Copy List with Random Pointer
Description
You are given a linked list of length n where each node contains an additional random pointer. This random pointer can point to any node in the list, or it can be null.
Your task is to construct a deep copy of this list. A deep copy means you must create n brand new nodes. Each new node should have the same value as its corresponding original node. Both the next and random pointers of the new nodes must point to new nodes in the copied list such that the structure of the copied list is identical to the original. No pointer in the new list should reference any node in the original list.
The linked list is represented in the input as a list of n pairs [val, random_index], where val is the node's integer value and random_index is the index (0-based) of the node that the random pointer points to, or null if the random pointer does not point to any node.
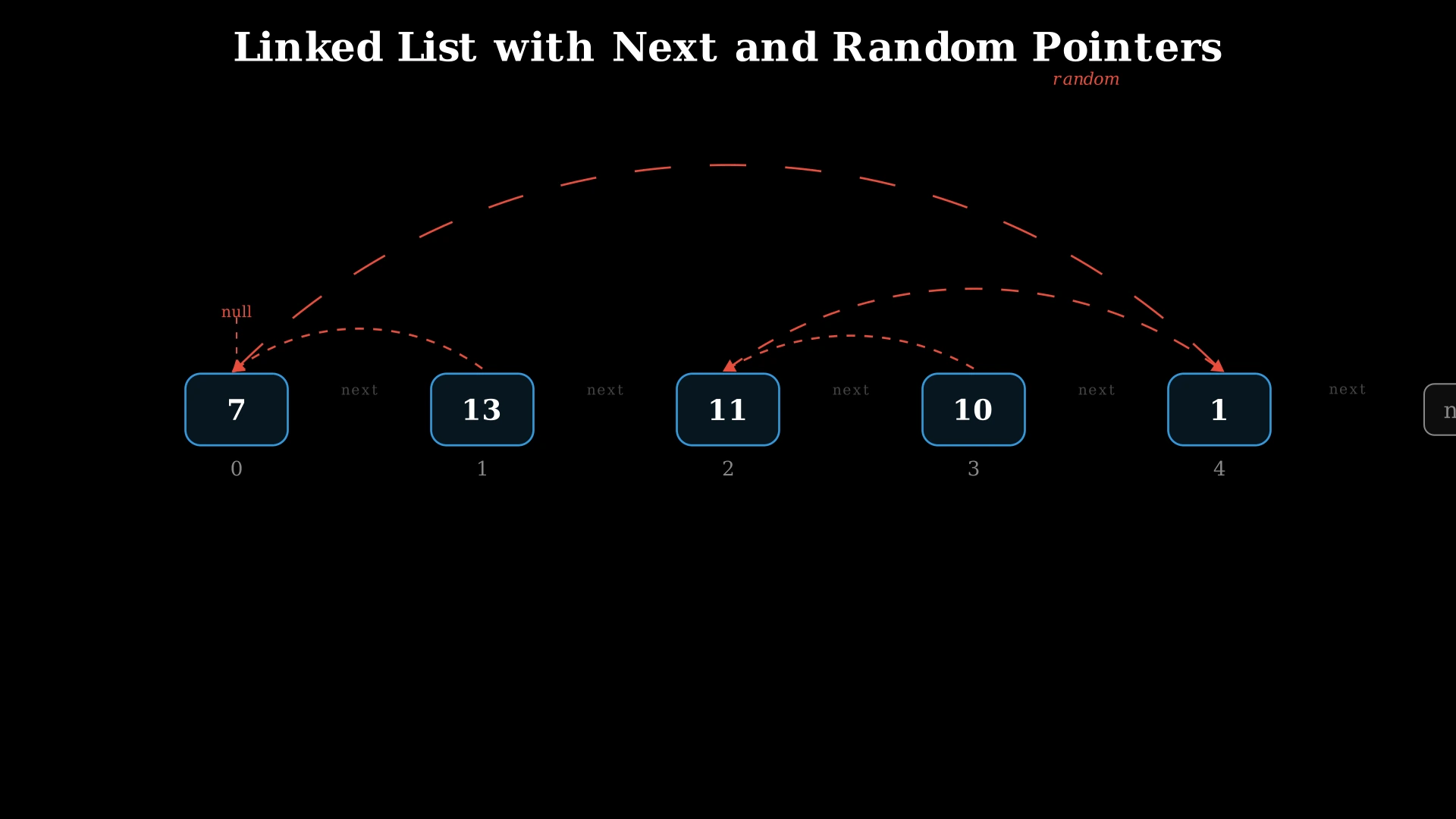
Examples
Example 1
Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]
Explanation: The list has 5 nodes:
- Node 0 (val=7): random → null
- Node 1 (val=13): random → Node 0 (val=7)
- Node 2 (val=11): random → Node 4 (val=1)
- Node 3 (val=10): random → Node 2 (val=11)
- Node 4 (val=1): random → Node 0 (val=7)
The deep copy must replicate this exact structure with entirely new nodes. No pointer in the copy should reference any original node.
