url-shortener
Introduction
A URL shortener is a service that converts long, unwieldy URLs into compact aliases that redirect to the original destination. Services like bit.ly, TinyURL, and Twitter's t.co handle billions of redirects daily, turning links like https://example.com/products/category/electronics/item?id=12345&ref=campaign into something as short as https://short.ly/a1B2c3.
Behind the simplicity lies a system with interesting engineering constraints. The write path must generate a globally unique short code in milliseconds. The read path must resolve that code back to the original URL and issue an HTTP redirect with sub-10 ms latency — because redirects sit in the critical path of every click. And the analytics path must count billions of clicks without slowing down redirection.
The core engineering challenges are:
- ID Generation — How do you produce short, unique identifiers across a distributed fleet of servers without coordination bottlenecks?
- Encoding — How do you convert numeric IDs into compact, URL-safe strings? The character set and length determine how many URLs your system can represent.
- Read-Heavy Scale — With a 100:1 read-to-write ratio and 100M read requests per day, the vast majority of traffic is redirects. Caching strategy dominates architecture decisions.
- Consistency vs Availability — A newly created short URL must be resolvable globally within seconds. But cross-region replication introduces latency. How do you handle the window where a URL exists in one region but not another?
In this design, we'll build the system incrementally: first the core shortening and redirect flows, then analytics, then the deep dives into ID generation strategies, encoding trade-offs, caching architecture, and scaling via sharding.
LLD Connection: This problem connects to the Hash Map Low-Level Design, where you implement the core data structure for O(1) key-value lookups. The URL shortener's in-memory cache and Base62 encoding both rely on hash-based access patterns.
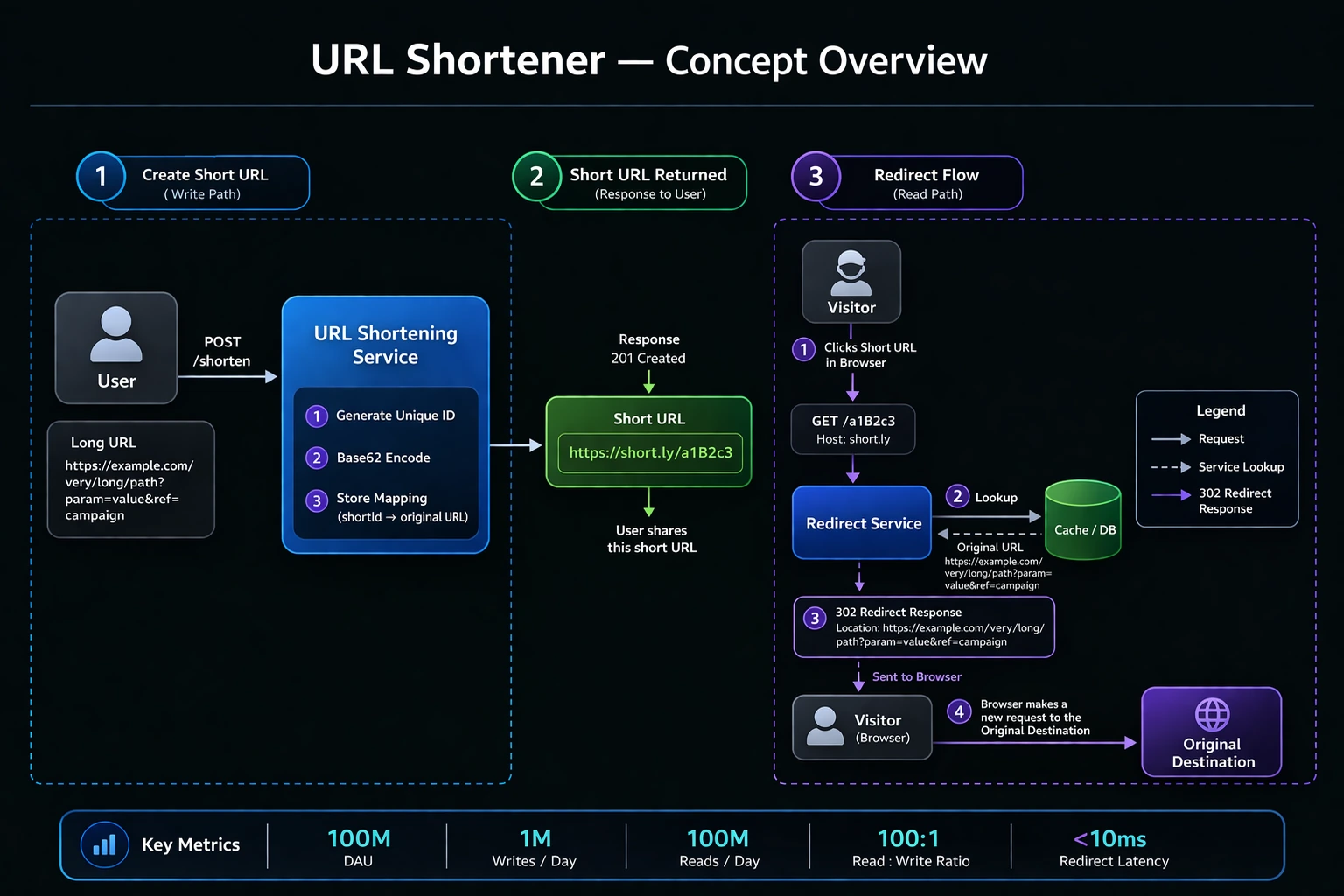
Functional Requirements
We extract the core operations by analyzing the verbs in the problem statement:
- "takes a long URL and generates a shorter alias" → CREATE operation
- "redirects users to the original URL" → READ operation
- "track link usage" → UPDATE/INCREMENT operation
Each verb maps to a functional requirement:
FR1 — URL Shortening. Users submit a long URL and receive a unique, shortened alias. The short URL uses a compact format with English letters and digits (Base62: a-z, A-Z, 0-9) to save space and ensure uniqueness. The mapping between short and long URLs is permanent and immutable — once created, a short URL always points to the same destination.
FR2 — URL Redirection. When a visitor accesses a shortened URL, the service resolves the alias to the original URL and issues an HTTP redirect (302 Found) with minimal delay. The redirect must work from any geographic region.
FR3 — Click Analytics. The system tracks how many times each shortened URL is accessed. This counter is eventually consistent — it doesn't need to be perfectly accurate in real time, but it must converge to the correct count.
- Authentication and authorization — Who can create URLs or access analytics (handled by a separate auth service)
- URL expiration — TTL-based deletion of old URLs (can be added as a background job later)
- Custom aliases — User-chosen vanity URLs (
short.ly/my-brand) add complexity to uniqueness guarantees - Advanced analytics — Geographic tracking, device types, referrer analysis (beyond basic click count)
- Link preview / unfurling — OpenGraph metadata fetching for social media previews

Non-Functional Requirements
We extract quality constraints from the adjectives in the problem statement:
- "unique" alias → System must guarantee no collisions
- "millions of URLs" + "high traffic" → System must handle large scale
- "efficiently" + "near real-time" → System must respond quickly
- "persistent" → System must not lose data
| Requirement | Target | Rationale |
|---|---|---|
| High Availability | 99.99% uptime | Short URLs are embedded in emails, social posts, printed media — downtime means broken links everywhere |
| Low Latency | < 10 ms p99 for redirects | Redirects sit in the critical path of every click; users perceive any delay as a "broken link" |
| High Durability | Zero data loss | A shortened URL must work forever; losing the mapping means permanently broken links |
| Uniqueness | Zero collisions | Each short code must map to exactly one long URL across all time and all regions |
| Consistency | Newly created URLs resolvable within 5 seconds globally | Acceptable delay between creation and global availability |
| Security | Prevent malicious URL creation | Block phishing, malware, and spam URLs; prevent enumeration attacks on short codes |
Resource Estimation
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily Active Users (DAU) | Given | 100M |
| Write requests per day | Given | 1M URLs shortened/day |
| Read:write ratio | Given | 100:1 |
| Read requests per day | 1M × 100 | 100M redirects/day |
| Write QPS (average) | 1M / 86,400 | ~12 writes/sec |
| Read QPS (average) | 100M / 86,400 | ~1,160 reads/sec |
| Peak read QPS (3× average) | 1,160 × 3 | ~3,500 reads/sec |
Storage Estimation
| Data | Size | Records | Total |
|---|---|---|---|
| URL mapping | ~500 bytes (short code + original URL + metadata) | 1M/day × 365 days × 5 years | 1.825B records |
| Total storage | 500 bytes × 1.825B | ~912 GB (~1 TB) | |
| Analytics record | ~50 bytes (short code + counter + timestamp) | 1 per URL mapping | ~91 GB |
ID Space Estimation
| Encoding | Characters | Length | Capacity | Sufficient? |
|---|---|---|---|---|
| Base62 (6 chars) | a-z, A-Z, 0-9 | 6 | 62⁶ = 56.8 billion | ✓ (30× our 5-year need) |
| Base62 (7 chars) | a-z, A-Z, 0-9 | 7 | 62⁷ = 3.5 trillion | ✓ (far more than needed) |
| Base16 hex (8 chars) | 0-9, a-f | 8 | 16⁸ = 4.3 billion | ✓ (but wastes 2 chars) |
6-character Base62 provides 56.8 billion unique codes — 30× our 5-year requirement of 1.825 billion URLs. This leaves ample headroom for growth.
Bandwidth Estimation
| Operation | Payload | QPS | Bandwidth |
|---|---|---|---|
| Shorten (write) | ~1 KB request | 12/sec | 12 KB/sec (negligible) |
| Redirect (read) | ~500 bytes response | 1,160/sec | 580 KB/sec |
| Analytics increment | ~100 bytes event | 1,160/sec | 116 KB/sec |
The system is read-dominated and storage-modest — classic traits of a caching-friendly architecture.
