google-calendar
Introduction
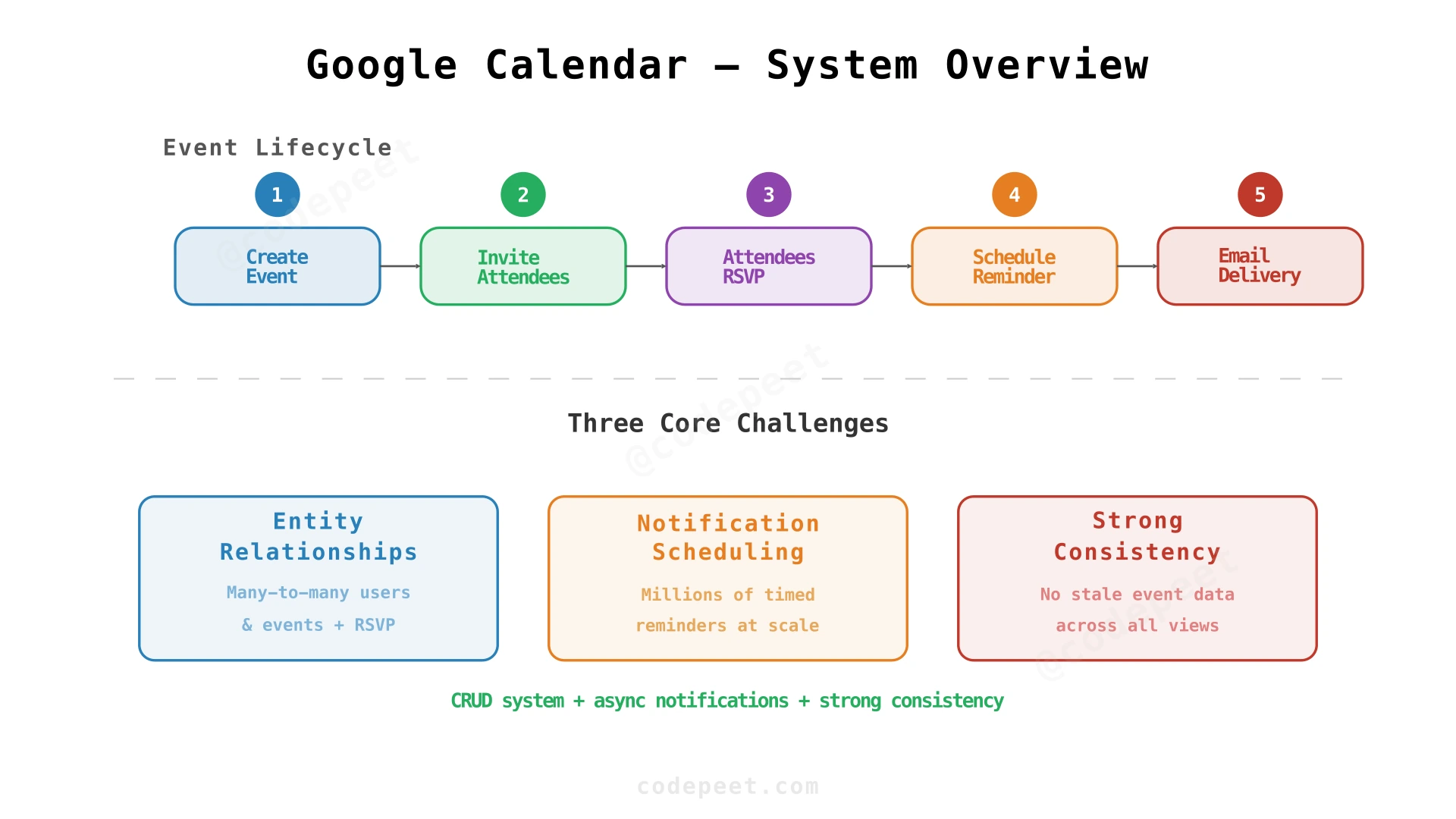
Google Calendar is a comprehensive calendar management system where users create events, invite attendees, RSVP, and receive automated reminders — it sounds straightforward until you dig into the design. Building a system like Google Calendar requires solving several interconnected problems:
-
Entity Relationship Complexity — A single event can involve multiple users with different roles (organizer vs attendee), each with their own RSVP status. The many-to-many relationship between users and events, combined with per-attendee metadata (rsvp_status, notification preferences), creates a schema that must be carefully modeled to support efficient queries.
-
Reliable Notification Scheduling — Every attendee must receive an email reminder exactly 30 minutes before an event. With millions of events, that means millions of notifications dispatched at precisely the right time. Late reminders are useless; duplicate reminders are annoying. This is essentially a distributed job scheduling problem disguised as a calendar feature.
-
Consistency Under Concurrent Access — When an organizer updates the meeting time while an attendee is RSVPing, both operations must complete correctly. The system can't show stale data — if a meeting was moved to 3pm, sending a reminder for the old 2pm slot is a bug, not a latency issue.
Unlike social media platforms where eventual consistency is acceptable for likes and comments, Google Calendar prioritizes data correctness and relationship integrity. Each event may involve multiple users, resources, time constraints, and access controls — making consistency and structured interactions central to the design.
At scale, the system serves ~10 million DAU. Users create ~3 events/day on average (~347 write QPS), and each event is accessed multiple times for viewing, syncing, and notifications (~3,472 read QPS). This is well within the capacity of modern cloud services, so the design focuses on correctness, relationships, and reliable async processing rather than raw throughput.
Functional Requirements
We extract verbs from the problem statement to identify core operations:
- "retrieves" events → Event retrieval by time range
- "creates, updates, deletes" events → Event CRUD
- "invites" attendees → Attendee management
- "RSVPs" to events → RSVP flow
- "notifies" attendees → Automated reminders
Each verb maps to a functional requirement that forms an event lifecycle: create → invite → RSVP → remind → retrieve.
-
Event Retrieval — Users retrieve their calendar events for a specific time range. Only calendar owners can view all events in their calendar.
-
Event CRUD — Calendar owners can create, update, and delete events. Modifications trigger notifications to attendees and update the notification scheduling system.
-
RSVP Management — Event attendees can RSVP (accepted / pending / denied) to events they're invited to. The system validates that only listed attendees can RSVP and triggers notifications about status changes.
-
Automated Notifications — The system sends email notifications to all event attendees 30 minutes before each event. The notification system must be reliable and handle large volumes efficiently.
Out of Scope
- Multi-calendar support per user
- Calendar sharing and permissions beyond owner/attendee
- Time zone handling and conversion
- Advanced recurring event patterns (discussed in deep dive)
- Integration with external calendar systems (CalDAV, iCal)
- Mobile push notifications (only email in scope)
- Event conflict detection and resolution (discussed in deep dive)
Non-Functional Requirements
We extract adjectives and descriptive phrases to identify quality constraints:
- "consistent" → Event data must be the same across all views
- "reliable" → Notifications must not be missed or duplicated
- "authorized" → Access control on every operation
- "scalable" → Millions of users and events without degradation
| NFR | Target | Reasoning |
|---|---|---|
| Strong Consistency | All users see the same event state at all times | A meeting moved from 2pm to 3pm must never show 2pm to any user — stale calendar data causes people to miss or arrive at wrong times |
| Notification Reliability | Every scheduled reminder delivered, zero duplicates | Late reminders are useless (the meeting already started). Duplicate reminders erode trust and clutter inboxes |
| Data Integrity | Foreign key constraints, valid state transitions | An attendee record must always reference a valid event and user. RSVP status must be one of: accepted, pending, denied — no invalid states |
| Security | Only authorized users can view/modify events | Calendar events contain sensitive information (meeting topics, attendee lists). Only the calendar owner can modify events; attendees can only RSVP |
| Availability | 99.9% uptime | Calendar is a coordination tool — downtime means teams can't schedule meetings |
| Scalability | 10M DAU, ~30M events/day | The system should handle growth without architectural changes |
Key insight: Unlike social media feeds where eventual consistency is fine, calendar systems demand strong consistency. If an event is updated, every attendee must see the latest state immediately. Stale data causes real-world consequences — people showing up at the wrong time, missing meetings, or RSVPing to cancelled events.
