Maximum Profit in Job Scheduling
Description
You are given n jobs where each job i has a start time, an end time, and a profit value. Your goal is to select a subset of these jobs that maximizes the total profit, with the constraint that no two selected jobs can overlap in time.
Two jobs are considered non-overlapping if one ends exactly when the other starts. In other words, if a job ends at time t, another job starting at time t can be selected alongside it — they will not conflict.
Return the maximum total profit achievable from any valid (non-overlapping) selection of jobs.
Examples
Example 1
Input: startTime = [1, 2, 3, 3], endTime = [3, 4, 5, 6], profit = [50, 10, 40, 70]
Output: 120
Explanation: We select job 0 (time 1-3, profit 50) and job 3 (time 3-6, profit 70). These two jobs do not overlap because job 0 ends at time 3 and job 3 starts at time 3. Total profit = 50 + 70 = 120. No other combination of non-overlapping jobs yields a higher profit.
Example 2
Input: startTime = [1, 2, 3, 4, 6], endTime = [3, 5, 10, 6, 9], profit = [20, 20, 100, 70, 60]
Output: 150
Explanation: We select job 0 (time 1-3, profit 20), job 3 (time 4-6, profit 70), and job 4 (time 6-9, profit 60). These jobs form a non-overlapping chain: each starts at or after the previous one ends. Total profit = 20 + 70 + 60 = 150. Although job 2 alone has profit 100, the chain of three smaller jobs gives a better total.
Example 3
Input: startTime = [1, 1, 1], endTime = [2, 3, 4], profit = [5, 6, 4]
Output: 6
Explanation: All three jobs start at time 1, so they all overlap with each other. We can only pick one job. Job 1 (time 1-3, profit 6) has the highest individual profit, so we select it alone for a total of 6.
Constraints
- 1 ≤ n ≤ 5 × 10^4
- 1 ≤ startTime[i] < endTime[i] ≤ 10^9
- 1 ≤ profit[i] ≤ 10^4
Editorial
Brute Force
Intuition
The most natural approach is to consider every possible combination of non-overlapping jobs and find the one with maximum profit. For each job, we face a binary choice: take it or skip it.
If we skip a job, we simply move on to the next one. If we take it, we earn its profit but must then jump ahead to the first job that starts after the current one ends, skipping any overlapping jobs in between.
This creates a decision tree where each branch represents a take-or-skip choice. We explore all branches and return the maximum profit found across every possible valid selection.
Think of it like planning a freelance work schedule: for each potential project, you either commit to it (blocking out that time window) or pass on it, always trying to maximize your earnings. The brute force tries every possible schedule.
Step-by-Step Explanation
Let's trace through with startTime = [1, 1, 1], endTime = [2, 3, 4], profit = [5, 6, 4]:
After sorting by start time, the jobs are:
- Job 0: start=1, end=2, profit=5
- Job 1: start=1, end=3, profit=6
- Job 2: start=1, end=4, profit=4
Step 1: Call dfs(0). We must decide: take job 0 or skip it.
Step 2: Explore skip branch → call dfs(1). Now decide about job 1.
Step 3: In dfs(1), explore skip → call dfs(2). Decide about job 2.
Step 4: In dfs(2), explore skip → call dfs(3). Index 3 is past the last job, so return 0 (base case).
Step 5: Back in dfs(2), explore take branch. Take job 2 (profit 4). Job 2 ends at time 4. Next valid job starting at ≥ 4 → none exist (j=3). take = 4 + dfs(3) = 4 + 0 = 4.
Step 6: dfs(2) resolves: max(skip=0, take=4) = 4. Job 2 alone is worth 4.
Step 7: Back in dfs(1), skip gave 4 from dfs(2). Explore take: job 1 (profit 6), ends at 3, next valid ≥ 3 → none (all start at 1). take = 6 + 0 = 6.
Step 8: dfs(1) resolves: max(skip=4, take=6) = 6. Job 1 alone beats job 2 alone.
Step 9: Back in dfs(0), skip gave 6. Explore take: job 0 (profit 5), ends at 2, next valid ≥ 2 → none. take = 5 + 0 = 5.
Step 10: dfs(0) resolves: max(skip=6, take=5) = 6.
Result: Maximum profit = 6 by selecting job 1 (profit 6) alone. Since all jobs overlap, we can only pick one, and job 1 has the highest profit.
Brute Force — Exploring All Take/Skip Decisions — Watch the recursion tree expand as we explore every possible combination of jobs. Each node represents a decision point where we either take or skip a job.
