Disjoint Set (Union-Find)
Description
A Disjoint Set (also called Union-Find) is a data structure that manages a collection of non-overlapping (disjoint) sets. It is initialized with n elements, where each element starts in its own singleton set.
The data structure supports two primary operations:
- Find(x): Determine which set element x belongs to. This is done by returning a representative (also called the root or leader) of that set. Two elements belong to the same set if and only if they share the same representative.
- Union(x, y): Merge the set containing element x with the set containing element y into a single set.
Disjoint Set is a foundational building block in graph algorithms. It is used for detecting cycles in undirected graphs, finding connected components, and powering Kruskal's Minimum Spanning Tree algorithm.
Your task is to implement an efficient Disjoint Set data structure that can handle a sequence of Union and Find operations on n elements labeled 0 through n - 1.
Examples
Example 1
Input: n = 5, Operations: union(0, 1), union(2, 3), union(1, 3), find(0), find(2), find(4)
Output: find(0) and find(2) return the same representative (elements 0, 1, 2, 3 are all in one set). find(4) returns 4 (still a singleton).
Explanation:
- After union(0, 1): Sets are {0, 1}, {2}, {3}, {4}.
- After union(2, 3): Sets are {0, 1}, {2, 3}, {4}.
- After union(1, 3): Since 1 is in the same set as 0, and 3 is in the same set as 2, all four merge: {0, 1, 2, 3}, {4}.
- find(0) and find(2) now return the same representative because 0 and 2 are in the same set.
- find(4) returns 4 because element 4 was never merged with anything.
Example 2
Input: n = 3, Operations: find(0), find(1), union(0, 2), find(0), find(2)
Output: Initially find(0) = 0, find(1) = 1 (each is its own representative). After union(0, 2), find(0) and find(2) return the same representative.
Explanation:
- Before any unions, every element is its own set: {0}, {1}, {2}.
- find(0) returns 0, find(1) returns 1 — they are in different sets.
- union(0, 2) merges the sets containing 0 and 2: {0, 2}, {1}.
- Now find(0) == find(2) confirms that 0 and 2 are connected.
- find(1) still returns 1 because element 1 remains in its own singleton set.
Example 3
Input: n = 1, Operations: find(0)
Output: find(0) = 0
Explanation: With only one element, it is trivially its own representative. This edge case confirms the data structure handles singletons correctly.
Constraints
- 1 ≤ n ≤ 10^6 (number of elements)
- 1 ≤ q ≤ 10^6 (number of union/find operations)
- 0 ≤ x, y < n (elements are 0-indexed)
- Each element starts in its own singleton set
- union(x, y) where x and y are already in the same set is a valid no-op
Editorial
Brute Force
Intuition
The most straightforward way to represent disjoint sets is to give every element a parent pointer. Initially, each element is its own parent (meaning it is the root of its own one-element tree). When we want to merge two sets, we find the root of each element by following parent pointers upward, then make one root point to the other.
Think of it like a corporate hierarchy. Each person has a manager. To find which company someone belongs to, you follow the chain of managers all the way up to the CEO. To merge two companies, you simply make one CEO report to the other.
The problem with this naive approach is that we have no control over how tall these trees grow. If unions happen in an unfortunate order, the tree can degenerate into a long chain — like a company where every employee is the direct report of the person hired just before them, creating a single line from the newest hire all the way up to the CEO.
Step-by-Step Explanation
Let's trace through n = 5 with operations: union(0,1), union(1,2), union(2,3), union(3,4), then find(0).
Our naive implementation always attaches the first argument's root under the second argument's root: parent[find(x)] = find(y).
Step 1: Initialize parent array. Every element is its own root.
- parent = [0, 1, 2, 3, 4]
Step 2: union(0, 1) — find(0) = 0, find(1) = 1. Set parent[0] = 1.
- parent = [1, 1, 2, 3, 4]
- Tree: 1 ← 0, and singletons 2, 3, 4
Step 3: union(1, 2) — find(1) = 1, find(2) = 2. Set parent[1] = 2.
- parent = [1, 2, 2, 3, 4]
- Tree: 2 ← 1 ← 0, and singletons 3, 4
Step 4: union(2, 3) — find(2) = 2, find(3) = 3. Set parent[2] = 3.
- parent = [1, 2, 3, 3, 4]
- Tree: 3 ← 2 ← 1 ← 0, and singleton 4
Step 5: union(3, 4) — find(3) = 3, find(4) = 4. Set parent[3] = 4.
- parent = [1, 2, 3, 4, 4]
- Tree: 4 ← 3 ← 2 ← 1 ← 0 (a chain of length 4!)
