Valid Parenthesis String
Description
Given a string s containing only three types of characters: '(', ')', and '*', determine whether the string is valid.
A string is considered valid if all of the following conditions are met:
- Every left parenthesis
'('has a matching right parenthesis')'. - Every right parenthesis
')'has a matching left parenthesis'('. - Each left parenthesis
'('appears before its corresponding right parenthesis')'. - The
'*'character is flexible — it can act as a single left parenthesis'(', a single right parenthesis')', or an empty string"".
Return true if the string can be made valid under some interpretation of the '*' characters, or false otherwise.
Examples
Example 1
Input: s = "()"
Output: true
Explanation: The string has one opening and one closing parenthesis in the correct order. No '*' characters are present, and the string is already balanced.
Example 2
Input: s = "(*)"
Output: true
Explanation: The '*' at index 1 can be treated as an empty string, making the effective string "()", which is valid. Alternatively, '*' could be '(' giving "(()" — wait, that has 2 open and 1 close. Actually the simplest interpretation is '*' as empty: "()" is valid.
Example 3
Input: s = "(*))"
Output: true
Explanation: If we treat '*' as '(', the string becomes "(())", which is perfectly balanced: the first '(' matches the last ')', and the second '(' (from '*') matches the third ')'. This is the only interpretation that works — treating '*' as ')' or empty both leave too many closing parentheses.
Constraints
- 1 ≤ s.length ≤ 100
s[i]is'(',')', or'*'
Editorial
Brute Force (Backtracking)
Intuition
The most direct way to solve this problem is to try every possible interpretation of each '*' character. Since each '*' can be one of three things — '(', ')', or an empty string — we can use recursion to explore all combinations.
Think of it like standing at a fork in the road every time you see a '*'. You pick one path (say, treat '*' as '('), walk as far as you can, and if you hit a dead end, you backtrack and try the next path. The moment you find any path that leads to a valid string, you can stop and declare success.
To check validity as we go, we maintain a counter called open_count that tracks unmatched left parentheses. Every '(' increments it, every ')' decrements it. If it ever goes negative, we have more closing parens than opening ones — that path is invalid. If we reach the end and the counter is exactly zero, every opener was matched.
Step-by-Step Explanation
Let's trace the backtracking on s = "(*))". There is one '*' at index 1, giving us 3 branches to explore.
Step 1: Start at index 0 with open_count = 0. Character is '(', so increase open_count to 1. Move to index 1.
Step 2: At index 1, character is '*'. Try treating it as ')': open_count = 1 - 1 = 0. Move to index 2.
Step 3: At index 2, character is ')'. open_count = 0 - 1 = -1. Negative! This means more closing than opening parens. This path is INVALID. Backtrack to index 1.
Step 4: Try treating '*' as empty string: open_count stays at 1. Move to index 2.
Step 5: At index 2, character is ')'. open_count = 1 - 1 = 0. Move to index 3.
Step 6: At index 3, character is ')'. open_count = 0 - 1 = -1. Negative again! INVALID. Backtrack to index 1.
Step 7: Last option: treat '*' as '('. open_count = 1 + 1 = 2. Move to index 2.
Step 8: At index 2, character is ')'. open_count = 2 - 1 = 1. Still positive, continue to index 3.
Step 9: At index 3, character is ')'. open_count = 1 - 1 = 0. Reached the end with open_count = 0!
Step 10: Found a valid interpretation! Treating '*' as '(' gives "(())" which is balanced. Return true.
Backtracking — Exploring All Interpretations of '*' — Watch the recursive exploration of three possible interpretations of '*' in '(*))'. Two branches fail (pruned), and one succeeds.
Algorithm
- Define a recursive function
solve(index, open_count)that returns whether the substring fromindexonwards can be balanced givenopen_countunmatched opening parens so far. - Base cases:
- If
open_count < 0, return false (too many closing parens). - If
index == n, returnopen_count == 0(all characters processed, check balance).
- If
- Recursive cases:
- If
s[index] == '(': recurse withopen_count + 1. - If
s[index] == ')': recurse withopen_count - 1. - If
s[index] == '*': try all three options (as'(', as')', as empty) and return true if ANY succeeds.
- If
- Call
solve(0, 0)from the main function.
