chatapp
Introduction
"Design WhatsApp" or "Design a Chat App" is a staple system design interview question because it touches on almost every pillar of distributed systems: real-time communication (WebSocket connections), guaranteed delivery (at-least-once with deduplication), offline message handling (inbox queue), end-to-end encryption, and massive scale (WhatsApp serves 2 billion users with only ~50 engineers).
The surface problem — "let two people send text messages to each other" — is deceptively simple. But at interview depth, the design forces nuanced decisions about:
- Connection management: Maintaining millions of persistent WebSocket connections across a fleet of stateful chat servers. How does the system route a message to the right server that holds the recipient's connection?
- Message delivery guarantees: How do you ensure a message is delivered exactly once — not lost, not duplicated — even when the recipient is offline, the server crashes mid-delivery, or the network drops?
- Ordering: Messages within a conversation must appear in the correct order, even when sender and receiver are on different servers in different time zones.
- Storage model: Unlike Twitter or Instagram, a chat app can adopt an "ephemeral" model where messages are deleted from the server after delivery (WhatsApp's default). This fundamentally changes the storage architecture.
- Group chat fan-out: A message in a 256-member WhatsApp group triggers 255 deliveries. A Slack channel with 10,000 members is a different beast entirely.
- Presence (online/offline status): Tracking when 100M users go online/offline in real time without overwhelming the system with status updates.
In this editorial we design a chat app like WhatsApp from first principles — connection management, the message delivery pipeline, offline inbox, group chat, presence, and end-to-end encryption. Depth is stratified by seniority level.
Functional Requirements
Core (must-have for MVP)
- Send & Receive — Authenticated users can send a text message (up to 1,000 characters) to another user. Messages are delivered in real time when the recipient is online.
- Offline delivery — When the recipient comes online, they receive all messages that were addressed to them while offline. No messages are lost.
- Delivery acknowledgment — The system confirms to the sender that the message was delivered to the recipient. Users see delivery status indicators (sent ✓, delivered ✓✓).
- No duplicates — Each message is delivered exactly once. Retries and network failures must not cause duplicate messages to appear.
- Chat history (optional) — By default, messages are stored on the user's device and deleted from the server after delivery (like WhatsApp). Users can optionally enable server-side history storage for up to 90 days.
Extended (out of scope but worth mentioning)
- Group chat (we cover this in Deep Dives).
- Media messages (images, videos, voice notes).
- End-to-end encryption (we discuss the architecture).
- Read receipts ("seen" indicators).
- Typing indicators.
- Online/offline presence (covered in Deep Dives).
- Voice and video calling.
Non-Functional Requirements
| Requirement | Target | Reasoning |
|---|---|---|
| Scale | 100M daily active users (DAU) | WhatsApp-scale platform |
| Messages per second | ~23K writes/sec avg, ~230K peak | 100M × 20 msgs/day ÷ 86,400 |
| Concurrent connections | ~10M WebSocket connections | ~10% of DAU online simultaneously |
| Delivery latency | < 200ms for online recipients | Real-time feel required |
| Delivery guarantee | Exactly-once semantics (at-least-once + idempotent dedup) | No lost or duplicate messages |
| Availability | 99.99% | Chat is a primary communication tool |
| Consistency | Eventual (within seconds); strong for message ordering within a conversation | Messages must appear in order |
| Data retention | Undelivered: 1 year; optional history: up to 90 days | Per-design requirement |
| Durability | No message loss once server acknowledges receipt | Users trust "✓" means stored |
A critical insight: a chat app is a real-time, bidirectional system — fundamentally different from a request-response web app. The server must push messages to clients without them asking. This requires persistent WebSocket connections, which makes the chat servers stateful — each server holds the connections for a specific set of users. This statefulness drives many design decisions.
Resource Estimation
Assumptions:
- 100M daily active users
- 20 messages per user per day → 2 billion messages/day
- Average message size with metadata: ~200 bytes
- 10% of users online simultaneously → 10M concurrent connections
- 1 server handles ~1M WebSocket connections (WhatsApp's 2012 benchmark)
- Average storage duration: 4 months (considering immediate delivery + optional history)
Traffic Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily messages | 100M × 20 | 2 billion/day |
| Write QPS (avg) | 2B ÷ 86,400 | ~23,000/sec |
| Write QPS (peak, 10×) | 23K × 10 | ~230,000/sec |
| Concurrent WebSocket connections | 100M × 10% | ~10 million |
| Chat server fleet | 10M ÷ 1M/server | ~10 servers |
Storage Estimation
| Metric | Calculation | Result |
|---|---|---|
| Daily message storage | 2B × 200 bytes | ~400 GB/day |
| 4-month average retention | 400 GB × 120 days | ~50 TB |
| Undelivered inbox cache | Assume 5% of messages undelivered at any time | ~20 GB in Redis |
Bandwidth Estimation
| Metric | Calculation | Result |
|---|---|---|
| Write ingress | 230K/sec × 200 bytes | ~46 MB/sec (368 Mbps) |
| Read egress (delivery) | ~same as write (1:1 model) | ~46 MB/sec |
The surprising number: only 10 chat servers to hold all connections. WhatsApp famously served 900M users with ~50 servers thanks to Erlang/OTP's lightweight process model. The bottleneck isn't CPU or memory — it's network I/O and message routing between servers.
API Design
Unlike REST APIs, chat messages are sent over a persistent WebSocket connection. The connection is bidirectional — both client and server can send messages at any time without a request/response cycle.
The protocol consists of 5 message types that form the complete delivery lifecycle:
1. Client → Server: Send Message
{
"action": "send_message",
"receiver_id": "usr-b7e3f291",
"content": "Hey, are you free for lunch?",
"message_id_by_client": 42,
"timestamp": 1710684600000
}The message_id_by_client is a temporary auto-incremented ID generated client-side. It will be replaced by a globally unique server-generated ID.
2. Server → Client A: Acknowledgment (✓)
{
"action": "message_received",
"message_id": "msg-8f2a4c91-e7b3",
"message_id_by_client": 42,
"timestamp": 1710684600123
}The server generates a globally unique message_id and returns it with the client's temporary ID so the client can match acknowledgments to sent messages.
3. Server → Client B: Deliver Message
{
"action": "incoming_message",
"message_id": "msg-8f2a4c91-e7b3",
"sender_id": "usr-a4d12e85",
"content": "Hey, are you free for lunch?",
"timestamp": 1710684600123
}4. Client B → Server: Delivery Confirmation
{
"action": "message_delivered",
"message_id": "msg-8f2a4c91-e7b3",
"timestamp": 1710684600456
}5. Server → Client A: Delivery Notification (✓✓)
{
"action": "message_delivered",
"message_id": "msg-8f2a4c91-e7b3",
"timestamp": 1710684600456
}This 5-step handshake ensures the sender knows the message was delivered. If step 4 (delivery confirmation) doesn't arrive within 10 seconds, the server marks the message as undelivered and stores it in the offline inbox.
PUT /api/user/settings— Update history storage policy (0 = device-only, 90 = 90-day server retention).GET /api/history/{participant_id}?last_timestamp={ts}— Retrieve paginated chat history (if server-side storage is enabled).GET /api/user/{user_id}/status— Get user's online/offline presence.