Step 6: find(0) — Follow the chain: 0 → 1 → 2 → 3 → 4. That is 4 hops to reach the root.
- In a balanced structure, this should take at most ~2 hops for 5 elements.
Step 7: The root is 4. Return 4.
- parent remains [1, 2, 3, 4, 4] (no modification in naive find)
Naive Union-Find — Worst-Case Chain Formation — Watch how the naive union-find creates a degenerate chain when unions always attach to the right, causing find to traverse the entire structure.
Algorithm
- Initialize: Create a parent array of size n where parent[i] = i (each element is its own root).
- find(x):
- If parent[x] == x, return x (x is a root).
- Otherwise, recursively return find(parent[x]) — follow parent pointers until a root is found.
- union(x, y):
- Find root_x = find(x) and root_y = find(y).
- If root_x ≠ root_y, set parent[root_x] = root_y (attach one tree under the other).
- If root_x == root_y, the elements are already in the same set — do nothing.
Code
#include <vector>
using namespace std;
class NaiveUnionFind {
vector<int> parent;
public:
NaiveUnionFind(int n) {
parent.resize(n);
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] == x) {
return x;
}
return find(parent[x]);
}
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
parent[rootX] = rootY;
}
}
bool connected(int x, int y) {
return find(x) == find(y);
}
};class NaiveUnionFind:
def __init__(self, n: int):
self.parent = list(range(n))
def find(self, x: int) -> int:
if self.parent[x] == x:
return x
return self.find(self.parent[x])
def union(self, x: int, y: int) -> None:
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
self.parent[root_x] = root_y
def connected(self, x: int, y: int) -> bool:
return self.find(x) == self.find(y)class NaiveUnionFind {
private int[] parent;
public NaiveUnionFind(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
public int find(int x) {
if (parent[x] == x) {
return x;
}
return find(parent[x]);
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
parent[rootX] = rootY;
}
}
public boolean connected(int x, int y) {
return find(x) == find(y);
}
}Complexity Analysis
Time Complexity: O(n) per find operation in the worst case
Without any balancing, the trees can degenerate into linear chains of depth n - 1. Each find operation must traverse the full chain to reach the root. For q operations, the total worst-case time is O(n × q).
The union operation itself is O(1) after finding roots (just a pointer update), but it calls find twice, making union also O(n) in the worst case.
Space Complexity: O(n)
We store a single parent array of size n. No additional data structures are used.
Why This Approach Is Not Efficient
