dropbox
Introduction
"Design Dropbox" or "Design a Cloud File Storage & Sync Service" is one of the most revealing system design interview questions because it tests a fundamentally different set of skills than real-time messaging or social media systems. Here, the challenge is large binary data — not small text payloads — and the core insight is that naively treating files as atomic blobs collapses under real-world conditions.
The surface problem — "let users upload files and sync them across devices" — hides several deeply technical design decisions:
- File chunking: A 10GB video file can't be uploaded atomically. Breaking files into 4MB blocks (chunks) enables resume-on-failure, parallel uploads, deduplication, and delta sync.
- Content-addressable storage: Each block is identified by its SHA-256 hash, not a filename or path. Two identical blocks anywhere in the system share the same storage — saving petabytes at Dropbox scale.
- Metadata vs. data separation: File metadata (names, paths, block lists, versions) lives in an RDBMS with ACID guarantees. Actual file bytes live in a distributed blob store (S3 or Dropbox's Magic Pocket). These systems have radically different consistency, scalability, and cost profiles.
- Sync across devices: When a file changes on one device, all other devices must learn about it and download only the changed blocks. This requires a notification system, a journaling/versioning model, and a conflict resolution strategy.
- Delta sync: For large files with small edits, even block-level chunking can be too coarse. Dropbox uses rolling checksums (Rabin fingerprinting) and variable-sized chunking to detect and transfer only the bytes that actually changed — not the entire block.
Dropbox famously started on AWS S3, then built their own storage system ("Magic Pocket") to store 600+ petabytes at lower cost. They serve 700M+ users with a team that emphasizes infrastructure efficiency over headcount. This design reflects the production architecture.
Functional Requirements
Core (must-have for MVP)
- Upload files — Users can upload files of any type and size (up to 50GB). Uploads must be resumable — interrupting a 10GB upload at 80% should not waste the first 8GB.
- Download files — Users can download any file they own or have been given access to. Downloads support range requests (partial content) for streaming.
- Sync across devices — When a file is added, modified, or deleted on one device, all other linked devices are notified and synced automatically.
- File versioning — Every change to a file is tracked. Users can view version history and restore previous versions.
- Sharing — Users can share files or folders with others via link or by granting direct permissions (read, write, admin).
Extended (out of scope but worth mentioning)
- Delta sync (we cover this in Deep Dives).
- Offline editing and conflict resolution.
- Content search and indexing.
- Team workspaces and administrative controls.
- Thumbnail generation and media preview.
- Compliance features (encryption at rest, HIPAA, SOC 2).
Non-Functional Requirements
| Requirement | Target | Reasoning |
|---|---|---|
| Scale | 100M daily active users | Dropbox-scale platform |
| Storage | 600+ petabytes total | Average ~1GB per user |
| Upload/Download QPS | ~23K sync operations/sec avg | 100M users × 20 syncs/day ÷ 86,400 |
| Peak QPS | ~230K sync ops/sec (10× average) | Business-hours spike |
| File size | Up to 50GB per file | Large video/dataset support |
| Sync latency | < 5 seconds for cross-device notification | User expects near-instant sync |
| Upload reliability | Resumable — no re-upload after interruption | Must survive flaky networks |
| Durability | 99.999999999% (11 nines) | Users trust cloud storage as backup |
| Availability | 99.9% | Planned: higher for reads, lower for writes |
| Consistency | Strong for metadata, eventual for blob replication | File tree must be consistent; blob copies can lag |
| Bandwidth efficiency | Transfer only changed bytes, not entire files | Delta sync for large files |
A critical insight: Dropbox is fundamentally a storage system, not a compute system. The bottleneck is I/O throughput and storage cost, not CPU. This drives the entire architecture — separate cheap blob storage from expensive RDBMS metadata, use content-addressable deduplication to minimize storage, and transfer only deltas to minimize bandwidth.
Resource Estimation
Assumptions:
- 100M daily active users
- 20 sync operations per user per day (read + write combined, 1:1 ratio)
- Average file size: 1MB (mix of documents, images, videos)
- Block size: 4MB (each file divided into 4MB chunks)
- Data retention: 120 days average (considering versioning)
- Average 1GB stored per user
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily sync operations | 100M × 20 | 2 billion/day |
| QPS (avg) | 2B ÷ 86,400 | ~23,000/sec |
| QPS (peak, 10×) | 23K × 10 | ~230,000/sec |
| Write:Read ratio | ~1:1 | Sync reads roughly equal sync writes |
Storage Estimation
| Metric | Calculation | Result |
|---|---|---|
| Total stored data | 100M users × 1GB avg | ~100 PB |
| Daily new data | 100M × 10 writes × 1MB | ~1 PB/day (before dedup) |
| After dedup (~50% savings) | 1 PB × 0.5 | ~500 TB/day net new |
| Metadata DB | 100M users × ~100 files × 1KB metadata | ~10 TB |
Bandwidth Estimation
| Metric | Calculation | Result |
|---|---|---|
| Upload bandwidth | 230K/sec × 4MB (block) | ~920 GB/sec peak |
| Download bandwidth | Similar | ~920 GB/sec peak |
The bandwidth number is astronomical — this is why Dropbox built their own storage infrastructure (Magic Pocket) instead of continuing with S3. At this scale, even a small per-GB cost difference saves hundreds of millions of dollars annually.
Deduplication impact: Dropbox reported that ~60% of uploaded blocks already exist in the system. This means 60% of uploads skip the actual data transfer entirely — the client just sends the hash, the server confirms it already has the block, and the upload is "completed" without transmitting any bytes.
API Design
The system exposes three separate API surfaces — one for each core server component. This separation reflects the fundamental split between metadata (structured, consistent, relational) and data (binary, content-addressed, eventually consistent).
Handles file tree operations — creating, reading, updating, and deleting file metadata.
POST /api/metadata/save
Authorization: Bearer {token}
Content-Type: application/json
{
"namespace_id": "ns-a4d12e85",
"filename": "project-proposal.docx",
"path": "/Documents/Work/project-proposal.docx",
"block_hashes": ["sha256-abc1", "sha256-def2", "sha256-ghi3"],
"file_size": 12582912,
"content_hash": "sha256-xyz789"
}
---
GET /api/metadata?path=/Documents/Work/project-proposal.docx
Authorization: Bearer {token}
Response:
{
"file_id": "file-8f2a4c91",
"filename": "project-proposal.docx",
"path": "/Documents/Work/project-proposal.docx",
"block_hashes": ["sha256-abc1", "sha256-def2", "sha256-ghi3"],
"latest_journal_id": "jrn-42",
"last_modified": "2025-03-17T14:30:00Z"
}Handles raw binary block operations — upload and download individual 4MB chunks.