The client needs to know which message the server is acknowledging. Without the temporary ID, if the client sends 3 messages rapidly and gets 3 acknowledgments, it can't match them.
The flow: Client assigns ID 42 → Server receives → Server generates msg-8f2a4c91-e7b3 → Server returns both IDs → Client replaces 42 with the server ID in its local store.
This also prevents duplicate messages: if the client retries (network timeout), the server can detect the retry by the (sender_id, message_id_by_client) pair and return the existing server-generated ID instead of creating a duplicate.
High-Level Design
We build the architecture incrementally, starting from the simplest possible design and evolving it as we discover problems that need solving. Each step addresses a specific non-functional requirement from our NFR list.
Step 1: Basic Design — Single Chat Server
Starting point: The simplest possible chat system. A single server holds all WebSocket connections. When Client A sends a message, the server looks up Client B's connection in memory and forwards the message directly.
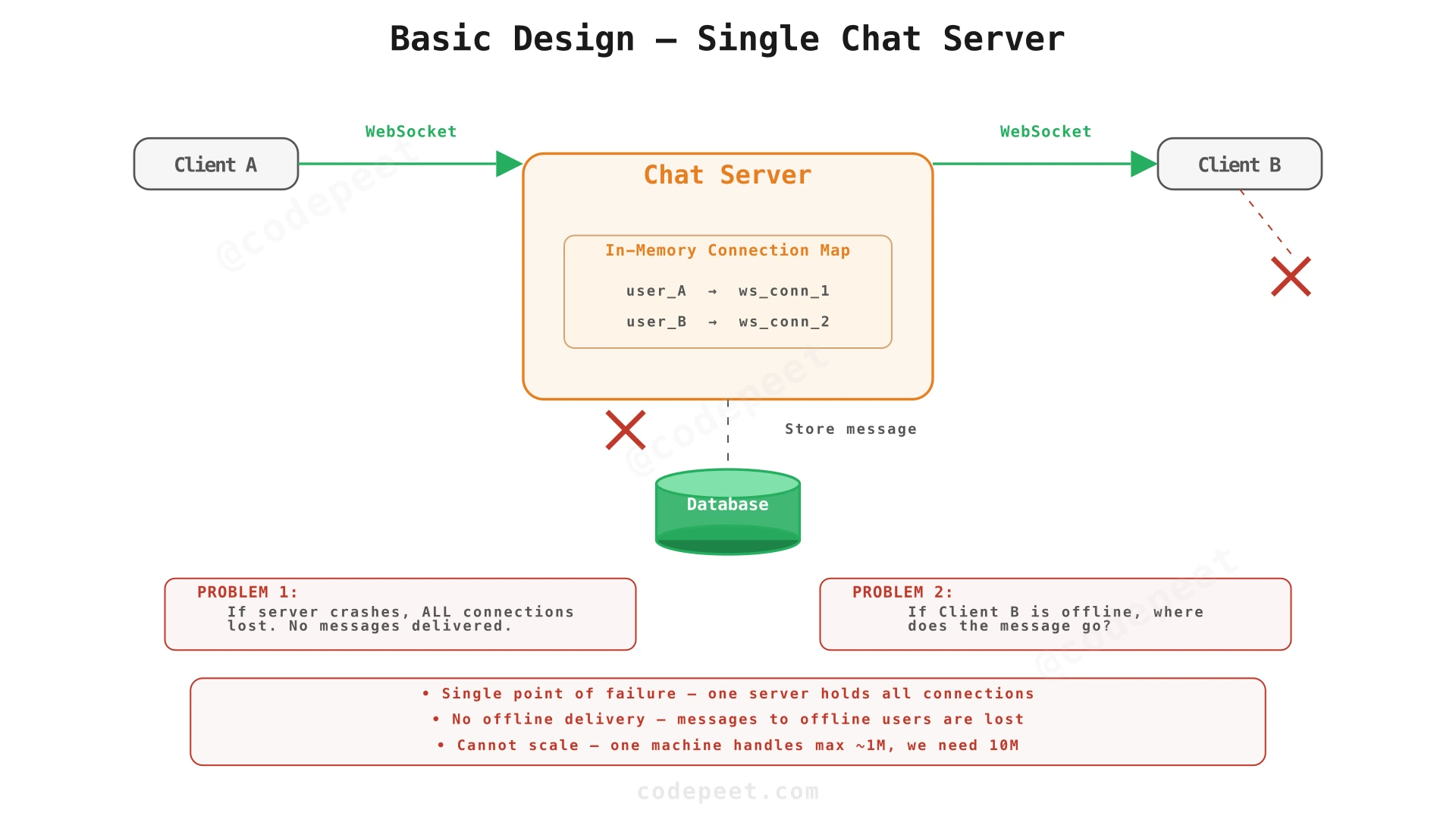
How it works:
- Both clients establish WebSocket connections to the Chat Server.
- Client A sends
send_messagewith receiver's user ID. - The server looks up Client B's WebSocket in its in-memory connection map.
- If found: forward the message directly. If not found: write to database and hope Client B fetches it later.
Three critical flaws:
| Problem | NFR Violated | Impact |
|---|---|---|
| Single point of failure | 99.99% availability | Server crash = all users disconnected, all in-flight messages lost |
| No offline delivery | Guaranteed delivery | Messages to offline users are silently dropped |
| Cannot scale past one machine | 10M concurrent connections | One server handles ~1M WebSockets max; we need 10M |
We need to solve all three. Let's start with the most fundamental: making the system real-time and multi-server.
Step 2: Multi-Server Routing with Connection Registry
Problem being solved: A single server can't hold 10M connections. We need a fleet of ~10 Chat Servers (each handling ~1M connections). But now: when Client A sends a message to Client B, how does the system know which Chat Server holds Client B's connection?
Solution: Add a Connection Registry — a shared Redis store that maps every connected user to their Chat Server.
