Most Stones Removed with Same Row or Column
Description
You are given n stones placed on a 2D coordinate plane. Each stone sits at an integer coordinate point [x_i, y_i], and no two stones occupy the same position.
A stone can be removed if it shares either the same row (same x-coordinate) or the same column (same y-coordinate) as at least one other stone that has not yet been removed.
Given an array stones of length n where stones[i] = [x_i, y_i] represents the position of the i-th stone, return the largest possible number of stones that can be removed.
Key Insight: Stones that are connected through shared rows and columns form groups (connected components). Within each group of k stones, you can always remove k - 1 of them — you just need to leave one stone behind as the anchor. So the answer is total stones - number of connected components.
Examples
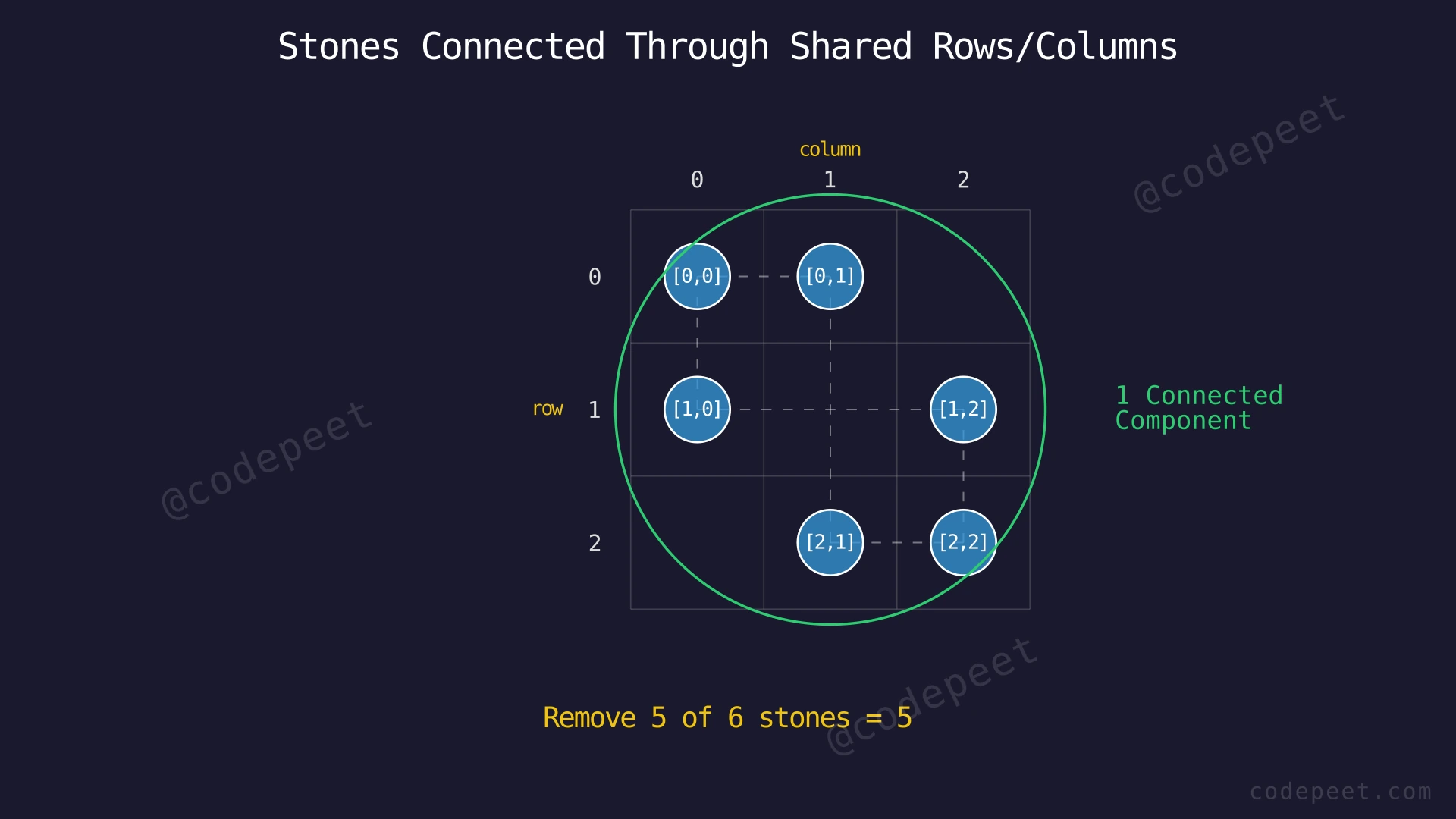
Example 1
Input: stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]
Output: 5
Explanation: All 6 stones are connected through shared rows and columns, forming a single connected component. For example:
- [0,0] and [0,1] share row 0
- [0,0] and [1,0] share column 0
- [1,0] and [1,2] share row 1
- [0,1] and [2,1] share column 1
- [1,2] and [2,2] share column 2
- [2,1] and [2,2] share row 2
Since all stones are connected transitively, we can remove 5 of them (leaving any 1 behind). One valid removal order: remove [2,2], then [2,1], then [1,2], then [1,0], then [0,1]. Stone [0,0] remains as the last anchor.
