pastebin
Introduction
A developer debugging a production incident copies 200 lines of error logs, drops them into a text box, and clicks "Create Paste." Within milliseconds they receive a short URL — something like pb.example/a7x3k — which they paste into a GitHub issue for the on-call team. Over the next week, dozens of engineers investigating the same incident click that link and instantly see the logs.
This deceptively simple interaction conceals several interesting engineering problems:
| Challenge | Why It's Hard |
|---|---|
| Unique short URL generation | Millions of pastes need unique, unpredictable identifiers — sequential IDs expose all content to enumeration attacks |
| Heterogeneous content storage | Paste sizes range from 10 bytes to 1 MB. Storing variable-length blobs in a relational database causes fragmentation, bloated backups, and cost inefficiency |
| Read-heavy serving | A 100:1 read-to-write ratio means every paste is read ~100 times on average. Without edge caching, the origin is overwhelmed |
| Expiration enforcement | When a user sets a paste to expire, it must become inaccessible promptly — but the read path goes through a CDN with no application logic |
| Deletion under traffic | Deleting a viral paste with millions of cached copies across 200+ CDN edge locations creates a thundering herd when caches are purged simultaneously |
LLD Connection: This problem connects to URL shortener design (ID generation, base62 encoding) and object storage patterns (metadata/content separation, CDN integration).
The system serves 1 million daily active users, stores 90 million pastes over a 3-month retention window, and handles a 100:1 read-to-write ratio — a scale where naive approaches still work for writes but collapse for reads without proper caching.
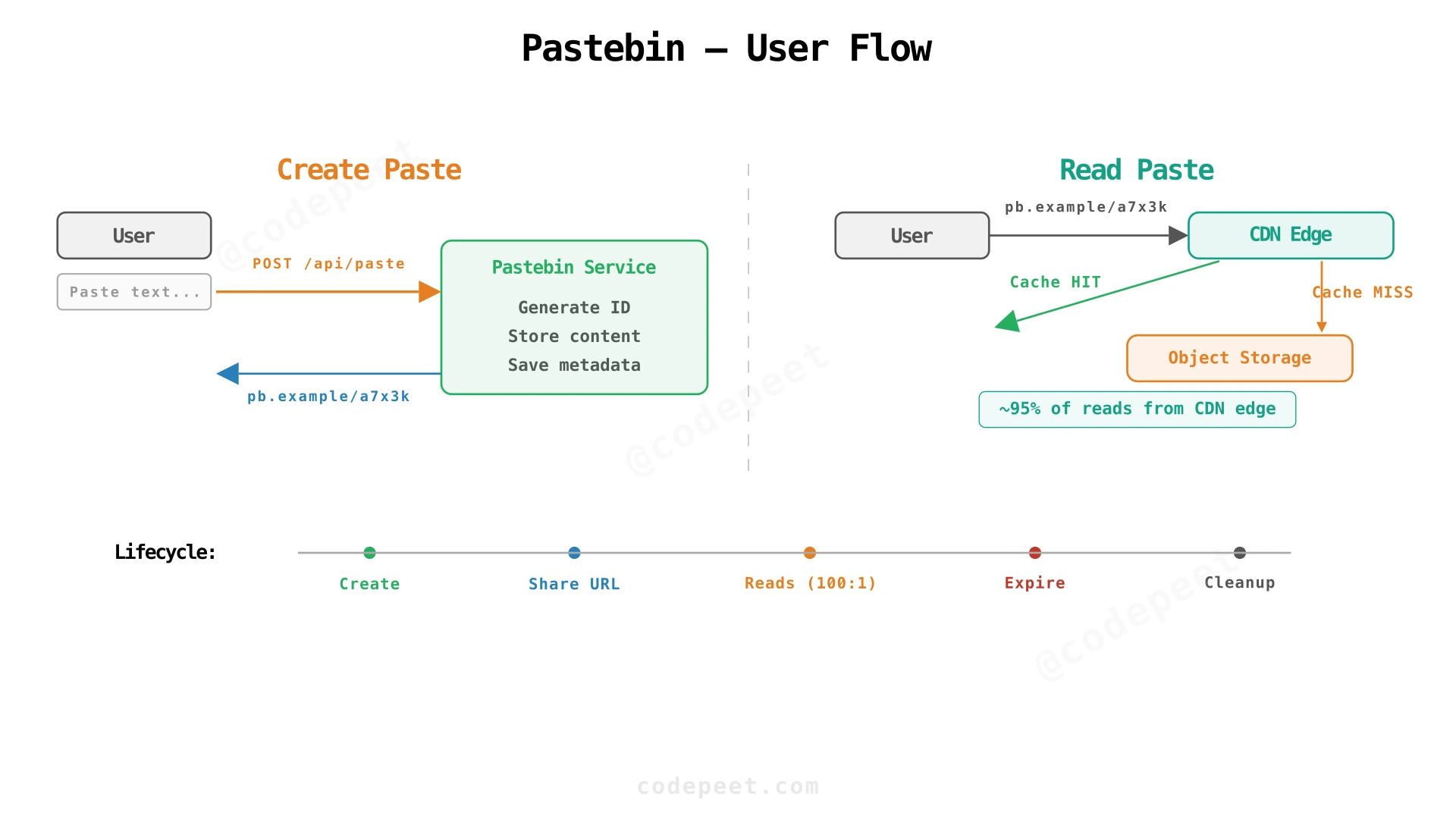
Functional Requirements
Pastebin has two core operations: storing text and retrieving it.
FR1 — Store Text Content. Users upload text of any size (up to 1 MB) along with an optional expiration time. The system generates a unique short URL, persists the text durably, and returns the URL immediately for sharing. A delete token is also returned, allowing the creator to remove the paste later without authentication.
FR2 — Retrieve Text Content. Users access a paste via its unique short URL. The system returns the text content with low latency. Expired or deleted pastes return an appropriate error response. The vast majority of reads are served from CDN edge caches without touching the origin infrastructure.
- User authentication and accounts — Anonymous paste creation; no login required
- Syntax highlighting — Client-side rendering concern, not a backend design problem
- Paste editing after creation — Pastes are immutable once created
- Comments and collaboration — No social features
- Analytics and view counts — No tracking of individual paste views
- Paste search/discovery — Pastes are unlisted; accessible only via direct URL
Scale Requirements
| Metric | Value |
|---|---|
| Daily active users | 1,000,000 |
| Pastes created per day | 1,000,000 (1 per user) |
| Read-to-write ratio | 100:1 |
| Data retention | 3 months |
| Average paste size | 10 KB |
| Maximum paste size | 1 MB |
| Total pastes in retention window | ~90,000,000 |
The write path is lightweight (~12 writes/sec) — the real engineering challenge is the read path at 100× the write volume, serving content globally with sub-100ms latency.
Non-Functional Requirements
| Requirement | Target | Rationale |
|---|---|---|
| Low Latency | Paste retrieval p95 < 100 ms | Users clicking shared links expect instant page loads |
| High Durability | Zero data loss once stored | Developers paste important code, error logs, configurations — loss is unacceptable |
| High Availability | 99.9% uptime (< 44 min downtime/month) | Shared links must work when teammates click them |
| Security by Obscurity | Unpredictable URLs, no enumeration | Pastes may contain sensitive code, credentials, or config files. URLs must be unlisted — not findable by guessing |
| Expiration Enforcement | Expired pastes inaccessible within minutes | Important for pastes containing temporary credentials or sensitive debug info |
Key assumption: Once a paste URL is shared, assume the entire internet can access it. Others can copy and redistribute the URL freely. Deletion removes access but cannot prevent prior cloning. The entire security model is based on URL secrecy, not access control — anyone with the URL can read the paste.