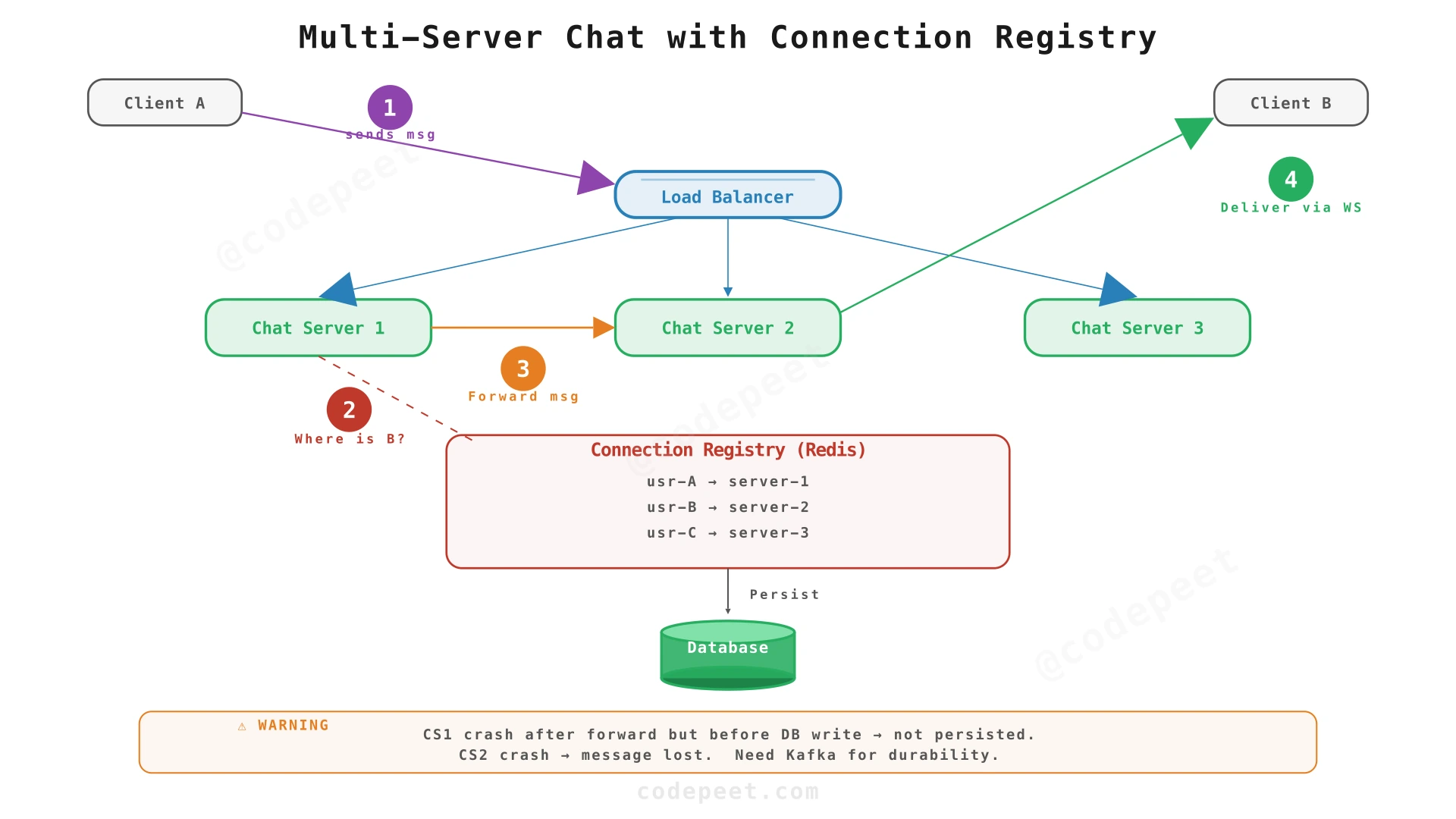
Message flow:
- Client A sends
send_messageover WebSocket to Chat Server 1. - Chat Server 1 queries the Connection Registry (Redis):
HGET connections:{receiver_id} server_id→ returnschat-server-2. - Chat Server 1 forwards the message directly to Chat Server 2 via internal RPC.
- Chat Server 2 delivers
incoming_messageto Client B over WebSocket. - Chat Server 1 writes the message to the Database.
The Connection Registry is a Redis hash map:
Key: connections:{user_id}
Value: {server_id: "chat-server-2", connected_at: 1710684600000}
- On connect: Chat Server writes
HSET connections:{user_id} server_id chat-server-2. - On disconnect: Chat Server deletes the entry.
- TTL-based cleanup: Each entry has a 60-second TTL, refreshed by periodic heartbeats. If a Chat Server crashes, stale entries expire automatically.
What we've solved:
- ✅ Scale: 10 servers × 1M connections each = 10M concurrent connections.
- ✅ Routing: Connection Registry lets any server find any user's connection.
What's still broken:
- ❌ Durability: If Chat Server 1 crashes after forwarding to Server 2 but before writing to DB → the message was delivered but not persisted (no history, no audit trail). If Server 2 crashes before delivering → message is lost.
- ❌ Offline delivery: If Client B isn't connected, we write to DB... but how does Client B know to check? When they come online, there's no mechanism to deliver stored messages.
- ❌ Tight coupling: The sending Chat Server must know about the receiving server, the database, and every other downstream concern.
The Load Balancer distributes connections (which user connects to which server), but it doesn't know which user is on which server after the connection is established. The Connection Registry fills this gap — it's a real-time index of user → server mappings.
Could we use consistent hashing in the LB to ensure User B always connects to Server 2? Yes, but this creates tight coupling between the user's identity and their server. When Server 2 goes down for maintenance, all its users must reconnect — and consistent hashing redistributes them, requiring a re-registration storm.
The Connection Registry is more flexible: any user can be on any server, and the registry tracks the current mapping dynamically.
Step 3: Message Queue for Durability and Decoupling
Problem being solved: In the direct server-to-server model, a crash at any point can lose the message. The sender gets no reliable acknowledgment. We need the message to be durably stored before we tell the sender "your message is safe".
Solution: Insert Kafka (message queue) between the Chat Server and the delivery pipeline. The Chat Server's only job is: receive the message → enqueue to Kafka → ACK to sender. A separate MQ Consumer handles delivery asynchronously.
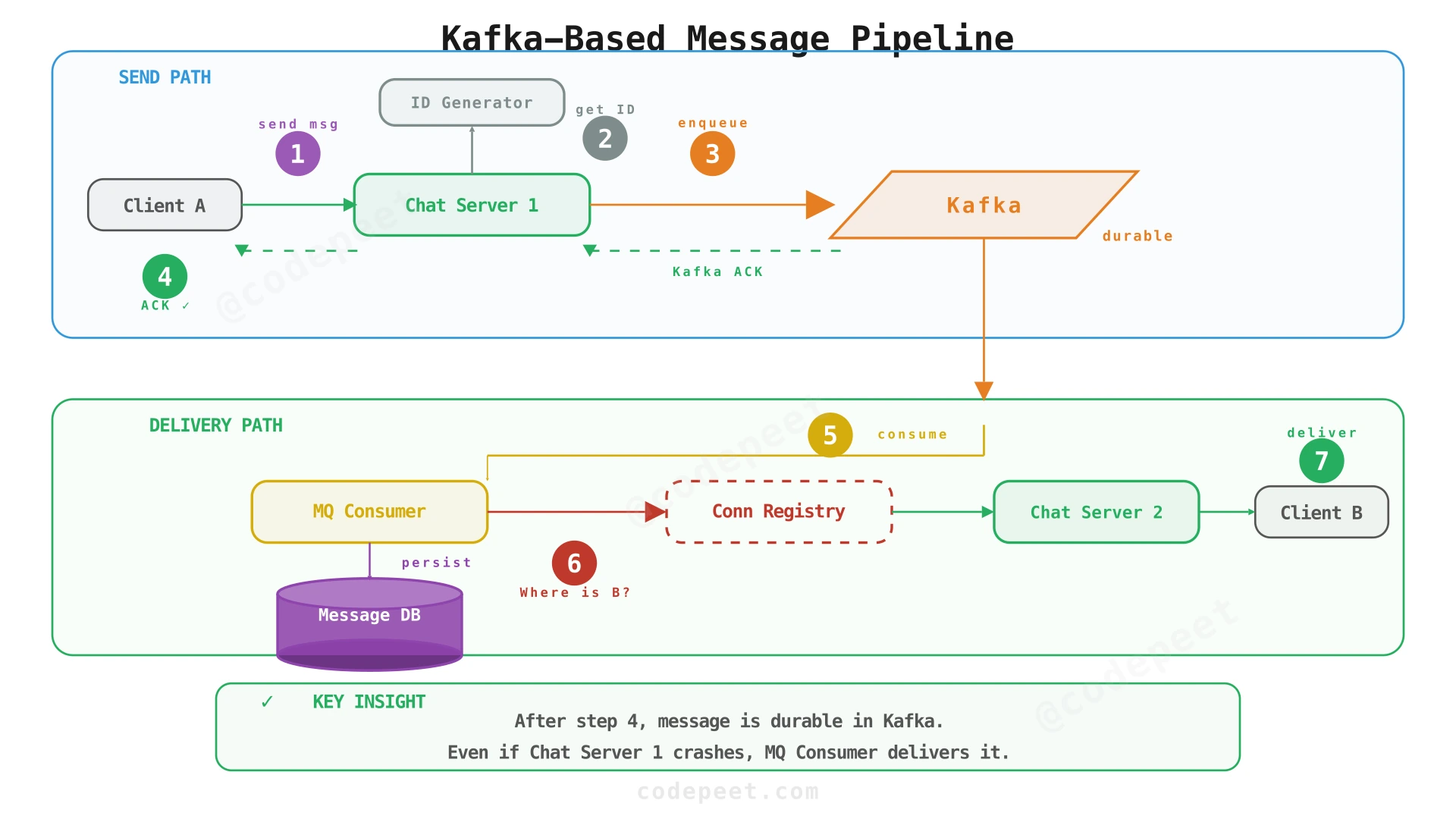
Send path (4 steps, all synchronous to the sender):
- Client A sends
send_messageover the WebSocket to Chat Server 1. - Chat Server 1 requests a unique message ID from the ID Generator (Snowflake).