POST /api/blocks/upload/{block_hash}
Authorization: Bearer {token}
Content-Type: application/octet-stream
Content-Length: 4194304
[4MB binary data]
Response: { "status": "success", "block_hash": "sha256-abc1" }
---
GET /api/blocks/download/{block_hash}
Authorization: Bearer {token}
Response: [4MB binary data]
Content-Type: application/octet-streamNotifies devices about changes so they can sync. Uses long polling — the client sends a request and waits; the server holds the connection open until a change occurs or a timeout expires.
GET /api/notify/long_poll
Authorization: Bearer {token}
X-Last-Journal-ID: jrn-40
// Server holds connection open...
// When a change is detected:
Response:
{
"status": "change_detected",
"changed_files": [
{
"file_id": "file-8f2a4c91",
"filename": "project-proposal.docx",
"path": "/Documents/Work/project-proposal.docx",
"latest_journal_id": "jrn-42"
}
]
}Dropbox chose long polling over WebSocket for the notification service:
| Approach | Pros | Cons |
|---|---|---|
| Long polling | Simple; works through all proxies/firewalls; stateless server | Higher latency (~1-5 sec); new connection per cycle |
| WebSocket | True real-time (<100ms); persistent connection | Stateful servers; proxy issues; more complex |
| SSE | Simple server-push; auto-reconnect | One-directional; limited browser connections |
Dropbox's reasoning: sync doesn't need sub-second latency (unlike chat). A 1-5 second delay between file change and notification is perfectly acceptable. The simplicity and reliability of long polling outweighs the latency advantage of WebSocket.
The notification itself carries no file data — it just says "something changed." The client then contacts the Metadata Server to learn what changed and the Block Server to download the new blocks. This keeps the notification path ultra-lightweight.
The upload order matters:
- Upload blocks to Block Server — each block individually via
POST /api/blocks/upload/{hash}. - Save metadata to Metadata Server — with the ordered list of block hashes.
Why this order? If we saved metadata first, other devices would be notified about the new file and try to download it — but the blocks wouldn't exist yet. By uploading blocks first, the metadata write is an atomic "commit" — once it succeeds, the file is fully available.
The Block Server can verify it received all blocks before the Metadata Server accepts the metadata. This is similar to a two-phase commit but simpler because blocks are immutable and content-addressed.
High-Level Design
We build the architecture incrementally, starting from the simplest possible design and evolving it as we discover problems that need solving. Each step addresses a specific non-functional requirement.
Step 1: Naive Design — Whole-File Upload
Starting point: The simplest file storage service. Users upload entire files to a single server, which stores the raw file on disk and records the filename + path in a database.
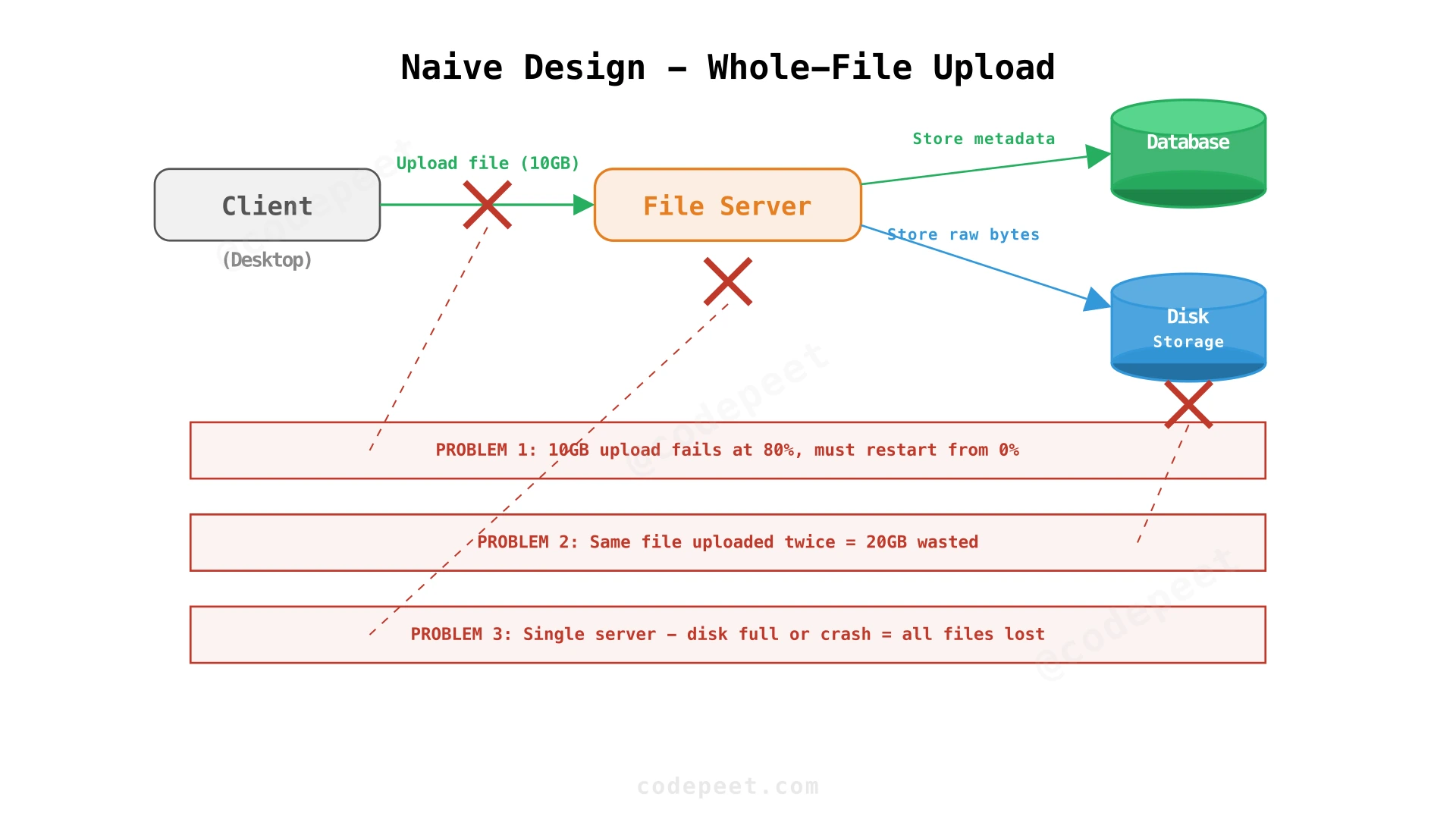
How it works:
- Client sends the entire file to the File Server over HTTP.
- File Server writes the raw bytes to local disk.