Example 2
Input: stones = [[0,0],[0,2],[1,1],[2,0],[2,2]]
Output: 3
Explanation: The 5 stones form two separate connected components:
- Component 1: {[0,0], [0,2], [2,0], [2,2]} — connected via shared rows and columns. We can remove 3 of these 4 stones.
- Component 2: {[1,1]} — isolated, shares no row or column with any other stone. Cannot be removed.
Maximum removable = (4 - 1) + (1 - 1) = 3 + 0 = 3.
Example 3
Input: stones = [[0,0]]
Output: 0
Explanation: There is only 1 stone on the plane. It shares no row or column with any other stone (there are none), so it cannot be removed. Maximum removable = 0.
Constraints
- 1 ≤ stones.length ≤ 1000
- 0 ≤ x_i, y_i ≤ 10^4
- No two stones are at the same coordinate point.
Editorial
Brute Force
Intuition
At first glance, the removal rules seem complicated — you can only remove a stone if it shares a row or column with another remaining stone, and the order of removal matters. Simulating every possible removal order would be exponential. But there is a powerful simplification.
Imagine treating each stone as a person at a party. Two people "know each other" if their stones share a row or a column. If person A knows person B, and person B knows person C, then A, B, and C are all in the same social group — even if A and C do not directly know each other.
Within any such group of k people (connected component of k stones), you can always send k - 1 of them home, leaving exactly one person behind. The last person cannot leave because there is no one left in their group to justify the removal.
This insight transforms the problem: build a graph where stones are nodes and edges connect stones sharing a row or column, then count connected components. The answer is simply n - components.
The most straightforward way to build this graph is to check every pair of stones and add an edge if they share a row or column. Then use DFS to count connected components.
Step-by-Step Explanation
Let's trace through Example 2: stones = [[0,0], [0,2], [1,1], [2,0], [2,2]]
Label stones by index: stone 0 = [0,0], stone 1 = [0,2], stone 2 = [1,1], stone 3 = [2,0], stone 4 = [2,2].
Step 1: Build the graph by checking all pairs of stones:
- (0,1): [0,0] and [0,2] share row 0 → edge ✓
- (0,2): [0,0] and [1,1] — no shared row or column → no edge
- (0,3): [0,0] and [2,0] share column 0 → edge ✓
- (0,4): [0,0] and [2,2] — no shared row or column → no edge
- (1,2): [0,2] and [1,1] — no shared row or column → no edge
- (1,3): [0,2] and [2,0] — no shared row or column → no edge
- (1,4): [0,2] and [2,2] share column 2 → edge ✓
- (2,3): [1,1] and [2,0] — no shared row or column → no edge
- (2,4): [1,1] and [2,2] — no shared row or column → no edge
- (3,4): [2,0] and [2,2] share row 2 → edge ✓
Graph edges: (0,1), (0,3), (1,4), (3,4). Stone 2 has no edges.
Step 2: Initialize visited = [false × 5], components = 0.