- Chat Server 1 writes the message into Kafka (Message Queue).
- Once Kafka acknowledges, Chat Server 1 sends
message_received(✓) back to Client A. At this point, the message is durably stored in Kafka — it will not be lost even if every Chat Server crashes simultaneously.
Delivery path (asynchronous, handled by the MQ Consumer):
5. The MQ Consumer reads the message from Kafka.
6. MQ Consumer queries the Connection Registry to find Client B's Chat Server.
7. Message is routed to Chat Server 2 → delivered to Client B → Client B confirms → stored in Message DB → sender notified (✓✓).
Why Kafka changes everything:
| Property | Without Kafka (Step 2) | With Kafka (Step 3) |
|---|---|---|
| Durability | Message lost if any server crashes | Message survives in Kafka until consumed |
| Sender ACK meaning | "I forwarded it" (might be lost) | "It's durably stored" (guaranteed) |
| Coupling | Chat Server handles routing, delivery, persistence | Chat Server only enqueues; consumer handles rest |
| Backpressure | Traffic spike overwhelms servers | Kafka absorbs burst; consumers drain at own pace |
| Multiple consumers | N/A | Delivery, analytics, spam detection can all consume the same event |
What we've solved:
- ✅ Durability: The ✓ checkmark now means "your message is safe" — not just "I received it".
- ✅ Decoupling: Chat Server doesn't know about the delivery pipeline, DB, or inbox.
What's still broken:
- ❌ Offline delivery: If Client B is offline, the MQ Consumer can write to the DB... but when Client B comes online, how does it know there are messages waiting?
Kafka has two properties that make it ideal for chat:
- Ordered per partition: Messages within a Kafka partition are strictly ordered. By using
conversation_idas the partition key, all messages in a conversation stay in order. - Replay capability: If a consumer crashes and restarts, it can replay from its last committed offset. No messages are lost during consumer downtime.
- High throughput: Kafka handles millions of messages per second — matching our 230K peak QPS with massive headroom.
RabbitMQ is also viable (better for complex routing) but lacks native replay. SQS is simplest operationally (fully managed) but doesn't guarantee ordering.
Step 4: Offline Inbox for Guaranteed Delivery
Problem being solved: When the MQ Consumer tries to deliver a message and Client B is offline (no entry in the Connection Registry), or if the delivery confirmation (message_delivered) doesn't arrive within 10 seconds, the message has nowhere to go.
Solution: Add an Inbox Cache — a per-user Redis Sorted Set (ZSET) that stores undelivered messages, sorted by timestamp. When Client B comes online, the system drains the inbox before switching to real-time delivery.
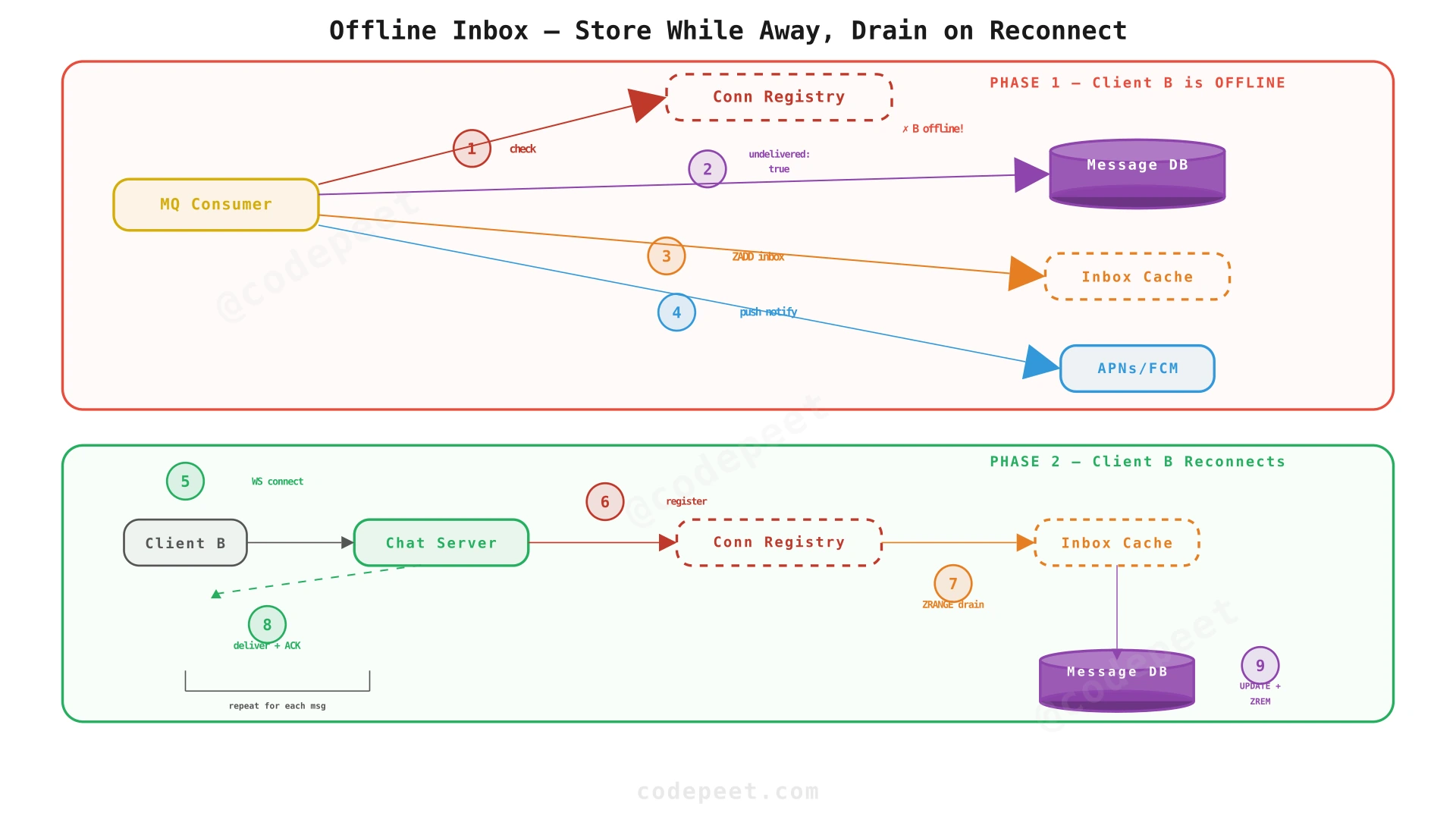
Offline delivery flow (message arrives while Client B is offline):
- MQ Consumer reads message from Kafka.