Example 2
Input: head = [[1,1],[2,1]]
Output: [[1,1],[2,1]]
Explanation: Two nodes:
- Node 0 (val=1): random → Node 1 (val=2)
- Node 1 (val=2): random → Node 1 (itself)
Note that Node 1's random pointer is a self-loop, pointing back to itself. The clone must preserve this self-referencing structure.
Example 3
Input: head = [[3,null],[3,0],[3,null]]
Output: [[3,null],[3,0],[3,null]]
Explanation: Three nodes all with value 3:
- Node 0: random → null
- Node 1: random → Node 0
- Node 2: random → null
Even though all node values are the same, each node is a distinct object. The clone must create three distinct new nodes with the correct random pointer relationships.
Constraints
- 0 ≤ n ≤ 1000
- -10^4 ≤ Node.val ≤ 10^4
- Node.random is null or is pointing to some node in the linked list
Editorial
Brute Force
Intuition
The most straightforward way to clone a linked list with random pointers is to break the problem into two tasks:
- Clone the structure: Create new nodes with the correct values and
nextpointers. This is the same as cloning a regular singly linked list. - Clone the random pointers: For each original node's
randompointer, figure out where it points and set the corresponding clone node'srandompointer.
The challenge is task 2. We have no direct way to map an original node to its clone. The brute force solution is position-based matching: find the position (index) of the random target in the original list by counting from the head, then walk the clone list to the same position.
Imagine you have two identical train routes drawn on separate maps. You need to copy special shortcut arrows from the first map to the second. For each shortcut, you count how many stations from the start it points to on the first map, then count the same number of stations on the second map to place the shortcut.
Step-by-Step Explanation
Let's trace through with head = [[7,null],[13,0],[11,4],[10,2],[1,0]]:
Original list structure:
- Node 0: val=7, next→Node 1, random→null
- Node 1: val=13, next→Node 2, random→Node 0
- Node 2: val=11, next→Node 3, random→Node 4
- Node 3: val=10, next→Node 4, random→Node 2
- Node 4: val=1, next→null, random→Node 0
Pass 1 — Create clone list with next pointers only:
Step 1: Walk the original list, creating a new node for each original.
Clone list: Clone0(7) → Clone1(13) → Clone2(11) → Clone3(10) → Clone4(1) → null
State: clone_head = Clone0, all random pointers are null.
Pass 2 — Set random pointers by position scanning:
Step 2: Process Node 0 (val=7). Original random = null.
Clone0.random = null. No scanning needed.
State: Clone0.random = null ✓
Step 3: Process Node 1 (val=13). Original random = Node 0.
Find position of Node 0 in original list:
- Start at head, count steps: Node 0 is at position 0.
Walk clone list 0 steps from clone_head: arrive at Clone0.
Clone1.random = Clone0 ✓
Scanning work: 0 steps to find position + 0 steps to walk clone = 0 total.
Step 4: Process Node 2 (val=11). Original random = Node 4.
Find position of Node 4 in original list:
- Walk from head: Node 0 (pos 0) → Node 1 (pos 1) → Node 2 (pos 2) → Node 3 (pos 3) → Node 4 (pos 4).
