yelp
Introduction
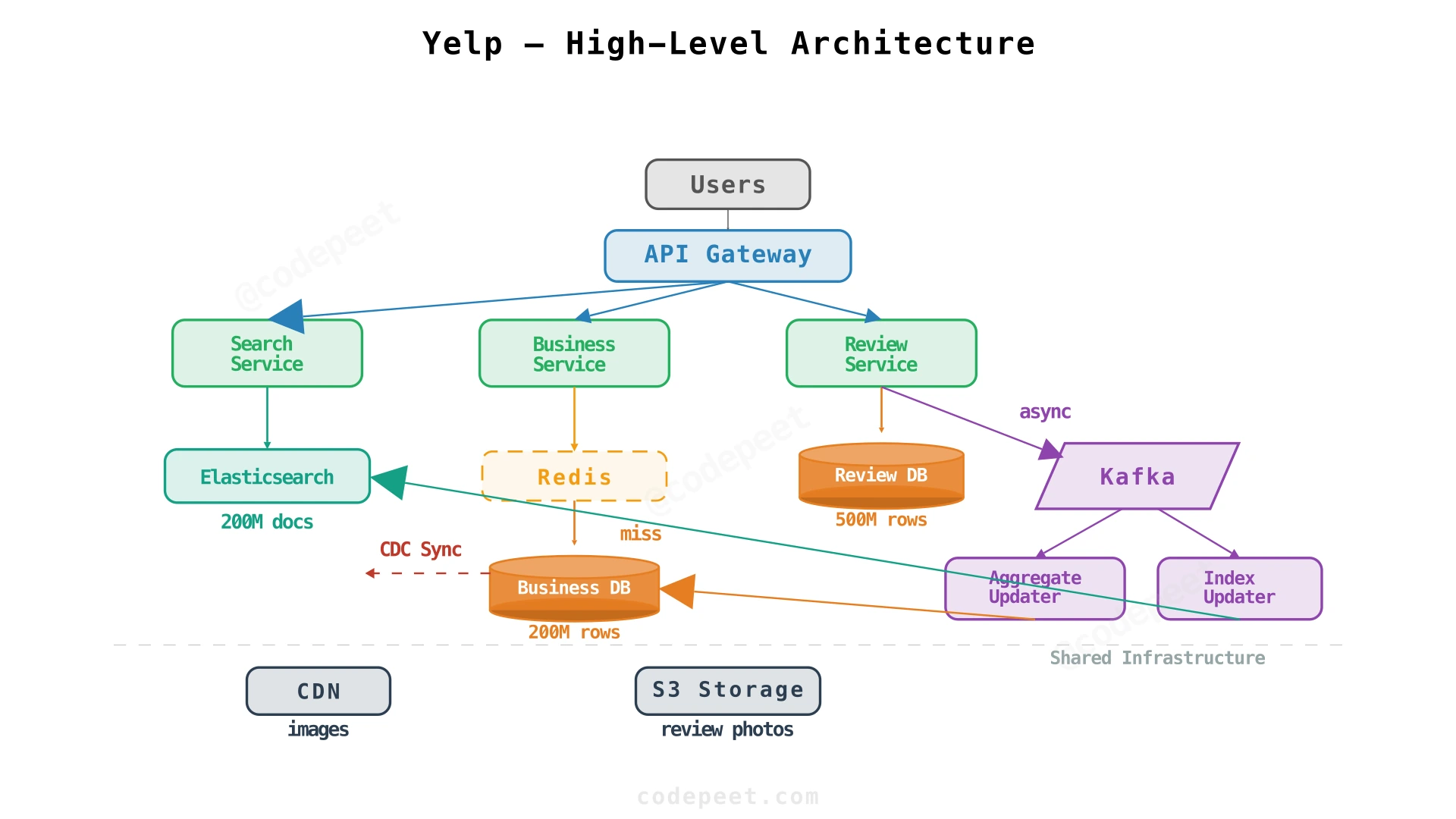
Yelp is a local business discovery platform where users search for nearby businesses, browse their profiles with ratings and reviews, and contribute their own reviews. At its core, the system solves three interconnected problems: geospatial search over hundreds of millions of business listings, high-throughput page rendering for business profiles with aggregated ratings, and durable review ingestion that updates derived data asynchronously.
The engineering challenges are layered:
| Challenge | Why It's Hard |
|---|---|
| Geospatial search | Finding businesses within a radius of a point on Earth's surface can't use regular B-tree indexes — latitude and longitude are two-dimensional, and distance calculations involve spherical trigonometry |
| Full-text + geo combined | Users search "sushi near me" — combining keyword relevance with geographic proximity requires specialized indexing structures |
| Read-heavy traffic | A 1000:1 read-to-write ratio means nearly every request is a read. Without aggressive caching, databases become the bottleneck long before write capacity matters |
| Rating aggregation | Computing AVG(stars) across millions of reviews on every page load would be catastrophically slow — aggregates must be precomputed and kept fresh |
| Search index freshness | When a restaurant changes its hours, how quickly does the search index reflect the change? The sync mechanism determines the trade-off between freshness and operational complexity |
LLD Connection: This problem connects to search indexing concepts (inverted indexes, scoring) and message queue patterns for decoupling writes from derived data updates.
The system serves 10 million daily active users, hosts 200 million business listings, and handles 50,000 peak search queries per second — a scale where naive approaches collapse and every architectural decision carries real performance implications.
Functional Requirements
We extract three core user operations from the problem statement:
FR1 — Search Businesses by Text and Location. Users enter a search query (e.g., "italian restaurant") along with their location or a specified area. The system returns a ranked list of matching businesses within the geographic radius, with support for filters (price range, rating, open now) and sorting (distance, rating, relevance). Results must be paginated for mobile and web clients.
FR2 — View Business Profile. Each business has a detail page showing its name, address, phone number, hours, photos, aggregate star rating, total review count, and paginated reviews sorted by date or helpfulness. The page loads fast despite aggregating data from multiple sources with no noticeable latency.
FR3 — Write a Review. Authenticated users submit a review consisting of a star rating (1–5), text body, and optional photos. The review must be durably persisted, and derived data — the business's aggregate rating and search index signals — must eventually update to reflect the new review.
- Business owner management — Claiming/editing business profiles, responding to reviews
- Photo gallery browsing — Dedicated photo browsing beyond review attachments
- Social features — Following users, activity feeds, check-ins
- Advertising / sponsored results — Paid placement in search results
- Messaging — Direct messages between users and business owners
- Reservations / ordering — Table booking, food delivery integration
Scale Requirements
| Metric | Value |
|---|---|
| Daily active users | 10,000,000 |
| Total businesses | 200,000,000 |
| Total reviews | 500,000,000 |
| Read-to-write ratio | 1000:1 |
| Peak search QPS | 50,000 |
| Average search QPS | ~12,000 |
| Review writes | ~1.2 per second (103K per day) |
| Average review size | ~1 KB (text) + optional photos |
The 1000:1 read-to-write ratio is the defining characteristic. Nearly every request is a search or page view. Write volume is modest — about 100K reviews per day — but each write triggers a cascade of derived data updates: aggregate recalculation, cache invalidation, and search index refresh.
Non-Functional Requirements
| Requirement | Target | Rationale |
|---|---|---|
| Low Search Latency | p95 < 200 ms | Users expect instant results; every 100 ms of latency costs ~1% of engagement |
| Low Page Load Latency | p95 < 100 ms | Business pages must feel instantaneous — users bounce if the page takes > 1 second |
| High Scalability | 50K peak search QPS, 200M businesses | Must handle viral traffic spikes (TikTok-famous restaurants) without degradation |
| Eventual Consistency | Reviews visible within seconds; aggregates within minutes | Users accept slight delay for rating updates; reviews must be durable immediately |
| High Availability | 99.95% uptime | Yelp is a destination for real-time decisions ("where to eat right now") — downtime directly impacts revenue |
| Durability | Zero lost reviews after acknowledgment | Once we confirm a review submission, it must survive infrastructure failures |
The consistency model is intentionally tiered:
- Strong consistency for the review write itself — the author's review is durable the moment the write returns
- Read-your-writes for the author — they see their own review immediately
- Eventual consistency for everything else — other users see the review within seconds, aggregate ratings update within minutes, search index reflects the change within minutes
Resource Estimation
Traffic Estimation
| Metric | Average | Peak |
|---|---|---|
| Search queries per second | ~12,000 | 50,000 |
| Business page views per second | ~1,700 | ~7,000 |
| Review writes per second | ~1.2 | ~5 |
| Total read QPS | ~14,000 | ~57,000 |
With 10M DAU and an average of ~100 search queries per user per day: 10M × 100 / 86,400 ≈ 11,574 QPS.