Resource Estimation
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Write QPS (average) | 1M pastes/day ÷ 86,400 sec | ~12 writes/sec |
| Read QPS (average) | 12 writes/sec × 100 (read:write ratio) | ~1,200 reads/sec |
| Peak write QPS | 12 × 5 (peak multiplier) | ~60 writes/sec |
| Peak read QPS | 1,200 × 5 | ~6,000 reads/sec |
At 12 writes/sec, a single application server handles the write load easily. The read path at 1,200 QPS (6K peak) requires CDN caching — without it, the origin bears the full load.
Storage Estimation
| Data | Calculation | Result |
|---|---|---|
| Daily content storage | 1M pastes × 10 KB avg | 10 GB/day |
| 3-month content retention | 10 GB × 90 days | ~900 GB |
| Daily metadata storage | 1M pastes × ~100 bytes | ~100 MB/day |
| 3-month metadata | 100 MB × 90 | ~9 GB |
| Total storage | 900 GB content + 9 GB metadata | ~910 GB |
Content storage (900 GB) goes to object storage at ~21/month. Storing the same 900 GB in a relational database costs 5-10× more and degrades query performance.
Infrastructure Estimation
| Component | Requirement |
|---|---|
| Application servers | 2–3 instances behind load balancer (12 writes/sec trivially handled) |
| Database (metadata) | Single PostgreSQL instance, ~9 GB disk (replicas for read scaling) |
| Object storage (content) | S3 or equivalent, ~900 GB with 3-month lifecycle policy |
| CDN | Global edge network (handles ~95% of reads) |
| Cache (metadata) | Redis, < 1 GB for hot paste metadata |
The system is read-dominated and CDN-dependent. The origin infrastructure is minimal because CDN absorbs most of the traffic. The engineering complexity lies in caching, expiration enforcement, and deletion — not raw throughput.
API Endpoints
Create a Paste
POST /api/paste
Content-Type: application/json
Request Body:
{
"text": "console.log('Hello world');",
"expiry": "24h"
}
Response: 201 Created
{
"id": "a7x3k",
"url": "https://pb.example/a7x3k",
"delete_token": "d8f2a1b9c4e7",
"expires_at": "2026-03-18T12:00:00Z"
}
Notes:
- Maximum content size: 1 MB (enforced via
Content-Lengthheader check before reading body) expiryaccepts durations (1h,24h,7d,30d) ornullfor no expiration (defaults to 3 months)delete_tokenis a 12-character random hex string returned only at creation — it's the only way to delete the paste without authentication
Retrieve a Paste
GET /{id}
Response: 200 OK
{
"id": "a7x3k",
"text": "console.log('Hello world');",
"created_at": "2026-03-17T12:00:00Z",
"expires_at": "2026-03-18T12:00:00Z"
}
Returns 404 Not Found if the paste doesn't exist, has expired, or has been deleted. In practice, most reads are served directly from CDN without reaching the application server.
Delete a Paste
DELETE /{id}
Content-Type: application/json
Request Body:
{
"delete_token": "d8f2a1b9c4e7"
}
Response: 200 OK
{
"status": "deleted"
}
Requires the delete_token returned at creation time. Returns 403 Forbidden if the token doesn't match. Returns 404 Not Found if the paste doesn't exist.
High-Level Design
The high-level design addresses two core design decisions:
- Store Text — Where do we store content, how do we generate unique IDs, and what does the write path look like?
- Retrieve Text — How do we serve content at sub-100ms latency with a 100:1 read-to-write ratio?
These two paths have fundamentally different characteristics: the write path is low-volume but latency-tolerant, while the read path is high-volume and latency-critical. The architecture reflects this asymmetry — writes go through an application server, reads go through CDN edges.
1. Store Text
How do we store text efficiently and generate unique short URLs?
A developer pastes 50 lines of error logs and clicks "Create." Within 200ms they have a URL to share. Let's build this write path step by step.
The First Decision: Where Should We Store the Text?
The simplest approach stores everything in one database table:
CREATE TABLE pastes (
id VARCHAR(8) PRIMARY KEY,
content TEXT,
created_at TIMESTAMP
);
At first glance this works. But consider what happens at scale: paste content varies from 10 bytes to 1 MB. With 1M pastes per day at 10 KB average, we accumulate 900 GB of content over 3 months. Storing all of that in a relational database creates compounding problems:
- Table bloat — Large
TEXTcolumns fragment across storage pages, slowing unrelated queries on the same table - Backup pain — Database dumps include all content; 900 GB takes hours to export and restore
- Cost — Database storage costs 5–10× more per GB than object storage (0.023/GB on AWS)
- Serving — Relational databases aren't designed to serve static blobs at high throughput; CDNs can't pull directly from PostgreSQL
This points toward separating metadata from content: database for structured metadata (fast queries, indexes), object storage for bulk text content (cheap, durable, CDN-compatible).
Why not object storage for everything?
If object storage is cheaper and more scalable, why not store everything there?
Without a database, we lose the ability to:
- Query "find pastes expiring tomorrow" without scanning all objects
- Build admin dashboards showing paste counts by day or by size
- Implement rate limiting based on a user's recent paste count
- Run efficient collision checks during ID generation (primary key constraint)
Object storage excels at blob retrieval by key but has no query, indexing, or transaction capability. By keeping metadata in the database we get cheap bulk storage AND queryable structured data — each system doing what it does best.
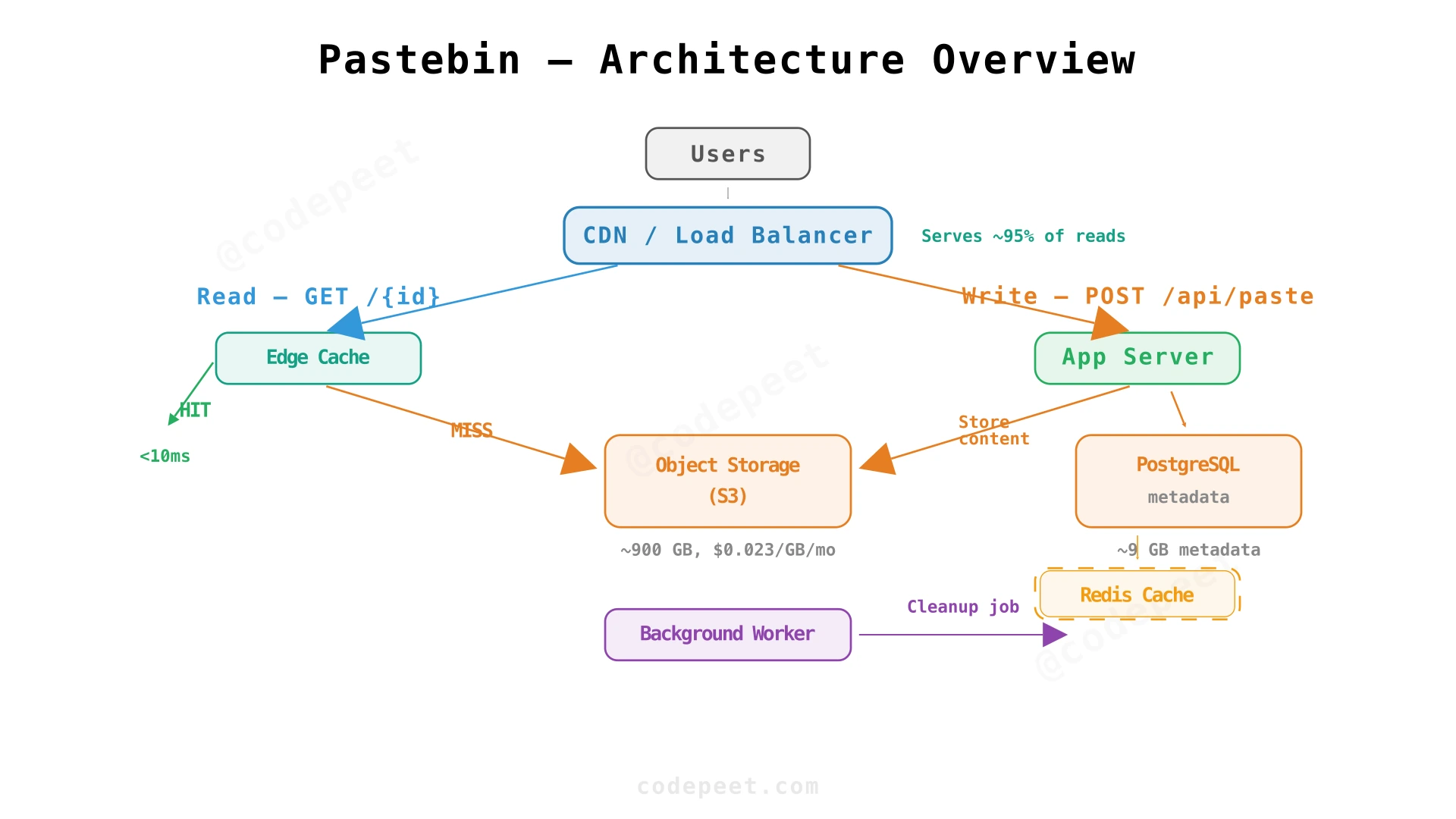
The Write Path
When a user creates a paste, the system executes these steps:
- Request arrives at the load balancer and routes to an application server
- Validate — Check content size (reject > 1 MB), parse expiry duration
- Generate ID — Create a unique 8-character alphanumeric identifier
- Store content — Write the text to object storage at path
/{id} - Save metadata —
INSERT INTO pastes (id, created_at, expires_at, size_bytes) - Return response — The short URL and delete token
The object storage write adds ~50ms of latency. This is acceptable for a write operation — users don't expect sub-10ms response when uploading content.