- Position = 4, required 4 steps.
Walk clone list 4 steps: Clone0 → Clone1 → Clone2 → Clone3 → Clone4.
Clone2.random = Clone4 ✓
Scanning work: 4 + 4 = 8 total.
Step 5: Process Node 3 (val=10). Original random = Node 2.
Position of Node 2 = 2 (2 steps from head).
Walk clone list 2 steps: Clone0 → Clone1 → Clone2.
Clone3.random = Clone2 ✓
Scanning work: 2 + 2 = 4 total.
Step 6: Process Node 4 (val=1). Original random = Node 0.
Position of Node 0 = 0.
Clone4.random = Clone0 ✓
Scanning work: 0 total.
Step 7: Return clone_head. Total scanning work for random pointers: 0 + 0 + 8 + 4 + 0 = 12 operations. In the worst case, every random pointer could point to the last node, making this O(n) per node → O(n²) total.
Algorithm
- Pass 1 — Clone structure:
- Create a new node for each original node with the same value
- Link clone nodes with next pointers in the same order
- Pass 2 — Set random pointers:
- For each original node with a non-null random pointer:
a. Walk the original list from head to find the position (index) of the random target
b. Walk the clone list from clone_head the same number of steps
c. Set the clone node's random pointer to that clone node
- For each original node with a non-null random pointer:
- Return clone_head
Code
class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head) return nullptr;
// Pass 1: Create clone list with next pointers
Node* curr = head;
Node* cloneHead = new Node(curr->val);
Node* cloneCurr = cloneHead;
while (curr->next) {
curr = curr->next;
cloneCurr->next = new Node(curr->val);
cloneCurr = cloneCurr->next;
}
// Pass 2: Set random pointers by position
curr = head;
cloneCurr = cloneHead;
while (curr) {
if (curr->random) {
// Find position of random target
int pos = 0;
Node* temp = head;
while (temp != curr->random) {
temp = temp->next;
pos++;
}
// Walk clone list to same position
Node* cloneTemp = cloneHead;
for (int i = 0; i < pos; i++) {
cloneTemp = cloneTemp->next;
}
cloneCurr->random = cloneTemp;
}
curr = curr->next;
cloneCurr = cloneCurr->next;
}
return cloneHead;
}
};class Solution:
def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':
if not head:
return None
# Pass 1: Create clone list with next pointers
curr = head
clone_head = Node(curr.val)
clone_curr = clone_head
while curr.next:
curr = curr.next
clone_curr.next = Node(curr.val)
clone_curr = clone_curr.next
# Pass 2: Set random pointers by position
curr = head
clone_curr = clone_head
while curr:
if curr.random:
pos = 0
temp = head
while temp != curr.random:
temp = temp.next
pos += 1
clone_temp = clone_head
for _ in range(pos):
clone_temp = clone_temp.next
clone_curr.random = clone_temp
curr = curr.next
clone_curr = clone_curr.next
return clone_headclass Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
// Pass 1: Create clone list with next pointers
Node curr = head;
Node cloneHead = new Node(curr.val);
Node cloneCurr = cloneHead;
while (curr.next != null) {
curr = curr.next;
cloneCurr.next = new Node(curr.val);
cloneCurr = cloneCurr.next;
}
// Pass 2: Set random pointers by position
curr = head;
cloneCurr = cloneHead;
while (curr != null) {
if (curr.random != null) {
int pos = 0;
Node temp = head;
while (temp != curr.random) {
temp = temp.next;
pos++;
}
Node cloneTemp = cloneHead;
for (int i = 0; i < pos; i++) {
cloneTemp = cloneTemp.next;
}
cloneCurr.random = cloneTemp;
}
curr = curr.next;
cloneCurr = cloneCurr.next;
}
return cloneHead;
}
}Complexity Analysis
Time Complexity: O(n²)
Pass 1 creates n clone nodes in O(n) time. Pass 2 processes n nodes, and for each node with a random pointer, we may need to scan up to n nodes in the original list to find the position, then scan up to n nodes in the clone list to reach that position. In the worst case (all random pointers point to the last node), this is O(n) per node × n nodes = O(n²).
