Non-overlapping Intervals
Description
Given an array of intervals where intervals[i] = [start_i, end_i], return the minimum number of intervals you need to remove so that the remaining intervals do not overlap each other.
Two intervals are considered non-overlapping if they only touch at a single point. For example, [1, 2] and [2, 3] are non-overlapping because they share only the boundary point 2.
Examples
Example 1
Input: intervals = [[1,2],[2,3],[3,4],[1,3]]
Output: 1
Explanation: Removing [1,3] leaves [[1,2],[2,3],[3,4]], which are all non-overlapping. The interval [1,3] overlaps with both [1,2] (they share the range [1,2]) and [2,3] (they share the range [2,3]). Removing just this one interval resolves all conflicts.
Example 2
Input: intervals = [[1,2],[1,2],[1,2]]
Output: 2
Explanation: All three intervals are identical and therefore overlap with each other. We can keep at most one of them, so we must remove two. Any single [1,2] is a valid non-overlapping set.
Example 3
Input: intervals = [[1,2],[2,3]]
Output: 0
Explanation: [1,2] ends at 2 and [2,3] starts at 2. Since they only touch at a single point, they are already non-overlapping. No removals needed.
Constraints
- 1 ≤ intervals.length ≤ 10^5
- intervals[i].length == 2
- -5 × 10^4 ≤ start_i < end_i ≤ 5 × 10^4
Editorial
Brute Force
Intuition
The most straightforward way to think about this problem is: for every interval, we have two choices — keep it or remove it. If we keep it, it must not overlap with the previously kept interval. If we remove it, we move on to the next one.
Imagine you are a conference organizer scheduling talks in a single room. You have a list of proposed time slots, and some of them conflict. You need to figure out the minimum number of talks to cancel so that no two remaining talks overlap. The brute force approach is to try every possible combination of cancellations and find the smallest set that resolves all conflicts.
After sorting the intervals by start time, we use recursion: at each interval, we either include it (if it does not overlap with the last included interval) or skip it (counting it as removed). We explore both choices and return whichever leads to fewer total removals.
Step-by-Step Explanation
Let's trace through with intervals = [[1,2],[2,3],[3,4],[1,3]]:
Step 1: Sort intervals by start time: [[1,2],[1,3],[2,3],[3,4]].
Step 2: Start with the first overlap: [1,2] and [1,3] both start at 1. Since end([1,2])=2 > start([1,3])=1, they overlap. We must choose which to remove.
Step 3: Path 1 — Remove [1,3], keep [1,2]. We've removed 1 interval so far. Continue scanning with last kept interval = [1,2].
Step 4: Check [1,2] vs [2,3]: end([1,2])=2, start([2,3])=2. Since 2 ≤ 2 (touching is allowed), no overlap. Keep [2,3].
Step 5: Check [2,3] vs [3,4]: end=3, start=3. Touch only — no overlap. Keep [3,4]. Path 1 total removals: 1.
Step 6: Backtrack. Path 2 — Remove [1,2], keep [1,3]. We've removed 1 interval so far. Continue with last kept = [1,3].
Step 7: Check [1,3] vs [2,3]: end([1,3])=3 > start([2,3])=2. Overlap! Must choose again.
Step 8: In Path 2, we must remove either [1,3] or [2,3]. Either way leads to at least 2 total removals — worse than Path 1.
Step 9: Compare all explored paths: Path 1 removes 1, Path 2 removes at least 2.
Step 10: Minimum removals = 1. The answer is 1.
Brute Force — Exploring All Removal Paths — Watch how the brute force explores two different removal paths for the first overlap, and compares their total removal counts to find the minimum.
