tinder
Introduction
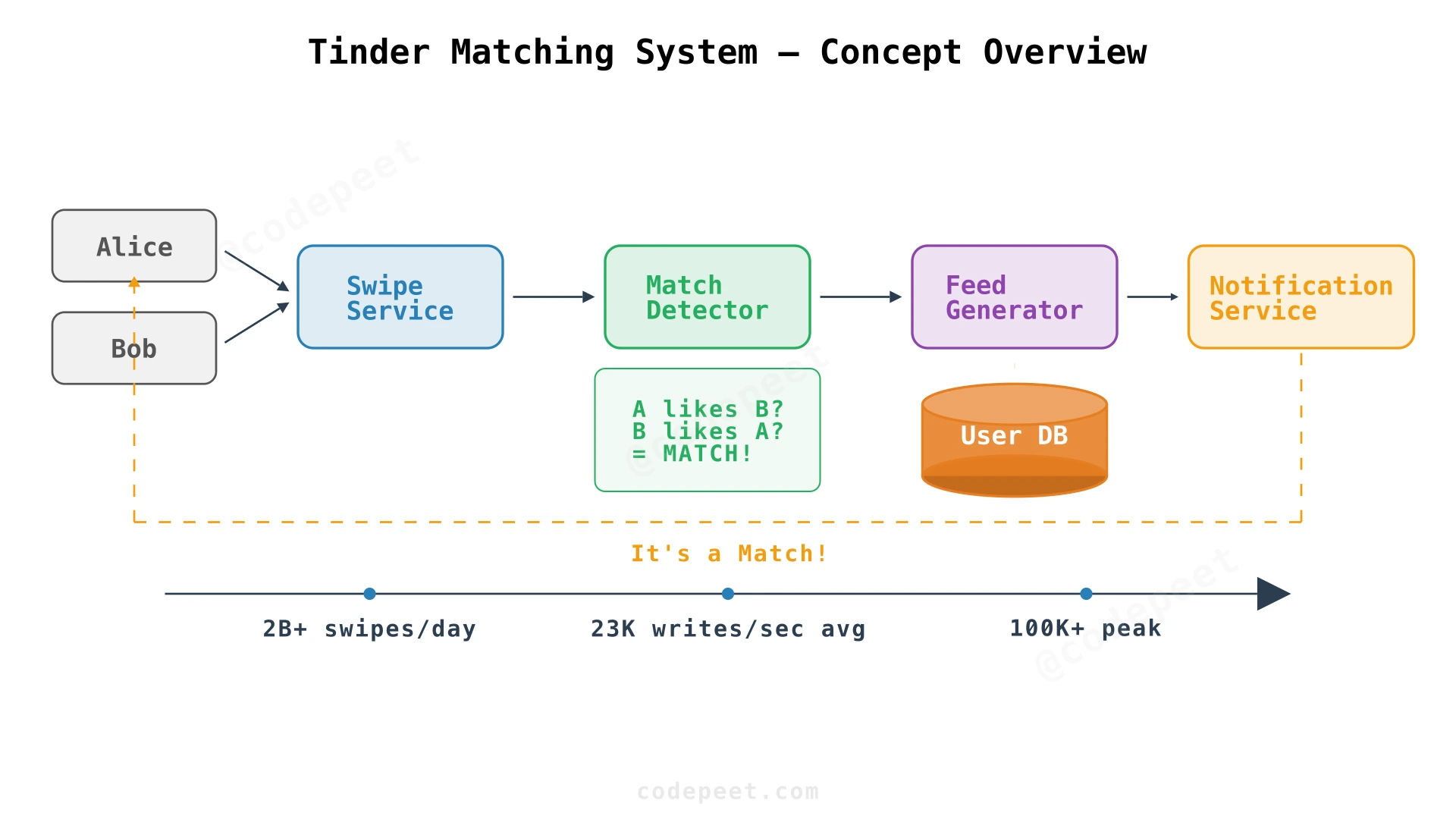
Every time you open a dating app, dozens of invisible systems spring into action. A feed generator identifies candidates from millions of users near you. A swipe recorder durably captures your decision in under 50 ms. A match detector determines — in real time — whether two people have liked each other. And a notification pipeline instantly alerts both users when a match occurs.
Tinder processes over 2 billion swipes per day across 190+ countries. Behind the simple "swipe right / swipe left" interface lies a distributed system that must handle massive write volumes, generate personalized feeds with sub-100 ms latency, and detect matches consistently even when two users swipe at the exact same millisecond from opposite sides of the planet.
The core technical challenges are:
- Data modeling — How do you store swipes and matches? A single design decision here ripples through feed queries, match detection, sharding strategy, and race condition handling.
- Feed generation — How do you efficiently find candidates from millions of users? Naive SQL queries collapse at scale. The solution separates slow-changing filters (precomputed offline) from fast-changing exclusions (applied live).
- Scaling writes — 23,000 writes/second average, 100,000+ at peak. Sharding strategy determines whether your most frequent queries stay local or scatter across the cluster.
- Match consistency — Simultaneous swipes create race conditions where both users like each other but zero matches are created. The fix depends entirely on which data model you chose.
In this design, we'll build the matching backend layer by layer: first the user flows, then the service architecture, then the data model trade-offs, and finally the deep dives into feed generation, swipe scaling, and consistency guarantees.
LLD Connection: This problem connects to the LRU Cache Low-Level Design (DP4), where you design the in-memory data structure for caching user profiles and swipe history. The HLD focuses on distributed architecture, sharding, and consistency across services.
Functional Requirements
We extract the core user flows by analyzing what users actually do in the app. Each flow maps to specific backend operations.
Four user flows define what the system must support:
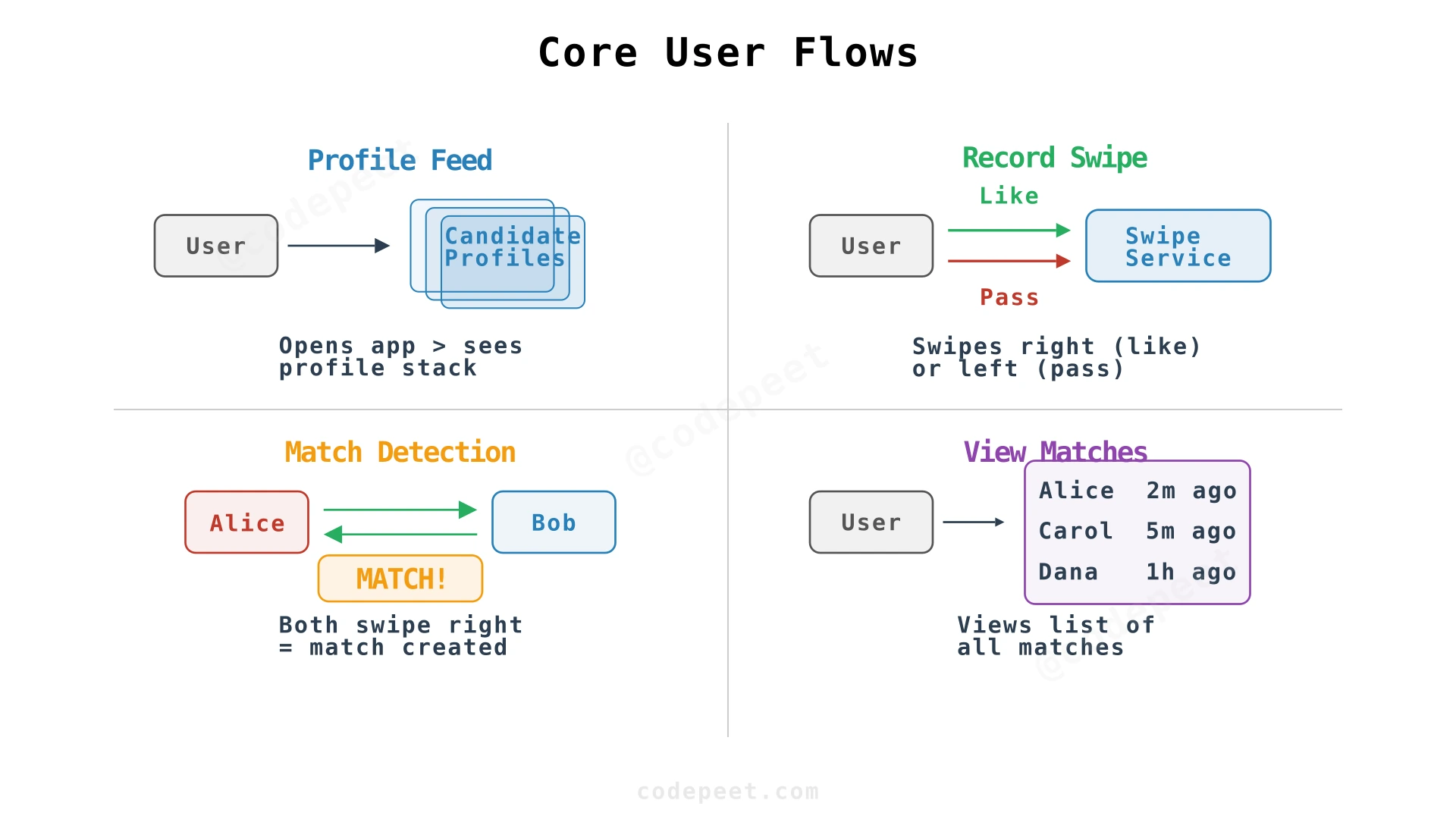
FR1 — Profile Feed. The user opens the app and sees a stack of candidate profiles. The feed must exclude people the user has already swiped on, people already matched with, and blocked users. Each profile includes name, age, bio, and photos.
FR2 — Record Swipe. The user swipes right (like) or left (pass). The backend records this decision durably. On a right swipe, the system immediately checks for a reverse swipe — if the other person already liked them, a match is detected.
FR3 — Match Detection. When Alice swipes right on Bob, the backend checks: did Bob previously swipe right on Alice? If yes, both users matched. The match must be recorded exactly once (no duplicates) and both users notified in real time.
FR4 — View Matches. The user can view their complete list of matches, ordered by recency. Each match entry shows the other user's profile and when the match occurred.
Out of scope: Chat messaging, push notification delivery infrastructure, photo upload/CDN, payment processing, and safety/moderation workflows beyond basic blocking.
We also cover feature extensions (premium "Who Liked Me", blocking, multi-region deployment) in the Deep Dive section to show how the initial design accommodates growth.
Non-Functional Requirements
| Requirement | Target | Rationale |
|---|---|---|
| Consistency | Matches appear exactly once, never duplicated | Duplicate matches confuse users and corrupt chat state |
| Availability | 99.95% uptime for feed and swipe | Core user flows must remain responsive; degraded mode acceptable for premium features |
| Swipe Write Latency | < 50 ms p99 | Users expect instant feedback when swiping |
| Feed Latency | < 100 ms p99 | Feed loads on every app open — the first thing users see |
| Match Detection | < 200 ms (sync) or < 5 s (async) | Instant "It's a Match!" is ideal; slight delay acceptable at extreme scale |
| Write Throughput | 23,000 swipes/sec average, 100,000+ peak | 20M DAU × ~100 swipes/day = 2B swipes/day |
| Feed Freshness | Candidate pool refreshed every 24h; exclusions applied in real-time | Stale pools are acceptable; stale exclusions are not (showing someone you already swiped on is a bad UX) |
Resource Estimation
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily Active Users (DAU) | Given | 20M |
| Swipes per user per day | ~100 (industry average) | 100 |
| Total swipes per day | 20M × 100 | 2 billion |
| Swipes per second (avg) | 2B / 86,400 | ~23,000/sec |
| Peak swipes per second | 4-5× average (evening hours) | ~100,000/sec |
| Feed requests per day | ~3 app opens per user × 20M | 60M/day |
| Feed requests per second (avg) | 60M / 86,400 | ~700/sec |
| Match rate | ~1-2% of mutual likes | ~200K matches/day |
Storage Estimation
| Data | Size per Record | Records | Total |
|---|---|---|---|
| Swipe record | ~40 bytes (two 8B IDs + bool + timestamp) | 2B/day × 90 days retention | 7.2 TB |
| Match record | ~24 bytes (two 8B IDs + timestamp) | 200K/day × forever | ~2 GB/year |
| User profile | ~2 KB (name, bio, preferences) | 50M total users | 100 GB |
| Photos (metadata) | ~200 bytes (URL, position) | 50M users × 5 photos | 50 GB |
| Candidate pool (segment) | ~12 bytes per entry | 10K segments × 1K candidates | 120 MB |
| Bloom filter (per user) | ~100 KB | 20M active users | 2 TB (Redis) |
Bandwidth Estimation
| Operation | Payload | QPS | Bandwidth |
|---|---|---|---|
| Swipe write | ~200 bytes | 23K/sec | 4.6 MB/sec |
| Feed response | ~20 profiles × 2 KB | 700/sec | 28 MB/sec |
| Match notification | ~500 bytes | ~2/sec | negligible |
Data Model
The system needs three categories of data: user profiles, swipe decisions, and matches.
Users and photos are straightforward — standard relational tables with well-understood access patterns. The interesting design decision lies in how we store swipes and matches, which affects every downstream system.
Users and Photos
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
age INT,
gender VARCHAR(20),
bio TEXT,
city VARCHAR(100),
home_region VARCHAR(10), -- 'us-east', 'eu-west', etc.
last_active TIMESTAMP
);
CREATE TABLE photos (
id BIGINT PRIMARY KEY,
user_id BIGINT REFERENCES users(id),
url VARCHAR(500),
position INT, -- display order
created_at TIMESTAMP DEFAULT NOW()
);These tables are standard. A composite index on (city, gender, age) supports the basic feed query. The home_region field supports multi-region deployment (covered in Feature Expansion).
Swipes and Matches: The Critical Design Decision
Consider Alice and Bob. Alice swipes right on Bob. Later, Bob swipes right on Alice. How should we represent this?
Two perspectives lead to two fundamentally different data models:
- Directed Swipes Model — These are two separate actions. Alice made a decision about Bob. Bob made a decision about Alice. Each action gets its own row. Direction matters.
- Pair Table Model — There's one relationship between Alice and Bob. Both users contribute to this relationship over time. The relationship has a state (no swipes → one-sided → mutual). One row per unique pair.
Neither is objectively correct. Each optimizes for different access patterns, and the choice ripples through match detection, feed queries, sharding strategy, and race condition handling.