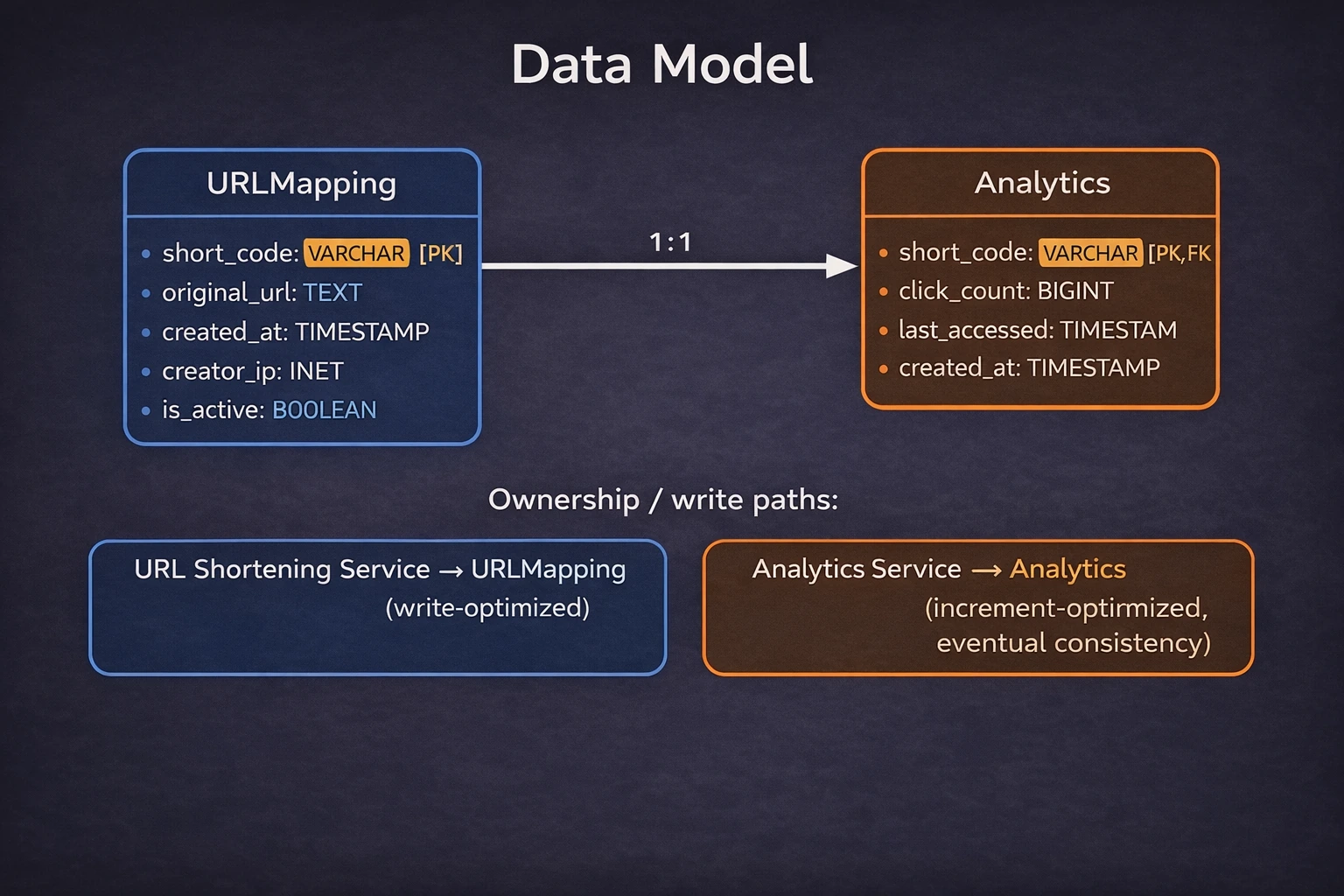
Data Model
The data model emerges from the nouns in the problem statement:
- "URL" and "alias" → URLMapping entity with
short_urlandoriginal_urlfields - "link usage" and "click counts" → Analytics entity with
click_countfield - "persistent" requirement →
created_attimestamp for durability tracking
Ownership is distributed across services to enable independent scaling. The URL Shortening Service owns URLMapping (write-optimized). The Analytics Service owns Analytics (increment-optimized).
URL Mapping Table
CREATE TABLE url_mappings (
short_code VARCHAR(7) PRIMARY KEY, -- Base62 encoded, 6-7 chars
original_url TEXT NOT NULL, -- Destination URL (up to 2048 chars)
created_at TIMESTAMP DEFAULT NOW(), -- Creation time
creator_ip INET, -- For abuse detection (hashed)
is_active BOOLEAN DEFAULT TRUE -- Soft-delete for malicious URLs
);
-- Index for reverse lookup (optional: "does this long URL already have a short code?")
CREATE INDEX idx_original_url ON url_mappings(original_url) WHERE is_active = TRUE;The short_code is the primary key — every redirect performs a lookup by this field. Using it as the primary key ensures a single B-tree index serves both write (INSERT) and read (SELECT) paths.
Why is_active instead of DELETE? When malicious URLs are detected, we soft-delete by setting is_active = FALSE. This preserves the audit trail for abuse investigations and prevents the short code from being reassigned (which would break cached redirects).
Analytics Table
CREATE TABLE url_analytics (
short_code VARCHAR(7) PRIMARY KEY REFERENCES url_mappings(short_code),
click_count BIGINT DEFAULT 0,
last_accessed TIMESTAMP,
created_at TIMESTAMP DEFAULT NOW()
);URLMapping and Analytics have a one-to-one relationship. Each shortened URL has exactly one analytics record. The relationship is optional — URLs can exist without analytics if tracking is disabled.
The analytics table is separated from the mapping table to isolate the high-frequency increment path (every redirect) from the low-frequency write path (URL creation). This prevents write contention on the mapping table and allows the analytics table to use a different storage engine optimized for counters.
API Endpoints
We derive API endpoints directly from the functional requirements (the verbs identified earlier):
- CREATE →
POST /api/urls/shorten(accepts longUrl, returns shortUrl) - READ →
GET /{shortCode}(returns 302 redirect to original URL) - UPDATE → Handled internally via event-driven architecture (not a public endpoint)
Shorten URL
POST /api/urls/shorten
Request Body:
{
"longUrl": "https://example.com/very/long/path?param=value"
}
Response (201 Created):
{
"shortUrl": "https://short.ly/a1B2c3",
"shortCode": "a1B2c3",
"createdAt": "2026-03-17T10:30:00Z"
}
| Status Code | Meaning |
|---|---|
201 Created | URL successfully shortened |
400 Bad Request | Invalid URL format |
409 Conflict | URL already shortened (returns existing short URL) |
429 Too Many Requests | Rate limit exceeded |
Redirect
GET /{shortCode}
Response (302 Found):
HTTP/1.1 302 Found
Location: https://example.com/very/long/path?param=value
Cache-Control: private, max-age=86400
| Status Code | Meaning |
|---|---|
302 Found | Redirect to original URL |
404 Not Found | Short code doesn't exist |
410 Gone | URL was deactivated (malicious content) |
Why 302 instead of 301? A 301 Moved Permanently tells browsers to cache the redirect indefinitely — subsequent visits bypass our server entirely. This breaks analytics (we can't count clicks we never see) and makes URL deactivation impossible (the browser ignores our 410 response). A 302 Found ensures every click hits our server, enabling accurate counting and immediate deactivation.
Get Analytics (Internal)
GET /api/urls/{shortCode}/analytics
Response:
{
"shortCode": "a1B2c3",
"clickCount": 42583,
"lastAccessed": "2026-03-17T15:22:00Z",
"createdAt": "2026-01-15T08:00:00Z"
}
High Level Design
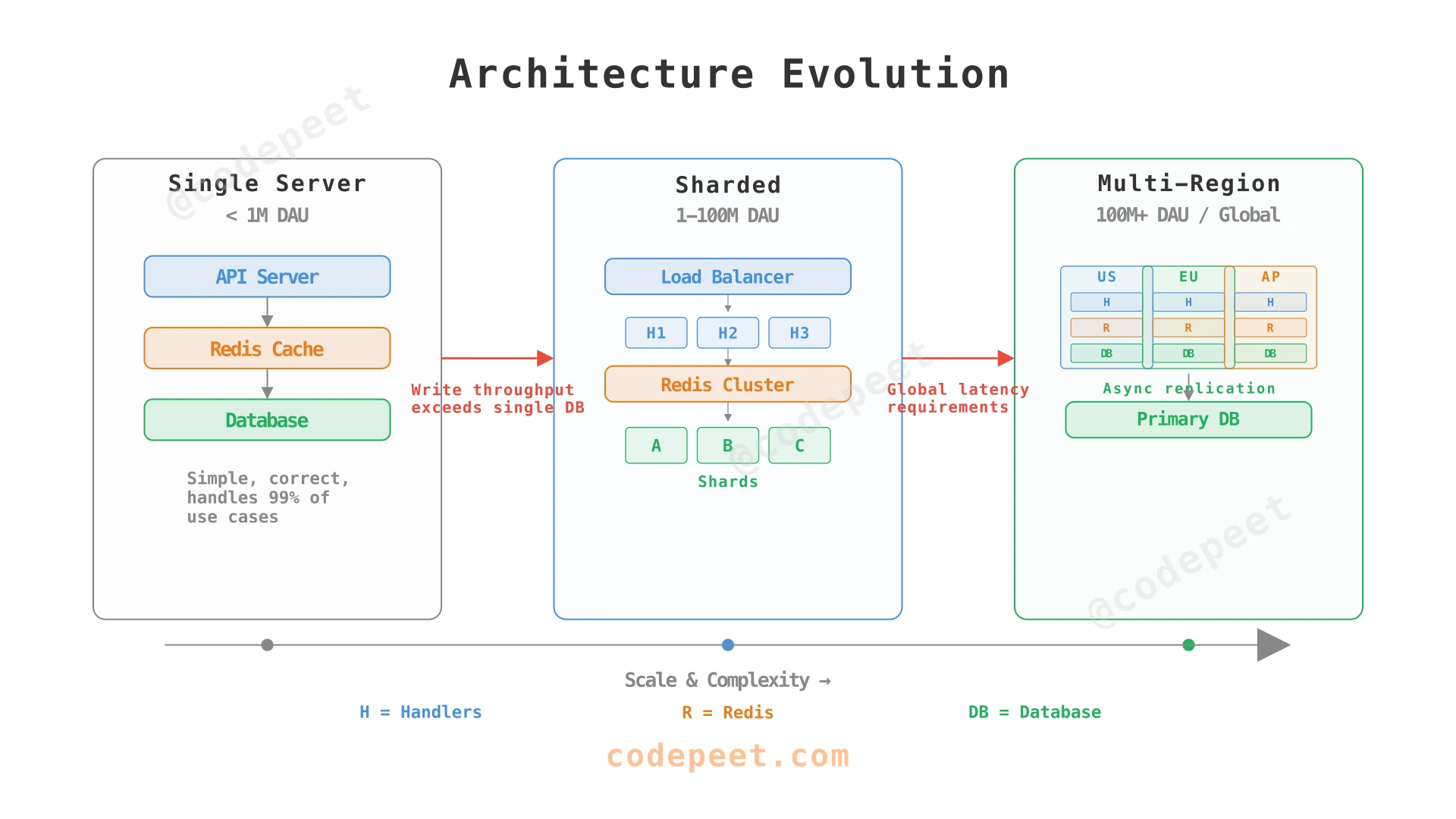
We build the architecture incrementally, adding components as each functional requirement demands them. This approach ensures every component exists for a reason — we're solving real problems, not drawing boxes for theoretical completeness.
1. URL Shortening (FR1)
Requirement: Users submit a long URL and receive a unique shortened alias.
The simplest architecture: a single service that generates an ID, encodes it as Base62, stores the mapping, and returns the short URL.
