rate-limiter
Introduction
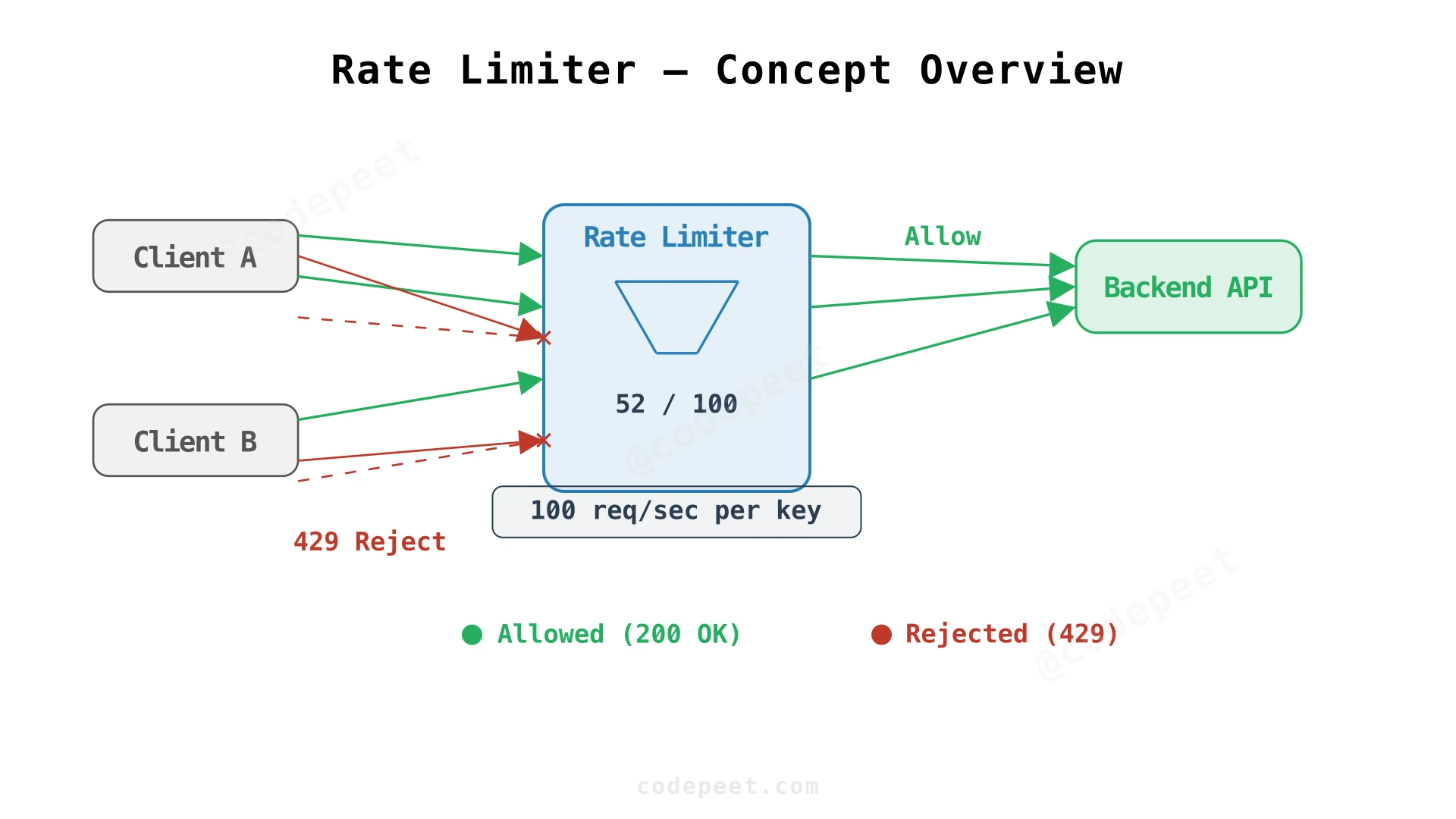
Every time you call the Stripe API, an invisible gatekeeper checks whether you've exceeded your quota. If you have, you receive a 429 Too Many Requests response before your request ever reaches the payment processing logic. That gatekeeper is a rate limiter — and it processes this decision in under 1 millisecond.
A rate limiter controls how many requests a user, API key, or IP address can make within a given time window. Stripe allows "100 requests per second per API key." If a client sends 150 requests in one second, the rate limiter allows the first 100 and returns 429 Too Many Requests for the remaining 50. This protects Stripe's backend from overload while giving each customer a fair share of capacity.
You'll find rate limiters in every public API (Twitter, GitHub, AWS), multi-tenant SaaS platforms, and any system that needs to prevent abuse or ensure fair resource sharing.
In this design, we'll build a distributed rate limiter that sits at the API gateway layer, enforces per-key limits with burst tolerance, and maintains consistency across multiple gateway instances — the same architecture that powers rate limiting at Stripe, Cloudflare, and Kong.
LLD Connection: This problem connects to the LRU Cache Low-Level Design problem (DP4), where you design the in-memory data structure that underpins token bucket state management. The HLD focuses on distributed architecture, gateway placement, and consistency across instances.
Why Rate Limiters Are Hard in Distributed Systems
A rate limiter on a single server is trivial: increment a counter, check a threshold, reset on a timer. The challenge appears when you have multiple servers. If you run 50 API gateway instances (common at any company handling significant traffic), and each gateway has its own local counter, a user can exploit this by distributing requests across all 50 gateways and effectively multiply their allowed rate by 50×.
This means the rate limiter needs: (1) shared state accessible by all gateway instances with sub-millisecond latency, (2) atomic operations to prevent race conditions when two gateways check the same user simultaneously, and (3) fault tolerance so the rate limiter itself doesn't become the system's weakest link.
These three challenges — shared state, atomicity, and fault tolerance — form the backbone of this design. Every architectural decision we make traces back to solving one of these problems.
Background
The question is intentionally vague, as is often the case in system design interviews. We want a rate limiter to protect backend services — but where do we put it?
Why Throttle Early
The core goal is protecting your backend from overload. If we check limits after a request reaches backend services, we've already paid the cost: database queries, business logic, downstream service calls. A throttled request should consume minimal resources. This means we need to enforce limits before any expensive work happens.
Where the Limiter Sits
Since where enforcement happens cascades into every other part of the system, we need to address it first. We need to enforce "100 requests per second per user" before the backend does any expensive work. But where in the request path should we check this limit? Let's reason through the options by thinking about when we can identify the user and when we can reject the request.
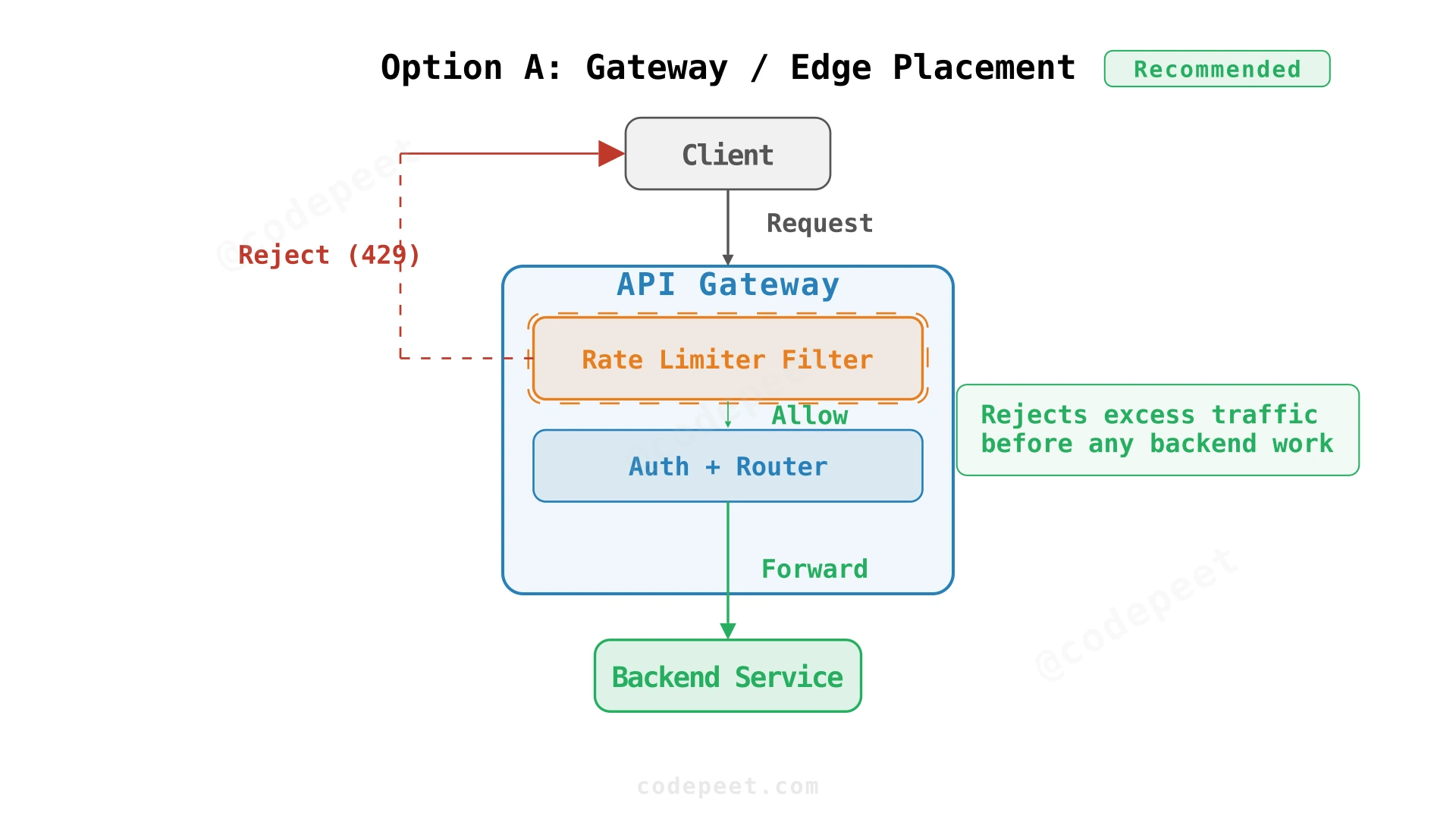
Option A: Gateway/Edge Placement (Recommended)
Requests hit your API gateway first — it's the entry point that routes traffic to backend services. The gateway sits at the "edge" of your infrastructure (the boundary between external clients and your internal services). We already extract the API key or user identity at the gateway for authentication. If we enforce rate limits right here, we can reject excess traffic before it consumes any backend resources.
The gateway sees every request before any backend service does. If we add a filter that checks "has this API key exceeded its limit?" we can return a 429 error immediately — no database query, no business logic, no wasted resources. Since the gateway already has the identity information, we're not adding new parsing overhead.
The problem: you're running multiple gateway instances for availability and scale. Each gateway needs to know the current count for every user. If Gateway A allows 50 requests and Gateway B allows 50 requests for the same user, you've allowed 100 total when the limit is 100 per second. This means gateways need to share state somehow (we'll address this later).
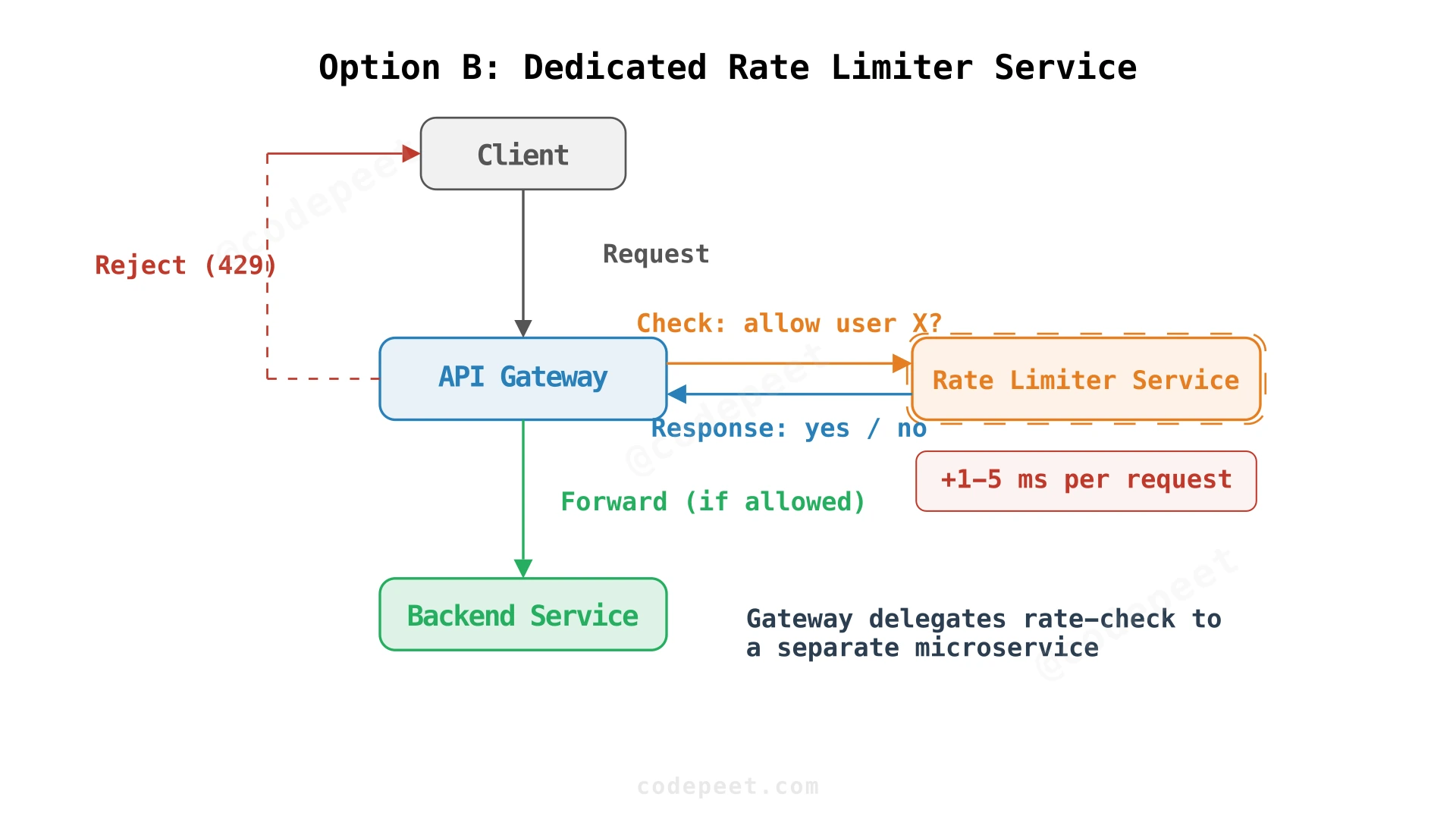
Option B: Dedicated Rate Limiter Service
What if rate limiting logic gets complex — weighted costs per endpoint, dynamic policies, machine learning models? You might want to isolate this logic in a dedicated service that's easy to update independently.