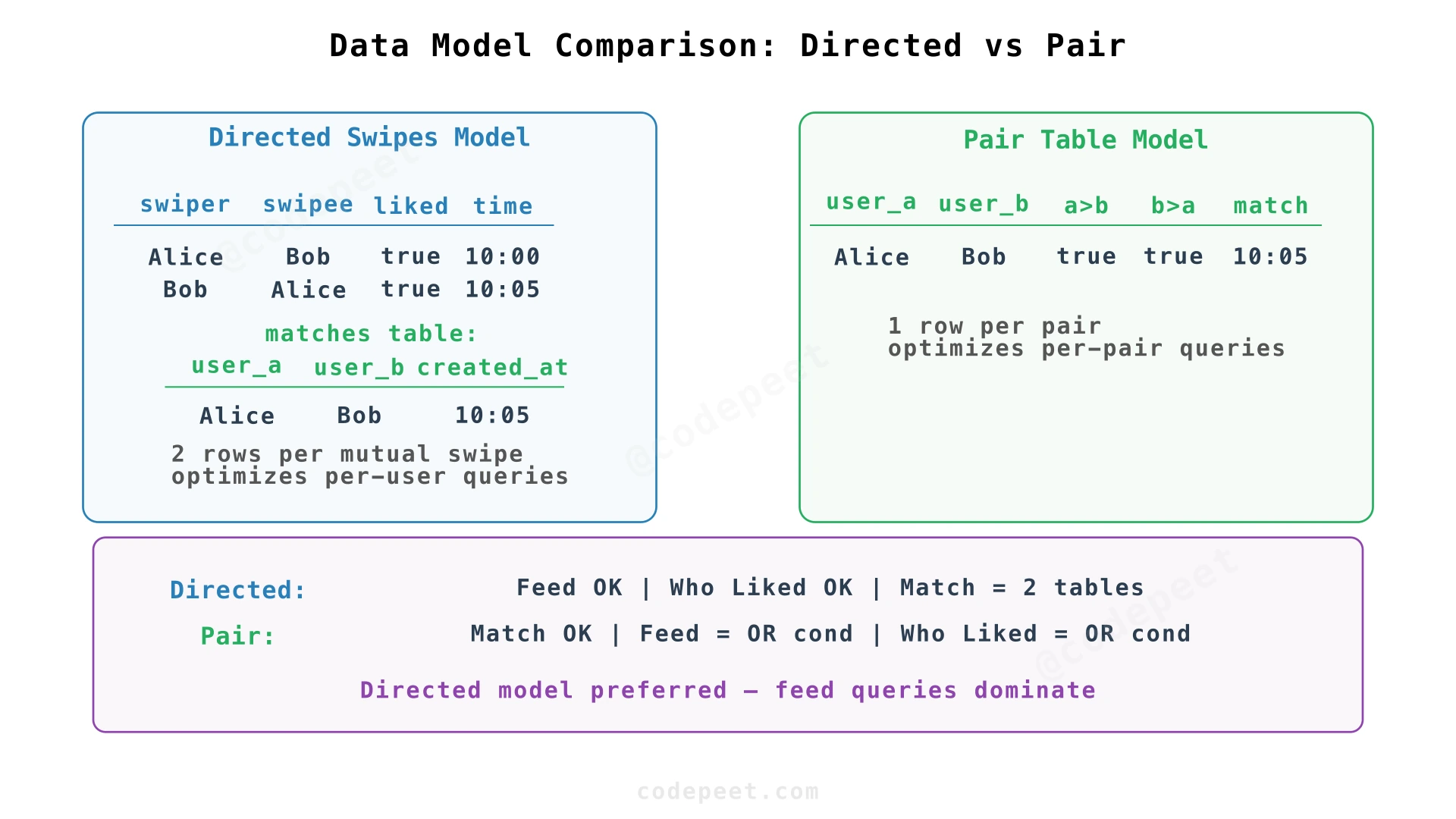
Directed Swipes Model
Each swipe gets its own row. Direction matters: Alice→Bob and Bob→Alice are separate records.
CREATE TABLE swipes (
swiper_id BIGINT NOT NULL,
swipee_id BIGINT NOT NULL,
liked BOOLEAN NOT NULL,
created_at TIMESTAMP DEFAULT NOW(),
PRIMARY KEY (swiper_id, swipee_id)
);
-- Index for match detection: "Did Bob swipe right on Alice?"
CREATE INDEX idx_swipee_liked ON swipes(swipee_id, liked);
CREATE TABLE matches (
user_a BIGINT NOT NULL,
user_b BIGINT NOT NULL,
created_at TIMESTAMP DEFAULT NOW(),
PRIMARY KEY (user_a, user_b),
CHECK (user_a < user_b) -- canonical ordering prevents duplicates
);
-- Index for "get my matches" query
CREATE INDEX idx_matches_user_b ON matches(user_b);The CHECK (user_a < user_b) constraint ensures each match is stored in one canonical order. Alice-Bob and Bob-Alice both store as (Alice, Bob) where Alice's ID is smaller. This PRIMARY KEY + canonical ordering combination makes duplicate matches impossible at the database level.
Pair Table Model
One row represents each potential pair. Both swipes update the same row.
CREATE TABLE user_pairs (
user_a BIGINT NOT NULL,
user_b BIGINT NOT NULL,
a_liked_b BOOLEAN,
b_liked_a BOOLEAN,
a_swiped_at TIMESTAMP,
b_swiped_at TIMESTAMP,
matched_at TIMESTAMP,
PRIMARY KEY (user_a, user_b),
CHECK (user_a < user_b)
);When Alice swipes on Bob, the system finds or creates the pair row (using canonical ordering), then updates a_liked_b. If b_liked_a is already TRUE, it sets matched_at = NOW().
The choice between models ripples through every subsequent design decision. Let's trace the impact:
Model Impact Analysis
Match detection asks: "Did Bob already swipe right on Alice?" This is a per-pair question — checking the state of a specific relationship.
Pair Model (natural fit): The match state lives in one row. One point lookup answers "are they matched?"
Directed Model (requires reconstruction): Match state spans two tables — check the swipes table for Bob's swipe, then check the matches table for existing match. Two queries, two tables.
Why Directed still works: Match checks happen once per swipe. Feed queries happen on every app open — 10-100× more frequent. Optimizing for the common case (per-user queries) is usually the right trade-off.
The feed must exclude users already swiped on. How hard is this exclusion?
Directed Model (natural fit): "Who have I swiped on?" maps directly: SELECT swipee_id FROM swipes WHERE swiper_id = :me. One column, one index, one direction.
Pair Model (awkward): The user might be user_a or user_b depending on ID ordering. You must check both positions with an OR condition that complicates query planning and may require two index scans.
Premium feature: show everyone who liked me, even if I haven't swiped back.
Directed Model (natural fit): Incoming likes are first-class: SELECT swiper_id FROM swipes WHERE swipee_id = :me AND liked = TRUE. Index on (swipee_id, liked) makes this fast.
Pair Model (awkward): Same OR-condition problem. You must decode "other side liked me" from symmetric decision fields. Often requires building a separate incoming_likes projection — effectively adding a directional view.
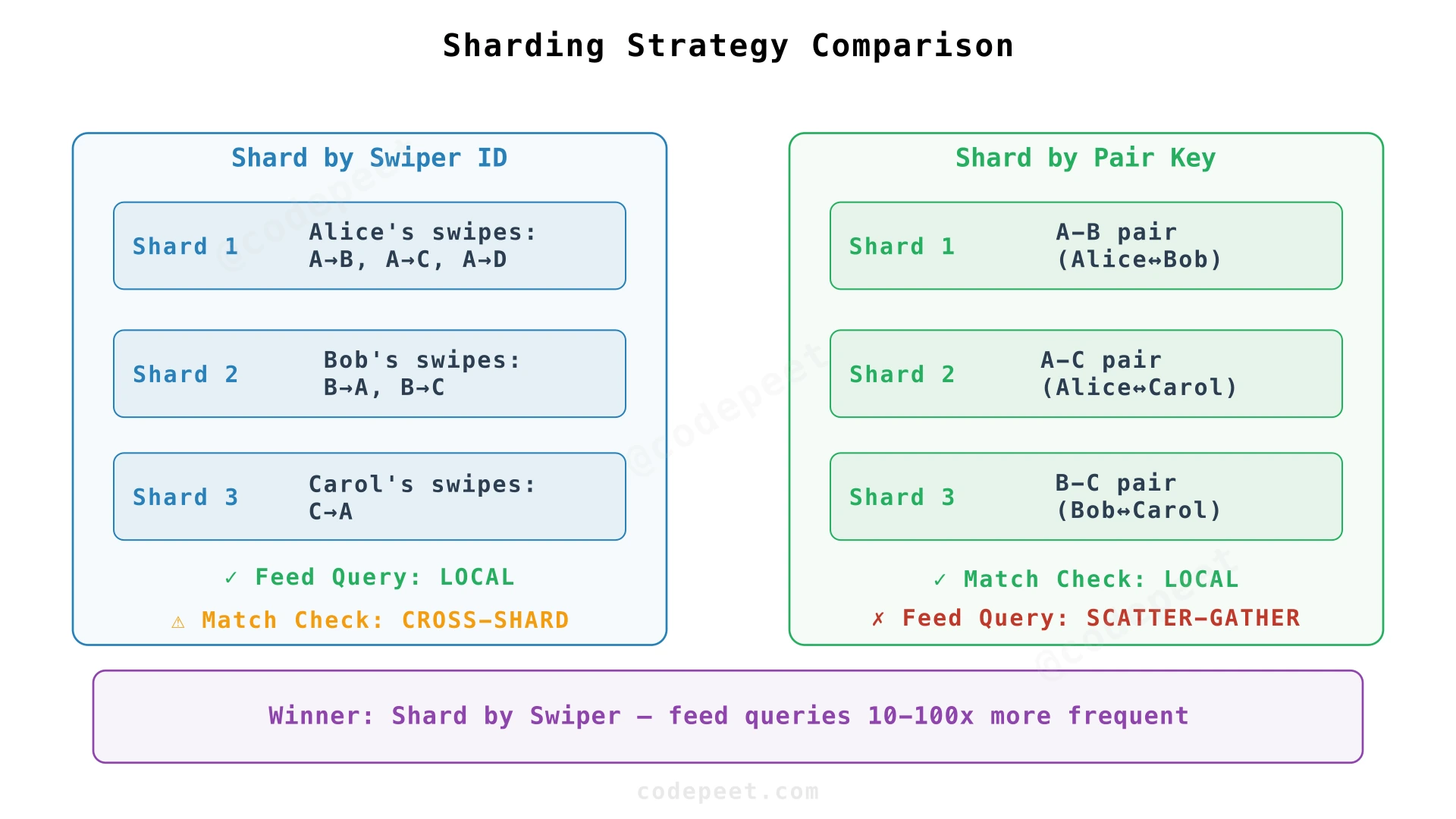
At scale, you partition data across nodes. The shard key determines which queries stay local.
Directed Model offers two strategies:
- Shard by swiper_id: Feed exclusion is local (all my swipes on one shard), match detection is cross-shard
- Shard by pair key: Match detection is local, per-user queries become scatter-gather
Pair Model naturally shards by pair key: match state is local, but per-user views span many shards and require projection tables.
You can only optimize for one access pattern with a shard key. Choose based on which query dominates.
Model Comparison Summary
| Aspect | Directed Swipes | Pair Table |
|---|---|---|
| Writing a swipe | INSERT one row | UPSERT, determine which column |
| Match check | Query separate row | Already in same row |
| Feed query | Single column scan | OR across two columns |
| "Who liked me" | Single column scan | OR across two columns |
| Sharding (feed) | Local | Scattered |
| Sharding (match) | Cross-shard | Local |
| Storage | 2 rows per mutual swipe | 1 row per pair |
| Race condition | Exists (needs handling) | Eliminated by row-level locking |
Recommendation: For most dating apps, Directed Swipes is the better default. Feed queries run on every app open (most frequent operation). Match checks run once per swipe (less frequent). Per-user operations dominate. But if your app centers on relationship state (collaborative features, mutual visibility controls), Pair Table may be worth the per-user query complexity.
Indexes make or break performance at scale. Each model needs different indexes optimized for its primary access patterns.
Directed Model Indexes:
-- Primary: write path (swipe recording)
CREATE UNIQUE INDEX idx_swipes_pk ON swipes(swiper_id, swipee_id);
-- Feed exclusion: "who have I already swiped on?"
-- Covered index: query answers entirely from index, no table access
CREATE INDEX idx_swipes_swiper_covered ON swipes(swiper_id) INCLUDE (swipee_id);
-- Match detection: "did this person like me?"
CREATE INDEX idx_swipes_swipee_liked ON swipes(swipee_id, liked) WHERE liked = TRUE;
-- "Who liked me" (premium): incoming likes
-- Partial index: only indexes TRUE likes, ~50% smaller
CREATE INDEX idx_swipes_incoming_likes ON swipes(swipee_id, created_at DESC)
WHERE liked = TRUE;
-- Matches: both users need to find their matches
CREATE UNIQUE INDEX idx_matches_pk ON matches(user_a, user_b);
CREATE INDEX idx_matches_user_b ON matches(user_b, created_at DESC);
Pair Model Indexes:
-- Primary: pair lookup and update
CREATE UNIQUE INDEX idx_pairs_pk ON user_pairs(user_a, user_b);
-- Matches: find all matched pairs involving a user
-- Requires scanning BOTH columns (OR condition)
CREATE INDEX idx_pairs_a_matched ON user_pairs(user_a) WHERE matched_at IS NOT NULL;
CREATE INDEX idx_pairs_b_matched ON user_pairs(user_b) WHERE matched_at IS NOT NULL;
-- Feed exclusion: find all pairs involving a user (any swipe state)
-- Two partial indexes needed, one for each position
CREATE INDEX idx_pairs_a_any ON user_pairs(user_a);
CREATE INDEX idx_pairs_b_any ON user_pairs(user_b);
Notice the Pair Model needs twice as many indexes for per-user operations because the user could be in either position (user_a or user_b). At 2B swipes/day, each additional index costs ~40-80 GB of storage.
API Endpoints
All endpoints are authenticated via JWT token. The user_id is extracted from the token — never passed as a parameter (prevents IDOR attacks).
Feed Endpoint
GET /api/v1/feed?limit=20
Response: Array of candidate profiles (id, name, age, bio, photos). Feed excludes already-swiped, already-matched, and blocked users.
| Parameter | Type | Default | Description |
|---|---|---|---|
limit | integer | 20 | Number of profiles to return (max 50) |
Response Codes: 200 OK with profiles array, 401 Unauthorized, 429 Too Many Requests
Swipe Endpoint
POST /api/v1/swipes
Request Body:
{
"swipee_id": "789456",
"liked": true
}
Response:
{
"status": "recorded",
"match": {
"matched": true,
"match_id": "abc123",
"matched_user": { "id": "789456", "name": "Bob", "photo_url": "..." }
}
}
match field is present only when liked: true results in a mutual match.
Response Codes: 201 Created, 400 Bad Request (duplicate swipe), 401 Unauthorized
Matches Endpoint
GET /api/v1/matches?cursor=<timestamp>&limit=20
Response: Paginated list of matches with the other user's profile and match timestamp. Cursor-based pagination using created_at timestamp.
| Parameter | Type | Description |
|---|---|---|
cursor | string (ISO timestamp) | Fetch matches older than this timestamp |
limit | integer | Number of matches to return (default 20, max 50) |
Profile Endpoint
GET /api/v1/users/:id/profile
Response: Full profile with photos. Used internally by the feed service and externally for match detail views.
High Level Design
How do we go from user flows to a working system? We could start by drawing services and databases, but that risks building architecture for its own sake. Instead, let's work bottom-up: start with what users actually DO, extract the operations, identify the data they touch, then let service boundaries emerge naturally.
This approach ensures we're solving real problems, not theoretical ones.
1. Extracting Core Operations
Before we draw any boxes, let's identify every operation the system needs to support. Each user action translates to backend operations:
| User Flow | Verb | Backend Operation |
|---|---|---|
| Profile Feed | "show profiles not seen" | get_swipe_candidates(user_id) |
| Record Swipe | "record this decision" | record_swipe(swiper, swipee, liked) |
| Record Swipe | "check for reverse swipe" | has_swiped(Bob, Alice) |
| Record Swipe | "create match if mutual" | create_match(user_a, user_b) |
| Match Detection | "did Bob swipe right?" | is_match(Alice, Bob) |
| View Matches | "list all matches" | get_matches(user_id) |
Three core operations emerge: get_feed, record_swipe, and create_match. Everything else is a supporting sub-operation.
2. Grouping Operations into Services
We group operations by what data they touch. Operations that read and write the same tables belong together.
Why group by data instead of by user flow? Two reasons:
- Cross-service calls add latency and failure modes. If
record_swipeandhas_swipedlived in different services, every swipe would require a network hop to check for matches. - Shared data ownership creates consistency nightmares. If two services both write to the swipes table, they must coordinate to avoid conflicts. Grouping by data keeps each table owned by exactly one service.
| Domain | Operations | Rationale |
|---|---|---|
| Swipe | record_swipe, has_swiped | Both read/write swipes table |
| Match | create_match, is_match, get_matches | All operate on matches table |
| Candidate / Feed | get_swipe_candidates | Read-only across multiple tables |
| User / Profile | update_profile, get_profile | Owns user and photos tables |
Should Swipe and Match merge? They could, since match detection happens during swipe handling. But swipes are write-heavy (every interaction writes), while match reads are low-frequency (users occasionally check their list). Separating them lets each scale independently — we add more Swipe Service instances during peak hours without over-provisioning Match Service.
