Introduction
"Design Twitter" is one of the most frequently asked system design interview questions — and for good reason. Twitter (now X) is deceptively simple on the surface: users post short messages and see a feed of messages from people they follow. But beneath that simplicity lies a system that serves 300 million daily active users, handles ~600 million tweets per day, and generates home timelines that blend content from hundreds of following relationships with a recommendation algorithm — all at sub-200ms latency.
The core design challenges that make Twitter such a rich interview problem:
- Fan-out at write vs. read time: When a user posts a tweet, should the system push it to all followers' timelines immediately (fan-out-on-write), or should each follower pull it when they open their feed (fan-out-on-read)? This single decision shapes the entire architecture.
- The celebrity problem: Lady Gaga has 84M followers. Fan-out-on-write means a single tweet triggers 84 million write operations. How do you handle users with millions of followers without melting the write path?
- Timeline ranking: Modern Twitter doesn't just show a chronological feed — it uses an ML ranking model to surface the most relevant tweets. This adds a real-time scoring step between data retrieval and display.
- Write throughput: At 300M DAU posting ~2 tweets/day on average, that's ~600M tweets/day — ~7,000 writes/sec steady, ~21,000/sec at peak. Each tweet must be durably stored and fanned out.
- Read throughput: With a 100:1 read-to-write ratio, the read path sees ~700K QPS average and ~2.1M QPS at peak. Caching and pre-computation are essential.
In this editorial we design Twitter from first principles — starting from requirements, estimating scale, choosing between fan-out strategies, designing the API and data model, and then diving deep into the timeline generation pipeline, caching, and the celebrity problem. Depth is stratified by seniority level.
Functional Requirements
We derive functional requirements from the verbs in the problem statement:
Core (must-have for MVP)
- Post Tweet — Authenticated users can post a short text message (up to 280 characters). Tweets are stored durably and visible on the author's profile and followers' timelines.
- Follow / Unfollow — Users can follow other users to see their tweets in the timeline. Unfollowing removes those tweets from future timeline loads.
- Home Timeline — Users see a feed of tweets from people they follow, ordered by a blend of recency and relevance (recommendation algorithm). Paginated via cursor.
- User Profile / User Timeline — View all tweets posted by a specific user, ordered by recency.
Extended (out of scope but worth mentioning)
- Retweets, quote tweets, and likes.
- @mentions and hashtags.
- Direct messages (DMs).
- Media attachments (images, videos).
- Search (full-text tweet search).
- Trending topics.
- Notifications.
Non-Functional Requirements
| Requirement | Target | Reasoning |
|---|---|---|
| Scale | 300M daily active users (DAU) | Twitter-scale platform |
| Write throughput | ~7,000 tweets/sec (peak ~21K/sec) | 300M users × 2 tweets/day |
| Read throughput | ~700K reads/sec (peak ~2.1M/sec) | 100:1 read:write ratio |
| Latency (timeline, p99) | < 200ms | Users expect instant feed loads |
| Latency (post tweet) | < 500ms response to author | Fan-out can happen asynchronously |
| Availability | 99.99% | Core social platform — downtime is PR-damaging |
| Consistency | Eventual (seconds) for timeline; strong for tweet storage | Followers may see tweets a few seconds late |
| Data retention | 5 years | Regulatory and analytics |
| Durability | No tweet loss | User-generated content is sacred |
The critical insight: Twitter is an extreme read-heavy system with a 100:1 read-to-write ratio. But unlike a key-value store, reads are aggregation queries — assembling a timeline from hundreds of different users' tweets. This makes the fan-out strategy the single most important design decision.
Resource Estimation
Assumptions:
- 300M daily active users
- 2 tweets per user per day → 600M tweets/day
- Average tweet size: 280 bytes (text) + 200 bytes (metadata) = ~480 bytes per tweet record
- Read:write ratio: 100:1
- Average user follows 200 accounts
- Data retention: 5 years
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily tweets | 300M × 2 | 600M/day |
| Write QPS (avg) | 600M ÷ 86,400 | ~7,000/sec |
| Write QPS (peak, 3×) | 7,000 × 3 | ~21,000/sec |
| Read QPS (avg) | 7,000 × 100 | ~700,000/sec |
| Read QPS (peak, 3×) | 700K × 3 | ~2,100,000/sec |
Storage Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily storage | 600M × 480 bytes | ~288 GB/day |
| Annual storage | 288 GB × 365 | ~105 TB/year |
| 5-year retention | 105 TB × 5 | ~525 TB total |
Fan-out Storage (Timeline Cache)
| Metric | Calculation | Result |
|---|---|---|
| Timeline cache per user | 200 tweets × 8 bytes (tweet_id) | ~1.6 KB/user |
| Total timeline cache | 300M × 1.6 KB | ~480 GB in Redis |
| Fan-out writes per tweet (avg) | avg followers: 200 | 200 cache writes per tweet |
| Fan-out writes/sec (avg) | 7,000 tweets/sec × 200 | ~1.4M cache writes/sec |
Bandwidth Estimation
| Metric | Calculation | Result |
|---|---|---|
| Write ingress | 21K/sec × 480 bytes | ~10 MB/sec (80 Mbps) |
| Read egress | 2.1M/sec × 480 bytes (avg page) | ~1 GB/sec (8 Gbps) |
The most surprising number: 1.4 million cache writes per second just for fan-out. This makes the fan-out pipeline the most infrastructure-intensive component.
API Design
Five core API endpoints grouped by service domain.
Request:
{
"content": "Just had the best coffee of my life ☕️",
"client_id": "t-9f2a3b81" // idempotency key
}Response: 201 Created
{
"tweet": {
"id": "tw-8c4e2f91",
"content": "Just had the best coffee of my life ☕️",
"author_id": "usr-04821",
"author_handle": "@alice",
"created_at": "2025-03-17T10:30:00Z",
"likes": 0,
"retweets": 0,
"replies": 0
}
}Design decisions:
- Idempotency key prevents duplicate tweets on network retries.