Algorithm
- Sort intervals by start time
- Define a recursive function
solve(index, lastEnd)that returns the minimum removals from index onward:- If
index == n, return 0 (no more intervals to process) - Option 1 (Remove): Skip current interval. Result = 1 + solve(index+1, lastEnd)
- Option 2 (Keep): If
intervals[index][0] >= lastEnd(no overlap), result = solve(index+1, intervals[index][1]) - Return the minimum of both options
- If
- Call
solve(0, -infinity)and return the result
Code
#include <vector>
#include <algorithm>
#include <climits>
using namespace std;
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(), intervals.end());
return solve(intervals, 0, INT_MIN);
}
int solve(vector<vector<int>>& intervals, int index, int lastEnd) {
if (index == (int)intervals.size()) return 0;
// Option 1: Remove current interval
int removeIt = 1 + solve(intervals, index + 1, lastEnd);
// Option 2: Keep current interval (if no overlap)
int keepIt = INT_MAX;
if (intervals[index][0] >= lastEnd) {
keepIt = solve(intervals, index + 1, intervals[index][1]);
}
return min(removeIt, keepIt);
}
};class Solution:
def eraseOverlapIntervals(self, intervals: list[list[int]]) -> int:
intervals.sort()
def solve(index, last_end):
if index == len(intervals):
return 0
# Option 1: Remove current interval
remove_it = 1 + solve(index + 1, last_end)
# Option 2: Keep current interval (if no overlap)
keep_it = float('inf')
if intervals[index][0] >= last_end:
keep_it = solve(index + 1, intervals[index][1])
return min(remove_it, keep_it)
return solve(0, float('-inf'))import java.util.Arrays;
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
Arrays.sort(intervals, (a, b) -> Integer.compare(a[0], b[0]));
return solve(intervals, 0, Integer.MIN_VALUE);
}
private int solve(int[][] intervals, int index, int lastEnd) {
if (index == intervals.length) return 0;
// Option 1: Remove current interval
int removeIt = 1 + solve(intervals, index + 1, lastEnd);
// Option 2: Keep current interval (if no overlap)
int keepIt = Integer.MAX_VALUE;
if (intervals[index][0] >= lastEnd) {
keepIt = solve(intervals, index + 1, intervals[index][1]);
}
return Math.min(removeIt, keepIt);
}
}Complexity Analysis
Time Complexity: O(2^n) where n is the number of intervals
At each interval, we make two recursive choices (keep or remove). This creates a binary decision tree of depth n, giving up to 2^n nodes to explore. The sorting step is O(n log n), which is negligible compared to the exponential recursion.
Space Complexity: O(n)
The recursion stack can be at most n levels deep (one level per interval). Each stack frame uses O(1) space. The sorted array is modified in place.
Why This Approach Is Not Efficient
The brute force explores up to 2^n possible combinations of keep/remove decisions. With n up to 100,000, this is astronomically large — even 2^50 is over a quadrillion, far beyond any time limit.
The problem exhibits optimal substructure: the best decision for intervals i through n depends only on which interval was last kept (specifically, its end time). This means there are at most n × (n+1) unique states (index × possible lastEnd values), not 2^n. Many branches of the recursion tree solve the same subproblem with the same parameters.
This observation leads to two improvements: (1) memoizing the recursion to avoid redundant computation, or (2) reformulating as a bottom-up DP that finds the longest non-overlapping subsequence.
Better Approach - Dynamic Programming
Intuition
Instead of thinking about which intervals to remove, let us flip the question: what is the maximum number of non-overlapping intervals we can keep? The answer to the original problem is then simply total intervals - max kept.
This reframing turns the problem into finding the Longest Non-overlapping Subsequence — similar to the classic Longest Increasing Subsequence (LIS) problem.
After sorting intervals by start time, define dp[i] as the maximum number of non-overlapping intervals in a chain that ends with interval i. For each interval i, we look back at all previous intervals j and check if j can precede i without overlap (meaning end_j ≤ start_i). If so, we can extend j's chain by one.
Think of it like building the longest possible schedule: for each time slot, check all earlier slots that finish before this one starts, and pick the longest chain to extend.
Step-by-Step Explanation
Let's trace with intervals = [[1,2],[2,3],[3,4],[1,3]]:
Step 1: Sort by start time: [[1,2],[1,3],[2,3],[3,4]]. Initialize dp = [1, 1, 1, 1] (each interval alone is a valid chain of length 1).
