Doubly Linked List Fundamentals
Description
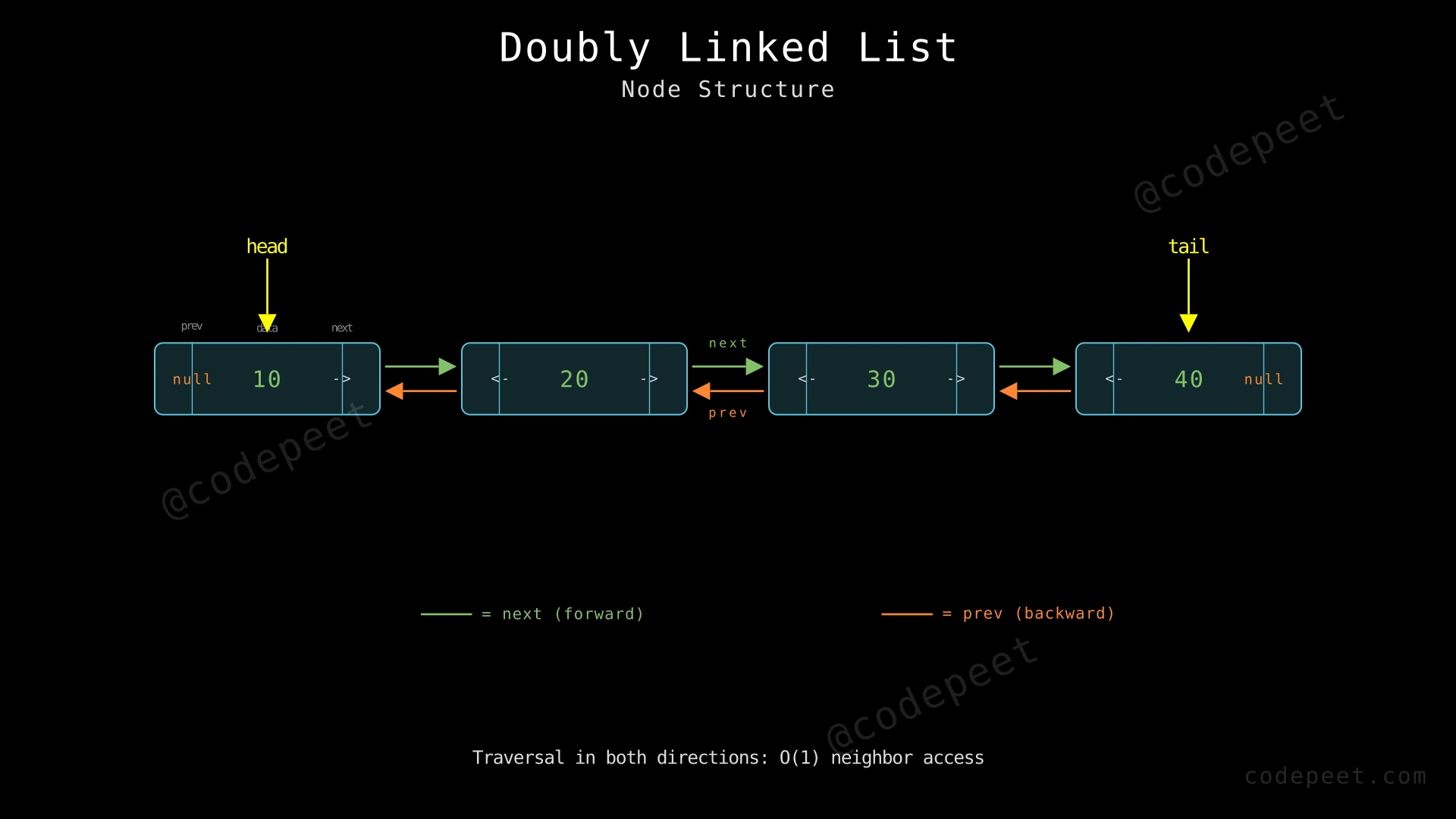
A Doubly Linked List (DLL) is a linear data structure where each element (called a node) contains three fields:
- Data — the actual value stored in the node
- Next pointer — a reference to the next node in the list
- Previous pointer — a reference to the previous node in the list
Unlike a singly linked list where each node only knows about the node after it, a doubly linked list allows traversal in both directions — forward and backward. This bidirectional capability makes certain operations more efficient, such as deleting a node when you only have a pointer to it (O(1) instead of O(n)).
