Longest Common Subsequence
Description
Given two strings s1 and s2, return the length of their longest common subsequence (LCS). If there is no common subsequence, return 0.
A subsequence is a sequence that can be derived from the given string by deleting some or no elements without changing the relative order of the remaining elements. For example, "ABE" is a subsequence of "ABCDE" because you can obtain it by removing 'C' and 'D' while keeping the remaining characters in their original order.
Note that a subsequence does not need to be contiguous — the characters can be spread apart in the original string, as long as their relative ordering is preserved.
Examples
Example 1
Input: s1 = "ABCDGH", s2 = "AEDFHR"
Output: 3
Explanation: The longest common subsequence is "ADH". Characters 'A', 'D', and 'H' appear in both strings in the same relative order: in s1 at positions 0, 3, 5 and in s2 at positions 0, 2, 4. No common subsequence of length 4 or more exists.
Example 2
Input: s1 = "ABC", s2 = "AC"
Output: 2
Explanation: The longest common subsequence is "AC". Both 'A' and 'C' appear in both strings in the same relative order. The character 'B' in s1 is not in s2, so the longest we can achieve is length 2.
Example 3
Input: s1 = "XYZW", s2 = "XYWZ"
Output: 3
Explanation: There are two longest common subsequences of length 3: "XYZ" and "XYW". Both are valid. Notice that "XYZW" and "XYWZ" share the prefix "XY" and then diverge — we can extend by picking either 'Z' or 'W' but not both in the correct order.
Constraints
- 1 ≤ s1.size(), s2.size() ≤ 10^3
- Both strings s1 and s2 contain only uppercase English letters.
Editorial
Brute Force
Intuition
The most natural way to think about this problem is recursively. Imagine you are standing at the end of both strings and asking: do the last characters match?
If they match, that character must be part of the LCS, so you include it and move both strings one step back. If they don't match, you have two choices — skip the last character of s1 and try again, or skip the last character of s2 and try again. You take whichever choice gives a longer subsequence.
Think of it like two people reading their respective books backwards. Whenever they find the same word on the current page, they both flip back a page together. When the words differ, one person flips back while the other waits, and then they try the other way around. The goal is to find the maximum number of pages they can flip together.
This naturally leads to a recursive solution where at each step we either have a character match (reducing both strings) or a mismatch (branching into two recursive calls).
Step-by-Step Explanation
Let's trace through with s1 = "ABX", s2 = "ACX":
Step 1: Call lcs("ABX", "ACX"). Compare last characters: 'X' and 'X'. They match! The LCS includes 'X', and we now need to find the LCS of "AB" and "AC". Result will be 1 + lcs("AB", "AC").
Step 2: Call lcs("AB", "AC"). Compare last characters: 'B' and 'C'. They don't match. We must explore two options: exclude 'B' from s1 (try lcs("A", "AC")) or exclude 'C' from s2 (try lcs("AB", "A")). Take the maximum.
Step 3: Call lcs("A", "AC"). Compare: 'A' and 'C'. No match. Branch into lcs("", "AC") and lcs("A", "A").
Step 4: lcs("", "AC") = 0. Base case — an empty string has no characters to match.
Step 5: Call lcs("A", "A"). Compare: 'A' and 'A'. Match! Result = 1 + lcs("", "").
Step 6: lcs("", "") = 0. Both strings empty. So lcs("A", "A") = 1 + 0 = 1.
Step 7: Resolve lcs("A", "AC") = max(0, 1) = 1. The best subsequence from "A" and "AC" is just "A".
Step 8: Now process the other branch from Step 2: lcs("AB", "A"). Compare: 'B' and 'A'. No match. Branch into lcs("A", "A") and lcs("AB", "").
Step 9: lcs("A", "A") has already been computed as 1! This is an overlapping subproblem — the exact same call appears in two different branches of the recursion tree.
Step 10: lcs("AB", "") = 0. Base case — empty string.
Step 11: Resolve lcs("AB", "A") = max(1, 0) = 1.
Step 12: Resolve lcs("AB", "AC") = max(1, 1) = 1. Whether we exclude 'B' or 'C', the LCS of the remaining is 1.
Step 13: Resolve lcs("ABX", "ACX") = 1 (from 'X' match) + 1 (LCS of "AB", "AC") = 2.
Result: The LCS length is 2, corresponding to the subsequence "AX".
LCS Recursive Calls — Tracing lcs("ABX", "ACX") — Watch how the recursive LCS function expands into a tree of calls, with overlapping subproblems computed multiple times.