Service Definitions
Each service owns specific tables and exposes operations to others:
| Service | Operations | Owns |
|---|---|---|
| User Service | update_profile, get_profile | users, photos tables |
| Swipe Service | record_swipe, has_swiped | swipes table |
| Match Service | create_match, is_match, get_matches | matches table |
| Candidate Service | get_swipe_candidates | read-only across tables |
The Candidate Service is unusual — it owns no tables. It reads from users, swipes, and matches to build the feed. This read-only pattern lets it use read replicas and aggressive caching without worrying about write consistency.
3. Building FR1: Profile Feed
Requirement: Users should see a stack of profiles to swipe on.
Let's start with the simplest approach: a single service handling everything. The User Service stores profiles and generates the feed. When a user opens the app, we query for nearby users matching their preferences:
SELECT id, name, age, photos
FROM users
WHERE city = :user_city
AND gender = :user_preferred_gender
AND age BETWEEN :user_min_age AND :user_max_age
LIMIT 20;This works for small scale. No service calls, no latency overhead.
But at 10M users with complex filtering (location, age, gender, preferences), full table scans become expensive. We'll address this in the Feed Generation deep dive. For now, the basic query establishes our starting point.
With profiles showing, users can now swipe. Let's add that capability.
4. Adding FR2: Record Swipe
Requirement: Users should be able to swipe right (like) or left (pass). The system must record each decision.
Should we add swipe recording to the User Service? Let's check our split criteria:
- Different scaling profile? Swipes are write-heavy (every interaction writes a row). Profile views are read-heavy. ✓ Split.
We'll create a separate Swipe Service:
Components added:
- Swipe Service — Receives swipe decisions, writes to swipes table
- Swipes table —
(swiper_id, swipee_id, liked, created_at)
Flow:
- User swipes right on a profile
- Client calls
POST /swipeswith swiper, swipee,liked=true - Swipe Service writes:
INSERT INTO swipes (swiper_id, swipee_id, liked) VALUES (:swiper, :swipee, TRUE) - Returns success
The swipe is recorded, but we haven't detected matches yet. When Alice swipes right on Bob, we save the decision — but if Bob also swiped right on Alice, we need to detect that match.
5. Adding FR3: Match Detection
Requirement: When both users swipe right on each other, create a match.
When Alice swipes right on Bob, we check: did Bob already swipe right on Alice? If yes → match.
We create a separate Match Service to keep match state independent from swipe writes:
Components added:
- Match Service — Detects matches, stores them, handles match queries
- Matches table —
(user_a, user_b, created_at)withCHECK (user_a < user_b)for canonical ordering
Flow:
- User swipes right on a profile
- Swipe Service writes the swipe
- Swipe Service calls Match Service:
check_for_match(swiper, swipee) - Match Service queries Swipe Service: "did swipee swipe right on swiper?"
- If yes, Match Service creates match:
INSERT INTO matches (user_a, user_b) VALUES (LEAST(:a,:b), GREATEST(:a,:b)) - Returns match status to client
The canonical ordering (user_a < user_b) ensures Alice-Bob and Bob-Alice map to the same row, preventing duplicates at the database level.
6. Completing FR4: View Matches
Requirement: Users should see their list of matches.
The Match Service owns the matches table, so it handles this query directly:
SELECT m.user_a, m.user_b, m.created_at,
u.name, u.photos
FROM matches m
JOIN users u ON u.id = CASE
WHEN m.user_a = :user_id THEN m.user_b
ELSE m.user_a
END
WHERE m.user_a = :user_id OR m.user_b = :user_id
ORDER BY m.created_at DESC
LIMIT 20;The client calls GET /matches and the Match Service returns the list with profile details fetched from User Service.
Checkpoint: All four core flows work. Users can view profiles, swipe, get matched, and view their matches. Now let's see the complete architecture.
7. System Architecture Overview
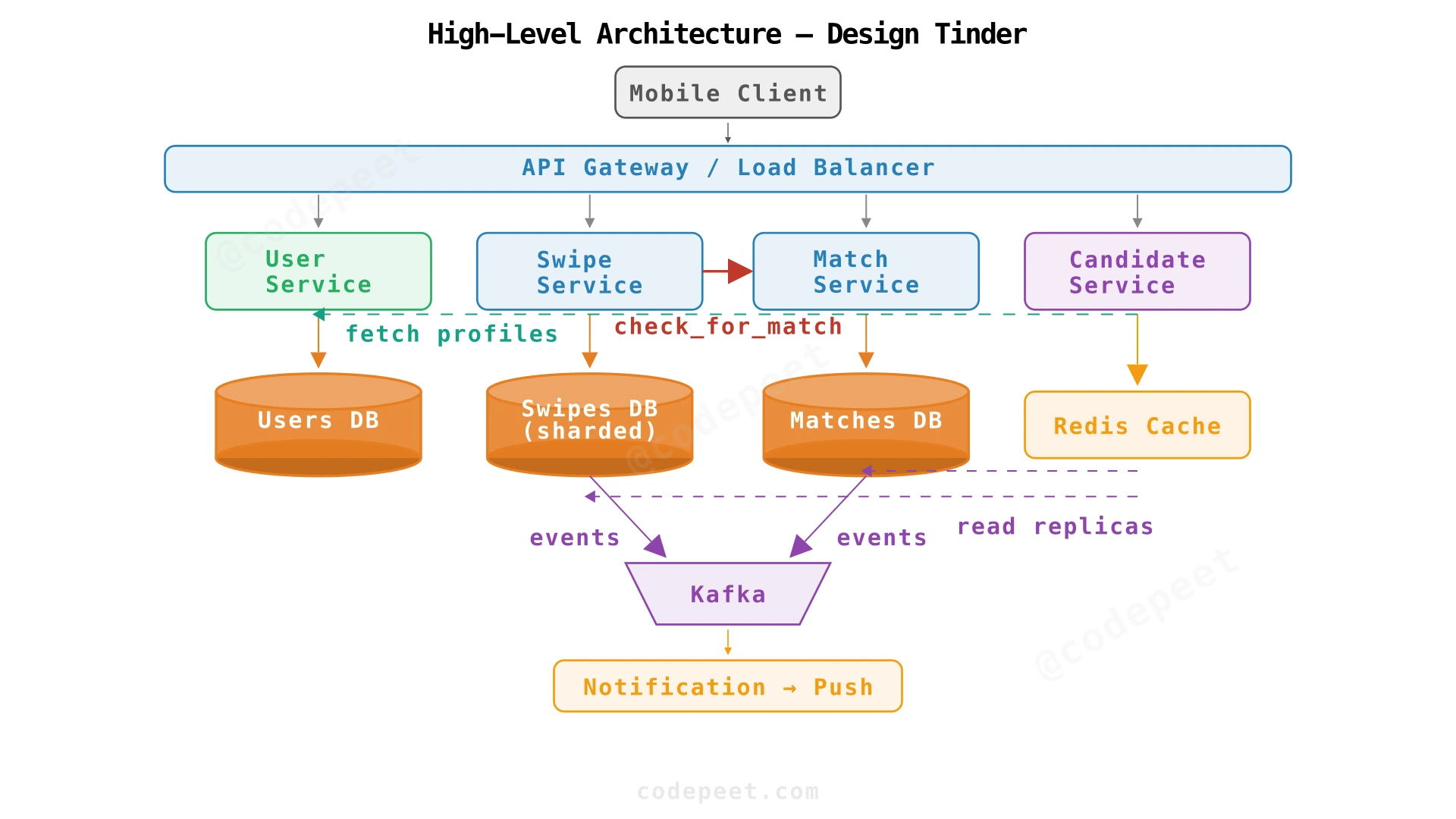
The API Gateway routes requests to the appropriate service. Each service owns its data and exposes operations to other services as needed. The Candidate Service has read-only access via replicas.
Every user-facing action maps to specific backend operations. This mapping makes service boundaries concrete:
| User Action | API Call | Service | DB Operation | Related Services |
|---|---|---|---|---|
| Open app | GET /feed | Candidate | Read segment_pools, check Bloom Filters | User Service (profile hydration) |
| Swipe right | POST /swipes | Swipe | INSERT into swipes | Match Service (check for match) |
| Swipe left | POST /swipes | Swipe | INSERT into swipes | None |
| View matches | GET /matches | Match | SELECT from matches JOIN users | User Service (profile data) |
| Update profile | PUT /users/me | User | UPDATE users | Candidate Service (invalidate cache) |
| Block user | POST /blocks | User | INSERT into blocks | All services (propagate exclusion) |
| View "Who Liked Me" | GET /likes/incoming | Swipe | SELECT from swipes WHERE liked=TRUE | User Service (profile data) |
Inter-service communication: All service-to-service calls use synchronous gRPC for latency-critical paths (swipe → match check) and Kafka events for non-critical propagation (block → update all caches).
At small scale (< 1M DAU), a monolith is the right choice. The service split we describe is the destination architecture — where you'd evolve as scale demands.
Stage 1 (< 1M DAU): Single service, single database. All operations in one process. Database handles 1-5K writes/sec easily.
Stage 2 (1-5M DAU): Split the Candidate/Feed service out first — it's the easiest because it's read-only. Add Redis cache layer. Database still handles writes.
Stage 3 (5-20M DAU): Split Swipe Service with its own database. Shard by swiper_id. Add Kafka for async match detection.
Stage 4 (20M+ DAU): Full service split. Match Service gets its own database. Multi-region deployment. The architecture diagram above represents this stage.
Key principle: Don't pre-optimize. Each split introduces operational cost (deployment, monitoring, debugging). Split only when a specific bottleneck demands it.
8. Sequence: Swipe Right with Match
When a user swipes right, the request flows through multiple services. Let's trace the complete path:
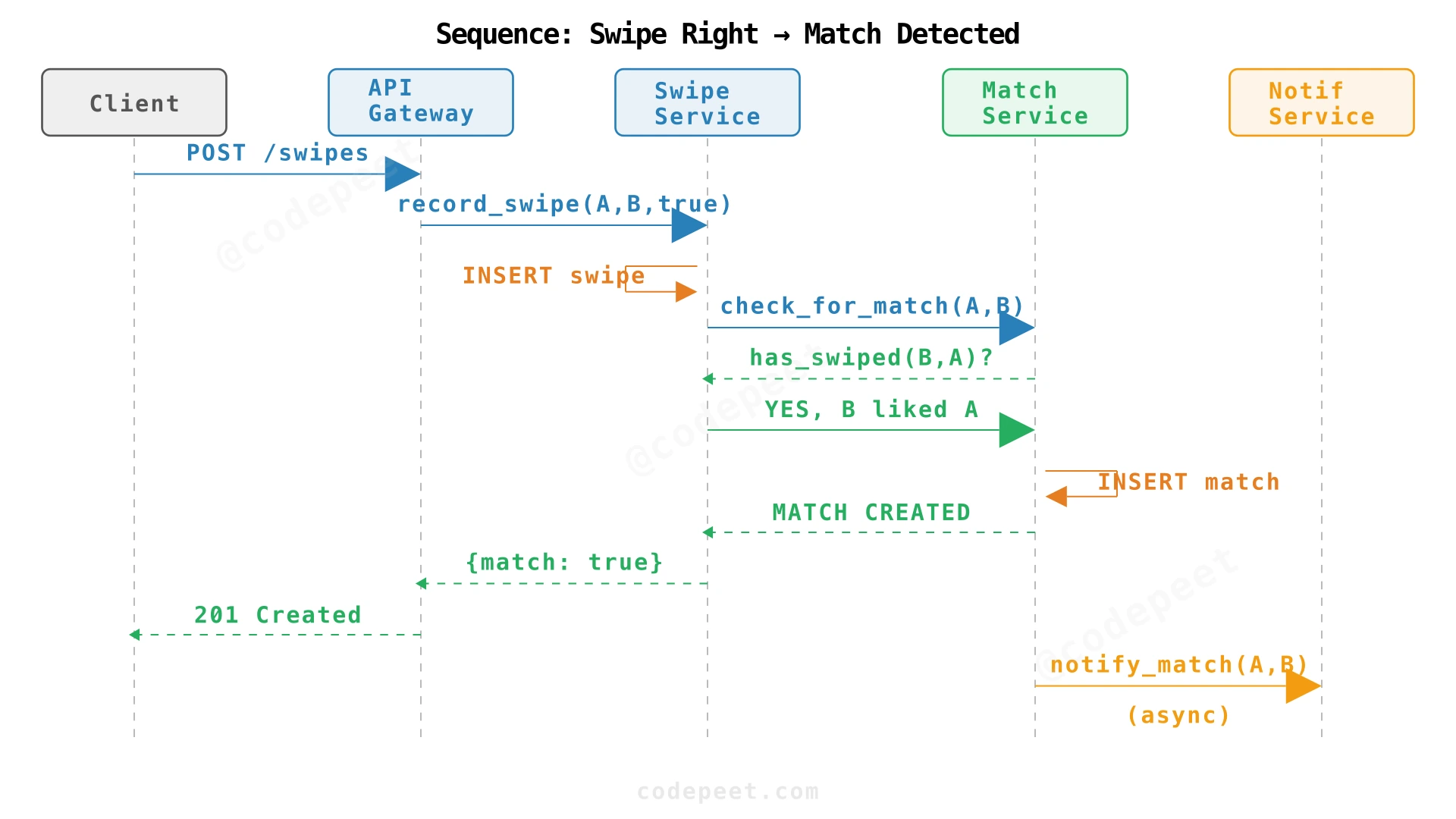
The swipe write happens first (durability), then match detection (consistency check), then notification (eventual delivery). This ordering ensures we never lose a swipe and never create orphan matches.
9. Sequence: Get Feed
Opening the app triggers a feed request. The Candidate Service orchestrates the full pipeline:
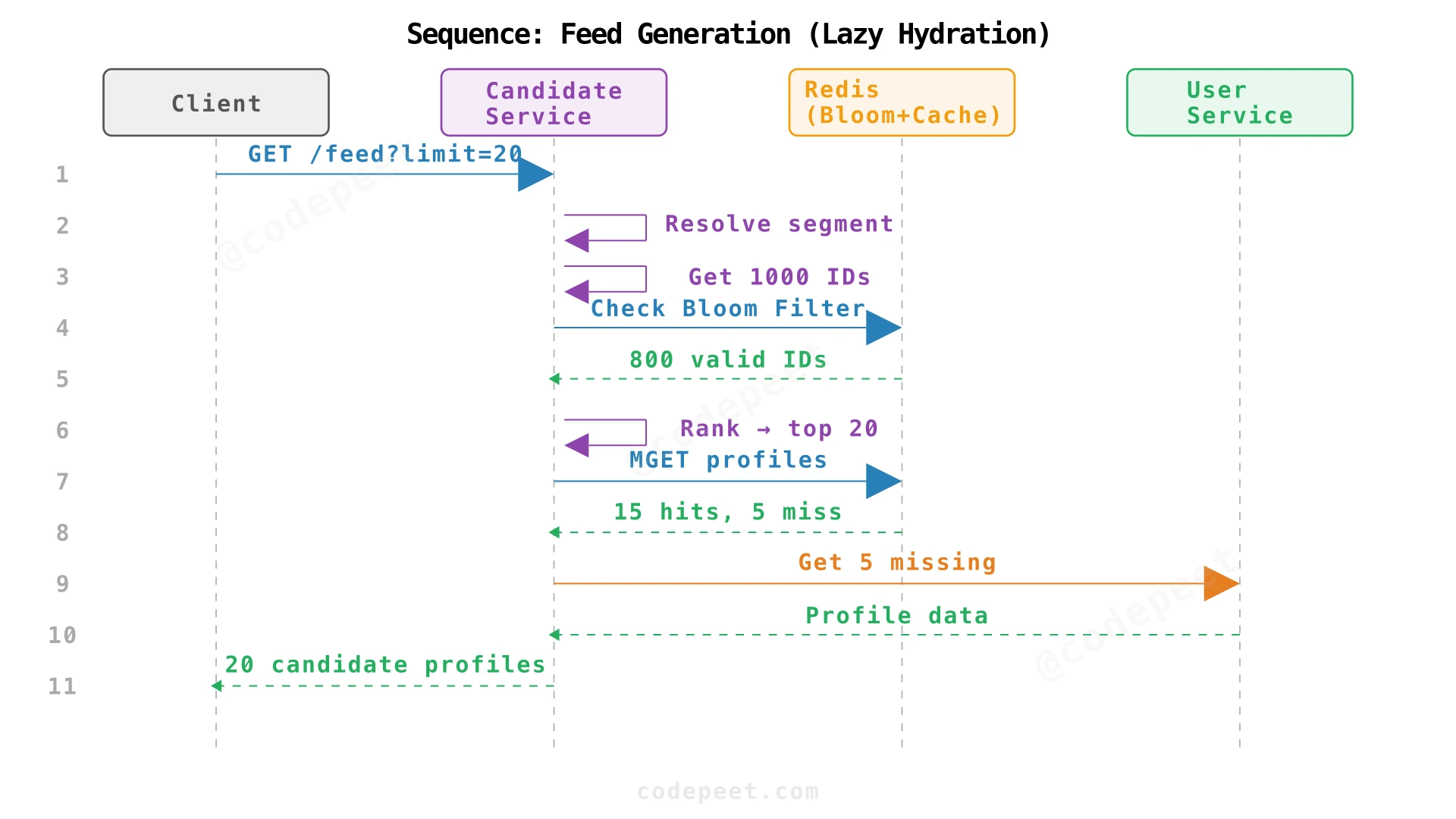
Deep Dive Questions
How do we generate the candidate feed efficiently at scale?