The first node's prev pointer is null (nothing comes before the head), and the last node's next pointer is null (nothing comes after the tail).
In this problem, you will learn to implement the fundamental operations on a Doubly Linked List:
- Traversal — visiting every node (forward and backward)
- Insertion — adding a node at the beginning, at the end, or at a specific position
- Deletion — removing a node from the beginning, from the end, or from a specific position
Examples
Example 1 — Forward Traversal
Input: DLL: 10 ↔ 20 ↔ 30 ↔ 40
Output (forward): 10 20 30 40
Explanation: Starting from the head (10), we follow the next pointers: 10 → 20 → 30 → 40 → null. Each node is visited in order from left to right.
Example 2 — Backward Traversal
Input: DLL: 10 ↔ 20 ↔ 30 ↔ 40
Output (backward): 40 30 20 10
Explanation: Starting from the tail (40), we follow the prev pointers: 40 → 30 → 20 → 10 → null. This is only possible because of the prev pointers — a singly linked list cannot do this.
Example 3 — Insert at Beginning
Input: DLL: 20 ↔ 30 ↔ 40, Insert value 10 at the beginning
Output: 10 ↔ 20 ↔ 30 ↔ 40
Explanation: A new node with value 10 is created. Its next is set to the current head (20), and the current head's prev is set to the new node. The head pointer is updated to point to the new node (10).
Example 4 — Delete from End
Input: DLL: 10 ↔ 20 ↔ 30 ↔ 40, Delete from the end
Output: 10 ↔ 20 ↔ 30
Explanation: The tail node (40) is removed. Its predecessor (30) becomes the new tail, and 30's next is set to null. Unlike singly linked lists where deleting the tail requires O(n) traversal to find the predecessor, a DLL can find the predecessor in O(1) using 40's prev pointer.
Constraints
- 0 ≤ number of nodes ≤ 10^5
- -10^9 ≤ Node.data ≤ 10^9
- Position for insertion/deletion is valid (within bounds of the list)
- The list may be empty (head = null)
Editorial
Brute Force
Intuition
Before learning the doubly linked list, let's understand what a singly linked list provides and where it falls short. A singly linked list gives us:
- Forward traversal: O(n) ✅
- Insertion at head: O(1) ✅
- Deletion at head: O(1) ✅
But a singly linked list struggles with:
- Backward traversal: Impossible (no
prevpointers) - Deletion of a given node (when you have a pointer to it): O(n) — you must traverse from the head to find the predecessor
- Deletion at the tail: O(n) — same reason, finding the second-to-last node requires full traversal
The "brute force" approach to handle these operations with a singly linked list would be to always traverse from the head to find predecessors. For example, to delete the last node, you'd walk the entire list to find the second-to-last node. This takes O(n) time for every such operation.
The doubly linked list was invented specifically to overcome these limitations by adding a prev pointer to each node.
Step-by-Step Explanation
Let's trace the inefficiency of deleting the tail node in a singly linked list:
Setup: Singly linked list: 10 → 20 → 30 → 40 → null. We want to delete the tail (40).
Step 1: Start at the head (10). We need to find the node whose next is 40.
Step 2: Check node 10: node.next = 20 (not 40). Move forward.
Step 3: Check node 20: node.next = 30 (not 40). Move forward.
Step 4: Check node 30: node.next = 40 (found the predecessor!).
Step 5: Set node 30's next to null. Node 40 is now disconnected.
Result: 10 → 20 → 30 → null. But we traversed 3 nodes to delete 1 node.
For a list of length n, deleting the tail always requires visiting n-1 nodes — O(n) time. In a doubly linked list, we can do this in O(1) because node 40 already knows its predecessor (40.prev = 30).