The gateway calls out to a rate limiter service: "Should I allow this request from user X?" The service responds "yes" or "no." This separation means you can deploy new rate limiting logic without touching the gateway code. You can also scale the rate limiter independently if it becomes a bottleneck.
The problem: Now every API request requires two network calls: client → gateway, then gateway → rate limiter service. That rate limiter call adds 1-5ms of latency. Plus, the rate limiter service becomes a new critical dependency — if it's down, you need a failure policy (allow all vs deny all). This extra hop consumes 10-50% of our entire latency budget when we're targeting single-digit millisecond overhead.
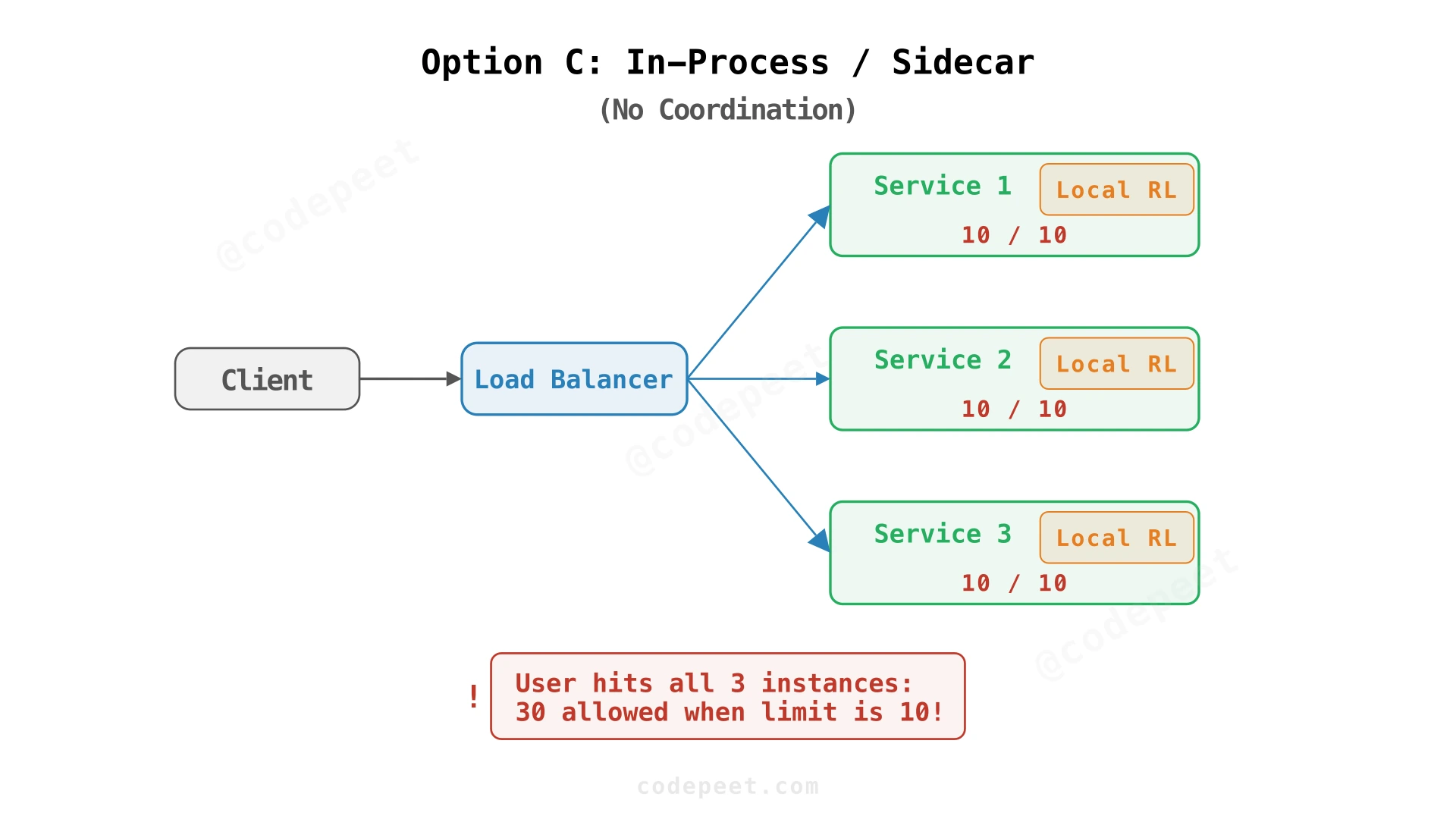
Option C: In-Process / Sidecar
What if we skip network calls entirely? Each service instance could track rate limits locally in memory. No shared state, no network latency — just an in-memory counter check.
The rate limiter lives in the same process (or sidecar container) as your API service. Checking limits is just a function call — sub-millisecond. No external dependencies, no network failures. This is the fastest option.
The problem: Each service instance has its own view of rate limits. If you have 10 gateway instances and a user sends 100 requests evenly distributed across them, each instance sees only 10 requests and allows them all. You've allowed 100 requests when the limit might be 10. You can't enforce global "per user" limits accurately without coordination between instances. This works if you only need coarse limits ("don't let one instance process more than 1000 req/sec total") but fails for precise per-user limits.
Our Choice: Gateway/Edge Placement
We're going with gateway placement. Here's why: the problem asks for "consistent global limits" across a distributed system. Gateway placement is the only option that gives us a single enforcement point without adding extra network hops. While a dedicated service would also work, it adds 1-5ms of latency on every request — that's 10-50% of our entire latency budget when we're targeting single-digit millisecond overhead.
The tradeoff is that the gateway becomes a critical dependency, but we mitigate that with multiple gateway instances (which we'd need anyway for scale). This matches production patterns you'll see at companies like Stripe, Twilio, and AWS API Gateway.
| Placement | Latency Added | Accuracy | Complexity | Used By |
|---|---|---|---|---|
| Gateway/Edge | ~1-2ms (Redis call) | High (shared state) | Moderate | Stripe, AWS, Cloudflare |
| Dedicated Service | +1-5ms (extra hop) | High (shared state) | High (new service) | Complex multi-tenant systems |
| In-Process/Sidecar | <0.1ms (memory) | Low (no coordination) | Low | Coarse per-instance limits |
Functional Requirements
We extract verbs from the problem statement to identify core operations:
- "rate limiter must run inline at the API gateway" → PLACEMENT requirement (the limiter runs as a gateway filter)
- "gateway must call a limiter module and react on allow vs deny" → INTERFACE requirement (the gateway-limiter protocol with proper HTTP responses)
- "system must determine a stable identity per request" → IDENTIFICATION requirement (extract user/API key/IP from each request)
- "limiter must allow short bursts while enforcing a long-term average rate" → ALGORITHM requirement (burst-tolerant rate limiting)
- "must enforce limits correctly across multiple instances" → CONSISTENCY requirement (shared state across gateways)
- "operators must be able to update rate limit policies" → CONFIGURATION requirement (dynamic policy management without restarts)
Each verb maps to a functional requirement that defines what the system must do.
-
Run inline at the API gateway: The rate limiter must intercept every request as a filter inside the API gateway, blocking excess traffic before it reaches backend services.
-
Call a limiter module with proper responses: The gateway must call the limiter, react correctly on allow vs deny, and return proper HTTP responses including
429 Too Many RequestswithRetry-Afterheaders and rate limit headers (X-RateLimit-Limit,X-RateLimit-Remaining,X-RateLimit-Reset). -
Determine a stable identity per request: The system must extract a stable identity per request (user ID, API key, tenant, or IP address) to track usage fairly and prevent abuse.
-
Allow short bursts while enforcing long-term average rate: The limiter must support short bursts of requests (e.g., a dashboard page making 20 parallel API calls) while enforcing a long-term average rate per identity.
-
Enforce limits correctly across multiple gateway instances: Traffic distributed across N gateways must see correct global limits, not N× the limit.
-
Update rate limit policies without redeploying gateways: Operators must be able to change rate limit rules (tighten during an attack, relax for enterprise customers) without restarting any gateway.
Out of Scope
- Billing integration (tracking prepaid request credits that roll over month-to-month)
- Weighted rate limits based on endpoint cost (e.g., treating "upload video" as 10× more expensive than "get profile")
- Instant policy propagation (we accept up to 60 seconds of staleness via cache refresh)
- Authentication and authorization (assume caller identity is already resolved)
- DDoS protection at the network layer (L3/L4 — we operate at L7)
- Rate limiting for WebSocket or streaming connections
Scale Requirements
- 1 million requests per second across all gateway instances (think: medium-sized API like Stripe, Twilio)
- 100 million different users/API keys (each gets their own rate limit bucket)
- Rate limiter must add less than 10ms to each request at p99
- Unused rate limit data should automatically delete itself (don't store limits for users who stopped making requests months ago)
Non-Functional Requirements
Non-functional requirements define the quality attributes that make the difference between a whiteboard sketch and a production system. While functional requirements answer "what does the system do?", non-functional requirements answer "how well does it do it?"
We extract adjectives and descriptive phrases from the problem statement to identify quality constraints:
- "controls how many requests" + "given time window" → Correctness (rate limits must be enforced accurately, not approximately)
- "protects backend from overload" → Availability (the rate limiter itself must not become a single point of failure)
- "before any expensive work" → Low latency (sub-10ms rate limit evaluation)
- "multiple gateway instances" → Consistency (all instances must agree on current usage counts)
- "short bursts" + "long-term average" → Burst tolerance (don't punish normal traffic patterns)
- "users can't fake their identity" → Security (prevent identity spoofing to bypass limits)
The scale requirements translate to these system qualities:
Scale
- Handle 1 million requests per second at the gateway
- Support 100 million different users/API keys without running out of memory
Latency
- Add less than 10ms per request for rate limit checks at p99
- Hot path must avoid any blocking I/O beyond the shared state lookup
Availability
- Keep the API running even if the rate limiter has problems
- Decide what happens when dependencies fail (allow all requests vs block all requests)
Correctness
- When two requests for the same user arrive at the same time, both checks must see the current token count (if we allow one request to read stale data, we might allow 101 requests when the limit is 100)
- Prevent users from bypassing limits by sending requests to different gateways at once
Security
- Make sure users can't fake their identity to get more quota (e.g., changing their API key in the header to look like a different user and reset their rate limit counter)
Data cleanup
- Rate limit state for inactive users must auto-expire to prevent unbounded memory growth
High Level Design
1. Gateway Placement with Inline Filter
Requirement: The rate limiter must run inline at the API gateway to block excess traffic before it reaches backend services.
From the background section, we chose gateway placement. Now let's make that concrete.
The Filter Approach
We run the rate limiter as a filter inside the API gateway — a piece of code that intercepts every request before it goes anywhere else. When a request arrives, the filter checks "has this user exceeded their limit?" If yes, return 429 immediately. If no, let the request through to the backend.
The gateway already extracts the API key for authentication. The rate limit filter reuses that identity to look up current usage. Since we're inline, denied requests never touch the backend — they cost only the limit check itself (a Redis call, typically 1-2ms).
What This Creates
The limiter now sits on the hot path for every request. This creates two constraints we need to solve:
- Speed — We have a 10ms latency budget. The limit check must be fast.
- Correctness — Multiple gateways might check the same user simultaneously. We can't let race conditions cause over-admission.
The remaining requirements address these constraints. FR2-4 define what the filter does. FR5 solves the multi-gateway coordination problem.
Two Components
It helps to think of the rate limiter as two separate pieces:
The RateLimit Filter runs in the gateway. It extracts identity, looks up the policy, calls the state store, and decides allow/deny. This is the decision logic.
The state store holds the counters (how many tokens does this user have?). In a single-gateway setup, this could be in-memory. In production with multiple gateways, it must be shared — we'll use Redis.
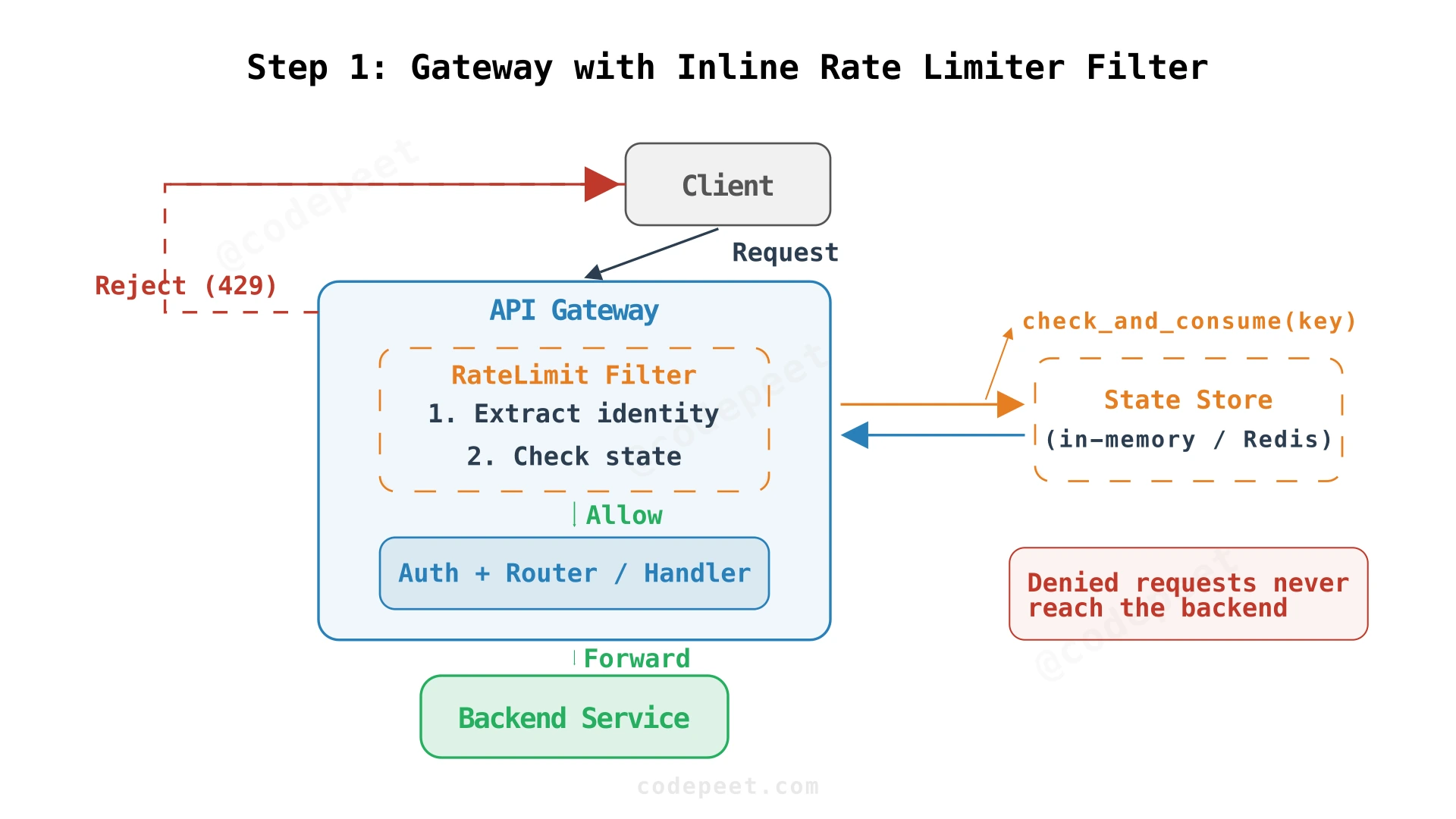
This design works perfectly for a single gateway instance. But in production, API traffic is distributed across multiple gateway instances behind a load balancer. Each instance has its own local counter — they don't share state. A user with a 100 req/min limit sending traffic across 5 gateways could effectively make 500 req/min (100 per gateway). We need shared state.