Code
class Solution {
public:
bool checkValidString(string s) {
return solve(s, 0, 0);
}
private:
bool solve(string& s, int index, int openCount) {
if (openCount < 0) return false;
if (index == (int)s.size()) return openCount == 0;
if (s[index] == '(') {
return solve(s, index + 1, openCount + 1);
} else if (s[index] == ')') {
return solve(s, index + 1, openCount - 1);
} else {
return solve(s, index + 1, openCount + 1) ||
solve(s, index + 1, openCount - 1) ||
solve(s, index + 1, openCount);
}
}
};class Solution:
def checkValidString(self, s: str) -> bool:
def solve(index, open_count):
if open_count < 0:
return False
if index == len(s):
return open_count == 0
if s[index] == '(':
return solve(index + 1, open_count + 1)
elif s[index] == ')':
return solve(index + 1, open_count - 1)
else:
return (solve(index + 1, open_count + 1) or
solve(index + 1, open_count - 1) or
solve(index + 1, open_count))
return solve(0, 0)class Solution {
public boolean checkValidString(String s) {
return solve(s, 0, 0);
}
private boolean solve(String s, int index, int openCount) {
if (openCount < 0) return false;
if (index == s.length()) return openCount == 0;
char c = s.charAt(index);
if (c == '(') {
return solve(s, index + 1, openCount + 1);
} else if (c == ')') {
return solve(s, index + 1, openCount - 1);
} else {
return solve(s, index + 1, openCount + 1) ||
solve(s, index + 1, openCount - 1) ||
solve(s, index + 1, openCount);
}
}
}Complexity Analysis
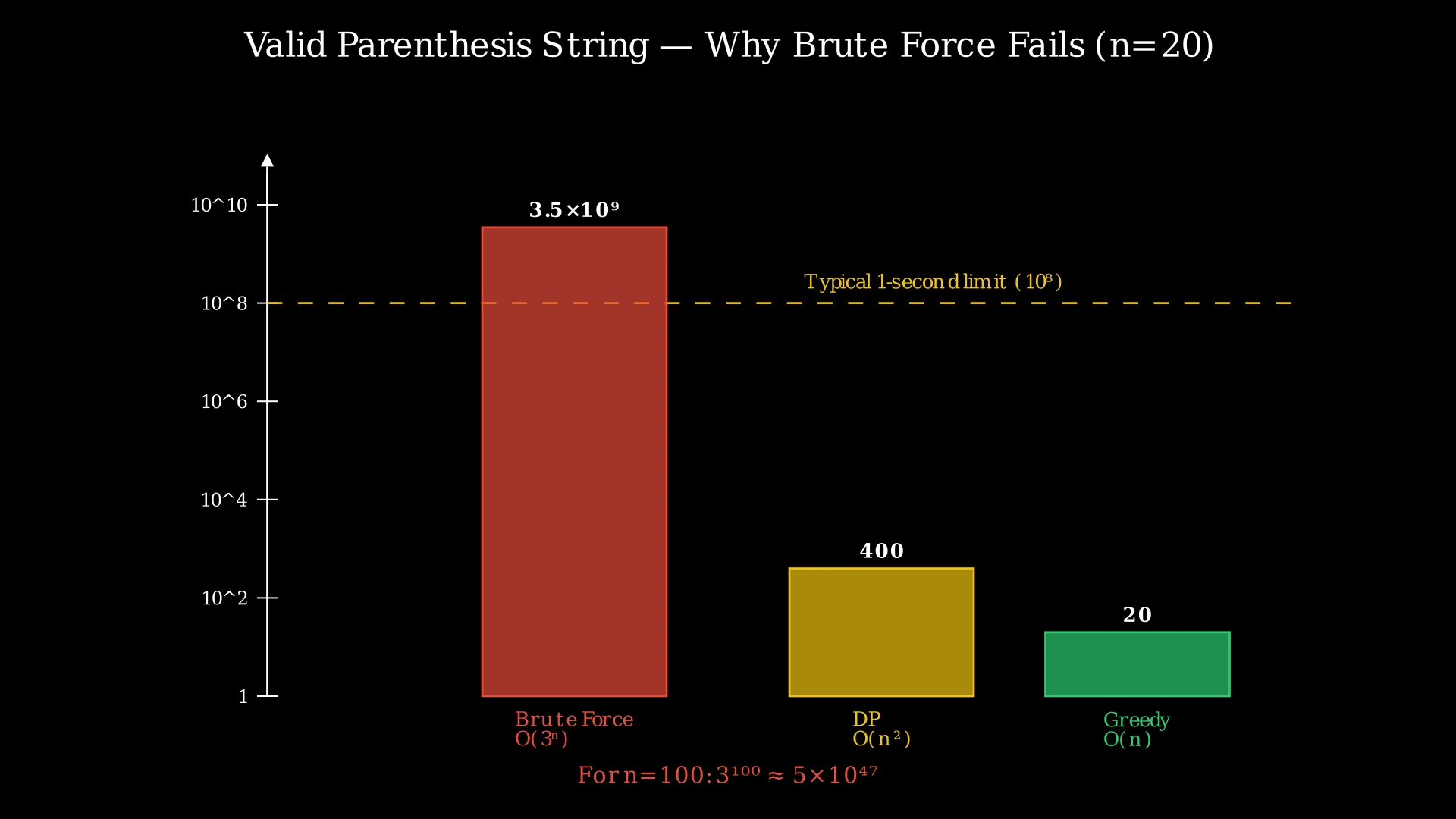
Time Complexity: O(3^n)
In the worst case, every character is '*', giving us 3 choices at each of the n positions. The recursion tree has up to 3^n leaf nodes. For n = 100, this is approximately 5 × 10^47 — astronomically large and completely infeasible.
Space Complexity: O(n)
The recursion stack can go at most n levels deep (one level per character in the string). Each stack frame uses constant space, so total space is O(n).
Why This Approach Is Not Efficient
The brute force explores up to 3^n combinations, where n is the string length. Even for moderate inputs like n = 30, we'd need 3^30 ≈ 2 × 10^14 operations — far beyond what any computer can handle in a reasonable time.
The fundamental waste: many branches reach the same state. For example, if the string is "***...", treating the first '*' as '(' and the second as ')' gives open_count = 0 at index 2. But treating both as empty ALSO gives open_count = 0 at index 2. Yet the brute force explores both paths independently, solving the same subproblem from scratch.