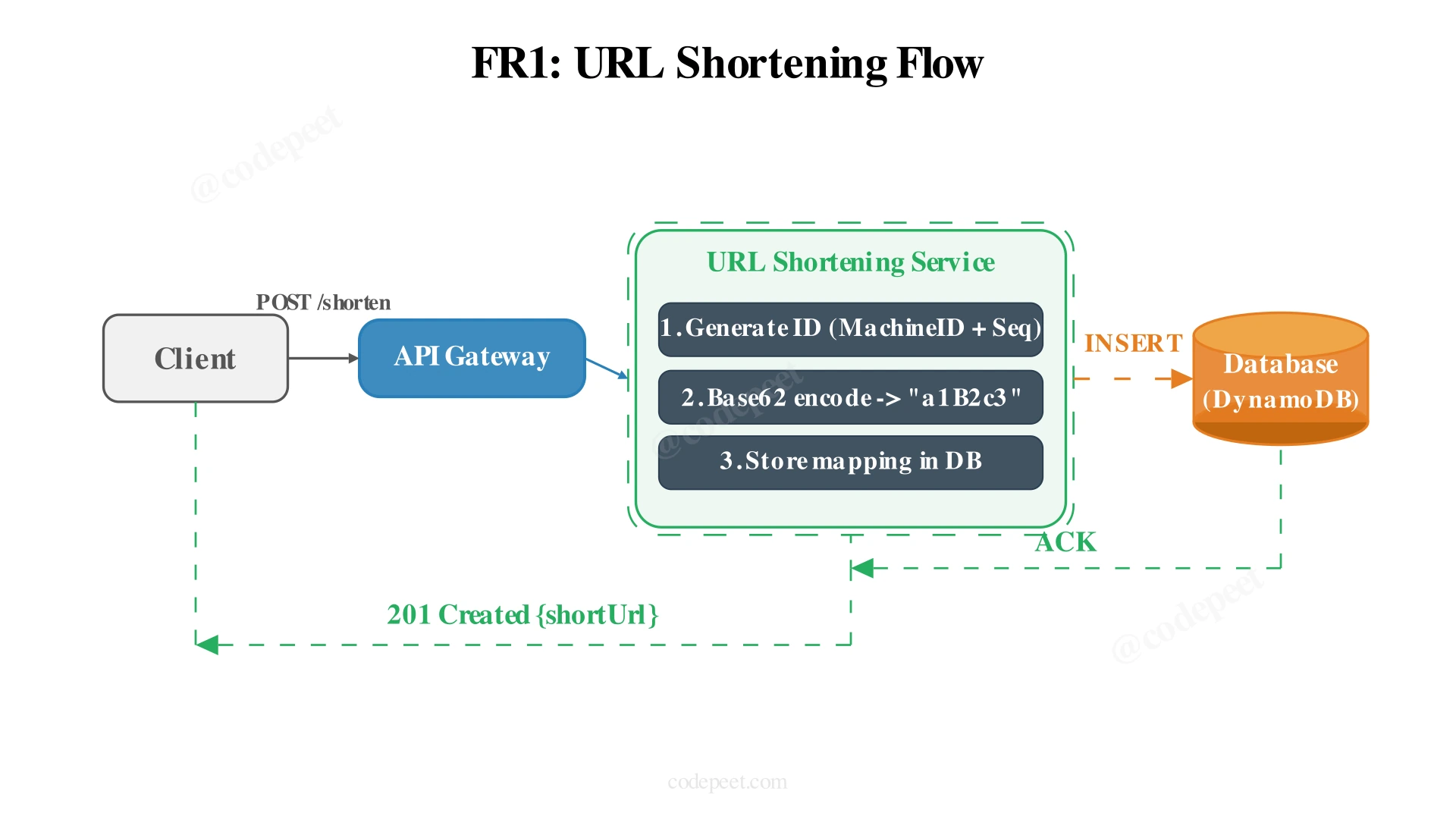
ID Generation: Each server is assigned a unique machine prefix (e.g., A, B, C). Within each server, an auto-incrementing sequence number generates IDs. The combination MachineID + SequenceNumber is globally unique without coordination.
Why this approach? Alternative approaches (hash functions, UUIDs, Snowflake IDs) either produce IDs that are too long or require coordination between servers. Machine ID + Sequence gives us:
- Short IDs — we control the length precisely
- No coordination — each server generates IDs independently
- Scalable — add more servers by assigning new machine prefixes
Base62 Encoding: The numeric ID is converted to a 6-character string using a-z, A-Z, 0-9:
import string
BASE62_CHARS = string.ascii_lowercase + string.ascii_uppercase + string.digits
def base62_encode(num: int) -> str:
"""Encode an integer to a Base62 string."""
if num == 0:
return BASE62_CHARS[0]
result = []
while num > 0:
num, remainder = divmod(num, 62)
result.append(BASE62_CHARS[remainder])
return ''.join(reversed(result))
def base62_decode(s: str) -> int:
"""Decode a Base62 string back to an integer."""
num = 0
for char in s:
num = num * 62 + BASE62_CHARS.index(char)
return num
# Examples:
# base62_encode(123456) → "W7E"
# base62_encode(56800235583) → "zzzzzz" (max 6-char value)With 6 characters, Base62 supports 62⁶ = 56.8 billion unique codes. At 1M URLs/day, that's enough for 155 years before exhaustion — far beyond our 5-year retention requirement.
2. URL Redirection (FR2)
Requirement: Clicking a short URL redirects to the original URL with minimal delay.
Redirects are the dominant traffic pattern — 100× more frequent than URL creation. A naive approach (query the database for every redirect) would require 1,160 QPS to the database. With a caching layer, we can serve the vast majority of redirects from memory.
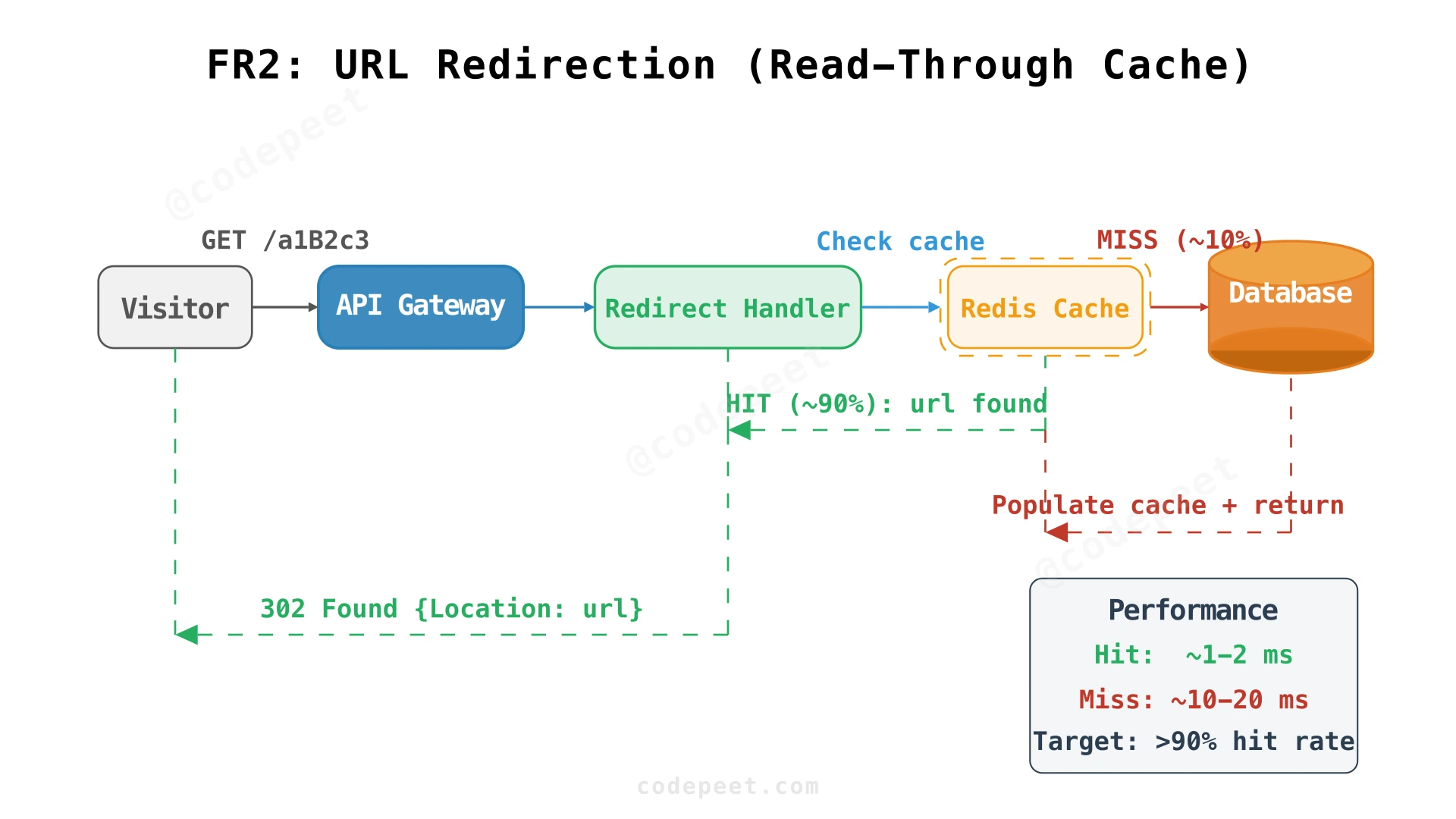
Read-through caching: When the Redirect Handler receives a request, it checks Redis first. On a cache miss, Redis itself fetches from the database, stores the result, and returns it to the handler. The handler never talks to the database directly — Redis acts as the unified read layer.
Why read-through instead of cache-aside? With cache-aside, the application must implement cache-miss logic (check cache → miss → query DB → populate cache). With read-through, the cache library handles this transparently. The Redirect Handler's code is simply:
original_url = cache.get(short_code) # Read-through: auto-fetches from DB on miss
if original_url:
return redirect(original_url, status=302)
return not_found(404)
Cache sizing: With 100M reads/day and Zipfian distribution (20% of URLs get 80% of traffic), we need to cache the top ~2M URLs. At 500 bytes per entry: 2M × 500B = 1 GB — easily fits in a single Redis instance.
TTL strategy: Set TTL to 24 hours for most URLs. Short URLs that are accessed frequently will be refreshed by natural reads. URLs that go cold expire from cache automatically, freeing memory for active URLs.
3. Link Analytics (FR3)
Requirement: Track the number of times each shortened URL is accessed.
Analytics must not slow down redirects. The redirect path returns a 302 in < 10 ms. Analytics recording happens asynchronously after the redirect response is sent.
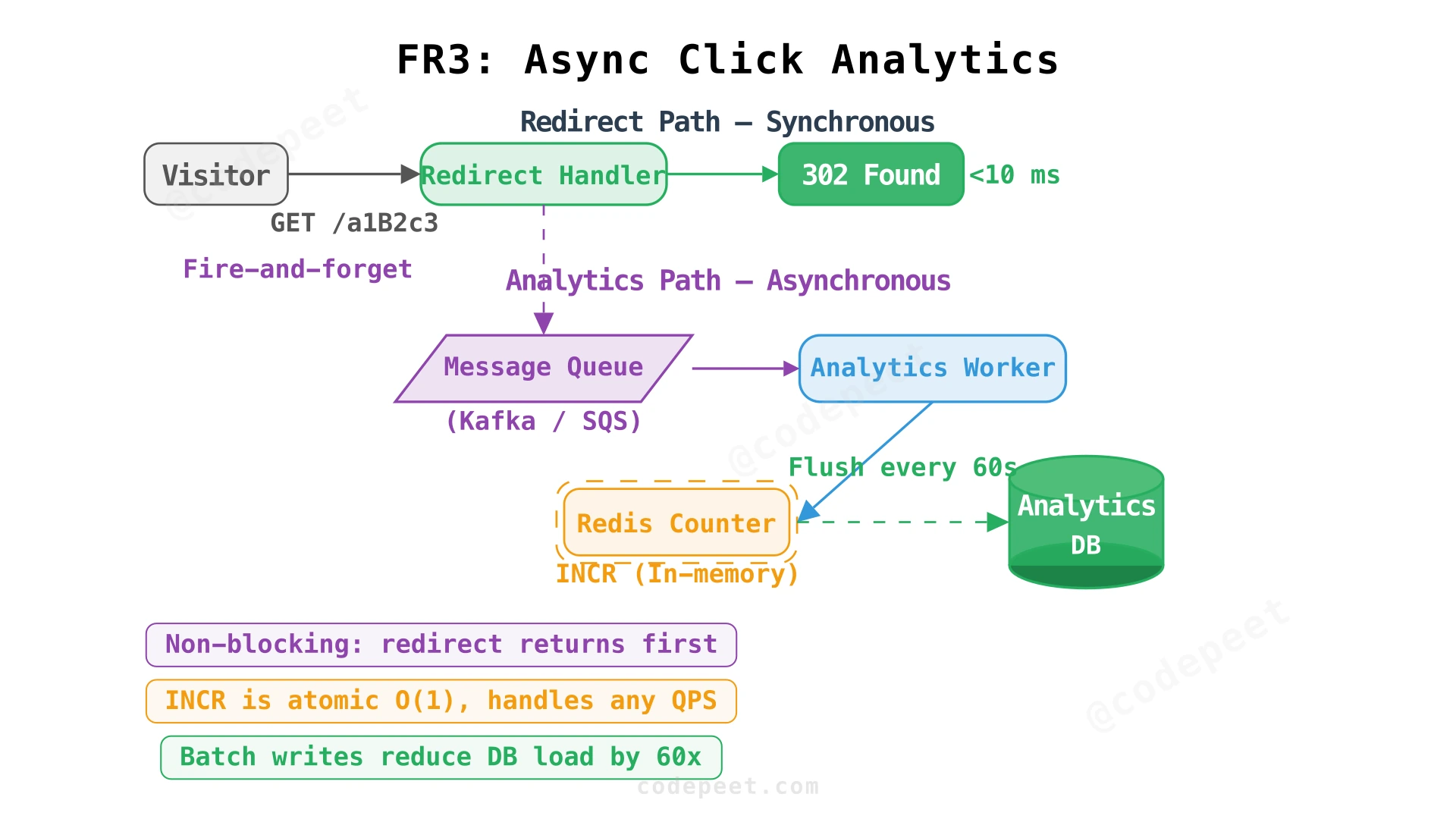
Two-tier counting:
-
Redis INCR — Every click triggers
INCR analytics:{short_code}in Redis. This is an atomic O(1) operation that handles any QPS. The counter is immediately queryable for real-time dashboards. -
Periodic DB flush — A background worker reads Redis counters every 60 seconds and batch-writes them to the Analytics database:
def flush_analytics_to_db():
"""Runs every 60 seconds via scheduled task."""