The feed is the heaviest read path — every app open triggers a feed request, potentially 100× more frequent than swipes. A naive SQL query with correlated subqueries collapses at 10M users. The solution separates slow-changing filters from fast-changing exclusions.
Feed Semantics
For user U, valid candidates V must satisfy:
Include: Near U, matches U's preferences (age, gender), optionally mutual compatibility
Exclude: U themselves, already-matched users, already-swiped users, blocked users
Expressed as set operations:
Candidates(U) = EligibleProfiles ∩ Near(U) ∩ PrefsCompatible(U)
− {U} − Matches(U) − SwipedBy(U) − Blocked(U)
The Naive Approach (and Why It Fails)
SELECT u.id, u.name, u.age, u.bio
FROM users u
WHERE u.id != :user_id
AND u.city = :city
AND u.age BETWEEN :min_age AND :max_age
AND u.gender = :preferred_gender
AND NOT EXISTS (SELECT 1 FROM swipes WHERE swiper_id = :user_id AND swipee_id = u.id)
AND NOT EXISTS (SELECT 1 FROM matches WHERE user_a = :user_id AND user_b = u.id
OR user_a = u.id AND user_b = :user_id)
AND NOT EXISTS (SELECT 1 FROM blocks WHERE blocker_id = :user_id AND blocked_id = u.id
OR blocker_id = u.id AND blocked_id = :user_id)
ORDER BY u.last_active DESC
LIMIT 20;Each NOT EXISTS is a correlated subquery — the database evaluates it for every candidate row. With 100,000 potential candidates in NYC, that's 100,000 lookups per exclusion table. Query cost grows with the candidate pool size, not the result size.
The key insight: Different filters change at different rates. Location and preferences change weekly. The exclusion list changes every swipe. Why recompute expensive location filtering every time when the results haven't changed?
Solution: Separate slow-changing filters (precompute offline) from fast-changing filters (apply live).
Precomputed Candidate Pools
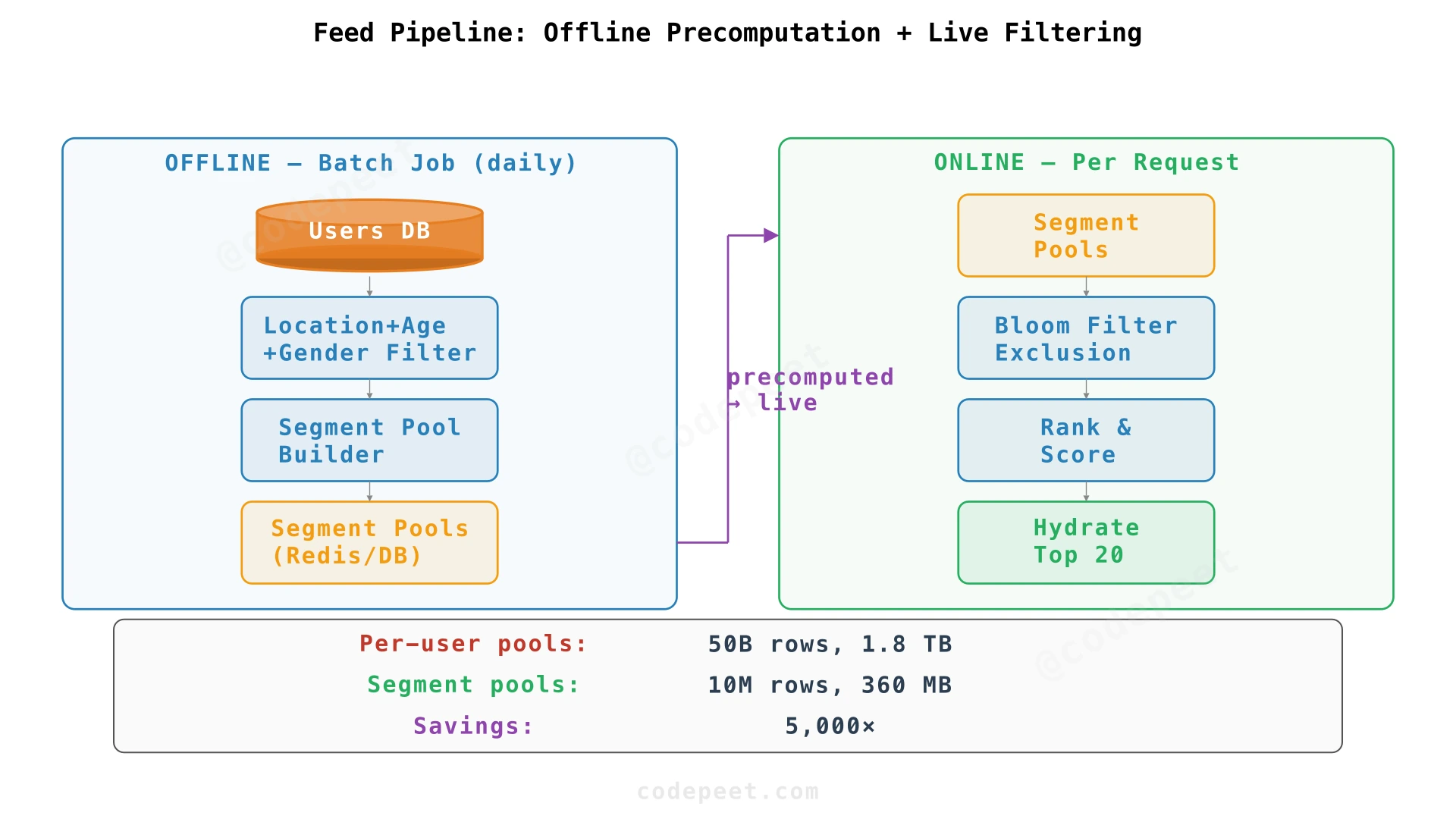
Per-user pools explode at scale: 50M users × 1,000 candidates each = 50 billion rows. The index alone exceeds 1 TB. Instead, we observe that users with identical preferences see nearly identical pools. Alice and Carol — both in NYC, both 25-30, both seeking males — have 95% overlap.
Segment pools deduplicate this redundancy:
def get_feed(user_id):
# Resolve user to segment based on preferences
segment = f"{user.city}:{user.preferred_gender}:{user.age_bucket}"
# Pull candidate IDs from shared segment pool (lightweight)
candidate_ids = db.query(
"SELECT candidate_id FROM segment_pools WHERE segment_id = ? LIMIT 1000",
segment
)
# Filter using Bloom Filter (no network transfer of full exclusion set)
excluded = bloom_filter(f"swiped:{user_id}")
valid_ids = [cid for cid in candidate_ids
if not excluded.contains(cid)
and not bloom_filter(f"matched:{user_id}").contains(cid)]
# Rank by score and hydrate ONLY the top 20
ranked_ids = rank_candidates(valid_ids, user_id)[:20]
profiles = fetch_profiles(ranked_ids) # Cache-first, DB fallback
return profiles| Approach | Rows | Storage | Why |
|---|---|---|---|
| Per-user pools | 50B | 1.8 TB (indexes) | 50M users × 1,000 candidates |
| Segment pools | 10M | 360 MB | 10K segments × 1,000 candidates |
Segment pools are 5,000× smaller. The entire index fits in memory.
Trade-off: Segment pools lose personalization. The score is generic (computed without knowing the specific user). Premium subscribers can pay for per-user pools with personalized ML scoring — keeping storage tractable by applying it to only 5% of users.
Lazy Hydration: Fetch IDs First, Profiles Last
The trap at scale: fetching 1,000 full profiles from cache/DB consumes massive bandwidth. After filtering, you discard 980 of them. Lazy hydration fetches IDs first, filters cheaply, then hydrates only the top 20:
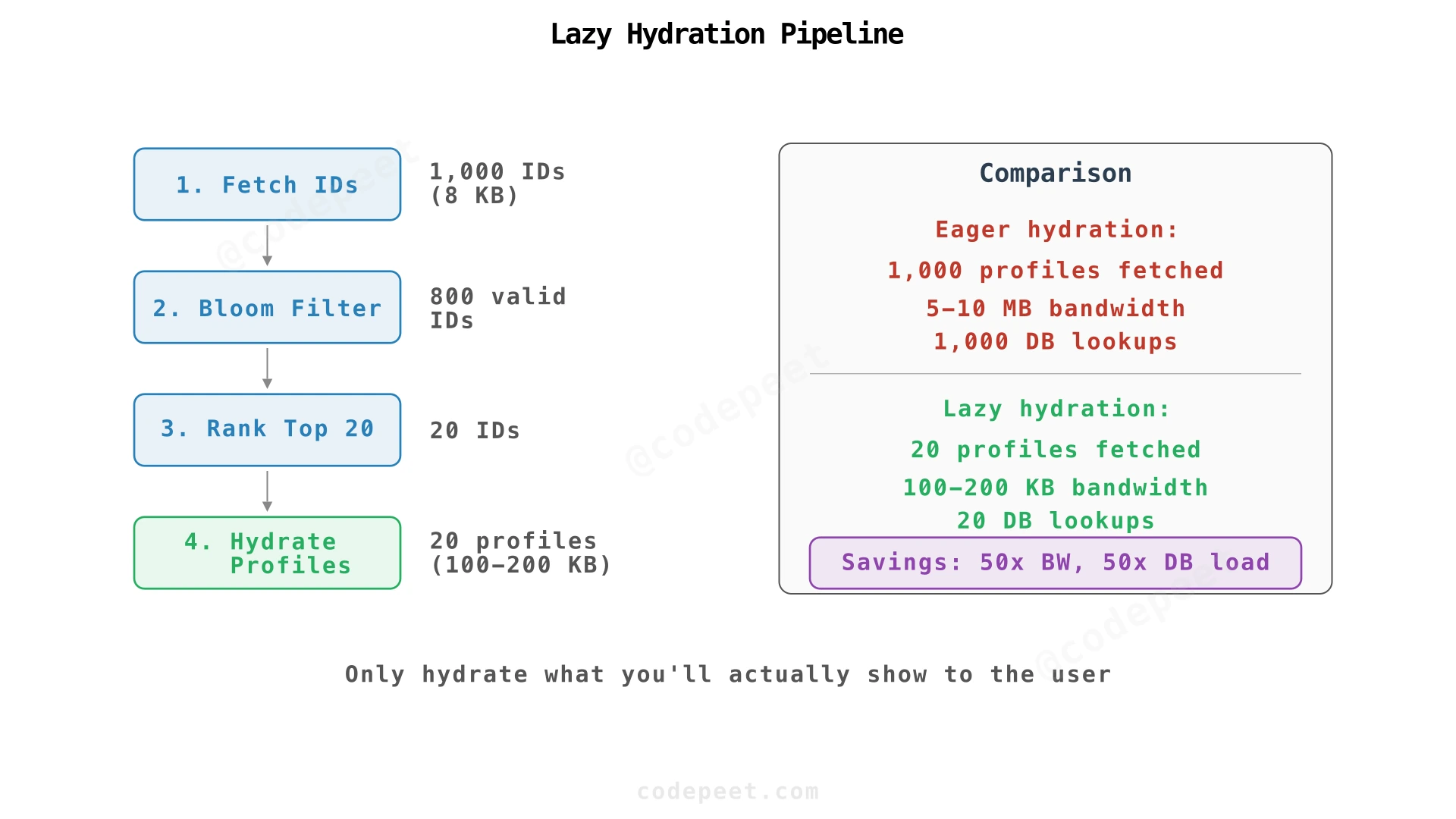
Bloom Filters for Memory-Efficient Exclusion
For users with 100,000+ swipes, storing the full exclusion set in Redis is expensive. Bloom Filters compress the exclusion check:
| Approach | Memory per User | Network Transfer | False Positives |
|---|---|---|---|
| Redis SET (100K swipes) | 800 KB | 800 KB per read | 0% |
| Bloom Filter (100K swipes) | 100 KB | 0 KB (check in place) | 0.01% (1 in 10,000) |
Bloom Filters reduce memory by 8× and eliminate network transfer for membership checks. The trade-off: occasionally hiding a candidate the user hasn't actually seen. This is acceptable — showing slightly fewer candidates is better than wasting megabytes of bandwidth.
The segment_pools table stores candidate_id and a lightweight score. Only after selecting the top N do you fetch full profiles:
def fetch_profiles(user_ids):
# Multi-get from cache (single network call)
profiles = cache.mget([f"profile:{uid}" for uid in user_ids])
# Fetch cache misses from database
missing = [uid for uid, p in zip(user_ids, profiles) if p is None]
if missing:
db_profiles = db.query(
"SELECT id, name, bio, age FROM users WHERE id IN (?)", missing
)
photos = db.query(
"SELECT user_id, url FROM photos WHERE user_id IN (?) ORDER BY position",
missing
)
# Cache for next request (1-hour TTL, profiles change infrequently)
cache.mset({f"profile:{p.id}": p for p in db_profiles}, ttl=3600)
return profiles
Cache hit rate optimization: Preload profiles for top-scoring candidates during pool generation. When users open the app, their likely-to-see profiles are already warm in cache.
Precomputed pools rely on static location. When Alice flies from NYC to LA, her segment pool becomes useless.
Hybrid fetch detects travel and switches strategy:
def get_feed(user_id):
current_location = get_current_location(user_id) # GPS / IP
if current_location.city == user.home_city:
return get_feed_from_segment(user_id) # Fast: precomputed pool
else:
return get_feed_from_geospatial(user_id, current_location) # Live query
| Aspect | Segment Pool | Live Geospatial |
|---|---|---|
| Latency | 10-50 ms | 50-200 ms |
| DB load | Low (cached pools) | Higher (live query) |
| Accuracy | Stale (based on home city) | Precise (current GPS) |
| When to use | 95% of requests (users at home) | 5% of requests (travelers) |
Geospatial tech options: Redis GEORADIUS (simple distance), PostGIS (compound filters), Elasticsearch (large-scale geo + text search). Start with Redis, migrate to PostGIS when compound filters are needed.
Location update strategy: Separate geospatial index (changes hourly, for real-time discovery) from home_city (changes after 30+ days sustained presence, for segment pool assignment). This prevents thrashing — a weekend trip to Vegas shouldn't rebuild your entire candidate pool.
After Bloom Filter exclusion, we have ~800 valid candidate IDs from the segment pool. Before returning 20 profiles, we rank them. The ranking pipeline has three stages:
Stage 1: Score Computation. Each candidate gets a composite score combining multiple signals:
def compute_score(candidate, user):
recency = decay(candidate.last_active, half_life_hours=48)
distance = 1.0 / (1.0 + km_distance(user, candidate))
popularity = log(1 + candidate.likes_received_24h, 10)
elo_match = 1.0 / (1.0 + abs(user.elo - candidate.elo))
return (0.3 * recency + 0.25 * distance + 0.2 * popularity + 0.25 * elo_match)
Stage 2: Diversity Injection. Showing only top-scored candidates creates filter bubbles. Inject 10-20% random candidates to increase diversity. Use stratified sampling: pick 16 top-scored + 4 random from the remaining pool.
