youtube
Introduction
"Design YouTube" is one of the most challenging system design interview questions because it sits at the intersection of massive storage (500+ hours of video uploaded every minute), compute-intensive processing (video transcoding), global content delivery (CDN at planetary scale), and real-time user experience (instant playback with adaptive quality).
The surface problem — "let users upload and watch videos" — is deceptively simple, but the engineering behind YouTube is staggering:
- Storage: YouTube stores over 1 exabyte of video data. Every minute, 500+ hours of new video are uploaded. Naive storage would bankrupt any company — YouTube uses tiered storage, aggressive transcoding, and intelligent CDN caching to manage costs.
- Transcoding: A single uploaded video at 4K produces 10-20 renditions (different resolutions × different codecs). A 10-minute 4K video might generate 50GB+ of transcoded output. YouTube operates one of the world's largest transcoding pipelines.
- Content Delivery: Serving 1 billion hours of video daily requires a CDN that spans every continent. YouTube caches the top ~20% of videos (which serve ~80% of views) at edge locations, while long-tail content is served from origin.
- Adaptive Bitrate Streaming: Viewers switch between Wi-Fi and cellular, between desktops and phones. The player must seamlessly adapt quality in real time using protocols like DASH or HLS, without rebuffering.
- Upload Experience: Creators expect to upload a 10GB file over a potentially flaky connection. The system must support resumable, chunked uploads so that a failure at 80% doesn't waste the first 8GB.
This editorial designs a YouTube-scale video platform from first principles — from the upload pipeline through the transcoding DAG, CDN distribution, and adaptive playback — progressively evolving the architecture from a naive single-server design to a globally distributed system serving billions of views.
Functional Requirements
Viewer Requirements (Read Path)
- Watch videos — Users can stream any published video with immediate playback. The system adapts video quality based on network conditions and device capability.
- Search and discover — Users can find videos through search, recommendations, and browsing. (Search and recommendation are out of scope for this design — we focus on the core upload/stream infrastructure.)
Creator Requirements (Write Path)
- Upload videos — Creators can upload video files of any format and size (up to 256GB). Uploads must be resumable — interrupting a 10GB upload at 80% should not waste the first 8GB.
- Video processing — After upload, the system automatically transcodes the video into multiple resolutions and formats, generates thumbnails, and performs content safety checks.
- Publish and manage — Creators can set titles, descriptions, tags, and visibility (public, unlisted, private). The video becomes available for viewing after processing completes.
Out of Scope
- Comments and social features (likes, shares, subscriptions)
- Search engine and recommendation algorithm
- Live streaming (fundamentally different architecture)
- Monetization (ads, payments, creator fund)
- Content moderation ML pipeline (we cover the integration point, not the model)
- User authentication and authorization
- Analytics dashboard for creators
Non-Functional Requirements
| Requirement | Target | Reasoning |
|---|---|---|
| Scale (DAU) | 100M daily active users | YouTube-scale platform |
| Read:Write ratio | 100:1 | Vastly more viewers than creators |
| Video watches/day | 5 per user avg → 500M watches/day | Average session |
| Video uploads/day | ~100K new videos/day | Assuming 100K active creators/day |
| Playback start latency | < 2 seconds to first frame | Users abandon after 2s buffer |
| Upload reliability | Resumable, chunked | Large files over unreliable networks |
| Processing latency | < 30 minutes for 1080p video | Creators expect fast publish |
| Availability | 99.99% for playback | Revenue loss: ~$100K per minute of downtime |
| Durability | 99.999999999% (11 nines) | Original uploads must never be lost |
| Adaptive streaming | Seamless quality switching | Network conditions change constantly |
| Global delivery | < 100ms to nearest CDN edge | Users are worldwide |
The fundamental tension in YouTube's architecture:
The write path (upload → transcode → distribute) is compute-expensive and slow (minutes to hours). The read path (search → stream) must be instant (sub-second playback start). This asymmetry drives the entire architecture: we invest heavily in pre-processing (transcoding into all formats ahead of time) so that reads are just serving pre-computed static files from CDN edge locations.
This is the "heavy write, light read" pattern — the opposite of a chat app (where both paths must be real-time).
Resource Estimation
Assumptions:
- 100M daily active users
- 5 video watches per user per day
- 100K new video uploads per day
- Average original video size: 500MB
- Average video duration: 10 minutes
- Read:Write ratio: 100:1
- Data retention: 10 years (original + transcoded)
- Transcoding expands storage ~5× (multiple resolutions + formats)
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily video watches | 100M × 5 | 500M/day |
| Watch QPS (avg) | 500M ÷ 86,400 | ~5,800/sec |
| Watch QPS (peak, 5×) | 5,800 × 5 | ~29,000/sec |
| Upload QPS | 100K ÷ 86,400 | ~1.2/sec |
| Upload QPS (peak, 10×) | 1.2 × 10 | ~12/sec |
Note: Upload QPS is low, but each upload triggers a heavy processing pipeline (transcoding, thumbnail generation, content safety), so the compute load is enormous.
Storage Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily upload volume | 100K × 500MB | ~50 TB/day (originals) |
| Daily transcoded volume | 50 TB × 5 (multi-resolution) | ~250 TB/day (all formats) |
| 10-year total (originals) | 50 TB × 365 × 10 | ~183 PB |
| 10-year total (all formats) | 250 TB × 365 × 10 | ~912 PB ≈ ~1 EB |
| Metadata DB | 100K videos/day × 365 × 10 × 2KB | ~7.3 TB |
Bandwidth Estimation
| Metric | Calculation | Result |
|---|---|---|
| Streaming bandwidth (avg) | 5,800 req/s × 5 Mbps (720p avg) | ~29 Gbps |
| Streaming bandwidth (peak) | 29,000 req/s × 5 Mbps | ~145 Gbps |
| Upload bandwidth | 12/s × 500MB / 300s avg upload ≈ 20 MB/s | ~160 Mbps |
The bandwidth numbers are why CDN is not optional — serving 145 Gbps from origin servers would require thousands of servers. CDNs distribute this load across thousands of edge locations worldwide, each serving a fraction of the total traffic.
API Design
The API is split into two paths reflecting the fundamental asymmetry: the write path (upload and processing) and the read path (streaming).
Uploading is a two-phase process: (1) initiate upload and get a signed URL, (2) upload the file directly to object storage using that signed URL.
# Phase 1: Initiate upload
POST /api/videos/upload/initiate
Authorization: Bearer {token}
Content-Type: application/json
{
"title": "How to Design YouTube",
"description": "System design walkthrough",
"visibility": "public",
"tags": ["system-design", "interview"],
"file_size": 524288000,
"content_type": "video/mp4"
}
Response:
{
"video_id": "vid-a8f23c91",
"signed_upload_url": "https://storage.googleapis.com/uploads/vid-a8f23c91?X-Goog-Signature=...",
"url_expires_at": "2025-03-17T15:30:00Z"
}
# Phase 2: Upload file directly to object storage
PUT {signed_upload_url}
Content-Type: video/mp4
Content-Length: 524288000
[binary video data]
# Phase 3: Notify upload completion
POST /api/videos/{video_id}/upload-complete
Authorization: Bearer {token}
Response: { "status": "processing", "video_id": "vid-a8f23c91" }Streaming is served via CDN. The API Gateway returns a manifest file (DASH/HLS) that the video player uses to request individual segments.
# Get video metadata + stream URL
GET /api/videos/{video_id}
Authorization: Bearer {token}
Response:
{
"video_id": "vid-a8f23c91",
"title": "How to Design YouTube",
"description": "System design walkthrough",
"duration_seconds": 600,
"stream_url": "https://cdn.youtube.com/vid-a8f23c91/manifest.mpd",
"thumbnail_url": "https://cdn.youtube.com/vid-a8f23c91/thumb.jpg",
"available_qualities": ["2160p", "1080p", "720p", "480p", "360p"],
"upload_date": "2025-03-17T14:30:00Z",
"view_count": 1245890,
"status": "published"
}
# The video player then fetches the DASH manifest:
GET https://cdn.youtube.com/vid-a8f23c91/manifest.mpd
# And individual segments:
GET https://cdn.youtube.com/vid-a8f23c91/720p/segment-001.m4s
GET https://cdn.youtube.com/vid-a8f23c91/720p/segment-002.m4s
# ... (player requests segments sequentially as playback progresses)Signed URLs are a critical architectural choice. Instead of streaming the (potentially massive) video file through our application servers, the client uploads directly to object storage (S3, GCS, Azure Blob).
Benefits:
- Offloads bandwidth: Application servers handle only lightweight metadata API calls, not multi-GB file transfers. This dramatically reduces the number of application servers needed.
- Scale: Object storage services (S3, GCS) are designed to handle massive concurrent uploads natively — they scale horizontally without us managing any upload servers.
- Security: The signed URL contains a cryptographic signature with an expiration time. Only the intended user can upload to the specific path, and only within the time window.
- Resumability: Object storage APIs (e.g., S3 multipart upload, GCS resumable upload) natively support chunked, resumable uploads. The client can resume from the last chunk on failure.
How signing works:
- Application server generates a pre-signed URL using a service account key.