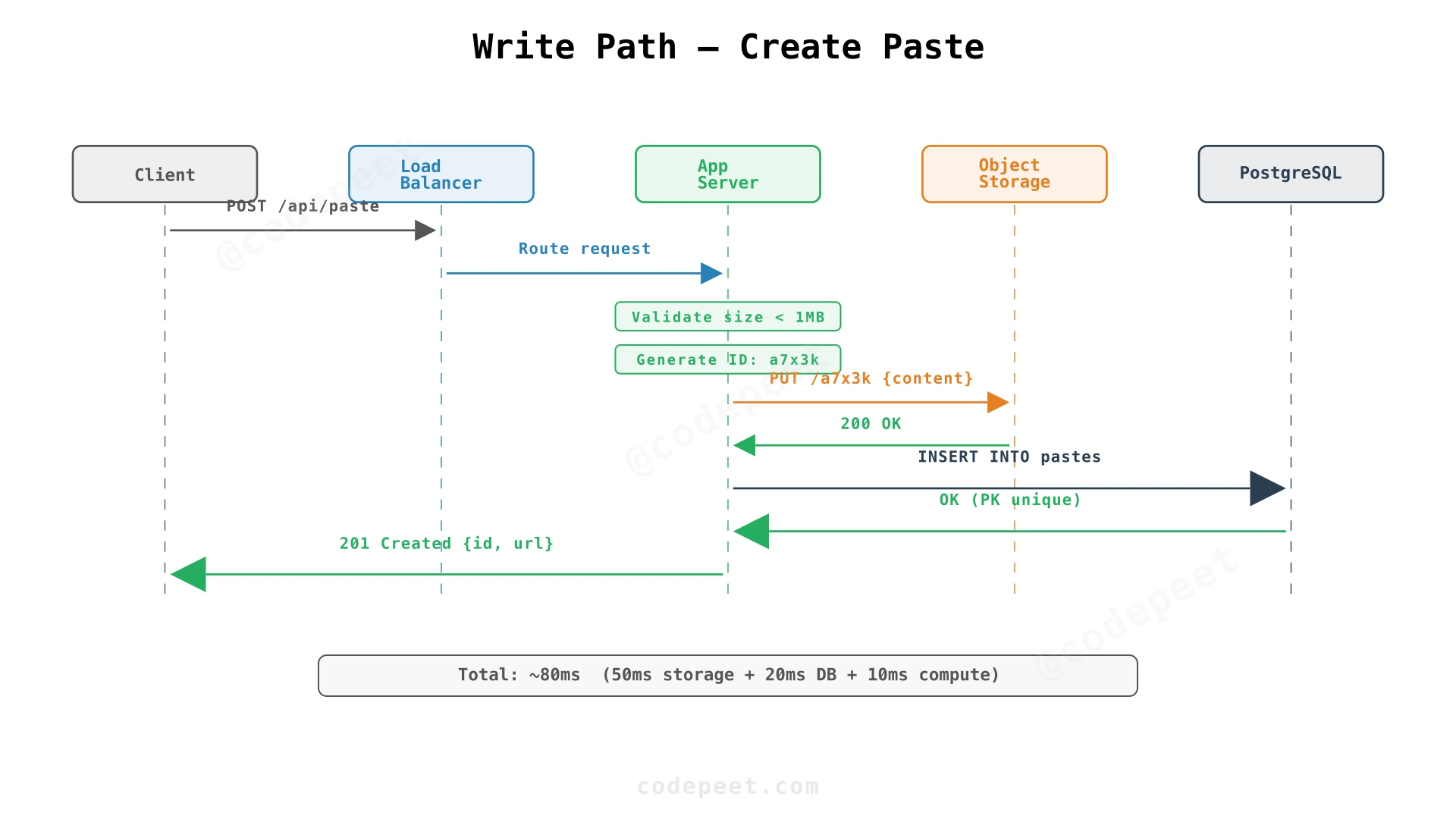
The Second Decision: How Do We Generate Unique IDs?
The short ID like a7x3k must be unique across all 90M pastes in the retention window, and — critically — must be unpredictable to prevent enumeration attacks.
Option 1: Auto-Increment + Base62 Encoding
The database generates sequential IDs (1, 2, 3...). Convert to base62: 1 → "1", 62 → "10", 1000000 → "4c92".
Advantage: Guaranteed unique with zero collision overhead.
Limitation: Sequential IDs are predictable. An attacker can enumerate a7x3k → a7x3l → a7x3m and systematically scrape every paste. Since pastes may contain sensitive code, credentials, or configuration files, this is a serious security vulnerability.
Option 2: Random Generation (Recommended)
Generate random 8-character strings from [a-zA-Z0-9] (base62). Attempt an INSERT; if the primary key constraint catches a collision, regenerate and retry.
Keyspace analysis: 62⁸ = 218 trillion possible IDs. With 90M pastes in the retention window, collision probability on any single attempt is 90M / 218T ≈ 0.00004% — negligibly small. The expected number of retries before a collision is ~2.4 million, meaning retries are astronomically rare.
Advantage: Unpredictable IDs resist enumeration. Implementation is simple — the database's PK constraint is the collision safety net.
Option 3: Pre-Generated ID Pool
A background worker pre-generates random IDs, validates uniqueness, and stores them in a pool (Redis list or database table). The write path pops an unused ID instantly — no collision check needed at write time.
Advantage: Zero ID-generation latency on the hot path.
Limitation: More moving parts — the pool must be monitored and refilled proactively. If the pool empties during a traffic spike (background worker can't keep up), writes fail. At 12 writes/sec baseline, this optimization provides minimal benefit for meaningful operational complexity.
Option 4: Bloom Filter for Collision Check
Maintain an in-memory Bloom filter containing all existing IDs. On write: generate random ID → check Bloom filter → if "maybe exists," regenerate; if "definitely not in set," proceed to INSERT (with PK constraint as the final safety net).
A Bloom filter is a space-efficient probabilistic data structure that answers: "definitely not in set" or "possibly in set." It eliminates ~99% of unnecessary database collision checks.
Advantage: Demonstrates knowledge of probabilistic data structures — a talking point in interviews.
Limitation: Collision probability is already 0.00004% — we're optimizing a non-problem. The Bloom filter adds memory overhead (~100 MB for 90M IDs at 1% false positive rate) and operational complexity (must be rebuilt on restart) for virtually no practical gain.