Page views follow search at roughly an 8:1 ratio (users view ~12 business pages per session).
Review writes: ~100K reviews/day ÷ 86,400 ≈ 1.2 QPS — trivially low write throughput.
Storage Estimation
| Data | Calculation | Result |
|---|---|---|
| Business metadata | 200M × ~2 KB avg | ~400 GB |
| Reviews (text) | 500M × ~1 KB avg | ~500 GB |
| Review photos | 500M × 5% with photos × 2 MB avg | ~50 TB (object storage) |
| Search index | 200M documents × ~3 KB avg | ~600 GB |
| Rating aggregates | 200M × 16 bytes | ~3.2 GB |
| Redis cache | Hot business data + popular searches | ~50 GB |
Infrastructure Estimation
| Component | Requirement |
|---|---|
| Search cluster (Elasticsearch) | 5–10 data nodes, 3 masters, ~600 GB index storage |
| Business database (PostgreSQL) | Primary + 2 read replicas, ~400 GB |
| Review database (PostgreSQL) | Primary + 2 read replicas, ~500 GB |
| Redis cache cluster | 3–6 nodes, ~50 GB total |
| Message queue (Kafka) | 3-broker cluster for CDC + review events |
| CDN | Global edge network for photos and static assets |
The system is read-dominated and latency-sensitive. The primary engineering challenge is serving 57K peak read QPS with sub-200ms latency — this requires effective caching, index optimization, and horizontal scaling of read paths.
API Endpoints
Search Businesses
GET /api/v1/search?query=pizza&lat=40.75&lng=-73.99&radius=5000&filters=price:$$,open_now:true&sort=relevance&cursor=eyJv...
Query Parameters:
| Parameter | Type | Required | Description |
|---|---|---|---|
query | string | Yes | Search text (e.g., "pizza", "hair salon") |
lat | float | Yes | User's latitude |
lng | float | Yes | User's longitude |
radius | integer | No | Search radius in meters (default: 5000, max: 40000) |
filters | string | No | Comma-separated key:value pairs (price, rating, open_now, category) |
sort | string | No | relevance (default), distance, rating, review_count |
cursor | string | No | Opaque pagination cursor for next page |
Response:
{
"businesses": [
{
"id": "biz_4kMBvIEWPxWk...",
"name": "Joe's Pizza",
"rating_avg": 4.5,
"rating_count": 1243,
"category": "Pizza",
"price_level": "$$",
"distance_meters": 320,
"address": "7 Carmine St, New York, NY",
"is_open": true,
"thumbnail_url": "https://cdn.yelp.example/photos/biz_4k/thumb.jpg"
}
],
"next_cursor": "eyJvZmZzZXQiOjIwfQ==",
"total_results": 847
}
View Business Details
GET /api/v1/businesses/{business_id}
Response:
{
"id": "biz_4kMBvIEWPxWk...",
"name": "Joe's Pizza",
"rating_avg": 4.5,
"rating_count": 1243,
"category": "Pizza",
"price_level": "$$",
"address": "7 Carmine St, New York, NY 10014",
"phone": "+1-212-366-1182",
"hours": {
"monday": {"open": "10:00", "close": "23:00"},
"tuesday": {"open": "10:00", "close": "23:00"}
},
"coordinates": {"lat": 40.7305, "lng": -74.0023},
"photos": ["https://cdn.yelp.example/photos/biz_4k/1.jpg"],
"is_open": true
}
Get Business Reviews
GET /api/v1/businesses/{business_id}/reviews?cursor=eyJv...&sort=recent
Response:
{
"reviews": [
{
"id": "rev_8xNqP2...",
"user": {"id": "usr_3Kd...", "name": "Sarah M.", "avatar_url": "..."},
"stars": 5,
"text": "Best pizza in NYC. The crust is perfectly crispy...",
"photos": ["https://cdn.yelp.example/photos/rev_8x/1.jpg"],
"created_at": "2026-03-15T14:30:00Z",
"helpful_count": 42
}
],
"next_cursor": "eyJvZmZzZXQiOjEwfQ==",
"total_reviews": 1243
}
Submit a Review
POST /api/v1/businesses/{business_id}/reviews
Authorization: Bearer <token>
Request Body:
{
"stars": 5,
"text": "Best pizza in NYC. The crust is perfectly crispy and the sauce is incredible.",
"photo_urls": ["https://uploads.yelp.example/tmp/abc123.jpg"]
}
Response: 201 Created
{
"id": "rev_9yMrQ3...",
"stars": 5,
"text": "Best pizza in NYC...",
"created_at": "2026-03-17T10:30:00Z"
}
High-Level Design
The high-level design addresses three core design decisions (DDQs), each building on the previous:
- Search Businesses — How do we make 200M businesses searchable by text + location at 50K QPS?
- View Business Details — How do we serve business pages with aggregated ratings at sub-100ms latency?
- Write a Review — How do we reliably ingest reviews and update all derived data?
Each DDQ follows the same pattern: identify the naive approach, explain why it breaks at scale, then build the solution incrementally.
1. Search Businesses
How do we search 200M businesses by text and location efficiently?
Users type "sushi near me" and expect ranked, filtered results within 200ms. With 200 million business listings, the search path is the single most critical component. Let's build it incrementally.
The Problem
A direct SQL query against the business table hits two walls simultaneously:
- Full-text search —
WHERE name LIKE '%sushi%' OR description LIKE '%sushi%'requires a full table scan. Even with a GIN index ontsvector, PostgreSQL isn't designed for 50K QPS full-text search across 200M rows. - Geospatial filtering —
WHERE ST_DWithin(location, user_point, 5000)computes haversine distance for every candidate. Even with a spatial index, combining this with text search in a single query is slow.
At 50K peak QPS, a relational database simply cannot serve both dimensions efficiently. We need a dedicated search engine.
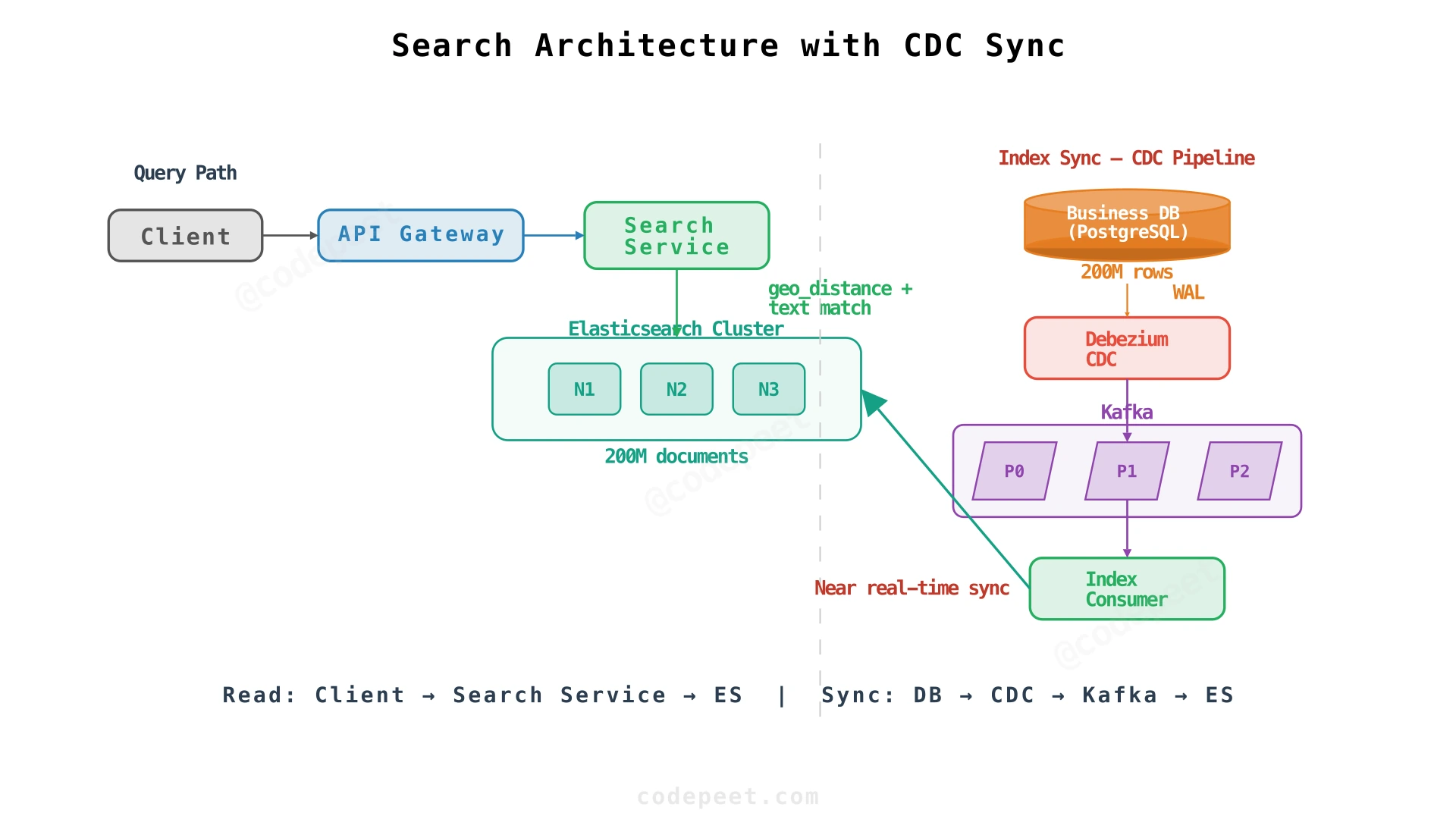
The Solution: Elasticsearch for Combined Geo + Text Search
Elasticsearch is purpose-built for this workload. It provides:
- Inverted indexes for fast full-text search — terms like "sushi" map directly to document IDs without scanning
geo_pointfield type with built-in geohash encoding —geo_distancequeries efficiently filter by radius- Combined queries — a single
boolquery can match text, filter by radius, and sort by a scoring function in one pass - Horizontal scaling — shards distribute across data nodes, with each shard handling a subset of the 200M documents
A search query becomes:
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "sushi",
"fields": ["name^3", "category^2", "description"],
"type": "best_fields"
}
}
],
"filter": [
{
"geo_distance": {
"distance": "5km",
"coordinates": {"lat": 40.75, "lon": -73.99}
}
},
{"term": {"is_active": true}},
{"term": {"price_level": "$$"}}
]
}
},
"sort": [
{"_score": "desc"},
{"_geo_distance": {
"coordinates": {"lat": 40.75, "lon": -73.99},
"order": "asc"
}}
],
"size": 20,
"from": 0
}The multi_match query scores text relevance with boosted weights — name^3 means a match in the business name is 3× more important than a match in the description. The geo_distance filter eliminates businesses outside the radius without affecting the relevance score. Filters are cached by Elasticsearch for repeated queries.
