comment-system
Introduction
Comment systems are one of the most ubiquitous social features on the internet. Every major platform — YouTube, Reddit, Facebook, Hacker News, Medium, and news sites like The New York Times — relies on a comment system that lets users post reactions, reply to each other, upvote/downvote, and engage in threaded discussions. Platforms like Disqus provide comment-as-a-service to hundreds of thousands of websites, handling billions of comments across millions of pages.
The problem sounds simple — "let users post text under a page" — but at scale it forces nuanced decisions about:
- Data modeling: Flat comments vs. nested/threaded replies — each requires a different schema, query strategy, and frontend rendering approach.
- Consistency model: Should a user see their own comment immediately (read-your-writes) while other users experience eventual consistency?
- Vote counting at scale: With thousands of concurrent upvotes on a popular comment, how do you avoid lost updates without serializing all writes?
- Pagination of dynamic data: New comments arrive while a user is reading — how do you avoid duplicates and missed items across pages?
- Moderation and spam: At 1 billion comments/day, manual moderation is impossible. You need ML-based spam detection, rate limiting, and admin tools.
- Peak traffic handling: A viral post can generate 10-100× normal comment traffic. The system must absorb spikes without downtime.
In this editorial we design a Comment System (like Disqus) from first principles — starting from requirements, estimating scale, choosing the right data model, designing the API, and walking through the architecture layer by layer. We stratify depth by seniority level so you can calibrate your interview answers precisely.
Functional Requirements
We decompose functional requirements from the verbs in the problem statement:
Core (must-have for MVP)
- Post — Authenticated users can submit a comment on a topic (page/article/video). Comments are stored durably and displayed under the associated topic.
- Reply — Users can reply to an existing comment, creating a threaded conversation. Replies are nested under the parent comment.
- Vote — Users can upvote or downvote any comment. Each user can vote once per comment (idempotent). Vote counts are displayed in near-real-time.
- List — Users can view all comments for a given topic, sorted by recency (default) or by popularity (vote count). Comments are paginated.
- Moderate — Administrators can delete comments and ban users. Moderation actions take effect immediately.
Extended (out of scope but worth mentioning)
- Real-time comment updates (WebSocket/SSE push to all viewers).
- Rich media in comments (images, GIFs, code blocks).
- Comment editing and edit history.
- @mentions and notification system.
- Emoji reactions (beyond upvote/downvote).
- Content recommendation ("trending comments").
Non-Functional Requirements
Non-functional requirements come from the adjectives in the problem statement:
| Requirement | Target | Reasoning |
|---|---|---|
| Scale | 100M daily active users (DAU) | Large platform like YouTube/Reddit |
| Write throughput | ~115K comments/sec (peak ~350K/sec) | 1B comments/day |
| Read throughput | ~11.5M reads/sec (peak ~35M/sec) | 100:1 read:write ratio |
| Latency (read, p99) | < 200ms for comment listing | Users expect instant page loads |
| Latency (write) | < 500ms for posting a comment | Acceptable for write path |
| Availability | 99.99% (52 min downtime/year) | Comments are a core engagement feature |
| Consistency | Eventual (seconds); read-your-writes for author | The poster should see their own comment immediately |
| Data retention | 10 years | Legal and analytics requirements |
| Durability | No comment loss | Users expect their content to persist |
A critical insight: comment systems are extremely read-heavy — the read:write ratio is roughly 100:1. Most users read comments; very few post them. This drives the design toward aggressive read-path caching and eventual consistency for readers, while ensuring the write path is durable and the author sees their own comment immediately.
Resource Estimation
Assumptions:
- 100M daily active users (DAU)
- 10 comments posted per user per day → 1 billion comments/day
- Average comment size: 100 bytes (text content)
- Read:write ratio: 100:1
- Data retention: 10 years
- Each comment record with metadata: ~500 bytes (content + IDs + timestamps + vote counts)
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily comments | 100M users × 10 comments | 1 billion/day |
| Write QPS (avg) | 1B ÷ 86,400 sec | ~11,500 writes/sec |
| Write QPS (peak, 3×) | 11,500 × 3 | ~35,000 writes/sec |
| Read QPS (avg) | 11,500 × 100 (read:write) | ~1,150,000 reads/sec |
| Read QPS (peak, 3×) | 1.15M × 3 | ~3,450,000 reads/sec |
Storage Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily raw storage | 1B comments × 500 bytes | ~500 GB/day |
| Annual storage | 500 GB × 365 | ~182 TB/year |
| 10-year retention | 182 TB × 10 | ~1.82 PB total |
| Vote records (daily) | Assume 5% of reads result in a vote = 57.5M votes/day × 100 bytes | ~5.75 GB/day |
Bandwidth Estimation
| Metric | Calculation | Result |
|---|---|---|
| Write ingress | 35K writes/sec × 500 bytes | ~17.5 MB/sec (140 Mbps) |
| Read egress | 3.45M reads/sec × 500 bytes (avg response) | ~1.7 GB/sec (13.6 Gbps) |
The bottleneck is clearly read throughput — 3.45M QPS at peak with 1.7 GB/sec egress. This makes caching the critical design lever.
API Design
We design six API endpoints grouped by operation: submission, listing, voting, and moderation.
Authenticated endpoint for posting a new top-level comment.
Request:
{
"content": "This is a great article! The section on caching was especially helpful.",
"client_id": "c-8f3a2e91" // idempotency key to prevent duplicate posts
}Response: 201 Created
{
"comment": {
"id": "cmt-7f3a9c2e",
"content": "This is a great article! The section on caching was especially helpful.",
"author_id": "usr-04821",
"author_name": "alice",
"topic_id": "topic-12345",
"parent_id": null,
"upvotes": 0,
"downvotes": 0,
"created_at": "2025-03-17T14:30:00Z"
}
}Design decisions:
- Idempotency key (
client_id): Prevents duplicate comments if the user double-clicks or the network retries. The server deduplicates using this key within a 5-minute window. - 201 Created (not 202): The comment is synchronously written to the primary DB. The author sees it immediately (read-your-writes consistency).
Request:
{
"content": "I agree — the cache invalidation section was the highlight.",
"client_id": "c-2b4d6e89"
}Response: 201 Created — same shape as above, with parent_id set to {comment_id}.