Our Choice: Random Generation
Random 8-character base62 strings with collision detection via the database primary key constraint. The collision check is "free" — it's just the INSERT itself. No separate lookup query needed. The implementation is simple, the security properties are strong, and the collision probability is negligible at our scale.
Data Schema
CREATE TABLE pastes (
id VARCHAR(8) PRIMARY KEY, -- Random base62: "a7x3k"
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
expires_at TIMESTAMP, -- NULL = default 3-month retention
size_bytes INTEGER NOT NULL, -- For analytics, rate limiting
state VARCHAR(10) DEFAULT 'ACTIVE' -- ACTIVE, GONE (soft delete for ID reservation)
);
-- Cleanup job: find expired pastes efficiently
CREATE INDEX idx_pastes_expires ON pastes(expires_at)
WHERE expires_at IS NOT NULL AND state = 'ACTIVE';
-- Analytics: paste count by day
CREATE INDEX idx_pastes_created ON pastes(created_at);The schema is intentionally minimal — 5 columns, small fixed-size rows. The actual text content lives in object storage at path /{id}, matching the URL structure. This keeps the database fast, backups quick (~9 GB), and queries efficient.
2. Retrieve Text
How do we serve pastes with sub-100ms latency at a 100:1 read-to-write ratio?
A teammate clicks pb.example/a7x3k in a GitHub issue and expects the page to load instantly. With 1,200 reads/sec (6K peak), we need a read path that scales without scaling the origin infrastructure proportionally.
The Baseline: Read Without Caching
Without optimization, every read follows this path:
- Parse ID from URL:
a7x3k - Query database:
SELECT * FROM pastes WHERE id = 'a7x3k' - Check if expired: compare
expires_atwith current time - Fetch content from object storage:
GET /a7x3k - Return content to user
At 1,200 reads/sec, the database handles metadata lookups fine — simple PK queries. But every read also fetches from object storage (~50ms), and since pastes are immutable (content never changes after creation), we're fetching identical bytes 100 times on average. This is exactly the pattern edge caching solves.
The Key Decision: How Do We Speed Up Reads?
Option 1: In-Memory Cache for Full Content
Cache the entire paste content in Redis or Memcached. Subsequent reads hit the cache instead of object storage.
Limitation: Memory is expensive and paste content is large. At 10 KB average, caching 50K hot pastes consumes 500 MB of RAM. In-memory caches are designed for small, fixed-size values (session tokens, metadata rows) — not multi-KB blobs. Large values cause memory fragmentation, eviction churn, and latency variance.
Option 2: In-Memory Cache for Metadata Only
Cache only metadata (existence, expiry time, state) in Redis. Content still served via CDN or direct object storage fetch.
Advantage: Small memory footprint (~100 bytes per entry). Fast "does this paste exist?" and "is it expired?" checks. Instant invalidation on delete.
At 1,200 reads/sec the database handles metadata lookups fine on its own, but a cache adds a safety margin for traffic spikes and reduces tail latency.
Option 3: CDN for Content (Recommended)
Place a CDN in front of the content origin (object storage). The CDN caches content at edge locations worldwide. First request for a paste fetches from origin; all subsequent requests from that edge hit the cache.
Why CDN is ideal for Pastebin:
- Paste content is immutable — once created, it never changes. Perfect for aggressive caching.
- CDN is purpose-built for serving static blobs at massive scale — it's literally what CDNs do.
- Geographically distributed edges reduce latency for users worldwide.
- CDN absorbs 95%+ of read traffic — the origin barely sees any load.
Limitation: CDN invalidation (for deletion) is eventually consistent — takes a few seconds to propagate globally. Acceptable for pastebin where instant deletion is not a hard requirement.
Our Choice: CDN for Content + In-Memory Cache for Metadata
CDN handles the heavy lifting of serving immutable text content at edge locations. Redis cache holds metadata for fast existence and expiry checks when the application server is involved (writes, deletes, edge function fallbacks).
How Does the CDN Integrate with the Domain?
The write path returns a short URL like pb.example/a7x3k. How does that request reach the CDN?
Option A: App Server Redirect
Client hits pb.example/a7x3k → app server checks metadata → returns 302 redirect to cdn.example/a7x3k.
Limitation: Every read hits the app server first. Adds latency (extra round trip) and load (app server in the read path for all requests). Defeats the purpose of CDN offloading.
Option B: CDN in Front of Domain (Recommended)
The main domain pb.example points directly to the CDN. The CDN routes requests based on path:
/{id}(paste IDs) → Object storage origin/api/*→ Application server origin
Users access pb.example/a7x3k directly — no redirect, no app server in the read path. Single domain, clean user experience. The CDN is configured with multiple origins and path-based routing rules.
Our Choice: CDN in front of the domain. Single domain, zero extra latency, and the app server is removed from the read path entirely for content requests.
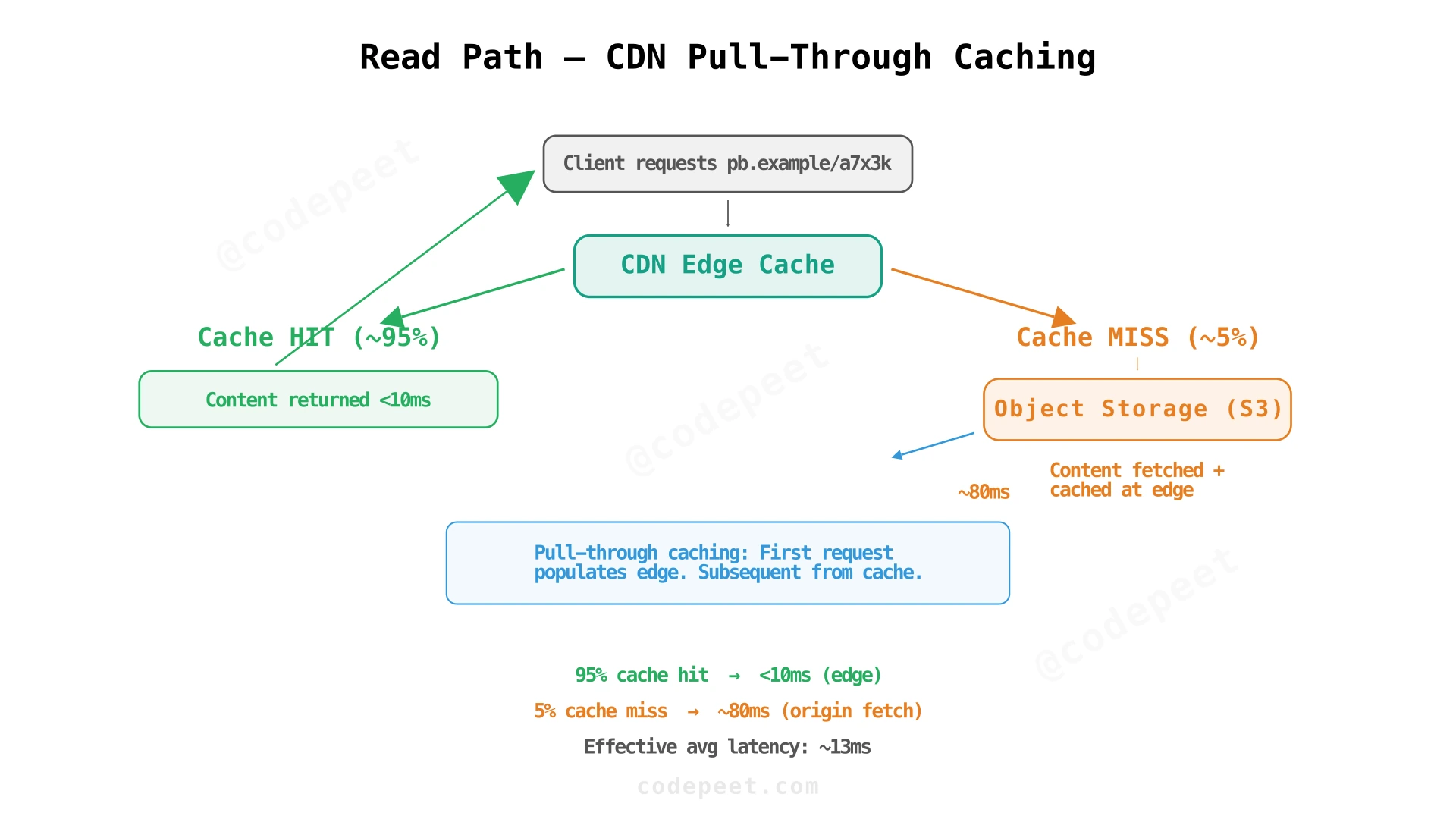
CDN Caching Behavior
CDNs use a pull-through pattern: on the first request for a paste, the CDN fetches from the object storage origin, caches the response at the edge location, and serves all subsequent requests from that edge's cache. This is ideal for Pastebin because:
- Most pastes are accessed shortly after creation (shared in an issue or chat), then traffic tapers off
- The CDN naturally keeps "hot" content cached and lets "cold" content expire
- Paste content is immutable — the cached version is always correct
CDN Configuration:
- TTL: Match paste expiry duration. For non-expiring pastes, use a reasonable default (24 hours). The CDN re-fetches from origin after TTL expires.