Stage 3: Position Bias Correction. Users swipe more generously on the first few profiles (position bias). Place medium-confidence candidates early and high-confidence at positions 5-8 where users are more selective.
| Ranking Factor | Weight | Why |
|---|---|---|
| Recency (last active) | 30% | Ghost profiles kill engagement |
| Distance | 25% | Closer users are more likely to meet |
| Elo/Compatibility | 25% | Similar attractiveness scores improve match rates |
| Popularity (24h likes) | 20% | Social proof, but dampened to prevent runaway popularity |
A Bloom Filter is a probabilistic data structure that can tell you "definitely not in the set" or "probably in the set." For feed exclusion, false positives (incorrectly excluding a valid candidate) are harmless — the user just sees one fewer profile. False negatives (showing an already-swiped user) would be bad UX, but Bloom Filters never produce false negatives.
Sizing formula: For n items with false positive rate p:
- Bits needed: m = -n × ln(p) / (ln(2))²
- Hash functions: k = (m/n) × ln(2)
For a power user with 100,000 swipes and 0.01% false positive rate:
- m = -100,000 × ln(0.0001) / (ln(2))² = 1,917,011 bits ≈ 234 KB
- k = 13 hash functions
import mmh3
from bitarray import bitarray
class BloomFilter:
def __init__(self, expected_items=100_000, fp_rate=0.0001):
self.size = int(-expected_items * 2.302585 / (0.693147 ** 2) * abs(fp_rate))
self.num_hashes = int(self.size / expected_items * 0.693147)
self.bits = bitarray(self.size)
self.bits.setall(0)
def add(self, item):
for seed in range(self.num_hashes):
idx = mmh3.hash(str(item), seed) % self.size
self.bits[idx] = 1
def contains(self, item):
return all(
self.bits[mmh3.hash(str(item), seed) % self.size]
for seed in range(self.num_hashes)
)
Redis integration: Store the Bloom Filter as a Redis string (raw bytes). Use BF.ADD and BF.EXISTS commands from the RedisBloom module for server-side operations. This avoids transferring the entire filter to the application layer.
Pipelined alternative: For users with fewer than 1,000 swipes, a simple Redis SET + SISMEMBER is cheaper than maintaining a Bloom Filter. Use a threshold: Bloom Filter for users with >5,000 swipes, Redis SET for smaller users.
The offline batch job runs daily (typically 2-4 AM local time) and rebuilds segment pools:
def rebuild_segment_pools():
segments = {}
# Phase 1: Assign each user to their target segments
for user in db.stream_all_active_users():
# A user seeking "women aged 25-30 in NYC" maps to segment "nyc:female:25-30"
target_segment = f"{user.city}:{user.preferred_gender}:{age_bucket(user.preferred_age_min, user.preferred_age_max)}"
candidate_segment = f"{user.city}:{user.gender}:{age_bucket(user.age, user.age)}"
if candidate_segment not in segments:
segments[candidate_segment] = []
segments[candidate_segment].append({
"candidate_id": user.id,
"score": compute_base_score(user), # Pre-computed, not personalized
})
# Phase 2: Truncate large segments, keep top-scored candidates
for seg_id, candidates in segments.items():
candidates.sort(key=lambda c: c["score"], reverse=True)
segments[seg_id] = candidates[:5000] # Cap at 5,000 per segment
# Phase 3: Atomic swap (write to new table, then rename)
db.execute("CREATE TABLE segment_pools_new AS SELECT * FROM segment_pools WHERE 1=0")
for seg_id, candidates in segments.items():
db.batch_insert("segment_pools_new", [
{"segment_id": seg_id, "candidate_id": c["candidate_id"], "score": c["score"]}
for c in candidates
])
db.execute("ALTER TABLE segment_pools RENAME TO segment_pools_old")
db.execute("ALTER TABLE segment_pools_new RENAME TO segment_pools")
db.execute("DROP TABLE segment_pools_old")
| Design Choice | Decision | Why |
|---|---|---|
| Refresh frequency | Daily | Location/preferences change slowly; more frequent wastes compute |
| Max candidates per segment | 5,000 | Balance between variety and memory. Power users won't exhaust 5K in one session |
| Score at pool-build time | Base score only (no personalization) | Personalized scores require per-user computation → defeats the purpose of shared pools |
| Atomic swap vs incremental | Atomic table rename | Zero-downtime; no partial state visible to readers |
Age bucket strategy: 5-year buckets (18-22, 23-27, 28-32, 33-37, 38-42, 43-50, 51+). Users seeking "25-35" map to segments "25-27" + "28-32" + "33-37". Wider preferences span more segments but the union is still small (3-4 pool lookups vs a full table scan).
How do we scale to 100,000+ swipe writes per second?
A dating app with 20M DAU generates roughly 2 billion swipes per day — 23,000 writes/sec average, spiking to 100,000+ during evening peaks. A single PostgreSQL instance handles ~10,000 writes/sec. We need to shard the database.
The Core Tension
Every swipe involves two parties: the swiper (the person acting) and the swipee (the person being seen). Our two critical operations query different dimensions:
- Feed filtering asks "Who has Alice already seen?" → per-user query, runs on every app open (most frequent)
- Match detection asks "Did Bob already like Alice?" → per-pair query, runs once per swipe (less frequent)
These pull in opposite directions. One groups data by user; the other groups by pair. We can't optimize both with a single shard key.
Choosing the Shard Key
Shard key: hash(swiper_id) % num_shards
Put everything Alice does on one server. All of Alice's outgoing swipes — Alice→Bob, Alice→Carol, Alice→Dave — live on Alice's shard.
The win: Alice's feed generation is local. One query to Alice's shard returns everyone she's already seen. Feed exclusion becomes a single-shard operation.
The trade-off: Match detection becomes cross-shard. When Alice likes Bob, we write to Alice's shard, then send a network request to Bob's shard to check if Bob liked Alice. Every mutual swipe requires one cross-shard read (+5-10 ms).
Shard key: hash(min(user_a, user_b), max(user_a, user_b)) % num_shards
Put everything about Alice and Bob on the same server. Both Alice→Bob and Bob→Alice live together.
The win: Match detection is instant and local. Checking for Bob→Alice requires no network hop.
The fail: Alice's "already seen" list is scattered across every shard in the cluster. To generate Alice's feed, we must ask every single shard for her swipe history. This is scatter-gather, and at 256 shards, it kills performance.
The Verdict: Shard by Swiper ID
When we can only optimize one access pattern, we optimize for frequency:
- Feed queries: every app open (10-100× more frequent) → must be local
- Match checks: once per swipe → can tolerate 5-10 ms cross-shard penalty
The 5-10 ms penalty on match checks is invisible to users. But making every feed query scatter-gather would push latency from 10 ms to 200 ms+ — users would notice immediately.
The Hot Swipee Problem
Sharding by swiper evenly distributes writes, but creates read hot spots on popular users' shards. When 10,000 people swipe on Bob today, those writes scatter across 10,000 shards (one per swiper). But all match-detection reads hit Bob's shard.
Solution: Decouple the write from the match check via async processing.
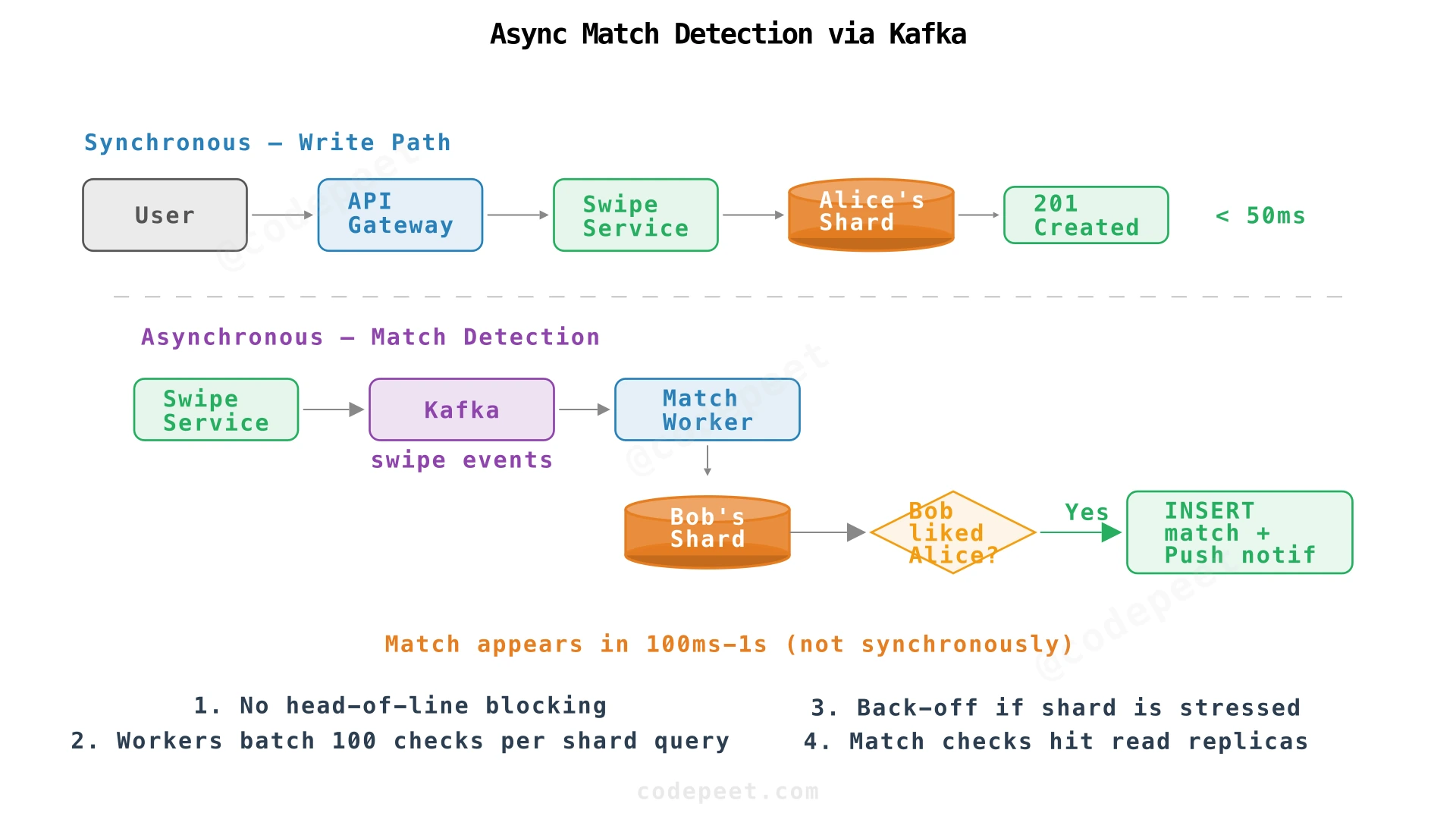
When Alice swipes on Bob:
- Swipe Service writes to Alice's shard immediately — always fast
- Swipe Service publishes event to Kafka
- Returns "Success" to Alice's phone in < 50 ms
- Background worker consumes the event, checks Bob's shard (using read replica)
- If match found → creates match row, sends push notification
Why this solves the hot shard problem:
- Batching: Instead of 10,000 individual queries to Bob's shard, workers batch:
WHERE swiper_id = :bob AND swipee_id IN (Alice, Carol, Dave, ...). One query checks 100 users. - Back-off: If Bob's shard is stressed, workers wait a few seconds. The database doesn't crash.
- Read replicas: Match detection reads from replicas (eventual consistency), not Bob's primary write database.
Trade-off: Matches appear in 100 ms – 1 s instead of instantly. The system turns a synchronous failure (Alice's app hangs because Bob is popular) into an asynchronous delay (the match appears 1 second later).
Bloom Filters in the Caching Layer
With shard-by-swiper, Alice's swipes live on one shard. Query once, cache in Redis:
# Write path: update cached exclusion set incrementally
def record_swipe(swiper_id, swipee_id, liked):
db.insert_swipe(swiper_id, swipee_id, liked) # Write to swiper's shard
bloom_filter.add(f"swiped:{swiper_id}", swipee_id)
cache.expire(f"swiped:{swiper_id}", days=30)
# Read path: use Bloom filter for feed exclusion
def get_feed(user_id):
candidates = get_candidate_pool(user_id, limit=10000)
valid = [c for c in candidates
if not bloom_filter.contains(f"swiped:{user_id}", c.id)
and not bloom_filter.contains(f"matched:{user_id}", c.id)]
return rank_and_limit(valid, limit=20)Why not use Bloom Filters to fix scatter-gather? A common question: "Can't we cache a Bloom Filter with shard-by-pair to avoid scatter-gather?" No — to build the Bloom Filter you must first collect all of Alice's swipes, which still requires asking every shard. On Friday night with 10,000 simultaneous logins, this creates a thundering herd of 1 million cross-shard queries. Bloom Filters optimize memory after retrieval, not data locality.
The async match detection pipeline uses a Kafka consumer group with partition-aware processing:
# Kafka topic: 'swipe-events', partitioned by swipee_id
# This ensures all swipes FOR the same person route to the same consumer
# (avoiding duplicate match detection)
class MatchDetectionWorker:
def __init__(self, consumer_group="match-detection"):
self.consumer = KafkaConsumer(
"swipe-events",
group_id=consumer_group,
value_deserializer=json.loads
)
self.batch = []
self.batch_size = 100
self.flush_interval_ms = 500
def process(self):
for message in self.consumer:
event = message.value
if event["liked"]:
self.batch.append(event)
if len(self.batch) >= self.batch_size or self.time_since_last_flush() > self.flush_interval_ms:
self.flush_batch()
def flush_batch(self):
if not self.batch:
return
# Group by swipee to batch queries to the same shard
by_swipee = defaultdict(list)
for event in self.batch:
by_swipee[event["swipee_id"]].append(event["swiper_id"])
for swipee_id, swiper_ids in by_swipee.items():
# Single batched query to swipee's shard (via read replica)
reverse_likes = db.read_replica.query(
"SELECT swipee_id FROM swipes "
"WHERE swiper_id = %s AND swipee_id IN %s AND liked = TRUE",
swipee_id, tuple(swiper_ids)
)
# reverse_likes contains IDs that swipee has liked back
for match_partner in reverse_likes:
create_match_if_not_exists(swipee_id, match_partner)
send_push_notification(swipee_id, match_partner)
self.batch.clear()
Partition strategy: Partition by swipee_id (not swiper_id). This ensures all "did X like me back?" checks for the same person route to the same consumer. Without this, two consumers might both detect (and both create) the same match.
Backpressure handling: If a consumer falls behind (e.g., celebrity user with 50K incoming swipes):
- Consumer lag metrics trigger alerts at 10K messages
- At 50K lag, auto-scale consumer instances for that partition
- At 100K lag, shed low-priority checks (pass swipes) and focus on likes only
At 2B swipes/day, storage grows by ~80 GB daily (40 bytes per swipe). After 90 days, you're sitting on 7.2 TB. Most of this data is "cold" — users rarely look up swipes older than a few weeks.
Tiered storage strategy:
| Tier | Age | Storage | Access Pattern |
|---|---|---|---|
| Hot | 0-7 days | NVMe SSD, primary shard | Feed exclusion, match detection |
| Warm | 7-30 days | SSD, read replicas | "Who liked me" lookups, audit |
| Cold | 30-90 days | HDD / S3 Glacier | Compliance, dispute resolution |
| Archive | 90+ days | S3 Glacier Deep Archive | Legal holds only |
Compaction for pass swipes: Left swipes (passes) are only needed for feed exclusion ("don't show again"). After 30 days of Bloom Filter membership, the exact swipe record is redundant. Batch job compacts pass swipes older than 30 days:
-- Compact pass swipes: transfer to Bloom Filter, then delete records
WITH old_passes AS (
SELECT swiper_id, swipee_id
FROM swipes
WHERE liked = FALSE
AND created_at < NOW() - INTERVAL '30 days'
LIMIT 100000
)
DELETE FROM swipes
WHERE (swiper_id, swipee_id) IN (SELECT swiper_id, swipee_id FROM old_passes);
-- Bloom Filter already contains these entries from the write path
This compaction reduces active storage by ~60% (most swipes are passes).