The naive Union-Find has O(n) worst-case time per find operation. When we perform unions without considering tree height, the resulting trees can degenerate into linear chains — essentially linked lists where every element points to the next.
With n up to 10^6 elements and q up to 10^6 operations, the worst case yields 10^6 × 10^6 = 10^12 operations — completely impractical.
The root cause is that we blindly attach one tree under another without considering which tree is taller. This means a single-node tree might become the parent of a much larger tree, creating an unnecessarily deep structure.
Key Insight: If we always attach the shorter tree under the taller one, the maximum tree height stays logarithmic. This is the idea behind Union by Rank — track each tree's approximate height and always merge the smaller tree into the larger one.
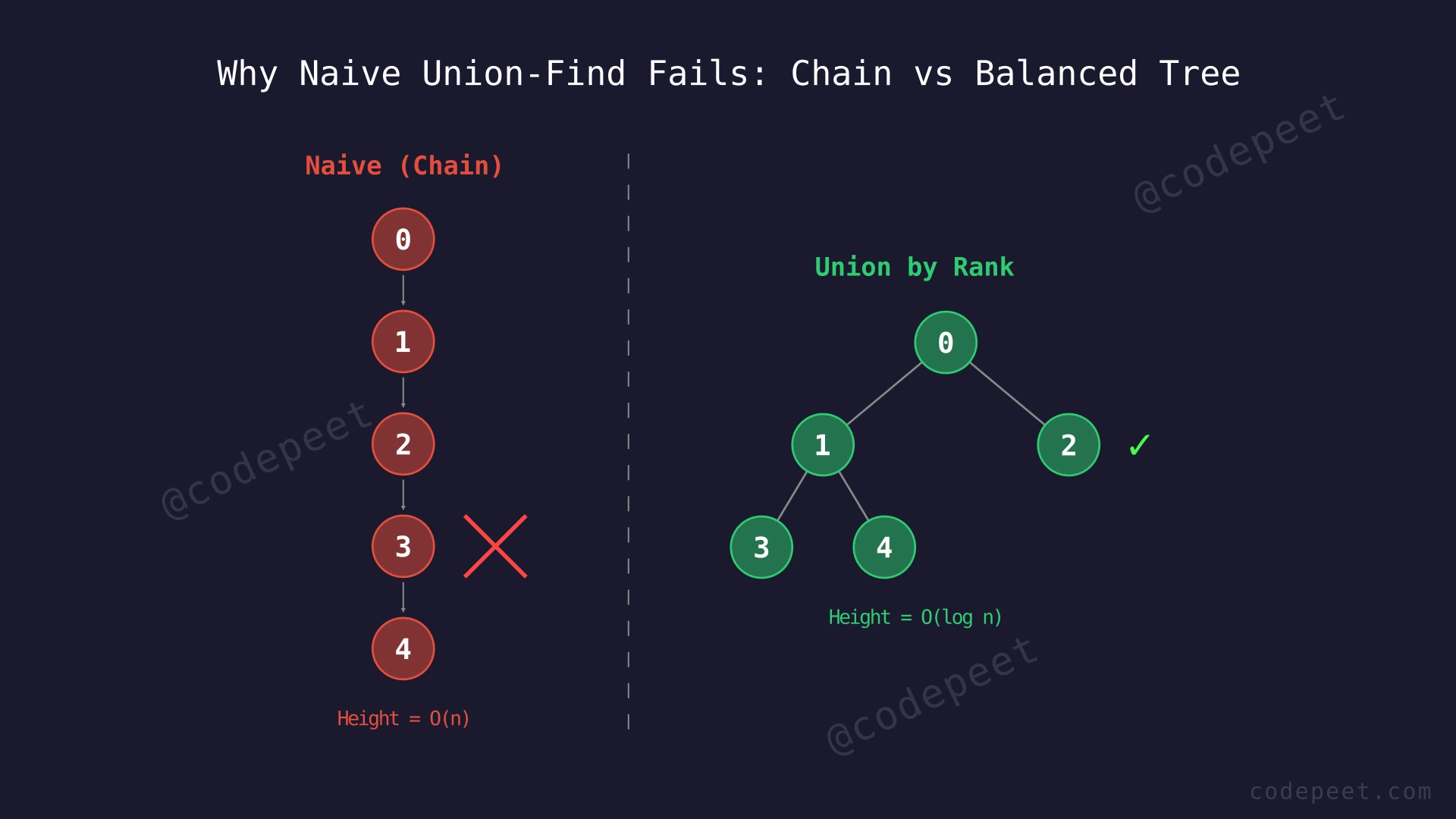
Better Approach - Union by Rank
Intuition
The problem with the naive approach is that we attach trees without considering their heights. Union by Rank fixes this by tracking the rank (approximate height) of each tree and always attaching the shorter tree under the taller one.
Imagine merging two companies. If Company A has a deep management hierarchy (rank 3) and Company B is flat (rank 1), it makes sense to put B's CEO under A's CEO rather than the other way around. Putting A under B would add A's entire deep hierarchy on top of B, creating an even deeper structure. But putting B under A barely affects the overall depth.
With this strategy, the maximum depth of any tree with n elements is at most log₂(n). Here is why: a tree of rank k must have at least 2^k nodes. Since we have n nodes total, the rank can be at most log₂(n).
This transforms the worst-case find from O(n) to O(log n) — a massive improvement for large inputs.
Step-by-Step Explanation
Let's trace n = 5 with operations: union(0,1), union(2,3), union(1,3), union(0,4), find(3).
Union by Rank rule: when ranks are equal, attach the second root under the first and increment the first's rank. When ranks differ, attach the lower-rank root under the higher-rank root.
Step 1: Initialize. parent = [0,1,2,3,4], rank = [0,0,0,0,0].
Step 2: union(0,1) — find(0)=0, find(1)=1. rank[0]=0 == rank[1]=0 → equal ranks. Attach 1 under 0, rank[0]++.
- parent = [0,0,2,3,4], rank = [1,0,0,0,0]
Step 3: union(2,3) — find(2)=2, find(3)=3. rank[2]=0 == rank[3]=0 → equal. Attach 3 under 2, rank[2]++.
- parent = [0,0,2,2,4], rank = [1,0,1,0,0]
Step 4: union(1,3) — find(1): parent[1]=0, root=0. find(3): parent[3]=2, root=2. rank[0]=1 == rank[2]=1 → equal. Attach 2 under 0, rank[0]++.
- parent = [0,0,0,2,4], rank = [2,0,1,0,0]
Step 5: union(0,4) — find(0)=0, find(4)=4. rank[0]=2 > rank[4]=0 → attach 4 under 0.