Why Elasticsearch over alternatives?
Option A: PostgreSQL with PostGIS + Full-Text Search
PostgreSQL supports both tsvector for full-text search and PostGIS for geospatial queries. For a small catalogue (<1M businesses), this works well — a single database handles everything, reducing operational complexity.
Limitation: At 200M rows and 50K QPS, neither the full-text nor the spatial index scales horizontally. PostgreSQL read replicas help but are limited by single-node index size and rebuild times. Query planning for combined text + geo predicates produces suboptimal plans — the optimizer can't efficiently merge two different index types.
Option B: Separate Text Index + PostGIS
Use Elasticsearch for text search, PostGIS for geospatial filtering, and merge results in the application layer. Each system does what it's best at.
Limitation: Application-level joins are complex and slow. You need to query both systems, intersect results, then sort by combined relevance. Two network round-trips, two result sets in memory, and edge cases where pagination breaks because the intersection is smaller than either result set.
Option C: Elasticsearch for Both (Recommended)
Elasticsearch handles text and geo in a single query plan. The bool query composes naturally — text match in must, geo filter in filter, additional filters stack without performance cliffs. Horizontal scaling via sharding supports 200M documents and 50K QPS.
Trade-off: Elasticsearch is not the source of truth — it's a read-optimized index that must be kept in sync with the primary database. This sync mechanism becomes a critical architectural decision.
Keeping the Search Index Fresh: How Do Changes Reach Elasticsearch?
When a business owner updates their hours or a new business registers, how does Elasticsearch learn about the change? Two primary approaches:
Approach 1: Dual Write (Simple but Fragile)
The application writes to both PostgreSQL and Elasticsearch in the same request handler:
def update_business(business):
db.update(business) # Step 1: Write to database
elasticsearch.index(business) # Step 2: Write to search index
Advantages:
- Trivially simple — no extra infrastructure
- Changes appear in search immediately (synchronous)
- Easy to understand, debug, and test
Failure mode: If the database write succeeds but the Elasticsearch write fails (network timeout, ES cluster overloaded), the data diverges silently. The database shows updated hours, but search returns stale data. There's no built-in mechanism to detect or repair this drift.
At small scale (<10K businesses), a nightly reconciliation script fixes drift before users notice. At 200M businesses, reconciliation takes hours and can't keep up with change volume.
Approach 2: Change Data Capture — CDC (Reliable at Scale)
A CDC connector (Debezium) reads the database's write-ahead log (WAL) and streams every change to Kafka. A consumer reads from Kafka and updates Elasticsearch. The application only writes to the database — it doesn't even know Elasticsearch exists.
How it works:
- Application writes to PostgreSQL (business update, new listing, etc.)
- PostgreSQL writes the change to its WAL (transaction log) — this happens anyway as part of normal database operation
- Debezium reads the WAL entry and publishes a change event to a Kafka topic
- An index consumer reads from Kafka and upserts the document in Elasticsearch
Advantages:
- Guaranteed consistency — every committed database change eventually reaches the index
- Decoupled — the application has zero knowledge of Elasticsearch
- Replayable — Kafka retains events; replaying the topic rebuilds the entire index
- No performance impact on writes — the application only waits for the database commit
Trade-off: The pipeline introduces operational complexity — Debezium, Kafka, and the consumer all need monitoring, alerting, and failure recovery. CDC lag (typically 1–5 seconds) means the index is slightly behind the database.
Our Choice: CDC for Yelp Scale
At 200M businesses and 50K search QPS, data drift is unacceptable. A user searching "restaurants open now" must see accurate hours. CDC guarantees that every database change reaches the search index, with typical lag under 5 seconds. The operational cost of running the CDC pipeline is justified by the consistency guarantee.
For a startup with <100K listings, dual writes with a reconciliation script would be the pragmatic choice — simpler infrastructure, acceptable drift.
2. View Business Details
How do we serve business detail pages with aggregated ratings at low latency?
A user taps a restaurant in search results. The business page must load in under 100ms, showing the name, hours, photos, a 4.5-star aggregate rating from 1,243 reviews, and the first page of reviews. Let's build this incrementally.
The Problem
The naive approach queries the business row and then computes the aggregate on the fly:
SELECT b.*, AVG(r.stars) AS rating_avg, COUNT(r.id) AS rating_count
FROM businesses b
LEFT JOIN reviews r ON r.business_id = b.id
WHERE b.id = 'biz_4kMBvIEWPxWk'
GROUP BY b.id;
For a popular restaurant with 10,000 reviews, this JOIN + aggregation takes hundreds of milliseconds. At 1,700 page views per second (7K peak), the database is overwhelmed. The aggregate computation runs 7,000 times per second for the same slowly changing data.
