Binary Tree Paths
Description
Given the root of a binary tree, return all root-to-leaf paths in any order.
A leaf is a node with no children. Each path should be represented as a string of node values connected by the arrow symbol "->", starting from the root and ending at a leaf node.
Examples
Example 1
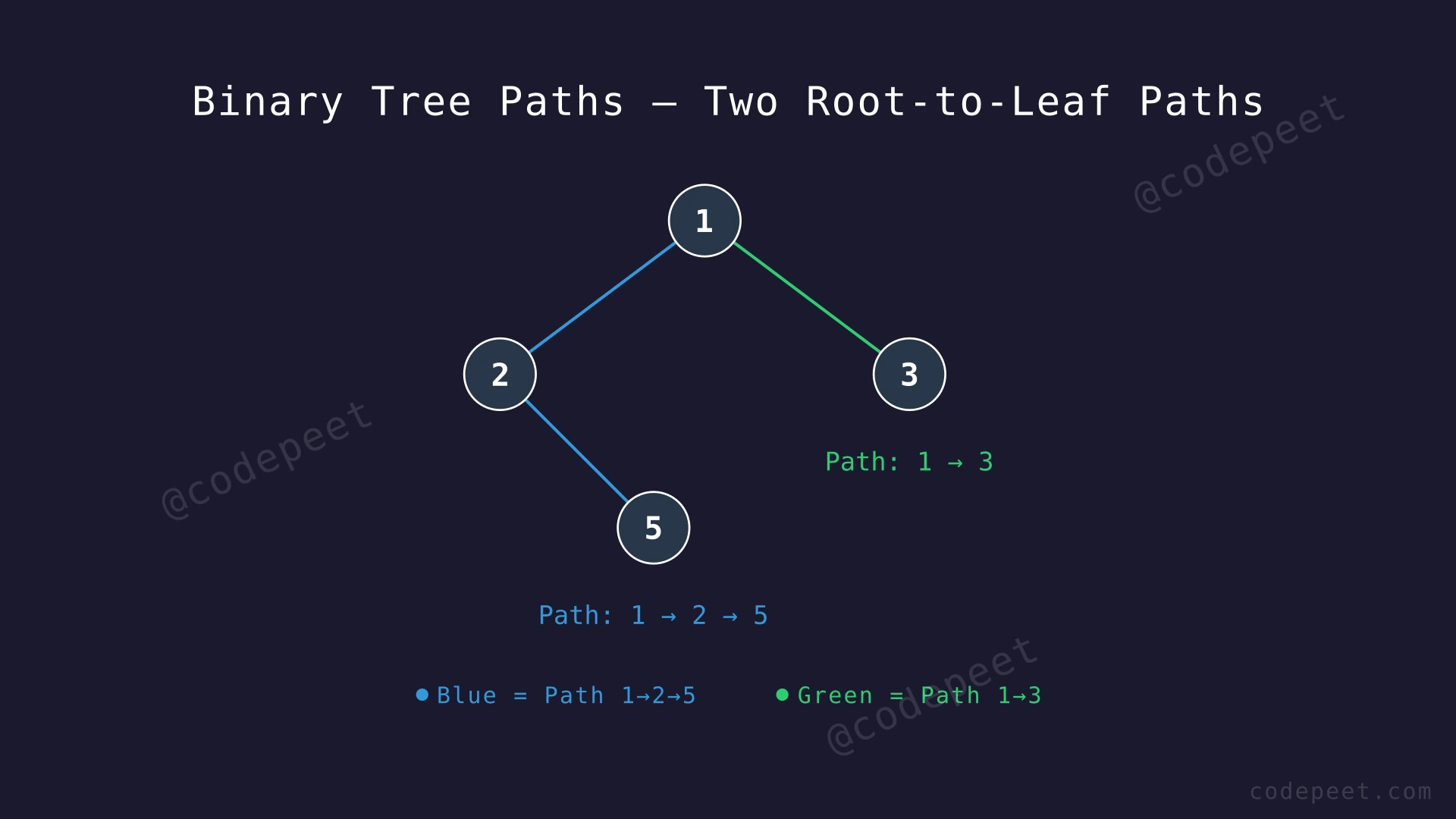
Input: root = [1, 2, 3, null, 5]
1
/ \
2 3
\
5
Output: ["1->2->5", "1->3"]
Explanation: There are two leaf nodes in this tree: node 5 and node 3. The path from the root (1) to leaf 5 passes through node 2, producing the string "1->2->5". The path from root (1) directly to leaf 3 gives "1->3". Both paths are returned.
Example 2
Input: root = [1]
Output: ["1"]
Explanation: The tree has only one node, which is both the root and a leaf (it has no children). The single path is just "1".
Constraints
- The number of nodes in the tree is in the range [1, 100]
- -100 ≤ Node.val ≤ 100
Editorial
Brute Force - DFS with String Concatenation
Intuition
The most natural way to find all root-to-leaf paths is to explore the tree from top to bottom using Depth-First Search (DFS). As we move from a parent node to a child, we build the path string by appending an arrow "->" followed by the child's value.
