ticketmaster
Introduction
Designing a system like Ticketmaster is deceptively challenging. Selling a ticket sounds simple — a user picks a seat, pays, and receives a confirmation. But Ticketmaster operates at the intersection of three engineering extremes that make it one of the most demanding system design problems:
-
Extreme Traffic Spikes — When Taylor Swift tickets go on sale, traffic can spike 100× over baseline within seconds. Unlike social media feeds where a slow page is annoying, a slow ticketing system means lost revenue and angry customers. The system must absorb millions of concurrent users hitting the same inventory simultaneously.
-
Zero Tolerance for Overselling — If two users buy the same seat, one gets turned away at the venue. This isn't just a bad experience — it's a legal and financial liability. Every seat reservation must be exactly-once: no double bookings, no phantom tickets, no race conditions.
-
Time-Pressured Transactions — Users expect to complete a purchase within seconds. But the flow involves inventory checks, temporary holds, payment processing with external providers, and confirmation — a multi-step distributed transaction with external dependencies and failure modes at every step.
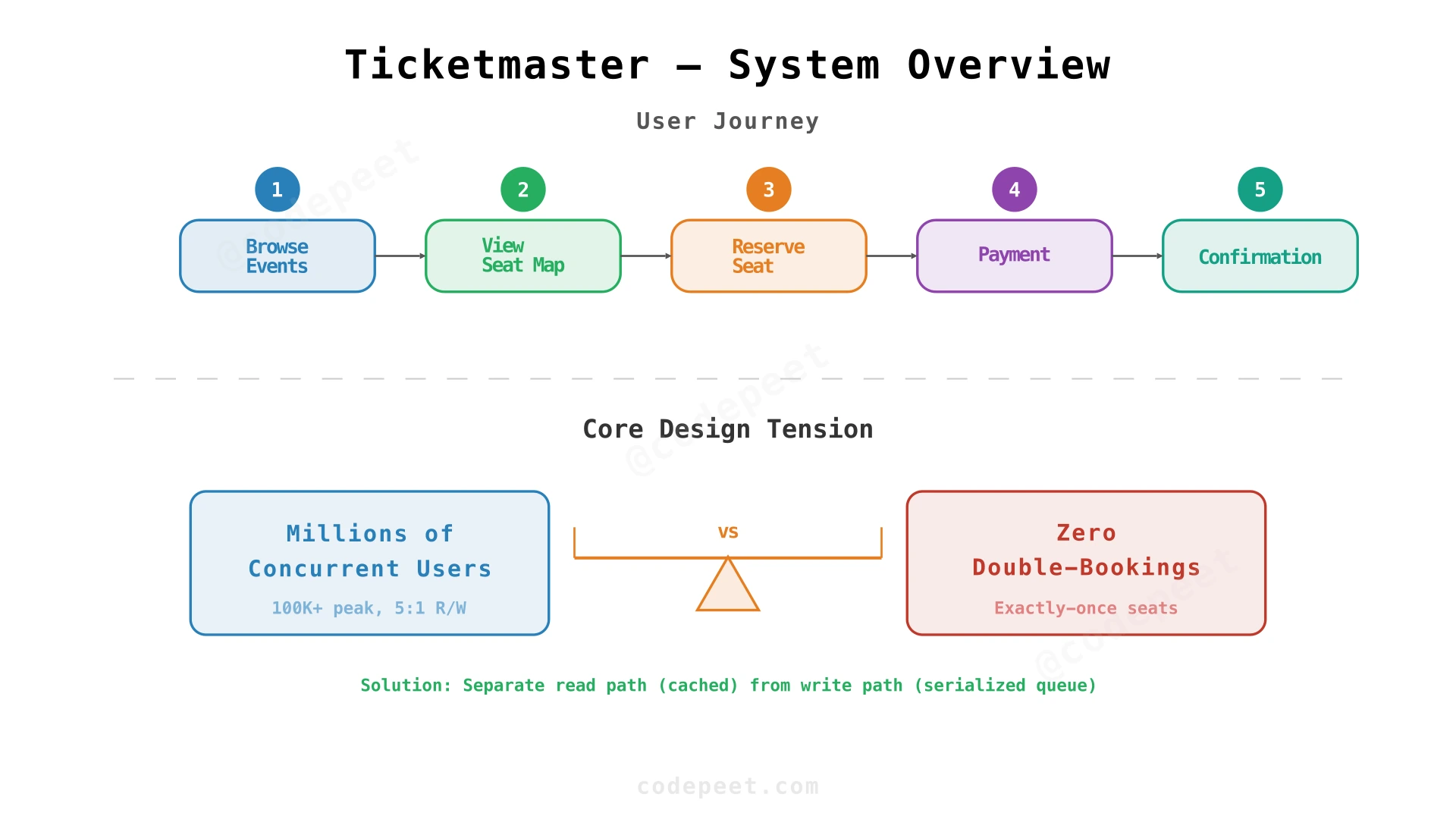
The core tension is between consistency (no overselling) and availability (serving millions of concurrent users). Most distributed systems can relax one or the other. Ticketmaster can't — it needs strong consistency on seat inventory while handling massive, bursty read traffic.