Space Complexity: O(1) extra space
Beyond the n new nodes required for the output (which is mandatory), we only use a few pointer variables and a position counter. No additional data structures are needed.
Why This Approach Is Not Efficient
The brute force spends O(n) time per random pointer to find the target's position by scanning from the head. With n random pointers to set, the total time is O(n²). For n up to 1000, this means up to 10⁶ operations — acceptable in practice, but the approach is fundamentally wasteful.
The core problem is that we have no direct mapping from an original node to its clone. We resort to position counting (walking both lists to the same index), which is a linear operation per lookup.
A hash map can store the direct mapping {original_node → clone_node}, providing O(1) lookup time for each random pointer assignment. This eliminates the repeated linear scans entirely.
Better Approach - Hash Map
Intuition
Instead of finding positions by scanning, we can build a hash map that directly maps each original node to its corresponding clone node. With this map, setting any pointer (next or random) on a clone becomes a simple O(1) lookup.
The approach works in two passes:
- First pass: Create all clone nodes and store the mapping {original → clone} in the hash map
- Second pass: For each original node, use the map to set clone.next and clone.random
Think of it like making a photocopy of a company directory. First, you create a blank entry for every employee (pass 1). Then, you go through the original directory and for each employee's connections (manager, mentor), you look up the corresponding copy in your new directory using an index and link them (pass 2). The index is your hash map.
Step-by-Step Explanation
Let's trace through with head = [[7,null],[13,0],[11,4],[10,2],[1,0]]:
Step 1: Create an empty hash map to store original → clone mappings.
Pass 1 — Create all clone nodes:
Step 2: Visit Node 0 (val=7). Create Clone(7). Map: {Node0 → Clone0}.
Step 3: Visit Node 1 (val=13). Create Clone(13). Map: {Node0 → Clone0, Node1 → Clone1}.
Step 4: Visit Node 2 (val=11). Create Clone(11). Map has 3 entries.
Step 5: Visit Node 3 (val=10). Create Clone(10). Map has 4 entries.
Step 6: Visit Node 4 (val=1). Create Clone(1). Map has 5 entries. All clones created.
Pass 2 — Set next and random pointers using the map:
Step 7: Node 0: Clone0.next = map[Node1] = Clone1. Clone0.random = map[null] = null.
Step 8: Node 1: Clone1.next = map[Node2] = Clone2. Clone1.random = map[Node0] = Clone0.
Step 9: Node 2: Clone2.next = map[Node3] = Clone3. Clone2.random = map[Node4] = Clone4.
Step 10: Node 3: Clone3.next = map[Node4] = Clone4. Clone3.random = map[Node2] = Clone2.
Step 11: Node 4: Clone4.next = map[null] = null. Clone4.random = map[Node0] = Clone0.
Step 12: Return map[head] = Clone0. The cloned list perfectly mirrors the original's structure, built in just two O(n) passes.
Hash Map Cloning — Two-Pass Approach — First pass creates all clone nodes and maps each original to its clone. Second pass uses the map for O(1) lookups to set next and random pointers.