Query parameters: cursor (timestamp-based, optional), size (default 20, max 50), sort ("recent" | "popular").
Response:
{
"total_count": 12345,
"next_cursor": "2025-03-17T14:25:00Z",
"comments": [
{
"id": "cmt-7f3a9c2e",
"content": "This is a great article!...",
"author_id": "usr-04821",
"author_name": "alice",
"parent_id": null,
"upvotes": 42,
"downvotes": 3,
"created_at": "2025-03-17T14:30:00Z",
"reply_count": 5
}
]
}Why cursor-based pagination (not offset)? With offset pagination (?page=2&size=20), new comments inserted while the user is reading cause items to shift — the same comment appears on both page 1 and page 2. Cursor-based pagination uses the timestamp of the last seen comment as the boundary, making results stable even as new data arrives.
Response: 200 OK with updated vote counts. Idempotent — voting twice has no additional effect. Server stores (user_id, comment_id) in a votes collection to enforce one-vote-per-user.
Requires admin role. Soft-deletes the comment (sets deleted_at timestamp) so it can be audited later. Replies to deleted comments remain visible but show "[deleted]" as the parent content.
High-Level Design
How does the system handle reads and writes at scale?
With a 100:1 read-to-write ratio and 3.45M peak read QPS, the architecture must be heavily read-optimized. The core insight: separate the read and write paths so each can be scaled independently.
A naive approach: a single service backed by a MongoDB replica set. MongoDB can handle ~30K reads/sec per node with secondaryPreferred reads. To reach 3.45M QPS, you'd need 115+ MongoDB nodes just for reads — and each node stores the full dataset.
The problem isn't just capacity — it's cost and operational complexity. A Redis cluster serving cached comment pages costs 10× less per read than a MongoDB query. By putting a cache in front of the database, we reduce DB load by 95%+.
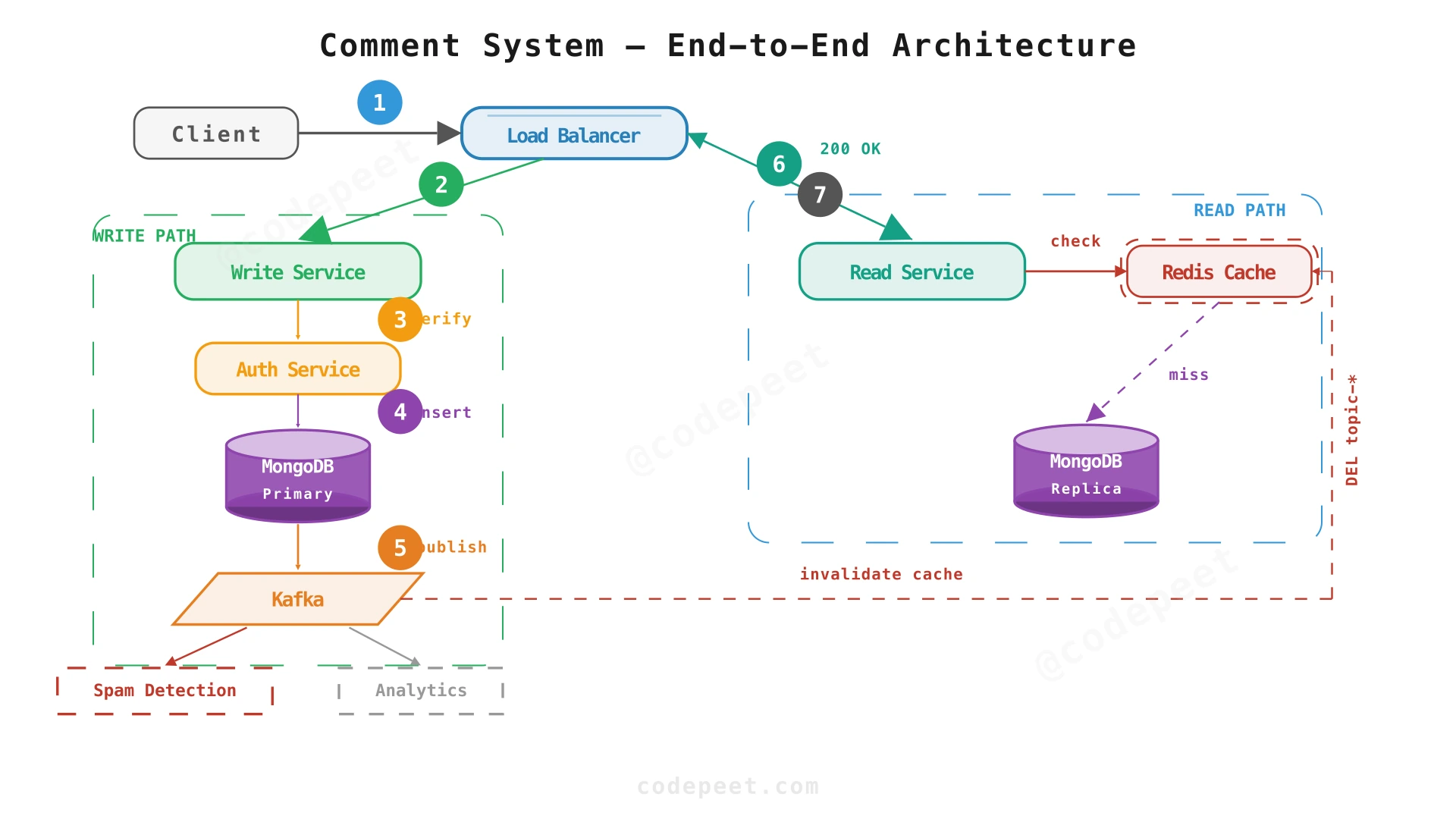
The architecture follows a CQRS-lite (Command Query Responsibility Segregation) pattern:
Write Path (Command):
- Client sends POST/PUT to the Load Balancer.
- LB routes to a Comment Service (Write) instance.
- Write service calls Auth Service to verify the user is authenticated and not banned.
- Comment is written to Primary MongoDB (synchronous, durable).
- An event is published to Kafka for:
- Cache invalidation (invalidate the cached comment pages for this topic).