The system manages ~10 million daily active users, with peaks of 100,000 concurrent users during hot on-sale events. Of these, roughly 20,000 are concurrently attempting to book, while the rest are browsing — giving a heavily read-centric 5:1 read/write ratio.
Functional Requirements
We extract verbs from the problem statement to identify core operations:
- "searches for events" → READ operation (Event Discovery)
- "views available seats" → READ operation (Seat Availability)
- "reserves a seat" → WRITE operation (Temporary Hold)
- "books the seat" via payment → WRITE operation (Purchase Confirmation)
- "joins a waitlist" if the seat is taken → WRITE operation (Waitlist)
Each verb maps to a functional requirement. The requirements form a pipeline: search → view → reserve → pay → confirm.
-
Event Discovery — Users search for events by name, artist, venue, location, or date. The system returns matching events with basic details (name, date, venue, price range).
-
Seat Availability — For a selected event, display all seats with their current status (available, reserved, booked). Typically rendered as an interactive seat map with color-coded indicators.
-
Seat Reservation — When a user selects a seat, temporarily hold it for a limited time window (e.g., 2 minutes) while they complete payment. No other user can reserve this seat during the hold.
-
Booking Confirmation — Process payment through an external provider (Stripe, PayPal). On success, transition the seat from reserved to booked. On failure or timeout, release the seat.
-
Waitlist — If a seat is already reserved, the user joins a FIFO queue. If the reservation expires without payment, the next waitlisted user gets the opportunity to reserve.
Out of Scope
- Event creation and venue management (admin side)
- Dynamic pricing / auction-style bidding
- Resale / secondary marketplace
- Seating chart designer
- Push notifications for upcoming events
- Social features (sharing, group bookings)
- Loyalty programs and promotional codes
Non-Functional Requirements
We extract adjectives and descriptive phrases to identify quality constraints:
- "no double bookings" → Strong consistency on seat inventory; exactly-once reservation semantics
- "millions of users" during on-sale events → High concurrency with extreme traffic spikes (100× baseline)
- "first-come, first-served" → Strict ordering of reservation requests
- "limited time window" for payment → Reservation expiry with automatic release
- "real-time" seat status updates → Low-latency seat availability updates as seats are reserved/released
| NFR | Target | Reasoning |
|---|---|---|
| Strong Consistency | Zero double-bookings across all race conditions | A sold seat must never be assigned to two users — legal and financial liability |
| High Availability | 99.99% during on-sale events | Downtime during a Taylor Swift on-sale is catastrophic — millions of users, minutes of window |
| Low Latency | <200ms for seat availability; <500ms for reservation | Users won't wait; slow = lost sales and user exodus to competitors |
| Burst Scalability | 100K → 10M+ concurrent users in seconds | On-sale traffic is not gradual — it's a step function at the announced time |
| Fairness | First-come, first-served ordering | Users who arrive first should get first access to seats |
| Reliability | Reservation expires if payment fails | Prevent seat hoarding — seats must be released back to inventory |
Key insight: The core tension is consistency vs availability during peak traffic. The system resolves this by separating the read path (seat availability — eventually consistent, cached) from the write path (reservation — strongly consistent, serialized). Reads scale horizontally via caching; writes are serialized through an ordered queue to guarantee consistency.
Resource Estimation
Scale Assumptions
| Parameter | Value |
|---|---|
| Daily active users | ~10 million |
| Peak concurrent users | ~100,000 (on-sale events) |
| Concurrent booking attempts | ~20,000 |
| Read:Write ratio | 5:1 |
| Average write requests per user per day | ~5 |
| Data per write request | ~1 KB |
Throughput
Read QPS (average):
Write QPS (average):
Peak write QPS (on-sale burst):
During a hot on-sale event, 20,000 users concurrently attempting to book in the first few seconds:
Storage
Event + seat data:
Assume 50,000 events/year, average 10,000 seats per event:
Booking + transaction records:
Bandwidth
Inbound (writes):
Outbound (reads with seat maps):
Seat map responses are larger (~50 KB with seat layout + status):
During on-sale peaks, read traffic can spike 50× — CDN and caching are critical to absorb this without overwhelming the backend.
API Design
We derive API endpoints from the functional requirements. The read path serves event browsing and seat availability; the write path handles reservations and bookings.