- parent = [0,0,0,2,0], rank = [2,0,1,0,0]
Step 6: find(3) — parent[3]=2 → parent[2]=0 → parent[0]=0, root=0. Only 2 hops! (vs 4 hops in naive)
Step 7: Return 0.
Union by Rank — Keeping Trees Balanced — Watch how tracking rank and always attaching the shorter tree under the taller one prevents the degenerate chain formation.
Algorithm
- Initialize: Create parent array (parent[i] = i) and rank array (rank[i] = 0) of size n.
- find(x):
- If parent[x] == x, return x.
- Otherwise, return find(parent[x]).
- union(x, y):
- Find root_x = find(x) and root_y = find(y).
- If root_x == root_y, do nothing (already in same set).
- If rank[root_x] < rank[root_y], set parent[root_x] = root_y.
- If rank[root_x] > rank[root_y], set parent[root_y] = root_x.
- If ranks are equal, set parent[root_y] = root_x and increment rank[root_x].
Code
#include <vector>
using namespace std;
class UnionFindByRank {
vector<int> parent, rank_;
public:
UnionFindByRank(int n) {
parent.resize(n);
rank_.resize(n, 0);
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] == x) {
return x;
}
return find(parent[x]);
}
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank_[rootX] < rank_[rootY]) {
parent[rootX] = rootY;
} else if (rank_[rootX] > rank_[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank_[rootX]++;
}
}
bool connected(int x, int y) {
return find(x) == find(y);
}
};class UnionFindByRank:
def __init__(self, n: int):
self.parent = list(range(n))
self.rank = [0] * n
def find(self, x: int) -> int:
if self.parent[x] == x:
return x
return self.find(self.parent[x])
def union(self, x: int, y: int) -> None:
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_y] = root_x
self.rank[root_x] += 1
def connected(self, x: int, y: int) -> bool:
return self.find(x) == self.find(y)class UnionFindByRank {
private int[] parent;
private int[] rank;
public UnionFindByRank(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
rank[i] = 0;
}
}
public int find(int x) {
if (parent[x] == x) {
return x;
}
return find(parent[x]);
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
public boolean connected(int x, int y) {
return find(x) == find(y);
}
}Complexity Analysis
Time Complexity: O(log n) per operation
By always attaching the smaller-rank tree under the larger-rank tree, the maximum tree depth is bounded by log₂(n). This is because a tree of rank k must contain at least 2^k nodes (provable by induction). Since we have n nodes, the rank cannot exceed log₂(n). Every find traverses at most log₂(n) edges, and union calls find twice.
For q operations on n elements: O(q × log n).
Space Complexity: O(n)
We store two arrays of size n: parent and rank. Total space is 2n = O(n).
Why This Approach Is Not Efficient
Union by Rank brings the worst-case find from O(n) down to O(log n), which is a huge improvement. For n = 10^6, the maximum depth is about 20 instead of 10^6.
However, O(log n) per operation is still not optimal. With q = 10^6 operations, that is 10^6 × 20 = 2 × 10^7 operations. While practical, we can do even better.
Notice that during a find operation, we traverse a path from the query node all the way up to the root. After finding the root, we simply return it — but all the intermediate nodes on that path still point to their original parents. The next time we call find on any of those intermediate nodes, we repeat the same traversal.
Key Insight: What if, during find, we rewire every visited node to point directly to the root? This is called Path Compression. After one find traversal, every node on the path is just one hop away from the root. Future finds on those nodes become nearly instant. When combined with Union by Rank, this achieves an amortized time complexity of O(α(n)) per operation, where α is the inverse Ackermann function — a function that grows so slowly it never exceeds 4 for any practical input size.
Optimal Approach - Union by Rank with Path Compression
Intuition
Path Compression is a brilliantly simple optimization: whenever we call find(x), we follow the chain of parents to the root (just like before), but on the way back, we make every node we visited point directly to the root.
Imagine a chain of command in the military: Private → Sergeant → Captain → General. When the Private needs to ask the General a question, they go through the entire chain. But with path compression, after the first question, the Private remembers the General's direct phone number. Next time, they call directly — no intermediaries needed.
In code, this is achieved with a single elegant change to the find function:
parent[x] = find(parent[x]) // instead of just: return find(parent[x])
This recursive call not only finds the root, but also sets parent[x] to point directly to that root. The same happens for every node along the path during the recursive unwinding.
When combined with Union by Rank:
- Union by Rank keeps trees short (logarithmic height)
- Path Compression flattens whatever height remains during finds
- Together, the amortized cost per operation is O(α(n)), where α(n) is the inverse Ackermann function
- For all practical input sizes (n < 10^600), α(n) ≤ 4
- This means each operation takes effectively constant time
Step-by-Step Explanation
Let's trace n = 5 with operations: union(0,1), union(2,3), union(1,3), union(0,4), find(3), find(3).