At 100K writes/sec peak, naive connection management becomes the bottleneck before the database does.
Connection pool sizing: With 16 shards and 8 Swipe Service instances:
- Max connections per shard: 8 instances × 20 connections = 160
- PostgreSQL max_connections per shard: 200 (leaving 40 for admin/monitoring)
- Total cluster connections: 16 × 200 = 3,200
Write batching with PgBouncer:
; pgbouncer.ini
[pgbouncer]
pool_mode = transaction
max_client_conn = 2000
default_pool_size = 50
reserve_pool_size = 10
reserve_pool_timeout = 3
server_lifetime = 3600
Transaction pooling mode releases the server connection after each transaction completes, allowing 2,000 application connections to share 50 actual PostgreSQL connections.
Prepared statements: The swipe INSERT is the same query 100K times/sec with different parameters. Prepared statements eliminate parsing overhead:
PREPARE insert_swipe (bigint, bigint, boolean) AS
INSERT INTO swipes (swiper_id, swipee_id, liked) VALUES ($1, $2, $3);
EXECUTE insert_swipe(123, 456, true);
How do we handle simultaneous swipes without losing matches?
Both users swipe right at the exact same moment. Both transactions write their swipe. Both transactions check for the reverse swipe. But neither transaction sees the other's uncommitted write. Result: two swipes recorded, zero matches created.
This is the classic write-write race condition under READ COMMITTED isolation (the default in PostgreSQL).
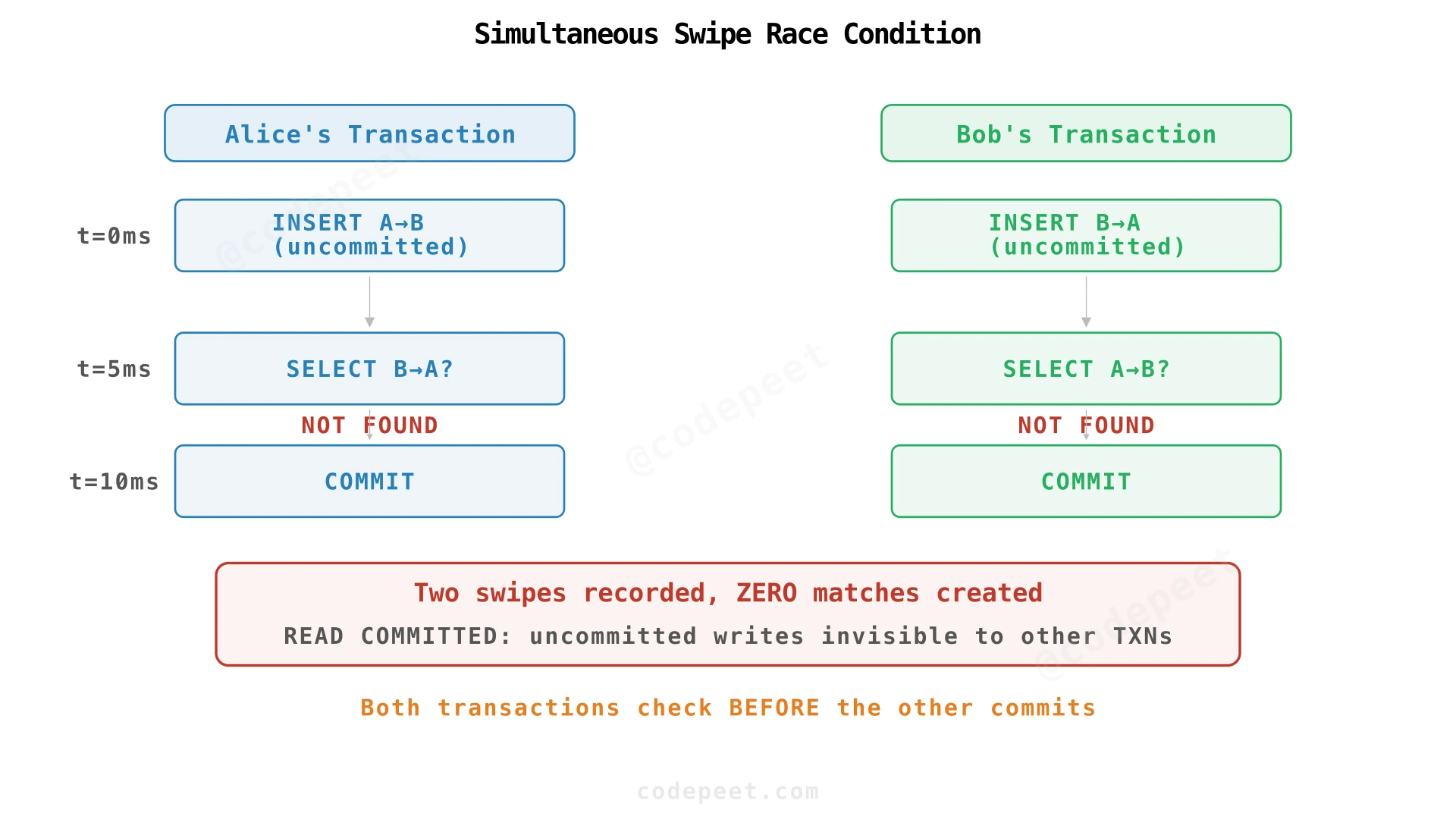
Solution 1: Background Reconciliation (Recommended for Scale)
A periodic job scans for mutual likes without corresponding match rows:
-- Runs every 30-60 seconds via background worker
INSERT INTO matches (user_a, user_b, created_at)
SELECT LEAST(s1.swiper_id, s1.swipee_id),
GREATEST(s1.swiper_id, s1.swipee_id),
NOW()
FROM swipes s1
JOIN swipes s2
ON s1.swiper_id = s2.swipee_id
AND s1.swipee_id = s2.swiper_id
WHERE s1.liked = TRUE
AND s2.liked = TRUE
AND NOT EXISTS (
SELECT 1 FROM matches m
WHERE m.user_a = LEAST(s1.swiper_id, s1.swipee_id)
AND m.user_b = GREATEST(s1.swiper_id, s1.swipee_id)
)
ON CONFLICT DO NOTHING; -- PRIMARY KEY prevents duplicatesAdvantages: Simple, no performance impact on write path, catches ALL race conditions (not just simultaneous swipes), scales independently.
Trade-off: Users see matches within seconds instead of milliseconds for the rare race case. Most matches are still detected immediately via inline checks.
Solution 2: Two-Transaction Approach (Eliminates Race Entirely)
Split into separate transactions so the second transaction sees the first's committed write:
def record_swipe(swiper_id, swipee_id, liked):
# Transaction 1: Write the swipe (commits immediately)
with db.transaction():
db.insert_swipe(swiper_id, swipee_id, liked)
# Transaction 2: Check for match (sees all committed writes)
if liked:
with db.transaction():
reverse = db.query(
"SELECT 1 FROM swipes WHERE swiper_id=? AND swipee_id=? AND liked=TRUE",
swipee_id, swiper_id
)
if reverse:
db.insert_match(min(swiper_id, swipee_id), max(swiper_id, swipee_id))With READ COMMITTED, Transaction 2 sees all committed changes. At least one SELECT will see the committed INSERT. Both might create the match (caught by PRIMARY KEY), but zero matches is impossible.
Trade-off: 2× transaction overhead (46,000 txn/sec instead of 23,000). At high scale, this doubles connection pool usage and redo log volume.
Pair Model: No Race Condition at All
The Pair Model eliminates the race entirely via row-level locking. Both Alice and Bob target the same row:
INSERT INTO user_pairs (user_a, user_b, a_liked_b, b_liked_a)
VALUES (LEAST(:alice, :bob), GREATEST(:alice, :bob), TRUE, NULL)
ON CONFLICT (user_a, user_b)
DO UPDATE SET
a_liked_b = TRUE,
matched_at = CASE WHEN user_pairs.b_liked_a = TRUE THEN NOW() ELSE NULL END;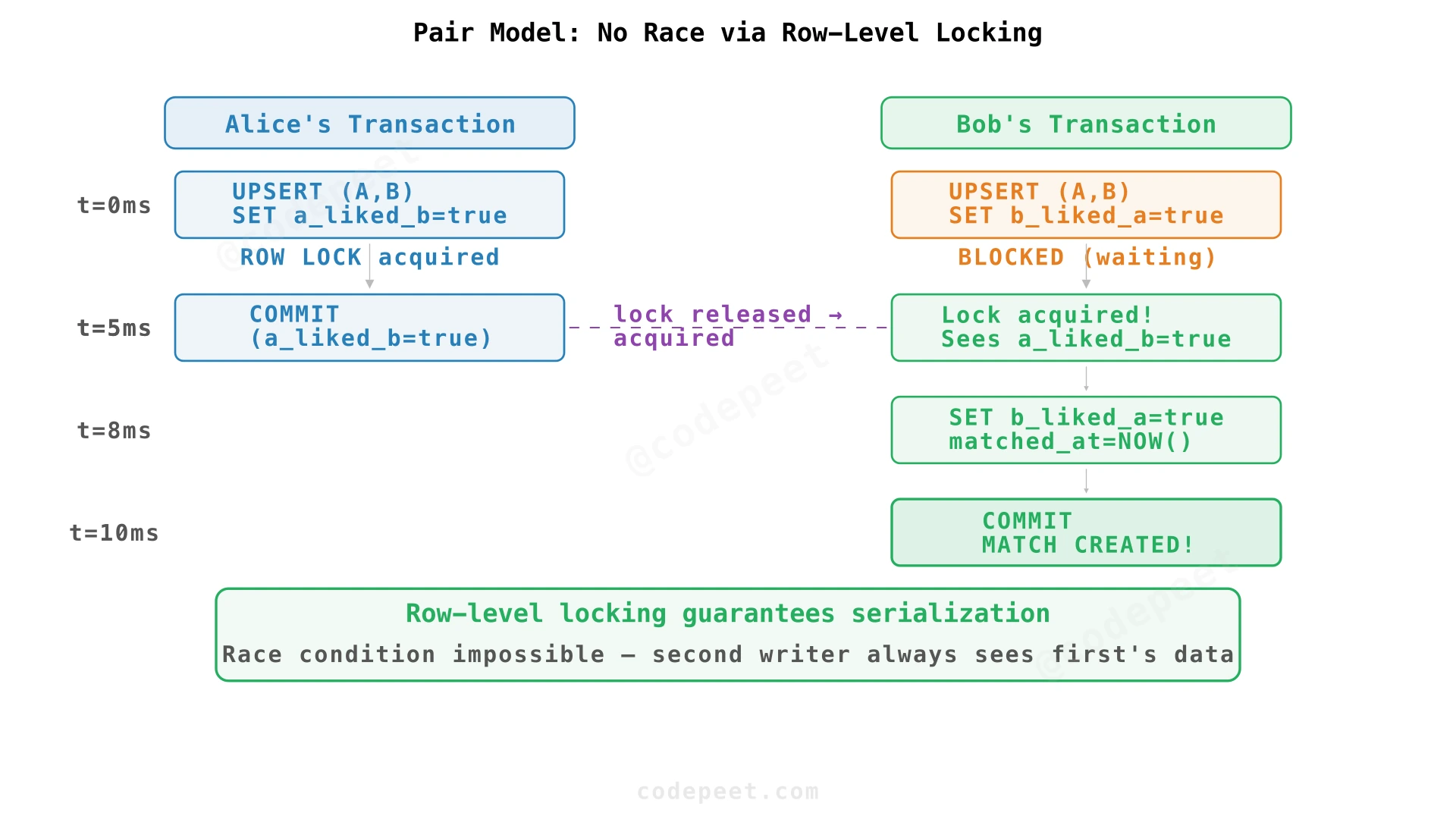
The database's UNIQUE constraint on (user_a, user_b) forces one transaction to wait. The second transaction always sees the first's committed changes.
Choosing the Right Solution
| Solution | Best For | Trade-off |
|---|---|---|
| Background Reconciliation | High-scale systems (recommended) | Catch-up delay of seconds for race cases |
| Two-Transaction | Lower-scale systems | 2× transaction overhead |
| Pair Model | Apps where match state integrity is paramount | Complex per-user queries |
All approaches require the PRIMARY KEY constraint with canonical ordering (user_a < user_b) on the matches table.
The race condition only exists because of how PostgreSQL's default isolation level (READ COMMITTED) handles concurrent transactions. Let's trace through the exact mechanics:
READ COMMITTED (PostgreSQL default):
- Each statement sees only rows committed before that statement began
- If Alice's INSERT is uncommitted when Bob's SELECT runs, Bob cannot see Alice's row
- This is why: INSERT(Alice→Bob) → SELECT(Bob→Alice) → invisible → MISS → no match
REPEATABLE READ:
- Each statement sees only rows committed before the transaction began
- Makes the race condition worse — even if Alice's INSERT commits before Bob's SELECT, Bob still sees the snapshot from transaction start
- Never use for this purpose
SERIALIZABLE:
- PostgreSQL detects read-write conflicts and aborts one transaction
- Would catch the simultaneous swipe race, but at heavy cost: retry logic for every aborted transaction, reduced throughput
- Too expensive for 23K writes/sec
The real fix is architectural, not isolation-level:
| Fix | Mechanism | Cost |
|---|---|---|
| Background reconciliation | Periodic scan for unmatched mutual likes | Zero impact on write path |
| Two-transaction | Second txn always sees first's commit | 2× transaction count |
| Pair model | Row lock serializes concurrent writes | Per-user query complexity |
| SERIALIZABLE isolation | Database detects conflicts | 30-50% throughput reduction + retry logic |
The recommended approach for most systems: Background reconciliation + inline optimistic check. The optimistic inline check catches 99.9% of matches instantly. The background job catches the 0.1% of race conditions within seconds.
def record_swipe_with_optimistic_match(swiper_id, swipee_id, liked):
# Transaction 1: Write the swipe
with db.transaction():
db.execute("INSERT INTO swipes VALUES (%s, %s, %s)", swiper_id, swipee_id, liked)
# Optimistic check (outside transaction, sees committed state)
if liked:
reverse = db.query_one(
"SELECT 1 FROM swipes WHERE swiper_id=%s AND swipee_id=%s AND liked=TRUE",
swipee_id, swiper_id
)
if reverse:
try:
db.execute(
"INSERT INTO matches (user_a, user_b) VALUES (LEAST(%s,%s), GREATEST(%s,%s))",
swiper_id, swipee_id, swiper_id, swipee_id
)
return {"matched": True}
except UniqueViolation:
return {"matched": True} # Already created by the other side — still a match!
return {"matched": False}
The UniqueViolation catch is key: if both sides detect the match simultaneously, one INSERT succeeds and the other gets a duplicate key error. We catch it and still return "matched" — the database's uniqueness constraint guarantees exactly one match row.
How do we handle hot users without destroying feed fairness?
Some users receive vastly more attention than others. This creates two compounding problems:
The load problem: Hot users' profiles get fetched repeatedly. Their cache entries consume disproportionate memory. The system spends most resources on a tiny fraction of users.
The fairness problem: Without intervention, popularity compounds. Hot users appear in more feeds → receive more swipes → rank higher → get more exposure. The top 1% consume most impressions. Average users get buried.