Key insight: The algorithm's state at any point is fully described by just two values: the current index and the current open_count. There are at most n × n distinct (index, open_count) pairs. If we record which pairs are reachable, we eliminate all redundant exploration — reducing the work from exponential to polynomial.
Dynamic Programming (Open Count Tracking)
Intuition
From the brute force analysis, we know the algorithm's state is determined by two things: which character we're currently processing (index) and how many unmatched opening parens we've accumulated (open_count). Instead of recursively exploring every branch, we can build a table that records all reachable (index, open_count) pairs.
Define dp[i][j] as: "Is it possible to process the first i characters and end up with exactly j unmatched opening parentheses?"
- Base case:
dp[0][0] = true— before reading any character, having 0 unmatched openers is the only valid starting state. - Transitions: For each character
s[i], look at all reachable states in rowiand propagate forward:'(':j → j+1(adds an unmatched opener)')':j → j-1(matches one opener), only ifj > 0'*':j → j+1,j → j-1, orj → j(all three options)
The answer is dp[n][0] — can we process all characters and end with zero unmatched openers?
Step-by-Step Explanation
Let's trace the DP on s = "(*))" (n = 4). We build a table where rows represent characters processed (0 to 4) and columns represent open_count (0 to 4). Each cell is True (1) or False (0).
Step 1: Initialize. dp[0][0] = True. Before processing anything, only open_count = 0 is reachable.
Step 2: Process s[0] = '('. The only reachable state is dp[0][0]. An opening paren takes j=0 to j=1. Set dp[1][1] = True.
Step 3: Process s[1] = '' (from dp[1][1] = True, j=1). Treat '' as ')': open_count goes from 1 to 0. Set dp[2][0] = True.
Step 4: Treat '*' as empty: open_count stays at 1. Set dp[2][1] = True.
Step 5: Treat '*' as '(': open_count goes from 1 to 2. Set dp[2][2] = True.
Step 6: Process s[2] = ')' (from dp[2][1] = True, j=1). Set dp[3][0] = True. Also from dp[2][2] = True: dp[3][1] = True.
Step 7: Process s[3] = ')' (from dp[3][1] = True, j=1). Set dp[4][0] = True.
Step 8: Check dp[4][0] = True. After processing all 4 characters, it IS possible to have 0 unmatched openers. The string is VALID!