- Queries Connection Registry → Client B has no active connection.
- Writes message to Message DB with
undelivered: true. - Pushes message to Client B's Inbox Cache:
ZADD inbox:{user_B} 1710684600000 "{msg_json}". - Sends push notification via APNs/FCM to wake Client B's device.
Reconnection flow (Client B comes online):
- Client B connects and establishes a WebSocket with Chat Server.
- Chat Server registers the connection in the Connection Registry.
- Chat Server queries the Inbox Cache:
ZRANGE inbox:{user_B} 0 -1(oldest first). - For each undelivered message, Chat Server sends
incoming_messageto Client B. - As Client B confirms each message (
message_delivered), the server:- Updates the Message DB:
undelivered→false. - Removes the message from the Inbox Cache:
ZREM inbox:{user_B} message.
- Updates the Message DB:
- Once the inbox is drained, Client B is in sync and receives new messages in real time.
We use Redis Sorted Sets (ZSET) for the inbox because:
- Score = timestamp: Messages are automatically sorted chronologically.
- ZPOPMIN: Retrieves and removes the oldest message (earliest timestamp) in O(log N).
- ZRANGEBYSCORE: Fetch messages within a time range.
- No duplicates: ZSET members are unique — if the same message is pushed twice (retry scenario), the second push is a no-op.
ZADD inbox:{user_id} 1710684600000 "{msg_json_1}"
ZADD inbox:{user_id} 1710684601000 "{msg_json_2}"
ZPOPMIN inbox:{user_id} // returns msg_json_1 (oldest first)
What we've solved:
- ✅ Offline delivery: No message is lost. Inbox stores everything until Client B confirms receipt.
- ✅ Ordering: ZSET sorts by timestamp. Messages drain oldest-first.
What's still broken:
- ❌ Duplicates: If Client B's
message_deliveredACK is lost, the server retries delivery — potentially showing the same message twice. We need exactly-once semantics.
Step 5: Complete Architecture — Exactly-Once Delivery
The last piece: deduplication for exactly-once delivery. We combine at-least-once delivery (guaranteed by Kafka + inbox + retries) with idempotency checks to suppress duplicates.
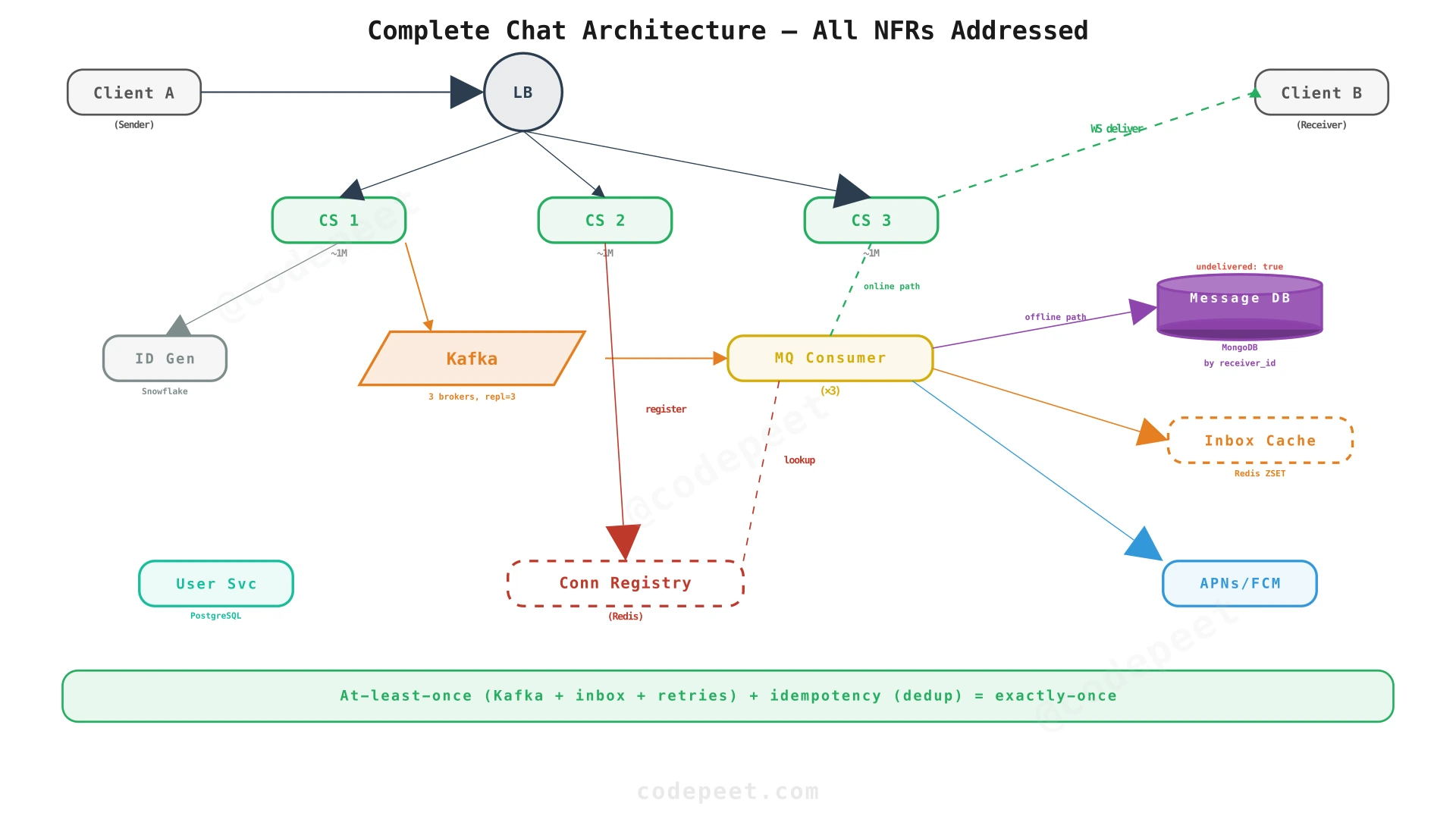
Exactly-Once Delivery: Three Dedup Layers
Duplicate messages can occur when:
- Client retries a
send_messagethat the server already processed (network timeout). - The MQ Consumer delivers a message, but the delivery ACK is lost, so it retries.
- The inbox drain sends a message to Client B, but the ACK is lost.
