leetcode
Introduction
An online judge (like LeetCode, HackerRank, or Codeforces) is a platform where users browse a question bank of coding problems, write solutions in various programming languages, and receive instant feedback on correctness. The system compiles and executes user-submitted code against hidden test cases, then reports results — all within seconds.
Beyond problem solving, the platform hosts coding contests — timed competitions where thousands of participants race to solve problems. A real-time leaderboard ranks contestants by accuracy and speed, updating live as submissions are graded. After the contest ends, the leaderboard freezes into a permanent historical record.
The engineering challenges are distinct from typical web applications:
- Untrusted Code Execution — The system must compile and run arbitrary code submitted by users. A single malicious submission (infinite loop, fork bomb, filesystem access) could crash the server or compromise other users' data. Strong sandboxing and resource isolation are non-negotiable.
- Bursty Traffic — During contests, 10,000 users submit solutions simultaneously. Submission rates spike 50× at contest start and end. The system must absorb these bursts without dropping submissions or degrading latency.
- Real-Time Ranking — The leaderboard must reflect score changes within seconds. With hundreds of score updates per second during peak contest periods, a traditional SQL
ORDER BYquery can't keep up. The data structure choice determines whether ranking is O(n log n) per query or O(log n). - Async Result Delivery — Code execution takes 1-10 seconds. The user can't wait synchronously. The system needs an efficient pattern for asynchronous result delivery without maintaining thousands of persistent connections.
- Fairness Under Load — If User A submits 2 seconds before User B but User A's execution is delayed by a queue backlog, their ranking could be unfair. The system must ensure execution order respects submission order.
LLD Connection: This problem connects to the Queue Low-Level Design, where you implement the producer-consumer pattern that powers the code execution pipeline. It also connects to the Skip List implementation that underlies Redis sorted sets for the leaderboard.
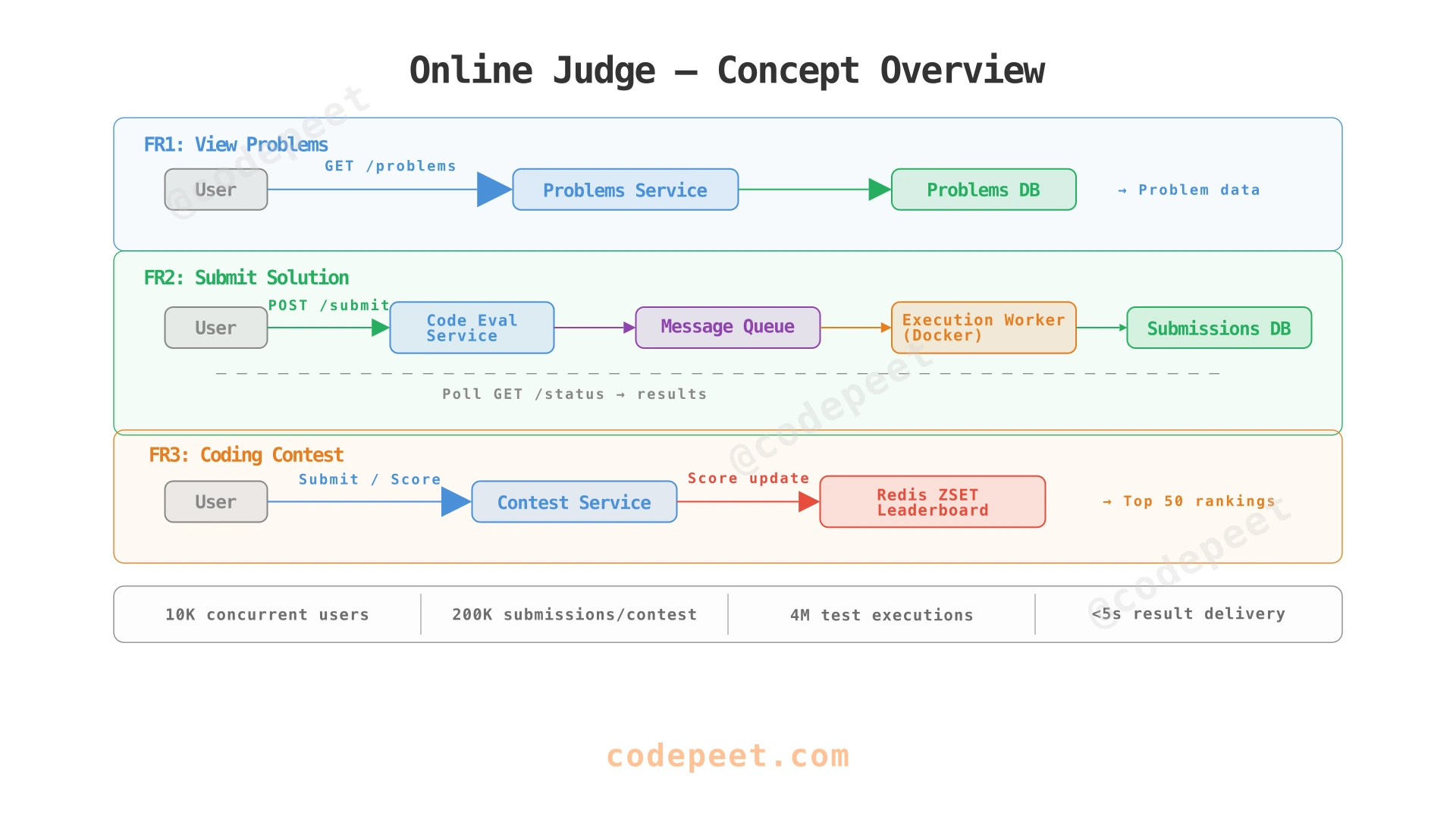
Functional Requirements
We extract the core operations by analyzing the verbs in the problem statement:
- "view" and "browse" (question bank) → READ operation
- "write, compile and submit code" + "get immediate feedback" → CREATE/READ operations
- "compete" + "ranked" + "real-time updates" → UPDATE/READ operations
Each verb maps to a functional requirement:
FR1 — View Problems. Users browse a catalogue of coding problems. Each problem displays a title, difficulty level, description, constraints, input/output examples, and starter code templates for multiple languages. The problem list supports filtering and pagination.
FR2 — Submit Solution. Users write code in a supported language, submit it, and receive feedback on correctness. The system executes the code against hidden test cases and reports: pass/fail per test case, execution time, memory usage, and overall verdict (Accepted, Wrong Answer, Time Limit Exceeded, Runtime Error, Compilation Error). User submissions are persisted for a minimum of 1 month for review and tracking.
FR3 — Coding Contest. Users participate in timed competitions (2 hours, 4 problems). Scoring uses a three-component model: points (harder problems = more points), time (earlier completion = better rank), and penalties (failed submissions add time). A real-time leaderboard displays the top 50 contestants, updating within seconds of each graded submission. After the contest ends, the leaderboard becomes a frozen historical view.
- Authentication / authorization — User identity management handled by separate auth service
- User management — Profile pages, settings, submission history browsing
- Contest history — Archived past contests and historical ranking trends
- Problem creation tools — Admin panel for authoring new problems and test cases
- Code syntax highlighting / IDE features — Editor capabilities handled by frontend
Scale Requirements
| Metric | Value |
|---|---|
| Concurrent contest users | 10,000 |
| Contest frequency | At most 1 per day |
| Contest duration | 2 hours |
| Avg submissions per user per contest | 20 |
| Total submissions per contest | 200,000 |
| Test cases per submission | ~20 |
| Total test case executions per contest | ~4,000,000 |
| Submission storage size | ~10 KB per submission |
| Retention policy | 1 month |
| Read:write ratio | 2:1 |
Non-Functional Requirements
We extract quality constraints from the adjectives in the problem statement:
- "thousands of people compete concurrently" → High concurrency and scalability
- "immediate feedback" + "real-time updates" → Low latency
- "persisted" (user submitted code) → Data durability
- Executing untrusted user code → Security and isolation
| Requirement | Target | Rationale |
|---|---|---|
| High Availability | 99.9% uptime | Platform must be accessible 24/7; contest downtime = PR disaster |
| High Scalability | 10K concurrent users, 200K submissions/contest | Contest traffic is 50× normal; must handle burst without degradation |
| Low Latency | Leaderboard updates within 2-3 seconds of submission grading | Users need real-time rankings to make strategic decisions during contest |
| Security | User code cannot affect server, other users, or access test cases | Executing untrusted code is the highest security risk in this system |
| Durability | Zero submission loss during contests | Losing a correct submission during a contest destroys user trust |
| Fairness | Submission order preserved in execution queue | Users who submit earlier must be graded first to ensure fair ranking |
Resource Estimation
Traffic Estimation
| Metric | Normal Day | Contest Day (2-hour window) |
|---|---|---|
| Problem views | ~100K/day | Same + contest problem views |
| Submissions | ~10K/day | 200K in 2 hours |
| Submission QPS (avg) | ~0.1/sec | ~28/sec |
| Submission QPS (peak, first 10 min) | — | ~83/sec (3× avg) |
| Test case executions | ~200K/day | 4M in 2 hours (~556/sec) |
| Leaderboard queries | — | ~10K users × 1 poll/5sec = 2,000/sec |
Storage Estimation
| Data | Size | Records | Retention | Total |
|---|---|---|---|---|
| Submissions | ~10 KB each | 200K/contest × 30 contests/month | 1 month | ~60 GB |
| Problems & test cases | ~50 KB per problem | ~3,000 problems | Permanent | ~150 MB |
| Leaderboard (Redis) | ~100 bytes per user | 10K per contest | Contest duration + archive | ~1 MB per contest |
| Contest results (archived) | ~1 KB per user | 10K per contest × 365 | Permanent | ~3.6 GB/year |
Compute Estimation
| Resource | Calculation | Result |
|---|---|---|
| Execution workers needed (peak) | 83 submissions/sec × 3 sec avg execution = 249 concurrent | ~250 workers |
| Execution workers (steady contest) | 28/sec × 3 sec = 84 concurrent | ~100 workers |
| Worker memory | 512 MB per container | 250 × 512 MB = 128 GB total |
| Worker CPU | 0.5 CPU per container | 250 × 0.5 = 125 vCPUs |
The system is compute-heavy during contests and nearly idle otherwise — a classic autoscaling use case. Pre-scaling before contests is essential since cold-start latency (spinning up containers) would delay the first wave of submissions.