- Response returns the tweet immediately — fan-out to followers happens asynchronously.
- The tweet is durably stored before returning 201. Fan-out is eventually consistent.
Returns the user's personalized home timeline. Cursor-based pagination using the timestamp of the last seen tweet.
Response:
{
"next_cursor": "2025-03-17T10:25:00Z",
"tweets": [
{
"id": "tw-8c4e2f91",
"content": "Just had the best coffee of my life ☕️",
"author_id": "usr-04821",
"author_handle": "@alice",
"author_avatar": "https://cdn.example.com/avatars/alice.jpg",
"created_at": "2025-03-17T10:30:00Z",
"likes": 42,
"retweets": 7,
"replies": 3,
"liked_by_user": false
}
]
}Returns all tweets from a single user, ordered by recency. Simpler than home timeline — no fan-out or ranking needed, just a direct query on the author's tweets.
Response: 200 OK with updated follower/following counts. Follow triggers an async background job that loads the followed user's recent tweets into the follower's timeline cache. Unfollow removes those tweets.
High-Level Design
How does the overall system architecture work?
The architecture is organized around three independent services — Tweet Service, Follow Service, and Timeline Service — each with its own data store and scaling characteristics.
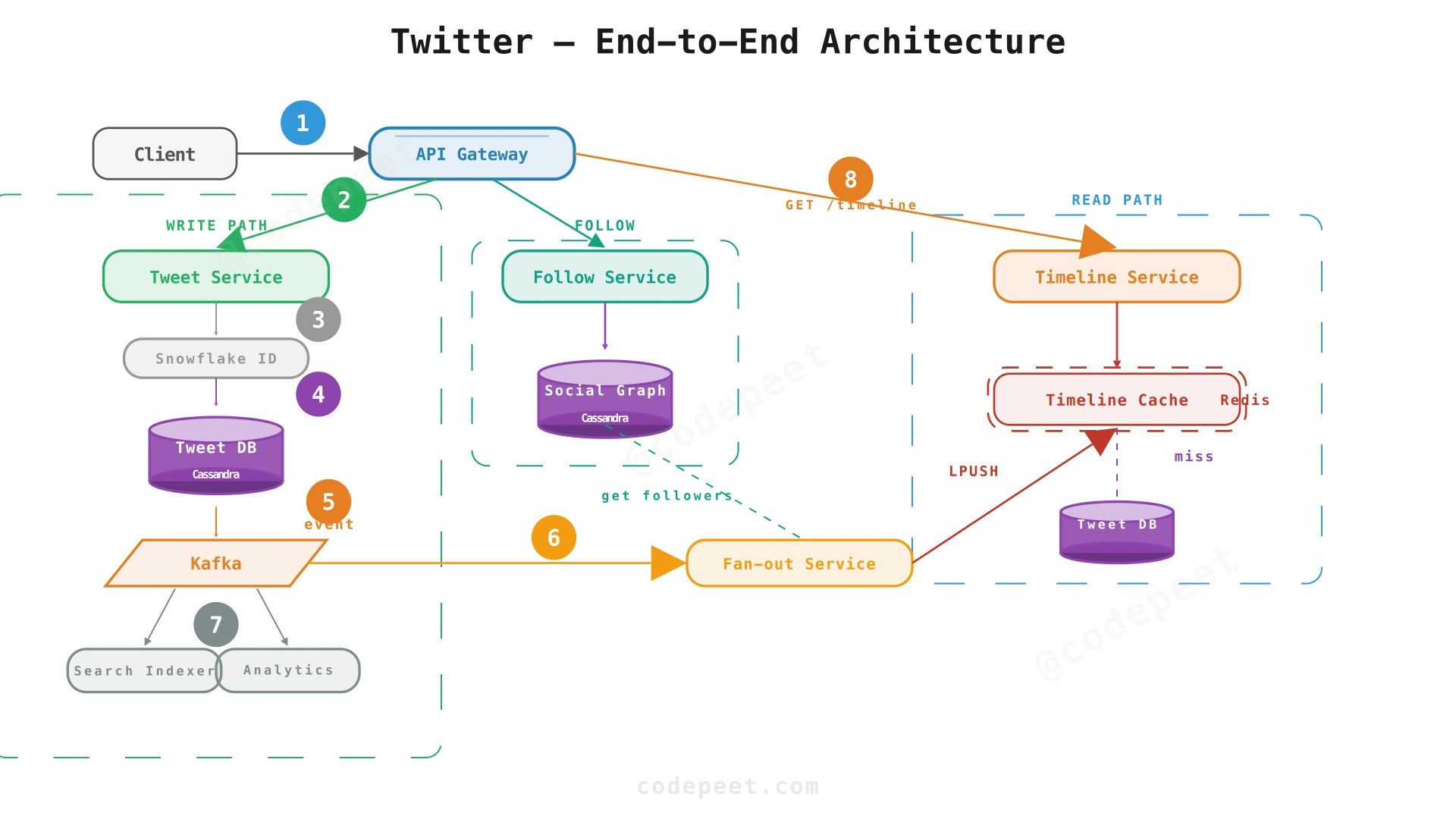
Write path (posting a tweet):
- Client sends POST /api/tweets to the API Gateway.
- Gateway routes to Tweet Service.
- Tweet Service generates a unique ID via the ID Generation Service (Snowflake).
- Tweet is written to Tweet DB (Cassandra) — synchronous, durable write.
- A
TweetCreatedevent is published to Kafka. - The Fan-out Service consumes the event and writes the tweet ID to every follower's Timeline Cache (Redis).
- Search Indexer and Analytics Pipeline also consume from Kafka.