Algorithm
- Define a recursive function lcs(s1, s2, m, n) where m and n are the current lengths of the prefixes being considered.
- Base case: If m == 0 or n == 0, return 0 (an empty string has no common subsequence with anything).
- Match case: If s1[m-1] == s2[n-1], the last characters match. Return 1 + lcs(s1, s2, m-1, n-1) — include this character and recurse on the remaining prefixes.
- Mismatch case: If s1[m-1] != s2[n-1], return max(lcs(s1, s2, m-1, n), lcs(s1, s2, m, n-1)) — try excluding the last character of either string and take the better result.
- The initial call is lcs(s1, s2, len(s1), len(s2)).
Code
class Solution {
public:
int lcs(int n, int m, string &s1, string &s2) {
// Base case: if either string is empty
if (n == 0 || m == 0)
return 0;
// If last characters match, include in LCS
if (s1[n - 1] == s2[m - 1])
return 1 + lcs(n - 1, m - 1, s1, s2);
// If they don't match, try both options
return max(lcs(n - 1, m, s1, s2),
lcs(n, m - 1, s1, s2));
}
};class Solution:
def lcs(self, n, m, s1, s2):
# Base case: if either string is empty
if n == 0 or m == 0:
return 0
# If last characters match, include in LCS
if s1[n - 1] == s2[m - 1]:
return 1 + self.lcs(n - 1, m - 1, s1, s2)
# If they don't match, try both options
return max(self.lcs(n - 1, m, s1, s2),
self.lcs(n, m - 1, s1, s2))class Solution {
public int lcs(int n, int m, String s1, String s2) {
// Base case: if either string is empty
if (n == 0 || m == 0)
return 0;
// If last characters match, include in LCS
if (s1.charAt(n - 1) == s2.charAt(m - 1))
return 1 + lcs(n - 1, m - 1, s1, s2);
// If they don't match, try both options
return Math.max(lcs(n - 1, m, s1, s2),
lcs(n, m - 1, s1, s2));
}
}Complexity Analysis
Time Complexity: O(2^min(n, m))
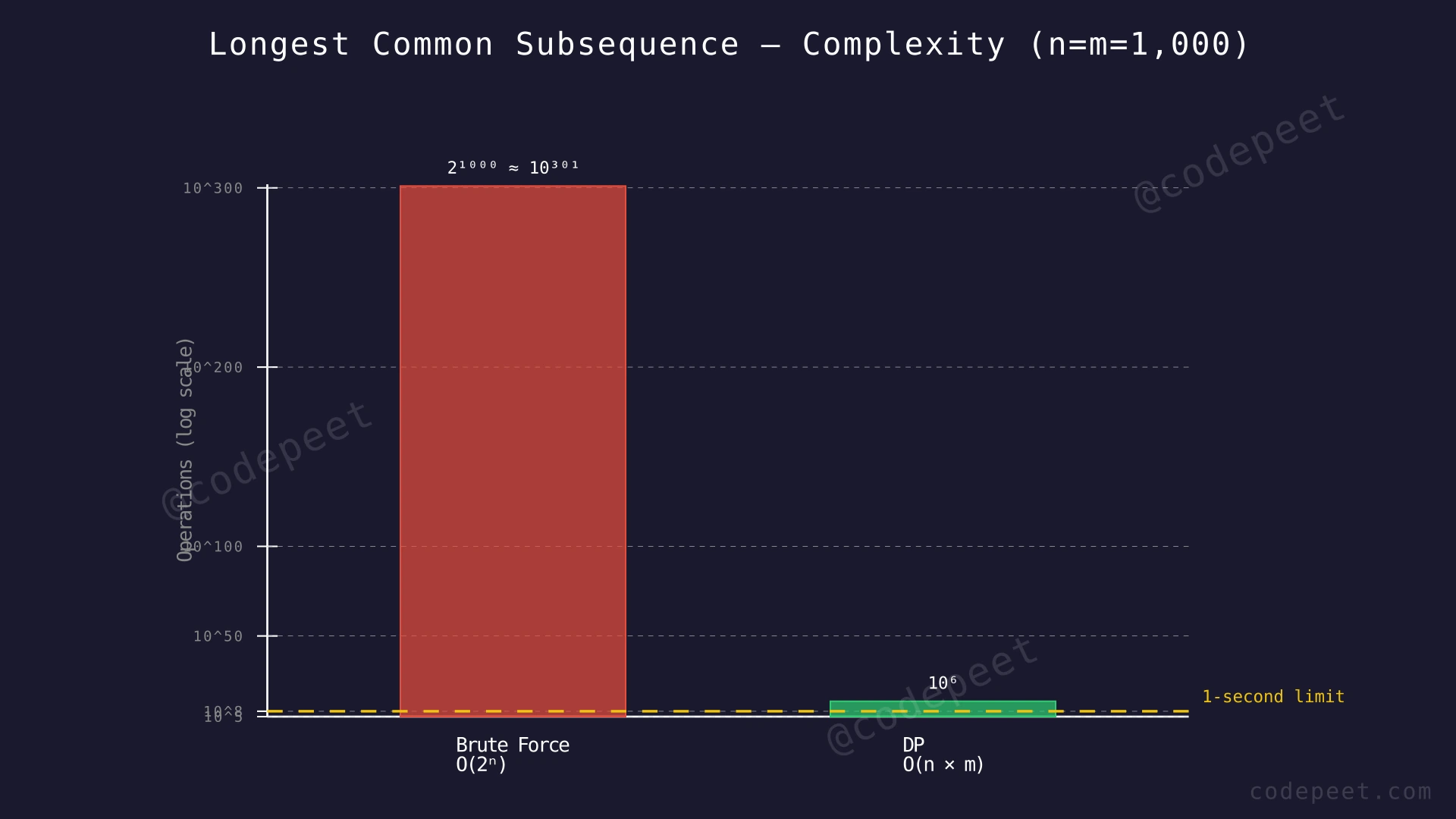
At each mismatch, the function makes two recursive calls — one reducing n by 1 and one reducing m by 1. In the worst case (when no characters match), this creates a binary tree of calls with depth min(n, m). The total number of calls can reach 2^min(n,m), which is exponential. For n = m = 1000, this is astronomically large and completely infeasible.
Space Complexity: O(min(n, m))
The recursion depth is at most min(n, m) because at each level of recursion, at least one of the string lengths decreases by 1. Each recursive call uses O(1) stack space, so the total stack space is O(min(n, m)).
Why This Approach Is Not Efficient