Data Model
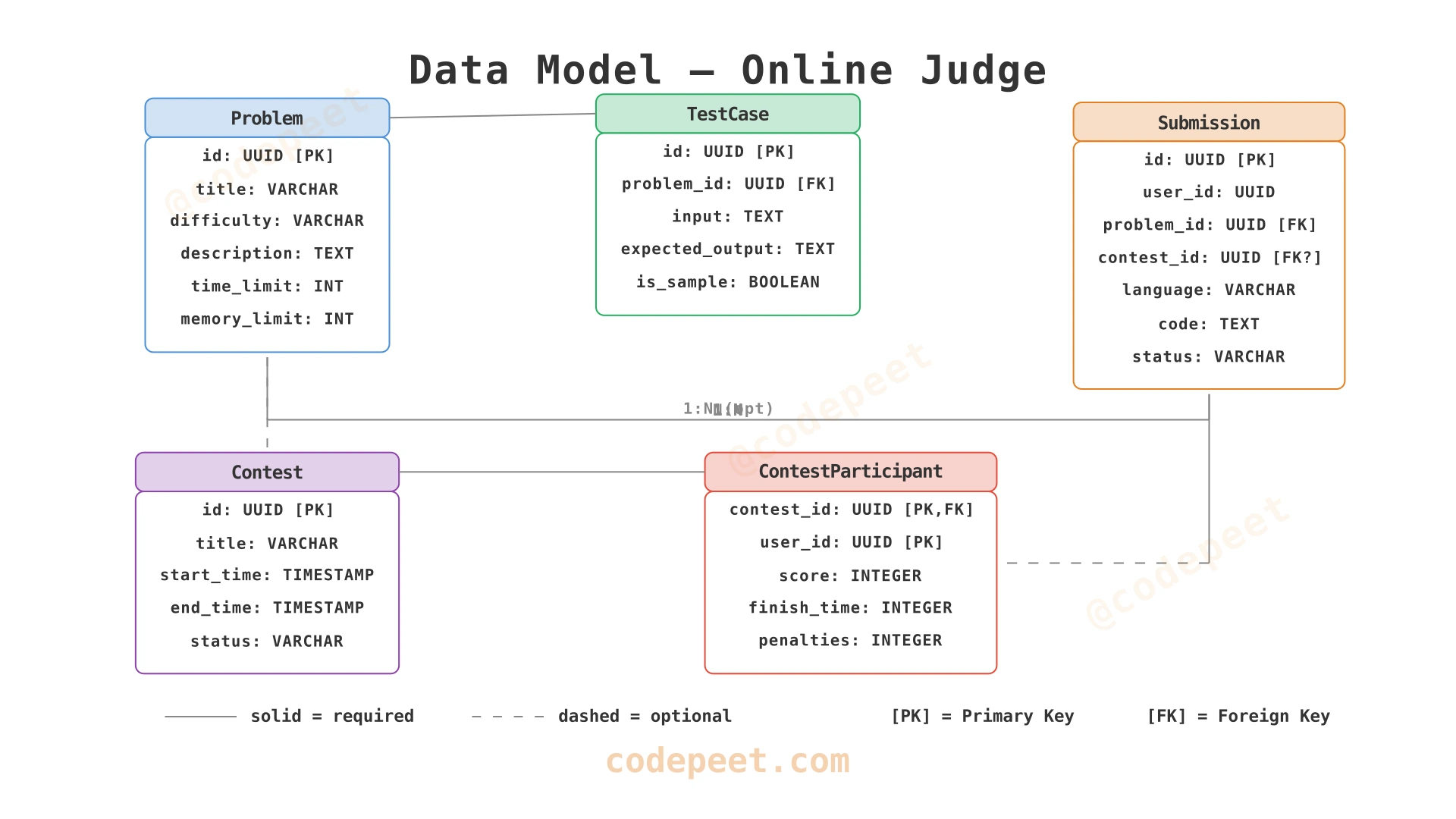
The data model emerges from the nouns in the problem statement:
- "question bank" with "description, examples, constraints" → Problem entity
- "test cases" → TestCase entity (linked to Problem)
- "submitted code" with "results" → Submission entity
- "contest" with "rankings" and "scores" → Contest + ContestParticipant entities
Each entity is owned by a service with different scaling and durability requirements.
Problems & Test Cases
CREATE TABLE problems (
id UUID PRIMARY KEY,
title VARCHAR(200) NOT NULL,
difficulty VARCHAR(10) CHECK (difficulty IN ('easy', 'medium', 'hard')),
description TEXT NOT NULL, -- Markdown with examples
constraints TEXT, -- Input constraints
time_limit INTEGER DEFAULT 1000, -- Milliseconds
memory_limit INTEGER DEFAULT 256, -- MB
created_at TIMESTAMP DEFAULT NOW()
);
CREATE TABLE test_cases (
id UUID PRIMARY KEY,
problem_id UUID REFERENCES problems(id),
input TEXT NOT NULL, -- Stored as raw text file content
expected_output TEXT NOT NULL, -- Stored as raw text file content
is_sample BOOLEAN DEFAULT FALSE, -- Visible to users in problem description
ordering INTEGER -- Execution order
);
CREATE TABLE starter_code (
problem_id UUID REFERENCES problems(id),
language VARCHAR(20) NOT NULL, -- python, java, cpp, javascript, etc.
code TEXT NOT NULL, -- Template with function signature
PRIMARY KEY (problem_id, language)
);Test cases are language-agnostic — stored as raw input/output text files. The execution worker reads test_case_1.in, runs the user's code with this input, captures stdout, and compares it character-by-character against test_case_1_expected_output.out. This means the same test cases work for Python, Java, C++, or any other supported language.
Submissions
CREATE TABLE submissions (
id UUID PRIMARY KEY,
user_id UUID NOT NULL,
problem_id UUID REFERENCES problems(id),
contest_id UUID REFERENCES contests(id), -- NULL if not a contest submission
language VARCHAR(20) NOT NULL,
code TEXT NOT NULL,
status VARCHAR(20) DEFAULT 'pending', -- pending, running, accepted, wrong_answer,
-- time_limit_exceeded, runtime_error, compile_error
passed_count INTEGER DEFAULT 0,
total_count INTEGER DEFAULT 0,
execution_time_ms INTEGER,
memory_used_mb INTEGER,
submitted_at TIMESTAMP DEFAULT NOW(),
graded_at TIMESTAMP
);
CREATE INDEX idx_submissions_user ON submissions(user_id, submitted_at DESC);
CREATE INDEX idx_submissions_contest ON submissions(contest_id, user_id);Submissions have a 1-month retention policy. A background job runs daily to delete submissions older than 30 days. Contest submissions may be retained longer for dispute resolution.
Contests
CREATE TABLE contests (
id UUID PRIMARY KEY,
title VARCHAR(200) NOT NULL,
start_time TIMESTAMP NOT NULL,
end_time TIMESTAMP NOT NULL,
status VARCHAR(20) DEFAULT 'upcoming', -- upcoming, active, grading, finished
created_at TIMESTAMP DEFAULT NOW()
);
CREATE TABLE contest_problems (
contest_id UUID REFERENCES contests(id),
problem_id UUID REFERENCES problems(id),
points INTEGER NOT NULL, -- Score awarded for solving
ordering INTEGER NOT NULL, -- Display order (Problem A, B, C, D)
PRIMARY KEY (contest_id, problem_id)
);
CREATE TABLE contest_participants (
contest_id UUID REFERENCES contests(id),
user_id UUID NOT NULL,
score INTEGER DEFAULT 0,
finish_time INTEGER DEFAULT 0, -- Seconds from contest start
penalties INTEGER DEFAULT 0, -- Wrong submission count × 5 min
PRIMARY KEY (contest_id, user_id)
);
API Endpoints
We derive API endpoints directly from the functional requirements:
- READ → Browse and view problems
- CREATE/READ → Submit code and poll for results
- READ → Fetch contest leaderboard
Problem Browsing
GET /problems?start={start}&end={end}
Response:
{
"problems": [
{ "id": "abc123", "title": "Two Sum", "difficulty": "easy" }
],
"total": 3000,
"page": 1,
"pageSize": 20
}
GET /problems/:problem_id
Response:
{
"id": "abc123",
"title": "Two Sum",
"difficulty": "easy",
"description": "Given an array of integers nums...",
"constraints": "2 <= nums.length <= 10^4",
"examples": [
{ "input": "nums = [2,7,11,15], target = 9", "output": "[0,1]" }
],
"starterCode": {
"python": "class Solution:\n def twoSum(self, nums, target):",
"java": "class Solution {\n public int[] twoSum(int[] nums, int target) {"
}
}
Code Submission
POST /problems/:problem_id/submission
Request:
{
"userId": "user123",
"code": "class Solution:\n def twoSum(self, nums, target):\n ...",
"language": "python"
}
Response (202 Accepted):
{
"submissionId": "sub456",
"status": "pending"
}
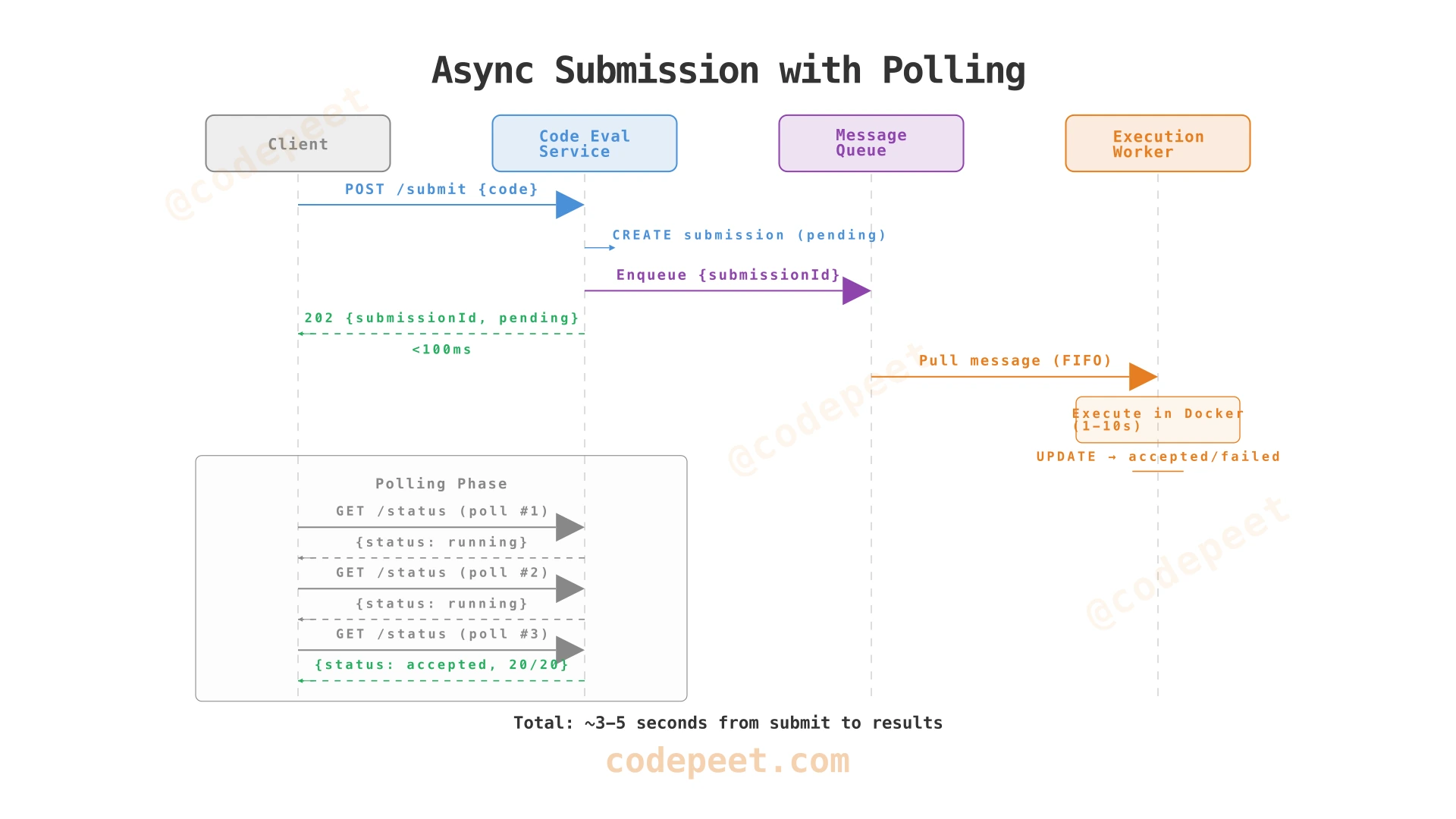
The 202 Accepted status indicates the submission was received and queued but not yet processed. The client must poll for results.