Algorithm
- Sort all jobs by their start time
- Define a recursive function dfs(i) returning the maximum profit from jobs i through n-1
- Base case: if i ≥ n, return 0 (no more jobs to consider)
- For each job i, compute two options:
- Skip: dfs(i + 1) — move to the next job
- Take: profit[i] + dfs(j), where j is the first job starting at or after endTime[i] (found by linear scan)
- Return max(skip, take)
- Call dfs(0) to get the answer
Code
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
int jobScheduling(vector<int>& startTime, vector<int>& endTime, vector<int>& profit) {
int n = startTime.size();
vector<tuple<int,int,int>> jobs;
for (int i = 0; i < n; i++) {
jobs.push_back({startTime[i], endTime[i], profit[i]});
}
sort(jobs.begin(), jobs.end());
return dfs(jobs, 0);
}
private:
int dfs(vector<tuple<int,int,int>>& jobs, int i) {
if (i >= (int)jobs.size()) return 0;
// Option 1: Skip current job
int skip = dfs(jobs, i + 1);
// Option 2: Take current job, find next non-overlapping
auto [s, e, p] = jobs[i];
int j = i + 1;
while (j < (int)jobs.size() && get<0>(jobs[j]) < e) j++;
int take = p + dfs(jobs, j);
return max(skip, take);
}
};class Solution:
def jobScheduling(self, startTime, endTime, profit):
jobs = sorted(zip(startTime, endTime, profit))
n = len(jobs)
def dfs(i):
if i >= n:
return 0
# Skip current job
skip = dfs(i + 1)
# Take current job, find next non-overlapping
_, end, p = jobs[i]
j = i + 1
while j < n and jobs[j][0] < end:
j += 1
take = p + dfs(j)
return max(skip, take)
return dfs(0)import java.util.*;
class Solution {
private int[][] jobs;
public int jobScheduling(int[] startTime, int[] endTime, int[] profit) {
int n = startTime.length;
jobs = new int[n][3];
for (int i = 0; i < n; i++) {
jobs[i] = new int[]{startTime[i], endTime[i], profit[i]};
}
Arrays.sort(jobs, (a, b) -> a[0] - b[0]);
return dfs(0);
}
private int dfs(int i) {
if (i >= jobs.length) return 0;
// Skip current job
int skip = dfs(i + 1);
// Take current job, find next non-overlapping
int j = i + 1;
while (j < jobs.length && jobs[j][0] < jobs[i][1]) j++;
int take = jobs[i][2] + dfs(j);
return Math.max(skip, take);
}
}Complexity Analysis
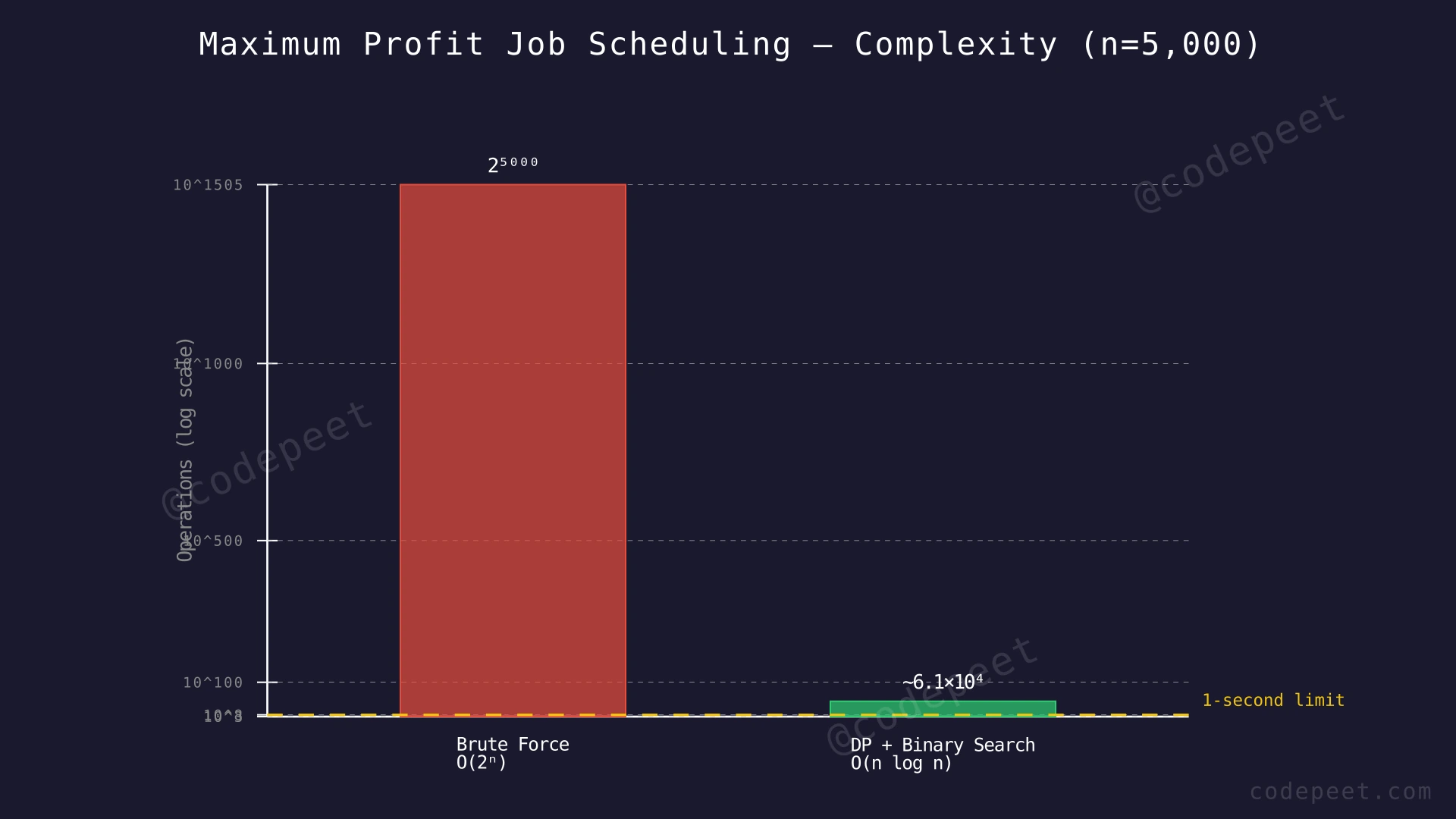
Time Complexity: O(2^n)
In the worst case where no jobs overlap, every subset is a valid selection. The recursion explores both take and skip for each job, creating a binary tree of depth n with up to 2^n leaf nodes. Additionally, each node does O(n) work to linearly scan for the next valid job, making the worst case O(n × 2^n).
Space Complexity: O(n)
The recursion depth is at most n (one call per job in the deepest chain), so the call stack uses O(n) space. Sorting requires O(n) space for the jobs array.
Why This Approach Is Not Efficient