The recursive approach has a time complexity of O(2^min(n, m)), which grows exponentially. For the given constraints where n and m can each be up to 1000, the number of recursive calls would be 2^1000 — a number larger than the total atoms in the observable universe.
The root cause of this inefficiency is overlapping subproblems. As we saw in the trace above, lcs("A", "A") was computed twice in our tiny example. For larger inputs, the same subproblems are recalculated millions of times. The recursion tree branches into two calls at every mismatch, and many branches lead to identical subproblems.
The key observation is that there are only O(n × m) unique subproblems — one for each pair of prefix lengths (i, j) where 0 ≤ i ≤ n and 0 ≤ j ≤ m. If we store each result the first time we compute it and reuse it instead of recalculating, we can reduce the time from exponential to polynomial. This is the core idea behind Dynamic Programming.
Better Approach - Dynamic Programming (Tabulation)
Intuition
Since the recursive solution recomputes the same subproblems over and over, why not store each answer in a table and look it up whenever we need it? This is the bottom-up dynamic programming approach.
We create a 2D table dp where dp[i][j] stores the length of the LCS of the first i characters of s1 and the first j characters of s2. We fill this table row by row, starting from the simplest subproblems (empty prefixes) and building toward the full answer.
The recurrence is straightforward:
- If
s1[i-1] == s2[j-1](characters match):dp[i][j] = dp[i-1][j-1] + 1— extend the LCS of the previous prefixes by one. - If they don't match:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])— take the better of excluding the last character of either string.
Think of building a spreadsheet. Each cell asks: "What's the best LCS I can form using this much of s1 and this much of s2?" Each cell's answer only depends on the cell above, the cell to the left, and the cell diagonally above-left.
Step-by-Step Explanation
Let's trace through with s1 = "ABCB", s2 = "BDCB":
Step 1: Create a (5×5) DP table. Rows represent prefixes of s1: "", "A", "AB", "ABC", "ABCB". Columns represent prefixes of s2: "", "B", "BD", "BDC", "BDCB". Initialize row 0 and column 0 with zeros — an empty prefix has LCS 0 with any string.
Step 2: dp[1][1]: s1[0]='A' vs s2[0]='B'. No match. dp[1][1] = max(dp[0][1], dp[1][0]) = max(0, 0) = 0.
Step 3: Complete row 1: 'A' doesn't match any of 'B','D','C','B'. All cells dp[1][1] through dp[1][4] are 0.
Step 4: dp[2][1]: s1[1]='B' vs s2[0]='B'. Match! dp[2][1] = dp[1][0] + 1 = 0 + 1 = 1. First character of LCS found.