Resource Estimation
Scale Assumptions
| Parameter | Value |
|---|---|
| Daily active users (DAU) | 10 million |
| Events created per user per day | ~3 |
| Average attendees per event | ~5 |
| Read:Write ratio | ~10:1 |
| Average event record size | ~500 bytes |
| Average notification record size | ~200 bytes |
| Data retention | Indefinite |
Throughput
Write QPS (event mutations):
This is relatively low — a single relational database can handle this throughput comfortably.
Read QPS (calendar views, syncs):
Each user opens their calendar ~10 times/day (views, refreshes, syncs):
Including API calls per view (metadata, attendees, events for the week):
Notification throughput:
Events per day × attendees per event:
Fairly distributed over 24 hours (events aren't uniformly distributed — peak during business hours in each timezone):
Peak (business hours, ~8 hour window covering major timezones):
Storage
Event data (1 year):
Attendee records (1 year):
Notification records (1 year):
Total storage is modest (~22 TB/year) and well within the capacity of a sharded relational database.
Bandwidth
Inbound (writes):
Outbound (reads):
Bandwidth is negligible. The design is clearly compute-and-logic bound (notification scheduling, consistency enforcement) rather than bandwidth-bound.
API Design
We derive API endpoints from the functional requirements. All endpoints are RESTful — Google Calendar is a CRUD system with asynchronous side effects (notifications), not a real-time streaming system.
# ── Event Retrieval ───────────────────────────────────────────
GET /api/calendars/{calendarId}/events?start={ISO}&end={ISO}
Authorization: Bearer {token}
→ 200 OK
{
"events": [
{
"event_id": "evt_123",
"title": "Team Meeting",
"description": "Weekly sync",
"start_time": "2024-01-15T14:00:00Z",
"end_time": "2024-01-15T15:00:00Z",
"location": "Conference Room A",
"attendees": [
{ "user_id": "user_456", "rsvp_status": "accepted" }
]
}
]
}
# ── Event Creation ────────────────────────────────────────────
POST /api/calendars/{calendarId}/events
Authorization: Bearer {token}
{
"title": "Team Meeting",
"description": "Weekly sync",
"start_time": "2024-01-15T14:00:00Z",
"end_time": "2024-01-15T15:00:00Z",
"location": "Conference Room A",
"attendees": ["user_456", "user_789"]
}
→ 201 Created
{ "event_id": "evt_123", "status": "created" }
# ── Event Update ──────────────────────────────────────────────
PATCH /api/calendars/{calendarId}/events/{eventId}
Authorization: Bearer {token}
{
"title": "Updated Team Meeting",
"start_time": "2024-01-15T15:00:00Z"
}
→ 200 OK
{ "event_id": "evt_123", "status": "updated" }
# ── Event Deletion ────────────────────────────────────────────
DELETE /api/calendars/{calendarId}/events/{eventId}
Authorization: Bearer {token}
→ 200 OK
{ "status": "deleted" }
# ── RSVP ─────────────────────────────────────────────────────
POST /api/events/{eventId}/rsvp
Authorization: Bearer {token}
{ "rsvp_status": "accepted" }
→ 200 OK
{ "status": "rsvp_updated" }Design Decisions
- Calendar-scoped URLs (
/calendars/{id}/events) — Events belong to a calendar. This naturally scopes authorization: verify the requester is the calendar owner before returning events. - RSVP is event-scoped (
/events/{id}/rsvp) — The attendee's identity comes from the JWT token, not the URL. The service validates that the authenticated user is in the attendee list. - Side effects are async —
POST /eventsdoesn't wait for notification scheduling to complete. It writes the event, then publishes an event-changed message. Notifications are handled asynchronously by worker consumers.
Data Model
Five entities model the calendar domain. The key insight is that attendees is a join table with its own attribute (rsvp_status), not just a foreign key — it captures the many-to-many relationship between users and events.
users — Application accounts.
| Field | Type | Description |
|---|---|---|
user_id | UUID | Primary key |
email | TEXT | Unique, for notifications |
calendars — Each user owns one calendar (extensible to many).
| Field | Type | Description |
|---|---|---|
calendar_id | UUID | Primary key |
owner_id | UUID | FK → users |
events — Time-bounded items within a calendar.
| Field | Type | Description |
|---|---|---|
event_id | UUID | Primary key |
calendar_id | UUID | FK → calendars |
created_by | UUID | FK → users (organizer) |
title | TEXT | Event title |
description | TEXT | Optional description |
location | TEXT | Optional location |
start_time | TIMESTAMP | Event start |
end_time | TIMESTAMP | Event end |
attendees — Join table (many-to-many between users and events).
| Field | Type | Description |
|---|---|---|
event_id | UUID | FK → events (composite PK) |
user_id | UUID | FK → users (composite PK) |
rsvp_status | TEXT | accepted, pending, denied |
notifications — Scheduled email reminders.
| Field | Type | Description |
|---|---|---|
notification_id | UUID | Primary key |
event_id | UUID | FK → events |
user_id | UUID | FK → users |
notify_at | TIMESTAMP | When to send |
sent | BOOLEAN | Default false |
sent_at | TIMESTAMP | When actually sent |
Key indexes: events(calendar_id, start_time) for range queries, attendees(event_id, user_id) composite PK, notifications(notify_at, sent) for scheduler polling.
Relationships: users → calendars (1:many). calendars → events (1:many). events ↔ users via attendees (many:many). events → notifications (1:many).
High-Level Design
We build the architecture progressively, starting from single-user event CRUD and evolving through four iterations. Each step addresses a capability that the previous design lacks.
Step 1: Basic Event CRUD — Single-User Calendar
The Starting Architecture
Start with the simplest case: one user creates events and retrieves them by time range. No attendees, no notifications — just event storage and retrieval.
Event Service
A single stateless service handles all event operations. The client sends REST requests through an API Gateway, which authenticates the user (JWT) and forwards to the Event Service.
Authorization
The Event Service checks that the authenticated user owns the calendar before allowing any operation. This is a simple ownership check: calendar.owner_id == token.sub.
Indexed Range Queries
Calendar views always request events within a time window (a week, a month). The key query pattern is:
SELECT * FROM events
WHERE calendar_id = :calendar_id
AND start_time >= :range_start
AND start_time <= :range_end
ORDER BY start_time;A composite index on (calendar_id, start_time) makes this query efficient — it narrows to the user's calendar first, then scans the time range.