- Cache key: The URL path (
/a7x3k) serves as the natural cache key. - Invalidation on delete: Call the CDN purge API to remove the paste from all edge caches.
Handling Expired Pastes
With CDN-only reads, there's no app server to check expires_at on every request. Expired paste enforcement relies on the background cleanup job:
- Cleanup job runs on schedule (e.g., nightly or hourly), finds pastes where
expires_at < NOW() - Deletes content from object storage (saves storage costs — we pay per GB stored)
- Purges CDN cache for deleted paste IDs
- Marks paste metadata as
GONEin the database
After cleanup, requests for expired pastes return 404 from object storage (object doesn't exist). Before cleanup runs, expired content may still be served — this brief window is acceptable for most use cases. For immediate enforcement (e.g., sensitive credentials), see the deep dive on edge KV enforcement.
-- Cleanup job: delete expired pastes
-- 1-day buffer for timezone edge cases and user grace period
WITH expired AS (
SELECT id FROM pastes
WHERE expires_at < NOW() - INTERVAL '1 day'
AND state = 'ACTIVE'
LIMIT 10000 -- batch processing to avoid long transactions
)
UPDATE pastes SET state = 'GONE'
WHERE id IN (SELECT id FROM expired);
-- Then: delete objects from S3, purge CDN cache for each IDDeep Dive Questions
How do we handle traffic spikes when many users create pastes simultaneously?
Traffic Spike Handling
The baseline write rate is 12 writes/sec — trivially low. But what happens when AWS has a major outage and thousands of developers simultaneously paste error logs? Write QPS jumps from 12 to 1,200 — a 100× spike. The application servers are stateless and horizontally scalable (spin up more instances behind the load balancer), but all instances write to the same database.
Understanding the Bottleneck
At 1,200 writes/sec with each write taking ~50ms (object storage + DB insert), you need 60 concurrent database connections just to maintain throughput. A typical connection pool has 100 connections — the pool fills up, requests queue, timeouts cascade, and users see "Service Unavailable." The database is the bottleneck, not compute.
Option 1: Bigger Database (Vertical Scaling)
Upgrade to a more powerful database instance with more connections and higher IOPS.
Advantage: Works immediately — no code changes, no architectural changes.
Limitation: Expensive. Larger instances cost significantly more, and you're paying for that capacity 24/7 for spikes that happen a few times per year. A database instance sized for 100× baseline traffic is mostly idle.
The Key Insight: Users Don't Need Synchronous Persistence
Users need a URL immediately. They don't need their paste's metadata queryable in the same request. The actual content is already in object storage (durable) before the database write. This decoupling insight unlocks a much more efficient spike handling strategy.
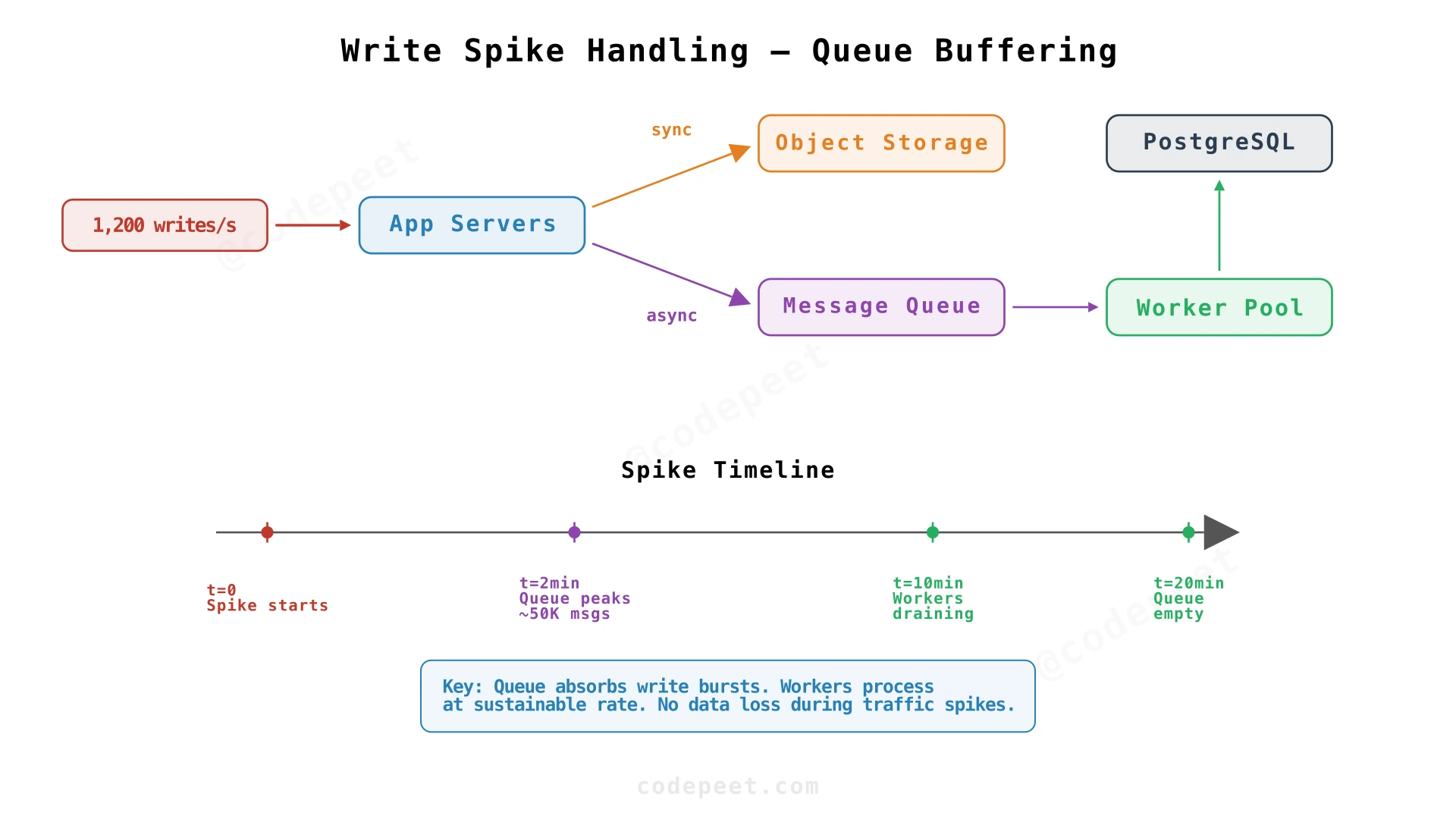
Option 2: Message Queue Buffering (Recommended)
Decouple the write path into two phases:
Phase 1 (Synchronous — user waits):
- Generate ID
- Store content in object storage
- Return URL to user
Phase 2 (Asynchronous — user doesn't wait):
4. Publish metadata to a message queue (Kafka, SQS)
5. Worker consumers process the queue at a steady rate
6. Workers write metadata to the database
During a spike, the queue absorbs the burst. At 1,200 writes/sec with workers processing 50/sec each, 24 workers drain the queue in real time. With fewer workers, the backlog clears within minutes. Users get their URLs instantly; metadata becomes queryable shortly after.