- File Server records the filename and path in the database.
Three critical flaws:
| Problem | NFR Violated | Impact |
|---|---|---|
| No resumable upload | Upload reliability | A 10GB upload that fails at 80% must restart from 0%. Over flaky networks, large uploads may never complete. |
| No deduplication | Storage efficiency | Two users uploading the same 10GB file = 20GB stored. At 100M users, this wastes petabytes. |
| Single server | Availability, durability | Server crash = all files lost. Disk full = can't accept new uploads. |
The most fundamental flaw is treating files as atomic blobs. We need to break them apart.
Step 2: File Chunking — Breaking Files into Blocks
Problem being solved: Large files can't be uploaded atomically — network interruptions, storage waste from duplicates, and inability to parallelize uploads.
Solution: Divide every file into fixed-size 4MB blocks before upload. Each block is hashed with SHA-256 to produce a unique fingerprint. The hash serves as the block's identity — its address in the storage system.
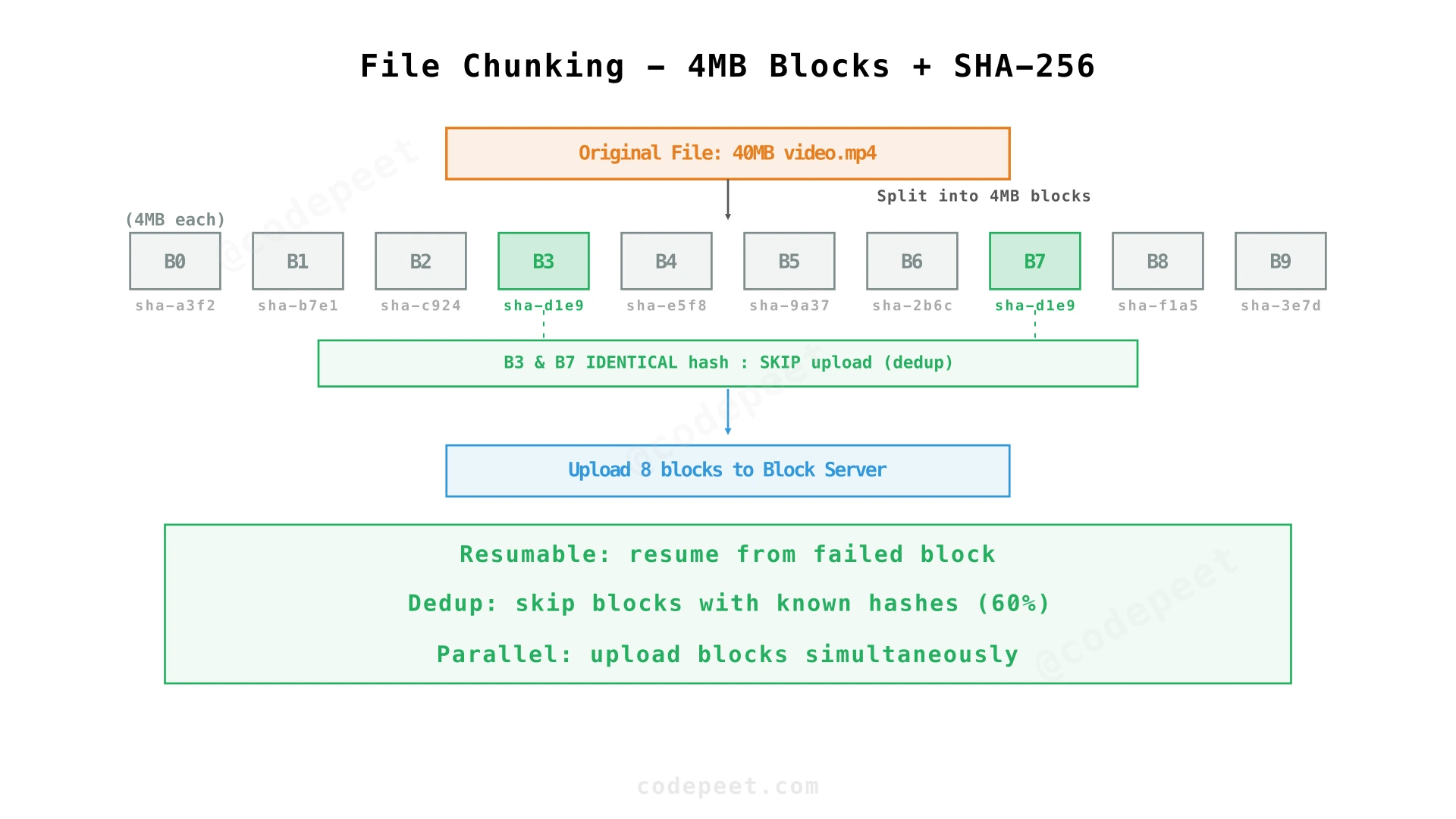
How it works:
- Client splits the file into 4MB blocks.
- Client computes SHA-256 hash for each block.
- Client asks the Block Server: "Do you already have blocks with these hashes?"
- Block Server responds with a list of missing hashes (blocks it doesn't have).
- Client uploads only the missing blocks — skipping duplicates entirely.
- Once all blocks are uploaded, client sends metadata (filename, path, ordered block list) to the Metadata Server.
Why 4MB blocks?
| Block size | Pros | Cons |
|---|---|---|
| 1MB | Finer dedup granularity; less re-upload on failure | More blocks per file → more metadata overhead; more HTTP requests |
| 4MB | Good balance of dedup vs overhead; matches Dropbox's production | Minor edits may re-upload 4MB even for tiny changes |
| 16MB | Fewer blocks per file; less overhead | Coarse dedup; larger re-upload penalty on failure |
Dropbox chose 4MB as the production block size based on empirical testing.
What we've solved:
- ✅ Resumability: If upload fails at block 5 of 10, resume from block 5.
- ✅ Deduplication: Identical blocks (across all users) are stored once. Dropbox reports ~60% dedup rate.
- ✅ Parallelism: Upload multiple blocks concurrently for faster throughput.
What's still broken:
- ❌ No cross-device sync: If I upload a file on my laptop, my phone doesn't know about it.
- ❌ No versioning: Overwriting a file destroys the old version.
- ❌ Single Block Server: All blocks in one place — no redundancy.
Step 3: Metadata Server + Notification Service — Cross-Device Sync
Problem being solved: After a file is uploaded from Device D1, other devices (D2, D3) don't know the file exists. We need a way to (a) track what files exist and what blocks compose them, and (b) notify other devices when changes happen.
Solution: Introduce two new services:
- Metadata Server — stores the file tree (names, paths, block lists, versions) in an RDBMS.