- Client receives
201 Createdwith the tweet — fan-out is async.
Read path (loading timeline):
- Client sends GET /api/timeline to the API Gateway.
- Gateway routes to Timeline Service.
- Timeline Service reads the user's pre-computed timeline from Redis.
- For each tweet ID in the timeline, it hydrates the full tweet data (content, author info, engagement counts).
- Returns the hydrated, sorted timeline to the client.
Tweet Service handles writes at 21K QPS peak — it needs to be optimized for fast, durable inserts.
Timeline Service handles reads at 2.1M QPS peak — it needs to be optimized for ultra-fast cache lookups.
Follow Service handles social graph mutations (~relatively rare, bursty when a celebrity account goes viral) — it has different scaling characteristics.
Each service can scale horizontally and independently based on its own traffic patterns. A spike in timeline reads doesn't need to scale the tweet write path, and vice versa.
When a tweet is posted, multiple things need to happen: fan-out to followers' timelines, indexing for search, analytics ingestion, and (for certain tweets) notification dispatch.
If the Tweet Service called each downstream service synchronously:
- Write latency would be 200-400ms (4 sequential calls).
- If fan-out or search indexing is down, tweet posting fails.
- Adding new consumers (e.g., a new recommendation signals pipeline) requires changing the Tweet Service.
Kafka decouples all of this: Tweet Service publishes once, each downstream consumer processes independently. Adding a new consumer is zero-change to the producer. If a consumer falls behind, events queue up in Kafka — no data loss, no back-pressure on the write path.
Fan-out-on-write vs. fan-out-on-read: which strategy should we use?
This is the defining design decision for Twitter. Every interviewer will ask about it.
Fan-out-on-write (push model):
When a user posts a tweet, the system immediately writes the tweet ID to every follower's timeline cache. When a follower opens their timeline, the tweets are already pre-computed — the read path is a simple cache lookup.
Fan-out-on-read (pull model):
When a user opens their timeline, the system queries the tweets of every user they follow, merges and sorts them, and returns the result. Nothing is pre-computed.
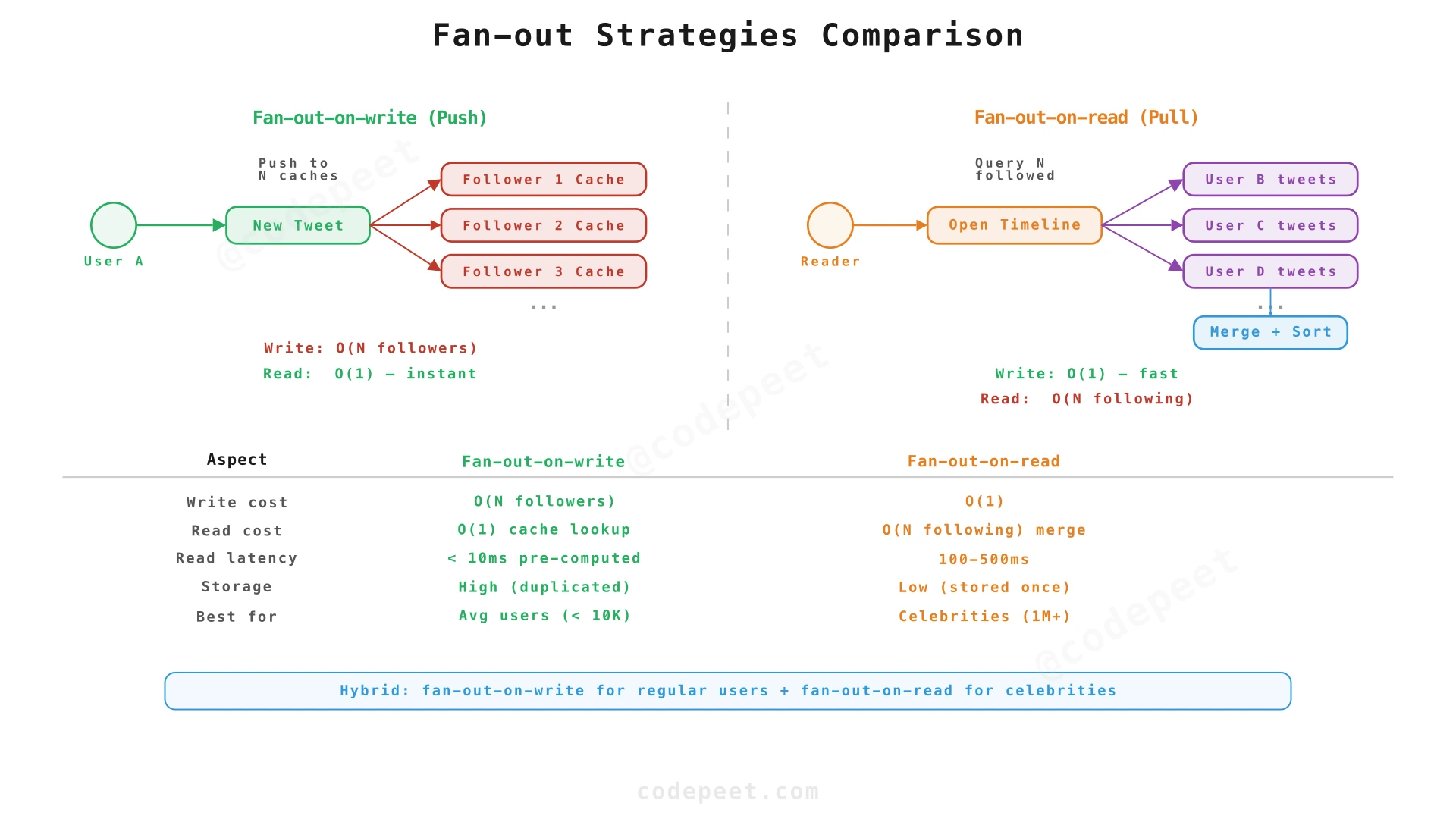
Comparison:
| Aspect | Fan-out-on-write | Fan-out-on-read |
|---|---|---|
| Write cost | O(N followers) per tweet | O(1) per tweet |
| Read cost | O(1) — cache lookup | O(N following) — merge N feeds |
| Read latency | < 10ms (pre-computed) | 100-500ms (merge at read time) |
| Write latency | Async — author doesn't wait | N/A |
| Storage | High — duplicate tweet IDs in every follower's cache | Low — store once |
| Best for | Average users (< 10K followers) | Celebrities (millions of followers) |
Recommendation: Fan-out-on-write for the majority, with a hybrid approach for celebrities. The real Twitter uses exactly this hybrid strategy.