- The URL encodes: bucket, object path, allowed HTTP method, expiration time, and HMAC signature.
- Object storage validates the signature on each request — no further authentication needed.
- After expiration, the URL stops working.
| Feature | DASH (Dynamic Adaptive Streaming over HTTP) | HLS (HTTP Live Streaming) |
|---|---|---|
| Standard | MPEG-DASH (ISO/IEC 23009-1) | Apple proprietary (widely adopted) |
| Manifest format | MPD (XML) | M3U8 (playlist) |
| Codec flexibility | Any codec (H.264, H.265, VP9, AV1) | Primarily H.264/H.265 |
| DRM | CENC (Common Encryption) — supports Widevine, PlayReady | FairPlay (Apple) + CENC |
| Segment duration | Configurable (typically 2-6s) | Typically 6s |
| Browser support | Via MSE API (all modern browsers) | Native on Safari; MSE elsewhere |
| Used by | YouTube, Netflix | Apple TV+, Twitch |
YouTube uses DASH for most playback. The player downloads the MPD manifest, which lists all available quality levels and their segment URLs. The client-side Adaptive Bitrate (ABR) algorithm monitors download speed and buffer level to decide which quality to request next.
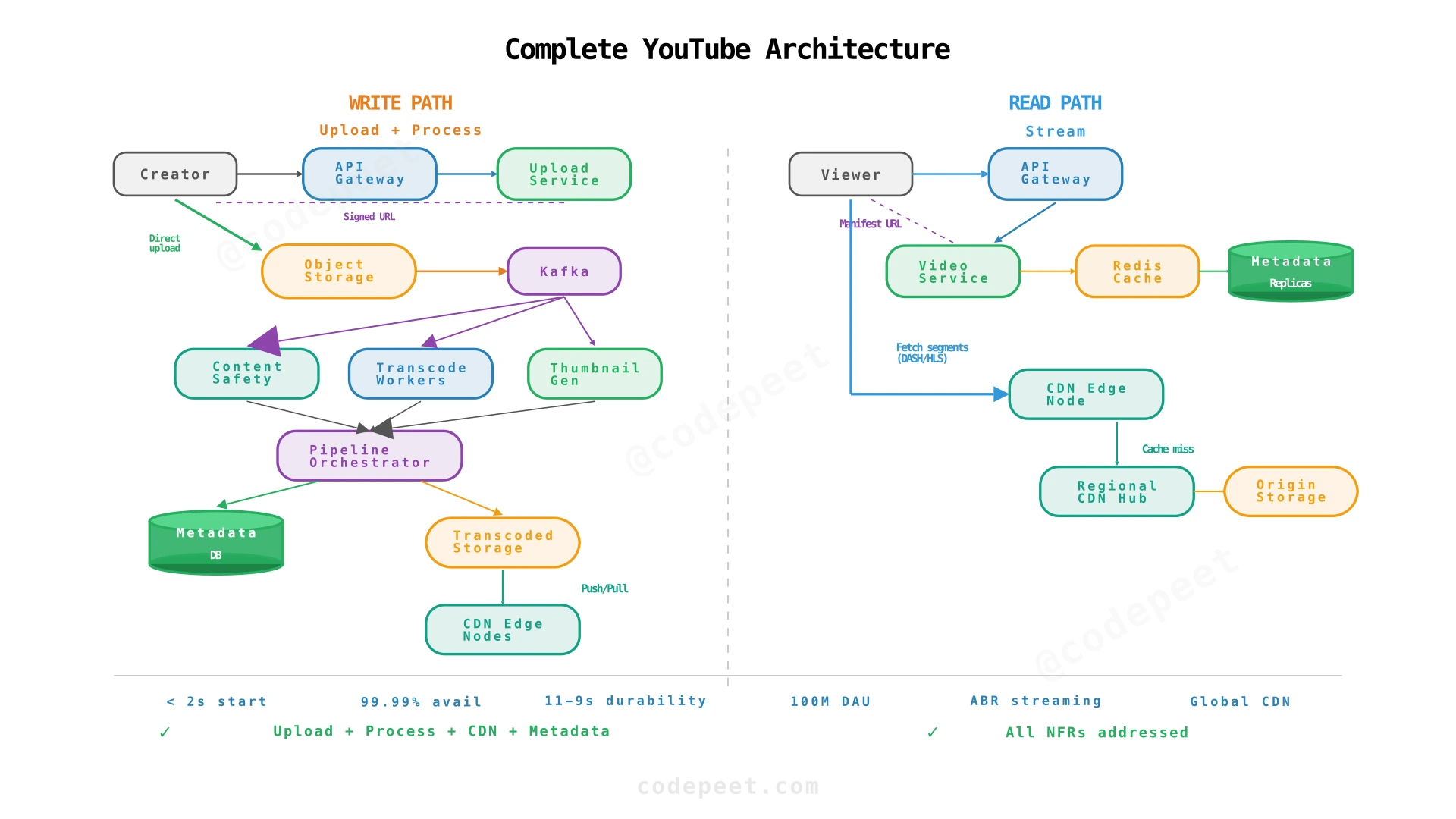
High-Level Design
We build the architecture incrementally, starting from the simplest possible video platform and evolving it as we discover problems that need solving. Each step addresses a specific non-functional requirement that the current design fails to meet.
Step 1: Naive Design — Single Server Upload & Stream
Starting point: The simplest video platform. Creators upload videos to a single server, which stores the raw file on disk. Viewers request the video, and the server streams it directly back. No transcoding, no CDN, no processing.
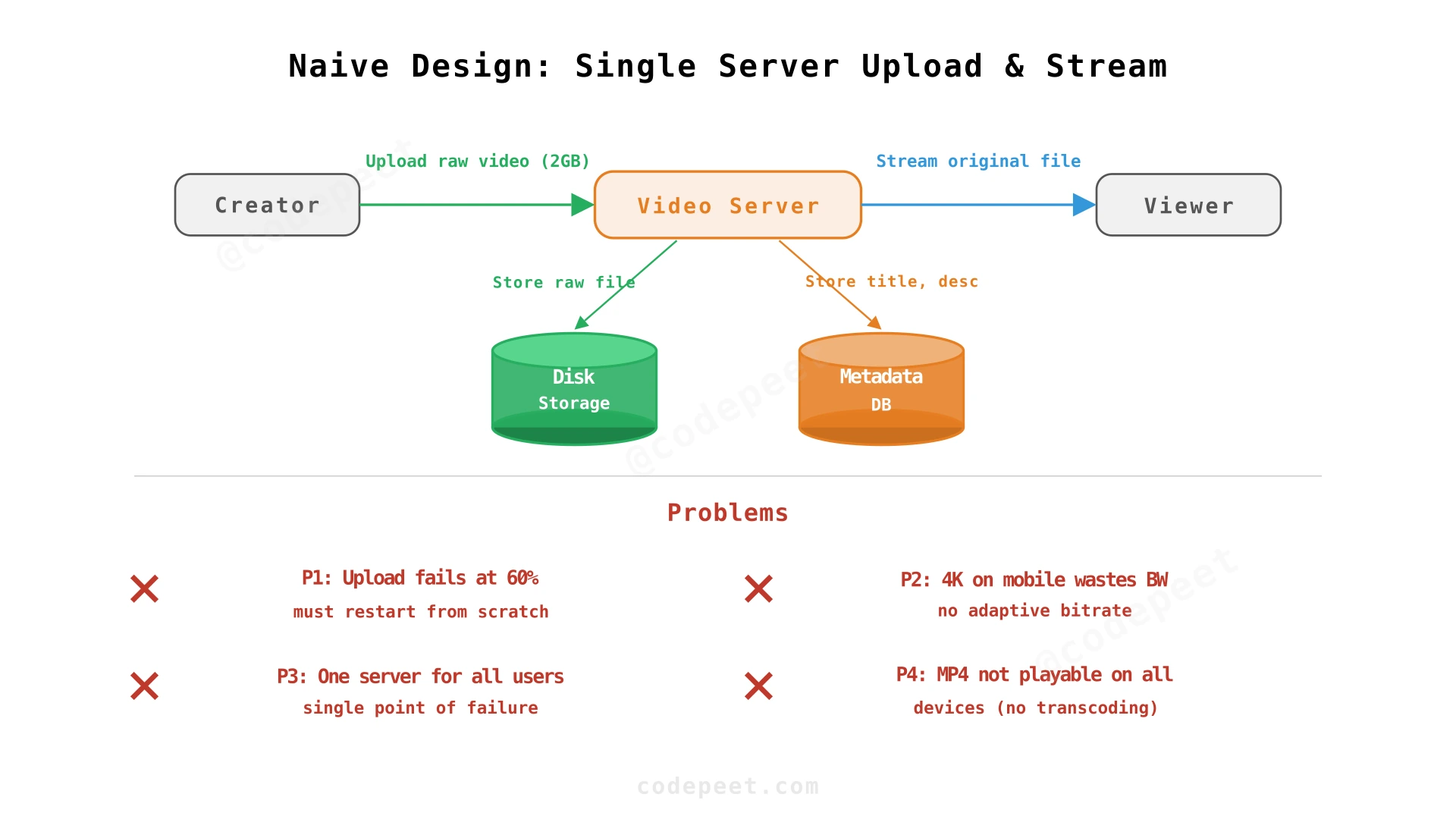
How it works:
- Creator uploads the raw video file to the Video Server via HTTP.