# GETDEL atomically reads and clears counters
pipeline = redis.pipeline()
keys = redis.keys("analytics:*")
for key in keys:
pipeline.getdel(key) # Get value and delete in one atomic op
counts = pipeline.execute()
# Batch upsert into database
batch = []
for key, count in zip(keys, counts):
if count and int(count) > 0:
short_code = key.split(":")[1]
batch.append((short_code, int(count)))
if batch:
db.executemany(
"""UPDATE url_analytics
SET click_count = click_count + %s,
last_accessed = NOW()
WHERE short_code = %s""",
[(count, code) for code, count in batch]
)Why not increment the DB directly? At 1,160 QPS, direct UPDATE statements would generate 1,160 transactions/sec on the analytics table. With 60-second batching, we reduce this to ~20 batch writes/sec — a 60× reduction in database load. The trade-off: click counts may be up to 60 seconds stale in the database, but they're always current in Redis.
4. Complete Architecture
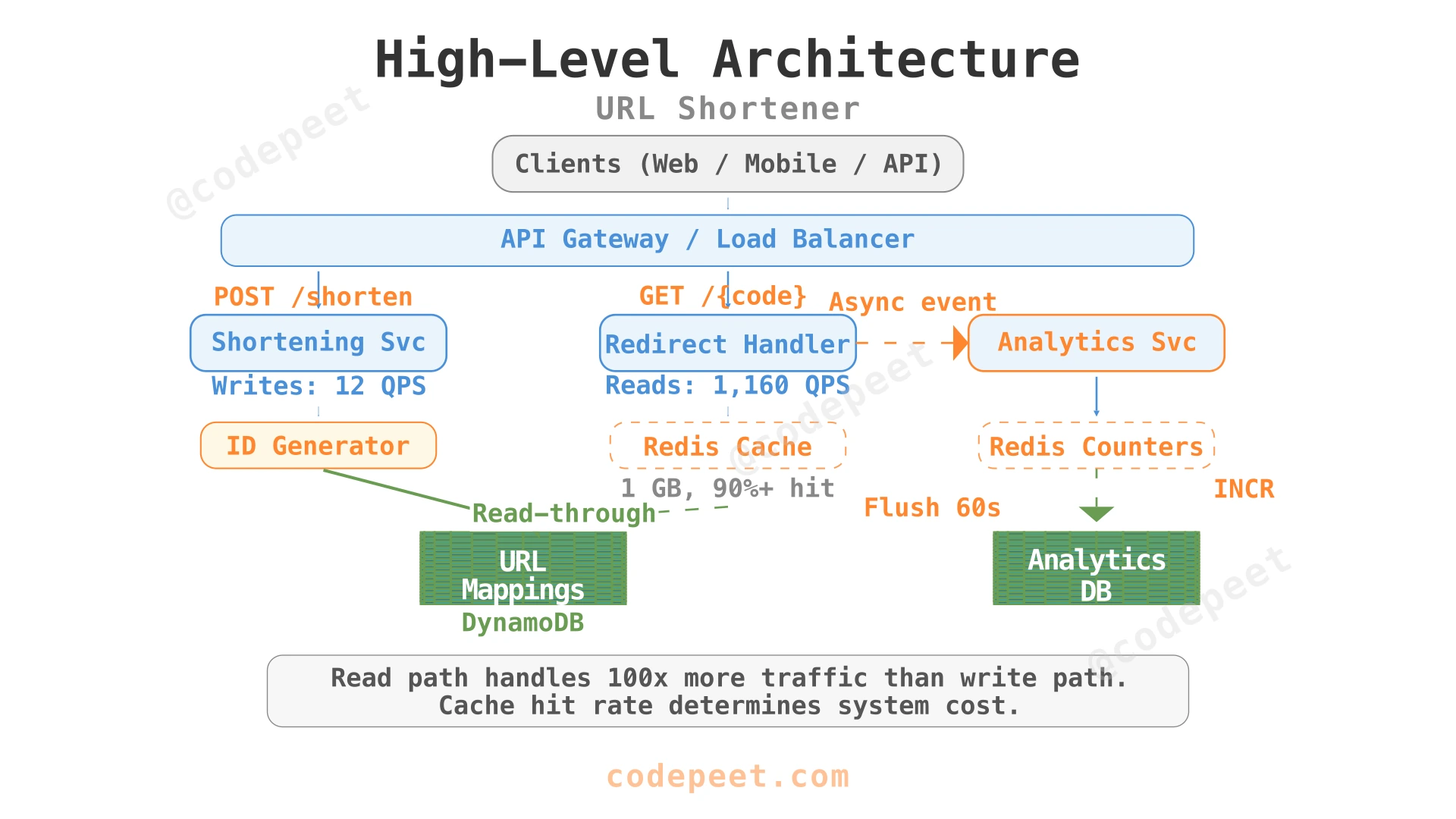
The architecture has three independent scaling paths:
| Service | Scaling Strategy | Bottleneck |
|---|---|---|
| URL Shortening | Add servers with new Machine IDs | ID generation throughput (rarely an issue at 12 QPS) |
| Redirect Handler | Horizontal scaling (stateless) + Redis cluster | Cache miss rate → DB read IOPS |
| Analytics Service | Redis sharding + batch write workers | Redis memory for counters |
Key property: The Redirect Handler is stateless — any instance can serve any redirect. This makes horizontal scaling trivial: add more instances behind the load balancer.
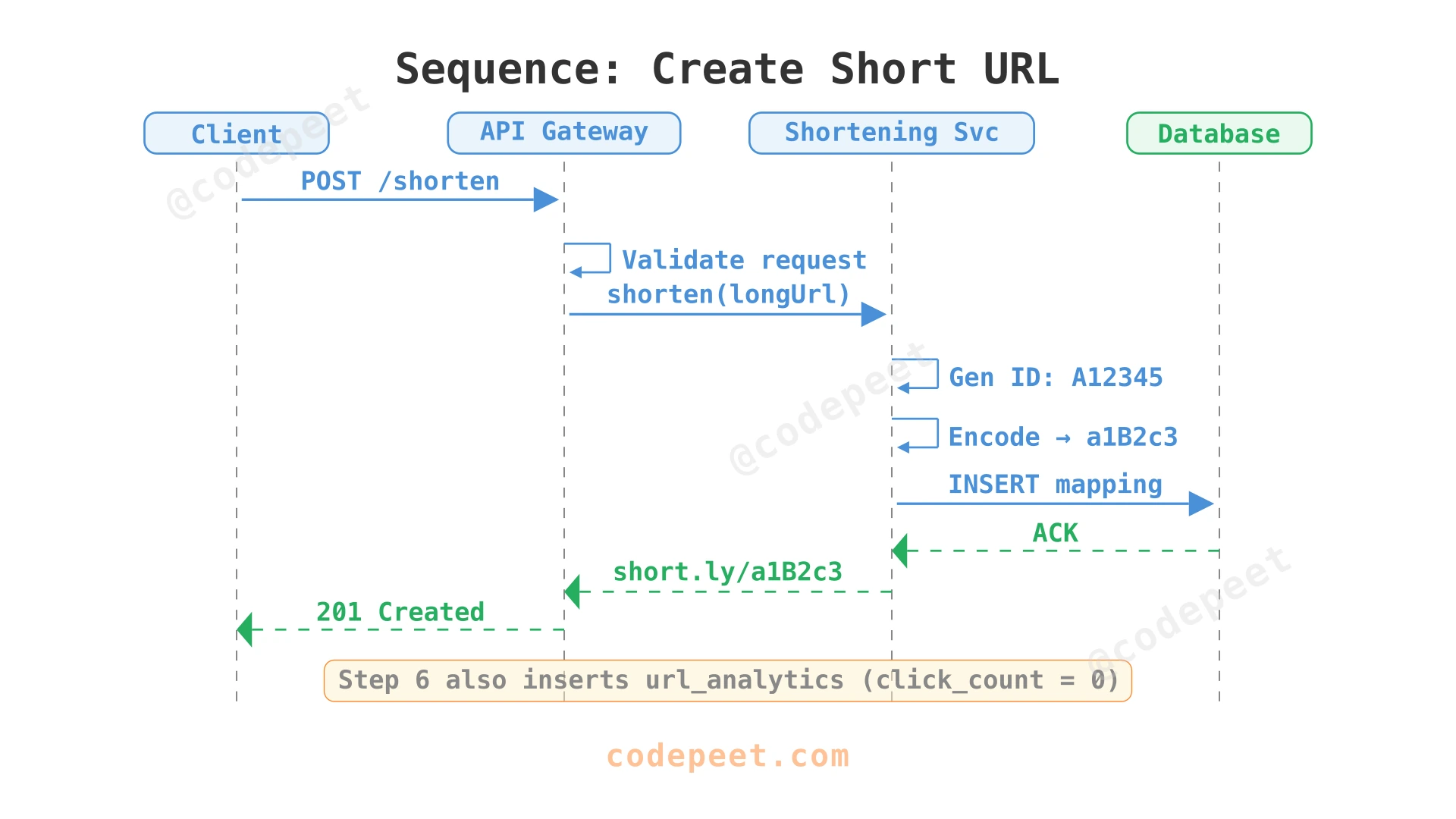
5. Sequence Diagrams
Sequence: Create Short URL
Sequence: Redirect (Cache Hit)
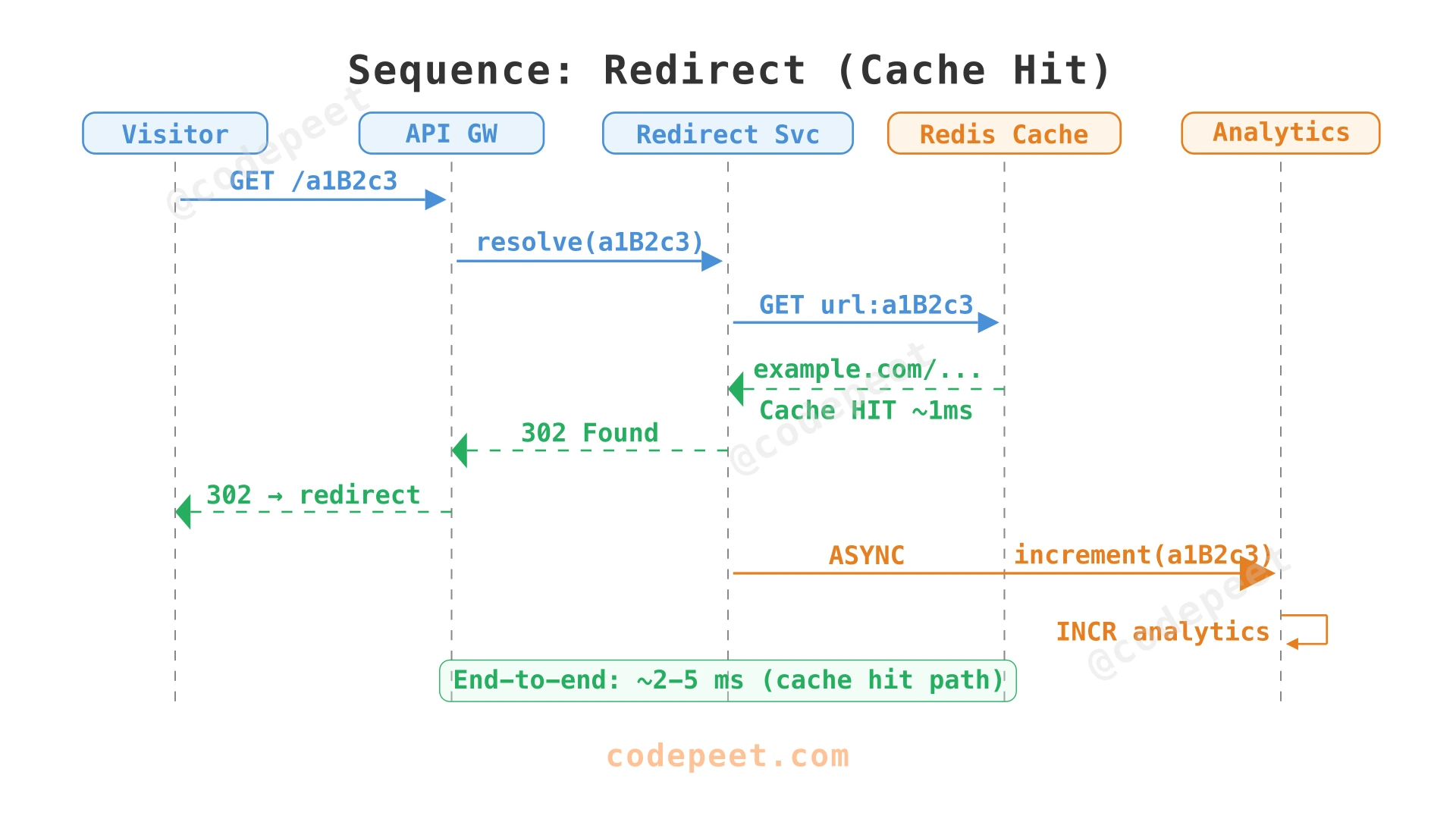
Deep Dive Questions
What ID generation strategy should we use, and why?