Breaking the Feedback Loop
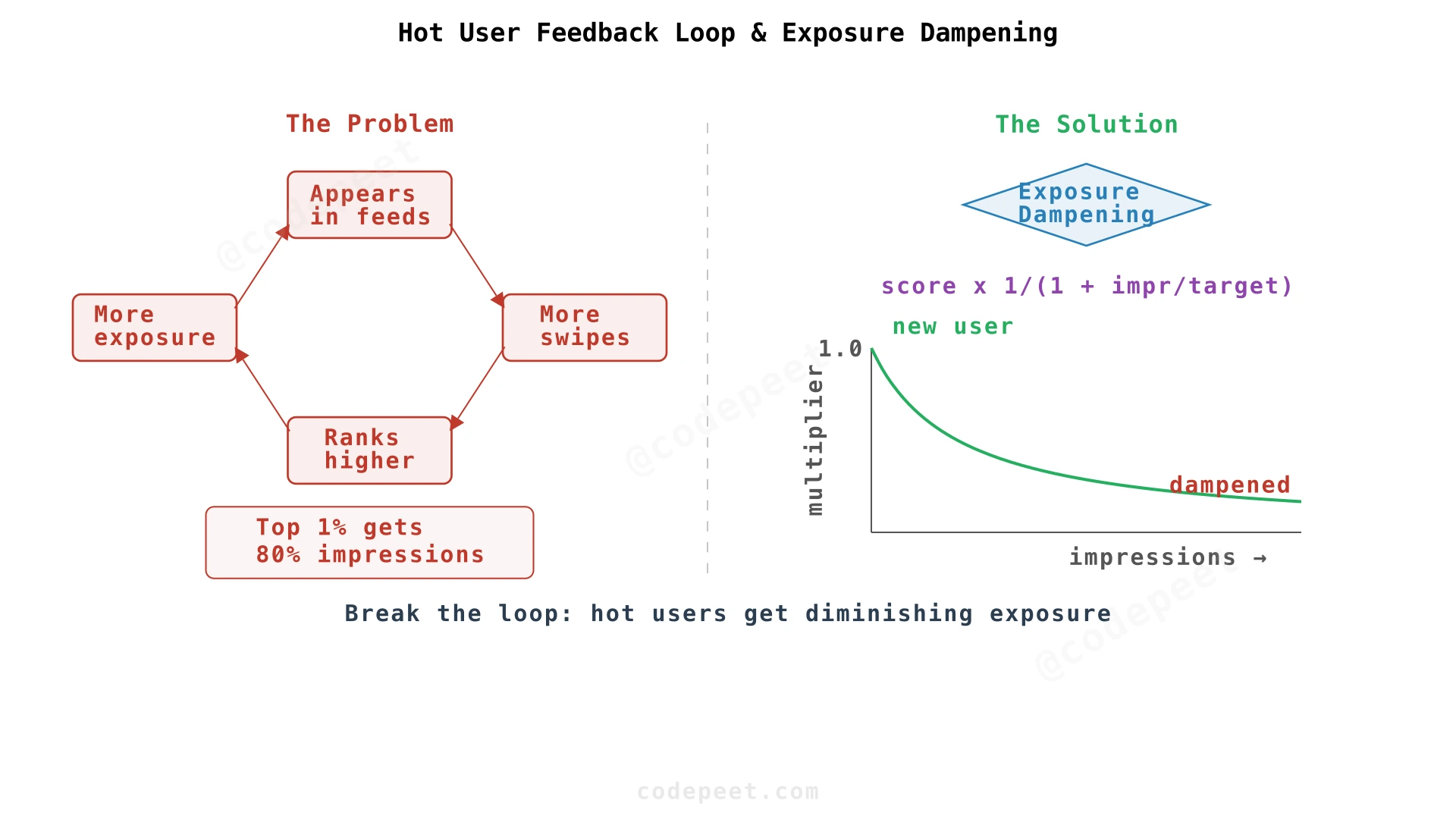
Exposure dampening formula:
def adjusted_score(base_score, impressions_today, target_impressions=1000):
exposure_ratio = impressions_today / target_impressions
dampening = 1 / (1 + exposure_ratio)
return base_score * dampening
| Impressions Today | Multiplier | Effect |
|---|---|---|
| 500 | 0.67× | Slight penalty |
| 1,000 | 0.50× | Half score |
| 10,000 | 0.09× | Heavily penalized |
| 100,000 | 0.01× | Nearly invisible |
Additional fairness mechanisms:
- Boost under-exposed users in ranking (affirmative action for new/less-popular users)
- Global impression cap: max N impressions per user per day
- Randomization: inject 10-20% random candidates to break filter bubbles
- Cache hot profiles aggressively (longer TTL, pre-warmed across regions)
Many dating apps use an ELO-style rating system (borrowed from chess) to estimate "desirability" and improve feed quality:
class ELOSystem:
K_FACTOR = 32 # How much each swipe moves the rating
BASE_RATING = 1000
def update_ratings(self, swiper_rating, swipee_rating, swipe_is_like):
# Expected probability that swiper likes swipee
expected = 1.0 / (1.0 + 10 ** ((swipee_rating - swiper_rating) / 400))
# Actual outcome: 1 for like, 0 for pass
actual = 1.0 if swipe_is_like else 0.0
# Update swipee's rating based on who swiped on them
swipee_new = swipee_rating + self.K_FACTOR * (actual - expected)
# If a "high-rated" user likes a "low-rated" user, the low-rated user's
# score increases more (they're "better than expected")
return swipee_new
| Aspect | ELO For | ELO Against |
|---|---|---|
| Feed quality | Shows compatible-tier profiles | Creates echo chambers |
| Match rates | Similar-ELO matches work better | Users don't know their tier (frustrating) |
| Fairness | Prevents "spam liking" strategy | Punishes new users (cold start) |
| Privacy | Internal signal only | Ethical concerns about "rating" people |
Cold start problem: New users have no ELO history. Solution: assign initial ELO based on profile completeness (photos, bio length, verification status) and boost for first 48 hours.
Decay: Inactive users' ELO decays toward the mean over 30 days. This prevents ghost profiles from clogging high-ELO tiers.
Should match detection be synchronous or asynchronous?
Synchronous: Write swipe → check for reverse → create match → return status. User sees "It's a Match!" immediately.
Asynchronous: Write swipe → return immediately. Background worker finds mutual likes, creates match, sends push notification.
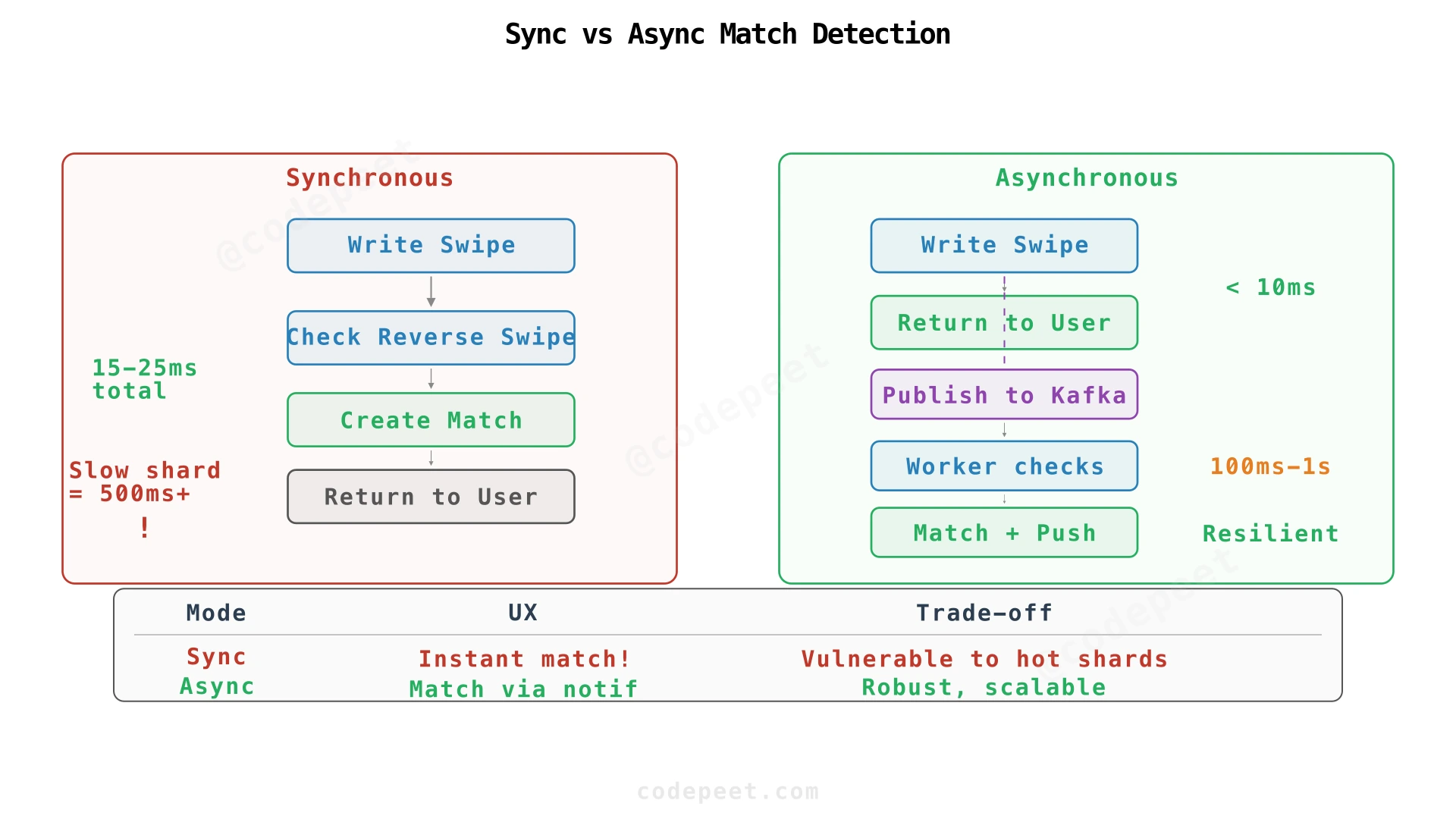
| Aspect | Synchronous | Asynchronous |
|---|---|---|
| User experience | Instant "It's a Match!" | Match appears via notification |
| Write latency | Higher (includes match check) | Lower (write only) |
| Hot shard resilience | Vulnerable (hangs if target shard is slow) | Resilient (workers batch and back-off) |
| Complexity | Simpler (single code path) | Higher (Kafka + background workers) |
| Consistency | Immediate | Eventual (seconds delay) |
Recommended: Start synchronous for simplicity. Switch to async when hot-shard issues appear at scale. The hybrid approach works too — synchronous for same-region match checks, async for cross-region.
How do we implement 'Who Liked Me' for premium users?
Premium users pay to see incoming likes before swiping back. This is a new directional query: "who liked me?"
With Directed Model (natural fit):
SELECT s.swiper_id, s.created_at, u.name, u.photos
FROM swipes s
JOIN users u ON u.id = s.swiper_id
WHERE s.swipee_id = :user_id
AND s.liked = TRUE
AND NOT EXISTS (
SELECT 1 FROM swipes reverse
WHERE reverse.swiper_id = :user_id
AND reverse.swipee_id = s.swiper_id
)
ORDER BY s.created_at DESC;Index on (swipee_id, liked) makes this efficient. The query directly expresses "edges pointing at me."
With Pair Model (awkward): You must decode direction from symmetric fields with OR conditions. Often requires building a separate incoming_likes(user_id, liker_id) projection.
Design considerations:
- Ranking: Prioritize active users and recent likes
- Staleness: Filter extremely old likes (90+ days)
- Performance: Dedicated cache for premium users' incoming likes list
- Privacy: Don't reveal exact timestamps to prevent stalking patterns
For premium users, we maintain a pre-materialized list of incoming likes in Redis:
# Write path: when someone likes a premium user, update their cache
def on_swipe_event(swiper_id, swipee_id, liked):
if liked and is_premium(swipee_id):
redis.zadd(
f"incoming_likes:{swipee_id}",
{swiper_id: time.time()} # Score = timestamp for ordering
)
# Trim to most recent 500 likes
redis.zremrangebyrank(f"incoming_likes:{swipee_id}", 0, -501)
# Read path: premium user views "Who Liked Me"
def get_incoming_likes(user_id, limit=20, cursor=None):
max_score = cursor or "+inf"
liker_ids = redis.zrevrangebyscore(
f"incoming_likes:{user_id}",
max_score, "-inf",
start=0, num=limit
)
# Filter out already-swiped (user already decided on these)
unswiped = [lid for lid in liker_ids
if not bloom_filter.contains(f"swiped:{user_id}", lid)]
profiles = fetch_profiles(unswiped)
return profiles
Why a sorted set? The ZADD score (timestamp) enables cursor-based pagination and automatic deduplication. ZREVRANGEBYSCORE returns likes in reverse chronological order.
Blurred preview for free users: Free users see a count and blurred thumbnails of incoming likes. The blurred preview uses the same Redis sorted set but only returns the count and photo URLs (heavily degraded quality):
def get_blurred_likes_preview(user_id):
count = redis.zcard(f"incoming_likes:{user_id}")
recent_ids = redis.zrevrange(f"incoming_likes:{user_id}", 0, 2)
blurred_photos = [get_blurred_photo(uid) for uid in recent_ids]
return {"count": count, "preview": blurred_photos}
How does blocking propagate through all system layers?
Users can block or report others. Blocking has bidirectional effects: if Alice blocks Bob, neither should see the other anywhere — in feeds, matches, or search results.
CREATE TABLE blocks (
blocker_id BIGINT NOT NULL,
blocked_id BIGINT NOT NULL,
reason VARCHAR(50),
created_at TIMESTAMP DEFAULT NOW(),
PRIMARY KEY (blocker_id, blocked_id)
);Integration points:
| System | Block Effect |
|---|---|
| Feed | Exclude blocked users in both directions |
| Swipe handling | Reject swipes on blocked users |
| Match creation | Do not create match if block exists |
| Existing matches | Soft-delete or disable the match + chat |
| "Who Liked Me" | Hide blocked users from incoming likes |
Consistency challenges:
| Scenario | Decision |
|---|---|
| Block after match | Soft-delete match, disable chat, notify neither user |
| Block while in cached feed | Remove from card stack within 1 minute via cache invalidation |
| Unblock | Start fresh (don't restore previous state) |
Implementation principle: Safety features override all other logic. Build block checks as a mandatory filter layer that cannot be bypassed by any service. Every query that returns user-visible data must pass through the block check.
When Alice blocks Bob, the block must propagate through multiple systems:
async def block_user(blocker_id, blocked_id, reason):
# Step 1: Record the block
db.execute(
"INSERT INTO blocks (blocker_id, blocked_id, reason) VALUES (%s, %s, %s)",
blocker_id, blocked_id, reason
)
# Step 2: Invalidate cached data
bloom_filter.add(f"blocked:{blocker_id}", blocked_id)
bloom_filter.add(f"blocked:{blocked_id}", blocker_id) # Bidirectional
# Step 3: Soft-delete existing match (if any)
db.execute(
"UPDATE matches SET deleted_at = NOW() "
"WHERE user_a = LEAST(%s,%s) AND user_b = GREATEST(%s,%s) AND deleted_at IS NULL",
blocker_id, blocked_id, blocker_id, blocked_id
)
# Step 4: Publish block event (async propagation to all services)
kafka.publish("block-events", {
"blocker_id": blocker_id,
"blocked_id": blocked_id,
"timestamp": datetime.utcnow().isoformat(),
})
# Step 5: Clear from any active feed sessions (real-time)
await websocket.send_to(blocker_id, {"type": "remove_card", "user_id": blocked_id})
Why bidirectional Bloom Filter entries? When Alice blocks Bob, both blocked:Alice includes Bob AND blocked:Bob includes Alice. This ensures feed generation for both users excludes the other, without requiring two table lookups per candidate.
Feed integration: The feed generation pipeline checks blocks alongside the swipe exclusion:
valid = [c for c in candidates
if not bloom_filter.contains(f"swiped:{user_id}", c.id)
and not bloom_filter.contains(f"matched:{user_id}", c.id)
and not bloom_filter.contains(f"blocked:{user_id}", c.id)] # Block check
Audit trail: All blocks are logged to an immutable audit table for safety reviews and dispute resolution. Reports trigger automated review workflows if a user accumulates >3 blocks within 24 hours.
How do we deploy across multiple regions for global users?
At global scale, deploy per-region. Each user is assigned a home region based on signup location. All of a user's writes go to their home region.
Core principle: User state (swipes, matches) lives in the home region. Profiles replicate more widely for discovery.