Prevention mechanisms:
| Layer | Mechanism | How It Works |
|---|---|---|
| Send-side | Server idempotency key | (sender_id, message_id_by_client) → if pair exists in DB, return existing message_id |
| Consumer-side | Processed ID tracking | MQ Consumer checks DB before delivering; skips if already delivered |
| Client-side | Received ID set | Client B maintains a set of seen message_ids; silently discards duplicates |
NFR Scorecard — All Requirements Met
| NFR | Target | How It's Achieved |
|---|---|---|
| 10M concurrent connections | 10 servers × 1M each | Chat Server fleet behind Load Balancer |
| 230K peak msg/sec | Kafka absorbs burst | MQ Consumers process at sustainable rate |
| < 200ms delivery latency | Direct WebSocket push | No polling; server pushes immediately on receipt |
| 99.99% availability | No single point of failure | Multiple Chat Servers, Kafka replicas, Redis cluster |
| Exactly-once delivery | At-least-once + dedup | Kafka guarantees no loss; 3-layer dedup prevents duplicates |
| Offline delivery | Inbox Cache + reconnect drain | Redis ZSET stores messages; drained on WebSocket reconnect |
| Message ordering | Kafka partition key | conversation_id as partition key → per-conversation ordering |
| Durability | Kafka + MongoDB replication | replication.factor=3; w: majority for DB writes |
| Component | Responsibility | Scaling Strategy |
|---|---|---|
| Chat Servers (~10) | Maintain WebSocket connections; send/receive | Horizontal: add servers behind LB |
| Connection Registry (Redis) | Map user_id → chat_server_id | Redis Cluster with sharding |
| Kafka (3 brokers) | Durable message queue | Add partitions for throughput |
| MQ Consumers (×3) | Process messages; route or store | Horizontal: add consumer instances |
| Inbox Cache (Redis ZSET) | Store undelivered messages per user | Separate Redis Cluster |
| Message DB (MongoDB) | Persistent message storage | Sharded by receiver_id |
| ID Generator (Snowflake) | Globally unique, time-sorted IDs | Multiple instances |
| User Service (PostgreSQL) | User profiles, settings, auth | Read replicas |
Deep Dives
Data Model and Storage Architecture
The storage model for a chat app is unique: most messages are ephemeral — stored on the server only until delivered, then deleted. This is fundamentally different from social media (store forever) or email (store until user deletes).
Database choice: Hybrid SQL + NoSQL
- MongoDB for messages — high write throughput, flexible schema, good for time-series-like queries (messages by conversation, ordered by timestamp).
- PostgreSQL for user profiles, settings, and relationships — relational queries, ACID transactions for user management.
- Redis for caches — connection registry, inbox ZSET, presence status.
// messages collection (MongoDB)
{
_id: "msg-8f2a4c91-e7b3", // server-generated unique ID
sender_id: "usr-a4d12e85",
receiver_id: "usr-b7e3f291", // null for group messages
group_id: null, // null for 1:1 messages
content: "Hey, are you free for lunch?",
undelivered: true, // flipped to false on delivery
timestamp: ISODate("2025-03-17T14:30:00Z"),
expires_at: ISODate("2026-03-17T14:30:00Z") // TTL: 1 year for undelivered
}
// Indexes:
// Inbox query: { receiver_id: 1, undelivered: 1, timestamp: 1 }
// Conversation history: { sender_id: 1, receiver_id: 1, timestamp: -1 }
// TTL cleanup: { expires_at: 1 } with expireAfterSeconds: 0| Partition key | Pros | Cons |
|---|---|---|
| receiver_id | All undelivered messages for a user on one shard — fast inbox query | Skewed if one user has millions of undelivered messages |
| message_id | Even distribution | Inbox query requires scatter-gather across all shards |
| timestamp | Good for time-range queries | Hot shard for current time bucket |
Recommendation: receiver_id — the inbox query ("get all undelivered messages for this user") is the most critical access pattern and must be a single-shard operation.
For conversation history queries ("get messages between user A and user B"), we can create a secondary index on (conversation_id, timestamp) where conversation_id is a deterministic hash of the two user IDs: conversation_id = hash(min(sender, receiver) + max(sender, receiver)).
The chat app has a unique retention model:
- Messages delivered and no server-side history: Delete from server immediately after Client B confirms
message_delivered. The message exists only on the clients' devices. - Messages delivered with 90-day history enabled: Keep in MongoDB for 90 days. TTL index on
expires_athandles automatic cleanup. - Undelivered messages: Keep for up to 1 year. If the user doesn't come online within 1 year, the message is permanently lost (acceptable — the conversation is effectively dead).
MongoDB TTL indexes handle all of this automatically. A background thread runs every 60 seconds, checking the expires_at field and deleting expired documents.
MongoDB replica sets (1 primary + 2 secondaries):
- Writes go to the primary with
w: majority— the write is acknowledged only after a majority of nodes confirm it. This ensures no data loss even if the primary crashes. - Reads for inbox queries: read from primary (for consistency of the
undeliveredflag). - Reads for history:
secondaryPreferred— eventual consistency is fine for browsing old messages.
For disaster recovery, place one secondary in a different availability zone.
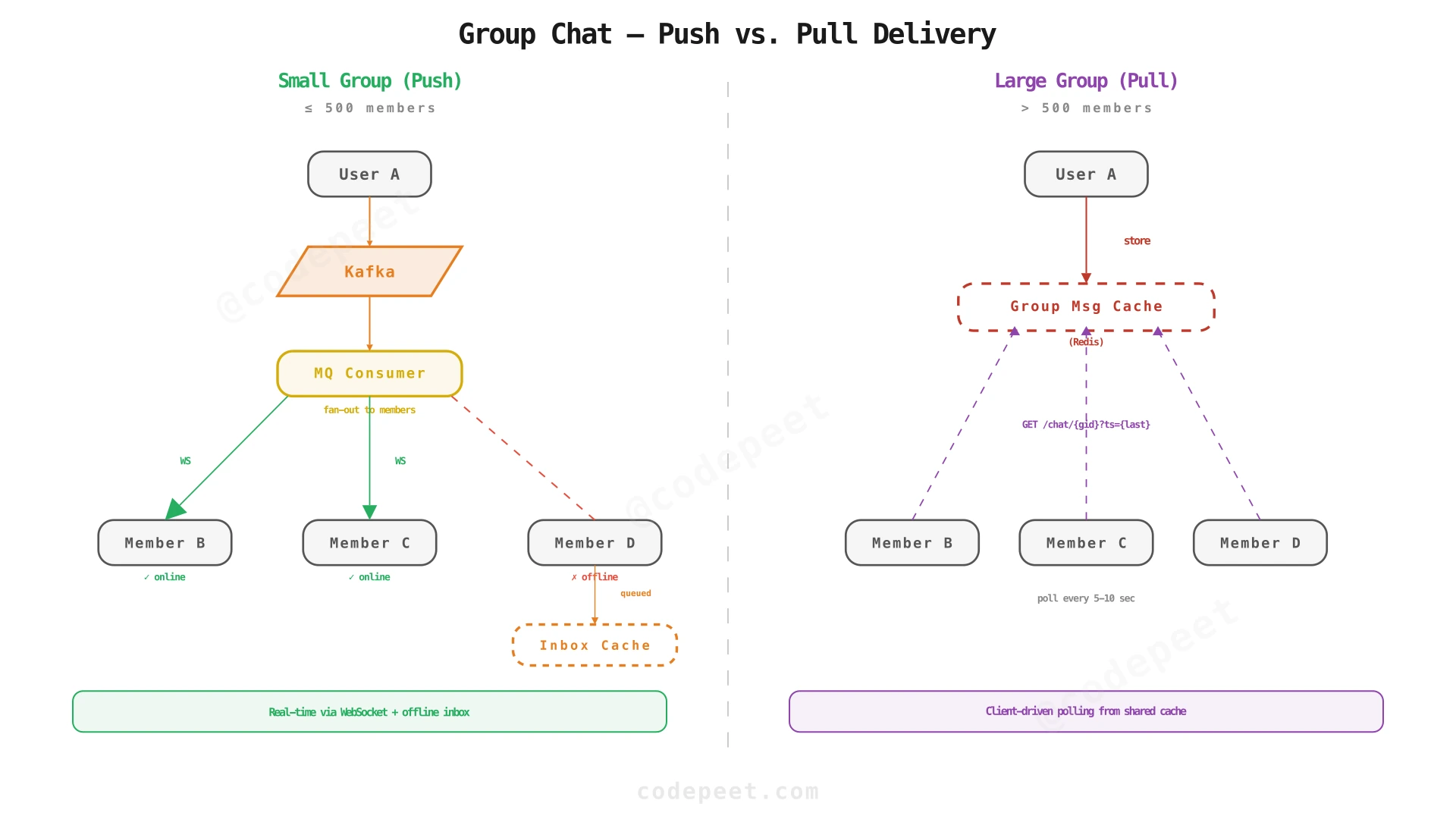
Group Chat Architecture
Group chat multiplies the delivery problem: a single message must be delivered to every member of the group. The approach depends on group size.