Algorithm
- Create an empty hash map: original_node → clone_node
- Pass 1: Traverse the original list. For each node:
- Create a new node with the same value
- Store the mapping {original → clone} in the hash map
- Pass 2: Traverse the original list again. For each node:
- Set clone.next = map[original.next]
- Set clone.random = map[original.random]
- Return map[head] as the head of the cloned list
Code
class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head) return nullptr;
unordered_map<Node*, Node*> nodeMap;
// Pass 1: Create all clone nodes
Node* curr = head;
while (curr) {
nodeMap[curr] = new Node(curr->val);
curr = curr->next;
}
// Pass 2: Set next and random pointers
curr = head;
while (curr) {
nodeMap[curr]->next = nodeMap[curr->next];
nodeMap[curr]->random = nodeMap[curr->random];
curr = curr->next;
}
return nodeMap[head];
}
};class Solution:
def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':
if not head:
return None
node_map = {}
# Pass 1: Create all clone nodes
curr = head
while curr:
node_map[curr] = Node(curr.val)
curr = curr.next
# Pass 2: Set next and random pointers
curr = head
while curr:
node_map[curr].next = node_map.get(curr.next)
node_map[curr].random = node_map.get(curr.random)
curr = curr.next
return node_map[head]class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
Map<Node, Node> nodeMap = new HashMap<>();
// Pass 1: Create all clone nodes
Node curr = head;
while (curr != null) {
nodeMap.put(curr, new Node(curr.val));
curr = curr.next;
}
// Pass 2: Set next and random pointers
curr = head;
while (curr != null) {
nodeMap.get(curr).next = nodeMap.get(curr.next);
nodeMap.get(curr).random = nodeMap.get(curr.random);
curr = curr.next;
}
return nodeMap.get(head);
}
}Complexity Analysis
Time Complexity: O(n)
Pass 1 visits each of the n nodes once, creating a clone and inserting into the hash map — each operation is O(1) average. Pass 2 also visits each node once, performing two O(1) map lookups per node. Total: O(n) + O(n) = O(n).
Space Complexity: O(n)
The hash map stores n key-value pairs (one per original node). Each pair holds two node references. This O(n) space is in addition to the n new nodes required for the output.
Why This Approach Is Not Efficient
The hash map approach achieves optimal O(n) time by providing instant lookups from original nodes to their clones. However, it requires O(n) extra space for the hash map, storing n node mappings.
Can we eliminate this auxiliary space entirely? The key insight is to use the existing list structure itself as the mapping mechanism. Instead of an external hash map, we temporarily insert each clone node directly after its original in the list. This creates an interweaved structure where, for any original node, its clone is always at original.next. This gives us O(1) access to any clone without a hash map.
After setting random pointers using this interweaved structure, we simply separate the two lists by restoring the original next pointers. The result is O(n) time with O(1) extra space.
Optimal Approach - Interweaving (In-Place Cloning)
Intuition
The interweaving approach is a clever three-phase technique that avoids any extra data structures by temporarily modifying the original list:
Phase 1 — Interweave: Insert a clone node right after each original node. The list doubles in length:
Before: A → B → C
After: A → A' → B → B' → C → C'
Phase 2 — Set random pointers: For any original node, its clone is the immediate next node. So if original.random = X, then clone.random = X.next (because X.next is X's clone). This gives us O(1) random pointer resolution without any map.
Phase 3 — Separate: Restore the original list by skipping over clone nodes, and connect clone nodes by skipping over original nodes.
Think of it like a dance where partners stand side by side. If Alice's random friend is Bob, then Alice's clone (standing right next to Alice) can find Bob's clone (standing right next to Bob) by just looking one step to the right of Bob. The spatial arrangement encodes the mapping.
Step-by-Step Explanation
Let's trace through with head = [[7,null],[13,0],[11,4],[10,2],[1,0]]:
Phase 1 — Interweave clone nodes after each original:
Step 1: Create Clone(7), insert after Node 0:
List: 7 → 7' → 13 → 11 → 10 → 1
Step 2: Create Clone(13), insert after Node 1 (now at index 2):
List: 7 → 7' → 13 → 13' → 11 → 10 → 1
Step 3: Create Clone(11), insert after Node 2:
List: 7 → 7' → 13 → 13' → 11 → 11' → 10 → 1
Step 4: Create Clone(10), insert after Node 3:
List: 7 → 7' → 13 → 13' → 11 → 11' → 10 → 10' → 1
Step 5: Create Clone(1), insert after Node 4:
List: 7 → 7' → 13 → 13' → 11 → 11' → 10 → 10' → 1 → 1'
Interweaving complete. Each clone is at an odd index.
Phase 2 — Set random pointers using the interweaved structure:
Rule: if original.random = X, then clone.random = X.next (X's clone).
Step 6: Clone(7) at index 1: Node 0.random = null → Clone(7).random = null.
Step 7: Clone(13) at index 3: Node 1.random = Node 0 (index 0). Node 0.next = Clone(7) (index 1). So Clone(13).random = Clone(7).