Step 3: Stone 0 is unvisited. Start DFS from stone 0. Mark 0 as visited.
Step 4: DFS explores neighbor stone 1 [0,2] (shares row 0). Mark 1 as visited.
Step 5: From stone 1, DFS explores neighbor stone 4 [2,2] (shares column 2). Mark 4 as visited.
Step 6: From stone 4, DFS explores neighbor stone 3 [2,0] (shares row 2). Mark 3 as visited.
Step 7: Stone 3's only unvisited neighbor is stone 0 (already visited). Backtrack. DFS complete. Component {0, 1, 3, 4} found. components = 1.
Step 8: Stone 2 [1,1] is unvisited. Start DFS. No neighbors. Component {2} found. components = 2.
Step 9: All stones visited. Answer = n - components = 5 - 2 = 3.
DFS — Finding Connected Stone Groups — Watch how DFS traverses the stone connectivity graph, discovering that 4 stones form one connected group while 1 stone is isolated.
Algorithm
- Build a graph where each stone is a node. For every pair of stones (i, j), add an edge if they share the same row (
stones[i][0] == stones[j][0]) or the same column (stones[i][1] == stones[j][1]). - Initialize a
visitedarray and a countercomponents = 0. - For each stone index
ifrom 0 to n-1:- If stone
iis not visited, run DFS fromito visit all connected stones, then incrementcomponents.
- If stone
- Return
n - components(the maximum number of removable stones).
Code
class Solution {
void dfs(int node, vector<vector<int>>& adj, vector<bool>& visited) {
visited[node] = true;
for (int neighbor : adj[node]) {
if (!visited[neighbor]) {
dfs(neighbor, adj, visited);
}
}
}
public:
int removeStones(vector<vector<int>>& stones) {
int n = stones.size();
// Build adjacency list: edge between stones sharing row or column
vector<vector<int>> adj(n);
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (stones[i][0] == stones[j][0] || stones[i][1] == stones[j][1]) {
adj[i].push_back(j);
adj[j].push_back(i);
}
}
}
// Count connected components using DFS
vector<bool> visited(n, false);
int components = 0;
for (int i = 0; i < n; i++) {
if (!visited[i]) {
dfs(i, adj, visited);
components++;
}
}
return n - components;
}
};class Solution:
def removeStones(self, stones: List[List[int]]) -> int:
n = len(stones)
# Build adjacency list: edge between stones sharing row or column
adj = [[] for _ in range(n)]
for i in range(n):
for j in range(i + 1, n):
if stones[i][0] == stones[j][0] or stones[i][1] == stones[j][1]:
adj[i].append(j)
adj[j].append(i)
# Count connected components using DFS
visited = [False] * n
components = 0
def dfs(node):
visited[node] = True
for neighbor in adj[node]:
if not visited[neighbor]:
dfs(neighbor)
for i in range(n):
if not visited[i]:
dfs(i)
components += 1
return n - componentsclass Solution {
public int removeStones(int[][] stones) {
int n = stones.length;
// Build adjacency list
List<List<Integer>> adj = new ArrayList<>();
for (int i = 0; i < n; i++) adj.add(new ArrayList<>());
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (stones[i][0] == stones[j][0] || stones[i][1] == stones[j][1]) {
adj.get(i).add(j);
adj.get(j).add(i);
}
}
}
// Count connected components using DFS
boolean[] visited = new boolean[n];
int components = 0;
for (int i = 0; i < n; i++) {
if (!visited[i]) {
dfs(i, adj, visited);
components++;
}
}
return n - components;
}
private void dfs(int node, List<List<Integer>> adj, boolean[] visited) {
visited[node] = true;
for (int neighbor : adj.get(node)) {
if (!visited[neighbor]) {
dfs(neighbor, adj, visited);
}
}
}
}Complexity Analysis
Time Complexity: O(n²)
Building the adjacency list requires checking every pair of stones. There are n × (n-1) / 2 pairs, and each comparison is O(1). The DFS traversal visits each node once and each edge once, but since there can be up to O(n²) edges (when many stones share rows/columns), the DFS is also O(n²). Total: O(n²).