Poll Submission Status
GET /submissions/:submission_id/status
Response (while running):
{ "submissionId": "sub456", "status": "running" }
Response (when complete):
{
"submissionId": "sub456",
"status": "accepted",
"testCases": [
{ "id": 1, "status": "passed", "executionTimeMs": 12, "memoryMb": 8 },
{ "id": 2, "status": "passed", "executionTimeMs": 15, "memoryMb": 9 }
],
"totalPassed": 20,
"totalCases": 20,
"executionTimeMs": 45,
"memoryUsedMb": 12
}
Contest Leaderboard
GET /contests/:contest_id/leaderboard
Response:
{
"contestId": "contest789",
"rankings": [
{ "rank": 1, "userId": "user42", "score": 1500, "finishTime": "45:23", "solved": 3 },
{ "rank": 2, "userId": "user17", "score": 1500, "finishTime": "52:10", "solved": 3 }
],
"totalParticipants": 10000,
"lastUpdated": "2026-03-17T15:30:00Z"
}
| Status Code | Meaning |
|---|---|
200 OK | Successful retrieval |
202 Accepted | Submission queued for processing |
400 Bad Request | Invalid code or unsupported language |
404 Not Found | Problem, submission, or contest doesn't exist |
429 Too Many Requests | Rate limit exceeded (anti-spam during contests) |
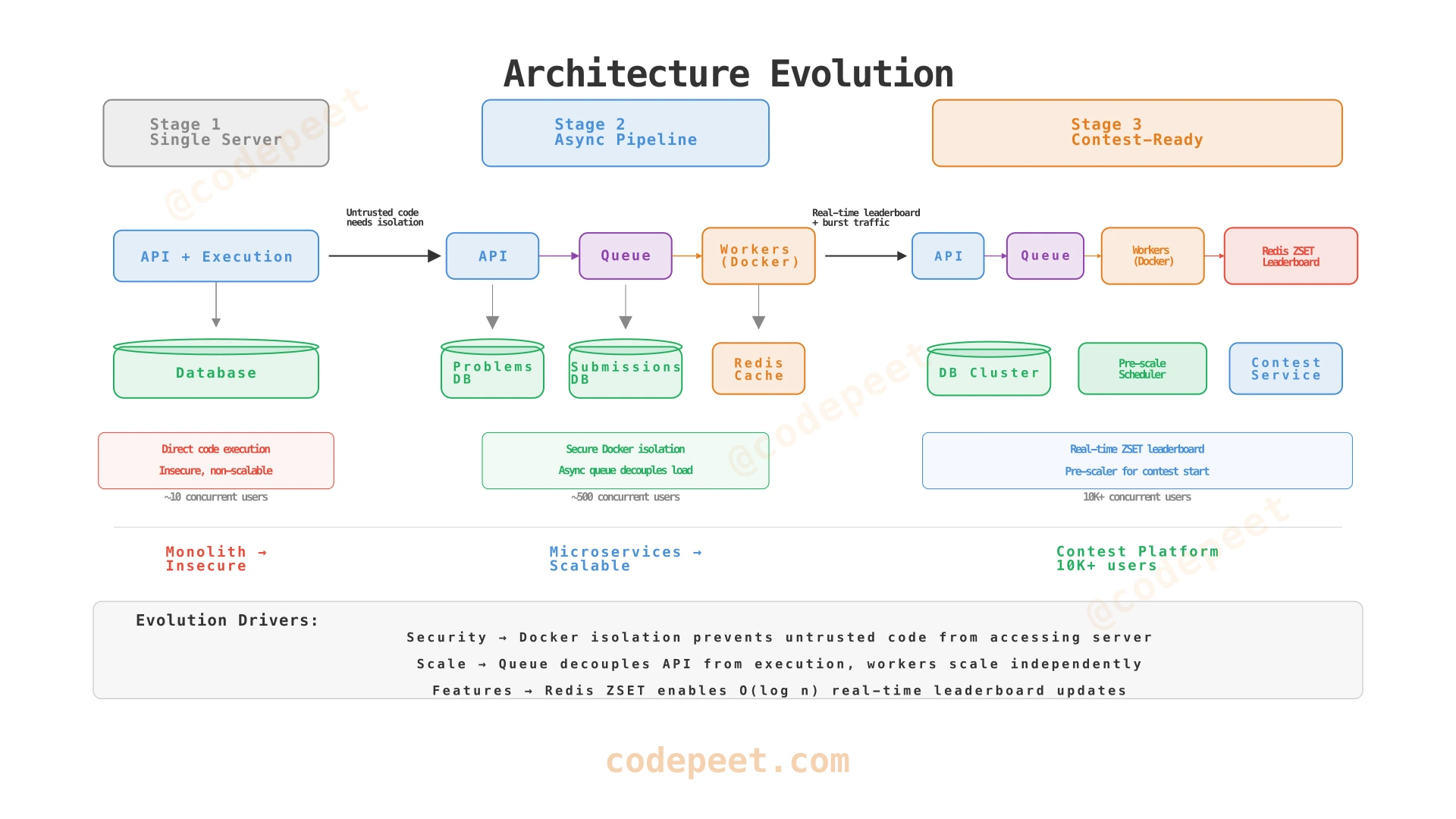
High Level Design
We build the architecture incrementally, adding components as each functional requirement demands them. Each step introduces exactly the components needed to solve a real problem — no premature abstraction.
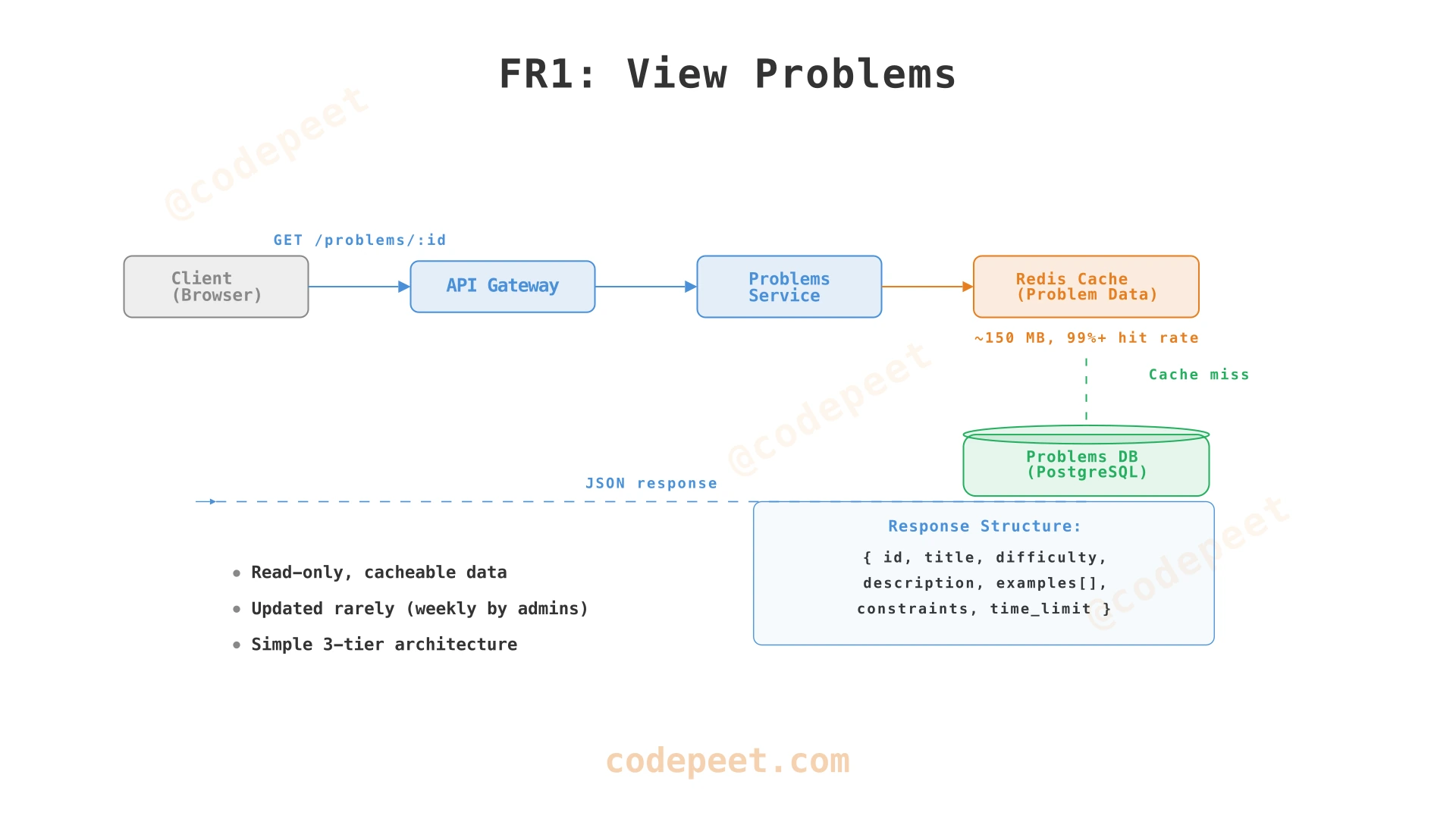
1. View Problems (FR1)
Requirement: Users browse a catalogue of problems with descriptions, examples, constraints, and starter code.