Why queue metadata instead of content? Message queues have size limits (typically 256 KB to 1 MB). Paste content can reach 1 MB. By storing content in object storage first and queueing only metadata (~100 bytes), we avoid hitting queue limits.
Eventual consistency trade-off: A user might share their URL before the metadata appears in database queries. But the content is already in object storage — the paste is readable immediately via CDN. Only metadata queries like "list my recent pastes" (which are out of scope anyway) would be delayed.
Option 3: Backpressure via Rate Limiting
When load exceeds capacity, return 429 Too Many Requests with a Retry-After header. Clients retry after the specified delay.
Advantage: Protects the system from overload with zero additional infrastructure.
Limitation: Users experience failures. Acceptable for free-tier services, frustrating for paying customers or during genuine emergencies (the exact moments people need pastebin most).
Our Choice: Message Queue Buffering + Rate Limiting as Safety Valve
| Traffic Level | Behavior |
|---|---|
| Normal (12 writes/sec) | Direct write to object storage + DB. Low latency, no queue overhead |
| High (100× spike) | Queue absorbs burst. DB writes drain at steady rate. Users still get URLs instantly |
| Extreme (queue depth exceeds threshold) | Rate limiting returns 429. Protects the queue from unbounded growth |
The slight delay in metadata availability is invisible to users. The paste is readable via CDN the moment the object storage write completes.
How would the design change at 100M or 1B daily active users?
Scaling the Design
Our current design handles 1M DAU comfortably with a single database, CDN, and minimal infrastructure. But what if the product scales by 10×, 100×, or 1000×? Each order of magnitude introduces new bottlenecks.
Recalculating the Numbers
| Scale | DAU | Write QPS | Read QPS | Storage (3 months) |
|---|---|---|---|---|
| Current | 1M | 12/sec | 1,200/sec | 900 GB |
| 10× | 10M | 120/sec | 12,000/sec | 9 TB |
| 100× | 100M | 1,200/sec | 120,000/sec | 90 TB |
| 1000× | 1B | 12,000/sec | 1.2M/sec | 900 TB |
At 10× (10M DAU): Expand CDN and Add Read Replicas
At ~12,000 reads/sec, the CDN handles content delivery without breaking a sweat — that's its purpose. But metadata queries increase: more "does this paste exist?" checks hit the database via edge function fallbacks.
Changes needed:
- Expand CDN edge locations for better global coverage. More edge nodes = lower latency worldwide.
- Add 1–2 PostgreSQL read replicas for metadata queries. Primary handles writes (120/sec — manageable); replicas absorb read spikes.
- Scale Redis cache if metadata cache miss rate increases.
The architecture stays fundamentally the same — just adding horizontal read capacity.
At 100× (100M DAU): Shard the Database
At 1,200 writes/sec, a single PostgreSQL primary becomes the bottleneck. Connection pools saturate, write latency spikes, and the cleanup job competes with writes for I/O.
Changes needed:
- Shard the metadata database by paste ID. Hash-based routing:
shard_id = hash(paste_id) % num_shards. With 10 shards, each handles ~120 writes/sec — comfortable. - Message queue becomes mandatory for write-spike absorption (no longer optional).
- Scale the Redis cache cluster with consistent hashing for key distribution.
- Object storage scales transparently — S3/GCS handle petabyte scale natively.
The random ID generation strategy pays off here: random IDs distribute evenly across hash-based shards. Sequential IDs would create hot shards.
At 1000× (1B DAU): Multi-Region Architecture
At 12,000 writes/sec globally, single-region deployment can't provide acceptable latency for users on other continents. Cross-Atlantic round trips add 100–150ms — exceeding our latency target before any processing begins.
Changes needed:
- Multi-region deployment — US, EU, APAC regions each with full infrastructure stack
- Global load balancing routes users to the nearest region (GeoDNS / Anycast)
- Cross-region object storage replication — A paste created in the US must be readable from Europe within seconds
- Conflict resolution — Trivial for Pastebin (IDs are globally unique, pastes are immutable)
- 900 TB storage moves to tiered architecture: hot tier (recent 7 days), warm tier (7–30 days), cold tier (30–90 days)
- Cleanup coordination across regions — deletion must propagate to all replicas
Summary: What Triggers Each Change
| Bottleneck | Scale Threshold | Solution |
|---|---|---|
| Content latency for global users | Users on multiple continents | Expand CDN edge locations |
| Metadata read throughput | Single cache/DB read path saturated | Add read replicas + cache nodes |
| Write throughput | Single DB primary saturated (~500 writes/sec) | Database sharding by paste ID |
| Regional latency | Users far from single region | Multi-region deployment |
| Storage cost | 100+ TB | Tiered storage (hot/warm/cold lifecycle) |
Key principle: Don't over-engineer for scale you don't have. Our 1M DAU design is intentionally simple — single database, CDN, no sharding, no queue. Add complexity only when a specific bottleneck materializes and is measurable.
How do we enforce expiration immediately instead of waiting for the cleanup job?
Immediate Expiration Enforcement
A developer accidentally shares a paste containing database credentials. They realize the mistake after 10 minutes and set the paste to expire immediately. But with the current design, the paste remains accessible until the next cleanup job runs — potentially 15 hours later. For sensitive content, this is unacceptable.
Why Can't We Check Expiry on Every Request?
The read path goes: User → CDN Edge → Object Storage. There's no application server in this path. No component checks expires_at. The object exists in storage, so it gets served. The cleanup job is our only enforcement mechanism, and it runs on a schedule.
We need real-time expiry checks without routing every read through an application server — which would defeat the purpose of CDN caching.
Moving the Check to the Edge
Modern CDNs offer edge compute — lightweight functions that execute at edge locations before requests reach origin. Instead of checking expiry at our servers, we check it right where the request arrives. But the edge function needs to know when each paste expires. Where does it get this information?
Option 1: Query the Backend from Edge
The edge function calls the application server's API to check expires_at on every request.
Limitation: Every read now hits the backend. At 1,200 reads/sec, we've eliminated the benefit of CDN caching entirely — we're paying for CDN infrastructure while doing all the work ourselves. This is worse than not having a CDN at all (added latency from the edge-to-origin hop).
Option 2: Embed Expiry in Signed URLs
Encode the expiry time directly in the URL: pb.example/a7x3k?expires=1705410000&sig=abc123. The edge validates the HMAC signature and checks the embedded timestamp.
Advantage: No external lookups needed — everything is self-contained in the URL.
Limitation: The URL is frozen at creation time. If a user extends or shortens the expiry, the original URL is wrong. Anyone who bookmarked the URL with the original expiry continues using it — you can't update shared URLs retroactively.