- Spam check (async ML pipeline screens the comment post-write).
- Notification dispatch (notify the parent comment's author of a reply).
- Analytics ingestion.
Read Path (Query):
- Client sends GET to the Load Balancer.
- LB routes to a Comment Service (Read) instance.
- Read service checks Redis Cache Cluster first.
- On cache hit → return immediately (< 50ms).
- On cache miss → query MongoDB Secondary replica → cache the result → return.
The author's own comment is visible immediately because the write service returns the created comment in the 201 response. Other users see it after the cache TTL expires (a few seconds) — acceptable for eventual consistency.
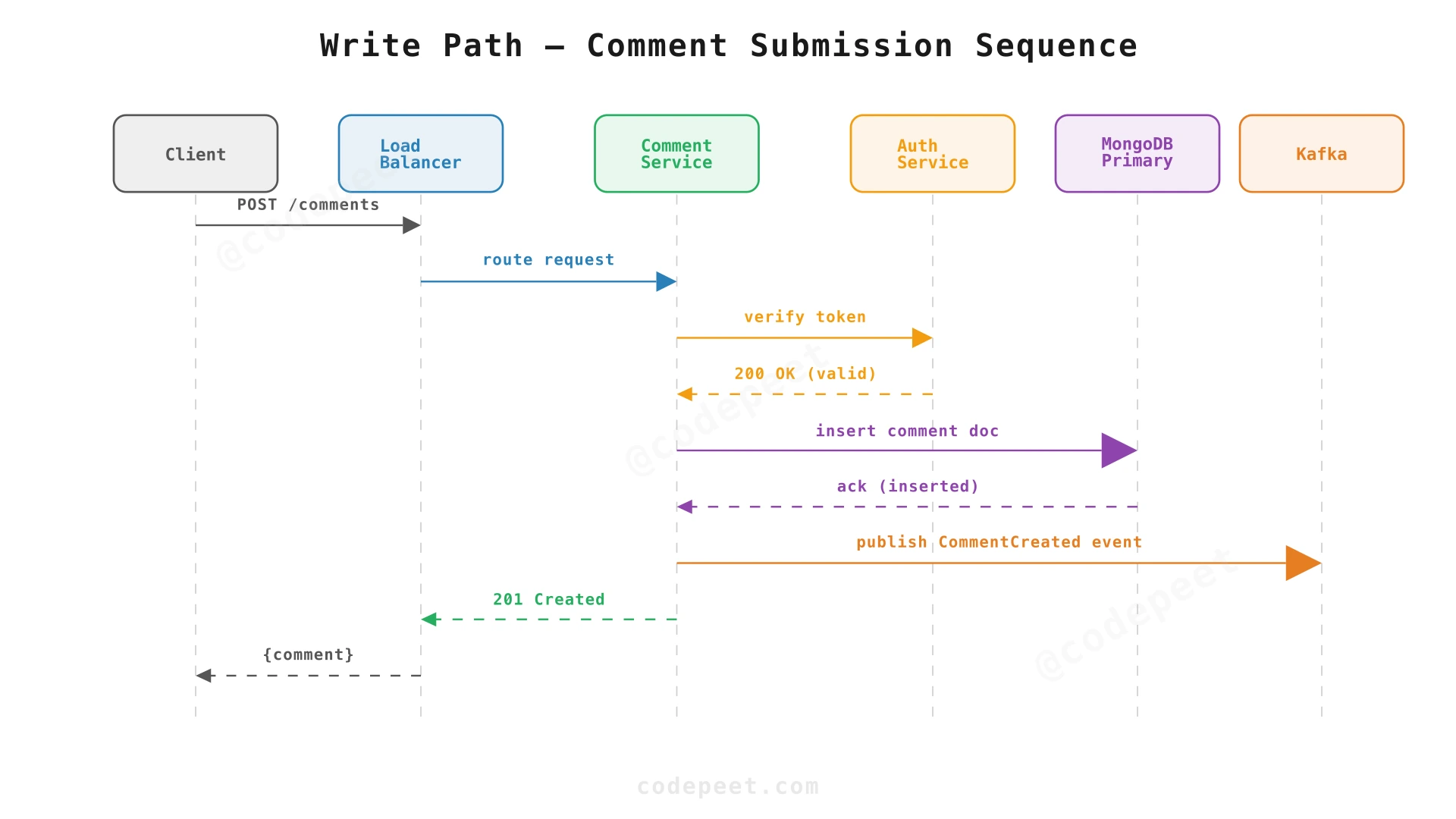
When a comment is posted, multiple things need to happen: cache invalidation, spam check, notification, analytics. If the write service called each of these synchronously:
- Latency: 4 sequential service calls add 200-400ms to the write path.
- Coupling: If the spam service is down, comment posting fails.
- Reliability: If any service call fails mid-way, we'd need distributed transactions.
Kafka decouples all of this: the write service publishes a single CommentCreated event, and each downstream consumer processes it independently. If the spam service is down, the event waits in Kafka until it recovers — no data loss.
The author expects to see their comment immediately after posting. But other readers are served from a cache that's seconds stale. How do we reconcile?
Two approaches:
-
Client-side optimistic update: After the POST returns 201 with the comment, the client inserts it into the local comment list without waiting for a server refresh. This is the simplest and most common approach (used by YouTube, Reddit, etc.).
-
Write-through cache: After writing to MongoDB, the write service also writes the updated comment page to Redis. This ensures even a page refresh shows the new comment. However, this adds complexity and potential race conditions.
Recommendation: Client-side optimistic update. It's simpler, requires no cache coordination, and covers 99% of cases.
How should we model comments, replies, and votes?
The data model is the foundation of the system. The key design decision is how to represent the parent-child relationship between comments and replies.
Approach 1: Adjacency List (parent_id pointer)
Each reply stores a parent_id referencing its parent comment. To fetch a thread, query all comments for a topic and reconstruct the tree on the server or client.
Approach 2: Materialized Path
Each comment stores its full ancestry path: root/child1/child2/this. Makes subtree queries easy (LIKE 'root/child1/%') but updates (moving a comment) are expensive.