This follows a standard three-tier architecture. The Problems Service exposes two endpoints:
GET /problems?start={start}&end={end}— paginated problem listGET /problems/:problem_id— full problem details including test case samples
The problem data (3,000 problems × ~50 KB each = ~150 MB) easily fits in memory. A Redis cache in front of the database serves problem data with sub-millisecond latency. Cache invalidation is simple because problems are updated rarely (new problems added ~weekly by admins).
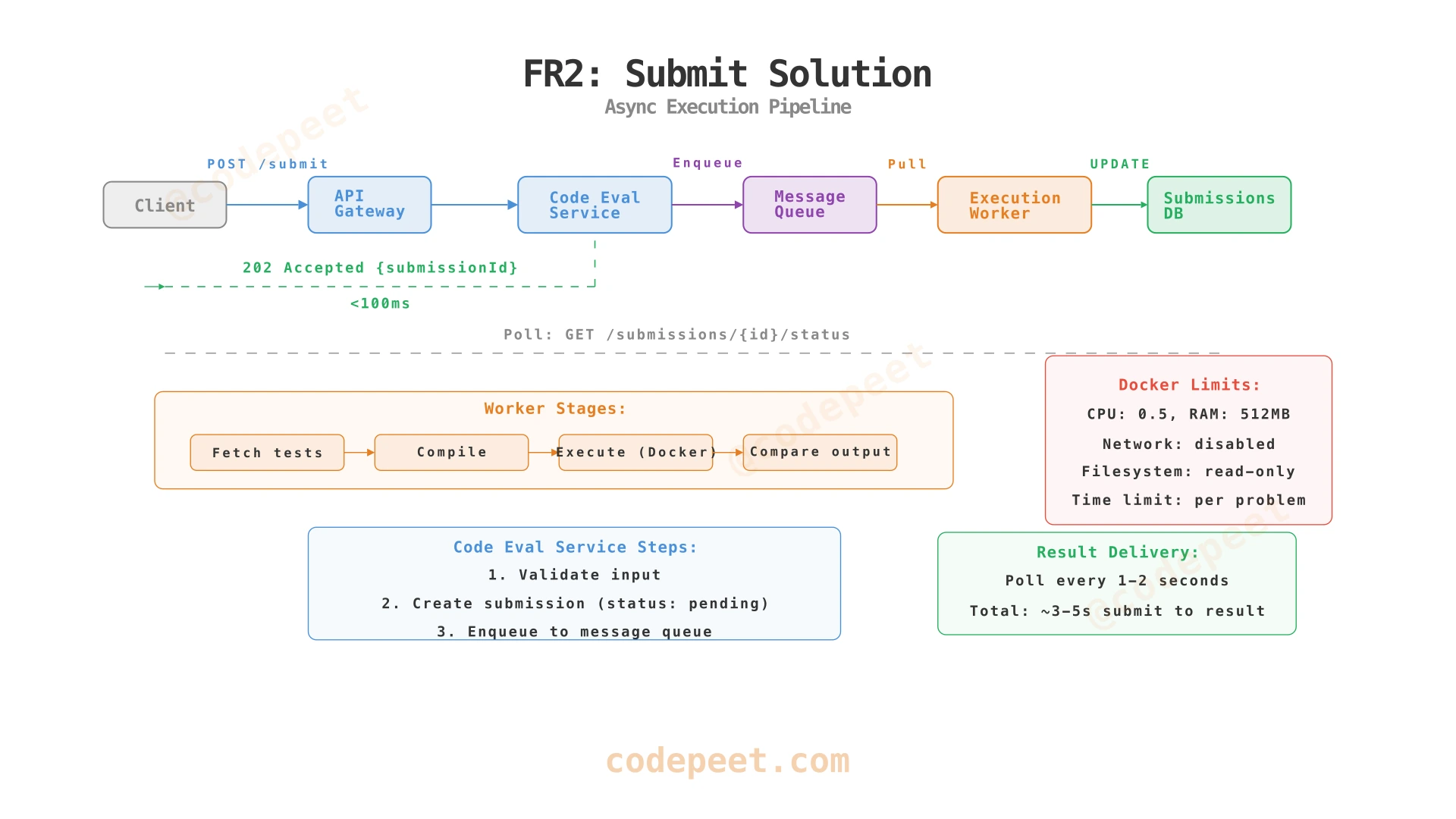
2. Submit Solution (FR2)
Requirement: Users submit code and receive feedback on correctness within seconds.
This is where the architecture gets interesting. We can't execute user code on the API server — a single malicious submission could crash the entire service. We need separation of concerns:
- Code Evaluation Service — Receives submissions, validates input, and enqueues work
- Message Queue — Buffers submissions to handle burst traffic
- Code Execution Workers — Run untrusted code in sandboxed Docker containers
Why three components? Each has a different traffic pattern and scaling profile:
| Component | Traffic Pattern | Scaling Need |
|---|---|---|
| Code Evaluation Service | Spiky (contest start/end) but lightweight (just enqueue) | Moderate (handles HTTP fast) |
| Message Queue | Absorbs bursts, smooths output rate | Fixed (SQS/Kafka auto-scales) |
| Code Execution Workers | CPU-intensive, 3-sec avg per execution | Heavy (250 workers at peak) |
Why Polling Over WebSockets?
The user submits code. Execution takes 1-10 seconds. How does the user get results?
| Approach | How It Works | Pros | Cons |
|---|---|---|---|
| Long polling | Client sends request, server holds until result ready | Simple, works everywhere | Ties up server connections |
| WebSockets | Persistent bidirectional connection | Real-time, efficient | 10K concurrent connections = memory pressure |
| Server-Sent Events | Persistent one-way connection (server→client) | Simpler than WebSocket | Still 10K persistent connections |
| Short polling | Client polls every 1-2s | Stateless, no persistent connections | Slightly delayed results |
Short polling wins for this use case. With a typical 3-second execution time, the client polls 2-3 times before getting results. The "wasted" polls are trivially cheap — simple database reads that hit a cached submission status. Meanwhile, the server holds zero persistent connections.
This is how LeetCode works in production — you can verify by watching Chrome DevTools during a submission. You'll see repeated GET /submission/{id}/status requests every 1-2 seconds.
3. Coding Contest (FR3)
Requirement: Real-time leaderboard showing top 50 contestants, updated within seconds of each graded submission.
The submission infrastructure already works. The new challenge is the leaderboard — a sorted ranking that updates on every score change.
Why Not SQL for the Leaderboard?
SELECT user_id, score FROM contest_participants
ORDER BY score DESC, finish_time ASC
LIMIT 50;
This query scans and sorts the entire table. With 10,000 participants and hundreds of score changes per second, the ORDER BY constantly invalidates indexes. PostgreSQL would need to re-sort on every query — O(n log n) per request at 2,000 leaderboard polls/sec.
Redis Sorted Sets (ZSET)
Redis ZSET maintains elements sorted by score using a skip list internally. Operations:
ZADD(insert/update score) → O(log n)ZREVRANGE(top N by score) → O(log n + N)
With 10,000 participants, log₂(10,000) ≈ 13 — both updates and queries touch ~13 skip list nodes. This is orders of magnitude faster than SQL sorting.
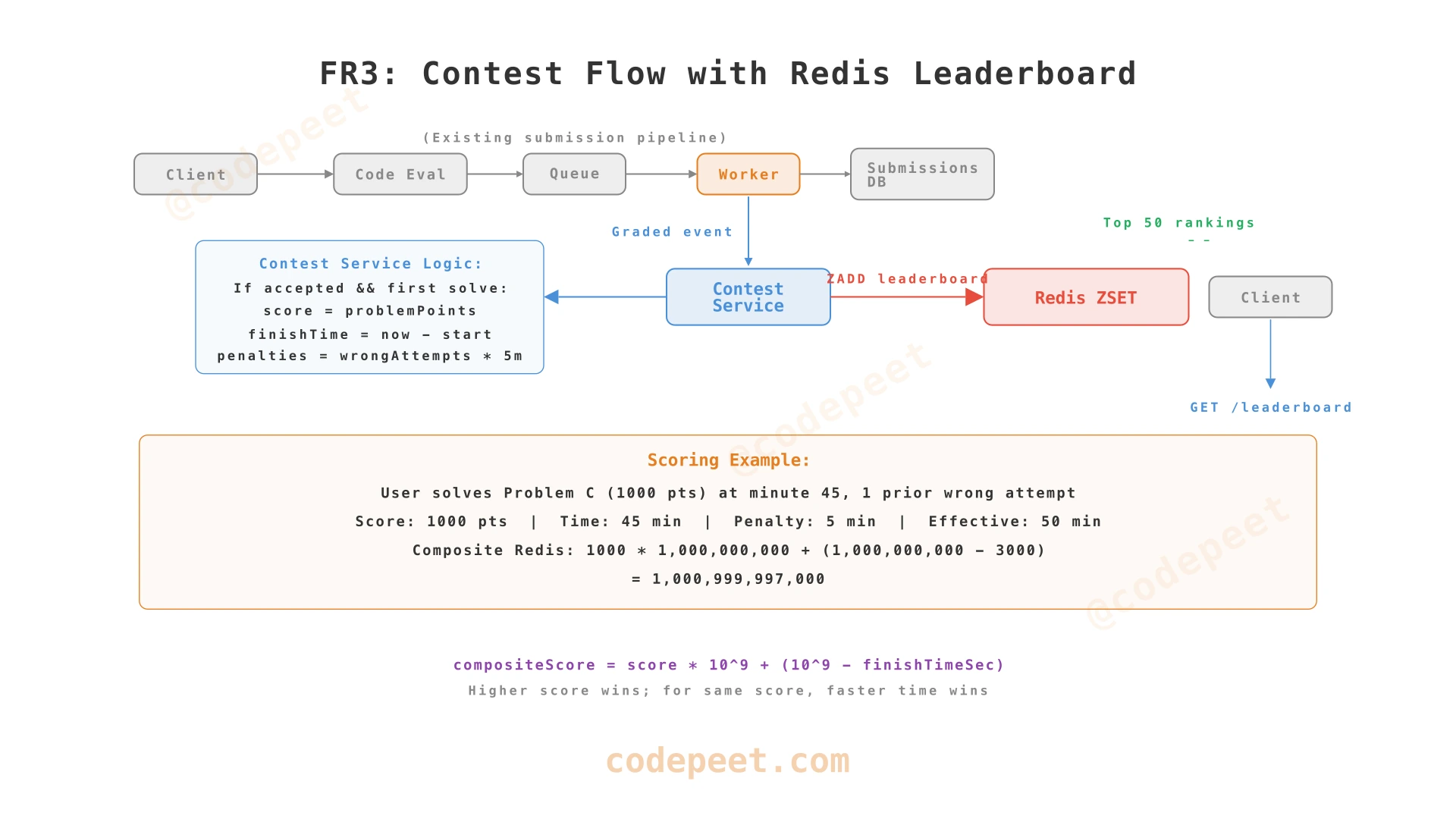
Score Composition
The leaderboard must rank by points first (primary) and time second (tie-breaker). But Redis ZSET only supports a single numeric score per member. We pack both values into one number:
compositeScore = (points × 1,000,000,000) + (1,000,000,000 - finishTimeInSeconds)
Why this works: Points occupy the billions place. Time (inverted so faster = higher) occupies everything below. They never overlap because finishTimeInSeconds for a 2-hour contest is at most 7,200 — far below 1 billion.