Step 1: Separate Business and Review Services
Business metadata (name, hours, location) has different access patterns than reviews (paginated, user-specific, sorted). Splitting into two services allows independent scaling:
- Business Service — Reads/writes business metadata from the Business Database
- Review Service — Handles review CRUD, pagination, and submission
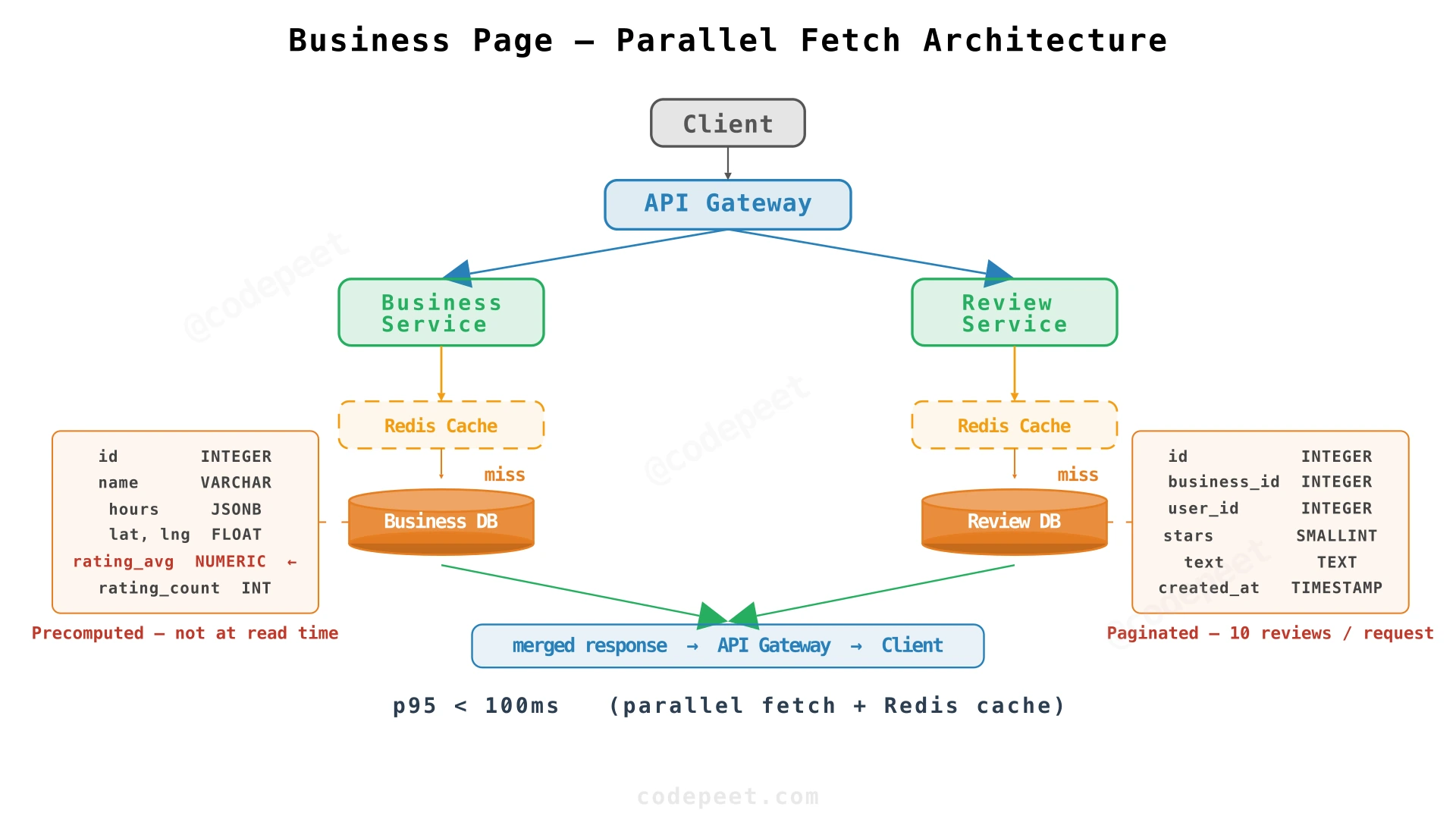
Step 2: Precompute Rating Aggregates
Instead of calculating AVG(stars) on every page load, store rating_avg and rating_count directly on the business row:
ALTER TABLE businesses ADD COLUMN rating_avg DECIMAL(3,2) DEFAULT 0;
ALTER TABLE businesses ADD COLUMN rating_count INTEGER DEFAULT 0;
When a review is submitted, the aggregate is updated asynchronously (via the message queue). The business page reads a single row — no JOIN, no aggregation, no scan of thousands of review rows.
Review Storage: Relational vs Wide-Column
Option 1: PostgreSQL (Recommended)
Reviews have a well-defined schema: user_id, business_id, stars, text, created_at. PostgreSQL provides ACID guarantees — each review is durable the moment the write returns. Flexible indexing supports multiple access patterns: reviews by business (paginated), reviews by user (profile page), and aggregate calculations.
At ~1.2 write QPS, horizontal write scaling isn't needed. 500M reviews at ~1 KB each is ~500 GB — fits on a single node with read replicas for query load. Compound index on (business_id, created_at DESC) supports efficient cursor-based pagination.
Option 2: Cassandra / DynamoDB
Partition by business_id, cluster by created_at. Pagination is natural — read the next N rows from the partition. Scales horizontally with no theoretical limit.
Limitation: Cross-partition queries are harder. "All reviews by user X" requires either a global secondary index (expensive) or a separate denormalized table. Eventual consistency by default complicates aggregate calculations — summing stars across replicas can produce stale results. At 1.2 QPS write throughput, Cassandra's distributed write optimization provides no benefit while adding operational complexity.
Our Choice: PostgreSQL. The write volume (~1.2 QPS) doesn't justify a wide-column store's operational complexity. Relational databases handle our query patterns naturally — paginate by business, query by user, JOIN for analytics — and ACID guarantees simplify the write path. Read replicas handle the read load.
Aggregate Update Mechanism
When a review is written, a review_created event is published to Kafka. An aggregate updater consumer processes the event:
UPDATE businesses
SET rating_count = rating_count + 1,
rating_avg = (rating_avg * rating_count + NEW_STARS) / (rating_count + 1)
WHERE id = 'biz_4kMBvIEWPxWk';
This incremental formula avoids recomputing from all reviews. The update is idempotent if we track which review IDs have been applied (a processed events table or Kafka offset tracking). The aggregate lags behind the actual review by 1–5 seconds — acceptable for a rating display.
3. Write a Review
How do we reliably ingest reviews and update all derived data?
A user finishes dinner and writes a 4-star review with a photo. The system must save the review durably, then propagate the change to multiple downstream systems: the rating aggregate, the search index, and the cache. Let's build this incrementally.
The Problem
When a user submits a review, the system needs to:
- Save the review to the Review Database
- Update the business's
rating_avgandrating_countin the Business Database - Update search index signals (businesses with more/better reviews rank higher in search)
- Invalidate cached business page data
The naive approach does all four synchronously. The user clicks submit → write review → update aggregates → update search index → invalidate cache → return success. If Elasticsearch is slow, the user waits. If Elasticsearch is down, the review submission fails even though the review itself could have been safely saved.
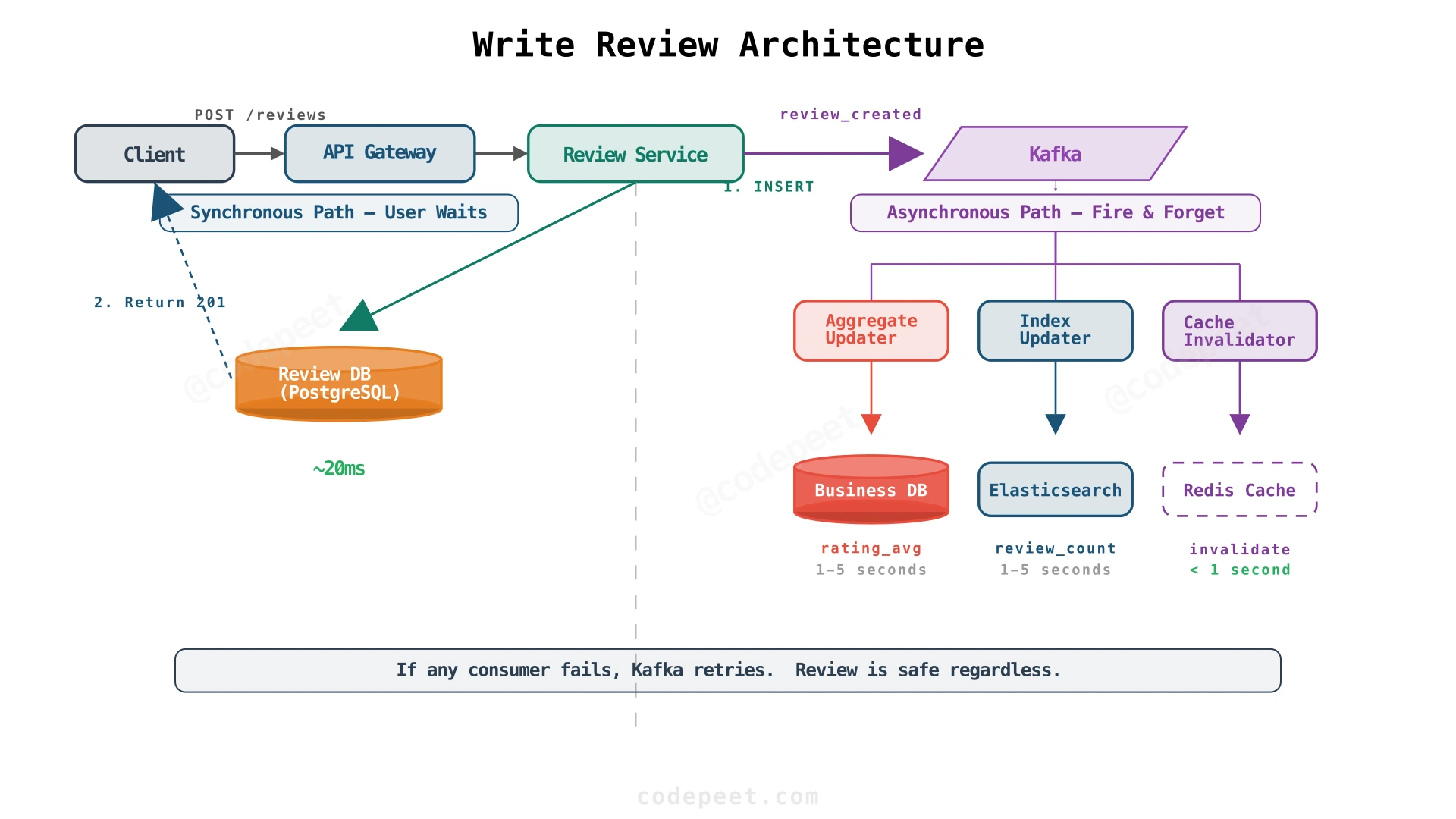
Step 1: Write to Database First, Return Success Immediately
The user cares that their review is saved. They don't care if the aggregate updates in the same request. The write path becomes:
- Validate the request (authentication, input validation, duplicate check)
- Write the review to the Review Database — commit
- Return
201 Createdto the user - Publish a
review_createdevent to Kafka (fire-and-forget from the user's perspective)
Now writes are fast (~20ms). But derived data (aggregates, search signals, cache) is temporarily stale. The user submitted a 5-star review, but the business page might still show the old average for a few seconds.