2. Gateway-Limiter Interface
Requirement: The gateway must call a limiter module and react correctly on allow vs deny, including returning proper HTTP responses to the client.
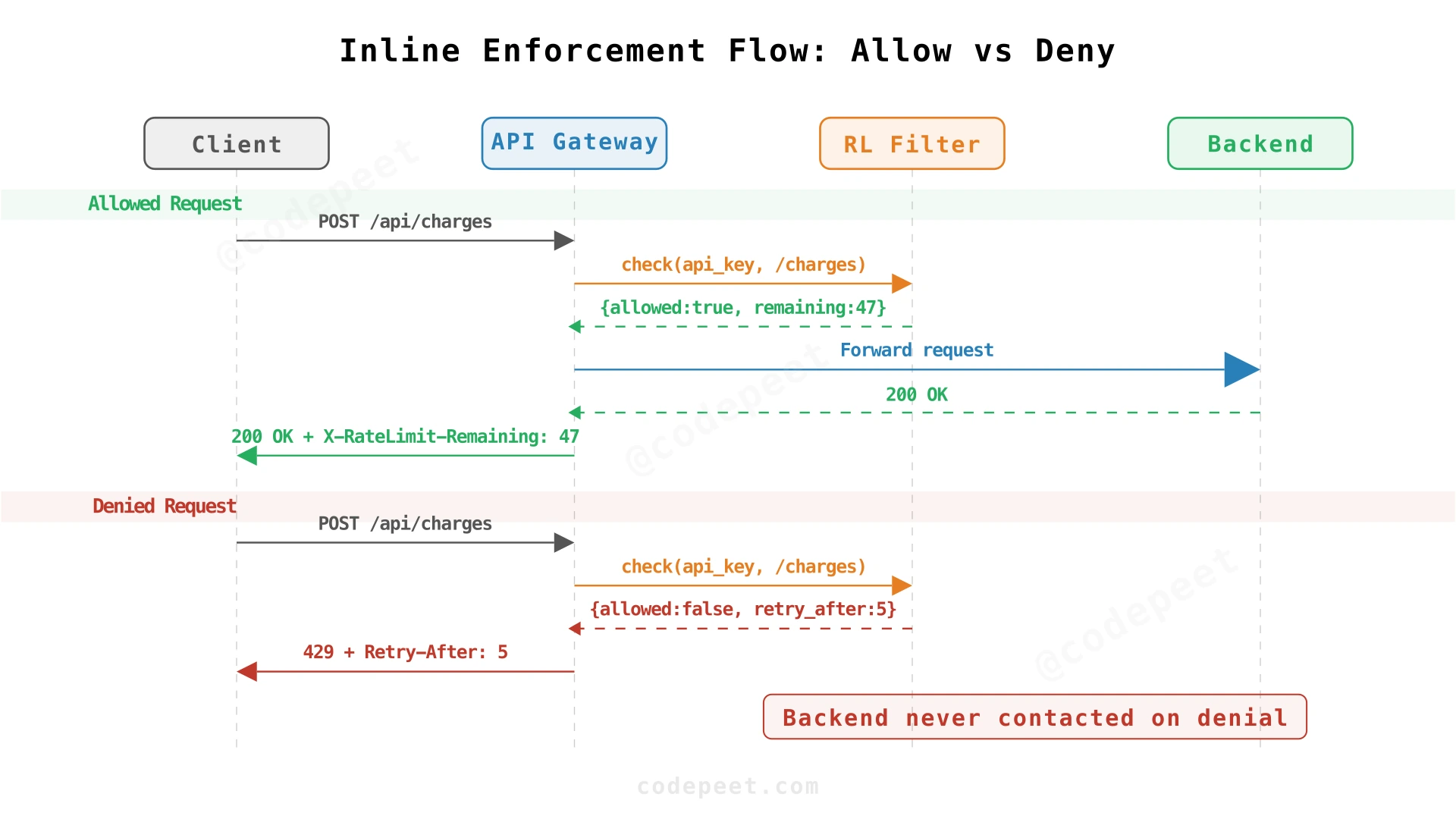
The gateway filter needs to ask one question: "Should I allow this request?" The limiter answers with three pieces of information: yes/no, how long to wait if denied, and how many requests remain in the quota.
The Check
For each request, the gateway passes the limiter three things: who's making the request (API key or user ID), which endpoint they're hitting (/api/search), and the policy that applies (10 requests per second, 20 token capacity). The limiter checks current usage against the policy and returns a decision.
If allowed, the gateway forwards the request to backend services. If denied, it returns an error immediately — no backend work happens.
The 429 Response
When denying a request, the gateway returns HTTP status 429 Too Many Requests. This status code is universally recognized by HTTP client libraries — most will automatically back off and retry.
The response also includes standard rate limit headers:
HTTP/1.1 429 Too Many Requests
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1710000060
Retry-After: 5
Without Retry-After, 1000 throttled clients would all retry immediately, creating a thundering herd. With Retry-After: 5, they spread their retries over time.
Reject vs Delay/Queue
When a request exceeds its limit, you have two choices: reject immediately or queue and process later.
Reject immediately: Return 429 right away. The client sees the error and decides whether to retry. This is simple — no queuing state, no background workers. The gateway stays stateless and fast. Every request either forwards immediately or rejects immediately. Zero added latency on the hot path. Most HTTP libraries already handle 429 retries automatically.
Queue and process later: Hold the request in a FIFO queue and process at a fixed rate. The backend sees perfectly smooth traffic. But now every request pays queue wait time. If the queue has 50 requests and you process 100/second, the 51st request waits 500ms. The gateway becomes stateful (harder to scale). You also need timeout handling — what if a request sits in the queue for 30 seconds and the client has already given up?
Our choice: Reject with 429. Queuing adds significant complexity (stateful gateway, queue management, timeout handling) for minimal benefit. Most production systems reject immediately and let clients handle retries.
3. Identify the Requestor
Requirement: The system must determine a stable identity per request (user, API key, tenant, IP) to track usage fairly and prevent abuse.
Before we can enforce "10 requests per second," we need to define what "per" means. Per user? Per API key? Per IP address?
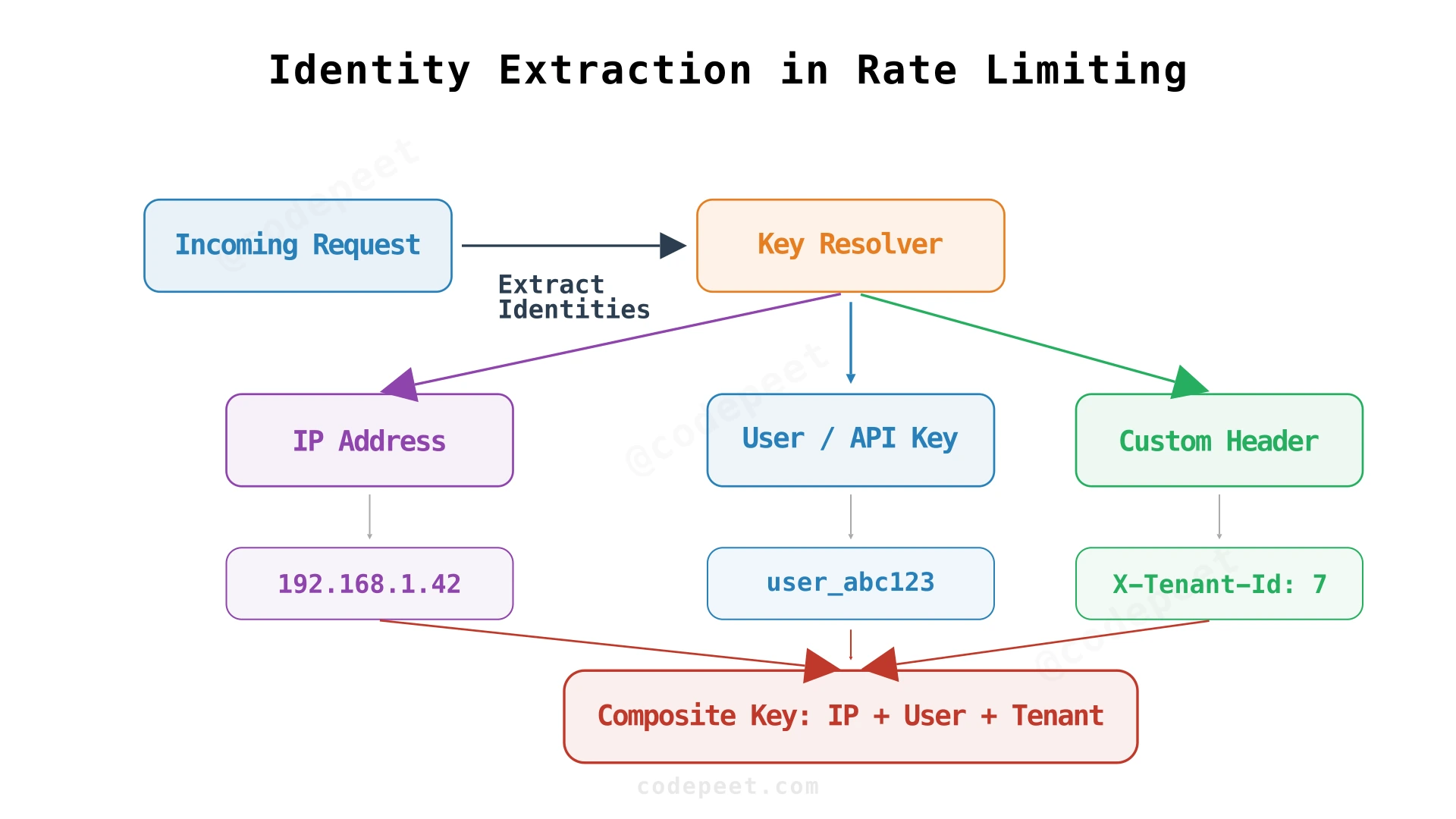
Extracting Identity
The gateway already parses the X-API-Key header or Authorization: Bearer <token> for authentication. We reuse this to identify who's making the request. From the authenticated context, we can also derive the tenant/organization (which maps to billing plans) and extract the IP address from headers or the direct connection.
Why Multiple Scopes
We don't pick one identity — we extract all of them and enforce limits at each scope simultaneously. A request must pass per-API-key, per-IP, and per-tenant checks. If any fails, deny.
Why layer them? Each scope catches different abuse patterns:
Per-User or Per-API-Key: You want to give each customer a fair share. Policy: "100 requests/minute per API key." Every customer gets the same limit regardless of others. The problem: a Sybil attack — an attacker creates 100 free accounts and gets 100× the limit.
Per-IP: Blocks brute-force attacks and bot traffic. Works for unauthenticated endpoints like login pages. The problem: 1000 employees at a company share one corporate NAT IP. Too low a limit blocks legitimate users; too high lets attackers through.
Per-Tenant: Aligns with billing for multi-tenant SaaS. Policy: "10,000 requests/hour per organization." The problem: one buggy script from one user can exhaust the entire tenant's quota.
Layering these prevents different attack patterns: Per-IP stops Sybil attacks. Per-user ensures fairness. Per-tenant prevents runaway scripts.
How Identity Resolution Works in Practice
The gateway already authenticates the request before rate limiting. Authentication resolves the raw Authorization: Bearer <token> into an api_key_id and tenant_id. The rate limiter receives these resolved identities — it never parses tokens itself.
For unauthenticated endpoints (login, registration, password reset), identity falls back to IP address extracted from X-Forwarded-For or the direct connection. Be careful with X-Forwarded-For — it can be spoofed if not validated. In production, strip and re-set this header at the load balancer so the first (leftmost) value is always the client's real IP as seen by your infrastructure.
The Redis key format combines identity and scope:
ratelimit:{scope}:{identifier}
Examples:
- Per-API-key:
ratelimit:ak_abc123:global - Per-IP:
ratelimit:ip:203.0.113.42 - Per-tenant:
ratelimit:tenant:org_acme - Per-endpoint:
ratelimit:ak_abc123:/api/charges
4. Burst-Tolerant Algorithm
Requirement: The limiter must allow short bursts of requests while enforcing a long-term average rate per identity.
Why Bursts Happen
A user loads a dashboard page. The page makes 20 API calls in parallel for different widgets. A strict "10 requests per second" limiter allows 10, denies 10. The page loads half-broken. But this user is well-behaved — over the next minute, they sent only 20 requests total (0.33 req/sec average). The strict enforcement punished a normal traffic pattern.
We need an algorithm that allows bursts while enforcing long-term average. Let's evaluate the four standard algorithms.
Fixed Window (boundary burst problem)
Count requests in fixed time buckets. Reset the counter every N seconds.