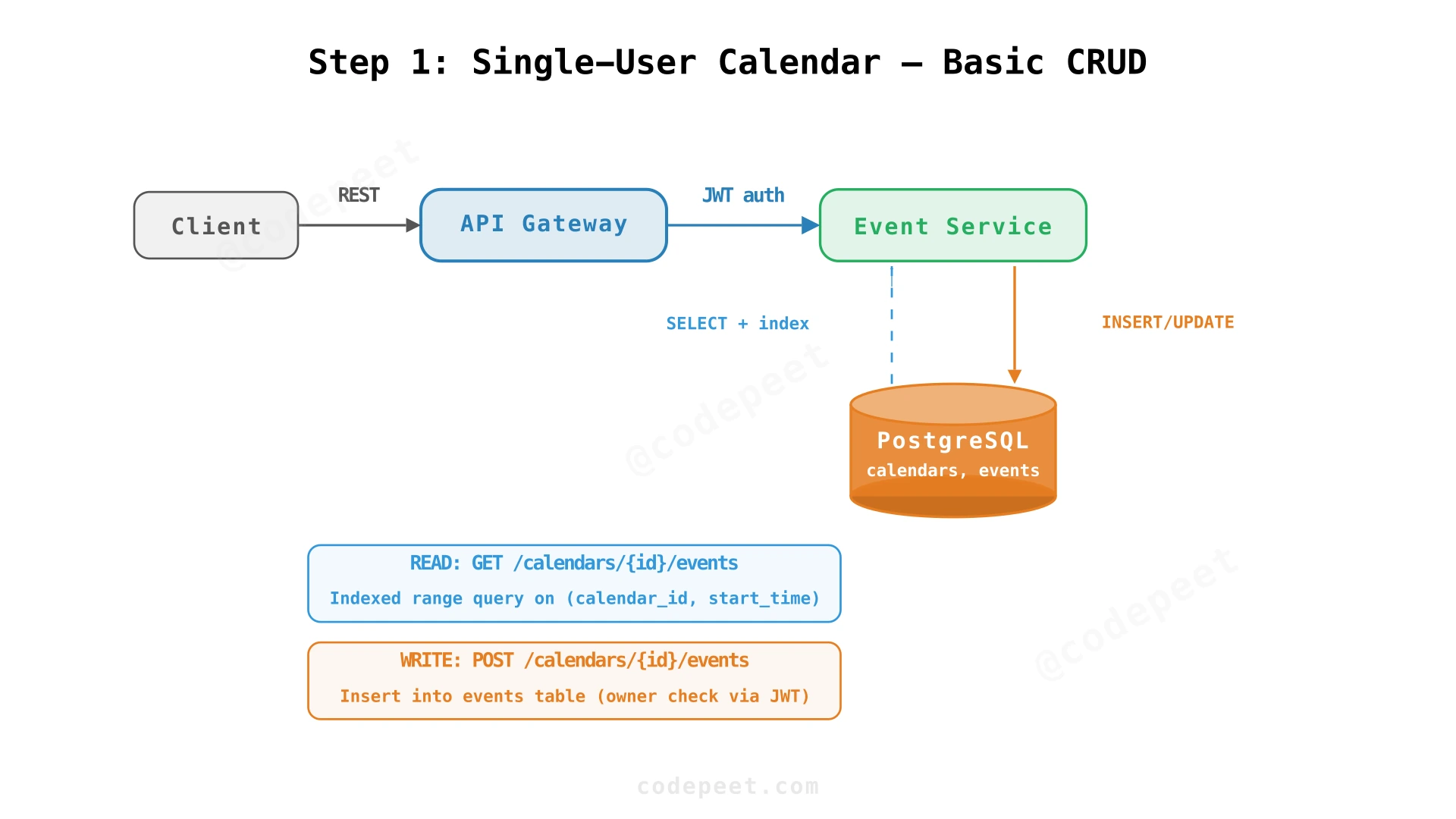
✅ Works for: A single user managing their own calendar events
❌ Missing: No attendees — events are single-user only. No notifications. No RSVP. No way to invite others to a meeting.
Step 2: Attendee Management & RSVP — Multi-User Events
Adding the Social Layer
A calendar without attendees is just a to-do list. Real value comes from multi-user events — invitations, RSVP tracking, and ensuring only valid attendees can respond.
The Attendees Join Table
Events and users have a many-to-many relationship. The attendees table captures this relationship with its own attribute — rsvp_status:
-- When creating an event with attendees:
BEGIN;
INSERT INTO events (event_id, calendar_id, created_by, ...)
VALUES (:event_id, :calendar_id, :creator, ...);
-- Auto-add creator as attendee with 'accepted'
INSERT INTO attendees (event_id, user_id, rsvp_status)
VALUES (:event_id, :creator, 'accepted');
-- Add invited attendees with 'pending'
INSERT INTO attendees (event_id, user_id, rsvp_status)
VALUES (:event_id, :invitee_1, 'pending'),
(:event_id, :invitee_2, 'pending');
COMMIT;RSVP Validation
When an attendee RSVPs, the service must validate two things:
- The user is actually in the attendee list (prevents unauthorized RSVP)
- The new status is a valid transition (accepted, pending, or denied)
The RSVP flow:
- Attendee sends
POST /events/{id}/rsvpwith their status - Event Service checks
attendeestable for(event_id, user_id)— if no row exists, reject with 403 - Update
rsvp_statusin the attendees table
Transactional Integrity
Event creation with attendees must be atomic — if the attendee inserts fail (e.g., invalid user_id), the event insert must also roll back. This is a natural fit for a SQL transaction wrapping all inserts.
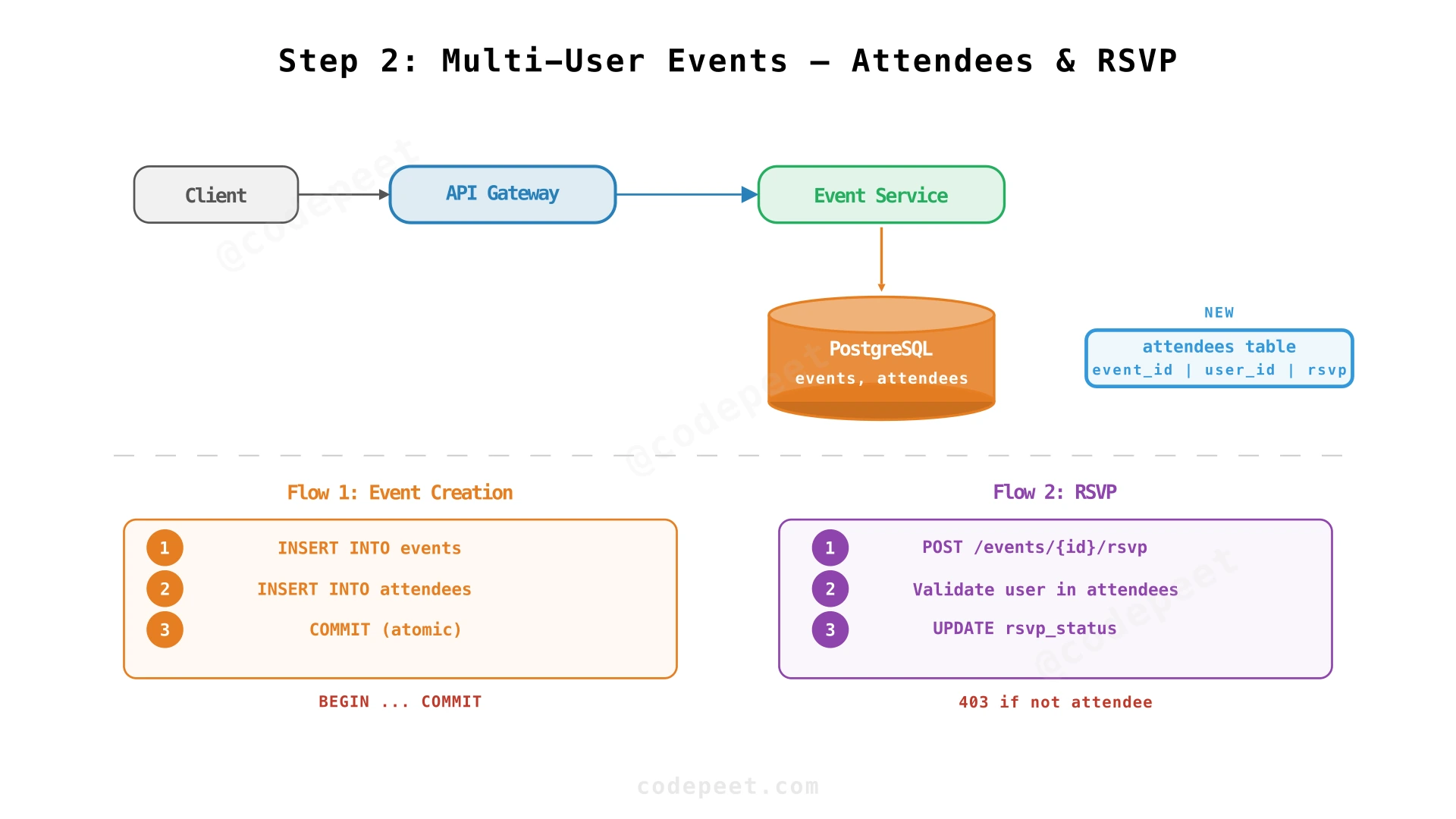
✅ NFRs addressed: Data integrity (transactional event+attendee creation), security (RSVP validation ensures only listed attendees can respond)
❌ Still missing: When an event is created or updated, attendees don't know about it. No notifications — the organizer could change the meeting time and attendees would never find out.