- Video Server writes the file to local disk.
- Video Server records metadata (title, description, file path) in the database.
- Viewers request the video → server reads from disk and streams the raw file.
Four critical flaws:
| Problem | NFR Violated | Impact |
|---|---|---|
| No resumable upload | Upload reliability | A 2GB upload that fails at 60% must restart. On mobile networks, large uploads may never complete. |
| No transcoding | Adaptive streaming, device compatibility | The raw 4K file is served to everyone — mobile users on 3G get a 12 Mbps stream they can't play. Apple devices may not support the uploaded codec. |
| Single server for all viewers | Latency, availability, scalability | A viewer in Tokyo gets their video from a server in Virginia — 200ms+ latency, constant buffering. Server overload during viral videos. |
| No content processing | Content safety | No copyright check, no content moderation, no thumbnail generation. |
The most fundamental limitation: we're streaming the original file in its original format. We need to transform it into multiple formats and distribute it globally.
Step 2: Signed URL Upload + Object Storage — Decoupling Upload from Application
Problem being solved: The application server is the bottleneck for uploads. Streaming multi-GB files through the application server wastes bandwidth, ties up server threads, and makes resumable uploads difficult to implement.
Solution: Instead of uploading through the application server, the creator uploads directly to object storage (S3/GCS) using a signed URL. The application server only generates the signed URL (lightweight) and records metadata.
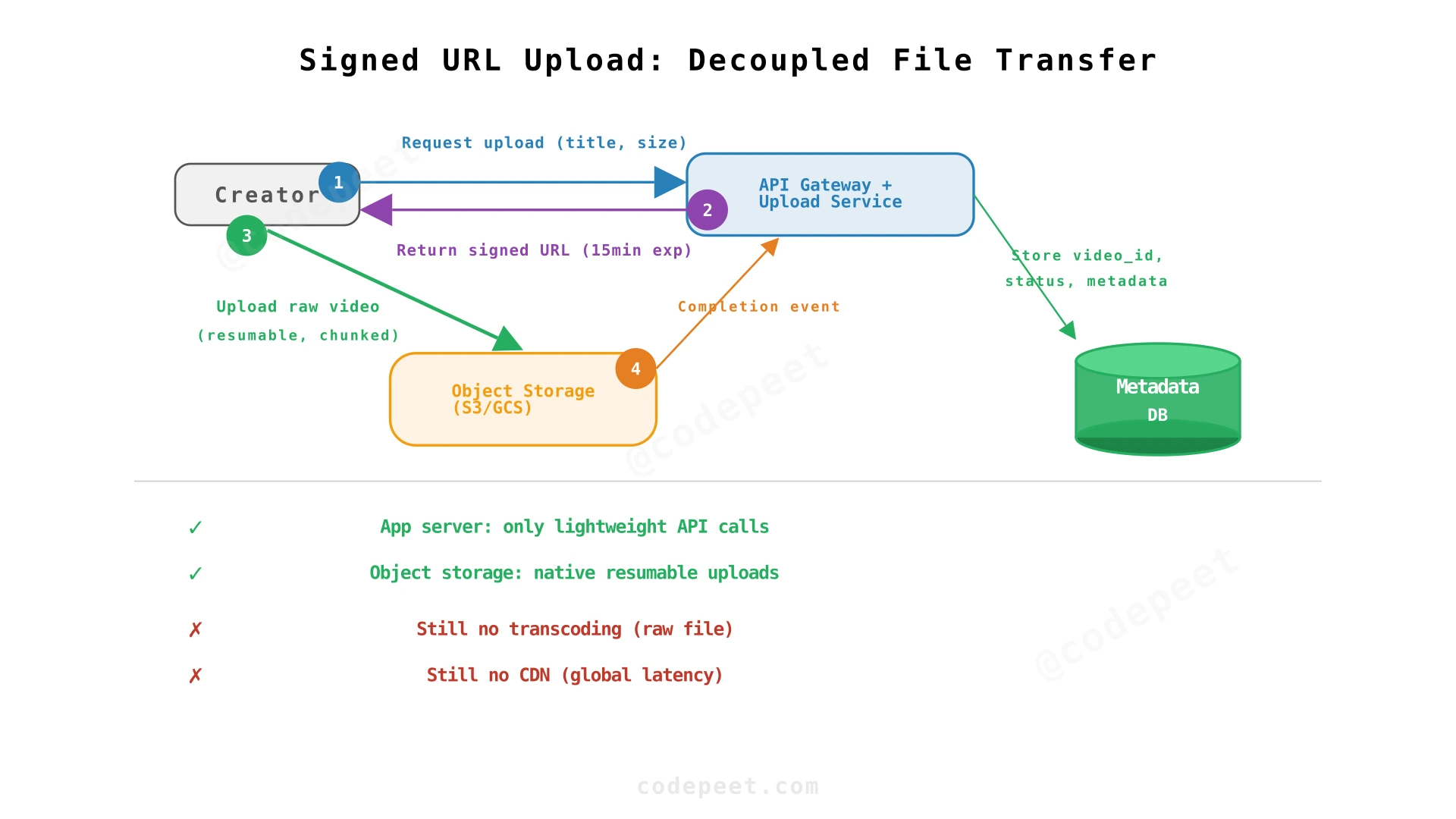
How it works:
- Creator calls
POST /api/videos/upload/initiatewith video metadata. - Upload Service generates a signed URL with a cryptographic signature, granting permission to upload to a specific path in object storage, with expiration (typically 15-60 minutes).
- Creator uses the signed URL to upload the raw video directly to object storage (S3 multipart upload or GCS resumable upload).
- Object storage notifies the Upload Service (via webhook/event) when the upload completes.
- Upload Service records the video metadata and triggers the processing pipeline.
Why this matters at scale:
- The application server processes ~12 upload requests/sec at peak — each is a lightweight JSON API call (~1KB). Without signed URLs, it would need to handle 12 concurrent multi-GB streams — requiring massive bandwidth and server resources.
- Object storage services (S3, GCS) are designed for exactly this pattern — they scale horizontally to handle thousands of concurrent uploads natively.
What we've solved:
- ✅ Upload reliability: Object storage provides chunked, resumable uploads natively. A 10GB upload that fails at 80% resumes from the last completed chunk.
- ✅ Server decoupling: Application servers handle only lightweight API calls, not file streams.
What's still broken:
- ❌ No transcoding: Raw 4K video in creator's codec served to all viewers.
- ❌ No CDN: All viewers fetch from the same origin — global latency.
- ❌ No content safety: Pirated or harmful content uploaded without any check.
Step 3: Video Processing Pipeline — Transcoding, Safety, and Thumbnails
Problem being solved: The raw uploaded video is in a single format and resolution. Viewers on different devices and network speeds need different versions. Content must be checked for copyright and safety before publishing.
Solution: After upload completion, trigger a video processing pipeline — a DAG of tasks that transforms the raw video into multiple formats, resolutions, and codecs, while simultaneously running content safety checks and generating thumbnails.