Step 5: dp[2][2]: 'B' vs 'D'. No match. dp[2][2] = max(dp[1][2]=0, dp[2][1]=1) = 1. The match from the left carries forward.
Step 6: dp[2][4]: 'B' vs 'B'. Match! dp[2][4] = dp[1][3] + 1 = 0 + 1 = 1.
Step 7: dp[3][3]: s1[2]='C' vs s2[2]='C'. Match! dp[3][3] = dp[2][2] + 1 = 1 + 1 = 2. The LCS of "ABC" and "BDC" has length 2 ("BC").
Step 8: dp[3][4]: 'C' vs 'B'. No match. dp[3][4] = max(dp[2][4]=1, dp[3][3]=2) = 2.
Step 9: dp[4][1]: s1[3]='B' vs s2[0]='B'. Match! dp[4][1] = dp[3][0] + 1 = 1.
Step 10: dp[4][4]: s1[3]='B' vs s2[3]='B'. Match! dp[4][4] = dp[3][3] + 1 = 2 + 1 = 3. This is the final answer!
Result: dp[4][4] = 3. The LCS of "ABCB" and "BDCB" has length 3 ("BCB").
LCS DP Table — Filling Cell by Cell — Watch how the 2D DP table is filled row by row. Each cell depends on the cell above, to the left, or diagonally above-left.
Algorithm
- Create a 2D table
dpof size (n+1) × (m+1), initialized to 0. - Row 0 and column 0 represent empty prefixes, so they remain 0.
- For each row
ifrom 1 to n:- For each column
jfrom 1 to m:- If
s1[i-1] == s2[j-1](characters match):dp[i][j] = dp[i-1][j-1] + 1 - Else (no match):
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
- If
- For each column
- Return
dp[n][m]— the LCS length of the full strings.
Code
class Solution {
public:
int lcs(int n, int m, string &s1, string &s2) {
// Create (n+1) x (m+1) table initialized to 0
vector<vector<int>> dp(n + 1, vector<int>(m + 1, 0));
// Fill the table row by row
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (s1[i - 1] == s2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
return dp[n][m];
}
};class Solution:
def lcs(self, n, m, s1, s2):
# Create (n+1) x (m+1) table initialized to 0
dp = [[0] * (m + 1) for _ in range(n + 1)]
# Fill the table row by row
for i in range(1, n + 1):
for j in range(1, m + 1):
if s1[i - 1] == s2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[n][m]class Solution {
public int lcs(int n, int m, String s1, String s2) {
// Create (n+1) x (m+1) table initialized to 0
int[][] dp = new int[n + 1][m + 1];
// Fill the table row by row
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (s1.charAt(i - 1) == s2.charAt(j - 1))
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
return dp[n][m];
}
}Complexity Analysis
Time Complexity: O(n × m)
We fill every cell of the (n+1) × (m+1) table exactly once. Each cell computation involves a character comparison and at most one max operation, both O(1). Total: (n+1) × (m+1) ≈ n × m operations. For n = m = 1000, this is 10^6 — easily handled within time limits.
Space Complexity: O(n × m)
We store the entire 2D table with (n+1) × (m+1) entries. For n = m = 1000, this requires about 10^6 integers ≈ 4 MB of memory.
Why This Approach Is Not Efficient
The tabulation approach runs in O(n × m) time, which handles n, m ≤ 1000 comfortably with at most 10^6 operations. However, it uses O(n × m) space for the entire 2D table.
Looking at how we fill the table, each cell dp[i][j] only depends on three cells: dp[i-1][j-1] (diagonal), dp[i-1][j] (above), and dp[i][j-1] (left). All three come from either the current row or the immediately previous row. This means when computing row i, we only need row i-1 — all earlier rows are never accessed again.
This insight allows us to reduce space from a full 2D table with n × m entries to just two 1D arrays of length m+1 — one for the previous row and one for the current row being computed. This cuts memory usage from O(n × m) to O(m), which can be significant when both strings are long.
Optimal Approach - Space-Optimized Dynamic Programming
Intuition
The core algorithm is identical to the tabulation approach — same recurrence, same time complexity. The only change is how we store intermediate results.
Instead of maintaining the full 2D table, we observe that filling row i only requires values from row i-1. So we keep just two arrays:
prev: the completely filled previous rowcurr: the row we are currently computing
After finishing each row, we swap prev = curr and reset curr for the next iteration.
Think of it like a printer that can only hold two sheets of paper at a time. You write on the current sheet by referring to the previous sheet. When done, you discard the old sheet, promote the current one, and grab a fresh blank. By the end, the last "previous" sheet has your answer.