Step 2: Compute dp[1] for [1,3]. Check j=0: [1,2] ends at 2, [1,3] starts at 1. Since 2 > 1, they overlap. Cannot chain. dp[1] = 1.
Step 3: Compute dp[2] for [2,3]. Check j=0: [1,2] ends at 2, [2,3] starts at 2. Since 2 ≤ 2, compatible! dp[2] = max(1, dp[0]+1) = 2.
Step 4: Still computing dp[2]. Check j=1: [1,3] ends at 3, [2,3] starts at 2. Since 3 > 2, overlap. Skip. dp[2] = 2.
Step 5: Compute dp[3] for [3,4]. Check j=0: [1,2] end=2 ≤ start=3. Compatible! dp[3] = max(1, dp[0]+1) = 2.
Step 6: Still dp[3]. Check j=1: [1,3] end=3 ≤ start=3. Compatible! dp[3] = max(2, dp[1]+1) = max(2, 2) = 2. No improvement.
Step 7: Still dp[3]. Check j=2: [2,3] end=3 ≤ start=3. Compatible! dp[3] = max(2, dp[2]+1) = max(2, 3) = 3. Best chain: [1,2] → [2,3] → [3,4].
Step 8: dp[3] = 3. Maximum chain length is max(dp) = 3.
Step 9: Answer = total intervals - max chain = 4 - 3 = 1.
DP Table — Longest Non-overlapping Subsequence — Watch how we build the dp array by checking all previous intervals for compatibility, similar to the Longest Increasing Subsequence approach.
Algorithm
- Sort intervals by start time
- Create array
dpof size n, initialized to 1 (each interval alone is a chain of length 1) - For each interval
ifrom 1 to n-1:- For each previous interval
jfrom 0 to i-1:- If
intervals[j][1] <= intervals[i][0](no overlap), updatedp[i] = max(dp[i], dp[j] + 1)
- If
- For each previous interval
- Find
maxKept = max(dp) - Return
n - maxKept
Code
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(), intervals.end());
int n = intervals.size();
vector<int> dp(n, 1);
for (int i = 1; i < n; i++) {
for (int j = 0; j < i; j++) {
if (intervals[j][1] <= intervals[i][0]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
}
return n - *max_element(dp.begin(), dp.end());
}
};class Solution:
def eraseOverlapIntervals(self, intervals: list[list[int]]) -> int:
intervals.sort()
n = len(intervals)
dp = [1] * n
for i in range(1, n):
for j in range(i):
if intervals[j][1] <= intervals[i][0]:
dp[i] = max(dp[i], dp[j] + 1)
return n - max(dp)import java.util.Arrays;
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
Arrays.sort(intervals, (a, b) -> Integer.compare(a[0], b[0]));
int n = intervals.length;
int[] dp = new int[n];
Arrays.fill(dp, 1);
for (int i = 1; i < n; i++) {
for (int j = 0; j < i; j++) {
if (intervals[j][1] <= intervals[i][0]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
}
int maxKept = 0;
for (int val : dp) {
maxKept = Math.max(maxKept, val);
}
return n - maxKept;
}
}Complexity Analysis
Time Complexity: O(n²)
Sorting takes O(n log n). The nested loops iterate over all pairs (i, j) where j < i, giving n×(n-1)/2 comparisons = O(n²). The O(n²) term dominates.
Space Complexity: O(n)
We use a dp array of size n. The sorting may use O(log n) stack space depending on implementation. Total: O(n).
Why This Approach Is Not Efficient
The DP approach runs in O(n²) time due to the nested loop that checks all previous intervals for each new interval. With n up to 100,000, this means up to 5 × 10^9 operations — well beyond typical time limits of 10^8 operations per second.
The key inefficiency is the inner loop: for each interval i, we scan ALL previous intervals j to find compatible predecessors. But we do not need to check every one — we only care about the best predecessor whose end time is at or before our start time.