Step 2: Async Fanout via Message Queue
After the review is committed, a review_created event is published to Kafka. Independent consumers handle each downstream update:
- Aggregate Updater — Reads the event, increments
rating_countand recalculatesrating_avgin the Business Database - Index Updater — Updates the business's
review_countandratingsignals in Elasticsearch so search rankings reflect the new review - Cache Invalidator — Invalidates the cached business page and first review page so the next reader gets fresh data
This decoupling is critical: if Elasticsearch is temporarily down, reviews still save. The index updater retries when ES recovers. Even at low write QPS (~1.2/sec), the queue's value is decoupling and fault isolation, not raw throughput.
Step 3: Read-Your-Writes for the Author
The author should see their own review immediately after submission. Two approaches:
- Read from primary — For the author's session, route review reads to the primary database instead of a read replica (which may have replication lag)
- Optimistic client-side display — Include the full review in the
201 Createdresponse. The client appends it to the review list locally without re-fetching from the server
Other users see the review with a slight delay (a few seconds) as replicas sync and caches invalidate. This is acceptable — most platforms work this way.
Idempotency and Duplicate Prevention
Users shouldn't submit duplicate reviews by double-clicking or network retries. We enforce this at two levels:
Database constraint: A unique index on (user_id, business_id) prevents duplicate rows. If a user tries to submit a second review for the same business, the INSERT fails with a constraint violation — the application returns a clear error message.
CREATE UNIQUE INDEX idx_unique_user_business
ON reviews(user_id, business_id);
Idempotency key: The client sends a unique X-Idempotency-Key header with each review submission. The server checks if a review with that key already exists — if so, it returns the existing review instead of creating a duplicate. This handles network retries transparently.
Both mechanisms are necessary: the database constraint is the safety net, the idempotency key provides a better user experience (no error on retry).
Photo Upload Flow
Review photos follow a separate upload path to avoid blocking the review submission:
- Pre-upload: Client requests a presigned URL from the server:
POST /api/v1/uploads/presigned-url - Direct upload: Client uploads the photo directly to object storage (S3) using the presigned URL — this bypasses the server entirely, reducing load
- Attach to review: Client includes the uploaded photo's URL in the review submission body
- CDN distribution: Photos are served via CDN with aggressive caching — review photos never change after upload
This pattern offloads large binary uploads to object storage infrastructure, keeping the review API lightweight and fast.
Deep Dive Questions
How does ranking and relevance work for search results?
Ranking & Relevance
When a user searches "pizza," they expect the best nearby pizzerias — not just the closest ones. Ranking must balance multiple competing signals at 50K QPS across 200M businesses.
The Challenge
Search results need to balance three signals:
- Proximity — Users want nearby options, not restaurants an hour away
- Quality — High ratings matter; a 4.5-star restaurant should outrank a 2-star one at the same distance
- Confidence — A 4.5-star rating from 500 reviews is far more trustworthy than a perfect 5.0 from a single review
At 50K QPS, ranking must be fast — there's no room for complex per-document computation across millions of candidates.
Approach 1: Distance-Only Ranking
Sort results purely by distance from the user's location. Trivially simple and extremely fast — Elasticsearch handles this natively with _geo_distance sort.
Limitation: The closest pizza place might have a 2-star rating with reviews mentioning "cold pizza and rude staff." Users expect quality, not just proximity. Distance-only ranking creates a poor user experience for any query where quality matters more than convenience.
Approach 2: Rating × Inverse Distance
Combine signals with a formula: score = rating × (1 / distance). Higher-rated places rank above closer mediocre ones. This captures both proximity and quality.
Limitation: A brand-new restaurant with a single 5-star review (possibly from the owner) outranks an established 4.5-star restaurant with 500 genuine reviews. Raw star ratings don't account for statistical confidence — small sample sizes produce unreliable averages.
Approach 3: Bayesian Smoothed Ratings
Apply Bayesian smoothing to pull ratings with few reviews toward the global average. The formula:
With prior = 10 and global_avg = 3.7:
- A single 5-star review → smoothed to ~3.8 stars (pulled toward average)
- 500 reviews averaging 4.5 → smoothed to ~4.49 stars (barely affected)
This rewards established businesses with consistent quality over newcomers with inflated ratings.
Limitation: At 50K QPS, applying complex scoring formulas to millions of candidates is too slow. We need a way to limit the scoring to a manageable subset.
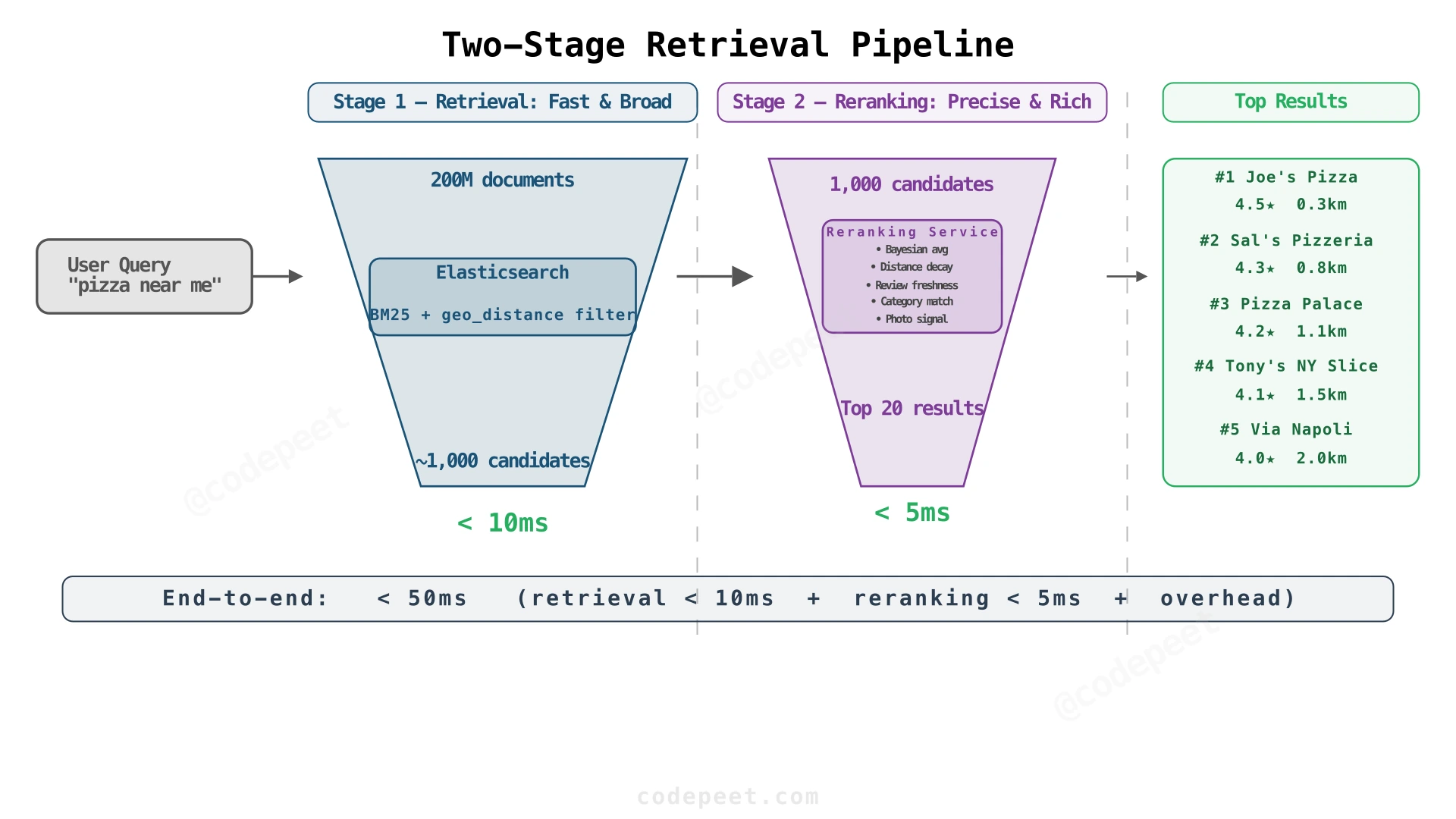
Approach 4: Two-Stage Retrieval (Recommended)
Split ranking into two stages:
Stage 1 — Retrieval: The search index returns the top ~1,000 candidates using simple, fast scoring: text relevance (BM25) + geo filter. This leverages precomputed index structures and runs in single-digit milliseconds.