Approach 3: Closure Table
A separate table stores all ancestor-descendant pairs. Most flexible for tree operations but doubles storage and write cost.
Recommendation: Adjacency List with limited nesting depth. Most comment systems (Reddit, YouTube, Disqus) limit nesting to 2-3 levels. With limited depth, the adjacency list is simple, efficient, and sufficient.
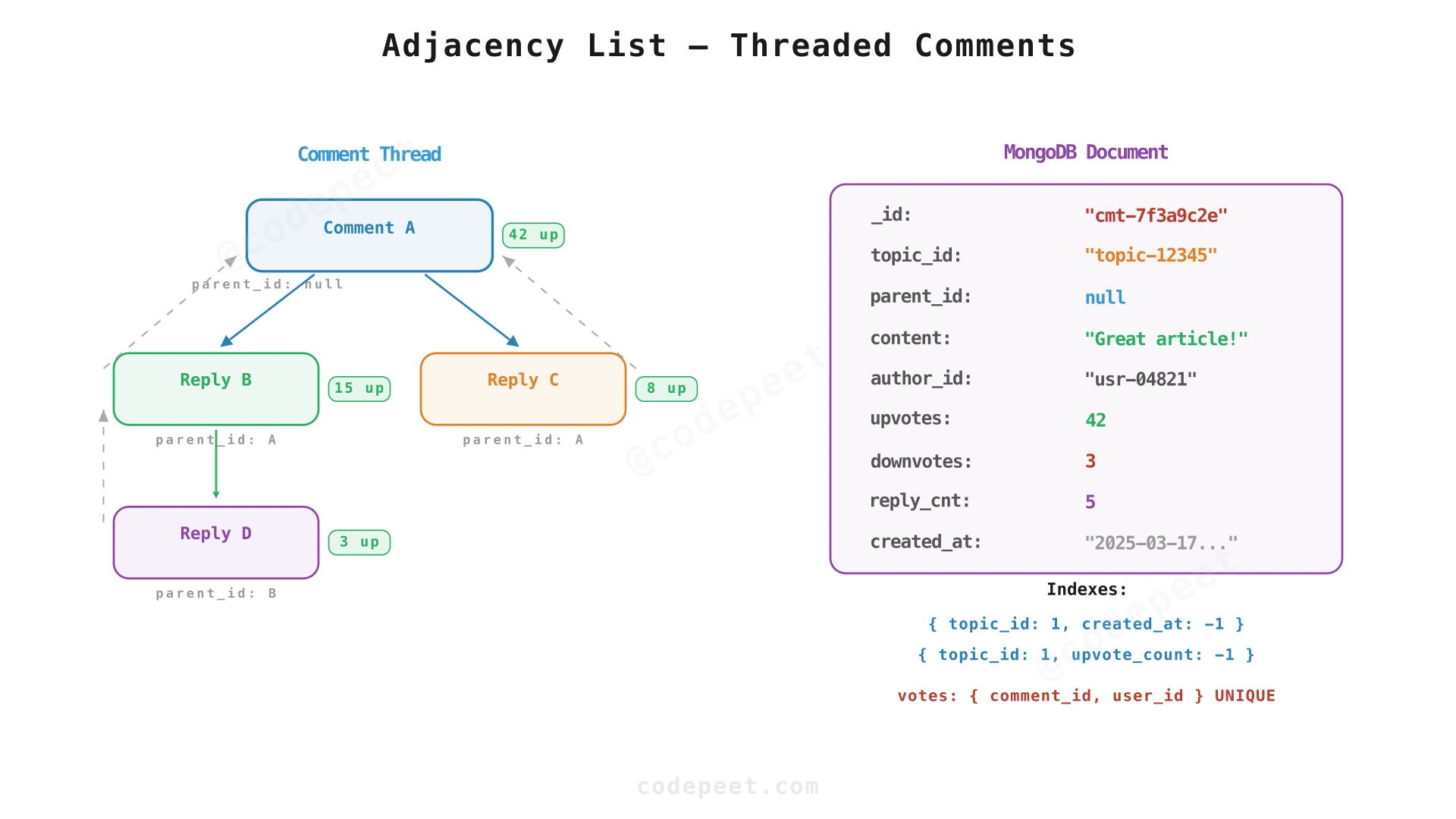
MongoDB Schema:
// comments collection
{
_id: ObjectId("cmt-7f3a9c2e"),
topic_id: "topic-12345", // indexed — partitioning key
parent_id: null, // null = top-level, ObjectId = reply
content: "This is a great article!",
author_id: "usr-04821", // indexed for user profile queries
author_name: "alice", // denormalized for display (avoid join)
upvote_count: 42,
downvote_count: 3,
reply_count: 5, // denormalized counter for quick display
deleted_at: null, // soft delete timestamp
created_at: ISODate("2025-03-17T14:30:00Z"),
updated_at: ISODate("2025-03-17T14:30:00Z")
}
// Compound index for pagination query:
// db.comments.createIndex({ topic_id: 1, created_at: -1 })
// db.comments.createIndex({ topic_id: 1, upvote_count: -1 }) // for "popular" sort
// votes collection (ensures one vote per user per comment)
{
_id: ObjectId("..."),
comment_id: ObjectId("cmt-7f3a9c2e"), // indexed
user_id: "usr-12345", // indexed
vote_type: "upvote", // "upvote" | "downvote"
created_at: ISODate("2025-03-17T15:00:00Z")
}
// Unique compound index to prevent duplicate votes:
// db.votes.createIndex({ comment_id: 1, user_id: 1 }, { unique: true })Relational schema (for User/Auth service — PostgreSQL):
CREATE TABLE users (
user_id VARCHAR(64) PRIMARY KEY,
username VARCHAR(100) NOT NULL UNIQUE,
email VARCHAR(255) NOT NULL UNIQUE,
role VARCHAR(16) NOT NULL DEFAULT 'normal', -- normal | admin | banned
created_at TIMESTAMPTZ DEFAULT NOW()
);
CREATE TABLE topics (
topic_id VARCHAR(64) PRIMARY KEY,
url VARCHAR(2048) NOT NULL,
title VARCHAR(500),
comment_count BIGINT DEFAULT 0, -- denormalized counter
created_at TIMESTAMPTZ DEFAULT NOW()
);Both are viable, but MongoDB has advantages for this workload:
| Aspect | MongoDB | PostgreSQL |
|---|---|---|
| Schema flexibility | Schemaless — easy to add fields (reactions, edits) | Requires migrations |
| Sharding | Native horizontal sharding by topic_id | Requires Citus or manual partitioning |
| Write throughput | Higher for document inserts (no row locking) | Strong consistency adds overhead |
| Nested data | Can embed replies in parent (for shallow threads) | Requires JOINs or CTEs |
| Replication | Built-in replica sets with secondaryPreferred reads | Streaming replication, read replicas |
PostgreSQL with TimescaleDB or Citus is also a strong choice if the team values SQL and transactional guarantees. YouTube uses a sharded MySQL setup; Reddit uses PostgreSQL.