The ID must have two properties: global uniqueness (no two URLs share a code) and shortness (compact enough to be useful as a short URL). These properties are in tension — longer IDs are easier to make unique; shorter IDs risk collisions.
The fundamental approach: generate a unique integer, then encode it into a compact string. Let's evaluate the integer generation options:
Option 1: Hash Functions (MD5 / SHA-256)
Hash the original URL to produce a fixed-length digest, then truncate to the desired length.
| Hash | Output Size | Truncated to 6 chars | Collision Risk |
|---|---|---|---|
| MD5 | 128 bits (32 hex chars) | First 6 hex chars → 16⁶ = 16.7M IDs | HIGH — birthday paradox: 50% collision at ~4,000 URLs |
| SHA-256 | 256 bits (64 hex chars) | First 6 Base62 chars → 56.8B IDs | Still requires collision detection |
Problem: Truncation dramatically increases collision probability. Even with collision detection and retry logic, the write path becomes: hash → check DB → collision? → re-hash with salt → check again. Under load, this creates hot-path database reads on every write.
The birthday paradox tells us collisions appear much sooner than expected. For a hash space of size N, the probability of at least one collision after k insertions is approximately:
For 6 hex characters (N = 16⁶ = 16,777,216):
- After 1,000 URLs: P ≈ 3%
- After 4,000 URLs: P ≈ 50%
- After 10,000 URLs: P ≈ 95%
For 6 Base62 characters (N = 62⁶ = 56,800,235,584):
- After 100,000 URLs: P ≈ 0.01%
- After 1,000,000 URLs: P ≈ 0.9%
- After 10,000,000 URLs: P ≈ 58%
Even with the larger Base62 space, hash-based approaches need collision detection by 10M URLs — which we'll reach in 10 days.
Option 2: UUID (v4 Random / v1 Timestamp)
| UUID Version | Format | Length | Uniqueness |
|---|---|---|---|
| UUIDv4 | Random 122-bit | 36 chars (f47ac10b-58cc-4372-...) | Extremely unlikely collisions |
| UUIDv1 | Timestamp + MAC | 36 chars | Guaranteed unique per machine |
Problem: 36 characters defeats the purpose of URL shortening. Even Base62-encoding a UUIDv4 produces ~22 characters. UUIDs solve uniqueness but fail the shortness requirement.
Option 3: Snowflake IDs (Twitter-style)
Structure: [timestamp: 41 bits][machine_id: 10 bits][sequence: 12 bits] = 64-bit integer.
| Property | Value |
|---|---|
| Total bits | 64 |
| Base62 encoded length | ~11 characters |
| Max machines | 1,024 |
| Max IDs per ms per machine | 4,096 |
Problem: Base62 encoding of a 64-bit integer produces ~11 characters. Still too long for a "short" URL. We could truncate, but that reintroduces collision risk.
Option 4: Machine ID + Sequence Number (Recommended)
Assign each server a unique 1-character prefix. Each server maintains an auto-incrementing counter. The ID is: MachinePrefix + SequenceNumber.
With 1 character for machine ID (62 options using Base62) and 5 characters for sequence (62⁵ = 916M per machine):
| Component | Bits/Chars | Capacity |
|---|---|---|
| Machine prefix | 1 Base62 char | 62 machines |
| Sequence number | 5 Base62 chars | 916M per machine |
| Total capacity | 6 chars | 62 × 916M = 56.8B |
class IDGenerator:
def __init__(self, machine_id: str):
"""
machine_id: single Base62 character ('a' through '9')
"""
assert len(machine_id) == 1
self.machine_id = machine_id
self.sequence = self._load_last_sequence() # Recover after restarts
def next_id(self) -> str:
self.sequence += 1
encoded_seq = base62_encode(self.sequence).zfill(5) # Pad to 5 chars
short_code = self.machine_id + encoded_seq
return short_code
def _load_last_sequence(self) -> int:
"""Load from persistent storage to survive restarts."""
try:
with open(f"/var/data/sequence_{self.machine_id}.txt") as f:
return int(f.read().strip())
except FileNotFoundError:
return 0
def _persist_sequence(self):
"""Called periodically (every 1000 IDs) to checkpoint."""
with open(f"/var/data/sequence_{self.machine_id}.txt", "w") as f:
f.write(str(self.sequence))Advantages over alternatives:
| Strategy | Length | Uniqueness | Coordination | Complexity |
|---|---|---|---|---|
| Hash + truncation | 6+ | Requires collision detection | None | Medium (retry logic) |
| UUID | 22+ (Base62) | Guaranteed | None | Low |
| Snowflake | 11+ (Base62) | Guaranteed | Clock sync | Medium |
| Machine ID + Sequence | 6 | Guaranteed (by construction) | Machine ID assignment | Low |
The Machine ID + Sequence approach produces the shortest IDs with guaranteed uniqueness and no runtime coordination between servers. The only coordination point is machine ID assignment — a one-time setup operation when adding servers.
If a server crashes and restarts, it must not reuse sequence numbers. Three approaches:
-
Persistent checkpoint (recommended): Write the current sequence to disk every N IDs (e.g., every 1,000). On restart, resume from the last checkpoint + 1,000 (skip the gap to avoid any overlap).
-
Database-backed sequence: Use a database counter (
SELECT last_seq FROM sequences WHERE machine_id = 'A' FOR UPDATE). Reliable but adds a DB call to every write. -
Time-based offset: On restart, jump the sequence forward by
(seconds_since_epoch × expected_rate). This wastes some ID space but requires no persistent state.
The checkpoint approach balances reliability with performance — you lose at most 1,000 IDs per crash (0.0001% of the per-machine capacity of 916M).
Under sudden traffic spikes, generating IDs on-demand could introduce latency if the sequence checkpoint or encoding becomes a bottleneck. Pre-generating a batch of IDs eliminates this concern:
class BulkIDGenerator:
BATCH_SIZE = 10_000
def __init__(self, machine_id: str):
self.machine_id = machine_id
self.buffer = []
self.sequence = self._load_last_sequence()
self._refill()
def next_id(self) -> str:
if not self.buffer:
self._refill()
return self.buffer.pop()
def _refill(self):
batch = []
for _ in range(self.BATCH_SIZE):
self.sequence += 1
batch.append(self.machine_id + base62_encode(self.sequence).zfill(5))
self.buffer = batch
self._persist_sequence()
Trade-off: Pre-generation wastes IDs if the server crashes before using all buffered IDs. With a 10K buffer and 916M capacity per machine, this waste is negligible (0.001%).
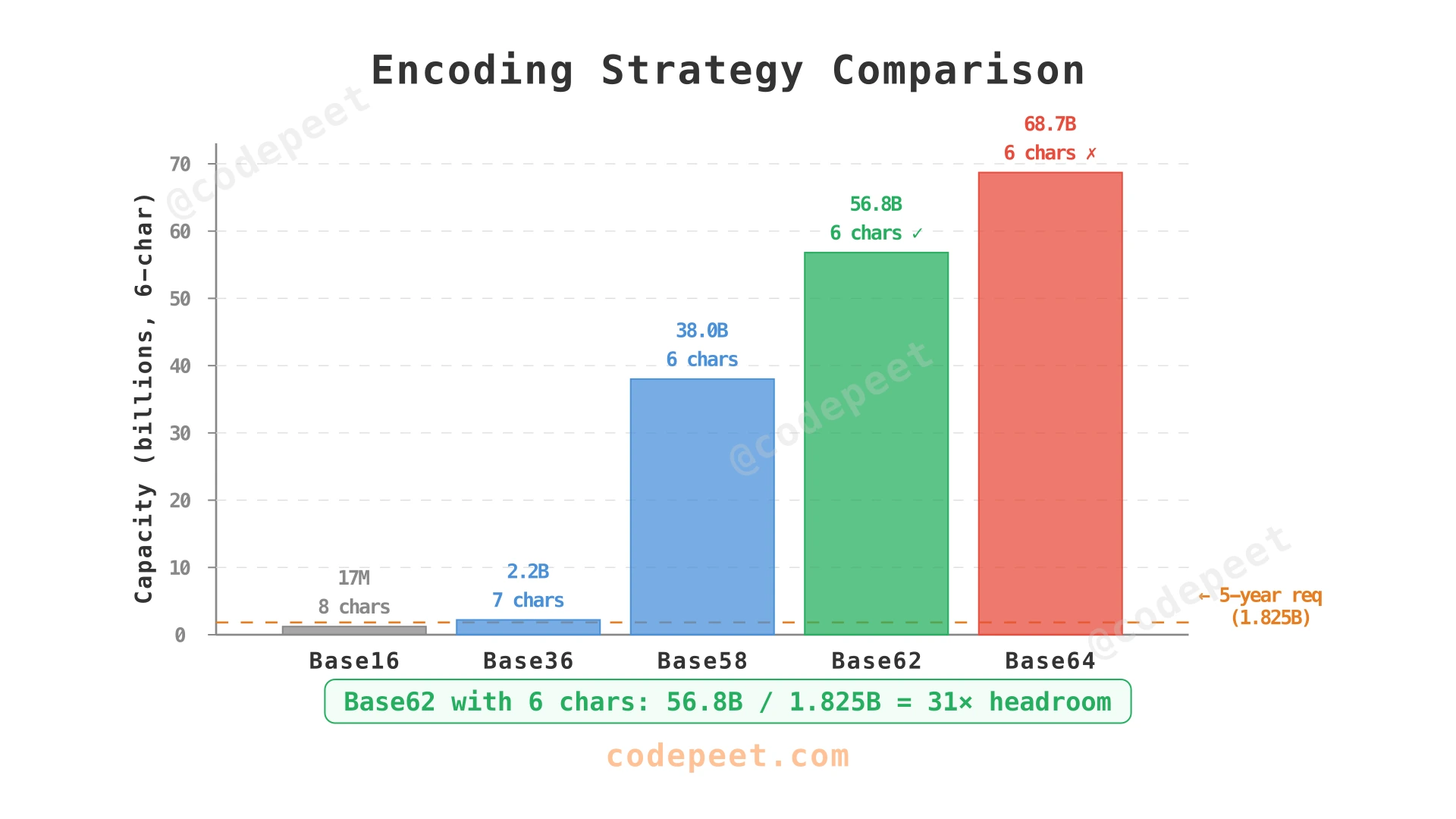
How should we encode IDs into short, URL-safe strings?