Stage 2 — Reranking: A lightweight reranking service rescores only the 1,000 candidates with richer signals:
- Bayesian-smoothed rating
- Review freshness (recent reviews weighted more)
- Category relevance (exact category match vs. partial)
- User personalization (if available)
- Photo quality signal (businesses with photos rank higher)
Returns the top 20 results to the user.
This is both fast (only 1,000 documents scored) and accurate (rich signals applied in reranking). The reranking service is stateless and horizontally scalable.
Our Choice: Two-stage retrieval with Bayesian-smoothed ratings in the reranking stage. Start with Elasticsearch's built-in function_score for the retrieval stage. Add a dedicated reranking service when you need ML models, A/B testing flexibility, or personalization — these are hard to implement inside Elasticsearch's scoring pipeline.
How does geo indexing work at scale?
Geo Indexing at Scale
A user at coordinates (40.75, -73.99) searches for pizza within 2 km. With 200 million businesses, we need a spatial index that narrows candidates efficiently. The naive approach — calculating haversine distance for every business — takes seconds and collapses at 50K QPS.
The Challenge
Finding "all points within a radius" appears simple on a 2D plane but is fundamentally hard because:
- Earth is a sphere — distance calculations involve trigonometry, not Pythagoras
- Standard B-tree indexes handle one dimension, not two
- At 200M businesses, even efficient algorithms must eliminate 99.99%+ of candidates before computing exact distances
Approach 1: B-tree on Latitude / Longitude
Index the lat column and query WHERE lat BETWEEN 40.73 AND 40.77. The B-tree narrows to ~1M rows in that latitude band.
Limitation: Latitude 40.75 spans the entire globe — you get businesses in Spain, China, and everywhere at that latitude. A compound index (lat, lng) helps, but B-trees handle one-dimensional ranges efficiently. The second dimension (longitude) is still a scan within the latitude range. Circular radius queries become rectangular bounding boxes that require expensive post-filtering.
Approach 2: Geohash Encoding (Recommended)
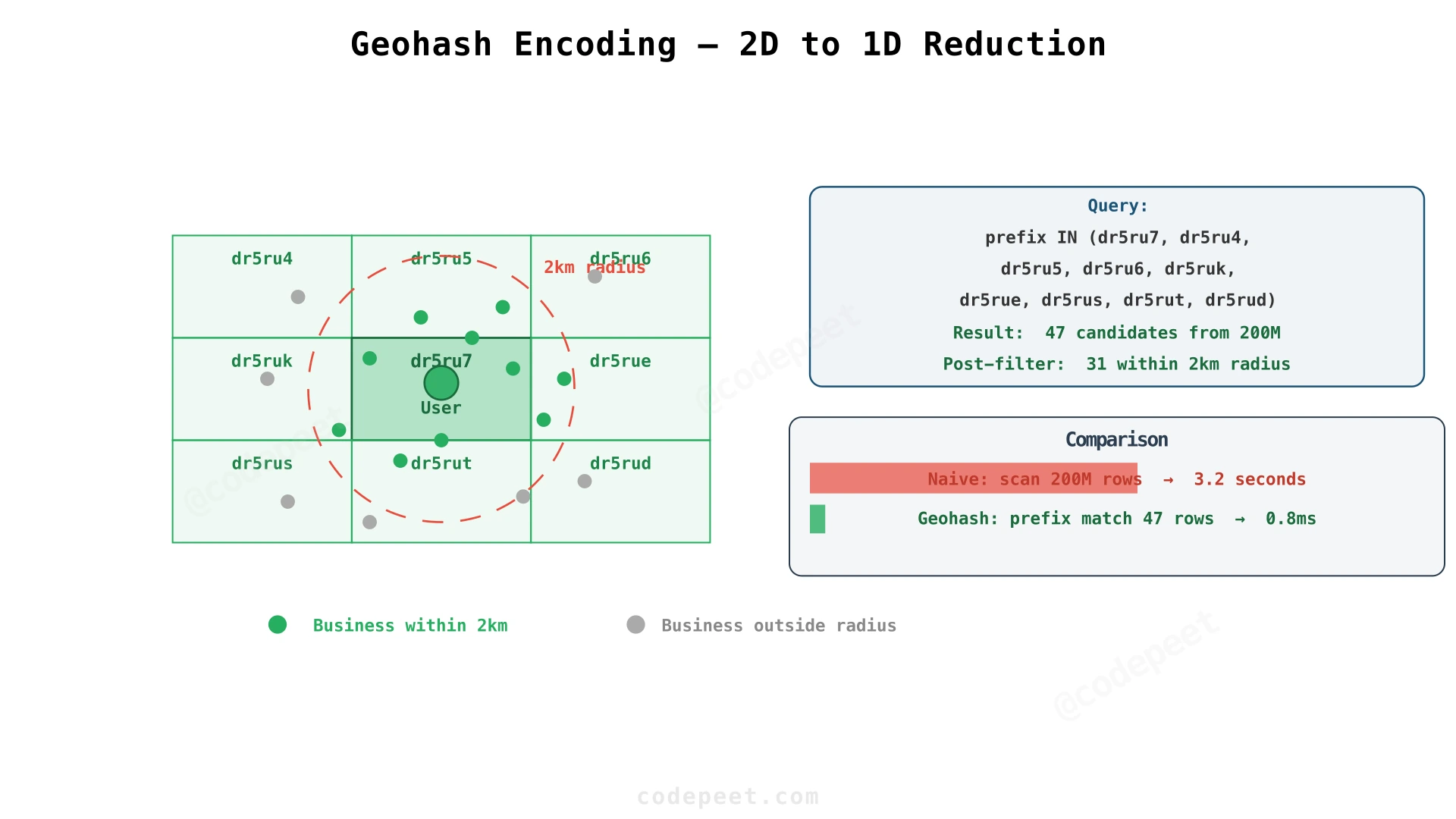
Encode latitude/longitude as a single string: (40.75, -73.99) → "dr5ru7". The key insight: nearby locations share prefixes. The prefix "dr5ru" covers a roughly 1 km² area.
To find nearby businesses:
- Compute which geohash prefixes intersect the search circle
- Query for businesses with those prefixes — this is a simple string prefix match, which B-trees handle efficiently
- Post-filter with exact haversine distance — the candidate set is now small
Why this works: Geohashing reduces a 2D spatial problem to a 1D string prefix problem. Standard indexes, caches, and distributed systems all handle strings well.
Edge case: Grid cells are rectangular, so businesses near cell boundaries may be closer than businesses in the same cell. The solution is to also query adjacent cells (the 8 neighbors). This is well-understood and handled automatically by Elasticsearch's geo_point type.
Approach 3: R-Tree (PostGIS)
R-trees group nearby points into bounding rectangles organized hierarchically. A query traverses the tree, pruning branches whose bounding boxes don't intersect the search area. More accurate for complex shapes (polygons, irregular boundaries).
Limitation: R-trees are single-node data structures — harder to distribute across shards. Well-suited for PostgreSQL with PostGIS, but scaling horizontally for 50K QPS requires application-level sharding or read replicas.
Approach 4: S2 / H3 Cells
Modern geo-indexing systems use spherical cells (Google's S2) or hexagonal cells (Uber's H3). These have mathematically superior properties:
- S2 cells project the sphere onto a cube, then subdivide — cell sizes are more uniform than geohash rectangles
- H3 hexagons have equidistant neighbors (unlike squares, where corner neighbors are √2 farther than edge neighbors)
Limitation: Both require specialized libraries and are less commonly supported by out-of-the-box search engines. Best suited for precision coverage analysis (delivery zones, ride-matching) rather than general proximity search.