A crucial insight from the Activity Selection Problem in greedy algorithms tells us: if we process intervals sorted by end time, we can make a single-pass greedy decision without looking backward at all. The interval that ends earliest always gives us the best chance of fitting more intervals afterward.
Optimal Approach - Greedy (Sort by End Time)
Intuition
The optimal solution uses a greedy strategy rooted in the classic Activity Selection Problem: sort all intervals by their end time, then greedily keep each interval that does not overlap with the last one kept.
Why does sorting by end time work? Consider two overlapping intervals. One ends earlier, the other ends later. Keeping the earlier-ending interval can never be worse than keeping the later-ending one, because the earlier ending time leaves strictly more room for future intervals. A later-ending interval blocks out a larger chunk of the timeline.
Think of parking cars in a single lane. If two cars want overlapping spots, you should always keep the one that takes less length toward the right end — it leaves more space for cars arriving later.
The algorithm is beautifully simple: sort by end time, maintain the end time of the last kept interval, and for each new interval, either keep it (if it starts at or after the last end) or discard it (if it overlaps). Count the discards.
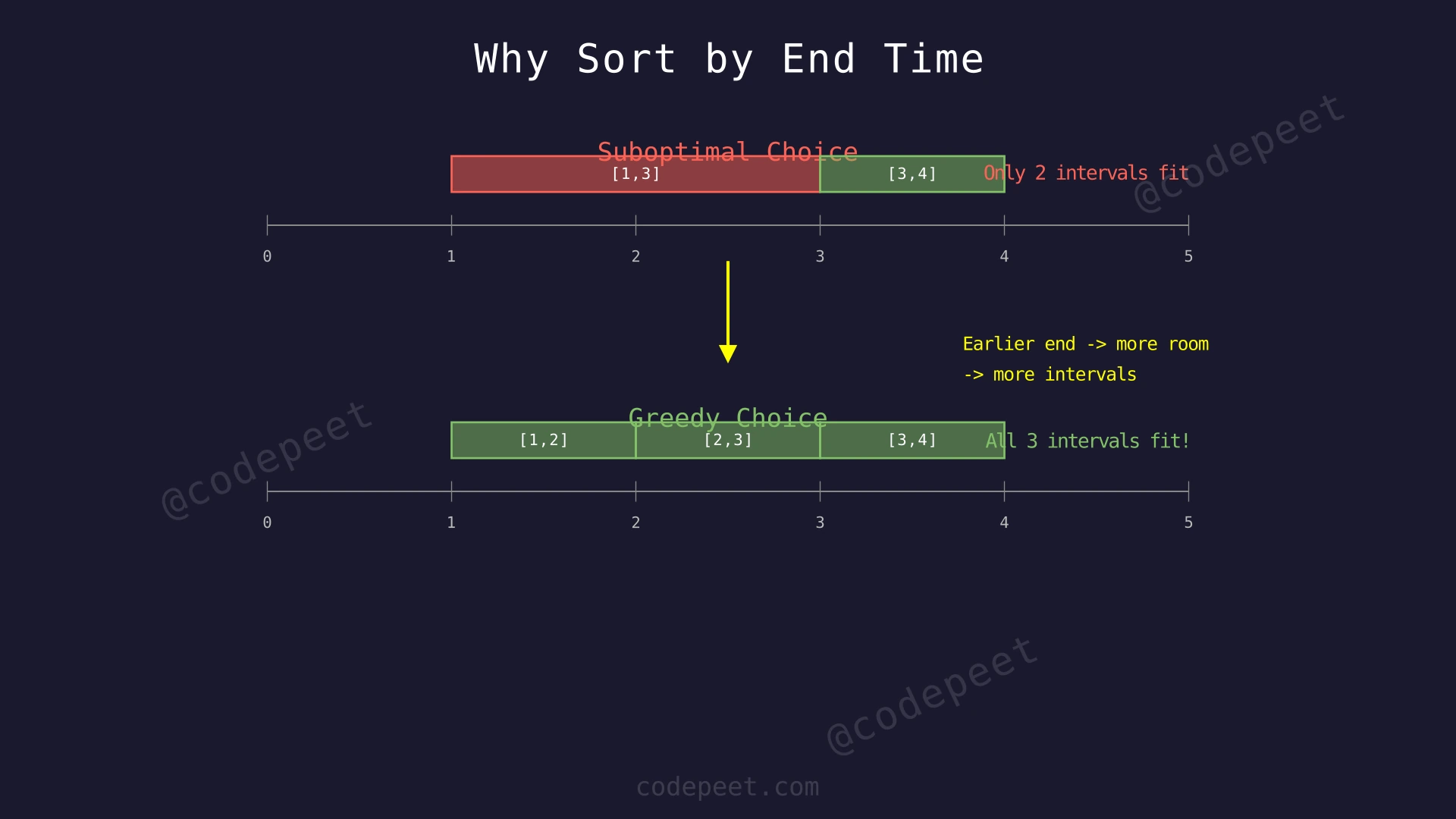
Step-by-Step Explanation
Let's trace with intervals = [[1,2],[2,3],[3,4],[1,3]]:
Step 1: Sort intervals by end time: [[1,2],[2,3],[1,3],[3,4]]. Initialize lastEnd = -∞, removals = 0.
Step 2: Process [1,2]. Start=1 ≥ lastEnd=-∞. No overlap. KEEP it. Update lastEnd = 2.
Step 3: Process [2,3]. Start=2 ≥ lastEnd=2. Touching only — no overlap. KEEP it. Update lastEnd = 3.
Step 4: Process [1,3]. Start=1 < lastEnd=3. OVERLAP! This interval starts before the last kept interval ends.
Step 5: REMOVE [1,3]. Increment removals to 1. The greedy keeps the earlier-ending intervals already chosen — they leave more room.