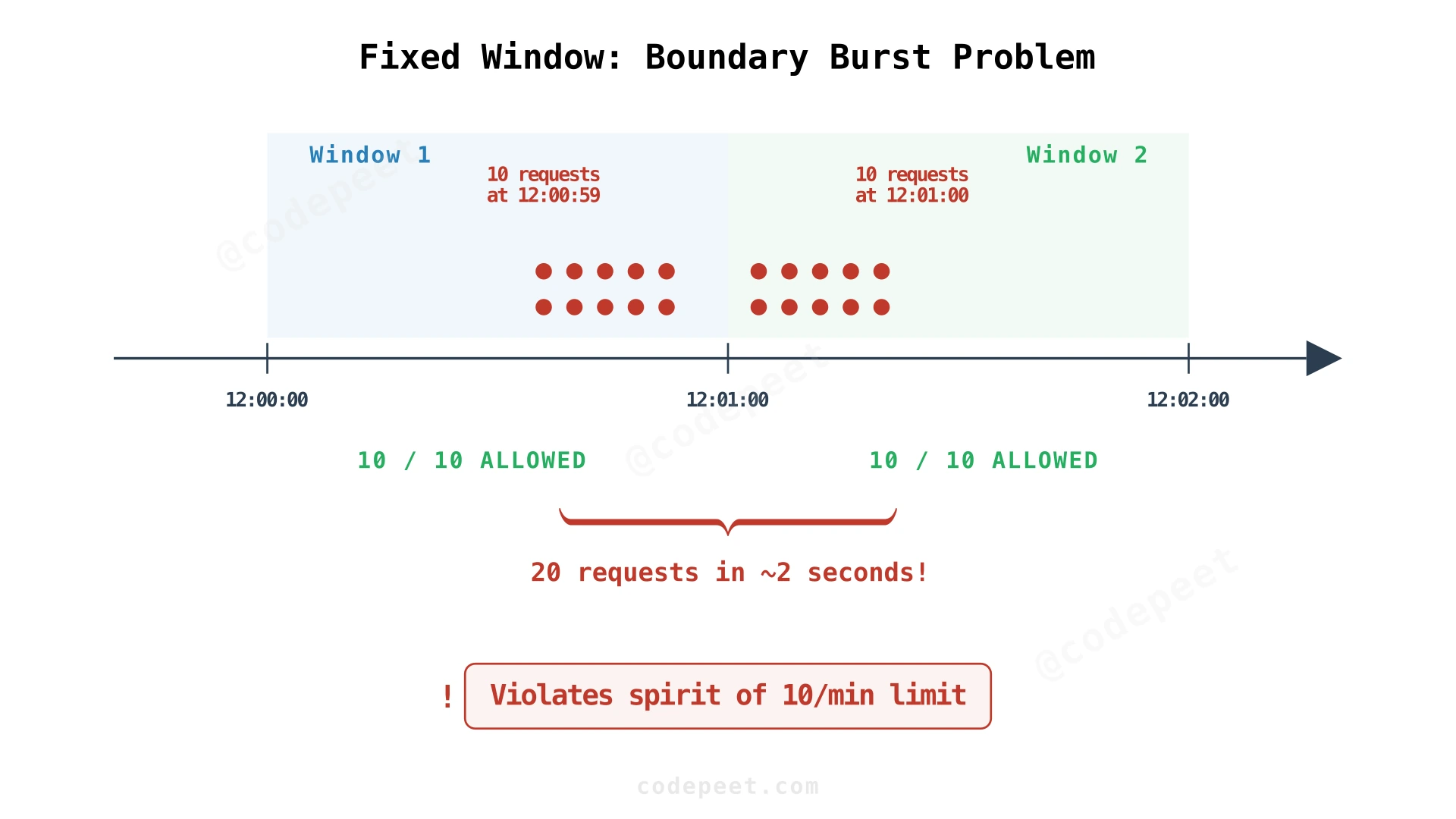
This is the simplest algorithm: maintain one integer per key. When a request arrives, increment the counter. If the counter exceeds the limit within the current window, deny. When the time window ends (e.g., every 60 seconds), reset the counter to zero.
The implementation requires minimal state — just one number — and the logic is trivial. This makes it extremely fast and memory-efficient.
The fatal flaw is the boundary burst problem. A user can send 10 requests at 12:00:59, then 10 more at 12:01:00. The limiter sees only 10 requests in the 12:00-12:01 window and 10 in the 12:01-12:02 window — both allowed. But the user sent 20 requests in 2 seconds, violating the spirit of "10 requests per minute."
This boundary condition makes fixed window unsuitable for any scenario where burst control matters.
Implementation detail: The Redis key incorporates the window boundary: ratelimit:{user_id}:{window_start}. Example: ratelimit:user_123:1710000000 for the window starting at that Unix timestamp. When the window rolls over, a new key is created. Old keys expire via TTL. The simplicity is appealing — one INCR command per request — but the boundary burst problem disqualifies it for production API rate limiting.
Sliding Window (high memory and CPU cost)
Store the timestamp of every request. When a new request arrives, count how many timestamps fall in the last N seconds.
This fixes the boundary problem. The window moves continuously with time. At 12:00:30, you count requests from 11:59:30 to 12:00:30. No fixed boundaries means no boundary gaming.
Fixed window would let 20 requests pass at the boundary. Sliding window would count all 20 in the same 60-second window and reject half.
The cost is prohibitive at scale. A "1000 requests per minute" limit stores 1000 timestamps per user. Each timestamp is 8 bytes. That's 8KB per user. For 100 million users, you need 800GB of Redis. Token bucket stores two numbers per user — 16 bytes total. That's 1.6GB for 100 million users.
The CPU cost is also high. Every check scans all timestamps to count which ones are fresh. For 1000 req/min, that's 1000 comparisons per request. Token bucket does 3 operations: read tokens, calculate refill, subtract one.
Production systems avoid this. They use token bucket or approximate sliding window with counters instead of full timestamp logs.
The approximate sliding window counter is a compromise: maintain two fixed-window counters (current and previous) and calculate a weighted average. If we're 30% into the current window, the approximate count is 0.7 × previous_count + 1.0 × current_count. This requires only 16 bytes (two counters) while solving the boundary burst problem. Cloudflare uses this approach and reports 0.003% error rate — good enough for most APIs. However, token bucket offers strictly superior burst handling because you can configure burst capacity independently of sustained rate.
Leaky Bucket (adds latency, queues requests)
Leaky bucket is the opposite of token bucket. Requests flow IN (enter a queue), then leak OUT at a constant rate. This creates perfectly smooth output traffic.
The output is perfectly smooth — no matter how bursty the input, requests leave the queue at exactly N per second. This is ideal for protecting downstream services that need consistent load.
The problem is latency. Every request waits in the queue. If the queue has 50 requests and processes 100 per second, the 51st request waits 500ms. Your p50 latency is now queue wait time plus actual processing time.
Memory grows under sustained load. If input exceeds the leak rate for an extended period, the queue fills up. You need to decide: reject new requests (defeating the purpose of queuing) or grow the queue unbounded (risking out-of-memory).
Leaky bucket also penalizes legitimate bursts. A user loading a dashboard with 20 parallel API calls gets 20 requests queued, even though their long-term average is well under the limit. The page loads slowly for no reason.
This algorithm makes sense for batch processing systems where smoothing traffic is more important than latency. It's rarely the right choice for user-facing APIs.
When leaky bucket makes sense: Network traffic shaping (controlling bandwidth), video streaming servers (sending frames at a constant rate), and batch job schedulers (processing tasks at a steady pace). In all these cases, the consumer genuinely needs smooth, predictable input.
Token Bucket (industry standard, burst-friendly)
Token bucket is the opposite of leaky bucket. Tokens flow IN (accumulate over time), then requests consume them OUT. This allows bursts while enforcing long-term average.
Each user gets a bucket that holds tokens. The bucket has two parameters: capacity (max tokens) and refill rate (tokens per second). When a request arrives, the algorithm checks if the bucket has at least one token. If yes, consume the token and allow the request. If no, deny the request.
Tokens refill continuously at the specified rate. If the bucket fills to capacity, excess tokens are discarded. This creates a natural burst allowance: users who stay quiet accumulate tokens, then can spend them in a burst. But sustained high traffic eventually drains the bucket.
Back to our dashboard example: the user was idle for 2 seconds, accumulating 20 tokens (10/sec × 2 sec). When the page loads and fires 20 parallel requests, the bucket has enough tokens. All 20 pass. The user's long-term average is still well under the limit.
The algorithm needs just two values per user: current token balance and the timestamp of the last refill. When a request arrives, calculate how much time has passed, add the appropriate tokens (capped at capacity), then check if there's enough to allow the request. This is 16 bytes of state and constant-time math — far cheaper than sliding window's timestamp log.
When denying a request, we can calculate exactly when enough tokens will refill. If the user has 0.3 tokens and needs 1, and tokens refill at 10/second, they'll have enough in 0.07 seconds. Round up to 1 second for the Retry-After header.
Step-by-step animation showing how the token bucket algorithm processes requests over time
Our Choice: Token Bucket
Token bucket gives users a "savings account" of requests. Tokens accumulate over time (the refill rate), up to a maximum balance (the capacity). Each request withdraws one token. If the account is empty, the request is denied.
| Algorithm | Burst Handling | Memory per Key | Complexity | Accuracy | Used By |
|---|---|---|---|---|---|
| Fixed Window | Poor (boundary spike) | 8 bytes (count + timestamp) | Simple | Approximate | Basic rate limiters |
| Sliding Window Log | Perfect | O(n) per request in window | Complex | Exact | Analytics systems |
| Sliding Window Counter | Good (approximation) | 16 bytes | Moderate | ~99% | Cloudflare |
| Token Bucket | Excellent (configurable burst) | 16 bytes (tokens + last_refill) | Moderate | Exact | Stripe, AWS, Kong |
| Leaky Bucket | Smooths all bursts (adds latency) | 16 bytes | Moderate | Exact | Network traffic shaping |
Token bucket wins for API rate limiting because:
- Burst tolerance is configurable — set
capacityto control how much burst you allow - Memory efficient — only 2 values per key (current tokens + last refill timestamp) = 16 bytes
- Redis-friendly — the check-and-update logic fits in a single Lua script for atomicity
- Deterministic
Retry-After— can calculate exactly when tokens will be available - Industry standard — Stripe, AWS API Gateway, Kong, and Google Cloud all use Token Bucket
Storing Token Bucket State
The algorithm needs to persist two values per user: current token count and last refill timestamp. On each request, you calculate elapsed time, refill tokens proportionally, check availability, and update the state.
Redis works well for this. It's an in-memory key-value store with sub-millisecond latency. Store the user's token state under a key like ratelimit:user:123:tokens. Redis handles millions of reads and writes per second, and its TTL feature automatically expires inactive user keys after a timeout (e.g., 1 hour). The basic flow: read the key, calculate new token count based on elapsed time, check if sufficient tokens exist, decrement if allowing the request, write back the updated state.
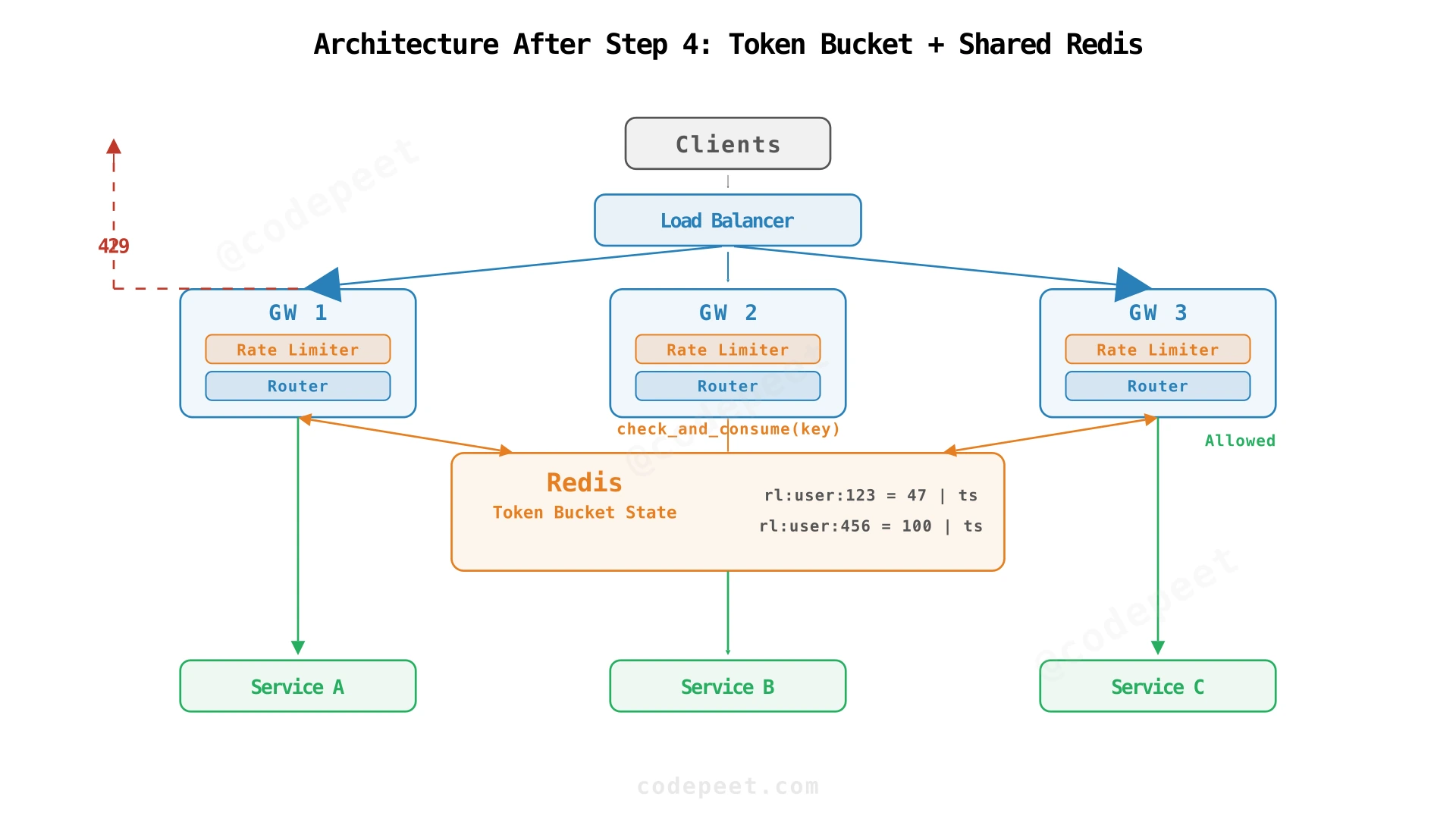
5. Consistent Enforcement Across Gateways
Requirement: The limiter must enforce limits correctly across multiple API gateway instances, so traffic cannot bypass limits by hitting different instances.
The Multi-Gateway Problem
In production, you run 10-100 gateway instances for availability and scale. If each gateway tracks limits in its own memory, a user can hit all 10 gateways and get 10× their limit. A policy of "10 req/sec per user" becomes "10 req/sec per user per gateway" = 100 requests per second total.