- Notification Service — maintains long-poll connections with all clients and notifies them when changes occur.
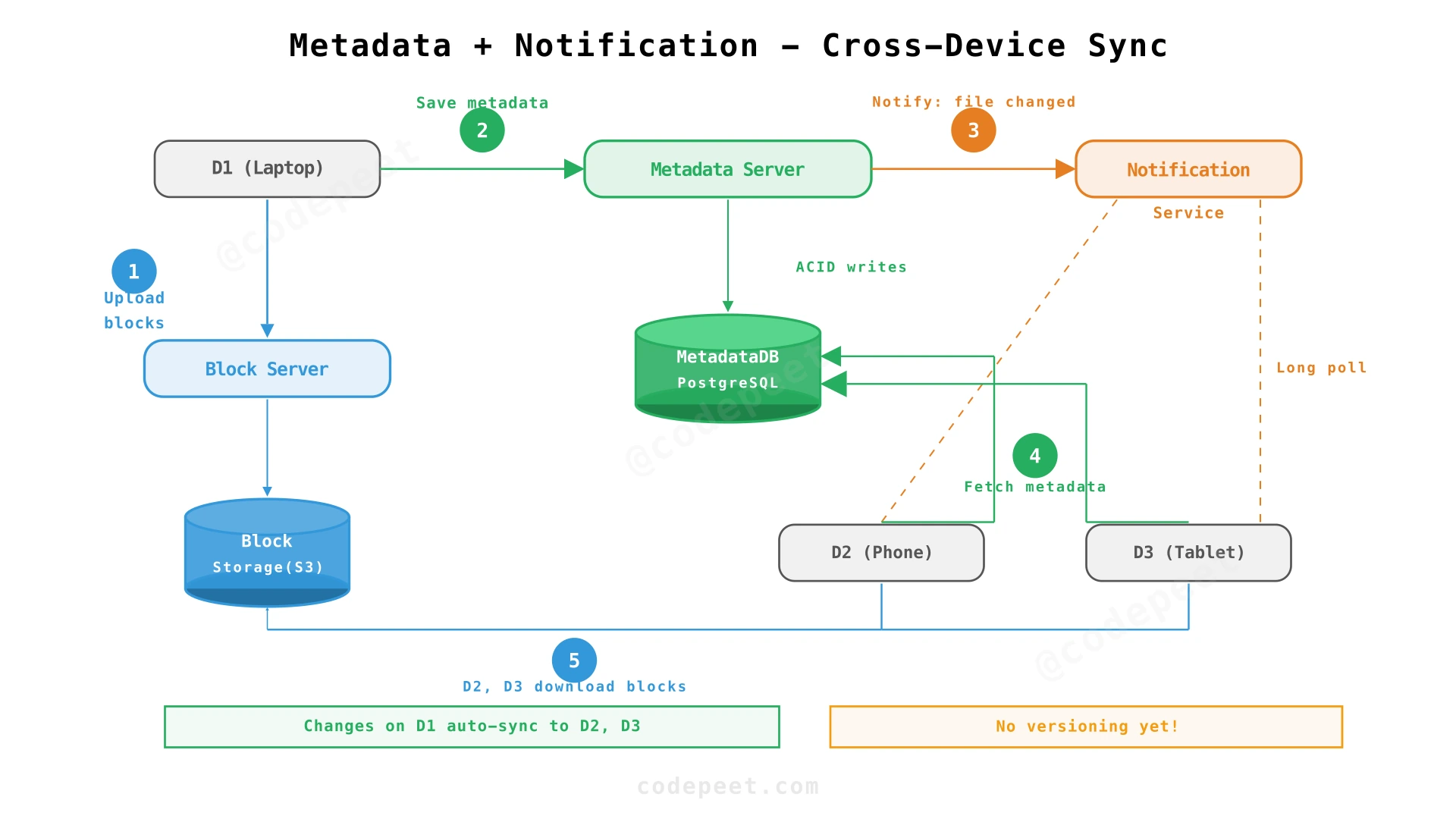
Write path (uploading a file from D1):
- D1 splits the file into 4MB blocks, computes hashes, and uploads missing blocks to the Block Server.
- D1 sends file metadata (filename, path, ordered block list) to the Metadata Server.
- Metadata Server writes to the Metadata DB (PostgreSQL) and notifies the Notification Service: "file X changed in namespace Y."
- Notification Service closes the open long-poll connections for all devices in namespace Y. This is the signal: "something changed, go check."
Read path (syncing to D2):
5. D2's long-poll connection returns. D2 queries the Metadata Server: "What changed since my last sync? (journal ID = 40)."
6. Metadata Server returns the list of changed files with their block hashes.
7. D2 checks which blocks it already has locally. For missing blocks, it downloads from the Block Server.
8. D2 reconstructs the file from blocks and saves it locally.
What we've solved:
- ✅ Cross-device sync: Notification Service ensures all devices learn about changes.
- ✅ Metadata consistency: PostgreSQL gives ACID guarantees for the file tree.
What's still broken:
- ❌ No versioning: Saving metadata overwrites the previous entry. No history, no rollback.
- ❌ Offline devices: If D2 was offline during the notification, what happens when it comes back?
- ❌ Block Server scalability: Single Block Server + S3 is a bottleneck at 600PB scale.
The file tree is inherently relational: files belong to namespaces (users), namespaces have permissions, files have ordered block lists, and every change creates a journal entry. These relationships require JOIN queries, transactions, and referential integrity — all strengths of an RDBMS.
MongoDB would work for the block-level storage (hash → blob), but the metadata layer needs strong consistency: if I rename a folder, all files inside must update atomically. PostgreSQL's transaction support makes this trivial.
Step 4: Journal Table — Versioning and Offline Sync
Problem being solved: (1) No version history — overwriting a file loses the old version. (2) Offline devices miss notifications — when D2 comes online, how does it know what changed?
Solution: Add a Journal table — an append-only log of every change to every file. Each entry records what changed, when, and which blocks were affected. Devices track their last-seen journal ID and sync by asking "what happened after journal ID X?"
-- File Metadata Table
CREATE TABLE file_metadata (
file_id UUID PRIMARY KEY,
namespace_id UUID NOT NULL, -- user or shared folder
relative_path TEXT NOT NULL,
block_list TEXT[] NOT NULL, -- ordered SHA-256 hashes
latest_journal_id BIGINT REFERENCES journal(journal_id),
file_size BIGINT,
content_hash TEXT, -- hash of entire file for quick equality check
UNIQUE (namespace_id, relative_path)
);
-- Journal Table (append-only change log)
CREATE TABLE journal (
journal_id BIGSERIAL PRIMARY KEY, -- monotonically increasing
file_id UUID REFERENCES file_metadata(file_id),
timestamp TIMESTAMPTZ DEFAULT NOW(),
change_type TEXT NOT NULL, -- ADD, MODIFY, DELETE, RENAME
changed_blocks TEXT[], -- blocks affected by this change
previous_block_list TEXT[] -- snapshot for rollback
);
-- Users & Permissions
CREATE TABLE namespace_permissions (
user_id UUID,
namespace_id UUID,
permission TEXT NOT NULL, -- READ, WRITE, ADMIN
PRIMARY KEY (user_id, namespace_id)
);How journaling solves both problems:
Versioning:
- Every file modification creates a new journal entry (change type, affected blocks, previous block list for rollback).