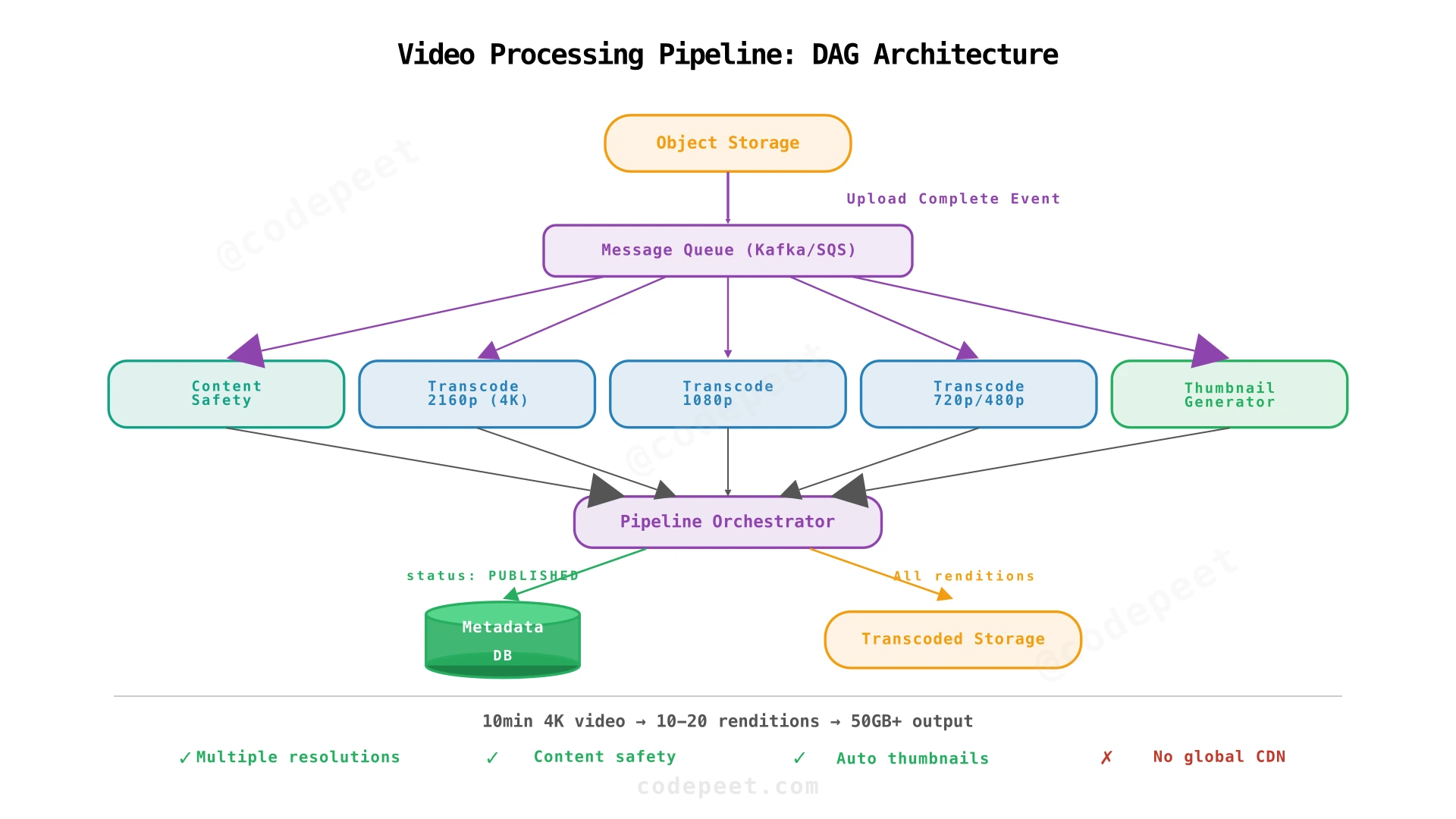
The processing DAG:
The pipeline is structured as a Directed Acyclic Graph (DAG) — tasks that can run in parallel do, while some tasks have dependencies:
Upload Complete
│
├──→ Content Safety Check ────────────────┐
│ (copyright, nudity, violence) │
│ │
├──→ Transcode to 2160p (H.264 + VP9) ───→│
├──→ Transcode to 1080p (H.264 + VP9) ───→├──→ Pipeline Orchestrator
├──→ Transcode to 720p (H.264 + VP9) ───→│ │
├──→ Transcode to 480p (H.264) ───→│ ├──→ Update metadata (PUBLISHED)
├──→ Transcode to 360p (H.264) ───→│ ├──→ Push to CDN
│ │ └──→ Notify creator
└──→ Generate thumbnails ─────────────────┘
Transcoding details:
- Each resolution is transcoded into multiple codecs: H.264 (universal), VP9 (better compression, used by Chrome), and optionally AV1 (best compression, but slow to encode).
- Each transcoded file is further split into segments (2-6 seconds each) for adaptive bitrate streaming. A 10-minute video at 1080p/H.264 produces ~100-300 segments.
- A DASH manifest (
.mpd) or HLS playlist (.m3u8) is generated listing all available quality levels and their segment URLs.
What we've solved:
- ✅ Device compatibility: Multiple codecs ensure playback on any device and browser.
- ✅ Adaptive streaming: Multiple resolutions + segments enable ABR.
- ✅ Content safety: Copyright + community guideline checks before publishing.
- ✅ Thumbnails: Auto-generated from video frames.
What's still broken:
- ❌ Global delivery: All transcoded segments sit in origin storage. A viewer in Tokyo still fetches from Virginia — high latency, buffering.
- ❌ Metadata management: No database design for tracking videos, stats, and processing state.
Transcoding is CPU-intensive because it involves:
- Decoding the original compressed video frame-by-frame.
- Scaling each frame to the target resolution.
- Re-encoding with the target codec at the target bitrate.
A single 10-minute 4K video transcoded to 5 resolutions × 2 codecs = 10 renditions. Each rendition may take 2-10× the video duration to encode (depending on codec and hardware). That's 200-1,000 minutes of CPU time for one 10-minute video.
At 100K uploads/day, that's 20M-100M CPU-minutes/day — requiring thousands of transcode workers. This is why YouTube uses hardware acceleration (GPU/ASIC encoding) and distributed transcoding (splitting a single video across multiple workers by time segments).
Step 4: CDN Distribution — Serving Video at the Edge
Problem being solved: Transcoded video segments sit in origin storage (S3/GCS in a single region). Viewers worldwide experience high latency and buffering because every segment request travels to the origin.
Solution: Distribute transcoded segments to a Content Delivery Network (CDN) with edge locations worldwide. Popular videos are cached at edge nodes closest to viewers. Origin is only contacted on cache misses.
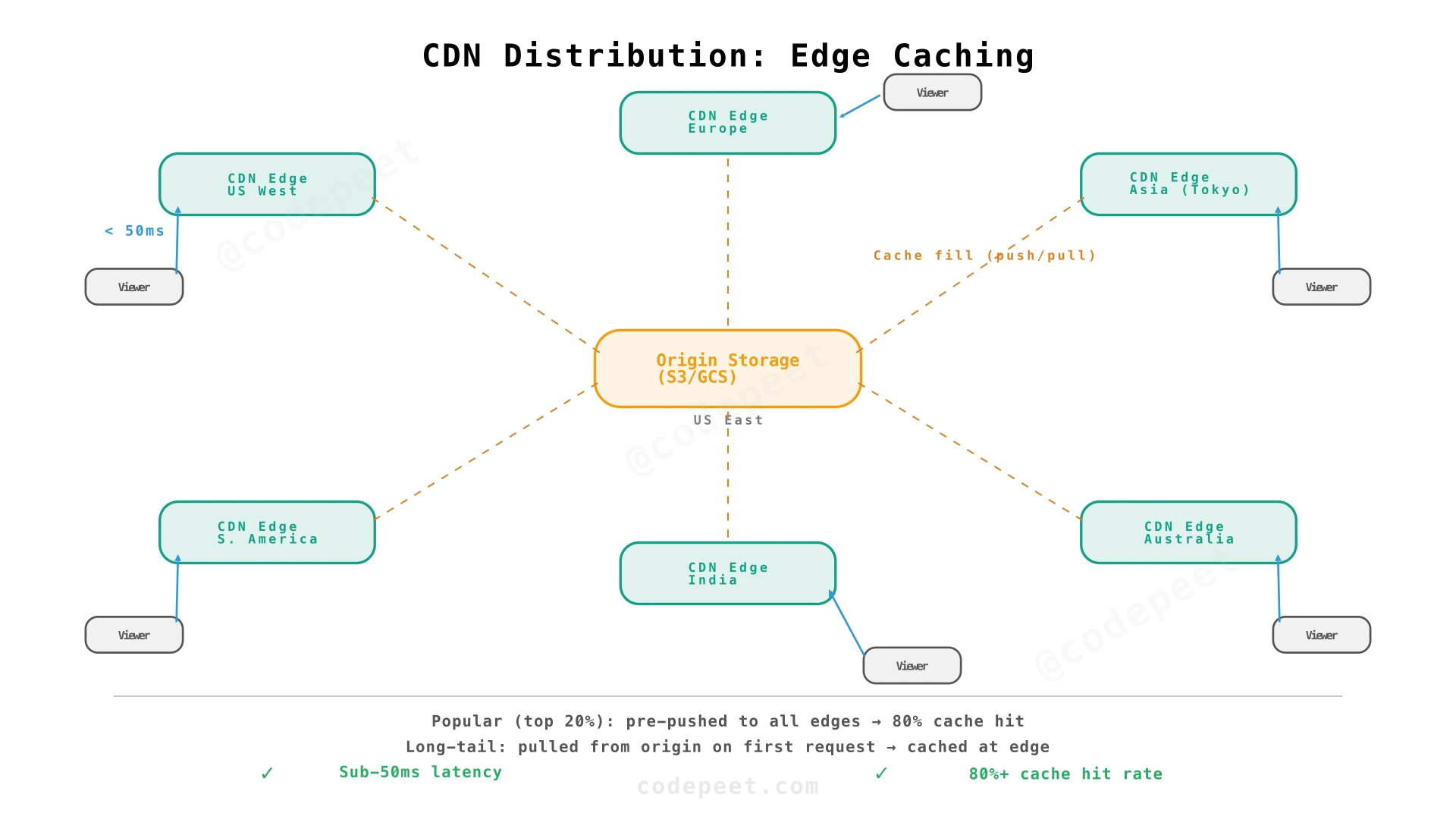
How CDN caching works for video:
| Strategy | How It Works | Used For |
|---|---|---|
| Push-based (proactive) | After transcoding, push popular segments to all edge locations | Trending/viral videos, new releases from top creators |
| Pull-based (reactive) | First viewer request triggers a cache fill from origin; subsequent requests served from cache | Long-tail content (millions of videos with few views) |
| Tiered caching | Edge → Regional hub → Origin (3-level hierarchy) | Reduces origin load; regional hubs absorb cache misses from multiple edges |
The 80/20 rule at YouTube scale:
- ~20% of videos account for ~80% of views (viral content, popular creators).
- These videos are proactively pushed to all CDN edge locations.