Example:
| User | Problems Solved | Points | Finish Time | Composite Score |
|---|---|---|---|---|
| Alice | 3 problems | 3500 | 45 min (2700s) | 3,500,999,997,300 |
| Bob | 3 problems | 3500 | 52 min (3120s) | 3,500,999,996,880 |
| Carol | 2 problems | 1500 | 30 min (1800s) | 1,500,999,998,200 |
Redis ranks: Alice > Bob > Carol. Alice beats Bob despite equal points because she finished faster (higher inverted time component).
4. Complete Architecture
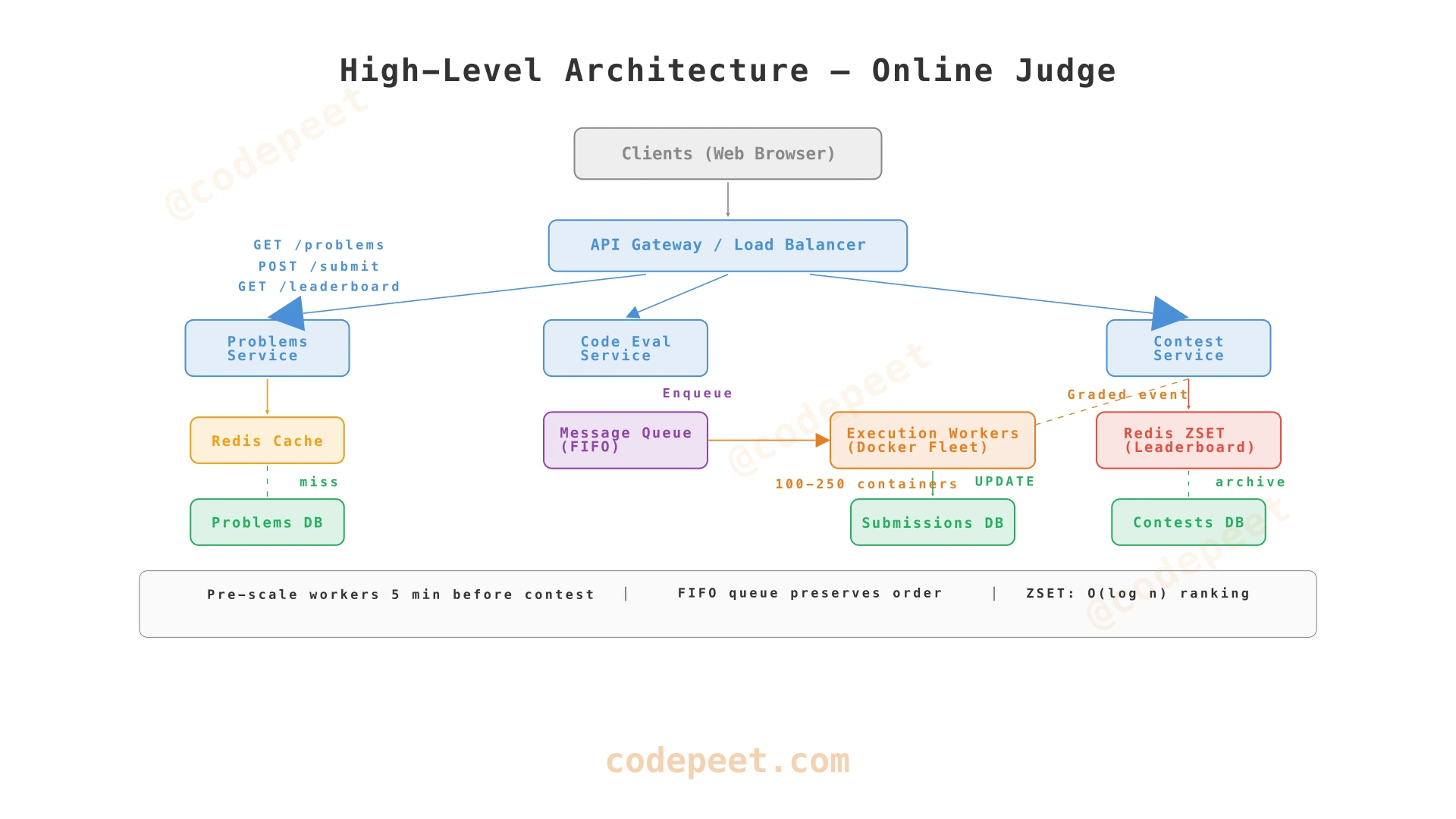
Service Ownership and Scaling
| Service | Owns | Scaling Profile | Database |
|---|---|---|---|
| Problems Service | Problem catalogue, test cases, starter code | Stable (~150 MB cached, rarely changes) | PostgreSQL + Redis cache |
| Code Evaluation Service | Submission intake, status tracking | HTTP-bound (handles enqueue fast) | PostgreSQL (submissions table) |
| Execution Workers | Code compilation and execution | CPU/memory-bound, scales 1:1 with submissions | None (stateless, reads test cases from Problems DB) |
| Contest Service | Scoring, leaderboard, contest lifecycle | Event-driven (triggered by graded submissions) | Redis ZSET + PostgreSQL (archived results) |
Key architecture property: The submission pipeline is fully asynchronous. The Code Evaluation Service responds in < 100 ms (just enqueues). The Worker processes seconds later. The Client polls for results. No component blocks on another.
Deep Dive Questions
How does the Code Evaluation Service decide if a submission is correct?
This question tests whether you can move beyond box-drawing into concrete implementation. The key insight: test cases must be language-agnostic so we don't maintain separate test suites for Python, Java, C++, etc.
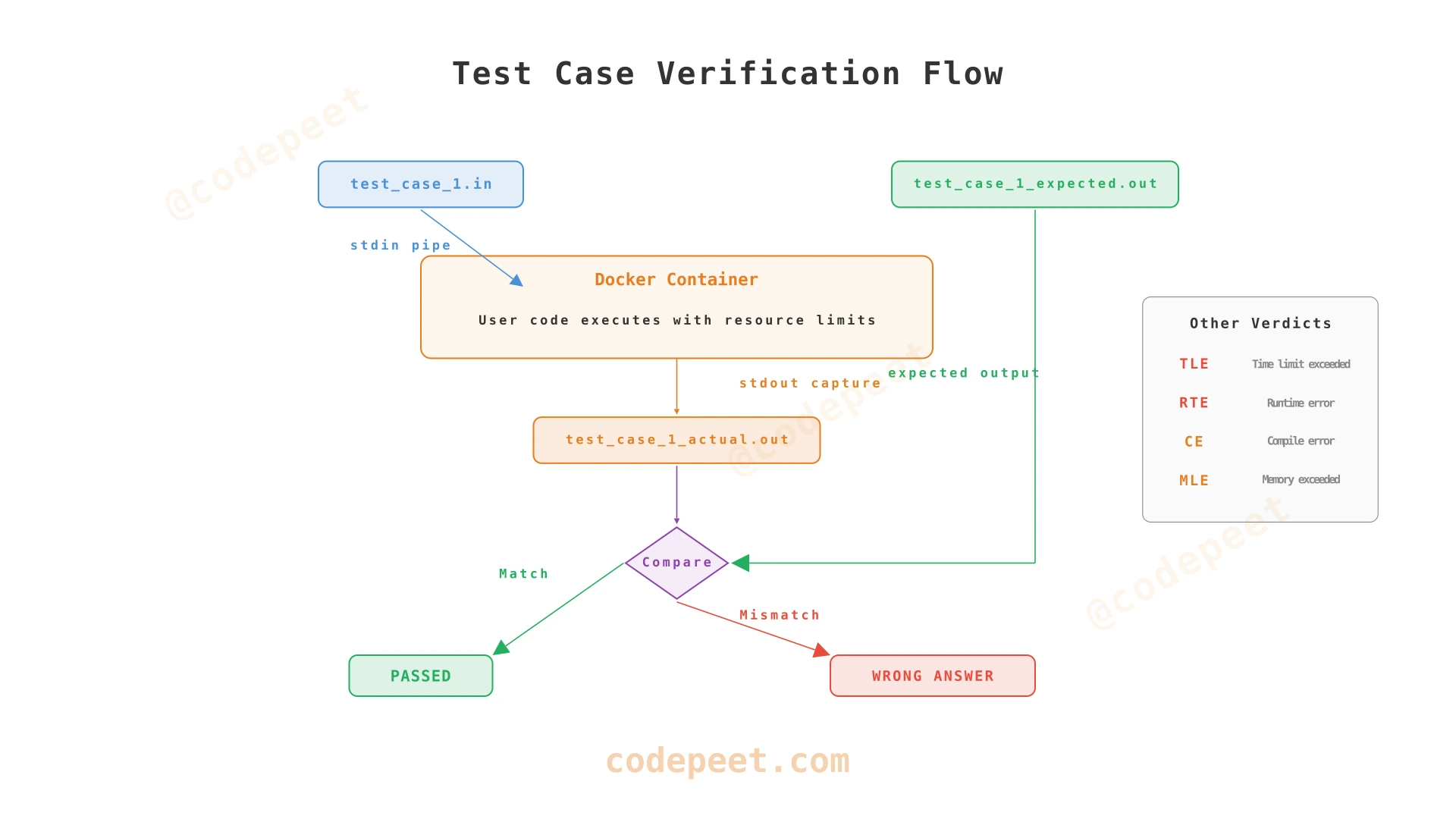
The Verification Flow
Consider a simple problem: "Add two numbers."