- The file_metadata table always points to the
latest_journal_id. - To restore version N: look up journal entry N → get
previous_block_list→ reconstruct. - Users can view version history:
SELECT * FROM journal WHERE file_id = ? ORDER BY journal_id DESC.
Offline device sync:
- Each device remembers the
last_journal_idit processed. - When D2 comes online: query
SELECT * FROM journal WHERE journal_id > {last_seen} AND namespace_id IN (user's namespaces) ORDER BY journal_id ASC. - D2 replays the journal entries in order, downloading any new blocks it needs.
- This is exactly the same mechanism as an event-sourcing pattern.
What we've solved:
- ✅ Full version history: Every change is an immutable journal entry.
- ✅ Offline sync: Devices catch up by replaying the journal from their last checkpoint.
- ✅ Conflict detection: If D1 and D2 both modify the same file offline, their journal entries will have different
previous_block_listvalues, signaling a conflict.
What's still remaining:
- ❌ Block storage scalability: We need distributed blob storage, not a single server.
- ❌ Metadata caching: At 23K QPS, PostgreSQL alone will struggle.
The journal pattern provides three critical benefits:
- Audit trail: Every change is permanently recorded. For compliance (SOC 2, HIPAA), this is mandatory.
- Conflict resolution: Two offline devices can detect conflicting edits by comparing their journal entries against the server's. Without a journal, you'd need complex vector-clock or CRDT mechanisms.
- Incremental sync: "Give me everything after journal ID 42" is a single, efficient range query. Without the journal, devices would need to do a full diff of their local state vs the server's — in the number of files.
- Rollback: Restoring a file to a previous version is just pointing
latest_journal_idto an older entry.
Step 5: Complete Architecture — All NFRs Addressed
The final architecture adds distributed block storage, metadata caching, and completes the system with all components needed for production-grade Dropbox.
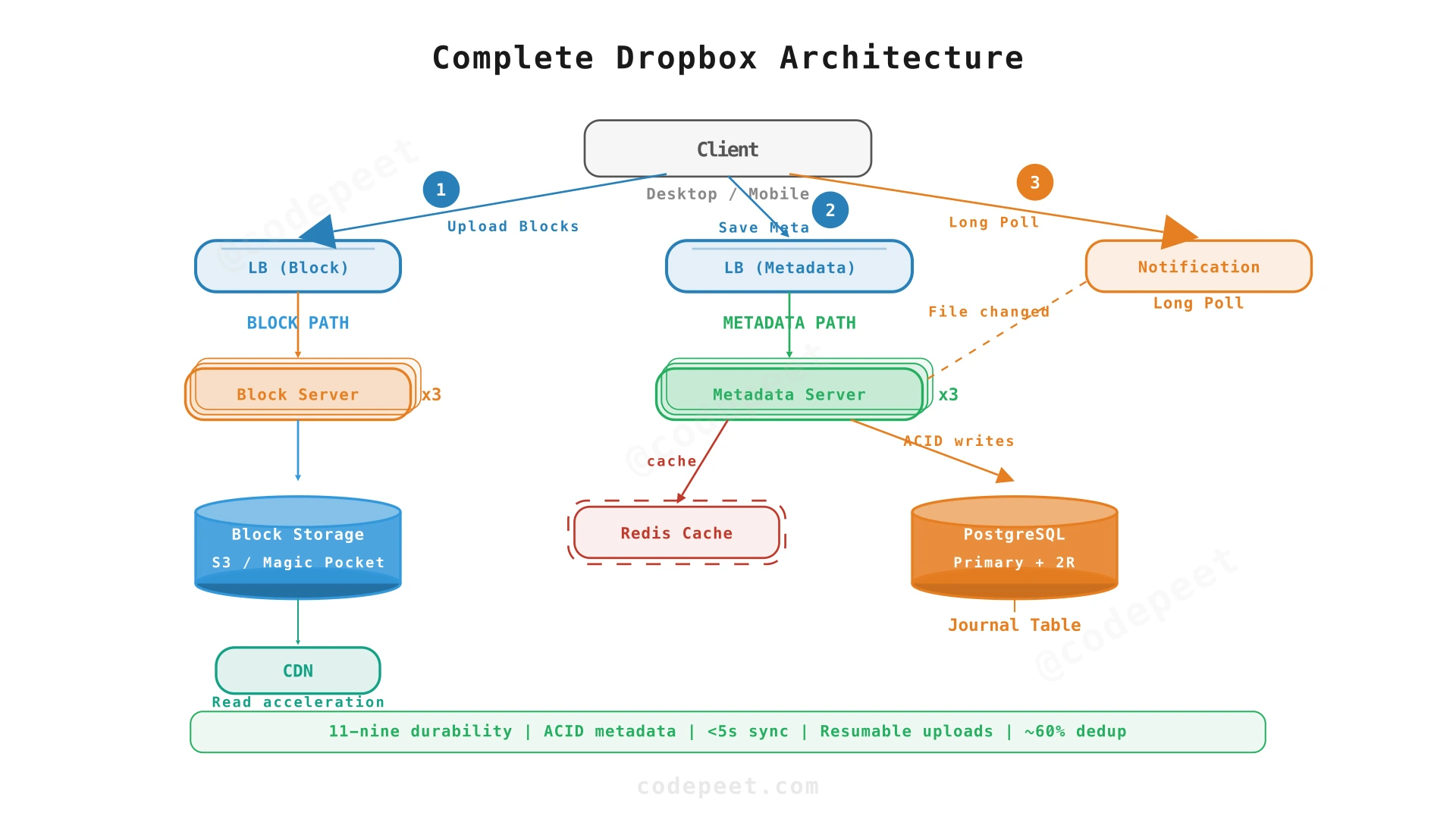
NFR Scorecard — All Requirements Met
| NFR | Target | How It's Achieved |
|---|---|---|
| 100M DAU | Horizontal scaling | Block Server fleet + Metadata Server fleet behind LBs |
| 600+ PB storage | Distributed blob store | S3 / Magic Pocket with 3× replication |
| 11-nines durability | Block replication | Each block stored in 3+ data centers |
| Resumable uploads | File chunking | 4MB blocks; resume from last successful block |
| Dedup (~60%) | Content-addressable | SHA-256 hash = block ID; identical blocks stored once |
| < 5s sync latency | Long polling | Notification Service signals devices; immediate metadata fetch |
| Strong metadata consistency | PostgreSQL ACID | File tree always consistent across devices |
| Version history | Journal table | Append-only change log; rollback to any version |
| Offline sync | Journal replay | Devices catch up from last journal ID |
| 230K peak QPS | Caching + fleet | Redis cache for hot metadata; horizontal scaling |
| Component | Responsibility | Scaling Strategy |
|---|---|---|
| Block Server Fleet | Upload/download 4MB blocks | Horizontal: add servers; stateless |
| Block Storage (S3 / Magic Pocket) | Persist binary blocks | Distributed: 3× replication across DCs |
| Metadata Server Fleet | File tree CRUD; journal writes | Horizontal: each server handles a namespace range |
| Metadata DB (PostgreSQL) | ACID storage for file metadata + journal | Primary + 2 replicas; sharded by namespace_id |
| Redis Cache | Cache hot metadata (recently accessed files) | Redis Cluster; TTL-based invalidation |
| Notification Service | Long-poll connections for change alerts | Horizontal: partitioned by namespace_id |
| CDN | Accelerate block downloads for popular files | Edge caching; content-addressed (immutable blocks are CDN-friendly) |
Dropbox stored blocks on AWS S3 from 2007 to 2016, then migrated to their own system called Magic Pocket. Why?