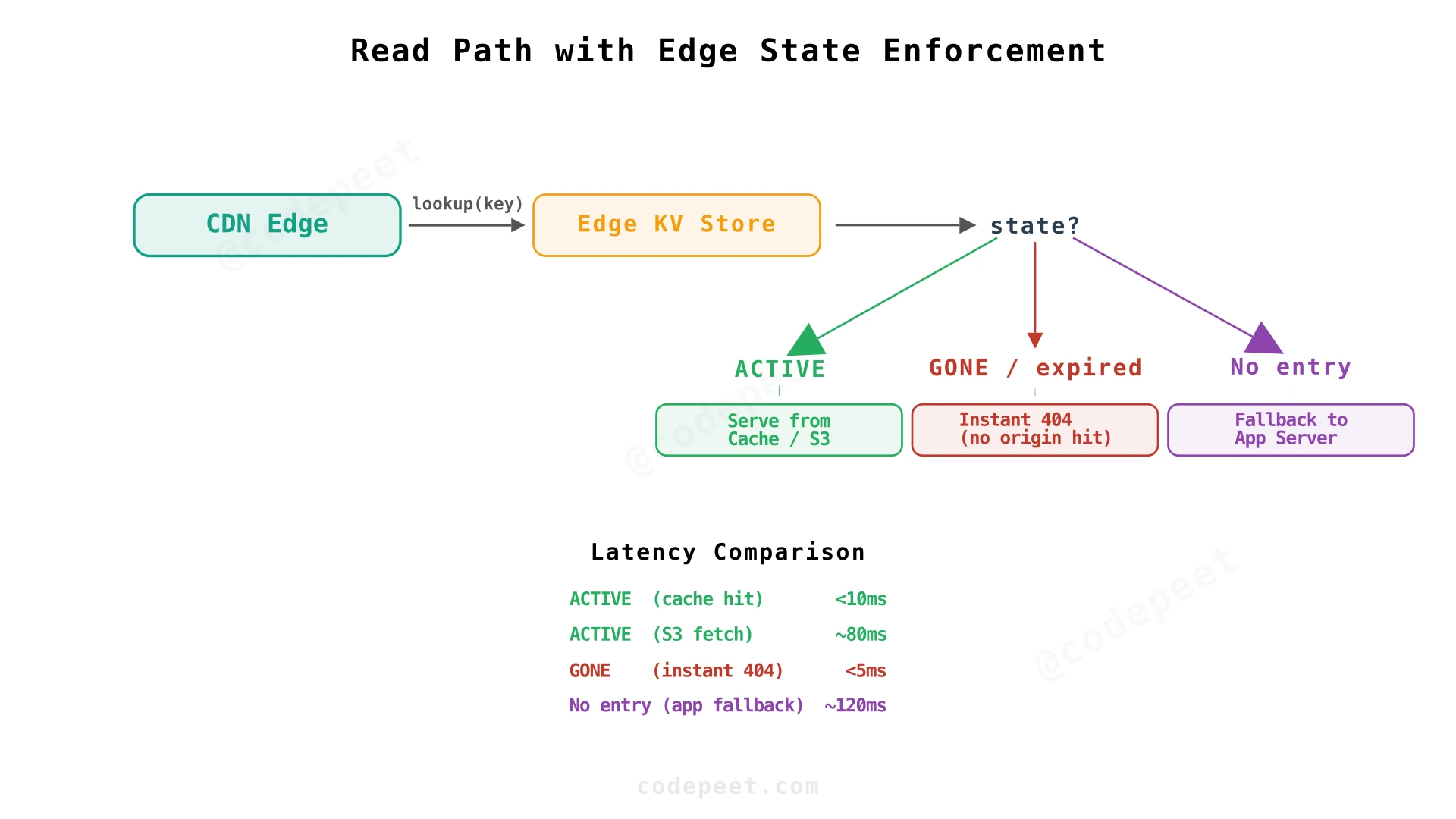
Option 3: Edge Key-Value Store (Recommended)
Store paste state in an edge KV store — a globally distributed key-value database replicated to CDN edge locations. Major CDN providers offer this natively: Cloudflare Workers KV, Fastly KV Store, AWS CloudFront KeyValueStore.
On paste creation, write state to edge KV:
key: "a7x3k"
value: {"state": "ACTIVE", "expires_at": "2026-03-18T12:00:00Z"}
On every read, the edge function:
- Looks up paste state in edge KV — sub-millisecond, no network round-trip to origin
- If
now >= expires_at→ return404 Not Foundimmediately - If state is
ACTIVEand not expired → proceed to fetch content from object storage
Advantages:
- Immediate enforcement — expiry takes effect within seconds of the timestamp
- Edge KV handles millions of reads/sec across global edge locations
- State can be updated (extend expiry, mark deleted) without changing the URL
- No origin load for expired/deleted pastes
Our Choice: Edge KV
Edge KV provides sub-millisecond state lookups without touching the backend. The edge function runs before every request reaches origin:
Updated Write Path with Edge KV
Creating a paste now includes an edge KV write:
- Generate random ID
- Write content to object storage
- INSERT metadata to database (PK uniqueness check)
- Write to edge KV:
id → {state: "ACTIVE", expires_at: "..."} - Return URL to user
The edge KV write propagates to global edge locations within ~50ms. By the time the user shares the URL, edges worldwide can enforce the expiry.
What Happens to the Cleanup Job?
The cleanup job's role changes:
| Before (without edge KV) | After (with edge KV) |
|---|---|
| Source of truth for expiration | Housekeeping only |
| Must run frequently for timely enforcement | Can run infrequently (nightly) |
| If it fails, expired pastes remain accessible | If it fails, edge KV still enforces expiry — just wastes storage |
Edge KV is now the source of truth for access control. The cleanup job saves storage costs by deleting objects we're no longer serving, but correctness doesn't depend on it.
How do we safely delete a paste without causing a thundering herd?
Deletion and Backend Protection
In the previous deep dive, we introduced edge KV to enforce expiration. Now consider deletion: a user deletes a popular paste with millions of cached copies across 200+ CDN edge locations. The obvious approach — delete the edge KV entry and purge the CDN cache — creates two serious problems.
Problem 1: The Thundering Herd
Imagine a viral paste getting millions of views is deleted:
- We delete the edge KV entry and call CDN purge
- CDN purge propagates across 200+ edges (takes seconds)
- After purge, all edges simultaneously have cache misses
- Edge functions check edge KV → "not found" → all forward to the app server
- App server is slammed with requests it rarely handles
The edge function can't distinguish "deleted" from "never existed" or "propagation delay" — when the KV entry is missing, it must fall back to the origin. Deleting the entry removes our edge protection precisely when we need it most.
Problem 2: ID Reuse
If we delete all records of a paste (object storage, database, edge KV), the ID a7x3k becomes available. The ID generator might accidentally reissue it. A user who bookmarked pb.example/a7x3k would see completely different content — a violation of URL stability that erodes trust.
With 218 trillion possible 8-character base62 IDs and only 90M active pastes, accidental collision is astronomically unlikely. But defensive engineering eliminates the possibility entirely — and the cost (keeping a database row) is negligible.
The Solution: Tombstones
Instead of deleting the edge KV entry, update it to a tombstone — a state marker that says "this paste was intentionally removed":
key: "a7x3k"
value: {"state": "GONE"}
When the edge function checks:
- Edge KV lookup → finds
state: GONE - Returns
410 Goneimmediately - No app server hit, no database query, no thundering herd
The tombstone absorbs the traffic spike. Even with millions of requests per hour, the backend stays quiet.
Tombstone Lifecycle
Tombstones don't need to persist forever. Traffic to deleted content cools off exponentially:
- First hour: potentially millions of requests (if viral)
- After 24 hours: a trickle of stragglers
- After 72 hours: effectively zero
After traffic dies off, we remove the tombstone (edge KV entry with 72-hour TTL) and rely on cheaper protections: CDN negative caching (cache the 404 response for 60 seconds) and request coalescing (multiple simultaneous cache misses share one origin fetch).