Step-by-Step Explanation
Let's trace through with s1 = "ABCB", s2 = "BDCB" using two arrays:
Step 1: Initialize prev = [0, 0, 0, 0, 0]. Columns represent: ε, B, D, C, B.
Step 2: Process s1[0]='A': Compare 'A' against each character of 'BDCB'. No matches found. All curr values stay 0. Swap: prev = [0, 0, 0, 0, 0].
Step 3: Process s1[1]='B', j=1: 'B'='B' → curr[1] = prev[0] + 1 = 0 + 1 = 1. First match!
Step 4: j=2: 'B'≠'D' → curr[2] = max(prev[2]=0, curr[1]=1) = 1. The match propagates.
Step 5: j=3: 'B'≠'C' → curr[3] = max(prev[3]=0, curr[2]=1) = 1.
Step 6: j=4: 'B'='B' → curr[4] = prev[3] + 1 = 0 + 1 = 1.
Step 7: Swap: prev = [0, 1, 1, 1, 1].
Step 8: Process s1[2]='C', j=1: 'C'≠'B' → curr[1] = max(prev[1]=1, curr[0]=0) = 1.
Step 9: j=3: 'C'='C' → curr[3] = prev[2] + 1 = 1 + 1 = 2. LCS grows to 2!
Step 10: j=4: 'C'≠'B' → curr[4] = max(prev[4]=1, curr[3]=2) = 2.
Step 11: Swap: prev = [0, 1, 1, 2, 2].
Step 12: Process s1[3]='B', j=1: 'B'='B' → curr[1] = prev[0] + 1 = 1.
Step 13: j=3: 'B'≠'C' → curr[3] = max(prev[3]=2, curr[2]=1) = 2.
Step 14: j=4: 'B'='B' → curr[4] = prev[3] + 1 = 2 + 1 = 3. Final answer!
Result: prev[4] = 3. Computed using only two arrays of size 5 instead of a 5×5 table.
Space-Optimized LCS — Two Rolling Arrays — Watch how we maintain only two rows (prev and curr) instead of the full 2D table, computing the LCS with O(m) space.
Algorithm
- Create two arrays
prevandcurr, each of size m+1, initialized to 0. - For each character
s1[i-1](i from 1 to n):- For each character
s2[j-1](j from 1 to m):- If
s1[i-1] == s2[j-1]:curr[j] = prev[j-1] + 1 - Else:
curr[j] = max(prev[j], curr[j-1])
- If
- After processing all columns: swap
prevandcurr, resetcurrto zeros.
- For each character
- Return
prev[m].
Code
class Solution {
public:
int lcs(int n, int m, string &s1, string &s2) {
vector<int> prev(m + 1, 0), curr(m + 1, 0);
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (s1[i - 1] == s2[j - 1])
curr[j] = prev[j - 1] + 1;
else
curr[j] = max(prev[j], curr[j - 1]);
}
swap(prev, curr);
fill(curr.begin(), curr.end(), 0);
}
return prev[m];
}
};class Solution:
def lcs(self, n, m, s1, s2):
prev = [0] * (m + 1)
curr = [0] * (m + 1)
for i in range(1, n + 1):
for j in range(1, m + 1):
if s1[i - 1] == s2[j - 1]:
curr[j] = prev[j - 1] + 1
else:
curr[j] = max(prev[j], curr[j - 1])
prev, curr = curr, [0] * (m + 1)
return prev[m]import java.util.Arrays;
class Solution {
public int lcs(int n, int m, String s1, String s2) {
int[] prev = new int[m + 1];
int[] curr = new int[m + 1];
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (s1.charAt(i - 1) == s2.charAt(j - 1))
curr[j] = prev[j - 1] + 1;
else
curr[j] = Math.max(prev[j], curr[j - 1]);
}
int[] temp = prev;
prev = curr;
curr = temp;
Arrays.fill(curr, 0);
}
return prev[m];
}
}Complexity Analysis
Time Complexity: O(n × m)
The time complexity is identical to the tabulation approach. We still iterate through every (i, j) pair exactly once, performing O(1) work per cell. The total operations are n × m.
Space Complexity: O(m)
Instead of storing the full (n+1) × (m+1) table, we only keep two arrays of size m+1. This reduces space from O(n × m) to O(m). For n = m = 1000, this means storing ~1000 integers instead of ~10^6, reducing memory by a factor of 1000.
Note: We can further optimize by choosing the shorter string as s2 to minimize the array size to O(min(n, m)).