Step 1 — Input file: test_case_1.in
2 3
Step 2 — Expected output file: test_case_1_expected.out
5
**Step 3 — User submits code (Python):
def add(a, b):
return a + b
# Read input from stdin
a, b = map(int, input().split())
print(add(a, b))Step 4 — Execution:
The worker runs the user's code with test_case_1.in piped to stdin. The program writes to stdout, which the worker captures as test_case_1_actual.out.
Step 5 — Comparison:
The worker compares test_case_1_actual.out with test_case_1_expected.out character-by-character. If they match, the test case passes.
Step 6 — Verdict determination:
def grade_submission(submission_id: str, problem_id: str, code: str, language: str):
test_cases = db.get_test_cases(problem_id)
problem = db.get_problem(problem_id)
results = []
for tc in test_cases:
result = execute_in_container(
code=code,
language=language,
stdin_input=tc.input,
time_limit_ms=problem.time_limit,
memory_limit_mb=problem.memory_limit,
)
if result.timed_out:
results.append({"status": "time_limit_exceeded"})
elif result.runtime_error:
results.append({"status": "runtime_error", "error": result.stderr})
elif result.compile_error:
results.append({"status": "compile_error", "error": result.stderr})
elif result.stdout.strip() == tc.expected_output.strip():
results.append({"status": "passed"})
else:
results.append({"status": "wrong_answer"})
passed = sum(1 for r in results if r["status"] == "passed")
overall = "accepted" if passed == len(results) else results[-1]["status"]
db.update_submission(submission_id, status=overall, passed=passed, total=len(results))The submission gets one overall verdict based on the first failing test case: if test case 5 gives Wrong Answer, the overall verdict is Wrong Answer — even if test cases 6-20 would pass. This matches LeetCode's behavior and provides useful debugging information (the user knows which test case failed first).
What about the comparison? Exact string matching with strip() handles trailing whitespace/newlines. Some judges implement more lenient comparison (ignore trailing spaces per line, allow floating-point tolerance) but exact match is the standard approach.
How do we ensure security and isolation when executing untrusted code?
Running untrusted code is the highest security risk in this system. A user could submit code that:
- Infinite loops — consumes CPU indefinitely
- Fork bombs — spawns processes until the system crashes
- Memory bombs — allocates memory until OOM
- Filesystem access — reads test case answers or other users' code
- Network access — exfiltrates data or launches attacks from your servers
- System calls — escapes the sandbox
Defense in Depth: Six Isolation Layers
Layer 1: Container isolation. Each submission runs in a fresh Docker container. Containers use Linux namespaces (PID, network, mount, user) to isolate processes. The container's filesystem snapshot is discarded after execution.
Layer 2: Resource limits. Docker's --cpus, --memory, and --pids-limit flags enforce hard ceilings:
docker run --cpus="0.5" --memory="512m" --memory-swap="512m" --pids-limit=50 --cap-drop=ALL --network=none --read-only --tmpfs /tmp:size=50m --security-opt=no-new-privileges --ulimit nproc=50:50 --ulimit fsize=10485760 sandbox-image timeout 10 python3 /submission/solution.py < /submission/input.txt| Flag | Protection |
|---|---|
--cpus="0.5" | Max 50% of one CPU core — prevents CPU hogging |
--memory="512m" | Hard memory limit — OOM-killed if exceeded |
--pids-limit=50 | Max 50 processes — prevents fork bombs |
--cap-drop=ALL | Drops all Linux capabilities (no raw sockets, no ptrace, etc.) |
--network=none | Zero network access — can't exfiltrate data or attack other servers |
--read-only | Root filesystem is read-only — can't modify container |
--tmpfs /tmp:size=50m | Writable temp space capped at 50 MB |
timeout 10 | Hard wall-clock kill after 10 seconds |
Layer 3: System call filtering (seccomp). Even inside a container, some system calls are dangerous (mount, ptrace, reboot). A seccomp profile whitelists only the ~40 syscalls needed for code execution (read, write, mmap, etc.) and blocks everything else.
Layer 4: User namespace. Run the code as a non-root user inside the container. Even if an attacker exploits a container escape vulnerability, they land in an unprivileged user space on the host.
Layer 5: Ephemeral containers. Each submission gets a fresh container from a pre-built image. After execution, the container is destroyed. There is no persistent state between submissions — nothing to exfiltrate from a previous user's run.
Layer 6: Worker isolation. Execution workers run on dedicated hosts separated from the API servers, databases, and internal services. Even a catastrophic container escape only compromises the worker host, not the production database or user data.
Standard Docker containers share the host Linux kernel. A kernel exploit (e.g., dirty COW) could escape the container. gVisor runs a userspace kernel that intercepts system calls, providing VM-like isolation with container-like performance:
| Isolation Level | Startup Time | Runtime Overhead | Security |
|---|---|---|---|
| Docker (standard) | ~100 ms | ~0% | Kernel shared with host |
| Docker + gVisor | ~200 ms | ~5-15% | Userspace kernel intercepts syscalls |
| Full VM (KVM) | ~1-5 sec | ~2-5% | Complete hardware virtualization |
For a coding judge, gVisor's 200 ms startup and 5-15% runtime overhead is acceptable. It closes the kernel-sharing attack surface that is Docker's main weakness for untrusted code.
Google uses gVisor internally for running untrusted code in GCP products like Cloud Run and Cloud Functions.
How do we implement a real-time leaderboard with O(log n) operations?
The leaderboard must handle two operations at high frequency during contests:
- Update score — happens on every graded submission (~28/sec average, 83/sec peak)
- Query top 50 — happens on every leaderboard poll (~2,000/sec)
Data Structure Options
| Option | Update | Top-N Query | Persistence | Concurrency |
|---|---|---|---|---|
SQL ORDER BY | O(1) insert, O(n log n) sort on query | O(n log n) + O(N) | Built-in | Good (transactions) |
| In-memory heap | O(log n) | O(N log n) to extract top N | Manual | Poor (locks) |
| Redis Sorted Set | O(log n) | O(log n + N) | Redis persistence | Excellent (single-threaded) |
Redis Sorted Set wins because:
- Both updates AND queries are O(log n) — no other option matches this
- Contest data is temporary (2 hours) — in-memory storage is ideal
- Redis is single-threaded, so concurrent ZADD/ZREVRANGE operations are serialized without application-level locking
Redis ZSET Commands
# Add/update a user's score
ZADD contest:123 3500999997300 "user:alice"
# Get top 50 (highest scores first)
ZREVRANGE contest:123 0 49 WITHSCORES
# Get a specific user's rank (0-indexed)
ZREVRANK contest:123 "user:alice"
# Get total participants
ZCARD contest:123Skip List Internals
Under the hood, Redis ZSET uses a skip list — a probabilistic data structure that maintains sorted order with O(log n) operations. Unlike balanced BSTs which require complex rotations, skip lists achieve balance through randomization.
A skip list is a hierarchy of linked lists. The bottom list (Level 0) contains all elements. Each higher level contains a random subset (~50%) of the level below. To search, you start at the top level, walk forward until you overshoot, then drop down a level. This is analogous to binary search but on linked lists.
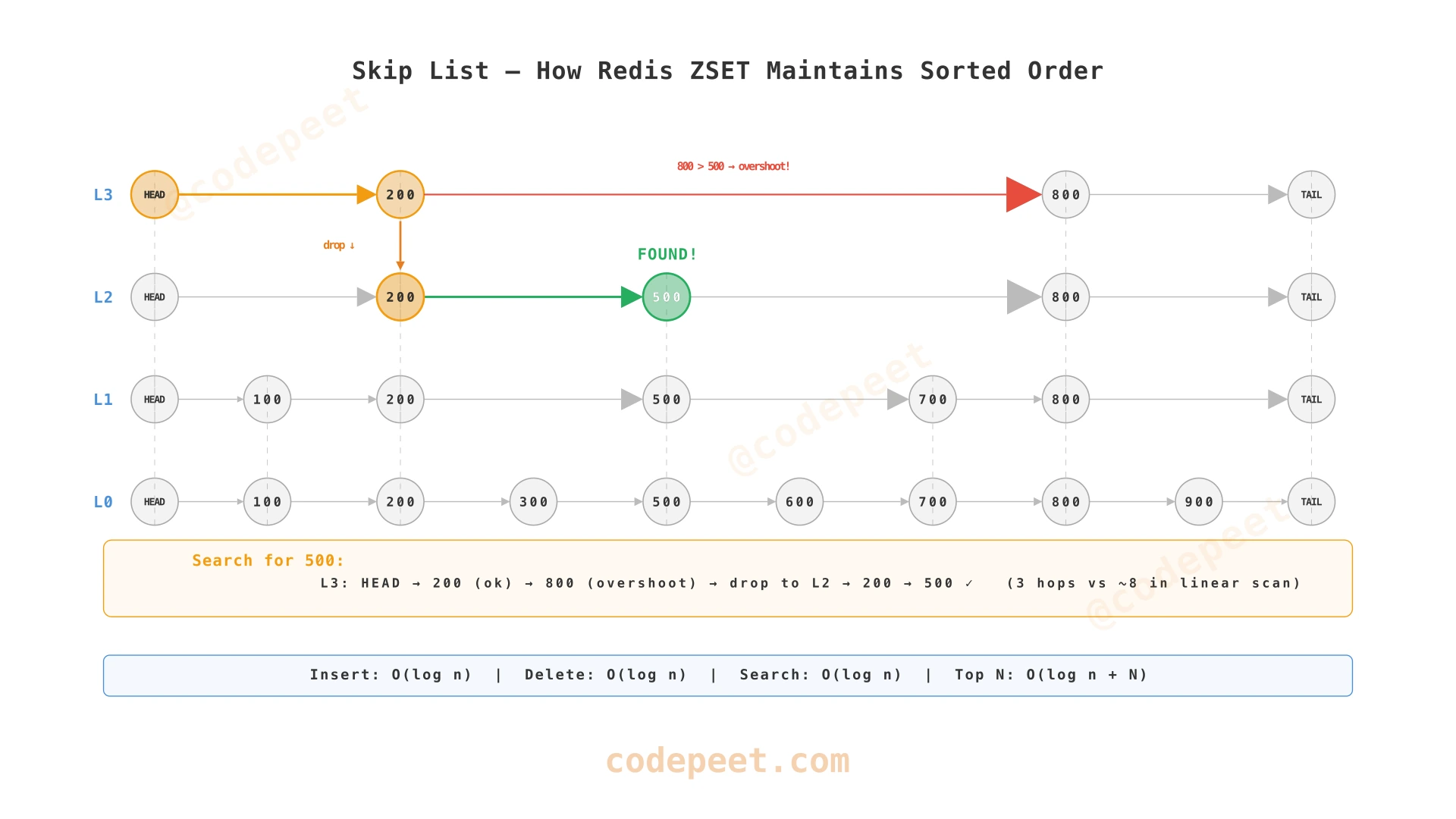
To get the top 50 for the leaderboard, Redis:
- Navigates to the end of the skip list (highest score) — O(log n)
- Walks backward through Level 0 for 50 elements — O(50)
- Total: O(log 10,000 + 50) ≈ O(63) — trivially fast
This is why Redis ZSET is the industry standard for real-time leaderboards.