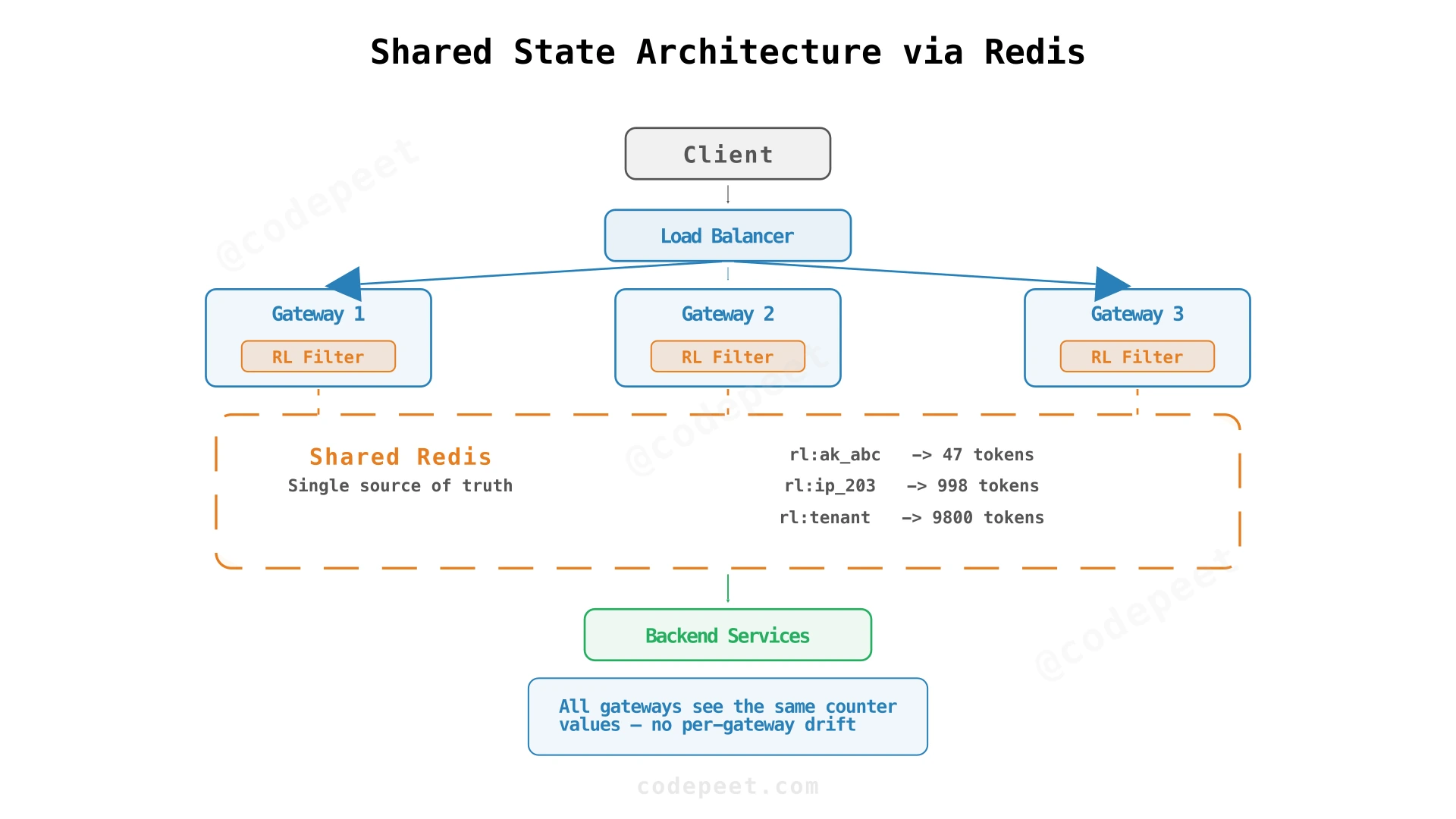
Shared State with Redis
The solution: all gateways read and write token counts from a shared store. When Gateway A allows a request and decrements the token count, Gateway B sees that update immediately.
Redis fits this role well. It's an in-memory key-value store with sub-millisecond latency (typically 0.2-1ms per operation). It supports Lua scripts for atomic read-modify-write operations — critical for preventing race conditions when multiple gateways check the same key simultaneously. And it has built-in TTL support, so inactive users' keys automatically expire.
Each rate limit key combines identity and scope: ratelimit:ak_abc123:/api/search. If enforcing multiple scopes (per-user + per-IP + per-tenant), create separate keys and check all of them. Deny if any fails.
Atomic Updates
Two gateways might check the same key at the same instant. If both read "5 tokens," both think they can allow a request, and both write "4 tokens." The user got two requests through but only paid for one token. This is a race condition.
Redis solves this with Lua scripts. The gateway sends a script that reads the current tokens, calculates the new value, and writes it back — all as a single atomic operation. No other command can run in the middle. The full Lua implementation is covered in the Deep Dives section.
Living with the Latency
Redis adds 1-2ms to every request. For most APIs, this is acceptable — your backend probably takes 50-200ms anyway. But it's not free. Minimize overhead with connection pooling (reuse connections instead of opening new ones) and pipelining (batch multiple Redis commands into one network round trip when checking multiple rules).
When Redis Fails
Redis is now on the critical path. If it's slow or down, set an aggressive timeout (5-10ms) so a slow Redis doesn't cascade into slow API responses. Most production systems fail-open (allow all requests) during outages to maintain API availability, with local in-memory limits as a coarse fallback. The failure handling deep dive covers this in detail.
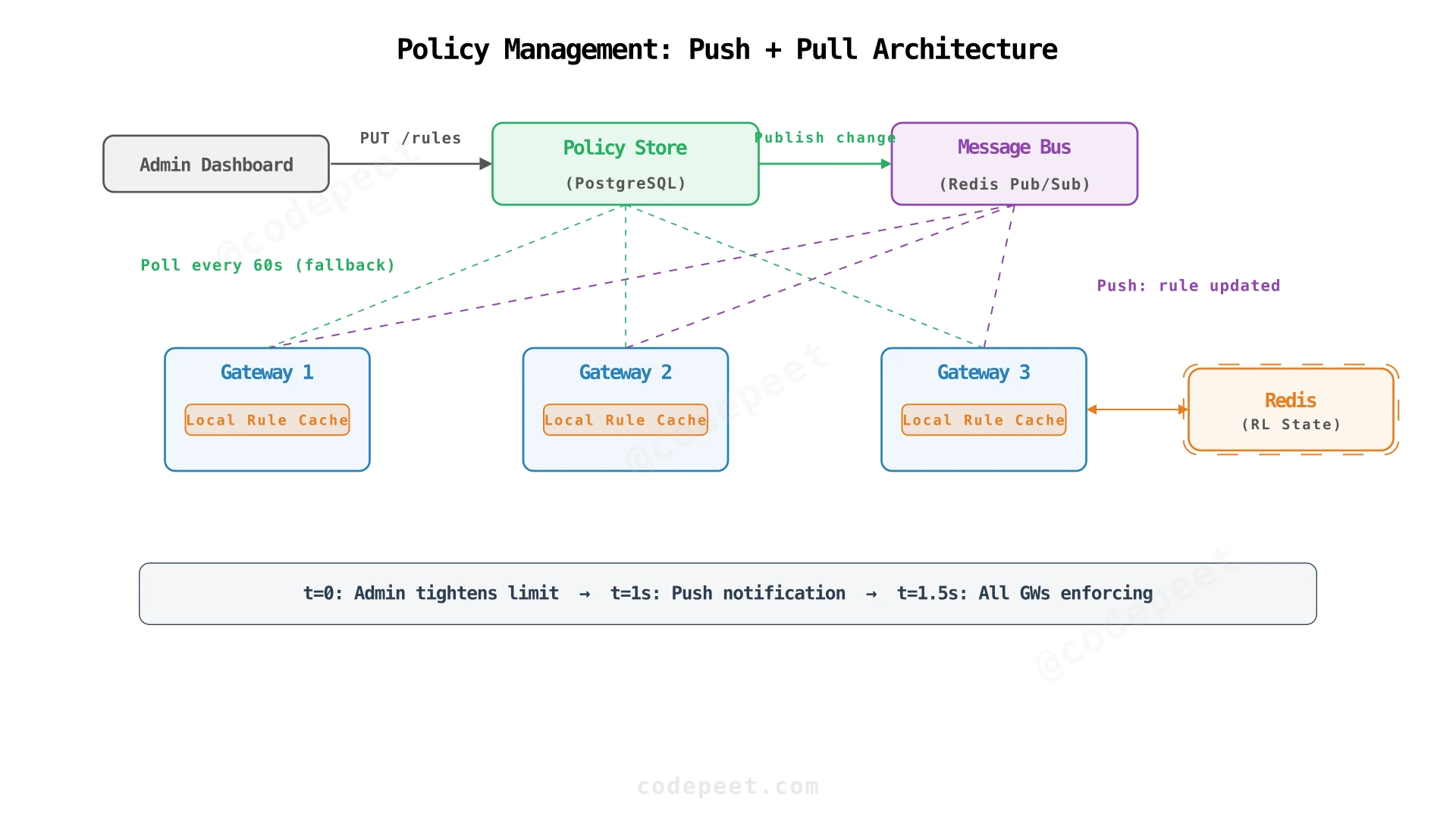
6. Policy and Configuration Management
Requirement: Operators must be able to update rate limit policies safely without redeploying gateways.
An attacker starts hammering your /api/login endpoint. You need to tighten the limit from 100/minute to 10/minute — right now. If policies are baked into gateway config files, you're looking at a rolling restart across 50 gateway instances. That takes 15 minutes. The attack continues.
Policies must update without restarts.
Adding Policy Components
We need two new components in our architecture:
A Policy Store (PostgreSQL, DynamoDB, or etcd) holds all rate limit rules: which endpoints they apply to, which identity scope to track, and the token bucket parameters. This is the source of truth that operators update.
A Policy Service sits between the store and gateways. When a policy changes, it notifies gateways to refresh their cache. Gateways cache policies in memory so the hot path never calls the policy service per-request.
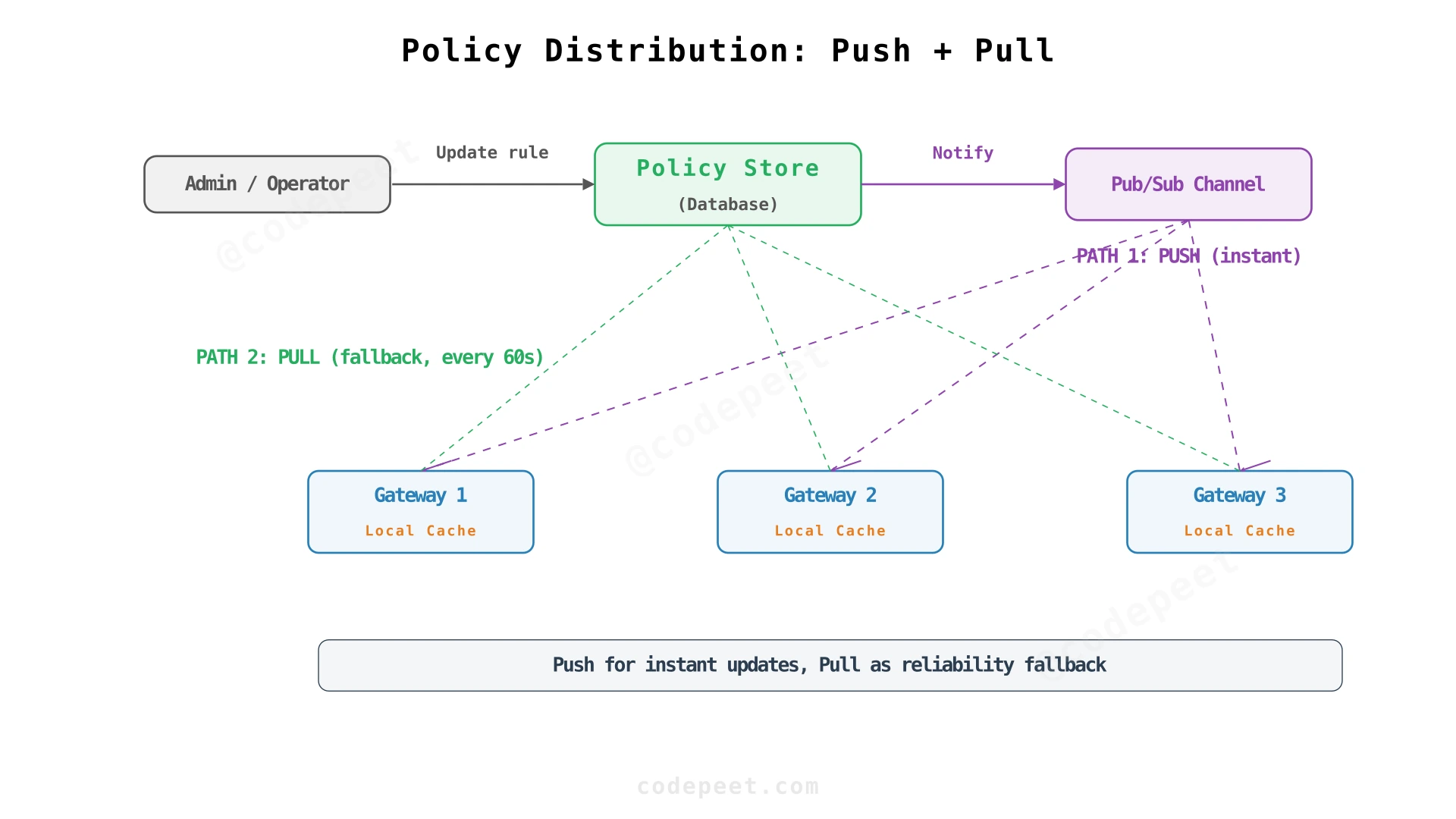
Push vs pull: Push (via pub/sub or webhooks) gives you instant propagation — the attacker scenario resolves in seconds. Pull (periodic polling every 30-60s) is simpler but slower. Most production systems use push with pull as a fallback for reliability.
The gateway's hot path reads from local cache, never calling the policy service per-request. Cache refreshes happen in the background.
Example rule format:
{
"rule_id": "rule_001",
"key_type": "api_key",
"endpoint": "/api/charges",
"capacity": 100,
"refill_rate": 1.67,
"description": "Standard tier: 100 req/min for charges endpoint"
}
Deep Dive Questions
How do you ensure consistent rate limiting across multiple gateway instances?
This is a senior-level deep dive.
You have 10 gateway instances behind a load balancer. A user with a 100 requests/minute limit sends 200 requests. The load balancer distributes them evenly — 20 requests to each gateway. If each gateway tracks limits independently, each sees only 20 requests and allows them all. The user just got 200 requests through — double their limit.