The brute force explores every possible subset of non-overlapping jobs. With n up to 5 × 10^4, even 2^50 exceeds 10^15 operations — far beyond any reasonable time limit.
The root cause is redundant computation: the same subproblem "what is the best profit starting from job i?" gets solved many times in different branches of the recursion tree. For instance, when deciding about job 0, both the skip path (which goes to job 1) and the take path (which jumps ahead) may eventually need the answer for dfs(3), dfs(4), etc.
Two key insights fix this:
- Memoization (caching): Since dfs(i) depends only on i and the answer never changes, we can store each result the first time it is computed. This reduces the number of unique subproblems from exponential to just n.
- Binary search: Instead of linearly scanning for the next valid job (O(n) per call), we sort jobs by start time and use binary search to find the first non-conflicting job in O(log n).
Combining these two optimizations collapses the time from O(2^n) to O(n log n).
Optimal Approach - Sorting + DP with Binary Search
Intuition
The brute force recursion has a crucial property called optimal substructure: the best answer starting from job i depends only on i, not on which jobs were selected before it. This is the classic signal for dynamic programming.
Instead of recomputing the same subproblems, we build a DP table bottom-up. Define dp[i] as the maximum profit achievable from jobs i through n-1. Working backwards from the last job to the first:
For each job i, we make the same take-or-skip choice:
- Skip: dp[i+1] — the best we can do without this job
- Take: profit[i] + dp[j] — this job's profit plus the best after this job ends
The critical optimization is finding j (the next non-conflicting job) efficiently. Since jobs are sorted by start time, we can use binary search to find the first job whose start time is ≥ the current job's end time. This turns an O(n) linear scan into an O(log n) lookup.
The final answer is dp[0] — the maximum profit considering all jobs.
Step-by-Step Explanation
Let's trace through with startTime = [1, 2, 3, 3], endTime = [3, 4, 5, 6], profit = [50, 10, 40, 70]:
Step 1: Sort jobs by start time:
- Job 0: (start=1, end=3, profit=50)
- Job 1: (start=2, end=4, profit=10)
- Job 2: (start=3, end=5, profit=40)
- Job 3: (start=3, end=6, profit=70)
Create DP array of size 5: dp = [_, _, _, _, 0]
Step 2: Base case: dp[4] = 0 (no jobs left means zero profit).
Step 3: Compute dp[3]. Job 3 = (3, 6, 70). Binary search for first job starting at ≥ 6 → j = 4 (none found).
- Skip: dp[4] = 0
- Take: 70 + dp[4] = 70
- dp[3] = max(0, 70) = 70
Step 4: Compute dp[2]. Job 2 = (3, 5, 40). Binary search for first job starting at ≥ 5 → j = 4.