Algorithm
Singly linked list tail deletion (brute force):
- If list is empty or has one node, handle edge case
- Start at head
- Traverse until you find the node whose
next.next == null - Set that node's
next = null(it becomes the new tail) - Return head
This requires O(n) traversal because singly linked nodes cannot look backward.
Code
#include <iostream>
using namespace std;
// Singly linked list node
struct SLLNode {
int data;
SLLNode* next;
SLLNode(int val) : data(val), next(nullptr) {}
};
// Delete tail in a singly linked list — O(n)
SLLNode* deleteTailSLL(SLLNode* head) {
if (head == nullptr || head->next == nullptr) {
// Empty list or single node
return nullptr;
}
// Traverse to find second-to-last node
SLLNode* curr = head;
while (curr->next->next != nullptr) {
curr = curr->next;
}
// Remove last node
delete curr->next;
curr->next = nullptr;
return head;
}class SLLNode:
def __init__(self, data):
self.data = data
self.next = None
def delete_tail_sll(head):
"""Delete tail in a singly linked list — O(n)"""
if head is None or head.next is None:
# Empty list or single node
return None
# Traverse to find second-to-last node
curr = head
while curr.next.next is not None:
curr = curr.next
# Remove last node
curr.next = None
return headclass SLLNode {
int data;
SLLNode next;
SLLNode(int val) { data = val; next = null; }
}
class Solution {
// Delete tail in a singly linked list — O(n)
public SLLNode deleteTailSLL(SLLNode head) {
if (head == null || head.next == null) {
// Empty list or single node
return null;
}
// Traverse to find second-to-last node
SLLNode curr = head;
while (curr.next.next != null) {
curr = curr.next;
}
// Remove last node
curr.next = null;
return head;
}
}Complexity Analysis
Time Complexity: O(n)
We traverse the entire list to find the second-to-last node. For a list of length n, we visit n-1 nodes.
Space Complexity: O(1)
Only a single pointer curr is used for traversal. No additional data structures.
Why This Approach Is Not Efficient
Using a singly linked list forces us to traverse O(n) nodes any time we need a node's predecessor — whether for tail deletion, arbitrary deletion, or backward traversal. Every node only knows about the node ahead of it, not the node behind it.
The fundamental problem is one-directional knowledge. If each node also knew about its predecessor (via a prev pointer), we could:
- Delete the tail in O(1) —
tail.prevgives us the predecessor instantly - Delete any node in O(1) — given a pointer to the node,
node.prevandnode.nextgive us both neighbors - Traverse backward — follow
prevpointers from tail to head
This is exactly what a Doubly Linked List provides. By trading a small amount of extra memory per node (one additional pointer), we gain significant efficiency for many common operations.
Optimal Approach - Doubly Linked List Operations
Intuition
A doubly linked list node has three fields: prev, data, and next. The prev pointer connects each node to the one before it, while next connects it to the one after. This creates a bidirectional chain where you can walk in either direction.
Think of it like a line of people holding hands. In a singly linked list, each person only holds the hand of the person in front of them — they can walk forward but can't easily turn around. In a doubly linked list, each person holds hands with both the person in front and behind. Anyone can walk in either direction, and if someone in the middle needs to leave, they can easily connect their two neighbors to each other.
We'll cover all the fundamental operations:
- Forward Traversal — walk from head to tail using
nextpointers - Backward Traversal — walk from tail to head using
prevpointers - Insert at Beginning — create a new head
- Insert at End — create a new tail
- Insert at Position — add a node at a specific index
- Delete from Beginning — remove the head
- Delete from End — remove the tail
- Delete at Position — remove a node at a specific index
Step-by-Step Explanation
Let's trace through the key operations on a DLL: null ← 10 ↔ 20 ↔ 30 → null
Operation 1: Insert at Beginning (insert value 5)
Step 1: Create a new node with value 5. Its prev = null, next = null.
Step 2: Set newNode.next = head (the current head is node 10).