Small groups (≤ 500 members) — push model:
When a user sends a message to a group:
- The message is published to Kafka.
- The MQ Consumer fetches the group member list from the database.
- For each member, it follows the same delivery pipeline as 1:1 messages: check connection registry → deliver via WebSocket if online → store in inbox if offline.
- The message is stored once in the Message DB (with
group_idinstead ofreceiver_id).
This is essentially fan-out-on-write for groups.
Large groups (> 500 members) — pull model:
For large groups (Slack channels, Discord servers with 10K+ members), pushing to every member is too expensive. Instead:
- The message is stored in the Message DB under the group.
- Cached in Redis:
ZADD group_messages:{group_id} timestamp message_json. - Clients poll periodically:
GET /api/chat/{group_id}?timestamp={last_seen}. - The server returns new messages since
last_seenfrom the Redis cache.
The messages collection is extended to support groups:
// Group message
{
_id: "msg-9c3b5d72",
sender_id: "usr-a4d12e85",
receiver_id: null, // null for group messages
group_id: "grp-f2e8a391", // present for group messages
content: "Who's up for lunch?",
timestamp: ISODate("2025-03-17T12:00:00Z")
}
Groups collection:
{
_id: "grp-f2e8a391",
group_name: "Lunch Crew",
members: ["usr-a4d12e85", "usr-b7e3f291", "usr-c8d93f12"],
created_at: ISODate("2025-01-01T00:00:00Z")
}
Index for group message retrieval:
{ group_id: 1, timestamp: -1 }
In a 1:1 chat, undelivered is a boolean — the message is either delivered or not. In a group of 256 members, the message might be delivered to 200 and pending for 56.
Approach: Don't track per-member delivery on the message document. Instead:
- Each member has their own inbox (Redis ZSET). If a group message is undelivered to member X, it's in member X's inbox.
- The
undeliveredflag on the message document means "at least one member hasn't received it". The flag is cleared when the last member confirms delivery (or the TTL expires). - For delivery receipts visible to the sender ("delivered to 200/256"), use a counter:
INCR delivered_count:{message_id}. The sender's client can poll for the count.
Online/Offline Presence System
Users expect to see whether their contacts are online, offline, or "last seen 5 minutes ago". At 100M DAU with 10M concurrent connections, the presence system generates a massive volume of status change events.
Heartbeat-based presence:
Each connected client sends a heartbeat to the Chat Server every 30 seconds. The Chat Server updates the user's presence in Redis:
SET presence:{user_id} {timestamp} EX 60
The 60-second TTL acts as a natural "offline" detector. If the client stops sending heartbeats (app backgrounded, network lost), the key expires and the user is considered offline.
Querying presence:
When Client A opens a chat with Client B, the app queries: GET presence:{user_b_id}.
- If the key exists: user is online (or was active within 60 seconds). Display "Online" or "Last seen {timestamp}".
- If the key doesn't exist: user is offline.
When a user goes online/offline, should we push a status update to all their contacts?
For a user with 500 contacts: Going online triggers 500 WebSocket push messages. At 10M concurrent users × 1 online/offline event per session average = 10M events → 5 billion fan-out messages per day. This is extremely expensive.
WhatsApp's approach: lazy presence (pull-based).
- Don't push presence updates proactively.
- When User A opens a chat with User B, the client queries User B's presence.
- The contact list screen shows cached presence data, refreshed periodically (every 60 seconds).
- Only the currently viewed chat screen shows real-time presence.
This reduces presence queries from billions of pushes to millions of pulls — a 1000× reduction.
WebSocket connections on mobile are fragile — they break when the user switches networks (WiFi → cellular), goes through a tunnel, or when the OS kills the background app.
Reconnection strategy:
- Client detects disconnection → exponential backoff reconnect (1s, 2s, 4s, 8s, max 30s).
- On reconnect: re-establish WebSocket → re-register in Connection Registry → drain inbox.
- Sticky sessions: The Load Balancer uses consistent hashing to route the same user to the same Chat Server when possible. This avoids the overhead of re-registering and transferring state.
- Graceful handoff: If the old Chat Server is still alive, the Connection Registry update will cause the old server to close the stale connection.
End-to-End Encryption and Security
WhatsApp is famous for end-to-end encryption (E2EE): the server never sees the plaintext content of messages. This has significant architectural implications.
How E2EE works (Signal Protocol):
- Each user generates a key pair (public + private) on their device at registration.
- The public key is uploaded to the server. The private key never leaves the device.
- When Alice wants to message Bob: Alice fetches Bob's public key from the server.
- Alice encrypts the message with Bob's public key.
- The encrypted message traverses the server (stored in MongoDB, queued in Kafka, etc.) — but the server cannot decrypt it.
- Bob receives the encrypted message and decrypts it with his private key.
E2EE changes several design assumptions:
- No server-side search: The server can't index or search message content (it's encrypted). Search must happen on-device.
- No server-side spam detection on content: Spam filtering must use metadata (frequency, sender reputation) rather than content analysis.
- Group chat key management: In a group, a shared group key is generated. When a member is added/removed, the group key must be rotated and redistributed to all members — this is the most complex part of E2EE.
- Multi-device sync: Each device has its own key pair. A message for Bob must be encrypted separately for each of Bob's devices (phone, tablet, desktop). WhatsApp calls this "multi-device" and it required a complete redesign of their encryption protocol.
- Chat history: Server-stored history (90-day setting) only works if the user provides a password-derived key for server-side encryption. Without it, the server stores only ciphertext that only the user's device can decrypt.