Step 3: Async Notification Pipeline — Scheduled Email Reminders
Making the Calendar Actually Useful
A calendar that doesn't remind you about meetings is barely better than a spreadsheet. Notifications transform it from a passive record into an active coordination tool. But notifications introduce asynchronous complexity: they must be scheduled for the future, survive service restarts, and handle failures gracefully.
Two Types of Notifications
- Immediate: Event created/updated/cancelled → notify attendees now
- Scheduled: Reminder 30 minutes before event start → deliver at
start_time - 30min
The Pipeline
We decouple event mutations from notification delivery using a message queue:
- Event Service writes the event to the database
- After commit, it publishes an
event-changedmessage to the queue - Notification Worker consumes the message and:
- For immediate notifications: sends emails via the Email Service
- For scheduled reminders: inserts rows into the
notificationstable withnotify_at = event.start_time - 30min
- A Scheduler periodically polls the
notificationstable for rows wherenotify_at <= now() AND sent = false - The Scheduler dispatches emails via the Email Service and marks rows as
sent = true
Why a Message Queue?
If the Event Service called the Email Service directly, a failed email would block the event creation response. The message queue decouples the write path from the notification path:
- Event creation always succeeds quickly (synchronous DB write)
- Notification delivery is retried independently (at-least-once via queue)
- If the notification worker is down, messages accumulate in the queue and are processed when it recovers
Handling Event Updates
When an event's time changes, existing notification rows become invalid. The Notification Worker must:
- Delete old unsent notification rows for that event
- Insert new rows with the updated
notify_attime
This is an idempotent operation — processing the same event-changed message twice produces the same result.
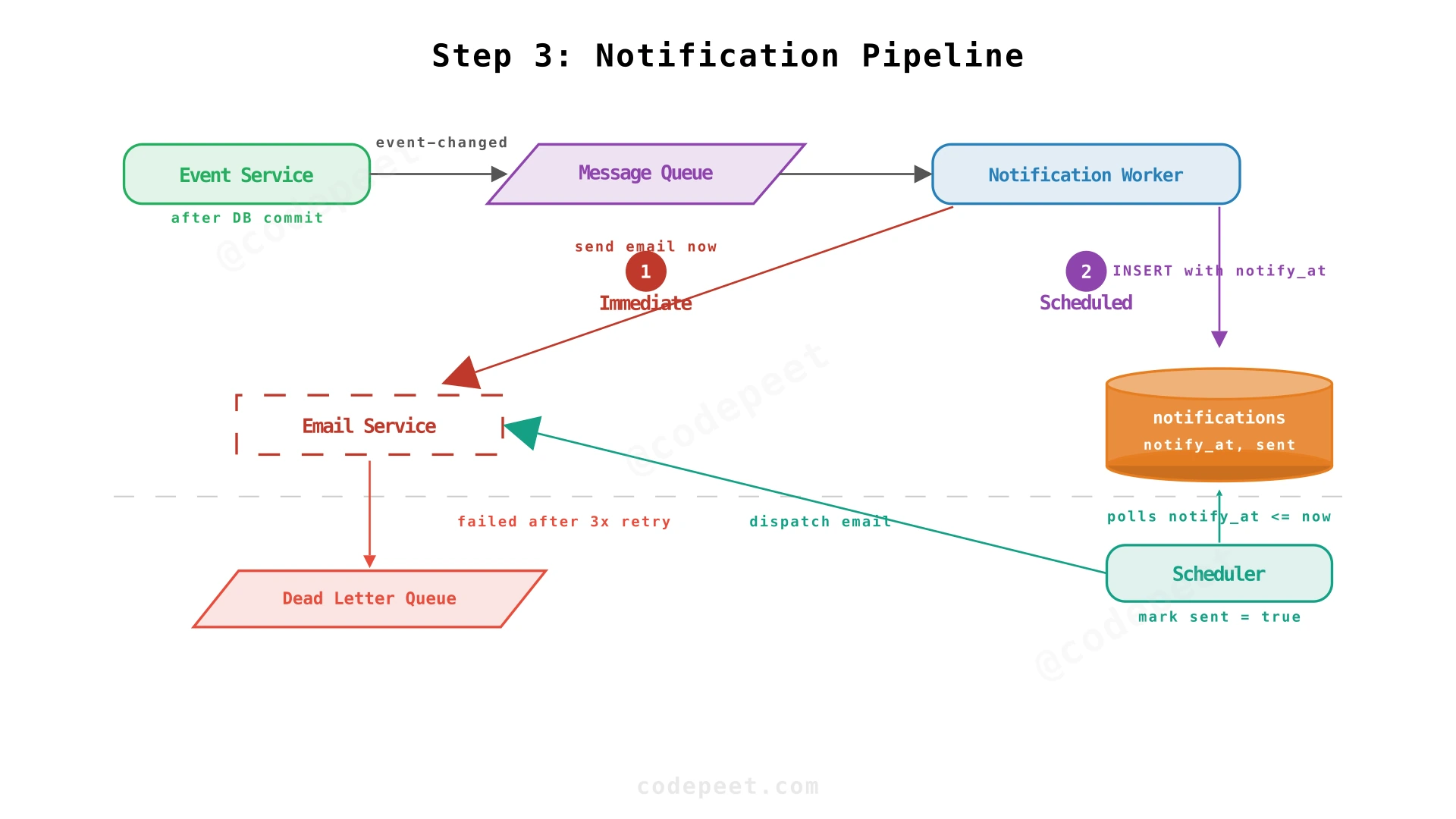
Failure Handling
- Email delivery failure: Retry 3 times with exponential backoff. After 3 failures, move to a Dead Letter Queue (DLQ) for manual review.