Think of it like walking through a family tree and writing down everyone's name on a piece of paper as you go deeper. Each time you reach a person with no children (a leaf), you have a complete lineage recorded. Then you start a fresh piece of paper for each new branch you explore.
In this approach, we pass the current path as a string parameter to each recursive call. Since strings are immutable in most languages (or copied by value), each recursive branch automatically gets its own copy of the path — no cleanup needed when we return. This makes the code very simple: at each node, if it is a leaf, we save the path; otherwise, we recurse into its children with the extended path string.
Step-by-Step Explanation
Let's trace through with root = [1, 2, 3, null, 5]:
Step 1: Start DFS at root node 1. Initialize path = "1". Node 1 has both a left child (2) and a right child (3), so it is not a leaf. We need to explore both subtrees.
Step 2: Go left to node 2. Pass path = "1->2" to the recursive call. Node 2 has no left child but has a right child (5), so it is not a leaf either.
Step 3: Node 2's left child is null (skip it). Go right to node 5. Pass path = "1->2->5" to the recursive call.
Step 4: Node 5 has no left child and no right child — it is a leaf! Add the current path "1->2->5" to our results list. First complete path found. result = ["1->2->5"].
Step 5: Return from node 5, then from node 2, back to node 1. The left subtree of node 1 is fully explored. Now explore the right subtree.
Step 6: Go right to node 3. Pass path = "1->3" to the recursive call.
Step 7: Node 3 has no left child and no right child — it is a leaf! Add "1->3" to results. Second path found. result = ["1->2->5", "1->3"].
Step 8: Return from node 3 to node 1. Both subtrees explored. DFS complete. Return ["1->2->5", "1->3"].
DFS with String Concatenation — Building Paths Top-Down — Watch how DFS explores each branch of the tree, building the path string as it descends and recording complete paths at leaf nodes.
Algorithm
- If the root is null, return an empty list
- Define a recursive DFS function that takes a node and the current path string:
a. If the node is a leaf (no left and no right child), add the path to the results list
b. If the node has a left child, recurse with path + "->" + left child's value
c. If the node has a right child, recurse with path + "->" + right child's value - Call DFS starting from the root with the initial path set to the root's value as a string
- Return the results list
Code
class Solution {
public:
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> result;
if (root) dfs(root, to_string(root->val), result);
return result;
}
private:
void dfs(TreeNode* node, string path, vector<string>& result) {
if (!node->left && !node->right) {
result.push_back(path);
return;
}
if (node->left)
dfs(node->left, path + "->" + to_string(node->left->val), result);
if (node->right)
dfs(node->right, path + "->" + to_string(node->right->val), result);
}
};class Solution:
def binaryTreePaths(self, root: Optional[TreeNode]) -> List[str]:
result = []
def dfs(node, path):
if not node.left and not node.right:
result.append(path)
return
if node.left:
dfs(node.left, path + "->" + str(node.left.val))
if node.right:
dfs(node.right, path + "->" + str(node.right.val))
if root:
dfs(root, str(root.val))
return resultclass Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
if (root != null) dfs(root, String.valueOf(root.val), result);
return result;
}
private void dfs(TreeNode node, String path, List<String> result) {
if (node.left == null && node.right == null) {
result.add(path);
return;
}
if (node.left != null)
dfs(node.left, path + "->" + node.left.val, result);
if (node.right != null)
dfs(node.right, path + "->" + node.right.val, result);
}
}Complexity Analysis
Time Complexity: O(n × h)
We visit every node exactly once during the DFS traversal, which is O(n). However, at each node, we perform a string concatenation that copies the entire path so far. In the worst case (a skewed tree where every node forms a single chain), the path length at depth d is O(d), so the total string work sums to 1 + 2 + ... + n = O(n²). For a balanced tree with height h = log n, the work per path is O(log n) and there are about n/2 leaves, giving O(n log n). In general, the time is O(n × h) where h is the tree height.
Space Complexity: O(n × h)
The recursion stack uses O(h) space for the call depth. Each recursive call holds its own copy of the path string, which can be up to O(h) characters long. Since there are up to O(h) frames on the stack simultaneously, the total space for in-flight path strings is O(h²). In a skewed tree, h = n, giving O(n²). The output list itself stores all paths, which in the worst case requires O(n × h) total characters.
Why This Approach Is Not Efficient
The core inefficiency lies in repeated string copying. Every time we move from a parent to a child, the entire path string built so far gets duplicated. For a node at depth d, the concatenation creates a brand-new string of length proportional to d.
Consider a worst-case skewed tree (every node has only one child) with n nodes. At depth 1 we copy 1 character, at depth 2 we copy 2 characters, and so on up to depth n. The total copying work is 1 + 2 + ... + n = n(n+1)/2 = O(n²).
Even for balanced trees, this redundant copying is wasteful. The fundamental problem is that strings are immutable — we cannot modify them in place. Each concatenation allocates new memory and copies old content.
Key insight: instead of creating a new string at every level, we can use a mutable list (array) that we modify in place. We append a value when entering a node and remove it when leaving — this is the classic backtracking pattern. String joining happens only once per leaf, eliminating all intermediate copies.