Space Complexity: O(n²)
The adjacency list can store up to O(n²) edges in the worst case (when every stone shares a row or column with every other stone). The visited array takes O(n) and the recursion stack O(n). Dominant term: O(n²).
Why This Approach Is Not Efficient
The brute force approach checks every pair of stones to build the graph, taking O(n²) time and O(n²) space. With n up to 1000, this means up to ~500,000 pair comparisons and potentially as many edges stored in the adjacency list.
The fundamental waste: we are comparing EVERY pair of stones to find connections, when the connections are actually structured by rows and columns. Stones on the same row are all connected to each other. Stones on the same column are all connected to each other. Instead of discovering this by checking all pairs, we can group stones by their row and column coordinates using hash maps.
For example, if 10 stones share row 5, the brute force creates 10 × 9 / 2 = 45 edges between them. But we really only need to know they are in the same component — which requires just 9 union operations (chaining them together: connect stone[0] to stone[1], stone[1] to stone[2], etc.).
Key Insight: Instead of comparing all n² pairs, group stones by row and by column. For each group, chain-union adjacent stones. This reduces the total union operations from O(n²) to O(n), since each stone appears in exactly one row group and one column group.
Optimal Approach - Union-Find with Coordinate Grouping
Intuition
The optimal approach avoids the O(n²) pairwise comparison entirely. Instead of asking "does stone A connect to stone B?" for every pair, we flip the question: which stones are on each row, and which are on each column?
We use two hash maps:
row_map: maps each row (x-coordinate) to the list of stone indices on that row.col_map: maps each column (y-coordinate) to the list of stone indices in that column.
Building these maps takes just O(n) — one pass through all stones.
Then, for each row that contains multiple stones, we union them all together. Similarly for each column. To union a group of k stones efficiently, we pick one stone as the "anchor" and union each other stone in the group with that anchor. This takes k - 1 union operations per group.
Since each stone belongs to exactly one row group and one column group, the total union operations across all groups is at most 2n (at most n from rows and n from columns). Combined with Union-Find's near-constant time per operation, this gives us O(n × α(n)) ≈ O(n) total time.
The answer is the number of successful unions, which equals n - number of components.
Step-by-Step Explanation
Let's trace through Example 2: stones = [[0,0], [0,2], [1,1], [2,0], [2,2]]
Label stones: 0=[0,0], 1=[0,2], 2=[1,1], 3=[2,0], 4=[2,2].
Step 1: Initialize parent array: parent = [0, 1, 2, 3, 4]. Each stone is its own component. Components = 5.
Step 2: Group stones by coordinates:
- Row map: {0: [stone 0, stone 1], 1: [stone 2], 2: [stone 3, stone 4]}
- Col map: {0: [stone 0, stone 3], 1: [stone 2], 2: [stone 1, stone 4]}
Step 3: Process Row 0 group: stones [0, 1]. Union(0, 1). find(0) = 0, find(1) = 1. Different roots → union. Set parent[0] = 1. Successful union! Components = 4.
Step 4: Process Row 2 group: stones [3, 4]. Union(3, 4). find(3) = 3, find(4) = 4. Different roots → union. Set parent[3] = 4. Successful union! Components = 3.
Step 5: Process Col 0 group: stones [0, 3]. Union(0, 3). find(0): parent[0] = 1, root = 1. find(3): parent[3] = 4, root = 4. Different roots → union. Set parent[1] = 4. Successful union! Components = 2. Now stones {0, 1, 3, 4} share a single root.
Step 6: Process Col 2 group: stones [1, 4]. Union(1, 4). find(1): parent[1] = 4, root = 4. find(4) = 4, root = 4. Same root! Already connected. Skip — no union.
Step 7: All groups processed. 3 successful unions. 2 components ({0,1,3,4} and {2}). Answer = n - components = 5 - 2 = 3.
Union-Find with Coordinate Grouping — Efficient Component Discovery — Watch how grouping stones by row and column lets us find all connections in O(n) time, avoiding the O(n²) pairwise comparison of the brute force.