Every time we display a comment, we need the vote count. If we computed it by counting rows in the votes collection (db.votes.count({ comment_id: X })), that's O(N) per comment — and with millions of votes on popular comments, it's far too slow.
Instead, we denormalize: store upvote_count and downvote_count directly on the comment document. When a user votes, we:
- Insert/update the vote record in the votes collection.
- Atomically increment/decrement the counter on the comment:
db.comments.updateOne({ _id: id }, { $inc: { upvote_count: 1 } }).
The $inc operator is atomic in MongoDB — no race condition even with concurrent votes.
Deep Dives
Caching and Cache Invalidation
With 3.45M peak read QPS and a 100:1 read-to-write ratio, caching is the most critical component. Without it, we'd need 100+ MongoDB nodes just for reads. With an effective cache, we can absorb >95% of reads in Redis.
Cache key design:
We cache entire paginated comment pages. The cache key encodes the query parameters:
{topic_id}:{sort}:{cursor}:{size}
For example: topic-12345:recent:2025-03-17T14:25:00Z:20
For the first page (no cursor): topic-12345:recent:0:20
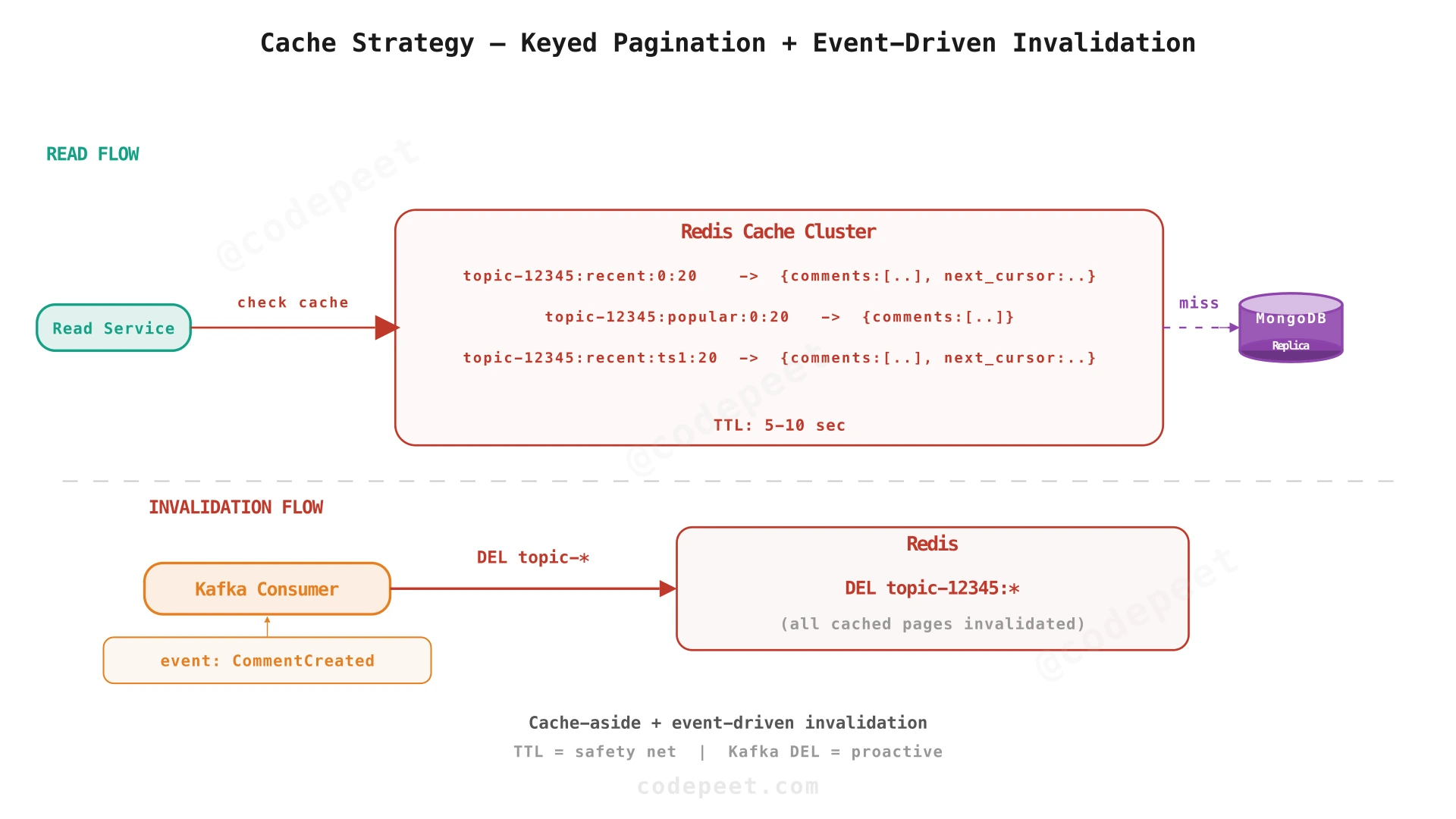
Cache TTL: 5-10 seconds. This is intentionally short because:
- Comments are dynamic (new comments, vote changes).
- A 5-second TTL means at most 5 seconds of staleness — acceptable for eventual consistency.
- Even a 5-second cache absorbs thousands of identical reads.