- The remaining 80% of videos (long tail) are pulled on demand — the first viewer triggers a cache fill; subsequent viewers in that region are served from cache.
What we've solved:
- ✅ Global low latency: Sub-50ms to nearest CDN edge.
- ✅ Bandwidth distribution: Origin only handles the initial cache fill; edges handle all viewer traffic.
- ✅ Scalability for viral content: CDN absorbs traffic spikes for popular videos.
What's still remaining:
- ❌ Database design: No structured system for video metadata, stats, and processing state.
- ❌ Metadata scalability: How to handle 5,800 QPS of metadata reads?
Step 5: Complete Architecture — All NFRs Addressed
The final architecture adds the metadata layer, database design, and caching to complete the system.
-- Video Table
CREATE TABLE videos (
video_id UUID PRIMARY KEY,
uploader_id UUID NOT NULL REFERENCES users(user_id),
title TEXT NOT NULL,
description TEXT,
duration_sec INTEGER,
original_path TEXT NOT NULL, -- S3 path to original upload
manifest_path TEXT, -- DASH manifest URL (set after transcoding)
thumbnail_path TEXT,
encoding_format TEXT, -- original codec
file_size BIGINT,
status TEXT NOT NULL DEFAULT 'uploading', -- uploading|processing|published|failed|banned
visibility TEXT NOT NULL DEFAULT 'private', -- public|unlisted|private
upload_date TIMESTAMPTZ DEFAULT NOW(),
published_date TIMESTAMPTZ
);
-- Users Table
CREATE TABLE users (
user_id UUID PRIMARY KEY,
username TEXT UNIQUE NOT NULL,
email TEXT UNIQUE NOT NULL,
join_date TIMESTAMPTZ DEFAULT NOW(),
last_login TIMESTAMPTZ
);
-- Video Stats Table (denormalized for fast reads)
CREATE TABLE video_stats (
video_id UUID PRIMARY KEY REFERENCES videos(video_id),
view_count BIGINT DEFAULT 0,
like_count BIGINT DEFAULT 0,
dislike_count BIGINT DEFAULT 0,
share_count BIGINT DEFAULT 0,
total_watch_sec BIGINT DEFAULT 0
);
-- Transcoding Jobs Table (tracks processing pipeline state)
CREATE TABLE transcoding_jobs (
job_id UUID PRIMARY KEY,
video_id UUID REFERENCES videos(video_id),
resolution TEXT NOT NULL, -- 2160p, 1080p, 720p, etc.
codec TEXT NOT NULL, -- h264, vp9, av1
status TEXT DEFAULT 'pending', -- pending|running|completed|failed
output_path TEXT,
started_at TIMESTAMPTZ,
completed_at TIMESTAMPTZ
);Database design rationale:
| Table | Why Separate? | Sharding Strategy |
|---|---|---|
| videos | Core metadata — read on every video page view | Shard by video_id (even distribution) |
| users | User profile data — relatively stable, low-volume | Shard by user_id |
| video_stats | High-write counters — updated on every view, like, share | Shard by video_id; use Redis counters with periodic flush to DB |
| transcoding_jobs | Processing pipeline state — ephemeral, high-churn | Shard by video_id for co-location with video metadata |
Why PostgreSQL for metadata over NoSQL? The relationships are inherently relational (videos belong to users, jobs belong to videos), and we need ACID for status transitions (uploading → processing → published). The read volume (~5,800 QPS) is well within PostgreSQL's capability with read replicas and Redis caching for hot data.
NFR Scorecard — All Requirements Met
| NFR | Target | How It's Achieved |
|---|---|---|
| 100M DAU, 29K peak QPS | Horizontal scaling | CDN absorbs 80%+ of read traffic; services + DB scale horizontally |
| < 2s playback start | CDN edge proximity | Video segments pre-cached at edge nodes < 50ms from viewers |
| Resumable uploads | Signed URL + object storage | S3/GCS multipart upload with chunk-level resume |
| Adaptive streaming | Multi-resolution transcoding | 5+ quality levels × 2 codecs; DASH/HLS manifest with ABR |
| < 30 min processing | Parallel transcoding DAG | GPU workers transcode in parallel; pipeline orchestrator tracks state |
| 99.99% playback availability | CDN + multi-region | CDN serves from cache even if origin is down; regional failover |
| 11-nines durability | Object storage replication | S3/GCS provides 11-nines durability with 3× replication |
| Content safety | Processing pipeline | Content safety checks run before video status transitions to PUBLISHED |
| Global < 100ms edge latency | CDN edge network | Thousands of edge locations; tiered caching (edge → regional → origin) |
| Component | Responsibility | Scaling Strategy |
|---|---|---|
| API Gateway | Auth, rate limiting, routing | Horizontal: stateless; load-balanced |
| Upload Service | Generate signed URLs, track upload state | Horizontal: stateless |
| Object Storage (S3/GCS) | Store original + transcoded files | Managed service; auto-scaling |
| Message Queue (Kafka) | Decouple upload from processing | Partitioned by video_id |
| Transcoding Workers | Convert video to multiple formats | Horizontal: GPU/CPU worker fleet; auto-scale on queue depth |
| Content Safety Workers | Copyright + guideline checks | Horizontal: ML inference workers |
| Pipeline Orchestrator | Track DAG completion, update metadata | Stateful: tracks job state per video |
| Metadata DB (PostgreSQL) | ACID metadata storage | Primary + read replicas; sharded by video_id |
| Redis Cache | Hot metadata (popular video info) | Redis Cluster; TTL-based invalidation |
| CDN | Edge caching for video segments | Managed service (CloudFront, Akamai, Google CDN) |
Deep Dives
Video Transcoding — Codec Selection and Quality Ladder
Video transcoding converts a raw uploaded video into multiple formats (codecs) and resolutions to ensure compatibility across all devices and network conditions. This is the most compute-intensive operation in YouTube's entire infrastructure.
What is transcoding?
Transcoding involves three steps per output rendition:
- Decode the original compressed video frame-by-frame.
- Scale each frame to the target resolution (e.g., 4K → 720p).
- Re-encode with the target codec at the target bitrate.
The Quality Ladder
YouTube generates multiple renditions, known as the quality ladder:
| Resolution | H.264 Bitrate | VP9 Bitrate | AV1 Bitrate | Use Case |
|---|---|---|---|---|
| 2160p (4K) | 35-45 Mbps | 18-25 Mbps | 12-18 Mbps | 4K TVs, high-end desktops |
| 1440p (2K) | 16-24 Mbps | 10-14 Mbps | 7-10 Mbps | Gaming monitors |
| 1080p (FHD) | 8-12 Mbps | 5-7 Mbps | 3-5 Mbps | Default desktop quality |
| 720p (HD) | 5-7 Mbps | 3-4 Mbps | 2-3 Mbps | Default mobile quality |
| 480p (SD) | 2.5-4 Mbps | 1.5-2.5 Mbps | 1-1.5 Mbps | Low-bandwidth / developing markets |
| 360p | 1-2 Mbps | 0.7-1 Mbps | 0.5-0.7 Mbps | Minimal viable playback |
Why multiple codecs?
| Codec | Pros | Cons | Browser Support |
|---|---|---|---|
| H.264 (AVC) | Universal support; hardware decode everywhere | Larger files; older compression | All browsers and devices |
| VP9 | ~30% better compression than H.264; royalty-free | Slower encode; no iOS native | Chrome, Firefox, Edge, Android |
| AV1 | ~30% better compression than VP9; royalty-free | Very slow encode (10-100× H.264) | Chrome, Firefox (growing) |
YouTube prioritizes: VP9 for Chrome/Android viewers (majority), H.264 as fallback, AV1 for high-traffic videos where the encoding cost is amortized over millions of views.
Not all videos are equal in complexity. A talking-head podcast (low motion, static background) can be encoded at much lower bitrate than a sports broadcast (fast motion, crowd scenes) at the same perceived quality.
Per-title encoding (Netflix coined the term) analyzes each video's complexity and generates a custom quality ladder for it, rather than using a fixed one. YouTube's equivalent system is called Dynamic Quality Optimization (DQO):
- Analyze the source video for complexity (motion estimation, scene changes, texture density).
- Encode sample segments at different bitrates.
- Compute perceptual quality (VMAF/SSIM) for each.
- Select the minimum bitrate that achieves the target quality for each resolution.
Result: A simple interview video at 1080p might need only 3 Mbps (H.264), while an action movie trailer at 1080p needs 10 Mbps. Bandwidth savings: 30-50% on average compared to fixed-bitrate ladders.
Video Processing Pipeline — DAG Orchestration
The video processing pipeline is not a simple linear sequence — it's a Directed Acyclic Graph (DAG) where some tasks run in parallel (transcoding multiple resolutions) while others have dependencies (DASH manifest generation depends on all transcoding jobs completing).