DP Table — Tracking Reachable Open Counts — Watch the DP table fill row by row. Each True cell means that specific (characters_processed, open_count) state is reachable through some valid interpretation of the '*' characters.
Algorithm
- Create a 2D boolean table
dpof size(n+1) × (n+1), initialized to false. - Set
dp[0][0] = true(base case: 0 characters, 0 open parens). - For each character index
ifrom 0 to n-1:- For each possible open count
jfrom 0 to n:- If
dp[i][j]is false, skip. - If
s[i]is'('or'*': setdp[i+1][j+1] = true(treat as opener). - If
s[i]is')'or'*': ifj > 0, setdp[i+1][j-1] = true(treat as closer). - If
s[i]is'*': setdp[i+1][j] = true(treat as empty).
- If
- For each possible open count
- Return
dp[n][0].
Code
class Solution {
public:
bool checkValidString(string s) {
int n = s.size();
// dp[i][j] = can first i chars leave exactly j unmatched opens?
vector<vector<bool>> dp(n + 1, vector<bool>(n + 1, false));
dp[0][0] = true;
for (int i = 0; i < n; i++) {
for (int j = 0; j <= n; j++) {
if (!dp[i][j]) continue;
if (s[i] == '(' || s[i] == '*') {
dp[i + 1][j + 1] = true;
}
if ((s[i] == ')' || s[i] == '*') && j > 0) {
dp[i + 1][j - 1] = true;
}
if (s[i] == '*') {
dp[i + 1][j] = true;
}
}
}
return dp[n][0];
}
};class Solution:
def checkValidString(self, s: str) -> bool:
n = len(s)
# dp[i][j] = can first i chars leave exactly j unmatched opens?
dp = [[False] * (n + 1) for _ in range(n + 1)]
dp[0][0] = True
for i in range(n):
for j in range(n + 1):
if not dp[i][j]:
continue
if s[i] == '(' or s[i] == '*':
dp[i + 1][j + 1] = True
if (s[i] == ')' or s[i] == '*') and j > 0:
dp[i + 1][j - 1] = True
if s[i] == '*':
dp[i + 1][j] = True
return dp[n][0]class Solution {
public boolean checkValidString(String s) {
int n = s.length();
// dp[i][j] = can first i chars leave exactly j unmatched opens?
boolean[][] dp = new boolean[n + 1][n + 1];
dp[0][0] = true;
for (int i = 0; i < n; i++) {
for (int j = 0; j <= n; j++) {
if (!dp[i][j]) continue;
char c = s.charAt(i);
if (c == '(' || c == '*') {
dp[i + 1][j + 1] = true;
}
if ((c == ')' || c == '*') && j > 0) {
dp[i + 1][j - 1] = true;
}
if (c == '*') {
dp[i + 1][j] = true;
}
}
}
return dp[n][0];
}
}Complexity Analysis
Time Complexity: O(n²)
The outer loop runs n times (once per character). The inner loop runs up to n+1 times (for each possible open count). Each iteration does constant work. Total: n × n = O(n²). For n = 100, this is only 10,000 operations — blazingly fast compared to brute force.
Space Complexity: O(n²)
The 2D table has (n+1) × (n+1) entries. This can be optimized to O(n) by using a rolling array (only keeping the current and previous rows), since row i+1 depends only on row i.
Why This Approach Is Not Efficient
The DP approach is a massive improvement over brute force — O(n²) versus O(3^n). For n ≤ 100, it runs in microseconds. But can we do better?
Look at the DP table we just built. At each row, the True cells (reachable open counts) always form a contiguous range. In our example:
- After '(': reachable = {1} → range [1, 1]
- After '*': reachable = {0, 1, 2} → range [0, 2]
- After ')': reachable = {0, 1} → range [0, 1]
- After ')': reachable = {0} → range [0, 0]
This is not a coincidence — it's always true! When you process '(', the entire range shifts up by 1. When you process ')', it shifts down by 1. When you process '*', it expands by 1 in both directions. The set of reachable open counts never has "gaps."
Key insight: Instead of storing an entire row of n+1 booleans, we only need two numbers: the minimum (low) and maximum (high) of the reachable range. This reduces both time and space from O(n²) to O(n) and O(1), respectively.