After generating a unique integer, we need to encode it into a compact, human-readable string. The encoding must balance shortness with usability — avoiding characters that are confusing to type or problematic in URLs.
Encoding Options Comparison
| Encoding | Characters | Capacity (6 chars) | Chars for 56B IDs | Issues |
|---|---|---|---|---|
| Base16 (Hex) | 0-9, a-f | 16⁶ = 16.7M | 8 chars | Only 16 chars → longer strings |
| Base36 | 0-9, a-z | 36⁶ = 2.2B | 7 chars | Case-insensitive (loses half the alphabet) |
| Base58 | A-Z, a-z, 0-9 minus 0OIl | 58⁶ = 38B | 6 chars | Avoids confusing characters but non-standard |
| Base62 | a-z, A-Z, 0-9 | 62⁶ = 56.8B | 6 chars | No special characters, URL-safe |
| Base64 | A-Z, a-z, 0-9, +, /, = | 64⁶ = 68.7B | 6 chars | +, /, = problematic in URLs |
Why Base62?
Base62 is the optimal choice because:
- No special characters —
+,/, and=from Base64 must be URL-encoded (%2B,%2F,%3D), defeating the purpose of shortening - 6 characters suffice — 62⁶ = 56.8B provides 30× headroom over our 5-year requirement
- Human-friendly — All characters are easily typeable on any keyboard
- Case-sensitive by definition — URLs are case-sensitive after the domain, so
a1B2c3andA1b2C3are different short codes
Base58 removes visually ambiguous characters: 0 (zero) vs O (letter O), I (uppercase i) vs l (lowercase L). This is valuable for Bitcoin addresses that are manually transcribed.
For URLs, visual ambiguity matters less — users click links, they don't type them. The extra 4 characters (0, O, I, l) give us Base62's larger space (56.8B vs 38B for same length), reducing the likelihood of needing 7-character codes.
When to choose Base58: If your short URLs appear on billboards, business cards, or physical media where humans must type them. When to choose Base62: If URLs are primarily shared digitally (links, messages, emails).
How do we scale the system to handle high traffic?
Request handlers are stateless HTTP servers — scaling them is trivial (add more instances behind the load balancer). The interesting scaling challenges are in the ID generator and the database.
Scaling the ID Generator
Each ID generator uses 1 character for machine ID, giving us 62 possible machines. Each machine generates up to 916M IDs. But how do we route requests to them?
Load balancing strategies:
- Random selection: Each request handler picks a random ID generator. Simplest, good load distribution.
- Least-loaded: Pick the generator with the shortest queue. Better under skewed load.
- Sticky routing: Route by client ID. Unnecessary (any generator works for any request).
Sharding the Database
The machine ID prefix in each short code serves double duty as the shard key. Each machine writes to its own database shard — the write paths are completely independent.
Shard key = Machine ID prefix in the short code.
When machine A generates code a1B2c3 (prefix a), it writes to shard a. When machine B generates B7x9pQ (prefix B), it writes to shard B. No cross-shard coordination is needed for writes.
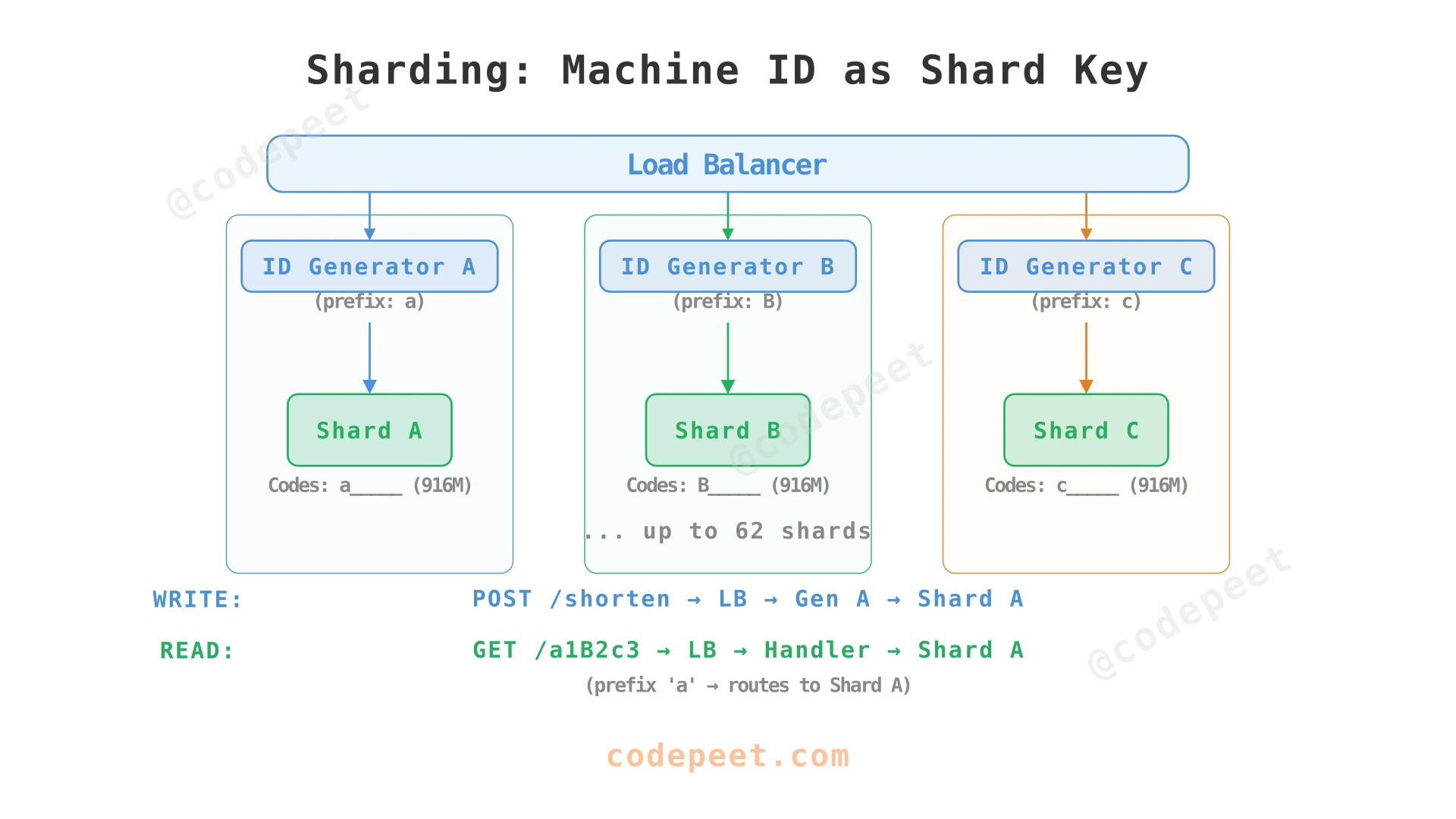
Write path: Completely parallel. Each machine writes to its own shard. No coordination, no locking, no cross-shard transactions. Adding a new machine = adding a new shard. Existing shards are unaffected.
Read path: On a cache miss, the redirect handler extracts the first character of the short code and routes to the correct shard. For example, a1B2c3 → shard a.
Why This Sharding Strategy Works
| Benefit | Explanation |
|---|---|
| No rebalancing | Unlike consistent hashing, adding a new shard doesn't redistribute existing data. All old data stays where it is. |
| Deterministic routing | The shard is encoded in the short code itself. No routing table lookup needed. |
| Independent scaling | If shard a gets hot, add a read replica. Other shards are unaffected. |
| Simple failure isolation | If shard B fails, only codes starting with B are affected. All other codes work fine. |
Should request handlers and ID generators be 1:1? No — they have different scaling profiles:
Request handlers are I/O-bound: handling HTTP connections, checking cache, holding sockets open. They need many instances for concurrency — often 10-50 instances for high traffic.
ID generators are CPU/IO-bound: generating IDs and writing to disk/DB. Each generator can handle thousands of IDs per second. At 12 QPS average, even a single generator has enormous headroom.
Typical ratio: 10-20 request handlers per ID generator.
Routing: Request handlers pick an ID generator using round-robin or least-loaded selection. Since any generator can serve any request, the routing doesn't need to be sticky.
| Database | Strengths | Weaknesses | Best For |
|---|---|---|---|
| DynamoDB | Managed, auto-scales, single-digit ms latency, built-in partitioning | Expensive at high throughput, limited query flexibility | AWS-native teams, low operational overhead |
| Cassandra | Linear horizontal scaling, tunable consistency, handles massive write throughput | Operational complexity, no transactions, limited secondary indexes | Write-heavy workloads, multi-region |
| PostgreSQL (sharded) | Rich query support, ACID transactions, familiar tooling | Manual sharding, scaling requires application-level routing | Teams with PostgreSQL expertise, analytics queries |
Recommended: DynamoDB for most teams (lowest operational burden). The URL shortener's access pattern (simple key-value lookups) maps perfectly to DynamoDB's design.
DynamoDB schema:
Table: url_mappings
Partition Key: short_code (String)
Attributes: original_url (String), created_at (Number), is_active (Boolean)
Read Capacity: On-demand (auto-scales)
Write Capacity: On-demand
How do we design the caching layer for 90%+ hit rates?
Caching is the single most impactful design decision for a URL shortener. With a 100:1 read-write ratio, the difference between 80% and 95% cache hit rate means 20× vs 5× load on the database — the difference between 1 database instance and 4.
Traffic Distribution: Zipf's Law
URL access follows a Zipfian distribution — a small fraction of URLs receive the vast majority of clicks. Empirical data from services like bit.ly shows:
- Top 1% of URLs → ~50% of all clicks
- Top 10% of URLs → ~90% of all clicks
- Bottom 50% of URLs → ~1% of clicks (many are clicked only once)
This is excellent for caching: a small cache capturing the top URLs handles most traffic.
Cache Sizing
| Cache Size | URLs Cached | Estimated Hit Rate | DB QPS (at 1,160 total) |
|---|---|---|---|
| 100 MB | ~200K URLs | ~75% | 290 |
| 500 MB | ~1M URLs | ~88% | 139 |
| 1 GB | ~2M URLs | ~93% | 81 |
| 5 GB | ~10M URLs | ~98% | 23 |
At 1 GB (easily fits in a single Redis instance), we achieve ~93% hit rate, leaving only ~80 QPS hitting the database. This is well within a single database node's capacity.