Step 3: Set head.prev = newNode (node 10 now knows 5 is behind it).
Step 4: Update head = newNode. The new head is node 5.
Result: null ← 5 ↔ 10 ↔ 20 ↔ 30 → null
Operation 2: Delete from End (remove last node)
Starting list: null ← 5 ↔ 10 ↔ 20 ↔ 30 → null
Step 1: Find the tail node. Traverse to reach node 30 (or maintain a tail pointer).
Step 2: Access tail.prev = node 20. This is the new tail.
Step 3: Set node 20's next = null. Node 20 is now the last node.
Step 4: Disconnect node 30 (it can be garbage collected).
Result: null ← 5 ↔ 10 ↔ 20 → null
Notice that Step 2 is O(1) — we used the prev pointer to find the predecessor instantly. In a singly linked list, this step would require an O(n) traversal.
Operation 3: Insert at Position 2 (insert value 15 between 10 and 20)
Starting list: null ← 5 ↔ 10 ↔ 20 → null
Step 1: Create a new node with value 15.
Step 2: Traverse to the node at position 1 (node 10). This will be the predecessor of the new node.
Step 3: Set newNode.next = node 10's next (which is node 20).
Step 4: Set newNode.prev = node 10.
Step 5: Set node 20's prev = newNode.
Step 6: Set node 10's next = newNode.
Result: null ← 5 ↔ 10 ↔ 15 ↔ 20 → null
The order of pointer updates matters! If we update node 10's next before saving a reference to node 20, we lose access to node 20.
Insert at Beginning — Adding a New Head to the DLL — Watch how a new node is inserted at the front of a doubly linked list by updating both next and prev pointers.
Delete from End — Removing the Tail Using prev Pointer — Watch how the tail node is removed in O(1) by using its prev pointer to find and update the predecessor — something impossible in a singly linked list.
Algorithm
Node Definition:
- Each node has:
data,prev(pointer to previous node),next(pointer to next node)
1. Forward Traversal:
- Start at head
- While current node is not null:
- Process current node
- Move to current.next
2. Backward Traversal:
- Start at tail (or traverse to the end first)
- While current node is not null:
- Process current node
- Move to current.prev
3. Insert at Beginning:
- Create new node
- Set newNode.next = head
- If head is not null, set head.prev = newNode
- Set head = newNode
4. Insert at End:
- Create new node
- If list is empty, set head = newNode and return
- Traverse to the last node
- Set lastNode.next = newNode
- Set newNode.prev = lastNode
5. Delete from Beginning:
- If list is empty, return
- Set head = head.next
- If new head is not null, set head.prev = null
6. Delete from End:
- If list has one node, set head = null and return
- Access tail.prev (predecessor) via the prev pointer
- Set predecessor.next = null
- The old tail is now disconnected
7. Insert at Position k:
- Traverse to node at position k-1
- Create new node
- Set newNode.next = predecessor.next
- Set newNode.prev = predecessor
- If predecessor.next exists, set predecessor.next.prev = newNode
- Set predecessor.next = newNode
8. Delete at Position k:
- Traverse to node at position k
- Set node.prev.next = node.next (skip forward)
- If node.next exists, set node.next.prev = node.prev (skip backward)
- Disconnect the node
Code
#include <iostream>
using namespace std;
class Node {
public:
int data;
Node* prev;
Node* next;
Node(int val) : data(val), prev(nullptr), next(nullptr) {}
};
class DoublyLinkedList {
public:
Node* head;
DoublyLinkedList() : head(nullptr) {}
// Forward traversal
void traverseForward() {
Node* curr = head;
while (curr != nullptr) {
cout << curr->data << " ";
curr = curr->next;
}
cout << endl;
}
// Backward traversal
void traverseBackward() {
if (head == nullptr) return;
// Go to the last node
Node* curr = head;
while (curr->next != nullptr) {
curr = curr->next;
}
// Traverse backward
while (curr != nullptr) {
cout << curr->data << " ";