- Cost: At 600+ PB, even small per-GB savings compound. Dropbox estimated they saved hundreds of millions by owning their storage.
- Performance: Magic Pocket is optimized for Dropbox's access patterns (write-once, read-sometimes, content-addressed). S3 is general-purpose and charges for metadata API calls.
- Control: Dropbox needed fine-grained control over replication, erasure coding, disk placement, and failure domain isolation.
For an interview, S3 is the right default answer. Mention Magic Pocket as evidence that at extreme scale, building custom infrastructure can be justified.
Deep Dives
Delta Sync — Transferring Only Changed Bytes
Our 4MB fixed-block chunking has a subtle flaw: inserting a single byte at position 0 shifts all subsequent block boundaries. Every block after the insertion point gets a new hash, even though the actual content barely changed. A 1-byte edit to a 1GB file would re-upload 250 blocks (1GB) instead of 1.
Fixed-size chunking failure example:
Original: [ Block 0 ][ Block 1 ][ Block 2 ][ Block 3 ]
Insert 1 byte at start:
After: [ Block 0' ][ Block 1' ][ Block 2' ][ Block 3' ]
↑ shifted ↑ shifted ↑ shifted ↑ shifted
All blocks changed! All re-uploaded. (Bad)
Solution: Content-Defined Chunking (CDC) with rolling hash.
Instead of splitting at fixed byte offsets (every 4MB), split at positions determined by the content itself. Use a rolling hash (Rabin fingerprint) that slides a window over the file bytes. When the hash hits a specific pattern (e.g., lowest 12 bits = 0), create a chunk boundary. This produces variable-sized chunks whose boundaries are determined by the data, not by position.
Original: [ Chunk A ][ Chunk B ][ Chunk C ][ Chunk D ]
Insert 1 byte at start:
After: [ Chunk A' ][ Chunk B ][ Chunk C ][ Chunk D ]
↑ changed ↑ same ↑ same ↑ same
Only ONE chunk re-uploaded! (Good)
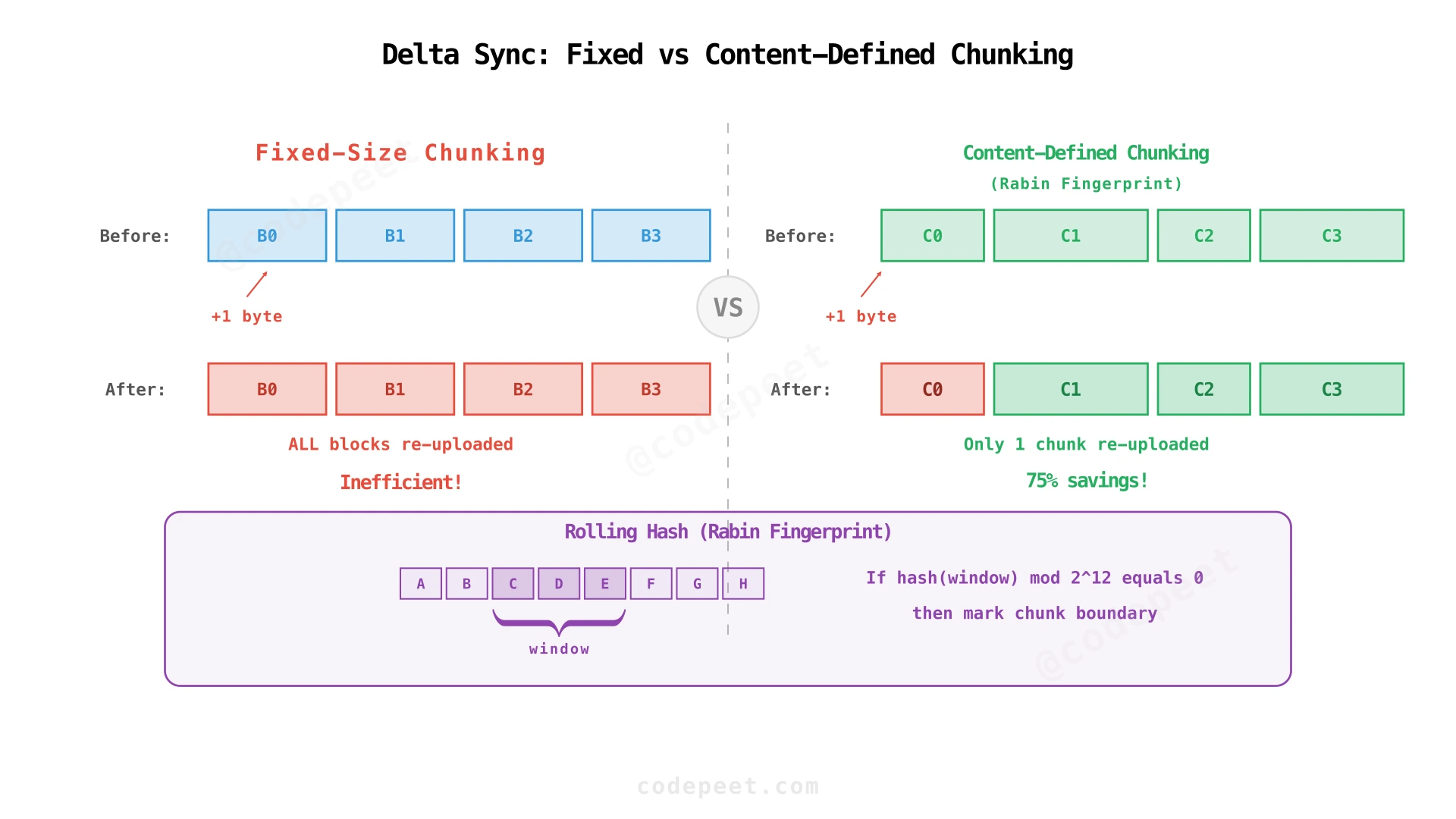
The Rabin fingerprint is a polynomial hash over a sliding window of bytes:
Where is a prime base and is a prime modulus. The key property: when the window slides by one byte (remove , add ), the new hash can be computed in O(1):
This means hashing an entire file takes O(n) time, same as a single pass — not .