# ── Event Search (Read Path) ─────────────────────────────────
GET /events?query={text}&location={city}&date={date}&page={n}
→ 200 OK
{
"events": [
{
"event_id": "evt_ts_2024",
"title": "Taylor Swift | The Eras Tour",
"venue": "SoFi Stadium, LA",
"date": "2024-08-15T19:30:00Z",
"price_range": { "min": 49, "max": 899, "currency": "USD" }
}
],
"total": 24,
"page": 1
}
# ── Seat Availability ────────────────────────────────────────
GET /events/{event_id}/seats
→ 200 OK
{
"event_id": "evt_ts_2024",
"sections": [
{
"section": "A",
"seats": [
{ "seat_id": "A-101", "status": "available", "price": 299 },
{ "seat_id": "A-102", "status": "reserved", "price": 299 },
{ "seat_id": "A-103", "status": "booked", "price": 299 }
]
}
]
}
# ── Reserve a Seat (Write Path) ──────────────────────────────
POST /events/{event_id}/seats/{seat_id}/reserve
{ "user_id": "u_12345" }
→ 201 Created
{
"reservation_id": "res_abc",
"seat_id": "A-101",
"status": "reserved",
"expires_at": "2024-08-15T10:02:00Z",
"payment_url": "https://pay.stripe.com/session/xyz"
}
# ── Confirm Booking (after payment webhook) ──────────────────
POST /bookings/{reservation_id}/confirm
{ "payment_id": "pay_xyz", "provider": "stripe" }
→ 200 OK
{
"booking_id": "bk_789",
"status": "confirmed",
"seat_id": "A-101",
"event": "Taylor Swift | The Eras Tour"
}
# ── Cancel Reservation ───────────────────────────────────────
POST /reservations/{reservation_id}/cancel
→ 200 OK { "status": "cancelled", "seat_status": "available" }
# ── Join Waitlist ────────────────────────────────────────────
POST /events/{event_id}/seats/{seat_id}/waitlist
{ "user_id": "u_67890" }
→ 201 Created
{
"position": 3,
"estimated_wait": "unlikely"
}WebSocket / SSE for Real-Time Updates
For live seat map updates during on-sale events, clients subscribe to a Server-Sent Events (SSE) stream:
| Direction | Event Type | Payload |
|---|---|---|
| Server → Client | seat_status_changed | {seat_id, new_status, section} |
| Server → Client | reservation_expiring | {reservation_id, seconds_left} |
| Server → Client | booking_confirmed | {booking_id, seat_id} |
| Server → Client | waitlist_offer | {seat_id, expires_at} |
SSE is preferred over WebSocket here because the communication is predominantly one-directional (server → client). The client only needs to know about seat status changes — it doesn't need to send frequent messages upstream.
Data Model
Five core entities drive the architecture, each owned by its respective microservice:
Event — Represents a scheduled event at a venue.
| Field | Type | Description |
|---|---|---|
event_id | string | Primary key |
title | string | Event name |
venue_id | string | FK to venue |
date | timestamp | Event date/time |
on_sale_date | timestamp | When tickets go on sale |
total_seats | int | Total inventory count |
Seat — Individual seat within an event/venue.
| Field | Type | Description |
|---|---|---|
seat_id | string | Primary key |
event_id | string | FK to event |
section | string | Section/area in venue |
row | string | Row identifier |
number | int | Seat number |
status | enum | available, reserved, booked |
price | decimal | Ticket price |
reserved_by | string | User ID (null if available) |
reserved_until | timestamp | Reservation expiry |
version | int | For optimistic concurrency |
Booking — Confirmed purchase linking user, event, and seat.
| Field | Type | Description |
|---|---|---|
booking_id | string | Primary key |
event_id | string | FK to event |
seat_id | string | FK to seat |
user_id | string | FK to user |
status | enum | pending, confirmed, cancelled |
created_at | timestamp | When booking was created |
Transaction — Payment record for a booking.
| Field | Type | Description |
|---|---|---|
transaction_id | string | Primary key |
booking_id | string | FK to booking |
payment_status | enum | pending, success, failed, refunded |
payment_provider_id | string | External payment reference |
amount | decimal | Payment amount |
Waitlist — FIFO queue per seat for users waiting for availability.
| Field | Type | Description |
|---|---|---|
waitlist_id | string | Primary key |
event_id | string | FK to event |
seat_id | string | FK to seat |
user_id | string | FK to user |
position | int | Queue position |
created_at | timestamp | When joined |
Relationships: Event → Seat is 1:many. Seat → Booking is 1:1 (per event). Booking → Transaction is 1:1. Seat → Waitlist is 1:many.
Each microservice owns its database: Search Service owns Events, Booking Service owns Seats + Bookings + Waitlist, Payment Service owns Transactions. Cross-service interaction is via API calls, not shared databases.