Consider an average user with 200 followers. When they post a tweet:
- Fan-out-on-write: 200 Redis
LPUSHoperations (extremely fast — Redis does 100K+ ops/sec per node). - Fan-out-on-read: Every time the 200 followers open their timeline, the system queries all 200 accounts' tweets, merges them, and sorts — 200× more reads per timeline load.
With a 100:1 read:write ratio, the math overwhelmingly favors pre-computing timelines at write time. The write cost per tweet (200 cache inserts) is amortized across 100 reads that each cost O(1) instead of O(200).
Lady Gaga has 84 million followers. A single tweet triggers 84M cache writes. Even at 100K writes/sec per Redis node, that's 840 seconds (14 minutes) across one node — or 84 seconds with 10 nodes working in parallel. During that time, the fan-out queue for her followers backs up, delaying timeline updates for millions of users.
The hybrid approach:
- Define a "celebrity threshold" (e.g., users with > 100K followers).
- For non-celebrities: fan-out-on-write (push). Tweet IDs are eagerly written to all followers' caches.
- For celebrities: fan-out-on-read (pull). The tweet is NOT pushed to follower caches. Instead, when a follower loads their timeline, the Timeline Service:
- Reads the pre-computed timeline from their cache (non-celebrity tweets).
- Queries the recent tweets of each celebrity they follow (typically < 10 celebrities).
- Merges the two lists and returns the combined timeline.
This hybrid approach is what the real Twitter implemented, as described by Raffi Krikorian (Twitter's VP of Engineering) in his 2013 architecture talk.
Deep Dives
Data Model and Fan-out Pipeline
Database choice: Cassandra for tweets and social graph.
At 600M tweets/day and 300M DAU, we need a database optimized for:
- High write throughput (distributed, no single point of bottleneck).
- Time-series-like queries (get recent tweets by user, ordered by timestamp).
- Horizontal scaling (add nodes to handle growth).
Cassandra excels at all three. Its log-structured merge (LSM) tree storage is optimized for writes, and its partition-key + clustering-key model is perfect for "get all tweets by user X ordered by time".
-- Tweets table (partitioned by author_id, clustered by tweet_id descending)
CREATE TABLE tweets (
author_id UUID,
tweet_id BIGINT, -- Snowflake ID (embeds timestamp)
content TEXT,
created_at TIMESTAMP,
likes_count INT,
rt_count INT,
reply_count INT,
PRIMARY KEY (author_id, tweet_id)
) WITH CLUSTERING ORDER BY (tweet_id DESC);
-- Social graph: who does user X follow?
CREATE TABLE following (
user_id UUID,
followed_id UUID,
followed_at TIMESTAMP,
PRIMARY KEY (user_id, followed_id)
);
-- Social graph: who follows user X? (for fan-out)
CREATE TABLE followers (
user_id UUID,
follower_id UUID,
followed_at TIMESTAMP,
PRIMARY KEY (user_id, follower_id)
);
-- Users table
CREATE TABLE users (
user_id UUID PRIMARY KEY,
handle TEXT,
display_name TEXT,
avatar_url TEXT,
follower_count BIGINT,
following_count BIGINT,
is_celebrity BOOLEAN, -- true if follower_count > 100K
created_at TIMESTAMP
);| Aspect | Cassandra | DynamoDB | PostgreSQL |
|---|---|---|---|
| Write throughput | Excellent (LSM tree, tunable consistency) | Excellent (managed) | Good but needs sharding |
| Partition-key + sort-key queries | Native | Native | Requires manual partitioning |
| Operational control | Full control (self-hosted or DataStax Astra) | Fully managed (AWS lock-in) | Full control |
| Multi-region | Native multi-DC replication | Global Tables (limited) | Complex (Citus, pgbouncer) |
| Cost at scale | Lower (commodity hardware) | Variable (expensive at high throughput) | Moderate |
Cassandra's partition-key model maps perfectly to our access patterns:
tweetspartitioned byauthor_id→ "get all tweets by user X" is a single partition scan.followerspartitioned byuser_id→ "get all followers of user X" is a single partition scan (needed for fan-out).
The real Twitter originally used MySQL with sharding, then moved to a custom storage layer called Manhattan (essentially a distributed key-value store similar to Cassandra's model).
Timeline cache (Redis):
Each user has a Redis list that stores the tweet IDs in their timeline:
Key: timeline:{user_id}
Value: [tweet_id_1, tweet_id_2, ..., tweet_id_200] // capped at 200 entries
When the user opens their app, the Timeline Service:
LRANGE timeline:{user_id} 0 19— get the first 20 tweet IDs.MGET tweet:{id1} tweet:{id2} ...— batch-hydrate tweet content from a separate Redis cache.- Return the hydrated tweets.