- Scheduler crash: On restart, it simply polls
notify_at <= now() AND sent = false— unprocessed rows are picked up. No state is lost. - Duplicate notifications: The
sentflag prevents re-sending. The Scheduler usesUPDATE ... WHERE sent = false RETURNING *to atomically claim rows.
✅ NFRs addressed: Notification reliability (at-least-once delivery via queue + DLQ), availability (async pipeline doesn't block event writes)
❌ Still missing: No support for recurring events — a user can't create "Team standup every Monday at 9am" without creating 52 separate events. No concurrent modification handling.
Step 4: Recurring Events — RRULE Storage and Virtual Expansion
The Feature That Changes Everything
Recurring events are by far the most complex feature in any calendar system. A simple "weekly standup" generates potentially infinite instances — you can't store them all. The system must generate instances on the fly while supporting exceptions ("skip next Monday" or "move this Friday's meeting to Thursday").
RRULE: The Industry Standard
We use the iCalendar RFC 5545 RRULE format — a well-defined standard with open-source libraries for parsing and expanding rules:
ALTER TABLE events ADD COLUMN recurrence_rule TEXT;
-- Example values:
-- 'FREQ=WEEKLY;BYDAY=MO,WE,FR' (Mon/Wed/Fri weekly)
-- 'FREQ=MONTHLY;BYMONTHDAY=15' (15th of each month)
-- 'FREQ=DAILY;INTERVAL=2' (Every 2 days)
-- 'FREQ=WEEKLY;BYDAY=MO;UNTIL=20241231T235959Z' (Weekly until end of 2024)Querying: Two-Phase Approach
When a user requests events for a time range, we query two categories:
- Non-recurring events — straightforward range query on
start_time:
SELECT * FROM events
WHERE calendar_id = :cal_id
AND recurrence_rule IS NULL
AND start_time >= :range_start
AND start_time <= :range_end;- Recurring events — select all recurring series that started before the query end:
SELECT * FROM events
WHERE calendar_id = :cal_id
AND recurrence_rule IS NOT NULL
AND start_time <= :range_end;Then expand each recurring event in application code using an RRULE library (e.g., rrule.js) to generate instances within the requested range. Merge both result sets into a single list sorted by start_time.
Exceptions to Recurring Events
Users often modify or cancel individual instances ("move this Monday's standup to Tuesday"). We handle this with an exceptions table:
CREATE TABLE recurrence_exceptions (
exception_id UUID PRIMARY KEY,
parent_event_id UUID REFERENCES events(event_id),
original_date TIMESTAMP NOT NULL, -- which instance
replacement_event_id UUID REFERENCES events(event_id), -- NULL = cancelled
UNIQUE (parent_event_id, original_date)
);- Skip an instance: Insert an exception with
replacement_event_id = NULL - Modify an instance: Create a new standalone event and reference it as the replacement
During expansion, the service checks the exceptions table and substitutes or removes instances accordingly.
Notification Scheduling for Recurring Events
We can't pre-schedule notifications for all future instances (infinite series). Instead, a rolling window scheduler creates notification rows for the next 7 days. A daily cron job refreshes the window.
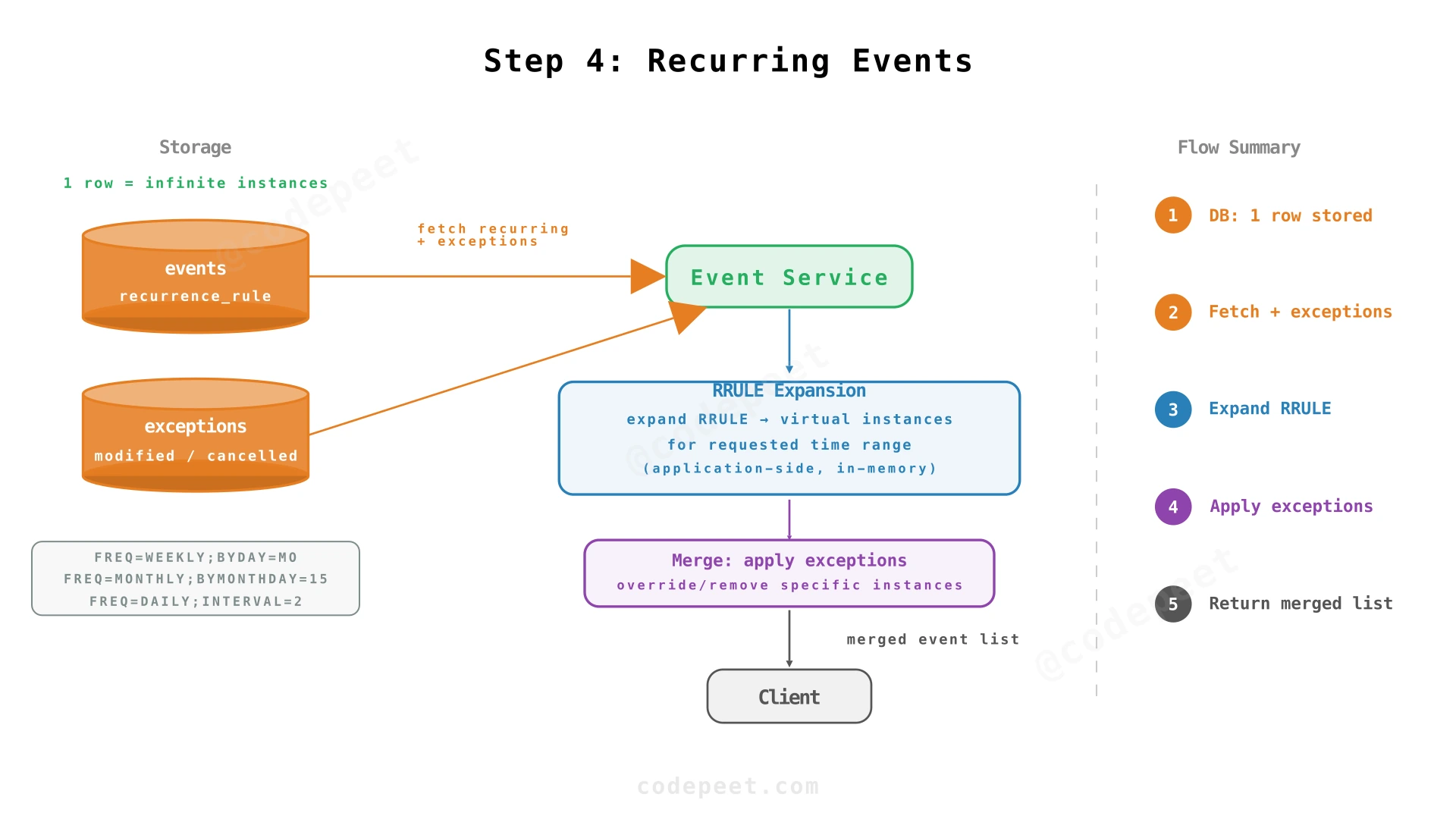
✅ NFRs addressed: Scalability (one DB row represents infinite instances), data integrity (exceptions cleanly override individual occurrences)
❌ Still missing: No conflict detection — two events can overlap without warning. No concurrent modification handling — two users editing the same event simultaneously can overwrite each other's changes.
Step 5: Complete Architecture — Conflict Detection & Concurrent Modifications
The Final Architecture
The last pieces address event conflicts and concurrent modifications — features that make the calendar reliable enough for enterprise use.