Caching Strategies Compared
| Strategy | How It Works | Pros | Cons |
|---|---|---|---|
| Cache-aside | App checks cache → miss → app queries DB → app writes cache | Simple, app controls logic | Cache miss requires 2 round trips |
| Read-through | App reads cache → miss → cache auto-fetches from DB | Transparent to app, fewer code paths | Requires cache library support |
| Write-through | On URL creation, write to both DB and cache | Cache is always warm for new URLs | Adds latency to write path |
| Write-behind | On URL creation, write to cache first, async to DB | Lowest write latency | Risk of data loss if cache crashes |
Recommended: Read-through + Write-through hybrid.
- Write path: When a new URL is created, write to both DB and cache (write-through). This ensures newly created URLs are immediately resolvable without a cache miss.
- Read path: On redirect, read from cache. On miss, the cache auto-fetches from DB (read-through).
Cache stampede: A popular URL's cache entry expires. 1,000 concurrent requests all experience a cache miss simultaneously. All 1,000 hit the database for the same URL. The database is overwhelmed.
Solution: Request coalescing (singleflight pattern)
import asyncio
from collections import defaultdict
class CoalescingCache:
def __init__(self, redis_client, db_client):
self.redis = redis_client
self.db = db_client
self._inflight = {} # short_code → Future
async def get(self, short_code: str) -> str:
# Check cache first
result = await self.redis.get(f"url:{short_code}")
if result:
return result
# Coalesce concurrent misses for the same key
if short_code in self._inflight:
return await self._inflight[short_code]
future = asyncio.get_event_loop().create_future()
self._inflight[short_code] = future
try:
# Only ONE request hits the database
url = await self.db.get(short_code)
if url:
await self.redis.set(f"url:{short_code}", url, ex=86400)
future.set_result(url)
return url
finally:
del self._inflight[short_code]
With coalescing, 1,000 concurrent requests for the same expired key result in 1 database query instead of 1,000. The first request fetches from DB; the other 999 wait on the same Future.
Stale-while-revalidate: An alternative approach: serve the stale cached value immediately while refreshing in the background. This provides zero-latency cache misses at the cost of serving slightly stale data (acceptable for URL mappings that never change).
For extreme scale (10B+ redirects/day), add a local in-process cache layer:
Tier 1: In-process LRU cache (each Redirect Handler instance)
- Size: 100 MB per instance (~200K URLs)
- Latency: < 0.1 ms (no network call)
- Hit rate: ~60% (top URLs accessed by this specific instance)
Tier 2: Redis cluster (shared)
- Size: 1-5 GB
- Latency: ~1 ms
- Hit rate: ~33% of remaining requests (93% total cumulative)
Tier 3: Database
- Latency: ~5-10 ms
- Only ~7% of requests reach this tier
async def resolve_url(short_code: str) -> str:
# Tier 1: In-process cache (no network)
url = local_cache.get(short_code)
if url:
return url
# Tier 2: Redis (1ms network)
url = await redis.get(f"url:{short_code}")
if url:
local_cache.put(short_code, url)
return url
# Tier 3: Database (5-10ms)
url = await db.get_url(short_code)
if url:
await redis.set(f"url:{short_code}", url, ex=86400)
local_cache.put(short_code, url)
return url
Should we use 301 or 302 redirects? What are the trade-offs?
The redirect status code determines browser behavior, caching semantics, and analytics accuracy. This seemingly small decision has significant downstream consequences.
| Status Code | Name | Browser Behavior | Cache-Control |
|---|---|---|---|
| 301 | Moved Permanently | Browser caches redirect forever; future visits bypass server | Cached by default |
| 302 | Found | Browser does NOT cache redirect; every visit hits server | Not cached by default |
| 307 | Temporary Redirect | Like 302 but preserves HTTP method (POST stays POST) | Not cached |
| 308 | Permanent Redirect | Like 301 but preserves HTTP method | Cached |
Impact Analysis
| Dimension | 301 (Permanent) | 302 (Temporary) |
|---|---|---|
| Server load | Lower — browser caches, fewer requests hit server | Higher — every click hits server |
| Analytics accuracy | Broken — cached redirects bypass server entirely, clicks go uncounted | Accurate — every click passes through server |
| URL deactivation | Broken — browser uses cached redirect even after deactivation | Works — server can return 410 Gone |
| SEO (link juice) | Passes full link equity to destination | Passes partial link equity |
| User latency | Lower — cached redirect is instant | Slightly higher — server round-trip required |
When to Use Each
Use 302 (recommended for most URL shorteners):
- You need click analytics (the primary business model for many shorteners)
- You need ability to deactivate malicious URLs
- You want to A/B test destination URLs
- The redirect is for external/marketing links
Use 301 for specific cases:
- Internal tool links where analytics don't matter
- Links embedded in documentation that will never change
- When minimizing server load is critical and analytics are unnecessary
Hybrid Approach
The best of both worlds: use 302 with a Cache-Control header that enables short-term browser caching:
HTTP/1.1 302 Found
Location: https://example.com/destination
Cache-Control: private, max-age=86400
This tells the browser: "Cache this redirect for 24 hours, but check back with us after that." You lose at most 1 click per user per day to caching, while still getting analytics for most visits.
How do we prevent abuse and detect malicious URLs?
URL shorteners are prime targets for abuse. Attackers use them to disguise phishing URLs, distribute malware, and bypass email security filters. If security vendors blocklist your domain, legitimate users lose access — a business-critical failure.
Defense Layers
Layer 1: Pre-creation scanning (synchronous)
Before storing a URL, check it against known malicious URL databases:
import aiohttp
SAFE_BROWSING_API = "https://safebrowsing.googleapis.com/v4/threatMatches:find"
async def check_url_safety(url: str) -> dict:
"""Check URL against Google Safe Browsing API."""
payload = {
"threatInfo": {
"threatTypes": ["MALWARE", "SOCIAL_ENGINEERING", "UNWANTED_SOFTWARE"],
"platformTypes": ["ANY_PLATFORM"],
"threatEntryTypes": ["URL"],
"threatEntries": [{"url": url}]
}
}
async with aiohttp.ClientSession() as session:
async with session.post(SAFE_BROWSING_API, json=payload) as resp:
result = await resp.json()
if result.get("matches"):
return {"safe": False, "threats": result["matches"]}
return {"safe": True}
async def shorten_url(long_url: str) -> str:
# Step 1: Check safety BEFORE creating short URL
safety = await check_url_safety(long_url)
if not safety["safe"]:
raise MaliciousURLError("URL flagged by Safe Browsing API")
# Step 2: Rate limit by IP (prevent bulk creation of phishing URLs)
if not rate_limiter.allow(request.client_ip, limit=100, window=3600):
raise RateLimitExceeded("Too many URLs created")
# Step 3: Create short URL
return create_short_url(long_url)Layer 2: Post-creation batch scanning (asynchronous)
URLs can become malicious after creation (e.g., destination changes, new threat intelligence). A background scanner rechecks URLs periodically:
| Scanning Strategy | Check Frequency | Coverage | Cost |
|---|---|---|---|
| New URLs (< 24h old) | Every 4 hours | Focus on fresh, unverified URLs | Low |
| Most-clicked URLs | Every 12 hours | High-impact URLs | Low |
| Random sample (1%) | Daily | Catch long-tail abuse | Low |
| Reported URLs | Immediately | User-triggered investigation | Reactive |
Layer 3: Enumeration prevention
Short codes like a00001, a00002, a00003 are sequential and predictable. An attacker can enumerate all URLs by incrementing the code. Mitigations:
- Randomize sequence within machine: Instead of strictly incrementing, use a permutation function that maps sequential integers to non-sequential outputs
- Rate limit redirect requests: Detect enumeration patterns (sequential codes from same IP)
- Don't expose creation-order information: Ensure short codes don't reveal when they were created
When a malicious URL is detected:
- Immediate: Set
is_active = FALSEin the database - Cache invalidation: Delete the cache entry (
DEL url:{short_code}) - Redirect behavior change: Return
410 Gonewith a warning page instead of redirecting - Notification: Alert the URL creator (if authenticated) and the reporter (if user-reported)
async def deactivate_url(short_code: str, reason: str):
await db.execute(
"UPDATE url_mappings SET is_active = FALSE WHERE short_code = %s",
short_code
)
await redis.delete(f"url:{short_code}")
await redis.set(f"deactivated:{short_code}", reason, ex=86400*30)
await audit_log.record(short_code, "DEACTIVATED", reason)
async def handle_redirect(short_code: str):
# Check deactivation first (cached check)
deactivation_reason = await redis.get(f"deactivated:{short_code}")
if deactivation_reason:
return render_warning_page(short_code, deactivation_reason)
url = await resolve_url(short_code)
if url:
await record_click(short_code) # Async analytics
return redirect(url, status=302)
return not_found()
Time to deactivation target: < 5 minutes from detection to global cache purge. This limits the exposure window for phishing campaigns.
How do we deploy across regions for global availability?
A user in California creates a short URL. Seconds later, someone in Tokyo clicks it. The URL must resolve globally with minimal latency. This requires multi-region deployment with careful consistency trade-offs.
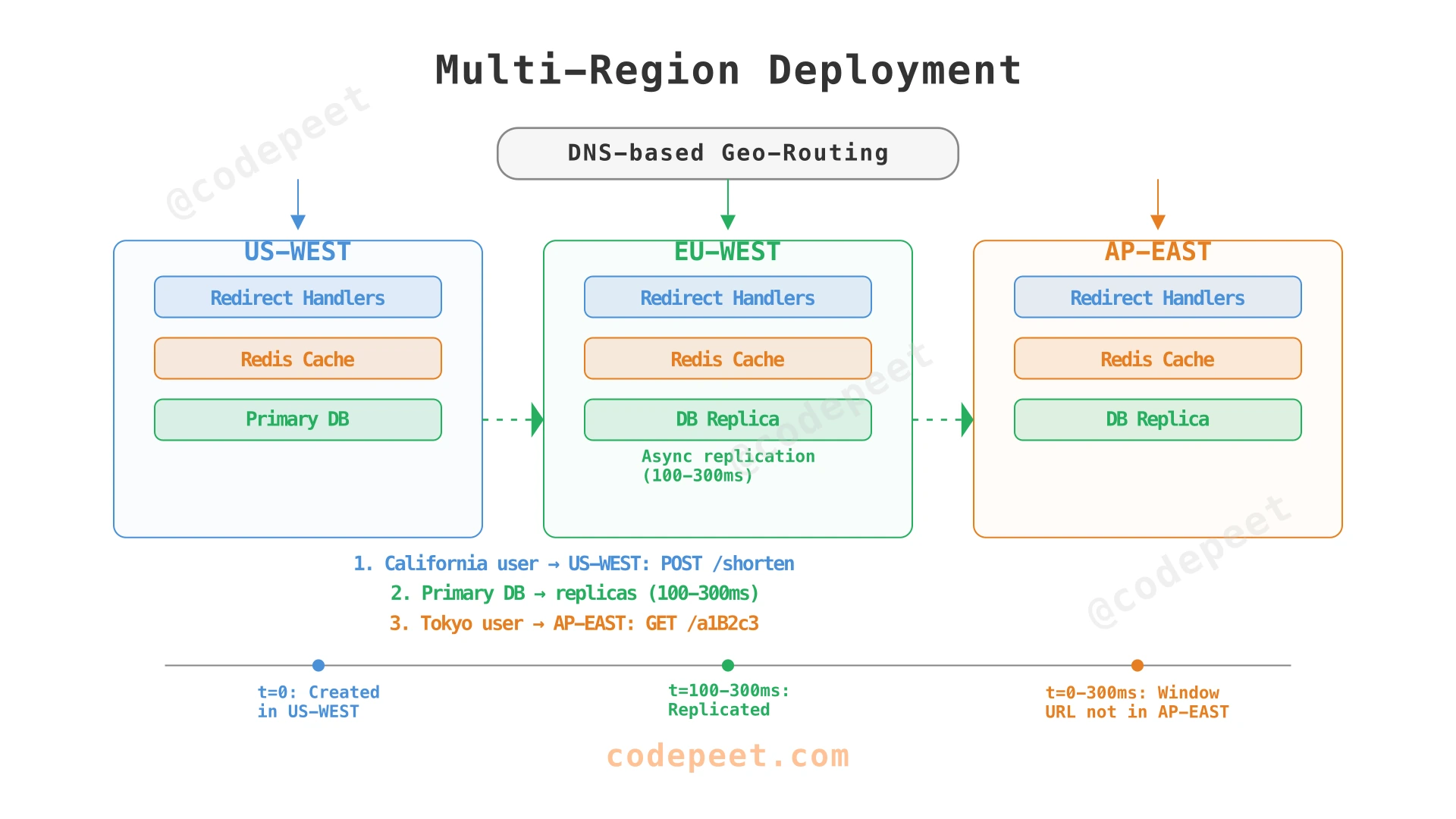
The Consistency Challenge
A newly created URL must be globally resolvable within seconds. But cross-region replication takes 100-300 ms. During this window, a request to the AP-EAST region returns 404 for a URL that exists in US-WEST.