Step 8: Clone(11) at index 5: Node 2.random = Node 4 (index 8). Node 4.next = Clone(1) (index 9). So Clone(11).random = Clone(1).
Step 9: Clone(10) at index 7: Node 3.random = Node 2 (index 4). Node 2.next = Clone(11) (index 5). So Clone(10).random = Clone(11).
Step 10: Clone(1) at index 9: Node 4.random = Node 0 (index 0). Node 0.next = Clone(7) (index 1). So Clone(1).random = Clone(7).
Phase 3 — Separate the two lists:
Step 11: Restore original next pointers (skip clones) and connect clone next pointers (skip originals):
Original: 7 → 13 → 11 → 10 → 1 → null
Clone: 7' → 13' → 11' → 10' → 1' → null
Step 12: Return Clone(7) as the head of the cloned list. Both lists are now independent.
Interweaving — In-Place Cloning Without Hash Map — Watch the three phases: interweave clone nodes into the original list, set random pointers using the interweaved structure, then separate into two independent lists.
Algorithm
- Phase 1 — Interweave: For each original node:
- Create a clone with the same value
- Insert clone between the original and its next node
- Advance to the next original node (skip the clone)
- Phase 2 — Set random pointers: For each original node:
- If original.random is not null:
- Set clone.random = original.random.next (the clone of the random target)
- Advance by 2 (skip clone to reach next original)
- If original.random is not null:
- Phase 3 — Separate: Traverse the interweaved list:
- Restore each original.next to skip over its clone
- Set each clone.next to skip over the next original
- Return the clone head
Code
class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head) return nullptr;
// Phase 1: Insert clone nodes between originals
Node* curr = head;
while (curr) {
Node* clone = new Node(curr->val);
clone->next = curr->next;
curr->next = clone;
curr = clone->next;
}
// Phase 2: Set random pointers for clones
curr = head;
while (curr) {
if (curr->random) {
curr->next->random = curr->random->next;
}
curr = curr->next->next;
}
// Phase 3: Separate the two lists
Node* cloneHead = head->next;
curr = head;
while (curr) {
Node* clone = curr->next;
curr->next = clone->next;
clone->next = clone->next ? clone->next->next : nullptr;
curr = curr->next;
}
return cloneHead;
}
};class Solution:
def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':
if not head:
return None
# Phase 1: Insert clone nodes between originals
curr = head
while curr:
clone = Node(curr.val)
clone.next = curr.next
curr.next = clone
curr = clone.next
# Phase 2: Set random pointers for clones
curr = head
while curr:
if curr.random:
curr.next.random = curr.random.next
curr = curr.next.next
# Phase 3: Separate the two lists
clone_head = head.next
curr = head
while curr:
clone = curr.next
curr.next = clone.next
clone.next = clone.next.next if clone.next else None
curr = curr.next
return clone_headclass Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
// Phase 1: Insert clone nodes between originals
Node curr = head;
while (curr != null) {
Node clone = new Node(curr.val);
clone.next = curr.next;
curr.next = clone;
curr = clone.next;
}
// Phase 2: Set random pointers for clones
curr = head;
while (curr != null) {
if (curr.random != null) {
curr.next.random = curr.random.next;
}
curr = curr.next.next;
}
// Phase 3: Separate the two lists
Node cloneHead = head.next;
curr = head;
while (curr != null) {
Node clone = curr.next;
curr.next = clone.next;
clone.next = (clone.next != null) ? clone.next.next : null;
curr = curr.next;
}
return cloneHead;
}
}Complexity Analysis
Time Complexity: O(n)
Phase 1 (interweaving) traverses the list once — n iterations. Phase 2 (random pointers) traverses the interweaved list, visiting each original once — n iterations. Phase 3 (separation) traverses the list once more — n iterations. Total: 3 × O(n) = O(n).
Space Complexity: O(1) extra space
Beyond the n new nodes required for the output, we use only a constant number of pointer variables. The interweaving technique uses the existing list structure as the mapping mechanism, eliminating the need for a hash map or any auxiliary data structure.