Preventing spam and abuse in a real-time chat system:
- WebSocket connection rate limit: Use a WAF (e.g., CloudFlare) to limit connection creation frequency per IP — prevents malicious clients from repeatedly creating/dropping connections.
- Message rate limit: Within an established WebSocket, limit messages per user: e.g., max 60 messages per minute. Implemented in the Chat Server using a Redis counter with TTL.
- Global throttle: If total message QPS exceeds 5× steady-state, reject new messages with a backoff signal to clients.
- Spam detection (metadata-based): Since E2EE prevents content analysis, detect spam via patterns: rapid-fire messages to many users, messages to users who never respond, newly created accounts with high message volume.
Staff-Level Discussion Topics
These open-ended topics test architectural judgment at the staff+ level.
Modern WhatsApp supports linked devices — phone, tablet, desktop, web. A message sent to User B must be delivered to all of B's devices simultaneously. If B reads on desktop, the phone should also show the message as read.
This introduces per-device connection tracking, per-device encryption, and cross-device sync of message state (delivered, read).
WhatsApp famously handled 900M users with ~50 engineers and ~500 servers using Erlang's BEAM VM. Each server handled 2M+ WebSocket connections. This is dramatically fewer resources than comparable systems.
The key: Erlang's lightweight process model (millions of processes per VM), built-in fault tolerance (let it crash philosophy), hot code reloading (zero-downtime deploys), and native distribution protocol (inter-node message passing).
In a distributed chat system with multiple Chat Servers and Kafka partitions, how do you guarantee that messages within a conversation appear in the correct order?
Scenarios where ordering breaks:
- Alice sends msg1, then msg2. They're processed by different Kafka partitions. msg2 arrives at Bob's server before msg1.
- Bob sends a reply to msg1, but Alice's client hasn't received msg1 yet.
Level Expectations
| Area | |||
|---|---|---|---|
| Requirements | Lists FRs (send, receive, offline delivery) | Derives 23K QPS, 10M connections; identifies exactly-once delivery as key NFR | Discusses ephemeral storage model, E2EE implications on design |
| Protocol | "Use WebSocket" | Designs full 5-step message handshake; explains client-generated temp IDs and dedup | Discusses protocol evolution (HTTP/2 streams, QUIC), mobile connection flakiness |
| Architecture | Client → Chat Server → DB | Chat Server → Kafka → MQ Consumer → Connection Registry → delivery; offline inbox pipeline | Multi-region deployment; Chat Server fleet sizing (10M connections ÷ 1M/server) |
| Storage | "Store messages in a database" | MongoDB for messages, Redis for inbox ZSET; explains partition by receiver_id | Conversation-level indexes; tiered retention (ephemeral vs 90-day vs 1-year) |
| Delivery | "Push message to receiver" | Handles online + offline paths; inbox drain on reconnect; delivery confirmation loop | At-least-once + idempotent dedup = exactly-once; Kafka consumer offset management |
| Group chat | "Send to all members" | Push for small groups; pull for large groups; group message data model | Delivery tracking per member; group key rotation for E2EE |
| Presence | "Track online/offline" | Heartbeat + Redis TTL; pull-based presence to avoid fan-out | Connection lifecycle management; sticky sessions; graceful handoff |
Interview Cheatsheet
"A chat app like WhatsApp lets users send real-time text messages with delivery guarantees. 100M DAU, 23K writes/sec, 10M concurrent WebSocket connections across ~10 chat servers. Messages flow: Client → Chat Server → Kafka → MQ Consumer. The consumer checks the Connection Registry to find the recipient's server. If online, deliver via WebSocket. If offline, store in a Redis ZSET inbox and push-notify. On reconnect, drain the inbox. Exactly-once delivery via server-generated IDs and client-side dedup."
- FRs: Send/receive text, offline delivery, delivery confirmation (✓✓), no duplicates, optional 90-day history
- NFRs: 100M DAU, 23K msg/sec (peak 230K), 10M concurrent connections, <200ms delivery latency
- Consistency: Eventual; strong per-conversation ordering
- Retention: Ephemeral by default (delete after delivery); undelivered: 1 year
- Out of scope: Media, voice/video calls, @mentions, reactions
- Chat Servers (~10) — maintain WebSocket connections; receive/send messages
- Kafka — message queue; decouples send from delivery; provides durability
- MQ Consumer — processes messages; routes to recipient's Chat Server or inbox
- Connection Registry (Redis) — maps user_id → chat_server_id for routing
- Inbox Cache (Redis ZSET) — stores undelivered messages, sorted by timestamp
- Message DB (MongoDB) — persistent storage; partitioned by receiver_id
- ID Generator (Snowflake) — globally unique, time-sorted message IDs
- User Service (PostgreSQL) — user profiles, settings, auth
- WebSocket vs long polling: WebSocket for real-time bidirectional; long polling as fallback for restrictive networks
- Ephemeral vs persistent storage: WhatsApp deletes from server after delivery; reduces storage 100×
- Push vs pull for group chat: Push (fan-out) for small groups; pull (polling) for large groups
- Heartbeat presence vs event-based: Heartbeat + TTL avoids the fan-out storm of broadcasting every status change
- At-least-once + dedup = exactly-once: True exactly-once is expensive; practical approach is idempotent delivery
- E2EE implications: Server can't read, search, or spam-filter content; changes retention model
| Metric | Value |
|---|---|
| DAU | 100M |
| Messages per day | 2 billion |
| Write QPS (avg / peak) | 23K / 230K |
| Concurrent connections | ~10M |
| Connections per server | ~1M |
| Chat server fleet | ~10 servers |
| Message size (with metadata) | ~200 bytes |
| Storage (4-month avg retention) | ~50 TB |
| Inbox cache | ~20 GB in Redis |
| Heartbeat interval | 30 seconds |
| Presence TTL | 60 seconds |
- "How do you handle server failure?" — Kafka retains messages. Connection Registry TTL expires stale connections. Client reconnects with exponential backoff. Inbox drains on reconnect.
- "How do you support media messages?" — Upload media to CDN (S3 + CloudFront). Message contains a media_url. File upload is a separate HTTP endpoint. The WebSocket message is just a reference (URL + thumbnail).
- "How do read receipts work?" — When Client B reads a message, it sends a
message_readevent through WebSocket → Kafka → deliver to Client A. Same pipeline as regular messages but lighter (no content, just message_id + timestamp). - "How do you handle typing indicators?" — Ephemeral events sent via WebSocket. NOT stored in Kafka or DB. Sent directly between Chat Servers via the Connection Registry. Fire-and-forget — losing a typing indicator is acceptable.
- "How do you prevent message spam?" — Rate limit: 60 msgs/min per user. Metadata-based detection (rapid sends to many users). Account reputation scoring.
Common Mistakes to Avoid
- ❌ Using HTTP polling instead of WebSockets for real-time chat — polling adds latency and wastes bandwidth
- ❌ Storing messages only in memory — messages are lost if the server crashes before persisting
- ❌ Broadcasting messages to all servers — messages should route only to the server holding the recipient's connection
- ❌ Ignoring offline delivery — users who aren't connected when a message arrives must receive it upon reconnect
- ❌ Not mentioning message ordering — concurrent messages from different senders can arrive out of order without sequencing
- ❌ Treating group chat the same as 1:1 — group fan-out, read receipts, and admin controls add significant complexity