Solution: Read-after-write consistency for creators
async def shorten_url(long_url: str) -> dict:
short_code = generate_id()
# Write to primary (US-WEST)
await primary_db.insert(short_code, long_url)
# Write-through to LOCAL cache (immediate availability in creation region)
await local_redis.set(f"url:{short_code}", long_url, ex=86400)
# Return short URL — creator can immediately share it
return {"shortUrl": f"https://short.ly/{short_code}"}
The creator's region has the URL immediately in cache. Other regions receive it within 300 ms via replication. For the rare case where someone clicks a URL within 300 ms of creation from a different region:
Fallback: Cross-region read on miss
async def resolve_url(short_code: str) -> str:
# 1. Check local cache
url = await local_redis.get(f"url:{short_code}")
if url:
return url
# 2. Check local DB replica
url = await local_db.get(short_code)
if url:
await local_redis.set(f"url:{short_code}", url, ex=86400)
return url
# 3. Fallback: check primary region (adds 100-200ms latency)
url = await primary_db.get(short_code)
if url:
await local_redis.set(f"url:{short_code}", url, ex=86400)
return url
return None # URL truly doesn't exist
The cross-region fallback adds 100-200 ms but only triggers for URLs created within the last 300 ms and accessed from a different region — an extremely rare path.
Regional Cache Warming
For high-profile URLs (e.g., a marketing campaign shared on social media), pre-warm caches in all regions at creation time:
| Strategy | When to Use | Latency Impact |
|---|---|---|
| Async replication only | Default (99% of URLs) | 100-300ms replication lag |
| Cross-region cache write | URLs created via API with priority: high flag | 50-100ms added to write path |
| Cross-region read fallback | Cache miss for very new URLs | 100-200ms for affected reads |
How do we handle URL expiration and storage growth?
At 1M URLs/day for 5 years, we accumulate 1.825B records (~1 TB). Without cleanup, storage grows indefinitely. But deleting URLs is dangerous — a "dead link" is worse than a "slightly slow link."
Expiration Policy
| URL Category | Retention | Rationale |
|---|---|---|
| Active URLs (clicked in last 90 days) | Forever | Still in use, never expire |
| Dormant URLs (not clicked in 90 days) | 5 years from creation | Might be embedded in old documents |
| Orphan URLs (never clicked, > 1 year old) | 1 year from creation | Likely created by bots or forgotten |
| Deactivated URLs (malicious) | Keep record forever, redirect disabled | Prevent short code reuse |
TTL-Based Cleanup
def cleanup_expired_urls():
"""Runs daily as a scheduled batch job."""
# Never delete — archive and soft-delete
expired = db.query("""
SELECT short_code FROM url_mappings
WHERE is_active = TRUE
AND created_at < NOW() - INTERVAL '5 years'
AND short_code NOT IN (
SELECT short_code FROM url_analytics
WHERE last_accessed > NOW() - INTERVAL '90 days'
)
""")
for batch in chunk(expired, 1000):
# Archive to cold storage (S3/Glacier)
archive_to_cold_storage(batch)
# Soft-delete
db.execute(
"UPDATE url_mappings SET is_active = FALSE WHERE short_code IN %s",
batch
)
# Invalidate cache
redis.delete(*[f"url:{code}" for code in batch])
Storage Tiering
| Tier | Data | Storage | Cost |
|---|---|---|---|
| Hot (0-30 days) | Recent URLs + active cache | NVMe SSD + Redis | $$$ |
| Warm (30 days - 1 year) | Most URLs | SSD | $$ |
| Cold (1-5 years) | Dormant, rarely accessed | HDD or S3 | $ |
| Archive (5+ years) | Historical records | S3 Glacier | ¢ |
Key principle: Never delete a short code that might be embedded somewhere. Soft-delete, archive, and serve a "this link has expired" page instead of a 404.
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions without prescriptive solutions. They are designed for staff+ conversations where you demonstrate systems thinking, trade-off analysis, and strategic decision-making.
301 vs 302 Redirect Strategy
Context: Your URL shortener serves both external marketing campaigns and internal employee tools. Product and engineering teams need to understand redirect behavior implications for different use cases.
Discussion Points:
- When would you choose 301 (permanent redirect) vs 302 (temporary redirect) and why?
- For an internal application, why is 301 better? How does it reduce server load?
- What are the browser caching implications of 301 vs 302 for both user experience and analytics?
- How does redirect choice affect click tracking and analytics accuracy?
- What happens if you need to change the destination URL after using 301? How would you handle migration?
- What organizational processes ensure the right redirect type is chosen for each use case?
Multi-Region Deployment and Global Consistency
Context: A user in California creates a shortened URL. Seconds later, a user in Asia tries to access it. The URL returns 404. Your support team is flooded with complaints about "broken links."
Discussion Points:
- What is the replication latency across regions when a URL is created in one region and accessed from another?
- How long is the acceptable lead time before the URL is usable across the globe?
- How do you design for acceptable user experience during replication lag without compromising write latency?
- What trade-offs exist between strong consistency guarantees, eventual consistency, and write performance?
- When would you choose synchronous cross-region replication vs eventual consistency?
- How would you communicate these trade-offs to product and business stakeholders?
Service Health Monitoring and Failure Detection
Context: It's 3 AM. Your on-call phone rings. The URL shortener is "broken" but monitoring shows all green. How do you know what's actually wrong and where to look?
Discussion Points:
- What are all the ways this service can break down? (database failure, cache failure, ID generator failure, network partitions, DNS issues, region outages)
- How do you detect each type of failure before users report it? What metrics and alerts would you implement?
- What monitoring and alerting strategy distinguishes between partial failures vs complete outages?
- How do you measure the "health" of the service from the user's perspective vs internal systems?
- What's your incident response playbook for each major failure mode?
- How do you handle cascading failures across components (e.g., database slow → cache overload → API timeout)?
Malicious URL Detection and Prevention
Context: Security vendors have blocklisted your domain because phishing campaigns are using your URL shortener. Legitimate users can no longer share links. Revenue is dropping. The exec team wants answers.
Discussion Points:
- How would you detect and prevent malicious URLs from being created in the first place?
- What are the trade-offs between real-time URL scanning (adds latency to shortening) vs batch scanning (allows malicious URLs temporarily)?
- How do you handle false positives that block legitimate URLs? What's the user impact and support burden?
- What happens to existing malicious URLs that get reported after creation? How quickly can you take them down?
- How do you prevent your domain from being blocklisted by security vendors and email providers?
- What's the balance between security measures and user privacy (e.g., scanning destination content)?
Level Expectations
| Dimension | Mid-Level (L4) | Senior (L5) | Staff (L6) |
|---|---|---|---|
| ID Generation | Explain uniqueness and shortness requirements; suggest one valid approach | Compare hash vs UUID vs Snowflake vs Machine ID approaches with collision math | Design ID coordination across regions; handle clock skew, machine failures, and sequence recovery |
| Encoding Strategy | Explain Base62 encoding and calculate ID space (62⁶ ≈ 56B) | Discuss Base16/58/62/64 trade-offs; explain why special characters matter in URLs | Consider encoding implications for analytics, debugging, enumeration prevention, and URL patterns |
| Scaling Strategy | Understand sharding concept and why it enables horizontal scaling | Design shard key strategy using machine ID prefix; explain write path independence and read routing | Handle shard rebalancing, hot shards, consistent hashing alternatives, and capacity planning |
| Caching & Performance | Include cache layer in design; explain read-through pattern | Calculate cache hit ratios using Zipf distribution; design cache invalidation strategy | Design multi-tier caching; handle cache stampede, thundering herd, and stale-while-revalidate |
| Redirect Semantics | Know the difference between 301 and 302 | Trace impact on analytics, deactivation, and SEO; propose hybrid approach with Cache-Control | Design redirect policy per use case; handle migration from 301→302 without breaking cached redirects |
| Security | Mention rate limiting and input validation | Design pre-creation scanning, post-creation batch scanning, and enumeration prevention | Build comprehensive abuse prevention system; handle domain blocklisting, takedown processes, and organizational response |
Summary
Key Design Decisions
ID Generation: Machine ID + Sequence Number produces the shortest codes (6 characters) with guaranteed uniqueness and no runtime coordination. Alternative approaches (hash, UUID, Snowflake) either produce longer codes or require collision detection.
Encoding: Base62 (a-z, A-Z, 0-9) avoids URL-encoding issues from special characters while providing 56.8B capacity in just 6 characters — 30× our 5-year storage requirement.
Caching: Read-through + write-through hybrid achieves 90%+ cache hit rate. With Zipfian access distribution, 1 GB of Redis cache (~2M URLs) handles 93% of traffic, reducing database load to ~80 QPS.
Redirect Strategy: 302 (temporary) over 301 (permanent) preserves analytics accuracy and URL deactivation capability. Hybrid approach with Cache-Control: max-age=86400 balances server load with tracking needs.
Sharding: Machine ID prefix as shard key enables zero-coordination writes. Each server writes to its own shard. Read routing extracts the prefix from the short code. No rebalancing needed when adding shards.
Analytics: Two-tier counting (Redis INCR for real-time, periodic DB flush) provides sub-millisecond counting without impacting redirect latency. 60-second batch writes reduce DB load by 60×.
Architecture Principles Applied
| Principle | Application |
|---|---|
| Read-write separation | Cache absorbs 90%+ of reads; DB handles only writes and cache misses |
| Async over sync for non-critical paths | Analytics recording is fire-and-forget, never blocks redirects |
| Data locality via shard key | Machine ID prefix encodes the shard in the URL itself — no routing table needed |
| Defense in depth | Pre-creation scanning + post-creation scanning + rate limiting + deactivation |
| Evolve incrementally | Start with one server → shard when writes exceed one DB → multi-region for global latency |
Common Pitfalls to Avoid
| Pitfall | Why It Fails | Better Approach |
|---|---|---|
| Hash-based IDs with truncation | Birthday paradox: 50% collision probability after ~4K URLs (6 hex chars) | Machine ID + Sequence (guaranteed unique) |
| Base64 encoding | +, /, = break URLs and require encoding | Base62 (URL-safe, no special characters) |
| Direct DB increment for analytics | 1,160 write txn/sec to analytics table | Redis INCR + periodic batch flush |
| 301 redirect for all URLs | Breaks analytics and deactivation (browser caches forever) | 302 with Cache-Control for hybrid approach |
| Eager scaling (sharding day one) | Operational complexity before it's needed | Single server handles 12 writes/sec easily |