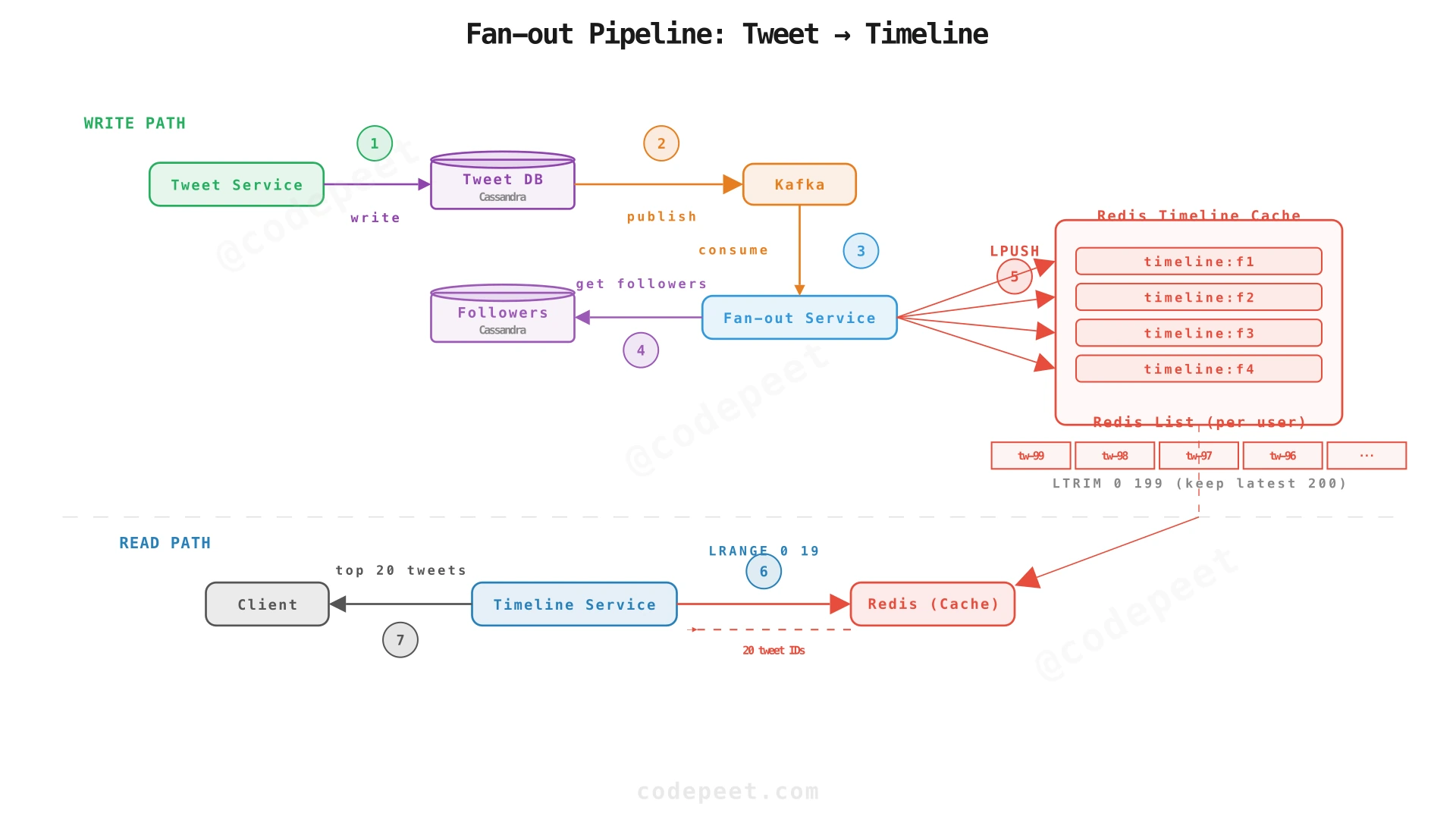
The Fan-out Service is the most write-intensive component. For each tweet from a non-celebrity:
- Look up the author's follower list from Cassandra (or a cached copy).
- For each follower, do
LPUSH timeline:{follower_id} tweet_idin Redis. - Do
LTRIM timeline:{follower_id} 0 199to cap the list at 200.
To handle 1.4M writes/sec:
- Parallel fan-out workers: 50 worker instances consuming from Kafka. Each processes ~28K writes/sec.
- Redis pipelining: Batch 100 LPUSH commands into a single Redis pipeline — reduces round-trip overhead by 100×.
- Redis cluster: 10 Redis nodes with consistent hashing. Each node handles ~140K ops/sec — well within Redis's capability of 500K+ ops/sec per node.
Each tweet needs a unique ID. Using a centralized auto-incrementing counter is a bottleneck. Twitter invented Snowflake — a distributed ID generation service that produces 64-bit IDs containing:
- 41 bits: Timestamp (millisecond precision) — makes IDs time-sorted.
- 10 bits: Machine ID — supports 1024 generator instances.
- 12 bits: Sequence number — supports 4096 IDs per millisecond per machine.
This means each machine can generate 4096 × 1000 = 4 million IDs/sec, and the total cluster can handle trillions of IDs/sec. Since IDs embed the timestamp, sorting by ID is equivalent to sorting by time — no need for a separate timestamp column for ordering.
Timeline Generation and Ranking
Modern Twitter doesn't show a purely chronological timeline — it uses an ML-based ranking algorithm to surface the most relevant tweets. This adds a scoring step between retrieving tweet IDs and returning the response.
Timeline generation pipeline:
- Candidate retrieval: Get 200 tweet IDs from the user's timeline cache (Redis).
- Hydration: Batch-fetch tweet content, author info, and engagement metrics.
- Feature extraction: For each tweet, compute features:
- Author features: follower count, engagement rate, historical tweet quality.
- Tweet features: age, likes, retweets, replies, media type.
- User-author features: interaction history (how often does this user engage with this author?).
- Ranking: An ML model (e.g., a lightweight neural network) scores each tweet 0-1.
- Filtering: Remove duplicates, already-seen tweets, and blocked users.