Conflict Detection & Free/Busy Queries
Users need to see availability before scheduling. The system exposes a free/busy API that merges time ranges:
- Fetch all accepted events for a user in a time range
- Merge overlapping intervals (classic greedy algorithm)
- Return busy blocks — other users see these as unavailable times
Conflict detection at event creation is a warning, not a block — Google Calendar allows double-booking but shows a visual warning.
Optimistic Locking for Concurrent Modifications
When multiple users can edit events (e.g., shared calendars in the future), concurrent modifications must not silently overwrite each other. We use optimistic locking with a version field:
ALTER TABLE events ADD COLUMN version INTEGER DEFAULT 1;
-- Update with version check:
UPDATE events
SET title = :new_title,
start_time = :new_start,
version = version + 1
WHERE event_id = :event_id
AND version = :expected_version;
-- If 0 rows affected → conflict, ask user to retryIf the version doesn't match, the update fails and the client receives a 409 Conflict response. The client fetches the latest state and asks the user to re-apply their changes — a reject-and-retry approach that's simple and effective for the low edit frequency of calendar events.
Caching Layer
Calendar views are read-heavy (10:1 read/write ratio). A Redis cache layer reduces database load:
- Cache key:
calendar:{calendarId}:events:{weekStart}→ list of events for that week - Invalidation: On any event mutation, invalidate the cache entry for the affected calendar and time range
- TTL: 5 minutes — stale data window is short enough for a calendar app
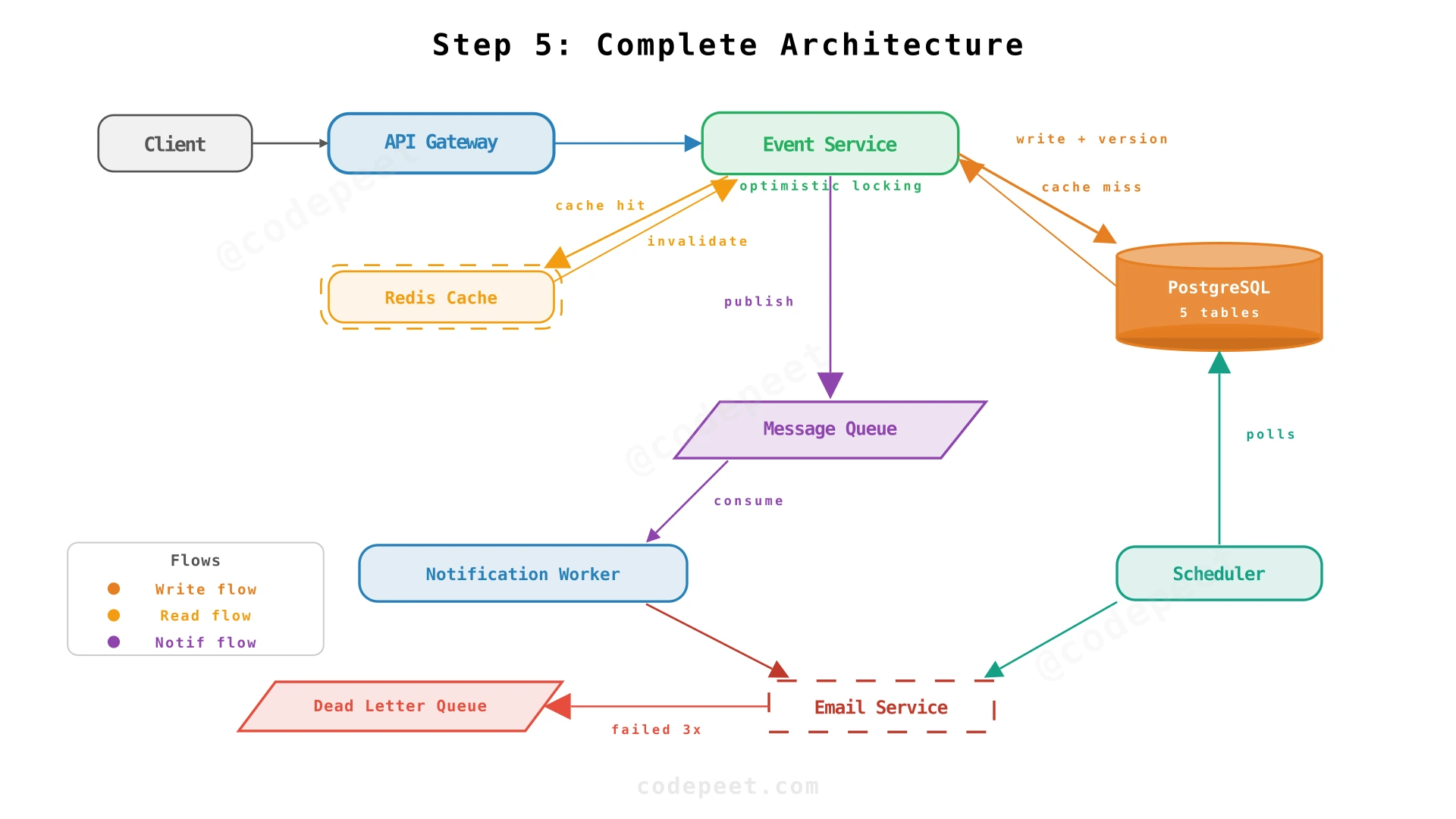
NFR Scorecard
| NFR | Target | How It's Met |
|---|---|---|
| Strong Consistency | All users see latest event state | PostgreSQL ACID transactions for all writes; optimistic locking prevents lost updates; cache invalidation on every mutation |
| Notification Reliability | Every reminder delivered, zero duplicates | Message queue guarantees at-least-once delivery; sent flag prevents re-delivery; DLQ captures persistent failures |
| Data Integrity | Valid state transitions, referential integrity | SQL foreign keys enforce relationships; RSVP validation checks attendee list; transactional event+attendee creation |
| Security | Authorization on every operation | JWT authentication at API Gateway; calendar ownership check on every event operation; attendee validation for RSVP |
| Availability | 99.9% uptime | Stateless Event Service scales horizontally; async notification pipeline doesn't block writes; scheduler recovers from crashes by re-polling |
| Scalability | 10M DAU, 30M events/day | Indexed range queries; Redis cache for read-heavy workload; rolling notification window for recurring events |
Deep Dives
How do you handle recurring events efficiently at scale?
Recurring Event Deep Dive
Recurring events are deceptively complex. A "weekly standup on Mondays" sounds simple, but consider: What if the user changes the name of just one instance? What if a holiday falls on Monday and they cancel that instance? What if they change the recurrence from weekly to biweekly — does that affect past instances?
Storage Strategies
| Strategy | Pros | Cons |
|---|---|---|
| Materialized instances (store every occurrence) | Simple queries, easy per-instance edits | "Every weekday forever" = infinite rows; bulk updates (change all future titles) require N writes |
| Virtual expansion (store rule, expand on query) | One row per series; bulk updates modify one row | Complex query logic; exception handling is tricky |
| Hybrid (virtual + materialized exceptions) | Best of both — efficient storage with clean exception handling | More complex code path |
We choose the hybrid approach: the recurring series is stored as a single row with an RRULE; exceptions (cancelled or modified instances) are materialized in a separate table.
