adj.size();
parent = new int[V];
rank = new int[V];
for (int i = 0; i < V; i++) parent[i] = i;
for (int v = 0; v < V; v++) {
for (int u : adj.get(v)) {
if (v < u) {
unite(v, u);
}
}
}
Map<Integer, List<Integer>> groups = new HashMap<>();
for (int i = 0; i < V; i++) {
int root = find(i);
groups.computeIfAbsent(root, k -> new ArrayList<>()).add(i);
}
return new ArrayList<>(groups.values());
}
}Complexity Analysis
Time Complexity: O((V + E) · α(V))
We iterate through all V vertices and their adjacency lists, which gives us E edges total (each counted once using the v < u filter). For each edge, we perform a find and unite operation, each taking O(α(V)) amortized time with path compression and union by rank. The inverse Ackermann function α(V) grows so slowly that it is effectively constant (≤ 4 for any V up to 10^80). The final grouping pass takes O(V · α(V)). Total: O((V + E) · α(V)) ≈ O(V + E) in practice.
Space Complexity: O(V)
The parent and rank arrays each use O(V) space. The groups hash map stores all V vertices. No recursion stack beyond path compression (which is at most O(log* V) deep after compression). Total: O(V).