- Return: Top 20 tweets sorted by score.
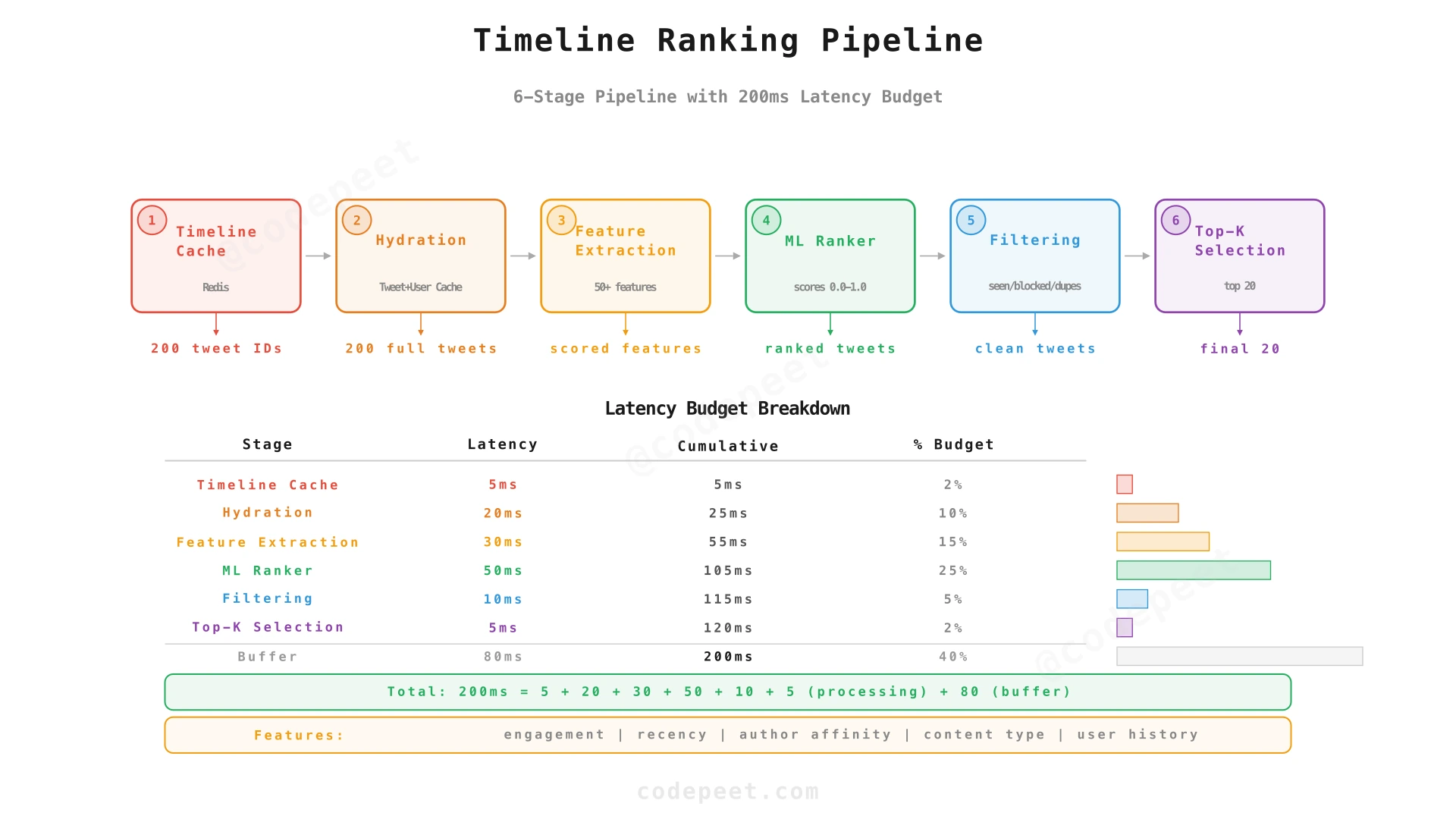
For the hybrid fan-out strategy, a follower's timeline is assembled from two sources:
-
Pre-computed cache (fan-out-on-write tweets from non-celebrities):
LRANGE timeline:{user_id} 0 199→ 200 tweet IDs. -
On-demand queries (fan-out-on-read tweets from celebrities the user follows):
For each celebrity (say 5 celebrities), query their latest tweets from Cassandra:
SELECT * FROM tweets WHERE author_id = ? LIMIT 20.
The Timeline Service merges these two lists, deduplicates, scores them through the ML ranker, and returns the top 20.
Performance impact: The celebrity queries add ~20-40ms to the read path (5 parallel Cassandra queries × ~5ms each). Compared to fanning out 84M writes, this is an excellent trade-off.
Not all 300M DAU are active at the same time. Many users haven't opened the app in days. Fanning out tweets to inactive users' caches wastes writes and memory.
Optimization: Only fan out to users who have been active in the last 3 days. For users who haven't been active:
- When they open the app, compute their timeline on-the-fly (fan-out-on-read) from the tweets of users they follow.
- Cache the result so subsequent reads are fast.
- Resume normal fan-out for this user going forward.
This reduces the fan-out write volume by 30-50% (since a large fraction of registered users are not daily active).
When a user follows a new account:
- The Follow Service writes the edge to the social graph (Cassandra).
- An async job fetches the followed user's latest 20 tweets from Cassandra.
- These tweet IDs are merged into the follower's timeline cache (Redis).
- The list is re-sorted by tweet_id (which is time-sorted via Snowflake) and trimmed to 200.
When a user unfollows an account:
- The Follow Service deletes the edge from the social graph.
- An async job removes all tweet IDs authored by the unfollowed user from the follower's timeline cache.
Both operations are eventually consistent — the user might see a brief period where the followed/unfollowed user's tweets appear or disappear.