This is the distributed enforcement problem. Local counting doesn't work when traffic spreads across instances.
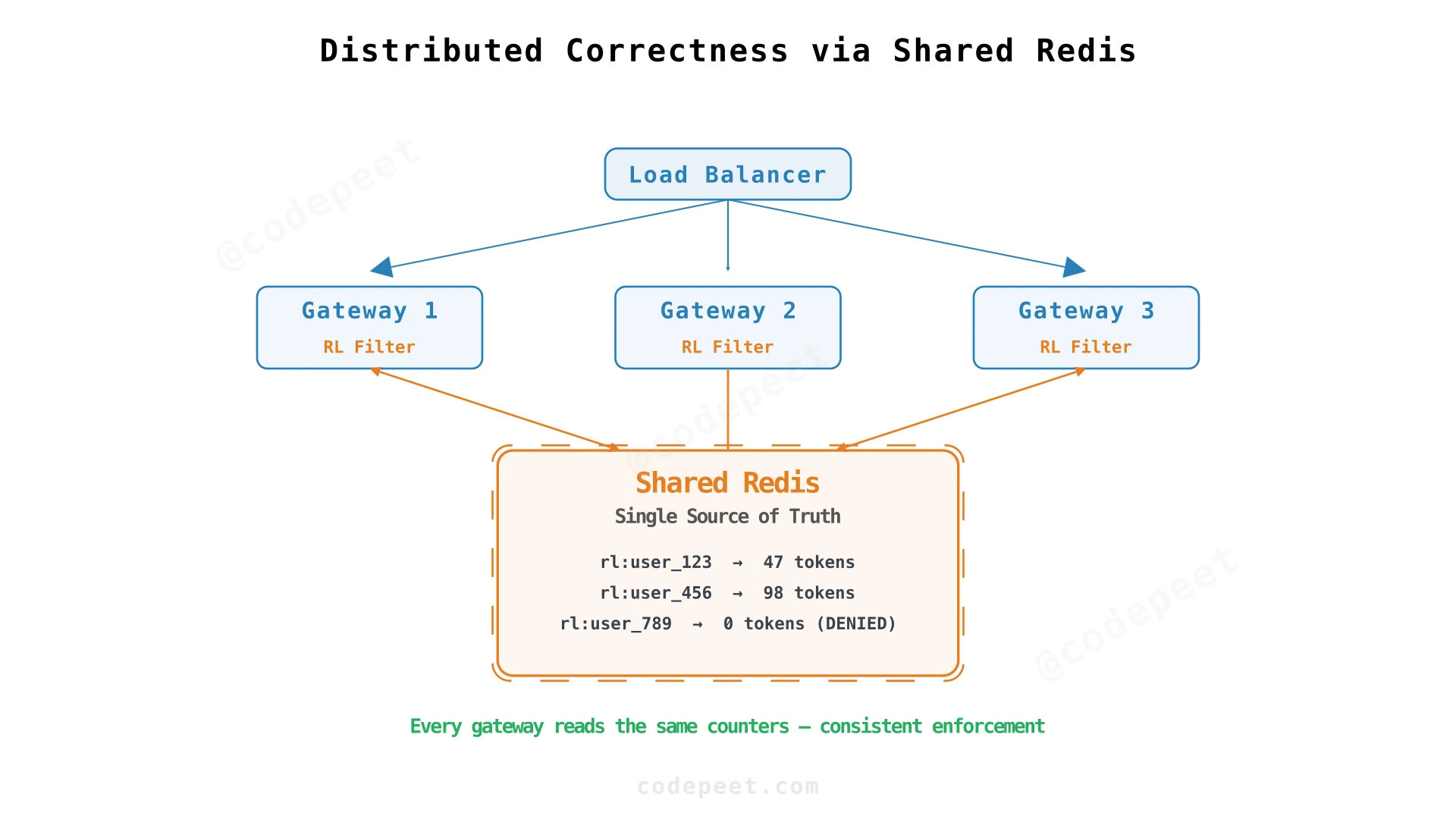
Why Shared State
All gateways need to read and write the same counters. When Gateway A allows a request and decrements the token count, Gateway B must see that updated count immediately. This points to a shared data store.
The store needs three properties:
- Fast reads and writes — We're checking limits on every API request. Adding 50ms of latency is unacceptable. We need sub-millisecond operations.
- Atomic updates — Two gateways might check the same key simultaneously. The store must handle this without race conditions.
- Auto-expiration — Users come and go. If someone stops making requests, their rate limit state should eventually disappear. We can't store counters forever.
Redis fits all three: in-memory storage gives sub-millisecond latency, Lua scripts provide atomicity, and TTL handles expiration automatically. A traditional SQL database would struggle with millions of writes per second. A distributed cache like Memcached lacks the atomic scripting we need.
Living with the Latency
Redis adds 1-2ms to every request. For most APIs, this is acceptable — your backend probably takes 50-200ms anyway. But it's not free.
Minimize overhead with connection pooling (reuse connections instead of opening new ones) and pipelining (batch multiple Redis commands into one network round trip when checking multiple rules).
The Availability Tradeoff
Redis is now on your critical path. If Redis goes down, what happens to your API? Set aggressive timeouts (5-10ms), use a circuit breaker to stop calling Redis when it's unhealthy, and fall back to local in-memory limits as a safety net.
Alternative: Local State with Sync
Some systems skip shared state entirely. Each gateway maintains local counters and periodically syncs with a central store. This trades accuracy for independence — if the central store goes down, gateways keep working with local limits.
The tradeoff: limits can be exceeded by up to num_gateways × local_limit during the sync interval. With 10 gateways and a 100/minute limit, a user could theoretically get 1000 requests through before the sync catches up. This is only acceptable for coarse limits where occasional bursts are fine.
How do you ensure atomic check-and-update of token bucket state under concurrent requests?
This is a senior-level deep dive.
A user with 1 token remaining sends two requests at the same instant. Gateway A reads "1 token available," allows the request, and writes "0 tokens." But Gateway B also reads "1 token available" before A's write lands. B allows its request too. Both requests pass. The user exceeded their limit.

The Problem: Read-Modify-Write
This is a classic race condition. Both gateways read the same value before either writes. The fix requires atomicity — bundling these three steps into one indivisible operation:
- Read current tokens
- Decide allow/deny and calculate new token count
- Write updated tokens
If another request tries to run while these steps execute, it must wait. No interleaving allowed.
How Redis Provides Atomicity
Redis is single-threaded — it processes one command at a time. But a token bucket check requires multiple operations. If we send these as separate commands, another gateway's commands can slip in between.
Redis solves this with Lua scripts. You upload a small program (written in Lua) once, and Redis caches it. Gateways call the script using EVALSHA — a command that says "run the script with this hash." Redis executes the entire script as a single atomic unit. While it runs, nothing else can interrupt.
Inside the script, we use HMGET and HMSET to read and write the token bucket state. These are Redis hash commands — they store multiple fields (tokens and last_refill timestamp) under one key. The script:
HMGETreads current tokens and last refill timestamp- Calculates how many tokens have refilled (elapsed time × refill rate)
- Checks if enough tokens exist; if yes, subtracts one
HMSETwrites the updated tokens and timestamp back- Sets an
EXPIREfor auto-cleanup of inactive keys - Returns allowed/denied plus retry_after time
With this script, Gateway A's check runs completely, then Gateway B's check runs. B sees 0 tokens and denies the request. No race condition.
The Lua Script
-- Token Bucket Rate Limiter (atomic Lua script)
local key = KEYS[1]
local capacity = tonumber(ARGV[1])
local refill_rate = tonumber(ARGV[2]) -- tokens per second
local now = tonumber(ARGV[3]) -- current timestamp
local cost = tonumber(ARGV[4]) or 1 -- tokens to consume
-- Read current state
local state = redis.call('HMGET', key, 'tokens', 'last_refill')
local tokens = tonumber(state[1]) or capacity
local last_refill = tonumber(state[2]) or now
-- Refill tokens based on elapsed time
local elapsed = now - last_refill
tokens = math.min(capacity, tokens + elapsed * refill_rate)
-- Check and consume
local allowed = 0
local retry_after = 0
if tokens >= cost then
tokens = tokens - cost
allowed = 1
else
retry_after = math.ceil((cost - tokens) / refill_rate)
end
-- Write updated state with auto-expiry
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
redis.call('EXPIRE', key, 3600) -- 1 hour TTL for inactive keys
return {allowed, math.floor(tokens), retry_after}
The gateway calls: EVALSHA <script-hash> 1 ratelimit:ak_abc123 100 1.67 1710000000 1
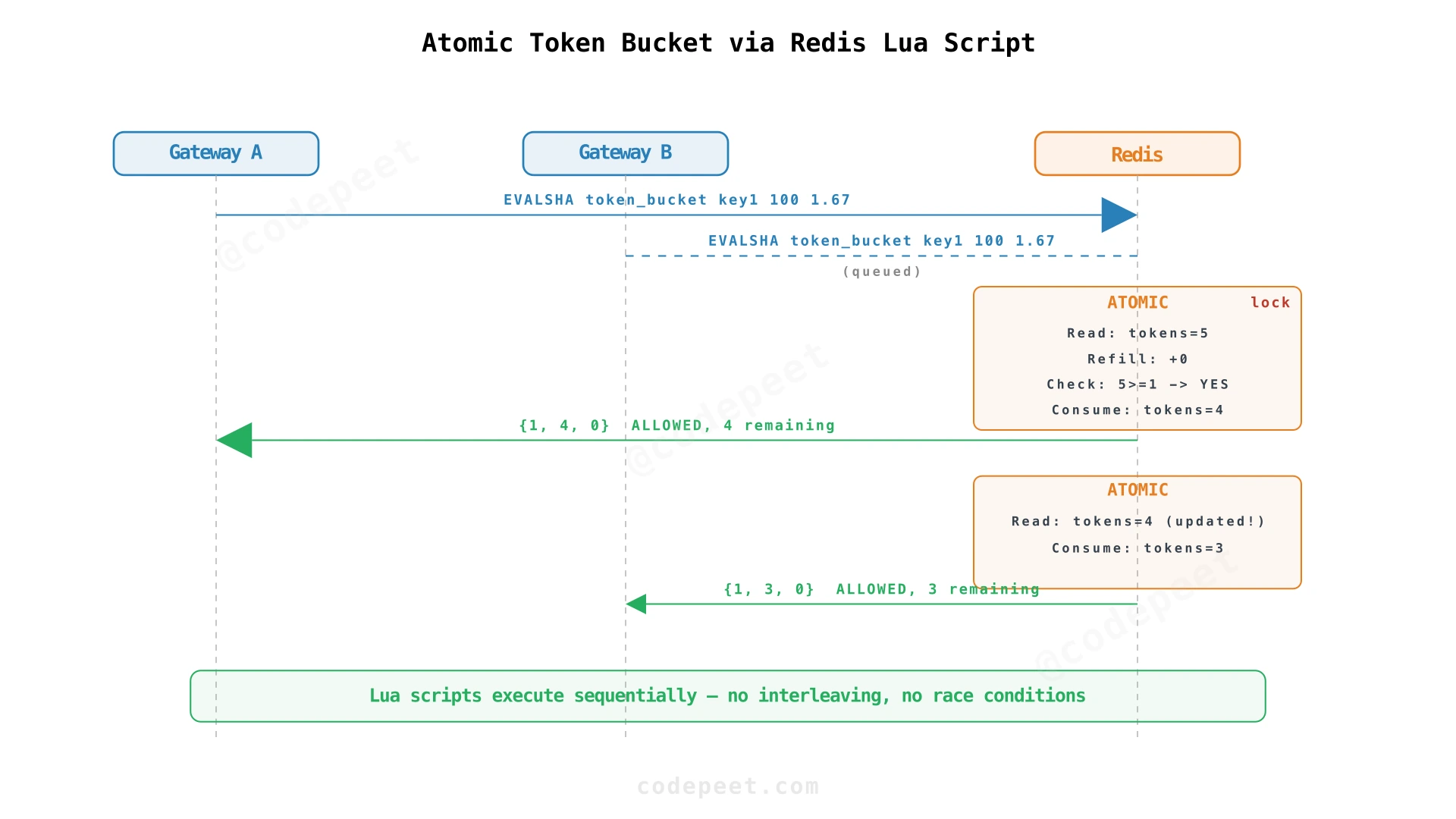
Performance impact: Lua script execution adds ~0.1ms over a simple INCR command. For our 10ms budget, this is negligible.
Alternative: Redis Transactions (MULTI/EXEC): Redis transactions guarantee atomic execution of multiple commands, but they don't support conditional logic ("if tokens > 0 then decrement"). Lua scripts can include conditionals, making them strictly more powerful for rate limiting.
Alternative: Distributed Locks: You could use Redis SETNX to lock a key before modifying it. But locks add latency (extra round trip for acquire/release) and introduce lock contention under high concurrency. Lua scripts are simpler and faster.
How do you handle multiple rate limit rules per request?
This is a mid-level deep dive.
A request arrives from API key ak_abc123, IP address 203.0.113.42, belonging to tenant org_acme. You want to enforce three limits simultaneously: 100 requests/minute per API key (fairness), 1000 requests/minute per IP (abuse prevention), and 10,000 requests/hour per tenant (quota control). How do you check all three efficiently without tripling your Redis latency?
Building Redis Keys
Each rule needs its own Redis key. Use a template that combines identity with scope:
- Per-API-key:
ratelimit:ak_abc123:global - Per-IP:
ratelimit:ip:203.0.113.42 - Per-tenant:
ratelimit:tenant:org_acme
The gateway extracts these identities from the request, builds all three keys, and checks each one against its corresponding policy.
Evaluating Multiple Rules
For our example request, the gateway runs three Lua scripts (one per rule). Redis pipelining sends all three in a single round trip — this takes 2-3ms total instead of 1-2ms per rule sequentially.
Each script returns {allowed, remaining, retry_after}. The gateway combines results with a simple rule: deny if any rule denies, and use the longest retry_after.
| Per-API-key | Per-IP | Per-Tenant | Decision | Retry-After |
|---|---|---|---|---|
| Allow | Allow | Allow | Allow | 0 |
| Deny (5s) | Allow | Allow | Deny | 5 |
| Allow | Deny (10s) | Allow | Deny | 10 |
| Deny (5s) | Deny (10s) | Deny (3s) | Deny | 10 |
Should You Short-Circuit?
If the first rule denies, should you skip checking the others? This saves Redis calls, but skipping means those rules don't update their token counts. Over time, skipped rules drift from reality — they think they have fewer tokens than they actually consumed.