We use Union by Rank for merging and Path Compression during find.
Step 1: Initialize. parent = [0,1,2,3,4], rank = [0,0,0,0,0].
Step 2: union(0,1) — find(0)=0, find(1)=1. Equal ranks → parent[1]=0, rank[0]=1.
- parent = [0,0,2,3,4], rank = [1,0,0,0,0]
Step 3: union(2,3) — find(2)=2, find(3)=3. Equal ranks → parent[3]=2, rank[2]=1.
- parent = [0,0,2,2,4], rank = [1,0,1,0,0]
Step 4: union(1,3) — find(1): 1→0 (root). find(3): 3→2 (root). Equal ranks → parent[2]=0, rank[0]=2.
- parent = [0,0,0,2,4], rank = [2,0,1,0,0]
- (Path compression had no extra effect here because the paths were short)
Step 5: union(0,4) — find(0)=0, find(4)=4. rank[0]=2 > rank[4]=0 → parent[4]=0.
- parent = [0,0,0,2,0], rank = [2,0,1,0,0]
Step 6: find(3) WITH PATH COMPRESSION:
- Start at 3. parent[3] = 2, not root.
- Move to 2. parent[2] = 0, not root.
- Move to 0. parent[0] = 0, this IS the root!
- Now compress: set parent[3] = 0, parent[2] = 0 (already 0).
- parent = [0,0,0,0,0] ← element 3 now points directly to root!
Step 7: find(3) AGAIN (after compression):
- Start at 3. parent[3] = 0. parent[0] = 0, root found!
- Only 1 hop! Path compression made future lookups nearly instant.
Union by Rank + Path Compression — Near-Constant Time — Watch how path compression rewires nodes directly to the root during find operations, making future queries nearly instant.
Algorithm
- Initialize: Create parent array (parent[i] = i) and rank array (rank[i] = 0) of size n.
- find(x) with Path Compression:
- If parent[x] == x, return x (root found).
- Otherwise, set parent[x] = find(parent[x]) and return parent[x].
- This single line flattens the entire path: every node on the path from x to root ends up pointing directly to root.
- union(x, y) with Union by Rank:
- Find root_x = find(x) and root_y = find(y).
- If root_x == root_y, do nothing.
- If rank[root_x] < rank[root_y], set parent[root_x] = root_y.
- If rank[root_x] > rank[root_y], set parent[root_y] = root_x.
- If ranks are equal, set parent[root_y] = root_x and increment rank[root_x].
Code
#include <vector>
using namespace std;
class UnionFind {
vector<int> parent, rank_;
public:
UnionFind(int n) {
parent.resize(n);
rank_.resize(n, 0);
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
// Find with path compression
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
// Union by rank
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank_[rootX] < rank_[rootY]) {
parent[rootX] = rootY;
} else if (rank_[rootX] > rank_[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank_[rootX]++;
}
}
bool connected(int x, int y) {
return find(x) == find(y);
}
};class UnionFind:
def __init__(self, n: int):
self.parent = list(range(n))
self.rank = [0] * n
def find(self, x: int) -> int:
# Path compression: make every node on
# the path point directly to the root
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x: int, y: int) -> None:
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
# Union by rank: attach shorter tree
# under taller tree
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_y] = root_x
self.rank[root_x] += 1
def connected(self, x: int, y: int) -> bool:
return self.find(x) == self.find(y)class UnionFind {
private int[] parent;
private int[] rank;
public UnionFind(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
rank[i] = 0;
}
}
// Find with path compression
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
// Union by rank
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
public boolean connected(int x, int y) {
return find(x) == find(y);
}
}Complexity Analysis
Time Complexity: O(α(n)) amortized per operation
When both Union by Rank and Path Compression are used together, the amortized time per operation is O(α(n)), where α is the inverse Ackermann function.
The inverse Ackermann function grows incredibly slowly — so slowly that for all conceivable practical input sizes (n < 10^600), α(n) never exceeds 4. This means each union or find operation costs at most about 4 steps amortized, which is effectively constant time.
The mathematical proof (by Tarjan, 1975) involves analyzing how path compression progressively flattens trees and how union by rank bounds the number of rank increases. The key insight is that path compression causes a cascading optimization: each find not only answers the current query but also speeds up all future queries involving the same nodes.
For q operations on n elements: O(q × α(n)) ≈ O(q) for practical purposes.
Space Complexity: O(n)
We store two arrays of size n: parent and rank. The path compression modifies the parent array in-place without requiring additional memory.