A chunk boundary is created when hash % 2^avg_chunk_bits == 0. For example, avg_chunk_bits = 22 gives an average chunk size of ~4MB ( bytes). The actual chunk sizes follow a geometric distribution around this average.
Dropbox's production delta sync pipeline:
- Local change detection: The desktop client watches the filesystem for changes (using inotify on Linux, FSEvents on macOS, ReadDirectoryChangesW on Windows).
- Compute delta: Compare old block list (from local metadata cache) with new block list after re-chunking the modified file using content-defined chunking.
- Upload only new blocks: Send only the blocks whose hashes don't exist on the server.
- Update metadata: Submit the new ordered block list to the Metadata Server.
The result: editing a single page in a 100MB Word document re-uploads ~4MB (one chunk) instead of 100MB.
Block-Level Deduplication
Content-addressable storage naturally enables deduplication: two blocks with the same SHA-256 hash are identical and stored only once, regardless of which user uploaded them.
Types of deduplication:
| Level | How it works | Savings |
|---|---|---|
| File-level | If content_hash of entire file matches another file → no blocks uploaded | Catches exact file duplicates (e.g., same PDF shared among 1000 users) |
| Block-level | Individual blocks compared by SHA-256 hash | Catches partial duplicates (e.g., two versions of a file sharing 90% of blocks) |
| Cross-user | Block hashes are global — dedup works across all users | Popular files (installers, stock photos) stored once for millions of users |
The upload dedup flow:
- Client computes SHA-256 hashes for all blocks.
- Client sends the list of hashes to the Block Server: "Which of these do you need?"
- Block Server checks its hash index. Returns only the hashes that don't exist.
- Client uploads only the missing blocks.
- For already-existing blocks, the upload is "free" — no data is transferred.
At Dropbox scale, ~60% of uploaded blocks already exist. This means 60% of upload bandwidth is saved — a massive cost reduction.
Hash collision: Two different blocks producing the same SHA-256 hash. The probability is — astronomically small. For practical purposes, SHA-256 collisions don't happen naturally. (SHA-1, which is weaker, has been broken — always use SHA-256+.)
Privacy concern: If User A can check whether a hash exists, they could test hashes of known sensitive files to determine if another user has that file. This is called a "confirmation-of-a-file" attack.
Mitigation: Dropbox uses convergent encryption — each block is encrypted with a key derived from the block's content hash before storing. The same plaintext produces the same ciphertext (enabling dedup), but the stored blocks are encrypted. Additionally, the hash-check API requires authentication and rate-limiting.
Conflict Resolution for Concurrent Edits
When two devices edit the same file offline and then both sync, we have a conflict. The journal detects it — both devices submit changes with the same previous_block_list — but how do we resolve it?
Dropbox's approach: last-writer-wins + conflict copy.
- D1 uploads first → its version becomes the "latest" in file_metadata.
- D2 uploads second → Metadata Server detects that D2's base version (journal ID 40) doesn't match the current latest (journal ID 42, from D1's upload).
- Instead of overwriting D1's version, the server creates a conflict copy:
project-proposal (D2's conflicted copy 2025-03-17).docx. - Both versions are preserved. The user manually resolves the conflict.
Why not automatic merge? Files are opaque binary blobs (not text). You can't merge two versions of a .docx or .psd file automatically. For text files, Dropbox could theoretically use OT (Operational Transform) or CRDTs, but they chose simplicity: save both versions, let the user decide.
When a device submits new metadata:
IF submitted.previous_journal_id != file_metadata.latest_journal_id:
→ CONFLICT: another device edited the file between this device's last sync and now.
→ Create conflict copy with device name + timestamp.
→ Both versions are preserved as separate journal entries.
ELSE:
→ Normal update: create new journal entry, update latest_journal_id.
This is optimistic concurrency control: assume no conflict, detect and handle if one occurs. It works well because conflicts are rare (most files are edited by one person at a time).
Encryption and Security Architecture
Dropbox stores sensitive user data — the encryption model must protect against both external attackers and internal access.
Encryption layers:
| Layer | Method | Protects Against |
|---|---|---|
| In transit | TLS 1.3 for all API calls | Network eavesdropping, MITM |
| At rest | AES-256 encryption on block storage | Physical disk theft, datacenter breach |
| Per-block key | Each block encrypted with a unique key; keys stored in a separate Key Management Service | Compromised storage node doesn't expose all data |
| Convergent encryption (for dedup) | Block encrypted with key = SHA-256(plaintext); same content → same ciphertext | Enables dedup on encrypted blocks |
Standard encryption (random IV) produces different ciphertext for identical plaintext, which breaks deduplication. Convergent encryption solves this by deriving the encryption key from the content itself: key = SHA-256(plaintext). This means identical blocks produce identical ciphertext, enabling dedup.
Trade-off: Convergent encryption is vulnerable to confirmation attacks — an attacker who knows the plaintext can compute the key and check if the ciphertext exists in storage. For targeted attacks on specific known files, this is a concern.
Mitigation: Rate-limit the block-existence-check API. Require authentication. For highly sensitive use cases, Dropbox Business offers customer-managed keys that disable cross-user dedup.
Staff-Level Discussion Topics
These open-ended topics test architectural judgment at the staff+ level.
Dropbox started on AWS S3, then spent 2.5 years building Magic Pocket to store 600+ PB in-house. This is one of the most consequential build-vs-buy decisions in tech history. When is building your own storage justified? When should you stay on S3?