Cache invalidation strategy:
When a new comment is posted, the Kafka consumer receives a CommentCreated event and invalidates all cached pages for that topic: DEL topic-12345:* (Redis supports pattern-based deletion with SCAN).
Write-through means: on every write, update both the DB and the cache atomically. For a comment system, this is problematic:
- Cache key complexity: A single new comment invalidates multiple cache keys (all pages for that topic, both sort orders). Computing which cache entries to update is complex.
- Race conditions: Two concurrent writes to the same topic could produce inconsistent cache states if not coordinated.
- Over-engineering: With a 5-second TTL, the worst case is 5 seconds of staleness. Write-through adds complexity to save those 5 seconds — not worth it.
Recommendation: Cache-aside with event-driven invalidation. The Kafka consumer proactively invalidates on writes, and the TTL acts as a safety net.
A viral post gets millions of simultaneous readers. When the cache expires, thousands of concurrent requests all miss the cache and hit MongoDB — a "thundering herd".
Mitigations:
- Request coalescing (singleflight): If a cache key is already being refreshed, queue new requests and serve them all from the single DB query result.
- Stale-while-revalidate: Serve the stale cache entry while asynchronously refreshing it from MongoDB. Users see slightly stale data for one cache cycle.
- Lock-based refresh: Only one request acquires a Redis lock to refresh the cache; others wait on the lock or serve stale.
Cursor-Based Pagination and Duplicate Avoidance
Comment lists are dynamic — new comments arrive while a user is reading. Traditional offset-based pagination breaks in this scenario.
The duplicate problem with offset pagination:
- User loads page 1 (comments 1-20, sorted by newest).
- A new comment is inserted.
- User loads page 2 (comments 21-40).
- Because the new comment shifted everything by 1, comment #20 from page 1 now appears as comment #21 on page 2 — a duplicate.

Cursor-based pagination solves this:
Instead of OFFSET 20, the query uses: WHERE topic_id = X AND created_at < cursor_timestamp ORDER BY created_at DESC LIMIT 20.
No matter how many new comments are inserted, the cursor (timestamp of the last seen comment) anchors the query to a stable position.
For recent sort: cursor = created_at timestamp of the last comment on the current page.
For popular sort: cursor = (upvote_count, created_at) compound cursor. Since upvote_count isn't unique, we use created_at as a tiebreaker:
WHERE topic_id = X AND (upvote_count, created_at) < (cursor_votes, cursor_ts)
ORDER BY upvote_count DESC, created_at DESC
LIMIT 20
The compound cursor is encoded as a single opaque token (base64(votes:timestamp)) to prevent clients from manipulating cursor values.
When listing top-level comments, should we also fetch their replies?
Eager loading (embed replies in response):
- Fetch all replies for all 20 comments on the page in a single query.
- Pro: One API call, no loading spinners for replies.
- Con: If some comments have 500 replies, the response is huge.
Lazy loading (separate API call):
- Return only top-level comments with
reply_count. Client shows "5 replies" link. - When clicked, fetch replies:
GET /api/comments/{id}/replies?cursor=...&size=10. - Pro: Fast initial load, predictable response size.
- Con: Additional roundtrip for replies.
Hybrid (recommended): Embed the first 3 replies inline; show "Load more replies" for the rest. This is what YouTube and Reddit do.
Database Sharding and Scaling Strategy
At 1.82 PB over 10 years, a single MongoDB replica set won't cut it. We need horizontal sharding.
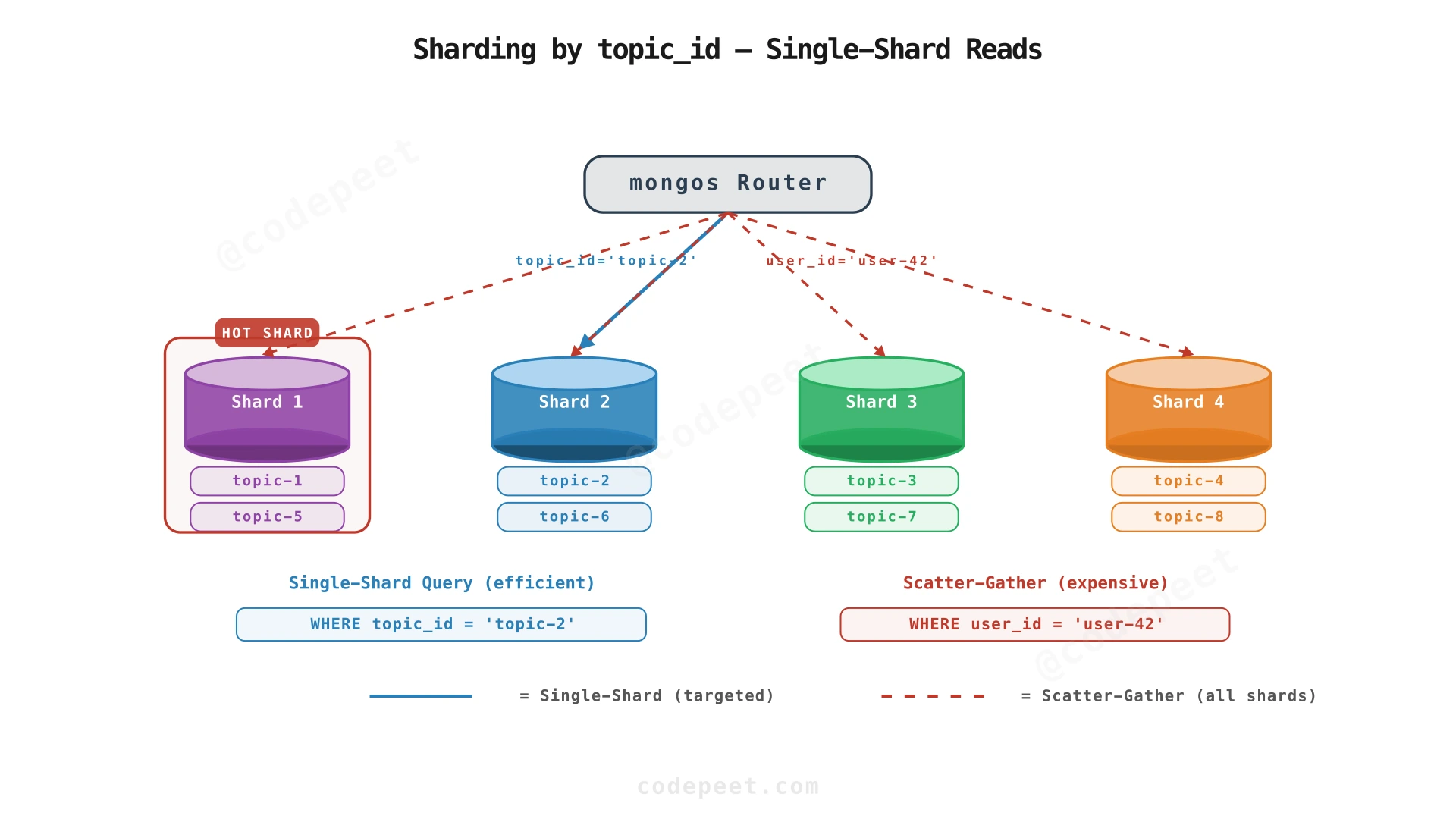
Shard key choice: topic_id
Comments are almost always queried by topic — "show me comments for this article". Sharding by topic_id ensures all comments for a given topic are on the same shard, making the common query a single-shard operation.