curr = curr->prev;
}
cout << endl;
}
// Insert at beginning
void insertAtBeginning(int val) {
Node* newNode = new Node(val);
newNode->next = head;
if (head != nullptr) {
head->prev = newNode;
}
head = newNode;
}
// Insert at end
void insertAtEnd(int val) {
Node* newNode = new Node(val);
if (head == nullptr) {
head = newNode;
return;
}
Node* curr = head;
while (curr->next != nullptr) {
curr = curr->next;
}
curr->next = newNode;
newNode->prev = curr;
}
// Insert at position (0-indexed)
void insertAtPosition(int val, int pos) {
if (pos == 0) {
insertAtBeginning(val);
return;
}
Node* curr = head;
for (int i = 0; i < pos - 1 && curr != nullptr; i++) {
curr = curr->next;
}
if (curr == nullptr) return;
Node* newNode = new Node(val);
newNode->next = curr->next;
newNode->prev = curr;
if (curr->next != nullptr) {
curr->next->prev = newNode;
}
curr->next = newNode;
}
// Delete from beginning
void deleteFromBeginning() {
if (head == nullptr) return;
Node* temp = head;
head = head->next;
if (head != nullptr) {
head->prev = nullptr;
}
delete temp;
}
// Delete from end
void deleteFromEnd() {
if (head == nullptr) return;
if (head->next == nullptr) {
delete head;
head = nullptr;
return;
}
Node* curr = head;
while (curr->next != nullptr) {
curr = curr->next;
}
curr->prev->next = nullptr;
delete curr;
}
// Delete at position (0-indexed)
void deleteAtPosition(int pos) {
if (head == nullptr) return;
if (pos == 0) {
deleteFromBeginning();
return;
}
Node* curr = head;
for (int i = 0; i < pos && curr != nullptr; i++) {
curr = curr->next;
}
if (curr == nullptr) return;
curr->prev->next = curr->next;
if (curr->next != nullptr) {
curr->next->prev = curr->prev;
}
delete curr;
}
};class Node:
def __init__(self, data):
self.data = data
self.prev = None
self.next = None
class DoublyLinkedList:
def __init__(self):
self.head = None
# Forward traversal
def traverse_forward(self):
result = []
curr = self.head
while curr is not None:
result.append(curr.data)
curr = curr.next
return result
# Backward traversal
def traverse_backward(self):
if self.head is None:
return []
# Go to the last node
curr = self.head
while curr.next is not None:
curr = curr.next
# Traverse backward
result = []
while curr is not None:
result.append(curr.data)
curr = curr.prev
return result
# Insert at beginning
def insert_at_beginning(self, val):
new_node = Node(val)
new_node.next = self.head
if self.head is not None:
self.head.prev = new_node
self.head = new_node
# Insert at end
def insert_at_end(self, val):
new_node = Node(val)
if self.head is None:
self.head = new_node
return
curr = self.head
while curr.next is not None:
curr = curr.next
curr.next = new_node
new_node.prev = curr
# Insert at position (0-indexed)
def insert_at_position(self, val, pos):
if pos == 0:
self.insert_at_beginning(val)
return
curr = self.head
for _ in range(pos - 1):
if curr is None:
return
curr = curr.next
if curr is None:
return
new_node = Node(val)
new_node.next = curr.next
new_node.prev = curr
if curr.next is not None:
curr.next.prev = new_node
curr.next = new_node
# Delete from beginning
def delete_from_beginning(self):
if self.head is None:
return
self.head = self.head.next
if self.head is not None:
self.head.prev = None
# Delete from end
def delete_from_end(self):
if self.head is None:
return
if self.head.next is None:
self.head = None
return
curr = self.head
while curr.next is not None:
curr = curr.next
curr.prev.next = None
# Delete at position (0-indexed)
def delete_at_position(self, pos):
if self.head is None:
return
if pos == 0:
self.delete_from_beginning()
return
curr = self.head
for _ in range(pos):
if curr is None:
return
curr = curr.next
if curr is None:
return
curr.prev.next = curr.next
if curr.next is not None:
curr.next.prev = curr.prevclass Node {
int data;