PostgreSQL can create a B-tree index on (score DESC, finish_time ASC). With this index, SELECT ... ORDER BY score DESC LIMIT 50 uses an index scan — no table sort needed.
The problem is write amplification. Every score update modifies the indexed column, which requires:
- Update the row in the heap
- Insert a new entry in the B-tree index
- Mark the old index entry as dead
- Vacuum later to reclaim space
At 83 updates/sec during peak, the index is constantly being modified. B-tree page splits fragment the index. VACUUM can't keep up during contests, causing index bloat.
Redis ZSET avoids this because:
- Skip list updates are in-place (no page splits)
- No WAL overhead (unless AOF is enabled)
- No VACUUM needed
- Single-threaded means no locking overhead
For a read-heavy, frequently-updated sorted dataset with a known short lifetime, Redis ZSET dominates PostgreSQL indexes.
How are contest scores calculated and stored as a single Redis score?
A fair ranking system answers three questions: Who solved harder problems? (points), Who solved them faster? (time), and Who made fewer mistakes? (penalties). These three factors must collapse into a single Redis ZSET score that preserves correct ranking order.
Scoring Model
| Component | Formula | Purpose |
|---|---|---|
| Points | Sum of solved problem values (e.g., Easy=500, Medium=1000, Hard=2000) | Primary ranking factor |
| Finish time | Time of last accepted submission minus contest start | Tie-breaker for equal points |
| Penalties | Wrong attempts × 5 minutes, added to finish time | Discourages blind guessing |
Example:
- User solves Problem A (500 pts) at minute 15 after 1 wrong attempt
- User solves Problem B (1000 pts) at minute 45 with no mistakes
- Total points: 1500
- Finish time: 45 minutes (last accepted submission)
- Penalty: 1 × 5 = 5 minutes
- Effective time: 50 minutes
Packing Two Values Into One Redis Score
Redis ZSET only accepts one numeric score per member. We need to encode points (primary) and effective time (secondary, lower is better) into a single number where higher is always better.
The Big Multiplier formula:
redis_score = (points × 1,000,000,000) + (1,000,000,000 - effectiveTimeInSeconds)
Points occupy the billions place. Inverted time occupies everything below. They never overlap because effective time for a 2-hour contest is at most ~10,000 seconds (7,200 + penalties) — far below 1 billion.
For small scoreboards where points are integers:
redis_score = points + 1 / (1 + effectiveTimeInSeconds)
User A (1500 pts, 3000s): 1500 + 1/3001 = 1500.000333...
User B (1500 pts, 2700s): 1500 + 1/2701 = 1500.000370...
User B ranks higher (faster time → larger decimal component).
Limitation: Redis uses 64-bit floats with ~15-17 significant digits. If points grow large (millions), the decimal portion rounds off, breaking the tie-breaker. The big multiplier approach avoids this by keeping everything as integers.
Use the underlying binary representation to separate points and time:
MAX_TIME = 0xFFFFFFFF # 32-bit max
redis_score = (points << 32) | (MAX_TIME - effective_time_seconds)
Points occupy the high 32 bits, inverted time the low 32 bits. No multiplier constant needed — the bit boundary guarantees separation.
Trade-off: Debugging is harder. A score like 6442450937856 requires bit-shifting to decode. Most teams prefer the big multiplier for readability.
import redis
r = redis.Redis()
MULTIPLIER = 1_000_000_000
def update_leaderboard(contest_id: str, user_id: str, points: int, effective_time_sec: int):
"""Update a user's score in the contest leaderboard."""
composite_score = (points * MULTIPLIER) + (MULTIPLIER - effective_time_sec)
r.zadd(f"contest:{contest_id}", {f"user:{user_id}": composite_score})
def get_top_n(contest_id: str, n: int = 50):
"""Get top N contestants with decoded scores."""
results = r.zrevrange(f"contest:{contest_id}", 0, n - 1, withscores=True)
rankings = []
for rank, (user_key, score) in enumerate(results, 1):
user_id = user_key.decode().split(":")[1]
points = int(score) // MULTIPLIER
effective_time = MULTIPLIER - (int(score) % MULTIPLIER)
rankings.append({
"rank": rank,
"userId": user_id,
"points": points,
"effectiveTimeSec": effective_time,
})
return rankings
def on_submission_graded(contest_id: str, user_id: str, problem_id: str, accepted: bool):
"""Called when a submission finishes grading."""
if not accepted:
# Increment wrong attempt counter
r.hincrby(f"contest:{contest_id}:penalties:{user_id}", problem_id, 1)
return
# Check if already solved (no double-counting)
if r.sismember(f"contest:{contest_id}:solved:{user_id}", problem_id):
return
# Mark as solved
r.sadd(f"contest:{contest_id}:solved:{user_id}", problem_id)
# Calculate score
problem_points = get_problem_points(contest_id, problem_id)
total_points = r.scard(f"contest:{contest_id}:solved:{user_id}") * problem_points # simplified
contest_start = get_contest_start(contest_id)
finish_time = int(time.time()) - contest_start
penalties = int(r.hget(f"contest:{contest_id}:penalties:{user_id}", problem_id) or 0) * 300
update_leaderboard(contest_id, user_id, total_points, finish_time + penalties)The on_submission_graded function is called by the Contest Service whenever a submission finishes execution. It handles deduplication (don't score a problem twice), penalty tracking, and composite score calculation — all using Redis data structures for atomic operations.
How do we handle 10,000 contestants submitting simultaneously?
At contest start, 10,000 developers click "Submit" within the first few minutes. That's 5,000+ submissions in the first minute — far beyond steady-state capacity. By the time auto-scaling detects the spike and provisions new workers, users are already waiting minutes for results. We need a comprehensive strategy.
Strategy 1: Pre-Scaling
We know exactly when contests start. Five minutes before start time, a scheduler provisions the full fleet of execution workers:
async def pre_scale_for_contest(contest_id: str):
"""Called 5 minutes before contest start by scheduler."""
contest = await db.get_contest(contest_id)
expected_participants = contest.registered_count # e.g., 10,000
# Calculate needed workers:
# Peak: 83 submissions/sec × 3 sec execution = 249 concurrent
# Plus 20% buffer
target_workers = int(expected_participants * 0.025 * 1.2)
await container_orchestrator.scale(
service="execution-workers",
replicas=target_workers,
timeout_sec=300, # Must be ready in 5 min
)
# Verify all workers are healthy
healthy = await container_orchestrator.health_check("execution-workers")
if healthy < target_workers * 0.9:
await alert_oncall(f"Only {healthy}/{target_workers} workers healthy before contest")Strategy 2: Message Queue as Buffer
The message queue absorbs the submission spike. Workers pull at their own pace:
| Minute | Submissions Received | Queue Depth | Workers Processing | User Wait Time |
|---|---|---|---|---|
| 0-1 | 5,000 | ~4,750 | 250 × 3sec = ~83/sec | ~60 sec (worst case) |
| 1-5 | 3,000 | ~2,000 (draining) | 250 | ~25 sec |
| 5-30 | 1,000/min | ~0 (steady state) | 250 | ~3-5 sec |
| 30-120 | 500/min | 0 | 250 (can scale down) | ~3 sec |
The first-minute spike creates a ~60 second worst-case wait. This is acceptable for most coding contests — users are still reading problems in the first minute.
Strategy 3: Two-Phase Processing
For extremely large contests (50K+ participants), even 250 workers may not be enough. Two-phase processing reduces computation by 90% during the contest:
Phase 1 (During Contest): Run submissions against only 10% of test cases (2 out of 20). Provide instant preliminary feedback: "Passed 2/2 sample cases." Users know immediately if their approach is correct.
Phase 2 (After Contest Deadline): Run all submissions against the full test case suite (20 cases). Determine official results with complete validation.