Our Choice: Geohash encoding via Elasticsearch's geo_point field type. It combines naturally with text search in a single query, scales horizontally via sharding, and is operationally straightforward. Elasticsearch handles geohash encoding transparently — a geo_distance query is efficient across 200M documents at 50K QPS.
Consider R-tree (PostGIS) if you're already using PostgreSQL and don't need combined text + geo queries. Consider S2/H3 for precise area calculations (delivery zones, ride-matching) where cell uniformity matters.
Geo Distance vs. Road Distance
All spatial indexes above compute geodesic distance — straight-line, "as the crow flies." Real-world travel follows roads. Two restaurants 3 km apart across the San Francisco Bay might be 40 km by road, around the Golden Gate Bridge and back.
How much does this matter? In dense urban grids (Manhattan, central London), geodesic distance closely approximates road distance. Near rivers, bays, mountains, or highways without exits, the gap widens significantly. For areas with many users near such barriers, this affects a meaningful share of results.
A layered approach handles this without slowing search:
- First pass: geo distance. The search index filters candidates by straight-line radius. This is fast and eliminates 99.9%+ of irrelevant businesses.
- Reranking: cached route estimates. Precompute approximate driving distances between geohash-pair grid cells using a routing API (Google Maps, OSRM). Store results in a lookup table. During reranking, replace geodesic distance with the cached road distance for the top ~1,000 candidates.
- Detail view: on-demand routing. When a user opens a specific business page, fetch the actual driving/walking route. A single routing API call is acceptable latency for a detail view.
For interview discussions, acknowledging the geo-vs-road distinction and sketching the layered mitigation demonstrates real-world thinking.
What caching strategy handles read-heavy traffic?
Caching Strategy for 1000:1 Read/Write Ratio
With a 1000:1 read-to-write ratio, every read hitting a database won't scale. At 1,700 business page views per second (7K peak), the database connection pool saturates. Caching is not an optimization — it's a requirement.
The Challenge
Caching involves two decisions: what to cache (and for how long) and how to keep the cache fresh when the underlying data changes. Different data types have different staleness tolerances — business hours should be accurate within minutes, but a rating aggregate lagging by a minute is fine.
What to Cache: TTL by Data Type
| Data Type | TTL | Rationale |
|---|---|---|
| Business metadata (name, hours, location) | 1 hour | Rarely changes. High cache hit rate — a popular restaurant's metadata is requested thousands of times per hour |
| Rating aggregates (avg stars, count) | 5 minutes | Changes with each review submission, but slight staleness (minutes) is acceptable for a display number |
| Search results (for popular queries) | 1 minute | Ranking signals change with each review and rating update. Short TTL still absorbs burst traffic effectively |
| Review pages (paginated) | 5 minutes | First page changes most often (new reviews appear at top). Deeper pages are more stable |
Invalidation Approach 1: TTL-Only
Let cached entries expire naturally based on their TTL. No invalidation logic needed — the simplest possible caching strategy.
Limitation: A restaurant permanently closes. With a 1-hour TTL on business metadata, users see "Open" for up to an hour. For critical updates like business closures, hours changes, or safety alerts, passive expiration creates unacceptable staleness.
Invalidation Approach 2: Event-Based Invalidation
Publish cache invalidation events whenever data changes:
- Business updated → invalidate
biz:{business_id}immediately - Review created → invalidate
agg:{business_id}andreviews:{business_id}:page:1
This provides near-instant freshness for important changes.
Limitation: If the event system (Kafka consumer, invalidation worker) fails or lags, the cache serves stale data indefinitely — there's no fallback expiration.
Invalidation Approach 3: TTL + Event-Based (Recommended)
Combine both strategies: event-based invalidation for immediate freshness on important changes, TTL as a safety net for eventual expiration. If the event system fails, data still expires at the TTL boundary.
Implementation:
- Business metadata changes → fire invalidation event + 1-hour TTL fallback
- Review submitted → fire invalidation for aggregate + first review page + 5-minute TTL fallback
- Search results → TTL-only (1 minute); no event invalidation needed because the cache turns over fast enough
This provides fast freshness when the event system is healthy and guaranteed maximum staleness when it isn't.
Our Choice: TTL + event-based invalidation. Set TTLs by data type based on staleness tolerance. Fire invalidation events for critical changes (business closures, hours updates, new reviews). Redis cluster with key prefixes (biz:*, agg:*, reviews:*, search:*) handles Yelp-scale workloads; add local in-process caching (e.g., Caffeine/Guava) for extreme hot spots.
How do you handle celebrity businesses (hotspots)?
Hotspot Handling
A viral TikTok video sends 100,000 users to a single restaurant's page within an hour. The page normally receives 10 requests per minute. Now it receives 1,000 requests per second — a 6,000× spike. How do we prevent this from degrading the entire system?
The Challenge
Without protection, the spike hammers a single database row and cache key. The database connection pool fills with queries for one business ID. A single Redis node serving the hot key spikes to 100% CPU. Other businesses' pages slow down. The entire system degrades because of one hot key — a classic noisy neighbor problem.
Mitigation 1: Aggressive Caching with Short TTL
Cache the full business page response with a short TTL (10 seconds). At 1,000 req/sec, the cache absorbs 9,990 requests out of every 10,000 — only one request per TTL window reaches the database.
Limitation: All 1,000 requests per second still hit the same Redis key on the same Redis node. The cache layer itself becomes a hotspot. This is the distinction between reducing database load (solved) and distributing cache load (unsolved).
Mitigation 2: Cache Key Replication
Replicate the hot key across multiple cache nodes: instead of a single biz:viral-restaurant, create biz:viral-restaurant:shard:{0-9}. Each request randomly picks a shard. Load distributes across 10 Redis nodes instead of concentrating on one.
Limitation: When the TTL expires, all replicas expire simultaneously. The next burst of requests all see a cache miss — a thundering herd hits the database at once.
Mitigation 3: Request Coalescing (Single-Flight)
When multiple requests hit a cache miss for the same key simultaneously, only the first request fetches from the database. All others wait for that result. 1,000 simultaneous cache misses collapse into a single database query.
Implementation: Use a distributed lock or an in-process single-flight library (e.g., Go's singleflight, Java's CacheLoader).
Limitation: Only helps when many requests arrive during the same cache-miss window. Doesn't help with different cache keys (e.g., paginated review pages — each page is a separate key).
Mitigation 4: Graceful Degradation
When a service is overwhelmed, serve partial data instead of failing entirely:
- Return cached business info without live reviews: "Reviews are temporarily unavailable"
- Pre-cache the first 5 review pages; return a "try again later" message for deeper pages
- If the Review Service is unresponsive, serve the business page without the review section
Users see the business name, hours, and location — the most critical information for deciding whether to visit. Reviews load when traffic subsides.
Detection and Preemptive Warming
Monitor per-key access rates in real time. When a single key exceeds a threshold (e.g., 500 req/sec), automatically:
- Extend the TTL for that key
- Replicate the key across additional cache shards
- Enable request coalescing for that key's cache misses
Integrating with social media monitoring (tracking Yelp business mentions on TikTok/Instagram) can preemptively warm caches before the traffic spike fully materializes.
Our Choice: Layer all four mitigations: aggressive caching reduces database load, key replication distributes cache load, request coalescing prevents thundering herds, and graceful degradation keeps the system usable under extreme conditions. Automated detection triggers escalation through these layers as traffic intensity increases.
What are the trade-offs between search index sync approaches?
CDC Trade-offs for Search Index Sync
The search index must reflect changes in the Business Database. A restaurant updates its hours from "closes at 9 PM" to "closes at 10 PM." How quickly and reliably does the search index reflect that change? The sync mechanism determines the freshness-vs-complexity trade-off.
Approach 1: Dual Write
The application writes to both the database and the search index in the same request handler:
def update_business(business):
db.update(business) # Step 1: primary write
search_index.upsert(business) # Step 2: index write
The simplest approach — no extra infrastructure, no event pipeline, no operational overhead.
Failure Mode: If step 2 fails after step 1 succeeds, the database and index silently diverge. There's no built-in mechanism to detect or repair the inconsistency. Wrapping both in a distributed transaction adds latency and couples availability — if the search index is down, database writes fail too.
Best for: Most applications — startups, internal tools, any system where a small team values simplicity. A nightly reconciliation script catches drift before users notice. At Yelp's scale (200M businesses), reconciliation becomes impractical — scanning 200M rows takes hours.
Approach 2: Periodic Batch Reindex
A scheduled job (every 5–15 minutes) queries the database for recently changed records and bulk-updates the index:
def reindex_job():
changed = db.query(
"SELECT * FROM businesses WHERE updated_at > %s",
[last_run_timestamp]
)
search_index.bulk_upsert(changed)
Limitation: The index can be up to 15 minutes behind the database. A restaurant marks itself as closed, but search results show it as "Open" for the full reindex interval. The batch job also creates periodic load spikes on the database — a thundering herd of reads every 5 minutes.