Pipeline stages:
| Stage | Description | Dependency | Duration (10 min, 4K video) |
|---|---|---|---|
| File validation | Check file integrity, format, duration limits | None (first stage) | ~10 sec |
| Content safety | ML models: copyright (Content ID), nudity, violence, spam | File validation | 1-5 min |
| Transcoding (per rendition) | Decode → scale → re-encode | File validation | 5-30 min per rendition |
| Segment splitting | Split renditions into 2-6 second segments | Transcoding | ~30 sec per rendition |
| Manifest generation | Generate DASH .mpd / HLS .m3u8 | All segmentation complete | ~5 sec |
| Thumbnail generation | Extract key frames, generate multiple sizes | File validation | ~30 sec |
| CDN pre-warm | Push segments to edge locations (for popular channels) | Manifest generation | ~1-5 min |
DAG Orchestration
The pipeline is orchestrated by a system like Apache Airflow, Temporal, or a custom DAG engine. The orchestrator:
- Tracks the state of each task (pending, running, completed, failed).
- Triggers sequential tasks only when their dependencies complete.
- Retries failed tasks with exponential backoff.
- Reports status back to the Metadata DB (so the Upload Service can show progress to creators).
Distributed transcoding optimization: For very long videos, a single rendition can be parallelized by splitting the video into time segments (e.g., 1-minute chunks), transcoding each chunk on a separate worker, and concatenating the outputs. This reduces wall-clock transcoding time from 30 minutes to ~5 minutes.
A sequential pipeline (validate → safety check → transcode → segment → manifest) would take the sum of all stage durations. For a 4K video:
- Sequential: 10s + 5min + 30min×5 renditions + 30s×5 + 5s + 5min ≈ 2.5+ hours
- DAG (parallel transcoding): 10s + max(5min, 30min, 30s) + 5s + 5min ≈ ~40 minutes
The DAG approach is ~4× faster because transcoding renditions run in parallel. Further, content safety can run in parallel with transcoding, and thumbnails run in parallel with everything else.
YouTube reportedly processes most videos within 15-30 minutes of upload, even for 4K content — only achievable with aggressive DAG parallelism.
Signed URLs — Secure Direct Upload at Scale
Signed URLs are a foundational security pattern for handling file uploads at scale. Understanding why they exist and how they work is critical for any system that handles user-generated binary content.
The Problem Without Signed URLs
Without signed URLs, the video upload flow would be:
- Creator sends the entire video file to the application server.
- Application server streams the file to object storage.
- Application server is a bottleneck — handling multi-GB streams ties up threads, consumes bandwidth, and requires massive server capacity.
At YouTube scale (100K uploads/day, avg 500MB each = 50 TB/day of upload bandwidth):
- Routing 50 TB/day through application servers would require hundreds of high-bandwidth servers just for proxying files.
- Every network hop doubles the latency and halves the throughput.
How Signed URLs Solve This
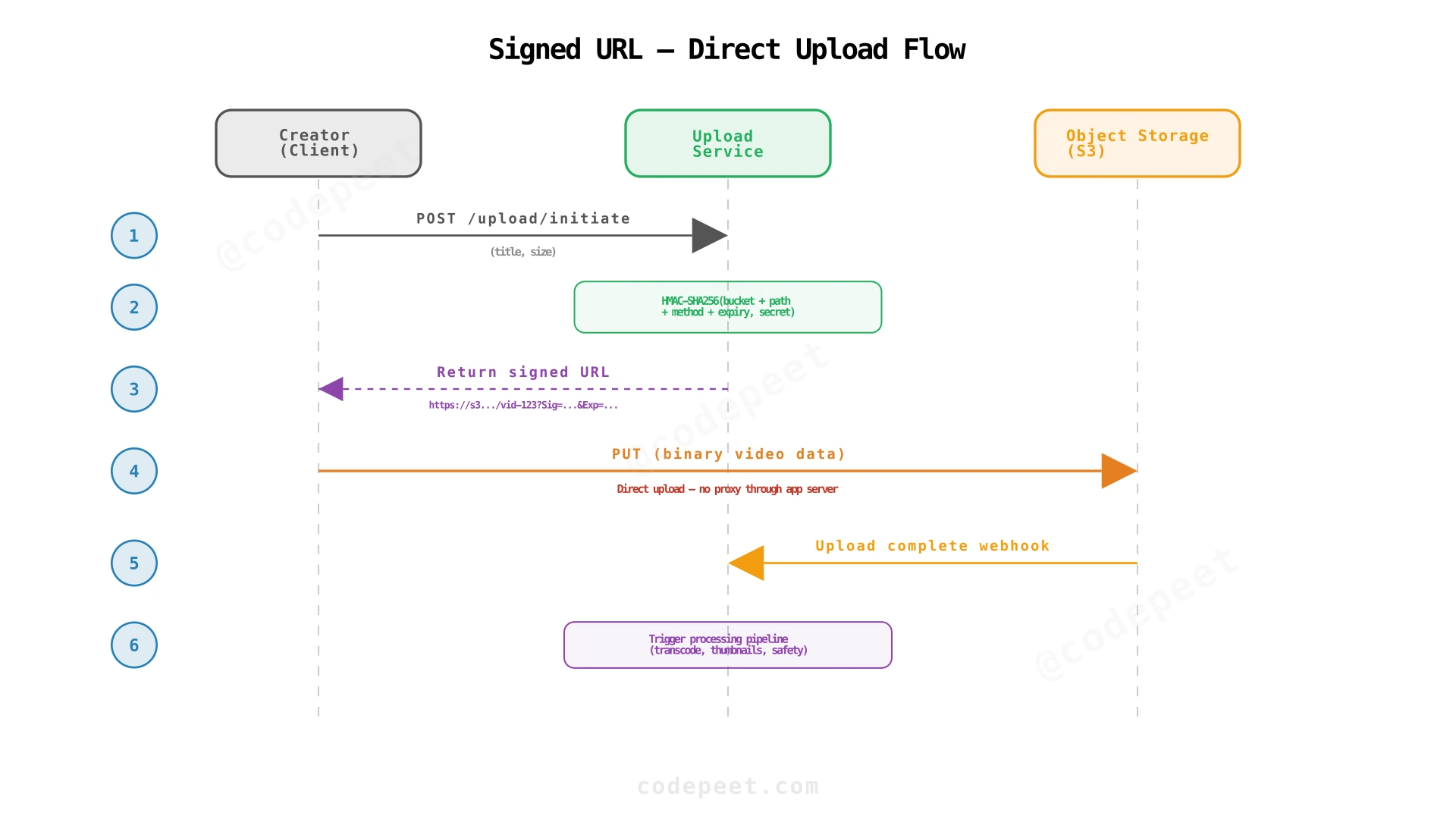
The cryptographic signature:
A signed URL encodes:
- Bucket + object path — where the file will be stored.
- HTTP method — typically
PUT(upload only, not download). - Expiration time — URL is valid for a limited window (e.g., 15 minutes).
- HMAC signature —
HMAC-SHA256(canonical_request, service_account_private_key).
Object storage validates the signature on every request. If the signature is invalid, expired, or the request doesn't match (wrong path, wrong method), the request is rejected.
Security properties:
- Only the intended creator can upload to the specified path.
- The URL expires — even if leaked, it becomes useless after the time window.
- The URL is scoped to a specific HTTP method — a PUT-signed URL can't be used for GET (download).
- Size limits can be enforced via
Content-Length-Rangeconditions in the policy.
For large files, object storage APIs support resumable uploads:
S3 Multipart Upload:
- Initiate multipart upload → get
upload_id. - Upload parts (e.g., 5MB chunks) — each part gets its own signed URL.
- Each part can be retried independently on failure.
- Complete upload with list of part ETags.
GCS Resumable Upload:
- Initiate resumable upload → get a
session_uri. - Upload in chunks to the session URI with
Content-Rangeheaders. - On failure, query the session to learn how many bytes were received.
- Resume from the next byte.
Both approaches ensure that a 10GB upload interrupted at 80% only re-uploads the remaining 20%, not the entire file.
CDN Architecture — Caching Strategy for Video at Scale
Video content delivery is the most bandwidth-intensive operation on the internet. YouTube serves over 1 billion hours of video daily. Making this work requires a sophisticated CDN strategy with multiple caching tiers.
Tiered CDN Architecture
YouTube's CDN uses a three-tier caching hierarchy:
| Tier | Location | Hit Rate | Latency to User |
|---|---|---|---|
| Edge POP | City-level (200+ locations) | ~60-70% | < 20ms |
| Regional Hub | Country/region-level (20-50 locations) | ~85-90% cumulative | < 50ms |
| Origin | 3-5 data centers globally | 100% (source of truth) | 100-300ms |
When a viewer requests a video segment:
- Request goes to the nearest Edge POP (point of presence).
- If cached → served immediately (cache hit). This handles ~60-70% of requests.
- If not cached → request falls through to the Regional Hub.
- If cached at Regional Hub → served from there (cumulative ~85-90% hit rate).
- If not cached anywhere → fetched from Origin, cached at both Regional Hub and Edge POP for future requests.
Content Popularity and Caching Strategy
| Content Type | % of Videos | % of Views | CDN Strategy |
|---|---|---|---|
| Head (viral, trending) | ~1% | ~40% | Proactive push to ALL edge POPs |
| Torso (moderate popularity) | ~19% | ~40% | Push to regional hubs; pull to edges |
| Long tail (few views) | ~80% | ~20% | Pull-only; cache on first access |
Edge cache eviction: LRU (Least Recently Used) eviction with a minimum TTL. Popular segments stay in cache; long-tail segments are evicted quickly. Edge storage is expensive (SSDs at 200+ locations), so cache efficiency matters enormously.