Database Sharding, Caching, and Scaling
At 525 TB of tweet data over 5 years and 2.1M peak read QPS, both the data layer and cache layer need careful scaling.
Cassandra partitioning:
The tweets table is partitioned by author_id. This means all tweets from a single user live on the same Cassandra node — making the common query ("get tweets by user X") a single-partition read (the fastest query type in Cassandra).
| Partitioning key | Pros | Cons |
|---|---|---|
| author_id | Single-partition for user timeline; even distribution | Celebrity accounts create large partitions |
| tweet_id | Even distribution | User timeline requires scatter-gather across all nodes |
| compound (author_id + date bucket) | Limits partition size for celebrities | More complex routing |
Recommendation: author_id with partition splitting for celebrity accounts. Cassandra automatically distributes partitions across the ring using consistent hashing.
Memory estimation:
- 300M users × 200 tweet IDs × 8 bytes per ID = 480 GB of timeline data.
- Tweet content cache: 600M tweets/day × 5 days hot window × 480 bytes = ~1.44 TB.
- Total: ~2 TB of Redis memory.
Cluster sizing:
- Redis maxes at ~25 GB of useful data per node (leaving headroom for overhead).
- 2 TB ÷ 25 GB = 80 Redis nodes minimum.
- With replication factor 2 (for HA): 160 nodes.
QPS capacity:
- Each Redis node handles ~100K-500K ops/sec depending on operation type.
- 2.1M read QPS ÷ 100K/node = 21 nodes minimum for reads.
- Combined with 1.4M write (fan-out) QPS: need at least 35 nodes for throughput.
So we're memory-bound (80 nodes) rather than QPS-bound (35 nodes). 80 primary + 80 replica = 160 nodes.
With a 5-year retention policy:
Hot tier (0-30 days): Tweets in the last 30 days are most frequently accessed. These live in Cassandra with SSD storage and are cached in Redis for the timeline.
Warm tier (30 days - 1 year): Older tweets are migrated to a cheaper Cassandra cluster with HDD storage. Still queryable for user profile pages.
Cold tier (1-5 years): Archived to object storage (S3) for compliance. Queryable via batch jobs (Spark/Presto) but not real-time.
Beyond 5 years: Deleted per retention policy. Cassandra TTLs can handle this automatically.
Cassandra TTL on the tweets table:
INSERT INTO tweets (...) VALUES (...) USING TTL 157680000; // 5 years in seconds
Twitter serves users globally. For low latency, deploy in 3+ regions (e.g., US-East, EU-West, AP-Southeast).
- Cassandra: Native multi-DC replication with tunable consistency. Writes go to the local DC and replicate asynchronously to other DCs. Reads are served locally.
- Redis: Each region has its own Redis cluster with its own copy of timeline data. Fan-out happens locally in each region.
- Kafka: Cross-region replication with MirrorMaker 2. Tweet events published in US-East are replicated to EU-West and AP-Southeast, triggering local fan-out.
User-follows-user across regions: the Follow Service writes are replicated to all regions within seconds via Cassandra's multi-DC replication.
Tweet Delivery Guarantees and Edge Cases
Users post tweets expecting them to be visible. What happens when things go wrong?
Failure scenario 1: Fan-out worker crashes mid-distribution.
A tweet has been written to Cassandra and the TweetCreated event is in Kafka. The fan-out worker processes 50,000 out of 200,000 followers and crashes.
Solution: Kafka consumer offsets are only committed after the entire fan-out is complete. When the worker restarts (or another worker picks up the partition), it re-processes the event from the uncommitted offset. Some followers might get the tweet ID in their cache twice — this is idempotent (LPUSH of the same tweet_id is harmless; the Timeline Service deduplicates when reading).
Failure scenario 2: Redis node goes down.
A Redis node holding timelines for ~3.75M users (300M ÷ 80 nodes) crashes.
Solution: Redis replication — the replica is promoted to primary automatically by Redis Sentinel. At most a few seconds of fan-out writes are lost. When those users load their timeline, the Timeline Service falls back to constructing the timeline on-the-fly from Cassandra — this is slower but correct. The fan-out pipeline repopulates the cache as new tweets arrive.
When a user deletes a tweet, it must be removed from:
- Cassandra: soft-delete (mark as deleted) for compliance, then hard-delete after grace period.
- Redis (author's profile cache): remove tweet_id.
- Redis (every follower's timeline cache): scanning and removing a specific tweet_id from 200,000+ lists is expensive.
Practical approach: Don't eagerly remove from follower caches. Instead:
- Mark the tweet as deleted in the tweet content cache.
- When the Timeline Service hydrates tweet IDs, it skips deleted tweets.
- Over time, new tweets push deleted tweet IDs off the end of the 200-entry list.
This is a lazy cleanup approach — simple, efficient, and eventually consistent.
To prevent spam and abuse:
- Per-user tweet rate limit: Max 300 tweets/day, max 1 tweet per 15 seconds. Enforced via Redis counter with TTL:
INCR tweet_count:{user_id}:{date}, check < 300. - Per-user follow rate limit: Max 400 follows/day. Prevents mass-follow spam.
- Global rate limit: If total write QPS exceeds 3× steady-state, shed traffic via HTTP 429 with Retry-After header.
- Spam detection: Content analysis on tweets (URL blacklists, ML-based spam classifier). Flagged tweets are hidden from timelines pending review.
- Bot detection: CAPTCHA challenges for accounts that exhibit bot-like patterns (rapid-fire tweets, immediate follower-unfollower cycles).
Staff-Level Discussion Topics
These open-ended topics test architectural judgment. Use the discussion buttons to practice articulating your reasoning.
Currently, timelines are loaded on app open and paginated on scroll. For a more engaging experience, Twitter shows a "New tweets" indicator when fresh tweets arrive. How is this delivered?