| Shard Key | Pros | Cons |
|---|---|---|
| topic_id | All comments for a topic on one shard; single-shard queries | Hot topics cause hotspots |
| comment_id | Even distribution | Cross-shard scatter-gather for topic queries |
| author_id | Good for user-profile queries | Topic queries scatter across all shards |
| compound (topic_id + timestamp) | Range queries within a topic | More complex routing |
Recommendation: topic_id as shard key, with hotspot mitigation:
- Hot topic detection: Monitor per-shard QPS. If a single topic causes a shard to exceed threshold, enable the cache TTL for that topic to 30 seconds (longer cache for hot content).
- Jumbo chunk splitting: MongoDB automatically splits chunks that grow too large. For mega-topics (10M+ comments), the chunk may need manual splitting.
Each MongoDB shard is a replica set (typically 3 nodes: 1 primary + 2 secondaries):
- Writes go to the primary.
- Reads use
secondaryPreferred— reading from secondaries distributes read load and keeps the primary free for writes. - Failover: If the primary dies, an automatic election promotes a secondary to primary within seconds. MongoDB's replica set protocol handles this transparently.
For cross-region disaster recovery, deploy one secondary in a different availability zone.
MongoDB supports TTL (Time-To-Live) indexes that automatically delete documents after a specified period:
// Auto-delete comments older than 10 years (315,360,000 seconds)
db.comments.createIndex(
{ created_at: 1 },
{ expireAfterSeconds: 315360000 }
);
MongoDB runs a background thread every 60 seconds that scans the TTL index and removes expired documents. This automatically enforces the 10-year retention policy without manual cleanup jobs.
For vote records, apply the same TTL — once the parent comment is deleted, orphaned votes serve no purpose.
Spam Detection, Moderation, and Peak Traffic
At 1 billion comments/day, automated moderation is essential. Manual review is physically impossible — you need ML-based screening in the pipeline.
Spam detection architecture:
The spam check runs asynchronously after the comment is written:
- Comment is written to MongoDB and visible to the author.
- A
CommentCreatedevent is published to Kafka. - The Spam Detection Service consumes the event and runs the comment through:
- Rule-based filters: Regex patterns for known spam phrases, URLs, excessive caps.
- ML classifier: A trained model (e.g., BERT-based text classifier) that scores the comment 0.0-1.0 for spam probability.
- If spam score > threshold (e.g., 0.8):
- Move to
spam_commentscollection (soft removal from display). - Increment user's spam counter. If counter > 5, auto-ban the user.
- Move to
- Borderline cases (score 0.5-0.8) are flagged for human review in the admin dashboard.
Two schools of thought:
Pre-write (synchronous): Check before saving. If spam, reject the POST.
- Pro: Spam never enters the database.
- Con: Adds 50-200ms to the write path. A slow ML model blocks all comment submission.
Post-write (asynchronous): Save first, check later. If spam, soft-delete.
- Pro: Write path stays fast (~50ms). ML model doesn't block the user experience.
- Con: Spam is briefly visible (typically 1-5 seconds) before being removed.
Recommendation: Post-write async. The brief visibility window is acceptable because:
- Other users are reading from a cache that doesn't include the spam comment yet (the comment was just written; cache hasn't refreshed).
- Only the spammer sees their own comment immediately (and it's their own spam).
A viral event (e.g., Super Bowl, product launch) can spike comment volume 10-100×. Protection strategies:
- Per-user rate limit: Max 1 comment per 10 seconds per user (Redis counter with TTL). Prevents spam bots and overly fast humans.
- Per-topic rate limit: If a single topic exceeds 10K comments/minute, enable a write queue (Kafka) and process at a sustainable rate. New comments are accepted with a
202 Accepted+ "Your comment will appear shortly" message. - Global circuit breaker: If total write QPS exceeds 5× steady-state, shed 50% of traffic via HTTP 429 (Too Many Requests) with a Retry-After header.
- Auto-scaling: The Comment Service (both read and write) runs on Kubernetes with horizontal pod autoscaling triggered by CPU and QPS metrics.
For extreme spikes, we can decouple the write API from the database entirely:
- The write service receives the comment and publishes it to a Kafka topic (instead of writing to MongoDB directly).
- A batch consumer drains the topic and writes to MongoDB at a controlled rate.
- The API returns
202 Accepted— the comment is guaranteed to be saved (Kafka durability) but not yet visible.
This adds write latency (seconds instead of milliseconds) but prevents MongoDB from being overwhelmed. The trade-off is acceptable during extreme spikes — users can tolerate a few seconds of delay when millions of people are commenting simultaneously.
Staff-Level Discussion Topics
These open-ended topics have no single correct answer — they test architectural judgment and the ability to reason about complex trade-offs. Use the discussion buttons to practice articulating your thinking.
Currently, users must refresh or paginate to see new comments. For a live discussion (e.g., during a sports event), users expect comments to appear in real time.
Staff candidates should discuss:
- WebSocket connections per topic — maintaining millions of persistent connections during a viral event requires dedicated WebSocket gateway servers.