CDN is YouTube's largest infrastructure cost. Some strategies to optimize:
- Codec efficiency: VP9 saves ~30% bandwidth vs H.264 for the same quality. At YouTube's scale ($B+/year in CDN), this is a massive saving. AV1 saves another ~30% but encoding is expensive.
- Adaptive quality: Serving 480p instead of 1080p when the viewer's screen or bandwidth can't benefit from higher quality saves 60-80% of bandwidth per stream.
- Popularity prediction: ML models predict which newly uploaded videos will go viral, pre-warming CDN caches before demand spikes.
- Off-peak preloading: Pre-position edge content during low-traffic hours to spread bandwidth costs.
- Google's own CDN: YouTube uses Google's private edge network, not a third-party CDN — which gives them hardware-level control over caching and routing.
Optimizing Upload Speed
For creators, upload speed directly impacts their workflow. A creator who waits 30 minutes for a 10GB upload will consider moving to a competitor. Here are the techniques to make uploads faster:
1. Parallel Chunk Uploads
Instead of uploading the file sequentially, split it into chunks (e.g., 5MB each) and upload multiple chunks simultaneously. With 8 parallel connections:
- Sequential: 10GB at 50 Mbps = ~27 minutes
- 8× parallel: ~3.4 minutes (if network is the bottleneck)
2. Client-Side Compression
For creators with fast CPUs but slow networks, client-side compression before upload can reduce file size by 30-50%. The YouTube app could re-encode using a fast preset (e.g., H.264 ultrafast) to optimize for upload speed, knowing the server will re-transcode anyway.
3. Upload from Near Edge
Instead of uploading to a centralized US-based storage, route uploads to the nearest edge/regional PoP. The signed URL can point to a regional storage endpoint: https://asia-southeast1.storage.googleapis.com/.... The file is then replicated to the primary origin asynchronously.
4. Progressive Processing
Don't wait for the entire upload to complete before starting processing. Begin transcoding as chunks arrive:
- After the first 60 seconds of video is uploaded, start transcoding that segment.
- By the time the full video is uploaded, the first several minutes are already transcoded.
- This overlaps upload and processing time, reducing end-to-end latency.
5. Bandwidth Feedback + Progress Bars
Show creators real-time upload progress with estimated time remaining. If the upload is going to take 30+ minutes, offer to send a notification when complete instead of requiring them to keep the app open.
YouTube's upload client:
- Uses GCS resumable upload protocol (not standard POST).
- Adjusts chunk size dynamically based on measured throughput (larger chunks for fast connections, smaller for slow/unreliable ones).
- Maintains a persistent connection to the nearest storage endpoint.
- Retries failed chunks with exponential backoff.
- Reports upload progress back to the YouTube frontend for UX.
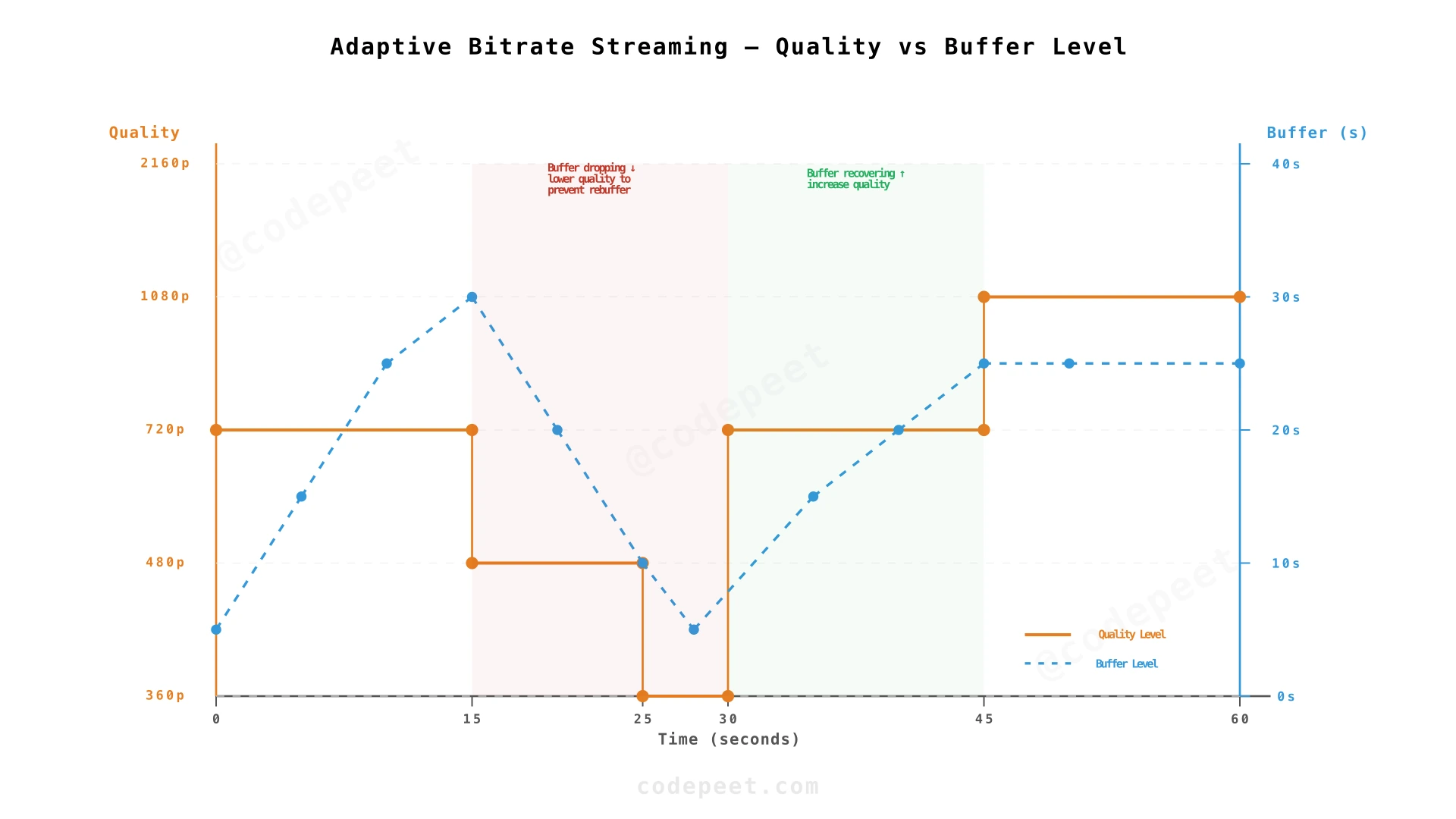
Adaptive Bitrate Streaming — Seamless Quality Switching
Adaptive Bitrate Streaming (ABR) is what makes video playback feel seamless even when network conditions change. The video player dynamically switches between quality levels based on real-time network measurements.
How ABR Works
- Manifest download: The player fetches the DASH MPD (or HLS M3U8) manifest, which lists all available renditions (quality × codec) and their segment URLs.
- Segment-by-segment quality decision: For each 2-6 second segment, the ABR algorithm decides which quality to request based on:
- Throughput estimate: Moving average of recent segment download speeds.
- Buffer level: How many seconds of video are buffered ahead of playback.
- Rebuffer risk: If the buffer is low, switch to lower quality to prevent stalling.
- Seamless switching: Because segments are independently decodable, the player can switch quality between any two consecutive segments without rebuffering.
ABR Algorithm Comparison
| Algorithm | Strategy | Used By |
|---|---|---|
| Throughput-based | Choose highest quality below estimated throughput | Early DASH implementations |
| Buffer-based (BBA) | Map buffer level to quality level; ignore throughput | Netflix (BBA-0, BBA-2) |
| Hybrid (MPC) | Model Predictive Control — optimize QoE over next K segments | YouTube (adapted) |
| ML-based (Pensieve) | Neural network trained via RL to maximize QoE | Research (deployed at some CDNs) |
YouTube uses a hybrid approach: primarily buffer-based with throughput as a secondary signal. The player prefers to maintain a target buffer (typically 20-40 seconds ahead) and selects the highest quality that the estimated throughput can sustain without depleting the buffer.
YouTube was one of the first to deploy QUIC (now HTTP/3) for video delivery. Benefits:
- 0-RTT connection establishment: Returning viewers connect instantly (no TCP+TLS handshake delay).
- Multiplexed streams without head-of-line blocking: Multiple segment requests can fly in parallel without one slow response blocking others.
- Connection migration: When a mobile user switches from Wi-Fi to cellular, the QUIC connection survives (it's identified by connection ID, not IP:port). The video doesn't rebuffer during the switch.
- Better congestion control: QUIC's congestion control is implemented in userspace, allowing YouTube to customize it for video delivery patterns.
Google reports that QUIC reduces rebuffer rates by 15-18% compared to TCP+TLS.
Database Sharding and Replication for Video Metadata
YouTube's video metadata (titles, descriptions, stats, processing state) must handle ~5,800 read QPS average (29K peak) with strong consistency for writes and eventual consistency acceptable for stats counters.