Node prev;
Node next;
Node(int val) {
data = val;
prev = null;
next = null;
}
}
class DoublyLinkedList {
Node head;
DoublyLinkedList() {
head = null;
}
// Forward traversal
void traverseForward() {
Node curr = head;
while (curr != null) {
System.out.print(curr.data + " ");
curr = curr.next;
}
System.out.println();
}
// Backward traversal
void traverseBackward() {
if (head == null) return;
// Go to the last node
Node curr = head;
while (curr.next != null) {
curr = curr.next;
}
// Traverse backward
while (curr != null) {
System.out.print(curr.data + " ");
curr = curr.prev;
}
System.out.println();
}
// Insert at beginning
void insertAtBeginning(int val) {
Node newNode = new Node(val);
newNode.next = head;
if (head != null) {
head.prev = newNode;
}
head = newNode;
}
// Insert at end
void insertAtEnd(int val) {
Node newNode = new Node(val);
if (head == null) {
head = newNode;
return;
}
Node curr = head;
while (curr.next != null) {
curr = curr.next;
}
curr.next = newNode;
newNode.prev = curr;
}
// Insert at position (0-indexed)
void insertAtPosition(int val, int pos) {
if (pos == 0) {
insertAtBeginning(val);
return;
}
Node curr = head;
for (int i = 0; i < pos - 1 && curr != null; i++) {
curr = curr.next;
}
if (curr == null) return;
Node newNode = new Node(val);
newNode.next = curr.next;
newNode.prev = curr;
if (curr.next != null) {
curr.next.prev = newNode;
}
curr.next = newNode;
}
// Delete from beginning
void deleteFromBeginning() {
if (head == null) return;
head = head.next;
if (head != null) {
head.prev = null;
}
}
// Delete from end
void deleteFromEnd() {
if (head == null) return;
if (head.next == null) {
head = null;
return;
}
Node curr = head;
while (curr.next != null) {
curr = curr.next;
}
curr.prev.next = null;
}
// Delete at position (0-indexed)
void deleteAtPosition(int pos) {
if (head == null) return;
if (pos == 0) {
deleteFromBeginning();
return;
}
Node curr = head;
for (int i = 0; i < pos && curr != null; i++) {
curr = curr.next;
}
if (curr == null) return;
curr.prev.next = curr.next;
if (curr.next != null) {
curr.next.prev = curr.prev;
}
}
}Complexity Analysis
Time Complexity:
| Operation | Time | Explanation |
|---|---|---|
| Forward Traversal | O(n) | Visit every node once |
| Backward Traversal | O(n) | Visit every node once (from tail to head) |
| Insert at Beginning | O(1) | Only pointer updates, no traversal needed |
| Insert at End | O(n) | Need to traverse to find the tail (O(1) if tail pointer is maintained) |
| Insert at Position k | O(k) | Traverse to position k-1 |
| Delete from Beginning | O(1) | Only pointer updates |
| Delete from End | O(n) | Need to traverse to find the tail (O(1) if tail pointer is maintained) |
| Delete at Position k | O(k) | Traverse to position k |
| Delete a Given Node (with pointer) | O(1) | Use prev/next to update neighbors — this is the DLL's biggest advantage |
Space Complexity: O(n)
Each node requires O(1) extra space for the prev pointer compared to a singly linked list. For n nodes, the total extra overhead is O(n). However, this is a fixed cost of the data structure itself — no additional space is used during operations.
Comparison with Singly Linked List:
| Operation | SLL | DLL | DLL Advantage |
|---|---|---|---|
| Delete given node (with pointer) | O(n) | O(1) | ✅ Major improvement |
| Delete from end | O(n) | O(n) or O(1) with tail | ✅ With tail pointer |
| Backward traversal | Impossible | O(n) | ✅ New capability |
| Memory per node | 1 pointer | 2 pointers | ❌ More memory |
The doubly linked list trades memory for flexibility. The extra prev pointer per node is a small cost that enables O(1) deletion of any node (given a pointer) and bidirectional traversal — two capabilities that are impossible or expensive with a singly linked list.