What Gets Deleted vs. What Stays
| Storage Layer | After Deletion | Lifecycle | Purpose |
|---|---|---|---|
| Object storage | Content deleted immediately | Within minutes | Privacy compliance — actual data removed |
| Edge KV | Tombstone (state: GONE) | ~72 hours (TTL auto-expire) | Backend protection during traffic cooldown |
| Database | Keep id + state = GONE | Permanent (tiny row) | ID reuse prevention via PK constraint |
The Complete Delete Flow
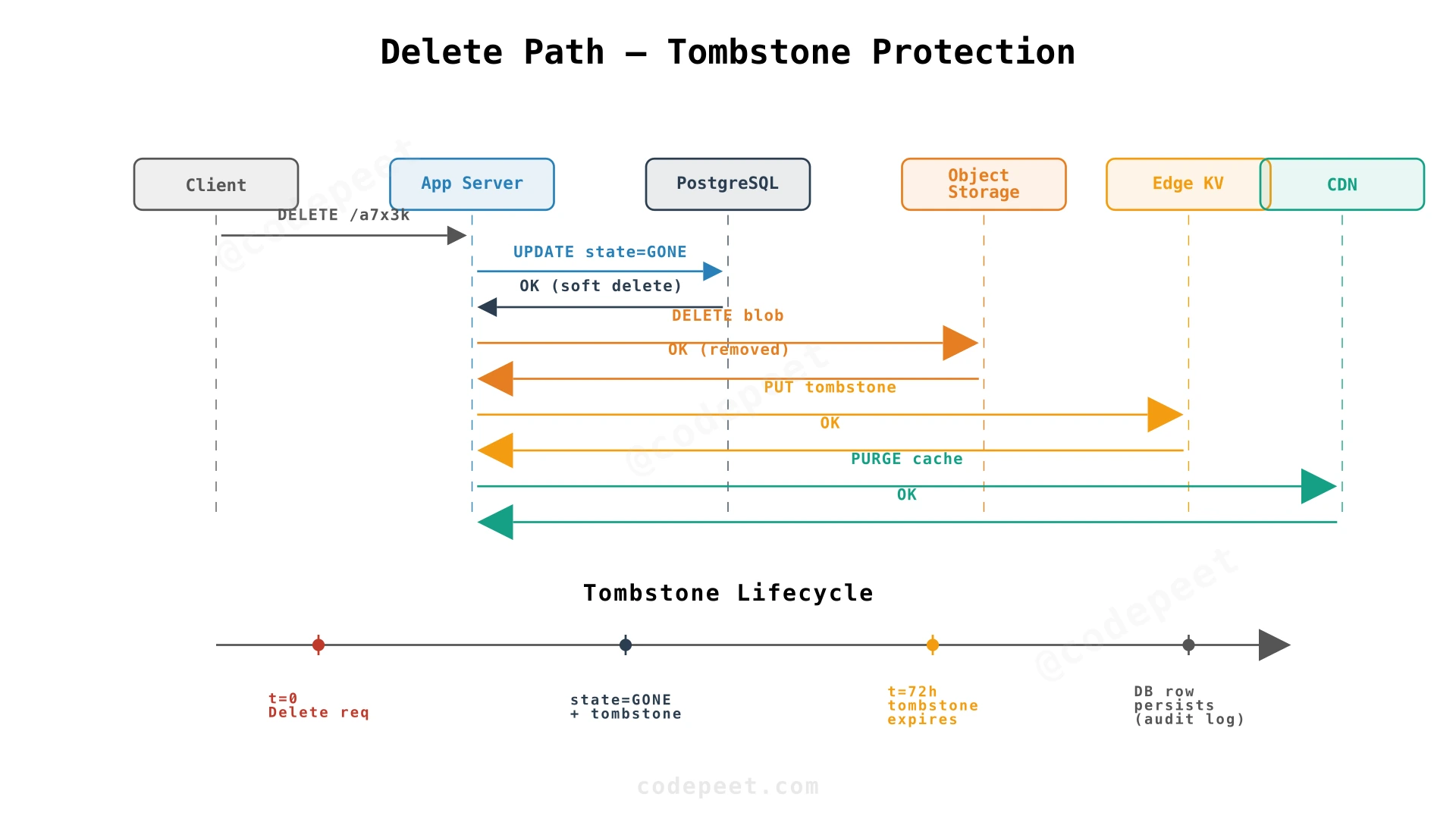
After 72 Hours (Tombstone Expires):
- Edge KV: No entry for
a7x3k→ miss - Request forward to origin → object already deleted →
404 - CDN caches the
404for 60 seconds (negative caching) - No thundering herd because traffic has died down to zero
Why 410 Gone Instead of 404 Not Found?
404is ambiguous — could mean typo, never existed, or propagation delay410explicitly signals "this resource existed and was intentionally removed"410tells caches this status is permanent — safe to cache aggressively
For privacy-sensitive applications, you might prefer 404 for everything (to avoid confirming a paste ever existed). The tombstone still works — you simply return 404 instead of 410.
Level Expectations
Pastebin is an entry-level system design problem that tests understanding of fundamental distributed systems concepts: storage separation, caching layers, and API design.
| Dimension | Mid-Level (L4) | Senior (L5) | Staff (L6) |
|---|---|---|---|
| Architecture | Identifies need to separate metadata from content storage | Explains trade-offs between SQL/NoSQL storage, designs for failure modes, chooses CDN + object storage | Considers multi-region deployment, cost optimization across storage tiers, edge compute patterns |
| Caching | Uses basic caching for reads (cache-aside pattern) | Compares CDN vs. application-level cache, explains when each applies, designs TTL strategy | Designs tiered caching (CDN + edge KV + in-memory), handles cache invalidation edge cases (thundering herd, tombstones) |
| Scalability | Calculates QPS and storage from scale requirements | Explains what changes at 10×/100× scale (read replicas, sharding, message queue), identifies which bottleneck appears first | Designs multi-region architecture, coordinates cross-region replication, tiered storage lifecycle |
| ID Generation | Recognizes need for unique IDs, mentions auto-increment or UUIDs | Compares random vs. sequential IDs, analyzes collision probability, explains security implications of predictable IDs | Discusses ID generation at multi-region scale (partition-aware generation, globally unique without coordination) |
Interview Cheatsheet
Core Architecture in 60 Seconds
"Separate metadata from content." Database for structured metadata (ID, expiry, size — fast queries, indexes), object storage for text content (cheap, durable, CDN-compatible). Object storage costs 5–10× less than database storage per GB.
"CDN for reads, app server for writes." With a 100:1 read-to-write ratio, CDN absorbs 95%+ of read traffic. The app server is not in the read path for content — CDN pulls from object storage directly. Writes are low-volume (12/sec) and latency-tolerant.
"Random IDs resist enumeration." 8-character base62 strings (218 trillion combinations). Collision probability at 90M pastes is 0.00004%. Database PK constraint is the collision safety net. No separate collision check needed.
"Expiry via cleanup job, enforced at edge." Background job deletes expired content from object storage (saves cost) and updates edge KV. Edge KV provides immediate enforcement at CDN edges — expired pastes return 404 without hitting origin.
Key Trade-offs to Mention
| Trade-off | Option A | Option B |
|---|---|---|
| Content storage | Database (simple, expensive, slow backups) | Object storage (cheap, durable, CDN-compatible) |
| Caching layer | In-memory cache (fast, expensive for blobs) | CDN (purpose-built for static content) |
| ID generation | Sequential (fast, predictable — security risk) | Random (secure, negligible collision probability) |
| Expiry enforcement | Cleanup job only (delayed, hours stale) | Edge KV (immediate, sub-second enforcement) |
| Spike handling | Over-provision DB (expensive, idle 99%) | Message queue buffering (efficient, eventual consistency) |
| Deletion strategy | Hard delete all records (thundering herd risk) | Tombstone + TTL (protects backend, prevents ID reuse) |
Common Mistakes to Avoid
- Storing text blobs in the relational database — causes fragmentation, bloated backups, and 5–10× higher cost
- Caching multi-KB content in Redis/Memcached — use CDN instead; in-memory caches are for small, structured data
- Using sequential IDs — trivial enumeration attack; use random IDs
- Forgetting expiration enforcement — cleanup job alone has hours of staleness; edge KV provides real-time enforcement
- Over-engineering at 12 writes/sec — this is an easy problem at baseline scale; add complexity only when bottlenecks appear