The RRULE Expansion Pipeline
When expanding recurring events for a time range:
- Parse the
recurrence_rulestring using an RFC 5545-compliant library - Generate all instance dates within
[range_start, range_end] - Check the
recurrence_exceptionstable for this series:- If an instance date has a
replacement_event_id→ use the replacement - If an instance date has
replacement_event_id = NULL→ skip (cancelled)
- If an instance date has a
- For each surviving instance, clone the parent event's metadata (title, location, attendees) with the computed start/end time
The "This and All Future" Problem
When a user modifies "this and all future events", we split the series:
- Update the original series' RRULE to end at the split date (
UNTIL=...) - Create a new recurring event starting from the split date with the new properties
This avoids retroactively changing past instances while giving the user a clean new series going forward.
<discuss-with-ai-button title="Recurring Event Strategies" context="Google Calendar uses hybrid virtual expansion: one DB row per series with RRULE, materialized exceptions for modified/cancelled instances. 'This and all future' splits the series into two. Expansion happens in application code using RFC 5545 libraries." points='["How do you handle notification scheduling for events that repeat infinitely?","What happens if an attendee RSVPs to a specific instance of a recurring event — where is that stored?","How does timezone handling interact with recurring events — what if DST changes the wall-clock time?","What is the performance impact of expanding recurring events for a year view (52+ instances per series)?","How does Google Calendar handle 'every weekday' vs 'every Mon-Fri' when holidays are involved?"]'>
How do you implement conflict detection and find free time slots?
Conflict Detection & Free/Busy Queries
Finding free time slots is essentially the merge intervals problem from LeetCode, but applied at system design scale with real-world complications: recurring events, multiple attendees, and privacy constraints.
Overlap Detection
Two events overlap if one starts before the other ends:
SELECT COUNT(*) FROM events e
JOIN attendees a ON e.event_id = a.event_id
WHERE a.user_id = :user_id
AND a.rsvp_status = 'accepted'
AND e.start_time < :proposed_end
AND e.end_time > :proposed_start;If the count is > 0, there's a conflict. The system shows a warning but still allows creation — Google Calendar intentionally permits double-booking.
Free/Busy API
The free/busy endpoint returns merged busy blocks without exposing event details (privacy). Other users can see when someone is busy, but not why.
The Merge Intervals Algorithm
- Fetch all accepted events for the user in the requested time range
- Sort by start_time
- Merge overlapping intervals:
def get_free_slots(events, range_start, range_end):
# Step 1: Merge overlapping busy intervals
intervals = sorted((e.start_time, e.end_time) for e in events)
merged = []
for start, end in intervals:
if merged and start <= merged[-1][1]:
merged[-1] = (merged[-1][0], max(merged[-1][1], end))
else:
merged.append((start, end))
# Step 2: Find gaps between busy blocks
free = []
prev_end = range_start
for busy_start, busy_end in merged:
if prev_end < busy_start:
free.append((prev_end, busy_start))
prev_end = max(prev_end, busy_end)
if prev_end < range_end:
free.append((prev_end, range_end))
return freeRecurring Event Complication
Free/busy queries must expand recurring events within the requested range before running the merge algorithm. This means the computation is O(total instances in range), not O(stored events).
Performance Optimization
- Index:
(user_id, start_time, end_time)on the attendees+events join for efficient conflict queries - Caching: Cache free/busy results per user per day (invalidate on event mutation)
- Batch queries: For scheduling meetings with multiple attendees, run free/busy queries in parallel and intersect the results
How do you handle concurrent event modifications safely?
Concurrent Modification Strategies
When multiple users can edit the same event — e.g., shared calendars or delegated access — concurrent modifications can silently overwrite each other. This is a classic distributed systems problem.
The Problem
Alice and Bob both open the same event. Alice changes the title, Bob changes the location. If both save:
- Without protection: Last writer wins. Alice saves first →
title=new, location=old. Bob saves second →title=old, location=new. Alice's title change is silently lost. - With optimistic locking: Bob's save fails because the version changed. He's prompted to refresh and retry.
Approach Comparison
| Approach | Behavior | Tradeoff |
|---|---|---|
| Last Writer Wins | Accept latest write, overwrite previous | Simple but loses data silently |
| Pessimistic Locking | Lock the event while editing | Prevents conflicts but adds latency and lock management |
| Optimistic Locking | Detect conflict at write time, reject stale writes | No locks, works well for low-contention resources |
| Field-Level Merge | Merge non-conflicting field changes | Complex but preserves both changes |
Our Choice: Optimistic locking. Calendar events are low-contention resources — the probability of two users editing the same event at the same second is low. When it does happen, the simple reject-and-retry UX is acceptable.
Implementation Details
- Event record includes a
versioninteger (starts at 1) - Client loads event and receives the current version
- On save, the client sends
versionin the request body - Server performs:
UPDATE events SET ... WHERE event_id = ? AND version = ? - If 0 rows affected → version mismatch → return 409 Conflict
- Client shows a dialog: "This event was modified by someone else. Refresh to see the latest changes."
Notification Implications
If an event update is rejected due to a version conflict, no notification is triggered — the update never happened. This prevents spurious notifications from failed writes.
How do you build a reliable notification scheduler at scale?
Distributed Notification Scheduling
Sending 5,000+ notifications per second at exactly the right time is a distributed scheduling problem. The naive approach — a single cron job polling the database — breaks down when you need precision, reliability, and scalability.
The Naive Scheduler and Its Problems
A simple SELECT * FROM notifications WHERE notify_at <= now() AND sent = false running every minute works for small scale, but:
- Latency: Up to 60 seconds late (poll interval)
- Throughput: One query returns thousands of rows during peak hours
- Single point of failure: If the cron job crashes, all notifications stop
Partitioned Scheduler
Divide the notification table into time-based partitions. Multiple scheduler instances each claim a partition (e.g., by minute) using a distributed lock:
- Scheduler instance claims partition for minute
T(e.g., via Redlock) - Fetches all notifications where
notify_atfalls within minuteT - Sends emails in batch via the Email Service
- Marks all as
sent = true - Releases the partition lock
Multiple instances can process different minutes in parallel, and no two instances process the same minute.
Exactly-Once Delivery
The combination of distributed lock + sent flag gives us effectively exactly-once delivery:
- The lock prevents two instances from claiming the same partition
- If an instance crashes mid-processing, the lock expires and another instance takes over — but only unsent rows are processed (checking
sent = false)
Clock Skew Handling
Scheduler instances must agree on "now". If instance A's clock is 2 seconds ahead of instance B, they might both try to process the same minute. The distributed lock prevents this, but to avoid wasted work, instances use a shared time source (database server time via SELECT NOW() or a time service).
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions for staff+ conversations.
Timezone Handling as a Fundamental Architecture Decision
Context: Google Calendar operates across timezones, but the SDS intentionally scopes out timezone handling. In practice, it's a fundamental design decision that affects storage, queries, notifications, and recurring events.
Discussion Points:
- All timestamps in the database should be stored in UTC. But events have a "wall-clock" intent — "team standup at 9am" means 9am in the organizer's timezone, not 9am UTC.
- Recurring events are especially tricky: "every Monday at 9am Pacific" should remain at 9am Pacific even when DST changes (jumping from UTC-8 to UTC-7). This means the RRULE must store the timezone, and expansion must use timezone-aware libraries.
- Notifications must be sent at the right wall-clock time for each attendee's timezone — or should they? Should the reminder be 30 minutes before the event's UTC start, or 30 minutes before the event's wall-clock time in the attendee's timezone?
- The
VTIMEZONEcomponent in iCal RFC 5545 defines how to handle timezone transitions, but implementing it correctly is notoriously difficult.