Production systems typically check all rules regardless of early denials. The cost is small (a few extra Redis calls), and it keeps all counters accurate for observability and debugging.
Why Redis Pipelining Matters Here
Without pipelining, three Redis calls happen sequentially: 1-2ms each = 3-6ms total. With pipelining, we batch all three into a single network round trip: the gateway sends three EVALSHA commands back-to-back without waiting for responses, then reads all three responses at once. Total time: 1-2ms (one round trip). This is critical for staying within our 10ms latency budget.
Pipelining also reduces connection overhead. Instead of 3 separate send-receive cycles, we do 1 send (with 3 commands) and 1 receive (with 3 responses). At 1M requests/second, this reduces Redis connection utilization by 2/3.
The Rate Limit Response Headers
The response headers report the most restrictive remaining limit:
HTTP/1.1 429 Too Many Requests
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1710000060
Retry-After: 5
How do you deploy and update rate limit policies without restarting gateways?
This is a senior-level deep dive.
An attacker starts hammering your /api/login endpoint. You need to tighten the limit from 100/minute to 10/minute — right now. But your rate limit rules are baked into gateway config files. Changing them means a rolling restart across 50 gateway instances. That takes 15 minutes. The attack continues.
Distributing Policies
Store policies in a central database (PostgreSQL, DynamoDB, or a config service like etcd). Gateways cache policies in memory and refresh them periodically or on push notification.
Push vs pull: Push (via pub/sub or webhooks) gives you instant propagation — the attacker scenario resolves in seconds. Pull (periodic polling every 30-60s) is simpler but slower. Most production systems use push with pull as a fallback for reliability.
The gateway's hot path reads from local cache, never calling the policy service per-request. Cache refreshes happen in the background.
Testing with Dry-Run Mode
You want to tighten /api/search from 100/minute to 50/minute. But what if legitimate power users regularly hit 80/minute? You'd block your best customers.
Dry-run mode lets you test before enforcing. Deploy the new policy with dry_run: true. Gateways evaluate the rule and log what would have happened, but always allow the request. Watch the logs for 24-48 hours: how many requests would have been blocked? Are they abusive or legitimate?
If the metrics look good, flip dry_run: false. If not, adjust the limit and repeat. No customer impact during testing.
Handling Exceptions
Enterprise customer signs a contract for 10× the standard limit. Internal monitoring service needs to bypass rate limiting entirely. Store exceptions separately: {api_key: "ak_enterprise", override: {rate: 1000}} and {api_key: "ak_monitoring", bypass: true}. Gateways check exceptions before applying standard rules. The exception lookup is in-memory (cached alongside regular policies), so it adds no latency.
Rolling Back Safely
A bad policy deploys. Requests that should pass are getting blocked. You need to rollback immediately.
Keep the last few policy versions in gateway memory. When you push a rollback, gateways switch to the previous version instantly — no restart, no deploy. Time to recovery: under a minute.
For extra safety, roll out policy changes gradually: 10% of gateways first, monitor for 10 minutes, then 50%, then 100%. If errors spike at 10%, you've only affected a fraction of traffic.
What happens when Redis is slow or unavailable?
This is a senior-level deep dive.
Redis goes down. Your rate limiter can't check limits. What happens to the 10,000 requests per second hitting your API?
The Cascading Failure
Without protection, here's what happens: each gateway thread calls Redis, waits for a response that never comes, and blocks until the default socket timeout (often 30 seconds). With 100 threads per gateway and requests backing up, your gateway runs out of threads in seconds. New requests queue up. Latency spikes from 10ms to 30+ seconds. Users see timeouts.
Your backend services are fine. Redis is the only thing broken. But because the rate limiter blocks on Redis, the entire API goes down. A feature meant to protect your system just became its biggest vulnerability.
Step 1: Add Timeouts
The fix starts with aggressive timeouts. Set Redis calls to timeout after 5-10ms. If Redis doesn't respond in time, the gateway gives up and moves to the failure policy.
Now a Redis outage doesn't block threads for 30 seconds — it fails fast in 5-10ms. The API stays responsive. But you're still making Redis calls on every request, and they're all failing. That's wasteful.
Step 2: Add a Circuit Breaker
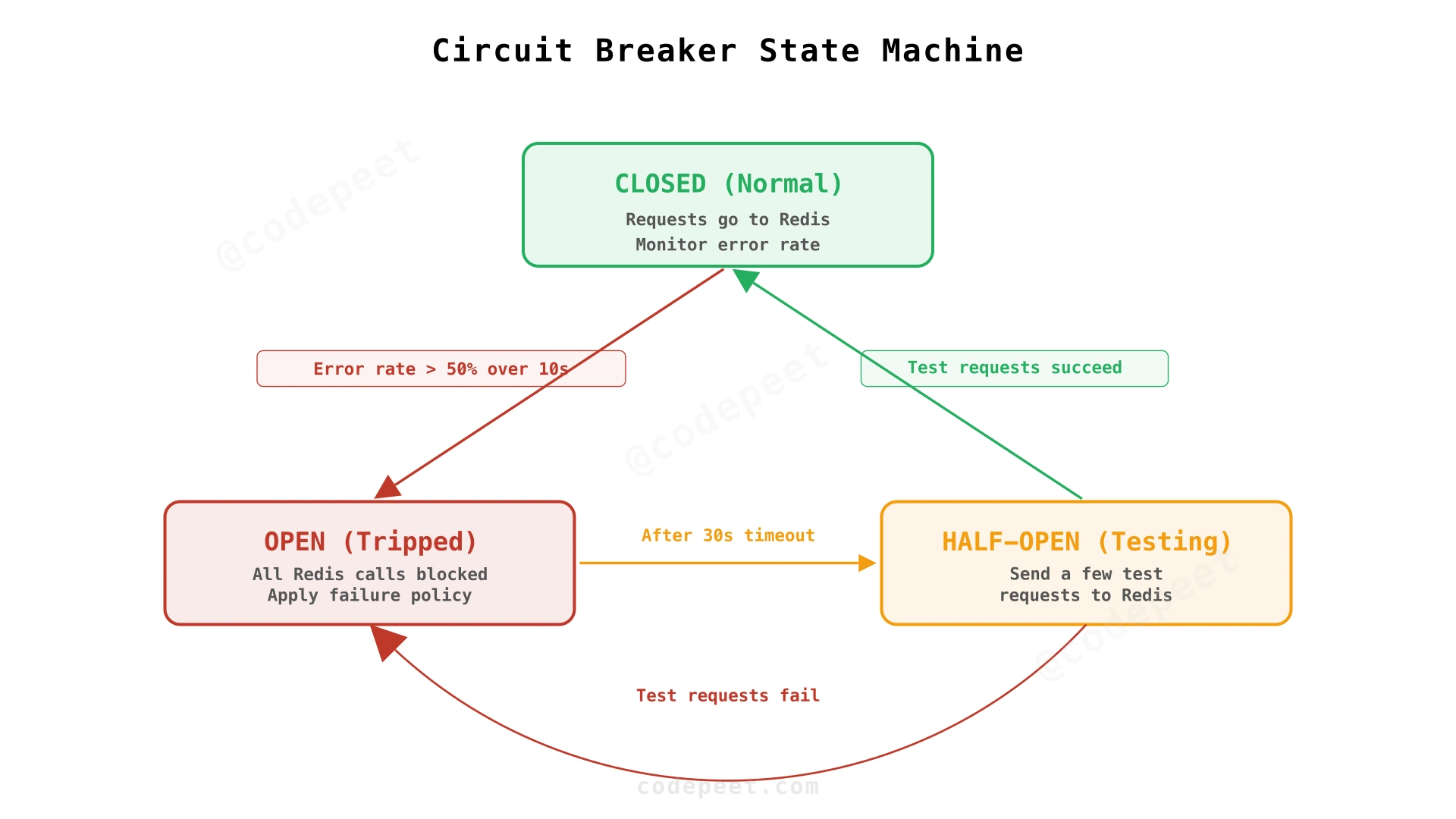
A circuit breaker stops calling Redis when it's clearly broken. Think of it like an electrical circuit breaker: when it detects a problem, it "trips" and stops the flow.
The circuit breaker has three states:
- Closed (normal): Requests go to Redis normally. The breaker monitors the error rate.
- Open (tripped): Too many errors occurred. The breaker stops all Redis calls and immediately applies the failure policy. No waiting, no timeouts.
- Half-open (testing): After 30 seconds, the breaker sends a few test requests to Redis. If they succeed, it closes and resumes normal operation. If they fail, it stays open.
When would it trip? A common setting: if 50% of requests fail over a 10-second window, open the circuit. This catches both complete outages (100% failure) and degraded performance (slow responses timing out).
Step 3: Choose a Failure Policy
The circuit is open. Redis calls are blocked. Now what? You have two choices:
Fail-open: Allow all requests. The API keeps working, but rate limiting is temporarily disabled. An attacker could slip through. Use this for most endpoints — a few seconds of unlimited traffic during an outage rarely causes lasting damage, but blocking all users definitely does.
Fail-closed: Deny all requests. The API returns 503 Service Unavailable to everyone. Use this only for sensitive endpoints where abuse would be catastrophic — password reset endpoints during a suspected attack, or billing APIs where unlimited calls could drain accounts.
Step 4: Add Local Fallback
Fail-open with zero limits feels risky. A middle ground: fall back to local in-memory rate limiting at each gateway.
Each gateway keeps its own token buckets in memory. The catch: gateways can't coordinate during a Redis outage, so a user hitting all 10 gateways gets 10× the intended limit.
To compensate, set local limits higher than the per-gateway share. If the global limit is 100 requests/minute across 10 gateways, set each gateway's local limit to 50/minute (not 10/minute). A well-behaved user hitting one gateway stays under limit. An attacker hitting all 10 gateways gets 500/minute instead of 100 — not ideal, but it blocks the obvious abuse case of 50,000 requests/second from a single IP.
Expire local buckets after 5 minutes of inactivity to prevent memory growth. This fallback isn't meant to be accurate — it's coarse protection until Redis recovers.
Putting It Together
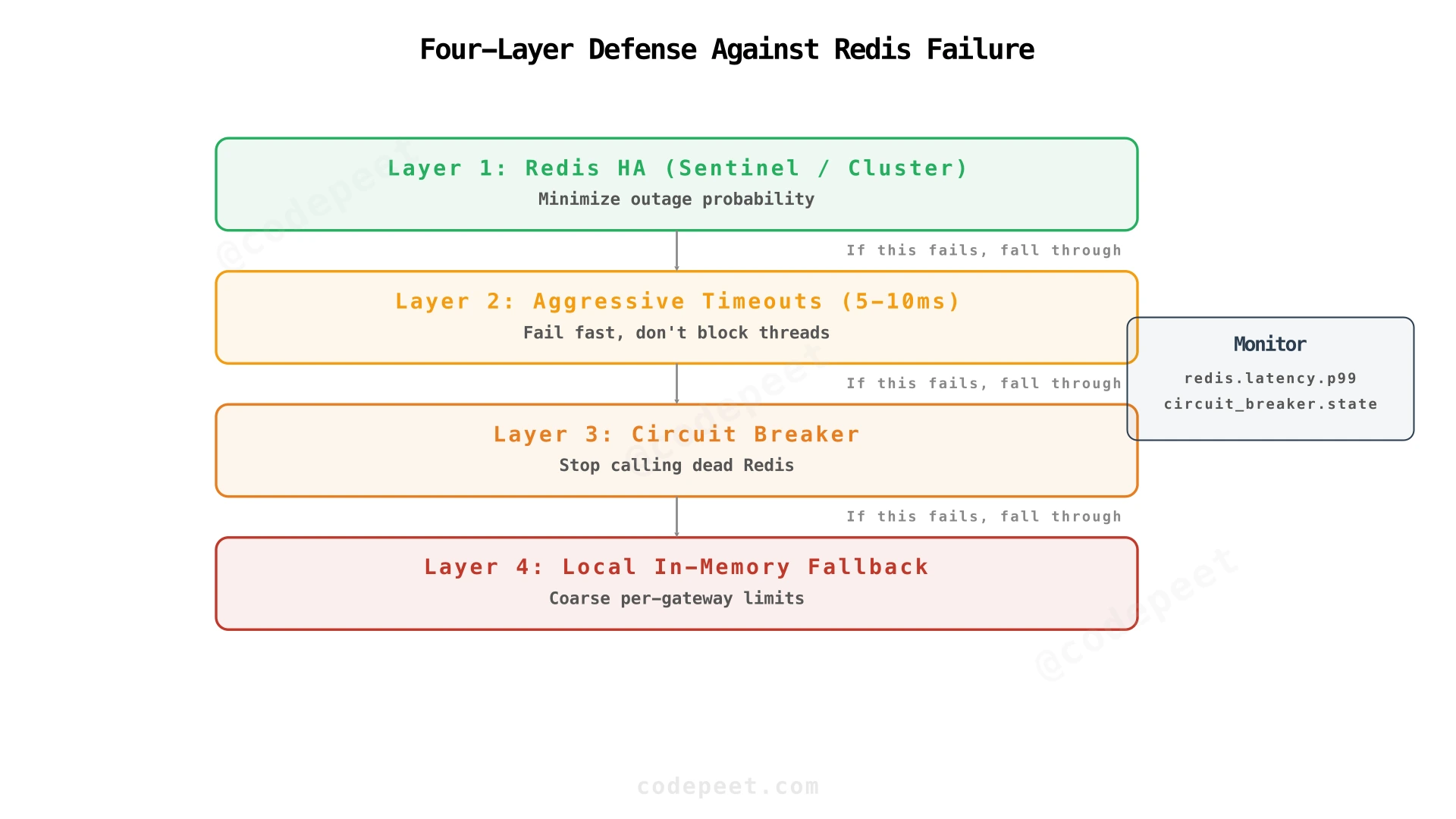
The production pattern combines all four layers:
- Redis HA (Sentinel or Cluster) to minimize outages
- Aggressive timeouts (5-10ms) to fail fast
- Circuit breaker to stop hammering a dead Redis
- Local fallback for coarse limiting during outages
Monitor redis.latency.p99 and circuit_breaker.state to catch problems before users notice.
Recovery Behavior
When Redis recovers, the circuit breaker enters half-open state and sends test requests. Once tests pass, it closes the circuit and resumes normal operation. Local token buckets are flushed — their state is now irrelevant since Redis has accurate counters again.
The key insight: during a Redis outage, some users may have exceeded their limits using local fallback. When Redis comes back, their Redis-tracked counter shows fewer requests than they actually made. This means they temporarily get a "bonus" until their bucket drains normally. For most APIs, this brief overshoot is acceptable. For billing-critical APIs, you should log all locally-allowed requests to a durable queue and reconcile with Redis once it's back. The reconciliation process reads the queue, adjusts each user's token count, and ensures no one keeps an inflated balance.