Optimal Approach - Greedy (Min-Max Range)
Intuition
The DP showed that reachable open counts always form a contiguous range [low, high]. We can track this range directly with just two variables:
low: the minimum possible number of unmatched'('(assuming'*'s are used to close as many as possible).high: the maximum possible number of unmatched'('(assuming'*'s are used to open as many as possible).
For each character:
'(': bothlowandhighincrease by 1 (an opener always adds to the count).')': bothlowandhighdecrease by 1 (a closer always removes from the count).'*':lowdecreases by 1 (wildcard closes) andhighincreases by 1 (wildcard opens). The range expands.
Two critical checks after each character:
- If
high < 0: even with all'*'s acting as'(', we still have more)than(. Return false. - If
low < 0: clamp it to 0. A negative low would mean we "used" a'*'as)even though there were no(to match — we simply don't take that option.
At the end, if low == 0, then zero unmatched opens is within the achievable range — the string is valid.
Step-by-Step Explanation
Let's trace the greedy approach on s = "(*))". We track the range [low, high] of possible open paren counts.
Step 1: Initialize: low = 0, high = 0. Range = [0, 0].
Step 2: Process s[0] = '('. Both increase by 1. low = 1, high = 1. Range = [1, 1]. The only possibility is exactly 1 unmatched open paren.
Step 3: Process s[1] = '*'. The wildcard can be '(' (increases), ')' (decreases), or '' (no change). low = 1-1 = 0, high = 1+1 = 2. Range = [0, 2]. Three possibilities: 0, 1, or 2 unmatched opens.
Step 4: Process s[2] = ')'. Both decrease by 1. low = 0-1 = -1, high = 2-1 = 1. Clamp: low = max(-1, 0) = 0. Range = [0, 1]. Check: high = 1 ≥ 0, so it's still possible to continue.
Step 5: Process s[3] = ')'. Both decrease by 1. low = 0-1 = -1, high = 1-1 = 0. Clamp: low = max(-1, 0) = 0. Range = [0, 0]. Check: high = 0 ≥ 0, still valid.
Step 6: All characters processed. low = 0, meaning 0 unmatched opens IS achievable. Return true!
Greedy — Tracking Min-Max Open Count Range — Watch how two counters (low and high) track the range of possible unmatched open parentheses as we scan left to right. The range expands at '*' and contracts at ')' and '('.
Algorithm
- Initialize
low = 0andhigh = 0. - For each character
cin the string:- If
c == '(': increment bothlowandhighby 1. - If
c == ')': decrement bothlowandhighby 1. - If
c == '*': decrementlowby 1 and incrementhighby 1. - If
high < 0: return false (impossible to balance). - Clamp:
low = max(low, 0)(can't have negative open count).
- If
- Return
low == 0(zero unmatched opens is achievable).
Code
class Solution {
public:
bool checkValidString(string s) {
int low = 0, high = 0;
for (char c : s) {
if (c == '(') {
low++;
high++;
} else if (c == ')') {
low--;
high--;
} else {
low--; // * acts as ')'
high++; // * acts as '('
}
if (high < 0) return false;
low = max(low, 0);
}
return low == 0;
}
};class Solution:
def checkValidString(self, s: str) -> bool:
low = 0 # min possible unmatched '('
high = 0 # max possible unmatched '('
for char in s:
if char == '(':
low += 1
high += 1
elif char == ')':
low -= 1
high -= 1
else: # '*'
low -= 1 # treat as ')'
high += 1 # treat as '('
if high < 0:
return False
low = max(low, 0)
return low == 0class Solution {
public boolean checkValidString(String s) {
int low = 0, high = 0;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c == '(') {
low++;
high++;
} else if (c == ')') {
low--;
high--;
} else {
low--; // * acts as ')'
high++; // * acts as '('
}
if (high < 0) return false;
low = Math.max(low, 0);
}
return low == 0;
}
}Complexity Analysis
Time Complexity: O(n)
We make a single pass through the string, performing O(1) work per character (a few integer additions, comparisons, and a max operation). Total: n iterations × O(1) = O(n).
Space Complexity: O(1)
We use only two integer variables (low and high) regardless of input size. No arrays, hash maps, or recursion stacks — just constant extra memory.
This is optimal: we must read every character at least once (the validity of the string could depend on the last character), so O(n) time is a lower bound. And O(1) space is as good as it gets.