Options:
- WebSocket/SSE: Server pushes "new tweets available" events to connected clients.
- Short polling: Client polls every 30 seconds for timeline updates.
- Long polling: Client holds an HTTP connection open; server responds when new data is available.
Twitter search requires indexing 600M tweets/day in near-real-time. A search for "Super Bowl" during the game should show tweets posted seconds ago.
Key challenges:
- Indexing throughput: 7K tweets/sec must be tokenized, analyzed, and added to the search index.
- Inverted index storage: 600M tweets/day × 30 tokens/tweet = 18 billion index entries/day.
- Query latency: Search results must return in < 200ms.
- Relevance ranking: Balance recency with engagement signals.
Twitter's "For You" feed uses a recommendation algorithm that surfaces tweets from accounts the user doesn't follow. This is a fundamentally different pipeline from the follow-based timeline.
The staff challenge: designing a recommendation pipeline that processes billions of candidate tweets across 300M users, scores them in real time, and blends them with the follow-based timeline.
Level Expectations
| Area | |||
|---|---|---|---|
| Requirements | Lists FRs (post, follow, timeline) and basic NFRs | Derives 7K write QPS, 700K read QPS; articulates 100:1 ratio implications | Fan-out write volume (1.4M cache writes/sec); inactive user optimization |
| Fan-out strategy | "Push tweets to followers" (fan-out-on-write) | Compares push vs pull; identifies celebrity problem; proposes hybrid | Calculates celebrity threshold; designs the merge pipeline; analyzes latency budget |
| Data model | Users/Tweets/Follows tables | Cassandra partition design; Snowflake IDs; timeline cache as Redis list | Compound partition keys for large accounts; multi-tier storage (hot/warm/cold) |
| API Design | Basic CRUD endpoints | Cursor pagination; idempotency keys; async fan-out acknowledgment | Opaque cursor tokens; rate limiting semantics; API versioning |
| Architecture | Client → Service → DB | 3-service split; Kafka event bus; Redis timeline cache | Multi-region deployment; Redis cluster sizing math; Kafka consumer groups |
| Caching | "Use Redis" | Timeline cache structure; tweet content cache; TTL strategy | 160-node Redis cluster sizing; stale-while-revalidate for timelines |
| Delivery guarantees | "Tweets should be delivered" | Idempotent fan-out; Redis failover; lazy deletion from cache | Consumer offset management; at-least-once vs exactly-once semantics |
Interview Cheatsheet
"Twitter is a 300M-DAU social platform where users post short messages and see a personalized feed. The core challenge is the timeline: assembling a feed from hundreds of followed accounts at 700K+ QPS. The architecture uses fan-out-on-write for regular users — tweets are pre-distributed to followers' Redis timeline caches via a Kafka-driven fan-out pipeline. Celebrities (>100K followers) use fan-out-on-read to avoid melting the write path. Timeline reads are a Redis LRANGE + hydration in under 200ms."
- FRs: Post tweet, follow/unfollow, home timeline (paginated, ranked), user timeline
- NFRs: 300M DAU, ~7K write QPS (peak ~21K), ~700K read QPS (peak ~2.1M), <200ms timeline latency
- Consistency: Eventual for timeline; strong for tweet storage
- Out of scope: Search, DMs, media, notifications, trending topics
- Tweet Service — stateless, writes to Cassandra, publishes to Kafka
- Follow Service — manages social graph in Cassandra
- Timeline Service — reads from Redis cache, hydrates tweets
- Fan-out Service — Kafka consumer, distributes tweet IDs to follower caches
- Cassandra — tweet storage + social graph, partitioned by user_id
- Redis — timeline cache (200 tweet IDs per user) + tweet content cache
- Kafka — event bus for TweetCreated events → fan-out, search, analytics
- ID Generation (Snowflake) — 64-bit time-sorted unique IDs
- Fan-out-on-write vs read: Write (push) for regular users, read (pull) for celebrities. Hybrid is the sweet spot.
- Consistency: Pre-computed timeline is eventually consistent — acceptable for social media.
- Cassandra vs relational: Cassandra for write throughput and partition-key queries; no JOINs needed for our access patterns.
- Snowflake IDs vs UUID: Snowflake embeds timestamp → time-sorted without secondary index.
- Cache size vs freshness: 200 tweet IDs per user balances memory (480 GB) with recency.
- Inactive user optimization: Skip fan-out for users inactive > 3 days; backfill on login.
| Metric | Value |
|---|---|
| DAU | 300M |
| Tweets per day | 600M |
| Read:write ratio | 100:1 |
| Write QPS (avg / peak) | 7K / 21K |
| Read QPS (avg / peak) | 700K / 2.1M |
| Fan-out cache writes/sec | 1.4M |
| Tweet size (with metadata) | ~480 bytes |
| Timeline cache per user | ~1.6 KB (200 IDs × 8B) |
| Total timeline cache | ~480 GB (300M users) |
| Redis cluster | ~160 nodes (80 primary + 80 replica) |
| 5-year storage | ~525 TB |
- "How would you handle trending topics?" — Real-time aggregation of tweet volume per hashtag using a sliding window counter in Redis. Kafka Streams for windowed counts.
- "How would you add retweets?" — A retweet is a new tweet with a
retweet_offield pointing to the original. Fan-out follows the same pipeline. - "How do you handle tweet editing?" — Store edit history in the tweet record. Invalidate the tweet content cache on edit. Timeline cache (which stores only IDs) is unaffected.
- "How do you prevent vote/like manipulation?" — One-like-per-user enforced by a unique index on (user_id, tweet_id). Rate limit likes per user per minute.
- "What about media (images/videos)?" — Upload to CDN (S3 + CloudFront). Tweet stores media_url. Fan-out and caching logic is identical — only the hydrated response includes media.