What happens if one tenant or API key dominates traffic (hot key problem)?
This is a staff-level deep dive.
Your largest customer generates 100,000 requests per second — 10× more than anyone else. All those requests hit the same Redis key: ratelimit:ak_bigcorp:global. Redis is single-threaded, so every update to that key serializes. The shard handling BigCorp's key maxes out its CPU. Latency for that shard spikes. Other customers whose keys happen to land on the same shard see their rate limit checks slow down too.
This is the hot key problem: one dominant key bottlenecks a Redis shard.
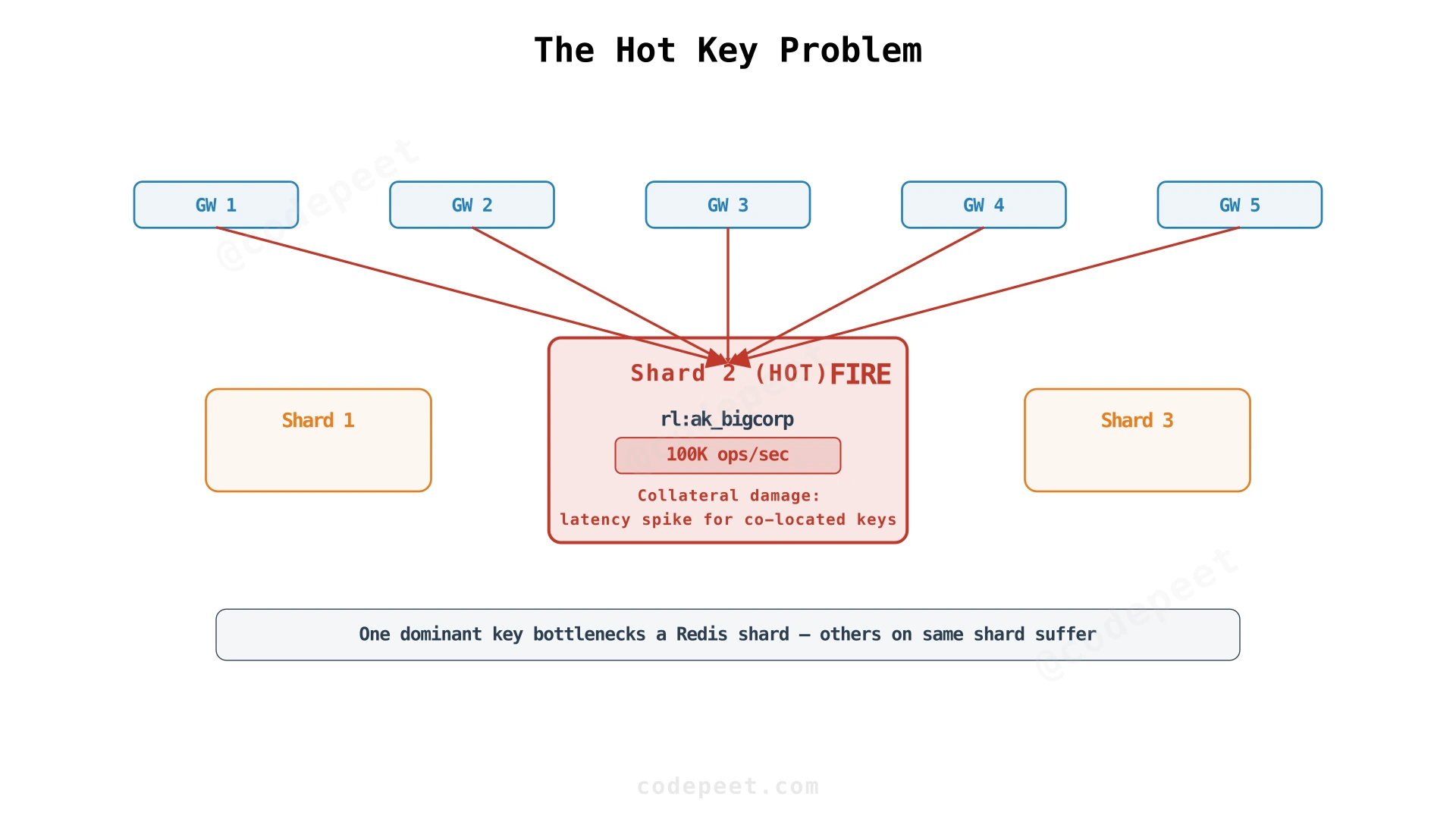
Containing the Blast Radius
Redis Cluster distributes keys across shards. BigCorp's hot key still overwhelms its shard, but other customers on different shards are unaffected. This doesn't solve the problem — it contains it.
Client-Side Aggregation
Instead of checking Redis on every request, the gateway "checks out" a batch of tokens and caches them locally for 100ms. During that window, requests consume cached tokens without hitting Redis. After 100ms, the gateway checks Redis again to refill.
This reduces Redis load by roughly 100× (one call per 100ms instead of one per request). The tradeoff is accuracy: if you have 10 gateways each caching 100 tokens for 100ms, the limit can be exceeded by up to 1000 tokens during that window. For high-volume keys, this slack is acceptable. For billing-critical limits, it's not.
Hierarchical Limiting (Key Sharding)
Split one big limit into multiple smaller limits. Instead of one key ratelimit:bigcorp:global with a 100,000/minute limit, create 10 keys: ratelimit:bigcorp:shard_0 through ratelimit:bigcorp:shard_9, each with a 10,000/minute limit.
Gateways hash the request to pick a shard: shard = hash(request_id) % 10. Load distributes across 10 Redis keys instead of 1. The tradeoff: if traffic concentrates on a few shards (bad hash distribution), some shards hit their limit while others have capacity left.
Probabilistic Sampling
For extremely hot keys (1M+ QPS), you can sample instead of checking every request. Check Redis on 10% of requests, consuming 10 tokens per check. Statistically, this enforces the same average limit with 10× fewer Redis calls.
| Approach | When to Use | Accuracy Tradeoff | Redis Load Reduction |
|---|---|---|---|
| Redis Cluster | Always (baseline) | None | Distributes across shards |
| Client-Side Aggregation | Key > 10K QPS | Up to num_gateways × cache_size overshoot | ~100× |
| Hierarchical Limiting | Key > 100K QPS | Uneven shard utilization | ~N× (N = shard count) |
| Probabilistic Sampling | Key > 1M QPS | Statistical variance | ~10-100× |
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions without prescriptive solutions. They are designed for staff+ conversations where you demonstrate systems thinking, trade-off analysis, and strategic decision-making.
Achieving Global Fairness Across Regions
Context: Your API runs in 5 AWS regions. A tenant with a global limit of 10,000 requests per hour sends traffic to all regions. How do you prevent them from exceeding their quota by 5× (2,000 requests per region)?
Discussion Points:
- Tradeoff between accuracy and latency: global shared state adds cross-region latency (50-200ms) which is unacceptable on hot path
- Hierarchical budgeting: allocate per-region sub-quotas (2,000/hr per region) with periodic rebalancing based on actual traffic patterns
- Eventual consistency approach: each region enforces local limits, background job reconciles and adjusts for next hour
- When to use synchronous vs asynchronous quota enforcement
- Edge cases: what happens when one region is down (should others absorb its quota?)
This topic is designed for AI-assisted discussion practice.
Cost-Based vs Count-Based Rate Limiting
Context: Different API endpoints have vastly different backend costs. A search query costs 100ms of CPU and hits 3 databases. A user profile lookup costs 5ms and hits cache. Should they count equally toward rate limits?
Discussion Points:
- Weighted token consumption: assign cost multipliers per endpoint (search=10 tokens, profile=1 token)
- Complexity vs simplicity tradeoff: cost-based limiting is more fair but harder to explain to customers
- How to measure and update cost weights in production (automated profiling vs manual tuning)
- Risk of gaming: can users exploit cheap endpoints to avoid limits on expensive ones?
- Alternative: separate rate limit policies per endpoint class (search=100/hr, profile=10,000/hr)
This topic is designed for AI-assisted discussion practice.
Distributed Quota Reservation System
Context: You're building a batch processing API where users submit jobs that consume quota over time (e.g., 'process 1M records' consumes 1M from daily quota). How do you prevent double-spending when requests are distributed across gateways?
Discussion Points:
- Reservation protocol: lock quota upfront, release unused portion on completion or timeout
- Handling partial failures: job crashes after consuming 500K of 1M reserved — how to recover?
- Tradeoff between optimistic (assume success) and pessimistic (reserve maximum) reservation
- Idempotency: how to handle retries of the same job without double-charging quota
- Interaction with traditional rate limiting: should batch jobs bypass per-request limits?
This topic is designed for AI-assisted discussion practice.
Challenging Constraints: Accuracy vs Throughput
Context: The requirements state 100% accuracy at 1M TPS. But strict atomicity limits Redis throughput. What if we relaxed accuracy to 99%? How would that change the architecture?
Discussion Points:
- 100% accuracy requires serialized atomic operations — limits single-key throughput to ~100K ops/sec
- Probabilistic sampling: check 10% of requests, consume 10 tokens per check. Same average rate, 10× fewer Redis calls
- Statistical guarantees: 99% accuracy means 1% overage on average — is that acceptable for your use case?
- Use cases where accuracy matters: billing-critical limits, security-sensitive endpoints
- Use cases where throughput matters more: general API protection, DDoS mitigation
This topic is designed for AI-assisted discussion practice.
Soft Limits and Dynamic Quotas
Context: Your API has 80% unused capacity at night but hits limits during business hours. How would you design a system that encourages more usage during off-peak while protecting peak capacity?
Discussion Points:
- Soft limits: allow burst above quota during low-traffic periods, warn but don't block
- Dynamic quotas: adjust limits based on current system load (lower limits when CPU > 70%)
- Time-based policies: higher limits at night, stricter during peak hours
- Credit system: unused quota rolls over (like cellular data) to reward well-behaved clients
- Fairness concerns: how to prevent one client from consuming all off-peak capacity
This topic is designed for AI-assisted discussion practice.
Rate Limiting as a Product Feature: Tiered Pricing and Fair Usage
Context: Product wants to introduce three pricing tiers: Free (100 req/day), Pro (10,000 req/min), Enterprise (custom limits). Engineering needs to design the rate limiting infrastructure to support dynamic, per-customer limits that can change in real-time when a customer upgrades.
Discussion Points:
- How do you handle the moment of upgrade? If a customer was rate-limited at 100 req/day and upgrades to Pro mid-day, should their counter reset?
- What happens when a customer downgrades? Do you immediately enforce the lower limit or provide a grace period?
- How do you prevent abuse of free tier accounts? (Multiple accounts, key rotation)
- How do you design the system to support "soft limits" (warn at 80%, throttle at 100%, hard-block at 120%)?
- What cross-functional collaboration is needed between product, billing, and engineering to define fair usage policies?
This topic is designed for AI-assisted discussion practice.
Level Expectations
Understanding what's expected at each level helps you calibrate your answer depth. A common mistake is over-engineering at mid-level (solving problems the interviewer hasn't asked about) or under-engineering at senior level (not addressing failure modes and edge cases).
This table summarizes what interviewers typically expect at each seniority level when discussing rate limiter design.
| Dimension | Mid-Level (L4) | Senior (L5) | Staff (L6) |
|---|---|---|---|
| Requirements | Identify basic functional needs (block requests over limit) and rough volume math | Define precise non-functional constraints: latency budgets, failure modes, accuracy guarantees | Challenge constraints — do we really need 100% accuracy at 1M TPS? How does relaxing either change the solution? |
| Placement Decision | Explain why gateway-side is preferred over client or server-side | Compare trade-offs of all three placements (Gateway vs Dedicated Service vs Sidecar) with latency/security analysis | Design adaptive placement that shifts rate limiting between gateway and service mesh based on traffic patterns |
| Algorithm Choice | Explain token bucket mechanics and calculate bucket capacity for given requirements | Compare fixed window, sliding window, token bucket, and leaky bucket with quantitative trade-offs (memory, CPU, accuracy) | Design hybrid algorithms (e.g., token bucket for burst + sliding window for sustained) and explain when each is needed |
| Data Store & Concurrency | Use Redis with basic key structure (user_id -> counter) | Handle race conditions: compare Locks vs Atomic operations (Lua scripts). Design multi-scope keys. | Data locality optimization, hot-key prevention (client aggregation, key sharding), distributed consensus costs |
| Failure Handling | Include Redis in the design; understand cache miss behavior | Design fail-open/fail-closed strategies with local fallback and circuit breaker; explain recovery | Design hierarchical failover (Redis HA -> timeout -> circuit breaker -> local cache); define SLAs for rate limiting accuracy during degraded mode |
| Configuration | Define basic rule schema (key, limit, window) | Design config propagation system with push+pull and <60s update latency; implement dry-run mode | Design multi-tenant policy engine supporting tiered pricing, soft/hard limits, real-time upgrades, and gradual rollouts |
Interview Cheatsheet
Common Mistakes to Avoid
- Starting with the algorithm instead of placement: Interviewers want to see you reason about where the limiter sits before diving into how it counts. The placement decision affects every downstream choice.
- Ignoring failure modes: Saying "we'll use Redis" without discussing what happens when Redis fails is a mid-level answer. Senior candidates address circuit breakers and local fallback.
- Over-complicating the algorithm: Don't implement sliding window log unless asked. Token bucket is the industry standard for a reason — it's simple, efficient, and handles bursts naturally.
- Forgetting about hot keys: If you mention Redis, be prepared to discuss what happens when one key gets disproportionate traffic.
- Not quantifying trade-offs: Saying "option A is faster" is weak. Saying "option A adds 1-2ms while option B adds 1-5ms" demonstrates production experience.
Start by clarifying the placement decision — where does the limiter run? (Gateway is the standard answer for most APIs.) Then sketch the base architecture: clients → gateway with inline filter → services. Walk through the request flow: extract identity → look up policy → check state → allow or deny.
For the algorithm, lead with token bucket and explain why (handles bursts naturally). Mention the state: just two values per key (tokens + timestamp). Show you understand the distributed problem: multiple gateways need atomic updates, which is why Lua scripts in Redis work well.
When discussing failure modes, demonstrate systems thinking: "If Redis is slow, what happens?" You want to show you'd add timeouts and a circuit breaker, and you'd probably fail-open with a local fallback for coarse limiting. This proves you think about availability, not just the happy path.
Finally, acknowledge hot keys as a scaling concern. You don't need a full solution, but mentioning client-side aggregation (cache tokens locally for 100ms) or hierarchical limiting (shard the key) shows you've seen production rate limiters at scale.