<discuss-with-ai-button title="Discuss Build vs. Buy" context="Your file storage startup has grown to 100PB on S3, spending 30M upfront and 30M + 24×8M", "Engineering opportunity cost: 2 years of storage team not building product features", "Operational risk: you're now responsible for durability of 100PB", "Performance control: custom optimizations for your access patterns", "Vendor lock-in: S3 API is ubiquitous but pricing changes are unilateral"]'>
Simple 3× replication stores 3 copies of every block — 3× storage overhead for 11-nines durability. Erasure coding (like Reed-Solomon) achieves the same durability with only 1.5× overhead by splitting each block into data shards + parity shards.
Magic Pocket uses erasure coding. At 600 PB, the difference between 3× and 1.5× overhead is 900 PB of saved storage — hundreds of millions of dollars.
Dropbox uses last-writer-wins + conflict copies. But modern tools like Google Docs allow real-time collaborative editing on the same document. What would it take to add this to Dropbox?
Level Expectations
| Area | |||
|---|---|---|---|
| Requirements | Lists upload/download/sync FRs | Derives 23K QPS; identifies resumability, dedup, and delta sync as key NFRs | Discusses 11-nines durability, storage cost at PB scale, build-vs-buy for storage |
| Architecture | Client → Server → Database | Separate Block Server + Metadata Server + Notification Service; explains progressive evolution | Magic Pocket vs S3 trade-offs; erasure coding; CDN for read acceleration |
| Chunking | "Split files into blocks" | Explains 4MB fixed blocks, SHA-256 hashing, dedup flow, parallel upload | Content-defined chunking (Rabin fingerprint) for delta sync; variable-size chunks |
| Storage | "Store files in S3" | Content-addressable blocks; block-level + cross-user dedup; convergent encryption | Replication vs erasure coding trade-off; tiered storage (hot/warm/cold) |
| Sync | "Notify other devices" | Journal table for versioning + offline sync; long-poll notification; read/write paths | Conflict resolution strategies; real-time collab (OT/CRDTs); event sourcing in journal |
| Database | "Store metadata in a database" | PostgreSQL for ACID; file_metadata + journal + permissions tables; sharding by namespace_id | Cache invalidation strategy; consistency between metadata DB and block storage |
Interview Cheatsheet
Core Architecture in 60 Seconds
"A chunked file sync system with three core services. Files are split into fixed-size blocks (4 MB), each content-addressed by SHA-256 hash. The Block Server handles uploads/downloads to S3 via pre-signed URLs. The Metadata Server tracks file→block mappings, versions, and folder structure in a relational database. The Notification Service (long-poll or WebSocket) pushes change events to other devices. On edit, only changed blocks are uploaded (delta sync), and deduplication across users means identical blocks are stored once."
"Dropbox is a cloud file storage and sync system. 100M DAU, 600+ PB, 23K sync ops/sec. Files are split into 4MB blocks, each identified by its SHA-256 hash — this gives us resumable uploads, block-level dedup (~60% savings), and parallel transfers. Three core servers: Block Server (stores binary blocks in S3/Magic Pocket), Metadata Server (PostgreSQL for ACID file tree + journal), and Notification Service (long-poll for cross-device sync). When a file changes on device D1: blocks uploaded → metadata committed → notification fires → other devices fetch changed blocks via journal replay."
- FRs: Upload/download files (up to 50GB), cross-device sync, file versioning, sharing
- NFRs: 100M DAU, 230K peak QPS, 11-nines durability, resumable uploads, <5s sync latency
- Key insight: Storage system, not compute system — I/O throughput and storage cost are the bottleneck
- Out of scope: Media preview, search, collaborative editing, compliance
- Block Server — stateless; uploads/downloads 4MB blocks; backed by S3/Magic Pocket
- Metadata Server — file tree CRUD; journal writes; backed by PostgreSQL + Redis cache
- Notification Service — long-poll connections; signals devices when files change
- Metadata DB (PostgreSQL) — file_metadata, journal, namespace_permissions tables
- Block Storage (S3/Magic Pocket) — content-addressable blob store; 3× replication
- Redis Cache — hot metadata; recently synced files
- CDN — edge caching for frequently downloaded blocks
- Fixed-size vs content-defined chunking: Fixed 4MB for simplicity; Rabin fingerprint for delta sync efficiency
- Long polling vs WebSocket: Long poll is simpler and sufficient for <5s sync latency
- 3× replication vs erasure coding: Replication simpler; erasure coding saves 50% storage at PB scale
- S3 vs custom storage (Magic Pocket): S3 for startups; build your own when storage cost dominates OpEx
- Convergent encryption: Enables dedup on encrypted data but vulnerable to confirmation attacks
- Last-writer-wins vs merge: LWW + conflict copies is simple; merge requires OT/CRDTs and document model
| Metric | Value |
|---|---|
| DAU | 100M |
| Total users | 700M+ |
| Total storage | 600+ PB |
| Sync QPS (avg / peak) | 23K / 230K |
| Block size | 4MB |
| Hash function | SHA-256 |
| Dedup savings | ~60% of blocks already exist |
| Durability target | 99.999999999% (11 nines) |
| Sync notification latency | < 5 seconds (long poll) |
| Replication factor | 3× (or erasure coding 1.5×) |
| Magic Pocket migration | 2.5 years (2014-2016) |
- "How do you handle file conflicts?" — Detect via journal (mismatched previous_journal_id). Create conflict copy with device name + timestamp. Let user resolve manually.
- "How do you handle offline devices?" — Device stores last journal_id. On reconnect, replays journal entries since that ID. Downloads only new/changed blocks.
- "How do you support large files (50GB)?" — 4MB blocks × 12,500 blocks. Upload in parallel (8-16 concurrent block uploads). Resume from any point on failure.
- "How do you generate thumbnails?" — Async worker triggered by metadata write. Generates thumbnails in background; cached in CDN.
- "How do you handle rate limiting?" — Per-user upload bandwidth limit. Token bucket at API gateway. Burst tolerance for initial sync.
- "How does sharing work?" — Namespace-level permissions (READ/WRITE/ADMIN). Shared folders = shared namespace. Link sharing = time-limited, permission-scoped tokens.
Common Mistakes to Avoid
- ❌ Uploading entire files on every change — delta sync (only changed blocks) reduces bandwidth by 90%+ for large files
- ❌ Storing files as whole objects without chunking — chunking enables resumable uploads, deduplication, and parallel transfers
- ❌ Using polling instead of push notifications for sync — polling adds latency and wastes resources across millions of clients
- ❌ Ignoring conflict resolution — two users editing the same file offline creates divergent versions that must be reconciled
- ❌ Skipping versioning — without a journal of changes, there's no way to undo accidental deletes or recover previous versions
- ❌ Not mentioning deduplication — content-addressed blocks mean identical files across users are stored once, saving massive storage costs