- Skip: dp[3] = 70
- Take: 40 + dp[4] = 40
- dp[2] = max(70, 40) = 70. Skipping wins — job 3 alone (70) beats job 2 alone (40).
Step 5: Compute dp[1]. Job 1 = (2, 4, 10). Binary search for first job starting at ≥ 4 → j = 4.
- Skip: dp[2] = 70
- Take: 10 + dp[4] = 10
- dp[1] = max(70, 10) = 70. Skipping again — job 1's profit is too low.
Step 6: Compute dp[0]. Job 0 = (1, 3, 50). Binary search for first job starting at ≥ 3 → j = 2.
- Skip: dp[1] = 70
- Take: 50 + dp[2] = 50 + 70 = 120
- dp[0] = max(70, 120) = 120. Taking wins! Job 0 (profit 50) plus the best from job 2 onwards (70) = 120.
Result: dp[0] = 120. The optimal selection is job 0 (1-3, profit 50) and job 3 (3-6, profit 70). They are non-overlapping since job 0 ends at 3 and job 3 starts at 3.
Bottom-Up DP with Binary Search — Filling the Table — Watch how we fill the DP table from right to left, using binary search at each step to find the next non-conflicting job and choosing the more profitable option between taking and skipping.
Algorithm
- Combine jobs into tuples (start, end, profit) and sort by start time
- Extract sorted start times into a separate array for binary search
- Create a DP array of size n+1, initialized to 0
- dp[i] represents the maximum profit achievable from jobs[i..n-1]
- Iterate from i = n-1 down to 0:
- For job i with end time e and profit p:
- Use binary search on start times to find j = first index where start[j] ≥ e (searching only indices > i)
- dp[i] = max(dp[i+1], p + dp[j])
- Return dp[0]
Code
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
int jobScheduling(vector<int>& startTime, vector<int>& endTime, vector<int>& profit) {
int n = startTime.size();
vector<tuple<int,int,int>> jobs;
for (int i = 0; i < n; i++) {
jobs.push_back({startTime[i], endTime[i], profit[i]});
}
sort(jobs.begin(), jobs.end());
// Extract sorted start times for binary search
vector<int> starts(n);
for (int i = 0; i < n; i++) {
starts[i] = get<0>(jobs[i]);
}
// Bottom-up DP: dp[i] = max profit from jobs[i..n)
vector<int> dp(n + 1, 0);
for (int i = n - 1; i >= 0; i--) {
auto [s, e, p] = jobs[i];
int j = lower_bound(starts.begin() + i + 1, starts.end(), e) - starts.begin();
dp[i] = max(dp[i + 1], p + dp[j]);
}
return dp[0];
}
};from bisect import bisect_left
class Solution:
def jobScheduling(self, startTime, endTime, profit):
jobs = sorted(zip(startTime, endTime, profit))
n = len(jobs)
# Bottom-up DP: dp[i] = max profit from jobs[i..n)
dp = [0] * (n + 1)
for i in range(n - 1, -1, -1):
start, end, p = jobs[i]
j = bisect_left(jobs, end, lo=i + 1, key=lambda x: x[0])
dp[i] = max(dp[i + 1], p + dp[j])
return dp[0]import java.util.*;
class Solution {
public int jobScheduling(int[] startTime, int[] endTime, int[] profit) {
int n = startTime.length;
int[][] jobs = new int[n][3];
for (int i = 0; i < n; i++) {
jobs[i] = new int[]{startTime[i], endTime[i], profit[i]};
}
Arrays.sort(jobs, (a, b) -> a[0] - b[0]);
int[] starts = new int[n];
for (int i = 0; i < n; i++) {
starts[i] = jobs[i][0];
}
// Bottom-up DP: dp[i] = max profit from jobs[i..n)
int[] dp = new int[n + 1];
for (int i = n - 1; i >= 0; i--) {
int end = jobs[i][1];
int p = jobs[i][2];
int j = lowerBound(starts, i + 1, n, end);
dp[i] = Math.max(dp[i + 1], p + dp[j]);
}
return dp[0];
}
private int lowerBound(int[] arr, int lo, int hi, int target) {
while (lo < hi) {
int mid = lo + (hi - lo) / 2;
if (arr[mid] < target) lo = mid + 1;
else hi = mid;
}
return lo;
}
}Complexity Analysis
Time Complexity: O(n log n)
Sorting the jobs takes O(n log n). The DP loop iterates n times, and each iteration performs one binary search in O(log n) time plus one constant-time max comparison. Total: O(n log n) for sorting + O(n log n) for the DP loop = O(n log n) overall.
Space Complexity: O(n)
We use O(n) for the sorted jobs array, O(n) for the extracted start times array used in binary search, and O(n) for the DP table. Total auxiliary space is O(n).