- Server-Sent Events (SSE) — simpler than WebSocket for unidirectional pushes, but each connection holds an HTTP thread.
- Fan-out architecture: New comments are published to a Kafka topic → a fan-out service pushes them to all connected clients for that topic.
- Scaling concern: A topic with 100K concurrent viewers means 100K WebSocket connections for a single piece of content.
Disqus provides comments to 750K+ websites. This introduces multi-tenancy challenges:
- Tenant isolation: Should each website (tenant) have its own database/shard, or share infrastructure with logical separation?
- Noisy neighbor: One viral website could consume disproportionate resources. How do you implement per-tenant rate limiting and resource quotas?
- Custom branding: Each website customizes the comment widget's appearance. The API must return tenant-specific CSS/config.
- Cross-origin embedding: The comment widget runs in an iframe on third-party sites. CORS, CSP, and cookie policies (third-party cookie deprecation) affect the design.
Pure chronological sorting buries high-quality comments under noise. Platforms like Reddit and Hacker News use sophisticated ranking algorithms:
- Reddit's Best sort: Uses Wilson score confidence interval (considers both upvotes and total votes to rank reliably even with few votes).
- Hacker News: Combines upvotes, time decay, and comment author reputation.
- YouTube: Uses ML to rank by engagement signals (replies, likes, sentiment).
The staff challenge: computing a real-time ranking over millions of comments per topic while serving 3.45M QPS reads. Pre-compute or compute on-the-fly?
Level Expectations
What interviewers expect at each seniority level for a comment system design:
| Area | |||
|---|---|---|---|
| Requirements | Lists FRs (post, reply, vote, list) and basic NFRs | Derives math: 11.5K write QPS, 1.15M read QPS; identifies 100:1 read:write ratio | Discusses eventual consistency with read-your-writes guarantee; multi-tenancy extensions |
| Data Model | Comments table with parent_id for replies | Compares adjacency list vs materialized path; explains denormalized vote counters | Discusses closure table trade-offs; sharding implications of each model |
| API Design | Basic CRUD endpoints for comments | Cursor-based pagination with cursor encoding; idempotency keys | Compound cursors for popular sort; opaque cursor tokens to prevent manipulation |
| Architecture | Client → Service → DB | CQRS-lite: separate read/write paths; Redis cache layer with event-driven invalidation | Kafka-based event bus for async spam check, notifications, analytics; circuit breakers |
| Caching | "Use Redis" | Cache key design, TTL strategy, thundering herd mitigation | Stale-while-revalidate, request coalescing, adaptive TTL for hot topics |
| Scaling | "Add more servers" | MongoDB sharding by topic_id; replica sets with secondaryPreferred reads | Hot shard detection, cross-shard user queries, 1.82 PB retention strategy, TTL indexes |
| Moderation | "Delete bad comments" | Async ML-based spam detection pipeline; rule + model hybrid | Pre-write vs post-write trade-offs; auto-ban thresholds; human-in-the-loop review |
Interview Cheatsheet
Quick-reference talking points for the interview:
"A comment system lets users post, reply, vote, and browse comments under any content page. The core challenge is a 100:1 read-to-write ratio at 1.15M read QPS. The architecture uses CQRS-lite: writes go to MongoDB via a stateless service, then events flow through Kafka for cache invalidation, spam detection, and notifications. Reads are served from a Redis cache layer with a 5-second TTL, backed by MongoDB secondaries."
- FRs: Post, Reply, Vote (up/down, idempotent), List (cursor-based, recent/popular sort), Moderate (admin delete)
- NFRs: 100M DAU, ~11.5K write QPS (peak ~35K), ~1.15M read QPS (peak ~3.45M), <200ms read latency
- Consistency model: Eventual for readers, read-your-writes for the comment author
- Out of scope: Real-time push, rich media, @mentions, editing
- Comment Service (Write) — stateless, authed, writes to MongoDB primary
- Comment Service (Read) — stateless, reads from Redis (cache hit) or MongoDB secondary (miss)
- MongoDB — sharded by topic_id, replica sets for HA, TTL indexes for 10-year retention
- Redis Cache Cluster — caches paginated comment pages, 5-sec TTL, event-driven invalidation
- Kafka — event bus for async: cache invalidation, spam check, notifications, analytics
- Auth Service — validates tokens, checks ban status
- Spam Detection — async ML pipeline consuming Kafka events
- Eventual vs. strong consistency: Read-your-writes for author (client-side optimistic update); eventual for everyone else (5-second cache TTL)
- Adjacency list vs. materialized path: Adjacency list is simpler and sufficient with limited nesting depth
- Cache-aside vs. write-through: Cache-aside with Kafka invalidation — simpler, avoids race conditions
- Sync vs. async spam check: Async post-write — keeps write path fast; brief visibility is acceptable
- MongoDB vs. PostgreSQL: MongoDB for schemaless flexibility and native sharding; PostgreSQL if team values SQL and transactions
- Offset vs. cursor pagination: Cursor prevents duplicates in dynamic lists
| Metric | Value |
|---|---|
| DAU | 100M |
| Comments per day | 1 billion |
| Read:write ratio | 100:1 |
| Write QPS (avg / peak) | 11.5K / 35K |
| Read QPS (avg / peak) | 1.15M / 3.45M |
| Comment size (with metadata) | ~500 bytes |
| Daily storage | ~500 GB |
| 10-year retention | ~1.82 PB |
| Cache TTL | 5-10 seconds |
| Cache hit rate | >95% |
- "How would you add real-time updates?" — WebSocket or SSE gateway. Fan-out service reads new comments from Kafka and pushes to connected clients. Fall back to polling if connection count exceeds threshold.
- "How do you handle a viral post?" — Adaptive cache TTL (increase from 5s to 30s for hot topics), per-topic write queuing via Kafka, auto-scaling the service fleet.
- "How would you support comment editing?" — Store edit history as an array in the comment document. Show "edited" badge on the UI. Invalidate cache on edit.
- "How do you prevent vote manipulation?" — One-vote-per-user enforced by unique compound index. Rate limit votes per user per minute. ML model detects coordinated voting patterns.