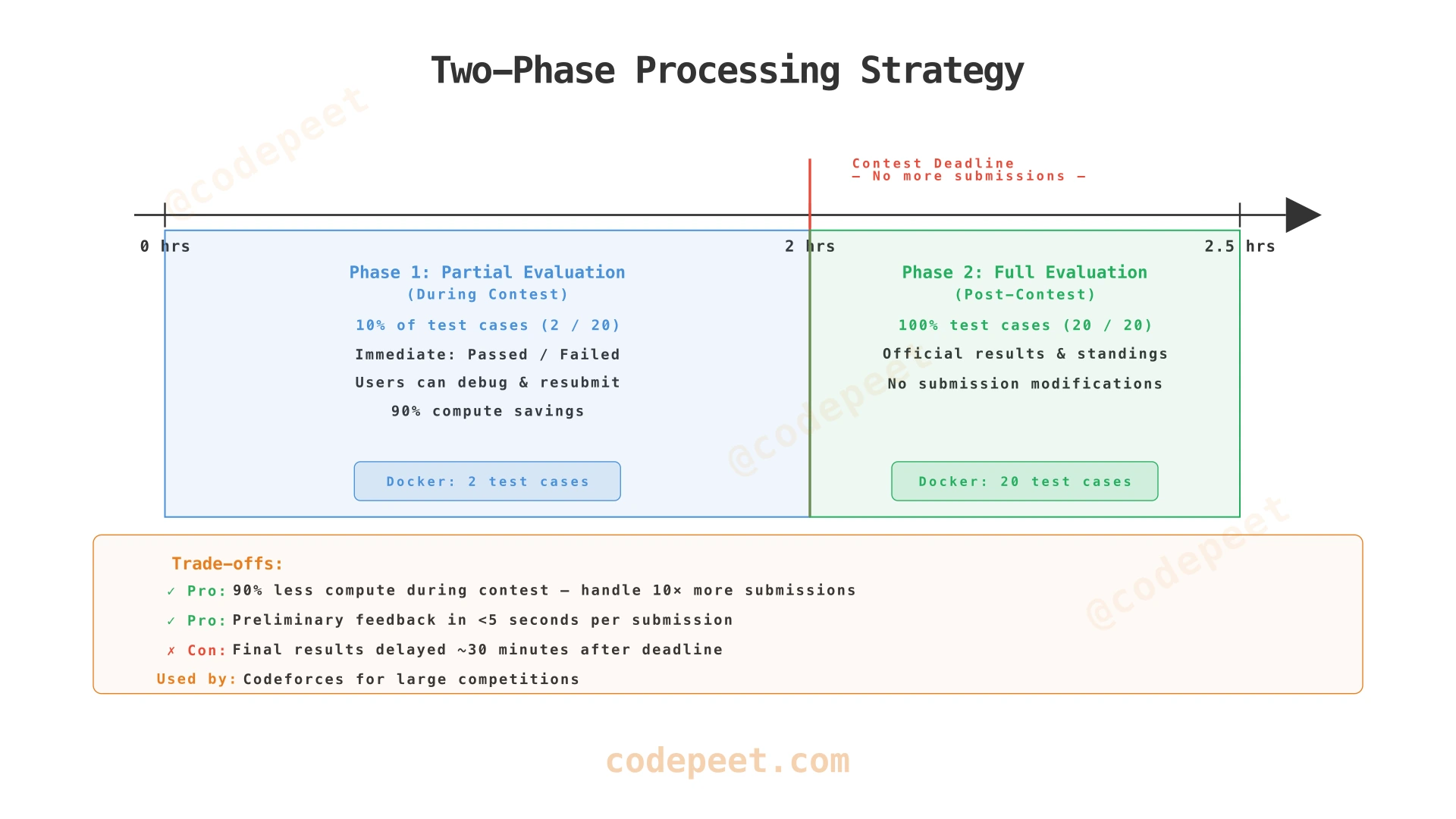
Why does this work? Users care most about instant feedback during the contest — they need to know if their approach is correct so they can debug and resubmit. Running 10% of test cases gives them that signal in seconds. Full validation after the deadline is fine because users can't change their code anyway.
This is a battle-tested approach. Codeforces uses two-phase processing (they call it "pretests" during the contest and "system tests" after) for contests with 10,000+ participants.
The message queue must be FIFO (first-in, first-out). If User A submits at 14:00:01 and User B submits at 14:00:02, User A must be graded first. Without FIFO guarantees, a queue reordering could grade User B first, giving them an unfair time advantage on the leaderboard.
AWS SQS FIFO queues guarantee exactly-once, in-order delivery. Kafka partitions maintain order within a partition — partition by user_id to ensure per-user fairness (though submissions from different users may be processed out of order across partitions, which is acceptable since they don't affect each other's scores).
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions without prescriptive solutions. They are designed for staff+ conversations where you demonstrate systems thinking, trade-off analysis, and strategic decision-making.
SLA Definition and Performance Trade-offs
Context: Your online judge platform has 10K concurrent users during contests. Product wants to promise "results within 5 seconds" in marketing materials. Engineering needs to define realistic SLAs that balance user experience with infrastructure costs.
Discussion Points:
- What specific SLA would you commit to for code execution latency? (e.g., P50, P95, P99)
- How do you measure and track SLA compliance during contests vs normal usage?
- What happens when you can't meet the SLA during traffic spikes? How do you communicate this to users?
- How would you use adaptive strategies to optimize resource allocation based on real-time SLA metrics?
- What trade-offs exist between strict SLA guarantees and infrastructure costs? When would you deliberately degrade service?
- How do you design SLAs differently for different user tiers (free users vs premium subscribers)?
Comprehensive Failure Mode Analysis
Context: It's Saturday morning. A contest is running with 10K participants. Suddenly, 30% of submissions return "execution timeout" but the code is correct. Your on-call engineer needs to diagnose and mitigate fast.
Discussion Points:
- What are all the failure modes in the code execution pipeline? (message queue failure, container orchestration issues, network partitions, database unavailability, worker node failures)
- How do you detect each failure mode before users report it? What metrics and alerts distinguish between them?
- What's your incident response playbook for each major failure scenario?
- How do you handle partial failures? (e.g., 20% of workers are down, message queue is slow but functional)
- What graceful degradation strategies preserve core functionality when components fail?
- How do you prevent cascading failures? (e.g., slow database → queue backup → memory exhaustion → worker crashes)
Advanced Sandboxing: Application Kernels
Context: Security researchers discover a container escape vulnerability. Your CISO demands "VM-level isolation" but engineering pushes back on performance costs. You need a solution that balances both concerns.
Discussion Points:
- What are the security limitations of standard Docker containers for untrusted code execution?
- How does gVisor (or similar application kernels like Kata Containers) provide a middle ground between containers and VMs?
- What performance trade-offs exist between Docker, gVisor, and full VMs? (startup time, runtime overhead, memory footprint)
- When would you choose gVisor over standard containers? What specific threat models does it address?
- How do you implement defense-in-depth? What layers beyond sandboxing protect against malicious code?
- How do you quantify security vs performance trade-offs for leadership?
State Persistence and Disaster Recovery
Context: Your Redis leaderboard instance crashes mid-contest. 10K users lose their rankings. Some had solved 3 problems; now the system shows zero. Twitter explodes with complaints. How do you prevent this?
Discussion Points:
- What data must persist beyond contest duration? What can be ephemeral?
- How do you design persistence for the leaderboard without sacrificing real-time performance?
- What recovery strategies exist if Redis fails mid-contest? (Redis persistence, write-ahead log, dual-write to durable store)
- How do you rebuild leaderboard state from submission history after a failure?
- What are the trade-offs between Redis RDB snapshots vs AOF logs for contest data?
- How do you test disaster recovery procedures without disrupting production contests?
Security Risk Assessment for Code Execution Platforms
Context: A security audit reveals that user-submitted code could potentially: mine cryptocurrency using your compute resources, exfiltrate test cases to sell online, or launch DDoS attacks from your worker IPs. You need a comprehensive security strategy.
Discussion Points:
- What are all the attack vectors in a code execution platform? (resource abuse, data exfiltration, lateral movement, test case theft)
- How do you prevent resource abuse? (CPU mining, memory bombs, fork bombs, disk exhaustion)
- How do you prevent data exfiltration? (stealing test cases, side-channel attacks to infer other users' solutions)
- What network-level protections prevent workers from being used as attack sources?
- How do you detect anomalous behavior? (unusual resource patterns, network activity, execution characteristics)
- How do you balance security monitoring with user privacy concerns?
Level Expectations
| Dimension | Mid-Level (L4) | Senior (L5) | Staff (L6) |
|---|---|---|---|
| Requirements & Estimation | List basic features (Submit, View, Leaderboard); identify basic NFRs | Define NFRs with targets (latency, security); calculate throughput and worker counts | SLA definition; failure mode analysis; cost optimization vs performance trade-offs |
| Architecture | Client → API → DB; synchronous execution or simple async | Microservices with async workers; message queue for decoupling; event-driven contest updates | Service mesh; graceful degradation; circuit breakers; cross-service observability |
| Code Execution | Basic Docker container isolation; mention memory/time limits | Docker with full resource limits (CPU, memory, PID, network, filesystem); seccomp profiles | gVisor/Kata Containers as middle ground; defense-in-depth layering; threat modeling |
| Leaderboard | Include a ranking mechanism; basic tie-breaking | Redis ZSET with composite score; explain skip list O(log n); compare DB vs Redis | ZSET internals; persistence/recovery strategy; leaderboard state reconstruction from submissions |
| Scalability | Mention pre-scaling; basic queue buffering | Pre-scaling with scheduler; two-phase processing; FIFO fairness; compute estimation | Adaptive scaling based on SLA metrics; cost modeling; deliberate degradation strategies |
Summary
Key Design Decisions
Async Code Execution: Submissions are enqueued immediately (< 100 ms response), executed by workers asynchronously, and results delivered via polling. This decouples submission intake from execution capacity, enabling the system to absorb traffic bursts without dropping submissions.
Docker Sandboxing with Six Isolation Layers: Container isolation + resource limits + seccomp + user namespace + ephemeral containers + dedicated worker hosts. Each layer addresses a different attack vector. gVisor provides optional VM-like isolation when kernel-sharing risk is unacceptable.
Redis ZSET for Leaderboard: Skip-list-based sorted set provides O(log n) updates and O(log n + N) top-N queries — orders of magnitude faster than SQL ORDER BY. Composite scores pack points + time into a single value using the big multiplier formula.
Polling over WebSockets: Short polling avoids maintaining 10,000 persistent connections. With 3-second average execution time, the client polls 2-3 times. The "wasted" polls are trivially cheap compared to the memory and complexity of persistent connection management.
Message Queue for Fairness: FIFO queues ensure submissions are graded in order of receipt. Pre-scaling workers before contests avoids cold-start latency. Two-phase processing handles extreme scale by evaluating 10% of tests during contest, 100% after.
Architecture Principles Applied
| Principle | Application |
|---|---|
| Separation of concerns | API servers never execute untrusted code; workers are isolated on dedicated hosts |
| Async over sync | Enqueue-then-poll pattern enables 100 ms submission response regardless of execution time |
| Right tool for the right job | PostgreSQL for persistent data, Redis for ephemeral leaderboard, Queue for work distribution |
| Pre-scale for known events | Contest start times are known; provision workers proactively instead of reactively |
| Defense in depth | 6 isolation layers for code execution; no single security mechanism is trusted alone |
Common Pitfalls
| Pitfall | Why It Fails | Better Approach |
|---|---|---|
| Execute code on API server | One malicious submission crashes entire service | Isolated Docker workers behind a queue |
| WebSockets for result delivery | 10K persistent connections = memory pressure | Stateless polling (2-3 polls per submission) |
| SQL leaderboard with ORDER BY | O(n log n) per query × 2,000 queries/sec = unsustainable | Redis ZSET: O(log n + 50) per query |
| Auto-scale workers reactively | 2-5 min spin-up time → first-minute submissions delayed | Pre-scale 5 min before contest start |
| Run all test cases during contest | 4M test case executions in 2 hours requires 250 workers | Two-phase: 10% during, 100% after (25 workers during) |