Step 6: Process [3,4]. Start=3 ≥ lastEnd=3. Touching only — no overlap. KEEP it. Update lastEnd = 4.
Step 7: All intervals processed. Total removals = 1. Kept set: [1,2],[2,3],[3,4].
Greedy Selection — Sort by End Time, Keep Non-overlapping — Watch how sorting by end time and greedily keeping non-overlapping intervals finds the optimal solution in a single pass.
Algorithm
- Sort intervals by end time (ascending)
- Initialize
lastEnd = -infinityandremovals = 0 - For each interval
[start, end]:- If
start >= lastEnd: no overlap → keep it, updatelastEnd = end - Else: overlap → remove it, increment
removals
- If
- Return
removals
Code
#include <vector>
#include <algorithm>
#include <climits>
using namespace std;
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(), intervals.end(), [](const auto& a, const auto& b) {
return a[1] < b[1];
});
int count = 0;
int lastEnd = INT_MIN;
for (const auto& interval : intervals) {
if (interval[0] >= lastEnd) {
lastEnd = interval[1];
} else {
count++;
}
}
return count;
}
};class Solution:
def eraseOverlapIntervals(self, intervals: list[list[int]]) -> int:
intervals.sort(key=lambda x: x[1])
count = 0
last_end = float('-inf')
for start, end in intervals:
if start >= last_end:
last_end = end
else:
count += 1
return countimport java.util.Arrays;
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
Arrays.sort(intervals, (a, b) -> Integer.compare(a[1], b[1]));
int count = 0;
int lastEnd = Integer.MIN_VALUE;
for (int[] interval : intervals) {
if (interval[0] >= lastEnd) {
lastEnd = interval[1];
} else {
count++;
}
}
return count;
}
}Complexity Analysis
Time Complexity: O(n log n)
Sorting the intervals by end time takes O(n log n). The single pass through the sorted array takes O(n). Total: O(n log n), dominated by sorting. For n = 100,000 this is roughly 1.7 million operations — extremely fast.
Space Complexity: O(1) auxiliary space (or O(log n) for sorting)
We only use two variables (count and lastEnd) regardless of input size. The sorting may use O(log n) stack space depending on implementation. No additional data structures needed.