<discuss-with-ai-button title="Timezone Handling in Calendar Systems" context="Timestamps stored in UTC, but events have wall-clock intent. Recurring events must handle DST transitions. Notifications must be timezone-aware. iCalendar RFC 5545 VTIMEZONE component defines the standard." points='["How does DST affect a 'weekly Monday 9am' recurring event — does the UTC representation shift?","Should the database store both UTC and the original timezone, or just UTC with the timezone as metadata?","How do you handle events across timezone boundaries — a meeting at 5pm ET that an attendee in PT sees at 2pm?","What is the VTIMEZONE component in iCal and why is it hard to implement?","How does timezone handling interact with free/busy queries across different timezones?"]'>
Calendar Federation and the CalDAV Protocol
Context: In the real world, organizations use different calendar systems (Google Calendar, Outlook, Apple Calendar). Scheduling a meeting across organizations requires interoperability — and the industry standard is CalDAV (RFC 4791).
Discussion Points:
- CalDAV is an extension of WebDAV that uses iCal format (
.icsfiles) for event data exchange. It's the protocol that makes cross-platform calendar syncing possible. - Free/busy lookup across organizations uses the "scheduling outbox" and "scheduling inbox" pattern — a user's calendar server publishes their availability, and other servers query it.
- The trust model is complex: how much availability data should you expose to external organizations? Full event details? Just busy/free? Should you allow external users to propose times?
- Supporting CalDAV means our internal data model must be mappable to/from the iCal format — which constrains schema design.
- Event identity across systems: if an event is created in Google Calendar and synced to Outlook via CalDAV, both systems must agree on the event's identity for updates and cancellations.
<discuss-with-ai-button title="Calendar Federation via CalDAV" context="CalDAV (RFC 4791) enables cross-platform calendar interoperability using iCal format. Free/busy queries work across organizations via scheduling inboxes/outboxes. Supporting CalDAV constrains internal data model design." points='["How would supporting CalDAV change our internal data model?","What are the security implications of exposing free/busy data to external organizations?","How do you handle event updates that originate from an external CalDAV client?","What is the 'scheduling outbox' pattern and how does cross-org meeting scheduling work?","How do you handle conflicts between the internal state and a CalDAV sync — which one wins?"]'>
Calendar as an Event-Sourced System
Context: Every mutation in Google Calendar (create, update, delete, RSVP) produces a side effect — a notification, a cache invalidation, a sync to an external system. Can we treat the calendar as an event-sourced system where the mutation log is the source of truth?
Discussion Points:
- The
event-changedandrsvp-changedmessages we publish to the message queue are already domain events. We could formalize them into an event store. - Calendar state would be a materialized view derived by replaying the event stream. Multiple consumers (notification worker, cache invalidator, CalDAV sync, analytics) each maintain their own projection.
- Event sourcing enables temporal queries: "show me what my calendar looked like last Tuesday" — useful for debugging and auditing.
- But: event sourcing adds complexity for a CRUD-heavy domain. Calendar mutations are relatively simple (compared to, say, financial transactions). Is the added complexity justified?
- GDPR implications: if the event log contains all changes with user identity, "right to be forgotten" requires scrubbing the log — which breaks the append-only guarantee.
Level Expectations
| Dimension | |||
|---|---|---|---|
| Requirements | Identify core FRs: event CRUD, attendees, RSVP. Mention notifications. Basic scale numbers (10M DAU → write/read QPS). | Define NFRs: strong consistency for calendar data, notification reliability (no duplicates, no missed sends), data integrity via foreign key constraints. Explain why eventual consistency fails for calendars. | Challenge scope — argue whether recurring events and timezone handling should be in scope. Identify the notification scheduler as a distributed job scheduling problem. Discuss CalDAV interoperability. |
| High-Level Design | Draw client → API Gateway → Event Service → DB. Mention REST endpoints. Show the attendees join table. | Design the async notification pipeline: message queue → notification worker → scheduler → email service. Decouple writes from notifications. Add caching for read-heavy workload. | Event sourcing for calendar mutations. CQRS if read/write patterns diverge. Timezone-aware RRULE expansion. CalDAV federation for cross-org scheduling. |
| Data Model | Identify the core entities: users, calendars, events. Know that attendees is a many-to-many relationship. | Design the full schema including the attendees join table with rsvp_status, notifications table with sent flag, and key indexes. Explain the recurrence_exceptions table. | Discuss VTIMEZONE storage, event versioning for optimistic locking, and how the schema must support CalDAV iCal mapping. |
| Recurring Events | Mention that recurring events need special handling. | Design RRULE storage with virtual expansion. Handle exceptions (cancel/modify single instance). Explain the "this and all future" series split. | Analyze DST interaction with recurring events. Discuss materialized vs virtual expansion tradeoffs at scale. Rolling window notification scheduling for infinite series. |
| Reliability | Mention retries for failed notifications. | Design the DLQ for failed emails. Explain idempotent notification scheduling (event-changed message processed twice produces same result). Optimistic locking for concurrent edits. | Distributed scheduler with partitioned locks and exactly-once semantics. Clock skew handling. Event sourcing for complete audit trail. |
Interview Cheatsheet
Core Architecture in 60 Seconds
"A CRUD system with async side effects. The write path is simple: REST endpoints → Event Service → PostgreSQL with ACID transactions. The interesting part is what happens after the write — a message queue triggers notification workers that schedule reminders, send emails, and invalidate caches."
"Strong consistency, not eventual. Calendar data can't be stale. If a meeting moves from 2pm to 3pm, every attendee must see 3pm immediately. PostgreSQL transactions + optimistic locking + cache invalidation on every mutation ensure this."
"Recurring events are virtual, not materialized. One DB row with an RRULE represents an infinite series. Instances are expanded on the fly during queries. Exceptions (cancelled or modified instances) are stored in a separate table. 'This and all future' splits the series."
"The notification scheduler is a distributed job scheduler. Time-based partition locking with multiple worker instances. Each instance claims a time partition, processes its notifications, marks them sent. The sent flag + distributed lock gives effectively exactly-once delivery."
Key Trade-offs to Mention
| Trade-off | Option A | Option B | When to Choose |
|---|---|---|---|
| Consistency | Strong (ACID) | Eventual | Strong for calendar — stale data causes real-world scheduling failures |
| Recurring storage | Materialized (all instances) | Virtual (RRULE + expand) | Virtual — can't store infinite instances; materialized only for exceptions |
| Concurrent edits | Pessimistic lock | Optimistic lock | Optimistic — low contention on calendar events makes lock overhead wasteful |
| Notification coupling | Synchronous (in request path) | Async (message queue) | Async — decouples write latency from email delivery |
| Conflict detection | Block double-booking | Warn but allow | Warn — users intentionally double-book (travel + meetings) |
| Scheduler | Single cron job | Partitioned workers | Partitioned workers for reliability and throughput |
| Free/busy privacy | Show event details | Show busy/free only | Busy/free for external users; details for internal team |
Common Mistakes to Avoid
- ❌ Materializing all recurring event instances — "every weekday" is infinite; store the RRULE and expand on query
- ❌ Sending notifications synchronously in the event creation path — blocks the response and creates a fragile coupling
- ❌ Using eventual consistency for event data — stale calendar data causes real-world scheduling failures (wrong time, cancelled events)
- ❌ Ignoring the "this and all future" problem in recurring events — modifying all instances retroactively is almost never the desired behavior
- ❌ A single cron job for notification scheduling — single point of failure and can't handle burst traffic during business hours
- ❌ Forgetting to cancel stale notifications when events are rescheduled — sending a reminder for 2pm when the meeting moved to 3pm is a critical bug