Optimal Approach - DFS with Backtracking
Intuition
Instead of building a new string at every node, we maintain a single shared list that represents the current path. When we visit a node, we append its value to the list. When we leave a node (after exploring all its subtrees), we remove the last value — this "undo" operation is called backtracking.
Think of it like a trail of breadcrumbs. As you walk deeper into a forest (the tree), you drop a breadcrumb at each turn. When you reach a dead end (leaf), you record the trail. Then you pick up the last breadcrumb and try a different direction. The same trail is reused for every path, just modified at the end.
The string is only constructed (by joining the list with "->" separators) when we actually reach a leaf. This avoids creating throwaway intermediate strings at every internal node. The list append and pop operations are both O(1), making the traversal itself O(n) total.
Step-by-Step Explanation
Let's trace through with root = [1, 2, 3, null, 5]:
Step 1: Start DFS at root node 1. Append "1" to the shared path list. path = ["1"]. Node 1 is not a leaf.
Step 2: Go left to node 2. Append "2" to path. path = ["1", "2"]. Node 2 is not a leaf (has right child).
Step 3: Node 2's left is null (skip). Go right to node 5. Append "5" to path. path = ["1", "2", "5"].
Step 4: Node 5 is a leaf (no children). Join the path list with "->" to form "1->2->5". Add to results. result = ["1->2->5"].
Step 5: Backtrack: pop "5" from path. path = ["1", "2"]. Return from node 5.
Step 6: Backtrack: pop "2" from path. path = ["1"]. Return from node 2 to node 1. Left subtree done.
Step 7: Go right to node 3. Append "3" to path. path = ["1", "3"]. Check if node 3 is a leaf.
Step 8: Node 3 is a leaf. Join path: "1->3". Add to results. result = ["1->2->5", "1->3"].
Step 9: Backtrack: pop "3" from path. path = ["1"]. Return from node 3.
Step 10: Backtrack: pop "1" from path. path = []. Return from node 1. DFS complete. Return ["1->2->5", "1->3"].
Notice how the path list grows and shrinks as we explore: [] → [1] → [1,2] → [1,2,5] → [1,2] → [1] → [1,3] → [1] → []. The same list is reused throughout — no copies created.
DFS with Backtracking — Shared Path List Grows and Shrinks — Watch how the shared path list is modified in place: values are appended when entering a node and popped when leaving, demonstrating the classic backtracking pattern.
Algorithm
- Initialize an empty results list and an empty shared path list
- Define a recursive DFS function that takes a node:
a. If the node is null, return immediately
b. Append the node's value (as a string) to the shared path list
c. If the node is a leaf (no left and no right child):- Join all elements of the path list with "->" to form the path string
- Add the path string to the results list
d. Otherwise, recurse on the left child, then recurse on the right child
e. Backtrack: Pop the last element from the path list (undo step b)
- Call DFS starting from the root
- Return the results list
Code
class Solution {
public:
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> result;
vector<string> path;
dfs(root, path, result);
return result;
}
private:
void dfs(TreeNode* node, vector<string>& path, vector<string>& result) {
if (!node) return;
path.push_back(to_string(node->val));
if (!node->left && !node->right) {
string s;
for (int i = 0; i < path.size(); i++) {
if (i > 0) s += "->";
s += path[i];
}
result.push_back(s);
} else {
dfs(node->left, path, result);
dfs(node->right, path, result);
}
path.pop_back();
}
};class Solution:
def binaryTreePaths(self, root: Optional[TreeNode]) -> List[str]:
result = []
path = []
def dfs(node):
if not node:
return
path.append(str(node.val))
if not node.left and not node.right:
result.append("->" .join(path))
else:
dfs(node.left)
dfs(node.right)
path.pop()
dfs(root)
return resultclass Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
List<String> path = new ArrayList<>();
dfs(root, path, result);
return result;
}
private void dfs(TreeNode node, List<String> path, List<String> result) {
if (node == null) return;
path.add(String.valueOf(node.val));
if (node.left == null && node.right == null) {
result.add(String.join("->", path));
} else {
dfs(node.left, path, result);
dfs(node.right, path, result);
}
path.remove(path.size() - 1);
}
}Complexity Analysis
Time Complexity: O(n)
The DFS traversal visits each of the n nodes exactly once. At each node, the append and pop operations on the path list are O(1). The string join operation happens only at leaf nodes — each join takes O(h) time where h is the current path length (tree height). With L leaf nodes and an average path length of h, the total join cost is O(L × h). In the worst case (skewed tree), L = 1 and h = n, so joining costs O(n). In a balanced tree, L ≈ n/2 and h = log n, giving O(n log n) for joins. The traversal itself is always O(n).
Space Complexity: O(h)
The shared path list holds at most h elements (one per level of the tree), using O(h) space. The recursion stack also uses O(h) space. Unlike the string concatenation approach, we do not create intermediate string copies — the path list is modified in place. In the worst case (skewed tree), h = n; in a balanced tree, h = log n. The output list is additional space proportional to the number of paths and their lengths.