Sharding Strategy
| Table | Shard Key | Rationale |
|---|---|---|
| videos | video_id | Even distribution; most reads are by video_id (video page) |
| users | user_id | Even distribution; accessed for profile pages |
| video_stats | video_id | Co-located with video metadata for JOIN efficiency |
| transcoding_jobs | video_id | Co-located for pipeline status checks |
Why video_id over uploader_id for the videos table?
- Sharding by
uploader_idwould co-locate all of a creator's videos on one shard — convenient for "my videos" queries. - But: a viral creator with 10M videos creates a hot shard.
video_iddistributes evenly. - "My videos" queries use a secondary index or a separate creator-to-videos lookup table.
Replication Strategy
| Replica Type | Count | Purpose |
|---|---|---|
| Primary | 1 per shard | All writes (metadata updates, new videos) |
| Read replicas | 2-3 per shard | Handle 80%+ of reads; ~100ms replication lag acceptable |
| Analytics replicas | 1 per shard | Batch analytics queries without impacting live traffic |
Video Stats: Write-Heavy Counter Pattern
video_stats is the hottest table — every view, like, and share is a write. Writing directly to PostgreSQL for every view would overwhelm the primary.
Solution: Redis counter + periodic flush
- On each view: increment
video_id:view_countin Redis (< 1ms, no DB write). - A background worker periodically (every 30-60 seconds) flushes accumulated counts to PostgreSQL in batch:
UPDATE video_stats SET view_count = view_count + {delta} WHERE video_id = ?. - Read path: Redis has the real-time count; DB has the durable count.
This reduces DB writes by 100-1000× (thousands of Redis increments batch into one DB UPDATE).
Cassandra/DynamoDB would handle the write throughput easily, but:
- Video metadata has relational structure: videos belong to users, transcoding jobs belong to videos. JOINs are needed for many queries.
- Status transitions (uploading → processing → published) need ACID transactions to prevent race conditions (e.g., marking a video as published before all transcoding jobs complete).
- The read volume (~29K QPS peak) is comfortably handled by PostgreSQL with read replicas and Redis caching.
For the stats table specifically, DynamoDB's atomic counters would work well, but mixing databases adds operational complexity. The Redis counter + periodic flush pattern achieves the same effect with the existing PostgreSQL infrastructure.
Staff-Level Discussion Topics
These open-ended topics test architectural judgment and strategic thinking at the staff+ level.
YouTube stores over 1 exabyte of video and adds ~250 TB of transcoded data daily. CDN bandwidth costs at this scale are in the billions. How do you continue scaling without costs growing linearly with views?
YouTube promises indefinite storage for creator content. With 500+ hours uploaded every minute, the storage footprint grows relentlessly. Most uploaded videos receive fewer than 100 views total, yet they must remain available indefinitely.
YouTube operates across dozens of data centers worldwide. A single data center failure should be invisible to users. A multi-region disaster (e.g., natural disaster affecting an entire continent) should degrade service, not eliminate it.
Level Expectations
| Area | |||
|---|---|---|---|
| Requirements | Lists upload and stream as core FRs | Derives 5,800 QPS for reads, 12/s for uploads; identifies the write-heavy/read-light asymmetry | Calculates exabyte-scale storage; discusses CDN cost as the dominant factor |
| Upload Architecture | "Users upload videos to a server" | Signed URLs + direct object storage upload; resumable chunked uploads | Progressive processing (start transcoding before upload completes); edge upload routing |
| Processing Pipeline | "Transcode videos to different formats" | DAG architecture with parallel transcoding; content safety as a pipeline stage; quality ladder | Per-title encoding; distributed transcoding by time segments; codec migration strategy |
| CDN & Streaming | "Use CDN to serve videos" | Three-tier CDN (edge, regional, origin); push vs pull caching; ABR with DASH/HLS | CDN cost optimization; QUIC/HTTP/3 for streaming; popularity prediction for pre-warming |
| Database | "Store video metadata in a database" | PostgreSQL with read replicas; Redis counters for view_count; sharding by video_id | Video stats as write-heavy counter pattern; analytics replicas; tiered storage for cold content |
| Trade-offs | Picks one codec and resolution | Compares H.264 vs VP9 vs AV1; explains latency-compression trade-off | Codec migration ROI; build vs buy for CDN; erasure coding vs replication for origin storage |
Interview Cheatsheet
Core Architecture in 60 Seconds
"A video platform with three distinct pipelines. Upload: clients get a pre-signed URL and upload directly to object storage (S3), bypassing application servers entirely. Processing: a DAG-based pipeline transcodes the raw video into multiple resolutions and codecs, generates thumbnails, runs safety checks, and extracts metadata — all asynchronously. Delivery: transcoded segments are pushed to a multi-tier CDN (edge → regional → origin). Clients use adaptive bitrate streaming (HLS/DASH) to switch quality based on bandwidth. Metadata (titles, views, likes) lives in a sharded database with a caching layer."
"YouTube is a video upload, processing, and streaming platform serving 100M+ DAU. The architecture has two asymmetric paths: a heavy write path (upload → transcode → CDN) and a lightweight read path (CDN edge → viewer). Creators upload via signed URLs directly to object storage, bypassing application servers. A DAG-based processing pipeline transcodes each video into 5+ resolutions × 2+ codecs (H.264, VP9), producing DASH/HLS manifests for adaptive bitrate streaming. Transcoded segments are distributed to a 3-tier CDN (edge → regional → origin). Viewers fetch segments from the nearest edge node with ABR quality switching based on throughput and buffer state."
- FRs: Upload videos (resumable), process/transcode, stream with adaptive quality
- NFRs: 100M DAU, 29K peak QPS (reads), <2s playback start, 11-nines durability
- Key insight: Heavy write, light read — invest in pre-processing so reads are just CDN serves
- Out of scope: Search, recommendations, comments, live streaming, monetization
- Upload Service — generates signed URLs; tracks upload state
- Object Storage (S3/GCS) — stores original uploads + transcoded output
- Message Queue (Kafka) — decouples upload from processing pipeline
- Transcoding Worker Fleet — GPU/CPU workers; parallel multi-resolution encoding
- Content Safety Workers — ML models for copyright + community guidelines
- Pipeline Orchestrator — DAG engine tracking pipeline completion
- Metadata DB (PostgreSQL) — video metadata, user data, processing state
- Redis Cache — hot metadata + view count counters
- CDN (3-tier) — edge POPs + regional hubs + origin
- Signed URL vs proxy upload: Signed URLs bypass application servers; massive bandwidth savings
- H.264 vs VP9 vs AV1: Compression vs encoding cost vs browser support
- Push vs pull CDN: Push for popular content; pull for long-tail (80/20 rule)
- Fixed vs per-title quality ladder: Per-title saves 30-50% bandwidth but adds analysis cost
- Sequential vs DAG pipeline: DAG is 4× faster through parallelism
- PostgreSQL + Redis vs Cassandra: Relational metadata needs ACID; Redis handles counter writes
| Metric | Value |
|---|---|
| DAU | 100M |
| Daily uploads | 100K videos (~50 TB) |
| Daily transcoded output | ~250 TB |
| Watch QPS (avg / peak) | 5,800 / 29,000 |
| Storage (10-year) | ~1 exabyte (all formats) |
| CDN cache hit rate | 85-90% (cumulative) |
| Playback start target | < 2 seconds |
| Quality levels | 6 (360p → 2160p) |
| Codecs | H.264 (universal), VP9 (30% better), AV1 (60% better) |
| Replication | 3× for originals |
- "How do you handle a viral video that gets 10M views in an hour?" — CDN absorbs it. Proactive push to all edges. Auto-scale origin bandwidth if cache fill rate spikes.
- "How do you handle a video upload that fails midway?" — Resumable upload via S3 multipart or GCS resumable session. Client resumes from last successful chunk.
- "How would you add live streaming?" — Fundamentally different path: RTMP/WebRTC ingest → real-time transcoding → segmented HLS/DASH → CDN push. No pre-processing pipeline.
- "How do you handle copyright?" — Content ID system: hash uploaded audio/video against a database of copyrighted content. Block, demonetize, or attribute based on owner's policy.
- "How do you handle thumbnail generation?" — Extract key frames at regular intervals; run scene-detection to pick diverse, representative frames. Offer creator override.
- "How do you handle transcoding at peak upload times?" — Auto-scaling worker fleet. Kafka queue absorbs spikes. Workers scale based on queue depth metric.
Common Mistakes to Avoid
- ❌ Uploading video through the application server — pre-signed URLs let clients upload directly to S3, avoiding a massive bottleneck
- ❌ Transcoding synchronously during upload — video processing takes minutes; it must be an async pipeline with progress tracking
- ❌ Storing only one video resolution — adaptive bitrate streaming requires multiple resolutions (240p to 4K) and codecs (H.264, VP9, AV1)
- ❌ Serving video directly from origin storage — without CDN edge caching, latency and bandwidth costs are prohibitive at scale
- ❌ Ignoring the video processing DAG — transcoding, thumbnail generation, and safety checks have dependencies and must be orchestrated
- ❌ Using a single database for metadata + analytics — view counts at YouTube scale (billions/day) need a separate counter service, not synchronous DB increments