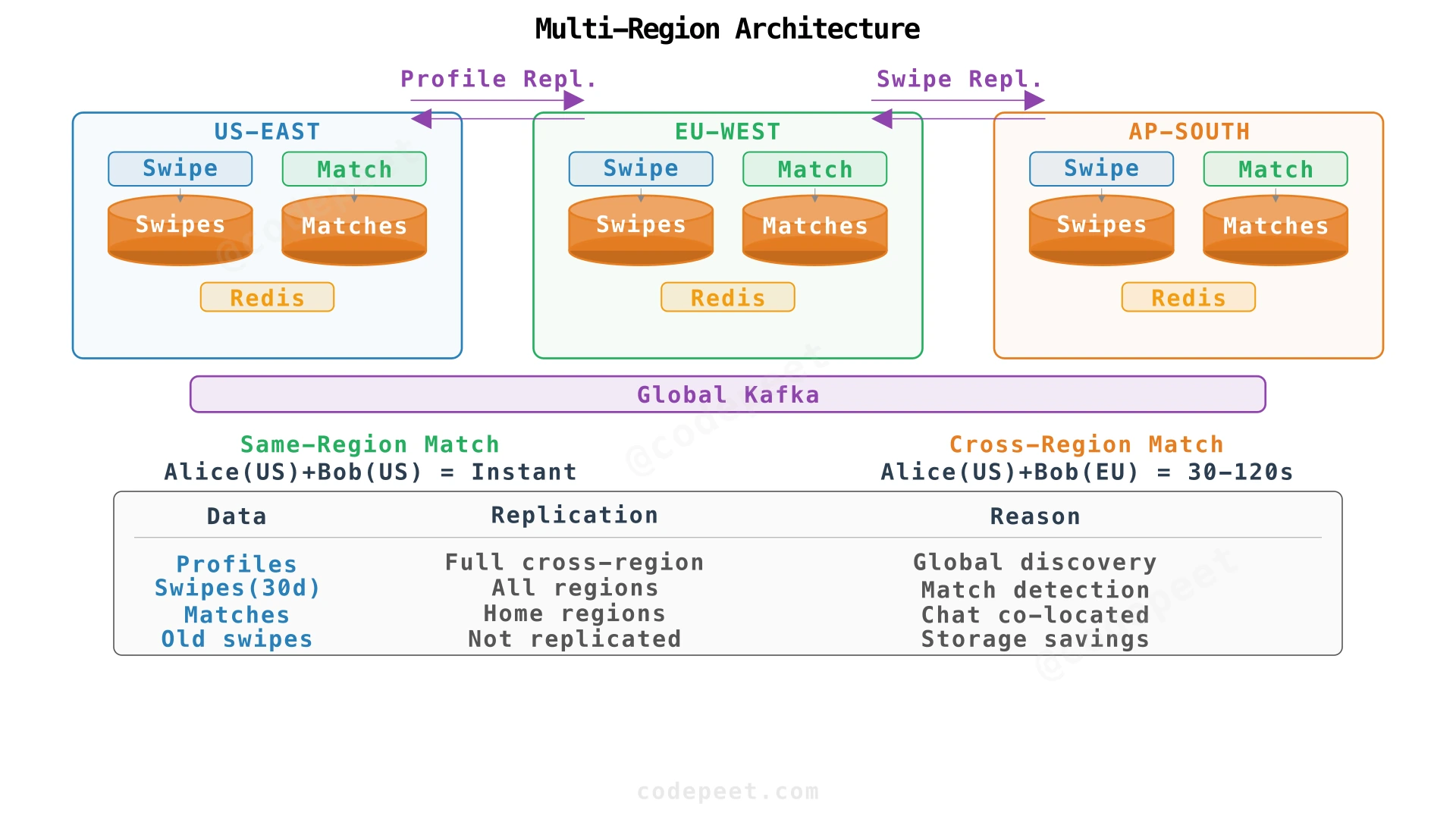
Same-Region Matching
Both Alice and Bob in US-EAST. Alice swipes right on Bob. Match detection reads Bob's swipes from the same region. Fast, consistent, simple.
Cross-Region Matching
Alice (US-EAST) travels to Europe, swipes on Bob (EU-WEST):
| Approach | Latency Impact | Match Detection | Failure Mode |
|---|---|---|---|
| Sync cross-region read | +100-300 ms per swipe | Immediate | Cross-region outage blocks matches |
| Async via replication | No added latency | 30s-2min delay | Graceful degradation |
Recommended hybrid: Synchronous for same-region matches (instant feedback), asynchronous for cross-region (push notification within 30-120 seconds).
Consistency Choices by Feature
| Feature | Consistency Level | Rationale |
|---|---|---|
| Feed candidates | Eventual | Can tolerate stale profiles |
| "Who liked me" | Eventual | Premium feature, can wait |
| Local-region match | Strong | Immediate feedback expected |
| Cross-region match | Eventual | Acceptable delay for tourists |
| Chat messages | Strong within region | Conversation integrity |
Users are assigned a home region at signup based on their IP geolocation. This determines where their swipe and match data lives.
Region assignment logic:
def assign_home_region(user_ip, signup_location):
geo = geoip_lookup(user_ip)
# Map to nearest data center region
region_map = {
"North America": "us-east",
"South America": "us-east", # closest DC
"Europe": "eu-west",
"Africa": "eu-west",
"Asia": "ap-south",
"Oceania": "ap-south",
}
return region_map.get(geo.continent, "us-east")
def should_migrate_home_region(user_id):
# Only migrate after 30+ consecutive days in new region
locations = db.query(
"SELECT region, date FROM user_location_history "
"WHERE user_id = %s ORDER BY date DESC LIMIT 30",
user_id
)
if len(locations) < 30:
return None
new_region = locations[0]["region"]
if all(loc["region"] == new_region for loc in locations):
return new_region # User has been in new region for 30+ days
return None
Migration process (when a user permanently moves):
- Begin dual-write: new swipes written to BOTH old and new region
- Background job copies historical data (swipes, matches) to new region
- Verify data integrity with checksums
- Atomic cutover: update user's home_region field
- Stop dual-write, old data expires per retention policy
Why 30 days? Shorter thresholds cause thrashing for frequent travelers. A two-week vacation shouldn't trigger a full data migration (7 TB transfer per user with extensive history).
When Alice (US-EAST) swipes on Bob (EU-WEST), the request must be routed correctly:
Alice's phone → US-EAST API Gateway → US-EAST Swipe Service
↓ Write Alice's swipe to US-EAST (Alice's home shard)
↓ Publish event to Global Kafka: {swiper: Alice(US-EAST), swipee: Bob(EU-WEST)}
↓
Global Kafka → EU-WEST Match Detection Worker
↓ Read Bob's swipes from EU-WEST (Bob's home shard, read replica)
↓ If Bob liked Alice → Create match in BOTH regions
↓ Push notification to both Alice and Bob
DNS-based routing: Each user's home region is encoded in the API token. The API Gateway routes swipe writes to the swiper's home region, regardless of their current physical location. This means Alice on vacation in Paris still writes to US-EAST.
Global Kafka vs Regional Kafka:
| Approach | Pro | Con |
|---|---|---|
| Global Kafka (single cluster) | Simple routing, total ordering | Higher inter-region latency, single point of failure |
| Regional Kafka + bridge | Low local latency, independent failure domains | Complex routing, eventual consistency between clusters |
Start with regional Kafka + MirrorMaker bridge between regions. Each region processes local events immediately, cross-region events arrive within seconds via replication.
Multi-region systems must handle partial failures gracefully:
| Failure | Impact | Mitigation |
|---|---|---|
| US-EAST ↔ EU-WEST link down | Cross-region matches delayed | Queue swipe events, process when link restores |
| EU-WEST region down entirely | EU-WEST users can't swipe | DNS failover to US-EAST (higher latency, functional) |
| Kafka partition leader election | Swipe events delayed 5-30s | Consumer lag alerts, increased batch timeout |
| Read replica lag > 5s | Stale match detection | Promote replica or route to primary for critical checks |
Circuit breaker pattern: If cross-region match checks fail for 30+ seconds, stop attempting synchronous checks and rely entirely on async detection. Resume synchronous checks after the circuit heals.
class CrossRegionCircuitBreaker:
def __init__(self, failure_threshold=5, recovery_timeout_s=30):
self.failures = 0
self.threshold = failure_threshold
self.state = "CLOSED" # CLOSED → OPEN → HALF-OPEN
self.opened_at = None
self.recovery_timeout = recovery_timeout_s
def call(self, func, *args):
if self.state == "OPEN":
if time.time() - self.opened_at > self.recovery_timeout:
self.state = "HALF-OPEN"
else:
raise CircuitOpenError("Cross-region checks disabled")
try:
result = func(*args)
if self.state == "HALF-OPEN":
self.state = "CLOSED"
self.failures = 0
return result
except TimeoutError:
self.failures += 1
if self.failures >= self.threshold:
self.state = "OPEN"
self.opened_at = time.time()
raise
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions without prescriptive solutions. They are designed for staff+ conversations where you demonstrate systems thinking, trade-off analysis, and strategic decision-making.
Algorithmic Fairness and Marketplace Dynamics
Context: Your dating app has grown to 50M users. Data analysis reveals that the top 5% of users receive 80% of all likes. New users churn within 48 hours because they receive almost no engagement. The ranking algorithm — which prioritizes users with high swipe-back rates — creates a rich-get-richer dynamic. Product leadership asks you to "fix fairness" without tanking engagement metrics.
Discussion Points:
- How do you define "fair" in a two-sided marketplace where users are both supply and demand? Is it equal impressions? Equal match rates? Equal satisfaction?
- If you boost visibility for less-popular users, popular users see fewer high-quality options. They might churn to a competitor. How do you balance majority satisfaction against power-user retention?
- Exposure dampening penalizes attractive profiles. Is this "fair" in a different sense? Should users who contribute disproportionate value to the platform receive disproportionate exposure?
- How do you measure success? If you optimize for match volume, you might create low-quality matches. If you optimize for conversation starters, you penalize users who are selective. What's the right metric?
- A/B testing fairness algorithms is ethically tricky — some users in the control group get demonstrably worse outcomes. How do you design experiments that are both valid and ethical?
Evolving the Data Model Under Load
Context: Your team chose the Directed Swipes model at launch. Two years later, with 100M total swipes, the match detection cross-shard reads consume 40% of your database IOPS. Product is launching "Super Likes" (visible signal) and "Rewind" (undo last swipe) — features that modify existing swipe rows, which the Directed model handles poorly. An engineer proposes migrating to the Pair Table model. The database has 7 TB of swipes data.
Discussion Points:
- How do you migrate a 7 TB table from Directed to Pair format with zero downtime? What's the dual-write strategy? How do you verify correctness during migration?
- The Pair model fixes match detection IOPS but breaks feed queries. You'd need to build a per-user projection layer. Is the complexity worth the IOPS savings, or should you add read replicas instead?
- "Super Like" and "Rewind" both modify existing rows. Directed model requires finding and updating the right row. Pair model updates the same row. But Pair model with Rewind needs to track "previous state" — how do you handle undo without event sourcing?
- At what scale does the 40% IOPS overhead justify the migration risk? What if read replica count can absorb the load for 18 more months?
ML-Powered Feed Ranking at Scale
Context: Your dating app currently uses a simple scoring formula combining proximity, recency, and popularity. Product wants to move to an ML-powered ranking model that predicts match probability for each user pair. The training data includes swipe history, message engagement, profile similarity, and behavioral signals. The model needs to run for every feed request (700 QPS, each evaluating 1,000 candidates), with < 50 ms inference latency.
Discussion Points:
- Where do you run inference? Client-side is impossible (model size). Server-side with a model per request means 700K inferences/sec. How do you architect the inference pipeline for this throughput?
- The model needs features from multiple services: user profiles, swipe history, location, and engagement. How do you build a real-time feature store that serves these features with < 10 ms latency?
- A model that maximizes match probability may create filter bubbles (showing you only "safe" recommendations). How do you balance exploitation (show high-probability matches) vs exploration (show diverse profiles)?
- Model retraining with fresh data creates a feedback loop: the model learns from its own recommendations. How do you detect and prevent this self-reinforcing bias?
- How do you A/B test a new ranking model when the metric (match quality → conversation → date → relationship) takes weeks to measure?
Level Expectations
| Dimension | Mid-Level (L4) | Senior (L5) | Staff (L6) |
|---|---|---|---|
| Data Model | Can describe Directed vs Pair trade-offs, choose one with justification | Traces impact through all downstream systems (feed, sharding, race conditions) | Proposes migration strategy between models under load, discusses hybrid approaches |
| Feed Generation | Describes naive query and identifies scaling bottleneck | Designs segment pools + lazy hydration + Bloom Filters pipeline with storage math | Questions segment granularity trade-offs, designs ML ranking integration, handles traveling users |
| Sharding | Identifies need to shard, picks a shard key | Analyzes shard-by-swiper vs shard-by-pair trade-offs with frequency analysis | Addresses hot swipee problem with async pattern, discusses multi-region shard routing |
| Consistency | Knows simultaneous swipes can race | Designs background reconciliation or two-transaction fix with correct isolation reasoning | Evaluates when eventual consistency is acceptable, designs cross-region consistency model |
| Scale Reasoning | Provides rough scale numbers (swipes/sec, storage) | Calculates segment pool savings, Bloom Filter memory, Redis cache sizing | Questions assumptions: "What if swipe distribution is Zipfian?", designs for 10× growth |
| Service Design | Proposes reasonable service split with databases | Justifies split criteria (scaling profile, data ownership), designs inter-service contracts | Questions whether services should merge/split based on operational evidence, designs deployment topology |
Summary
Key Design Decisions
Data Model: Choose between Directed Swipes (two rows per mutual swipe, optimizes per-user queries) and Pair Table (one row per pair, optimizes per-pair queries). The choice affects feed queries, match detection, sharding strategy, and race condition handling. Directed Swipes is the recommended default — feed queries dominate access patterns.
Feed Generation: Separate slow-changing filters (location, preferences → precomputed offline) from fast-changing exclusions (already swiped → applied live via Bloom Filters). Segment pools reduce storage by 5,000× versus per-user pools. Lazy hydration reduces bandwidth by 50× by fetching IDs before profiles.
Scaling Swipe Writes: Shard by swiper_id to keep feed queries local. Accept cross-shard match checks as the less frequent operation. Handle hot swipees with async match detection via Kafka — batching, back-off, and read replicas protect popular users' shards.
Race Conditions: Simultaneous swipes create races in the Directed Model. Fix with background reconciliation jobs (recommended for scale) or the two-transaction approach (simpler for lower scale). The Pair Model eliminates races entirely via row-level locking.
Feature Expansion: Premium "Who Liked Me" reveals directional query requirements — Directed Model excels here. Blocking must propagate through every system layer as a mandatory filter. Multi-region deployment uses home regions for writes with async cross-region match detection.
Architecture Principles Applied
| Principle | Application |
|---|---|
| Group by data ownership | Each service owns its tables, preventing consistency nightmares |
| Optimize for frequency | Shard key chosen for the most frequent operation (feed), not the most complex (match) |
| Separate offline from online | Expensive filtering precomputed in batch jobs, cheap exclusions applied live |
| Async over sync at scale | Match detection decoupled from write path when hot-shard issues appear |
| Safety overrides UX | Block checks are mandatory filters that cannot be bypassed |
| Evolve incrementally | Start monolith → split by bottleneck evidence → full microservices only at 20M+ DAU |
Common Pitfalls to Avoid
| Pitfall | Why It Fails | Better Approach |
|---|---|---|
| Per-user candidate pools | 50B rows, 1.8 TB indexes — impossible to maintain | Segment pools (10K segments × 5K candidates) |
| Eager profile hydration | Loading 1,000 profiles to show 20 wastes 50× bandwidth | Lazy hydration: IDs → filter → rank → hydrate top 20 |
| Shard by pair for Directed Model | Scatter-gather on every feed request | Shard by swiper, accept cross-shard match checks |
| SERIALIZABLE isolation for races | 30-50% throughput loss, retry storms | Background reconciliation + optimistic inline check |
| Synchronous match checks at scale | Hot swipees block swipers' requests | Async via Kafka with batching and back-off |
| Single-region deployment | 200ms+ latency for half your users | Multi-region with home region writes + async cross-region |