Best for: Systems where minutes of staleness are acceptable and operational simplicity matters more than freshness — internal tools, analytics dashboards, secondary search features.
Approach 3: CDC Pipeline (Recommended at Scale)
A CDC connector (Debezium) tails the database's transaction log (WAL) and streams changes to the index in near real-time. The database doesn't know the pipeline exists — no application code changes needed.
CDC solves the consistency problem but introduces four dimensions of operational complexity:
1. Stream Joins. Yelp stores businesses and reviews in separate tables. CDC emits row-level change events — a review event carries business_id but not the business name, hours, or coordinates. The consumer must hydrate each event by joining with business data, either via a stream processor (Kafka Streams, Flink) or a lookup service. This is significantly more complex than the SQL JOIN that dual write can do inline.
2. Infrastructure Sprawl. Dual write has two components: the application and the search index. CDC introduces a longer chain: App → DB (WAL) → Connector → Kafka → Consumer → Search Index. Each link needs monitoring, alerting, and operational runbooks. If the connector crashes and the database log rotates before recovery, those changes are permanently lost — a full reindex is the only recovery path.
3. Schema Evolution. An ALTER TABLE ADD COLUMN changes the binary log format. The connector may not recognize the new field, consumers crash on unknown columns, and the search index has no mapping for them. Production CDC pipelines use a schema registry (Confluent Schema Registry, AWS Glue) that enforces compatibility rules (backward, forward, or full compatibility) so schema changes propagate safely through the pipeline.
4. Ordering and Duplication. A user creates a review, then deletes it seconds later. If the delete event arrives before the create event — possible when the consumer parallelizes across partitions — the review becomes a "zombie": permanently in the index, deleted in the database. The fix is partitioning by entity ID so all events for a given entity are processed sequentially within a single partition.
When to Use Each Approach
The decision depends on three factors: required index freshness, team operational capacity, and write volume.
| Scenario | Recommended Approach |
|---|---|
| Write volume < 10 QPS, small team, staleness acceptable | Dual write + nightly reconciliation |
| Minutes of staleness acceptable, batch-friendly workload | Periodic reindex every 5–15 minutes |
| Near real-time freshness required, production-grade system | CDC pipeline with monitoring and alerting |
Comparison Summary
| Dimension | Dual Write | CDC Pipeline |
|---|---|---|
| Implementation effort | Trivial (few lines of code) | High (DevOps/data engineering required) |
| Data consistency | Poor — network failures cause permanent drift | Excellent — guaranteed eventual consistency |
| Write latency impact | Higher — user waits for both writes | None — user only waits for DB commit |
| Coupling | High — application knows about search index schema | Low — application only writes to database |
| Reindexing | Difficult — must query production database | Easy — replay the Kafka topic from offset 0 |
| Failure detection | Manual — requires reconciliation scripts | Automated — consumer lag monitoring alerts |
Verdict for Yelp: CDC is the right choice. Users filtering by "open now" must see accurate hours across 200M businesses. Data drift directly erodes user trust. The operational cost of the CDC pipeline is justified by the consistency guarantee and the ability to replay/rebuild the index from Kafka. For a smaller directory with 10K–100K listings, dual write with reconciliation is the pragmatic choice.
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions without prescriptive answers. They're designed for staff+ conversations where you demonstrate systems thinking, trade-off analysis, and cross-functional strategic reasoning.
Search Index Operations
Context: Your search index has drifted out of sync with the database. Some businesses display incorrect hours, permanently closed businesses still appear in search results, and newly registered businesses aren't discoverable. Users are filing complaints.
Discussion Points:
- How do you detect index drift? What metrics or monitoring would surface the problem — consumer lag, document count divergence, spot-check sampling?
- How do you design reindex/backfill jobs that don't impact production traffic? (Blue-green indexing, throttled reindex, off-peak scheduling)
- What's your strategy for zero-downtime index schema changes? (Alias swapping, reindex-in-background, compatible vs. breaking schema changes)
- How do you handle the trade-off between index freshness and indexing throughput? (Batch size tuning, backpressure, consumer scaling)
- What organizational processes ensure index health is monitored and maintained over time?
Multi-Region Deployment
Context: Yelp expands to Europe. Users in Paris searching for restaurants should hit European infrastructure, not US servers. But a business owner in the US updates their Paris restaurant's hours — that update must propagate to Europe.
Discussion Points:
- How do you route users to the nearest region while maintaining data consistency? (GeoDNS, Anycast, region-aware load balancing)
- Where does the source-of-truth database live? How do you handle cross-region writes? (Single-leader, multi-leader, CRDTs, conflict resolution)
- What's acceptable replication lag for search index vs. business data vs. reviews?
- How do you handle a region outage? Failover strategy — active-passive vs. active-active?
- What trade-offs exist between latency, consistency, and operational complexity in a multi-region setup?
Review Integrity and Abuse
Context: A competitor is paying people to leave 1-star reviews on a client's restaurant chain. Legitimate business owners are furious. Your trust & safety team needs engineering solutions alongside policy.
Discussion Points:
- What signals indicate fake or coordinated review attacks? (Burst patterns, new account clustering, IP correlation, review text similarity, rating distribution anomalies)
- How do you balance aggressive fraud detection with not blocking legitimate negative reviews? (False positive cost vs. false negative cost)
- What's the user experience for flagged reviews? Immediate removal vs. held for manual review vs. visible with reduced trust weight?
- How do you handle appeals from businesses who claim reviews are fake? (Automated review, human escalation queue, transparency reports)
- What cross-functional processes involve legal, support, and engineering in abuse response?
Level Expectations
The following table summarizes what interviewers typically expect at each seniority level when discussing the Yelp system design.
| Dimension | Mid-Level (L4) | Senior (L5) | Staff (L6) |
|---|---|---|---|
| Requirements | List core features (search, view, review); identify the read-heavy traffic pattern | Define latency SLAs per endpoint; distinguish consistency requirements for writes vs. derived data | Detailed failure mode analysis; cross-region consistency trade-offs; capacity planning |
| Search Architecture | Recognize the need for a dedicated search index; mention Elasticsearch | Explain combined geo + text query flow; discuss index sync mechanisms (dual write vs. CDC) | Index operations (zero-downtime reindex, schema evolution); multi-region search; reranking pipeline |
| Data Model | Separate business and review storage; basic pagination approach | Precomputed rating aggregates; cache strategy with TTL by data type; cursor-based pagination | Hotspot handling (key replication, request coalescing); cross-region data ownership; eventual consistency proofs |
| Write Path | Async updates for derived data (aggregates, index) via message queue | Idempotency enforcement (unique constraints + idempotency keys); read-your-writes consistency | Abuse detection and review integrity; CDC operational challenges (stream joins, schema evolution, ordering) |
Interview Cheatsheet
Core Architecture in 60 Seconds
"Search is geo + text → search index." Direct database queries can't achieve sub-200ms latency at 200M businesses. Elasticsearch handles geo filtering and text matching in a single query. CDC keeps the index in sync with the primary database.
"Business page reads details + reviews + cached aggregates." Separate services for business metadata and reviews (different access patterns, independent scaling). Precompute rating_avg and rating_count — never calculate aggregates on every request. Redis cache with TTL-based + event-driven invalidation.
"Write review to DB first; async updates aggregates and index." Durable write to the source of truth, return success. Then fan out via message queue: update aggregates, refresh search signals, invalidate caches. User sees their review immediately (read-your-writes); others see it within seconds (eventual consistency).
"Cache for read-heavy traffic; eventual consistency for derived data." 1000:1 read/write ratio demands aggressive caching. Business metadata (1h TTL), aggregates (5min TTL), search results (1min TTL), reviews (5min TTL). Layer TTL + event-based invalidation for critical updates.
Key Trade-offs to Mention
| Trade-off | Option A | Option B |
|---|---|---|
| Search index sync | Dual write (simple, drifts at scale) | CDC pipeline (reliable, operationally complex) |
| Aggregate computation | Calculate on read (always fresh, slow at scale) | Precompute on write (fast reads, slight lag) |
| Cache invalidation | TTL-only (simple, may serve stale data) | TTL + events (fresh, more infrastructure) |
| Geo indexing | Geohash (simple, good for proximity) | R-tree/S2/H3 (precise, harder to distribute) |
| Review consistency | Strong everywhere (slow, complex) | Tiered: strong writes, eventual derived data |
| Hotspot handling | Over-provision (expensive, wasteful) | Layered mitigation (complex, efficient) |