Algorithm
- Initialize a Union-Find structure with
nelements (one per stone). Setunions = 0. - Build two hash maps:
row_map: maps each x-coordinate to the list of stone indices in that row.col_map: maps each y-coordinate to the list of stone indices in that column.
- For each row group with multiple stones:
- Pick the first stone as anchor. Union every other stone in the group with the anchor.
- Count each successful union (where roots were different).
- For each column group with multiple stones:
- Same process: union each stone with the group's anchor.
- Return the total number of successful unions (which equals
n - components).
Code
class Solution {
vector<int> parent;
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
bool unite(int x, int y) {
int px = find(x), py = find(y);
if (px == py) return false;
parent[px] = py;
return true;
}
public:
int removeStones(vector<vector<int>>& stones) {
int n = stones.size();
parent.resize(n);
iota(parent.begin(), parent.end(), 0);
// Group stone indices by row and column
unordered_map<int, vector<int>> rowMap, colMap;
for (int i = 0; i < n; i++) {
rowMap[stones[i][0]].push_back(i);
colMap[stones[i][1]].push_back(i);
}
int unions = 0;
// Union all stones in the same row
for (auto& [row, indices] : rowMap) {
for (int i = 1; i < (int)indices.size(); i++) {
if (unite(indices[0], indices[i])) unions++;
}
}
// Union all stones in the same column
for (auto& [col, indices] : colMap) {
for (int i = 1; i < (int)indices.size(); i++) {
if (unite(indices[0], indices[i])) unions++;
}
}
return unions;
}
};from collections import defaultdict
class Solution:
def removeStones(self, stones: List[List[int]]) -> int:
n = len(stones)
parent = list(range(n))
def find(x):
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def unite(x, y):
px, py = find(x), find(y)
if px == py:
return False
parent[px] = py
return True
# Group stone indices by row and column
row_map = defaultdict(list)
col_map = defaultdict(list)
for i, (x, y) in enumerate(stones):
row_map[x].append(i)
col_map[y].append(i)
unions = 0
# Union all stones in the same row
for indices in row_map.values():
for i in range(1, len(indices)):
if unite(indices[0], indices[i]):
unions += 1
# Union all stones in the same column
for indices in col_map.values():
for i in range(1, len(indices)):
if unite(indices[0], indices[i]):
unions += 1
return unionsclass Solution {
int[] parent;
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
boolean unite(int x, int y) {
int px = find(x), py = find(y);
if (px == py) return false;
parent[px] = py;
return true;
}
public int removeStones(int[][] stones) {
int n = stones.length;
parent = new int[n];
for (int i = 0; i < n; i++) parent[i] = i;
// Group stone indices by row and column
Map<Integer, List<Integer>> rowMap = new HashMap<>();
Map<Integer, List<Integer>> colMap = new HashMap<>();
for (int i = 0; i < n; i++) {
rowMap.computeIfAbsent(stones[i][0], k -> new ArrayList<>()).add(i);
colMap.computeIfAbsent(stones[i][1], k -> new ArrayList<>()).add(i);
}
int unions = 0;
// Union all stones in the same row
for (List<Integer> indices : rowMap.values()) {
for (int i = 1; i < indices.size(); i++) {
if (unite(indices.get(0), indices.get(i))) unions++;
}
}
// Union all stones in the same column
for (List<Integer> indices : colMap.values()) {
for (int i = 1; i < indices.size(); i++) {
if (unite(indices.get(0), indices.get(i))) unions++;
}
}
return unions;
}
}Complexity Analysis
Time Complexity: O(n × α(n)) ≈ O(n)
Grouping stones into row and column hash maps takes O(n) — one pass through all stones. The total number of union operations across all groups is at most 2 × (n - 1): each stone contributes at most one union in its row group and one in its column group. Each union operation runs in O(α(n)) amortized time with path compression. Since α(n) is effectively constant for practical inputs, the total time is O(n). This is a dramatic improvement over the brute force's O(n²).
Space Complexity: O(n)
The Union-Find parent array takes O(n). The two hash maps collectively store each stone index at most twice (once in row_map, once in col_map), so O(n) total entries. No adjacency list is needed. Total: O(n), significantly better than the brute force's O(n²) adjacency list.