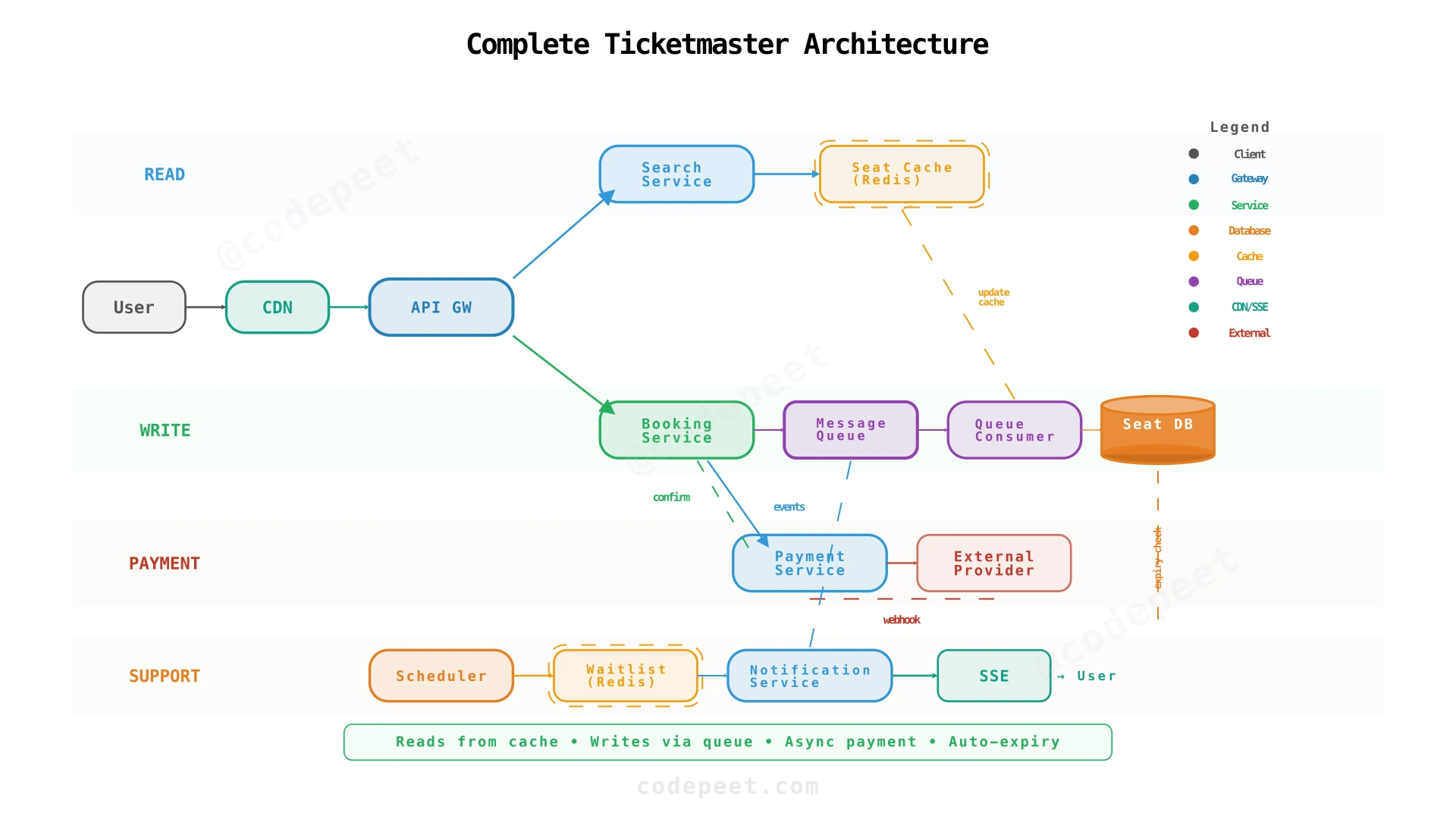
High-Level Design
We build the architecture progressively, starting from a naive single-service design and evolving through three iterations. Each step addresses specific failure modes revealed by the previous design.
Step 1: Naive Design — Direct Database Booking
The Starting Architecture
Start with the simplest possible approach: a single service that handles all operations — search, reservation, payment — with a single relational database.
The Flow
- User searches for events → direct database query
- User selects a seat →
UPDATE seat SET status = 'reserved' WHERE seat_id = X - User pays → synchronous call to payment provider
- On payment success →
UPDATE seat SET status = 'booked'
Why This Breaks
This design fails under three simultaneous pressures:
- Read contention: 100K concurrent users all querying the same event's seats. Every seat map request hits the database. At 100K QPS with complex seat map queries, the database connection pool is exhausted.
- Write races: 20,000 users trying to reserve the same popular seats. Without proper concurrency control, two users reserve the same seat → double booking.
- Synchronous payment: The reservation holds a database connection while waiting for Stripe/PayPal to respond (1-3 seconds). At 2,000 concurrent payments, that's 2,000 database connections held open doing nothing.
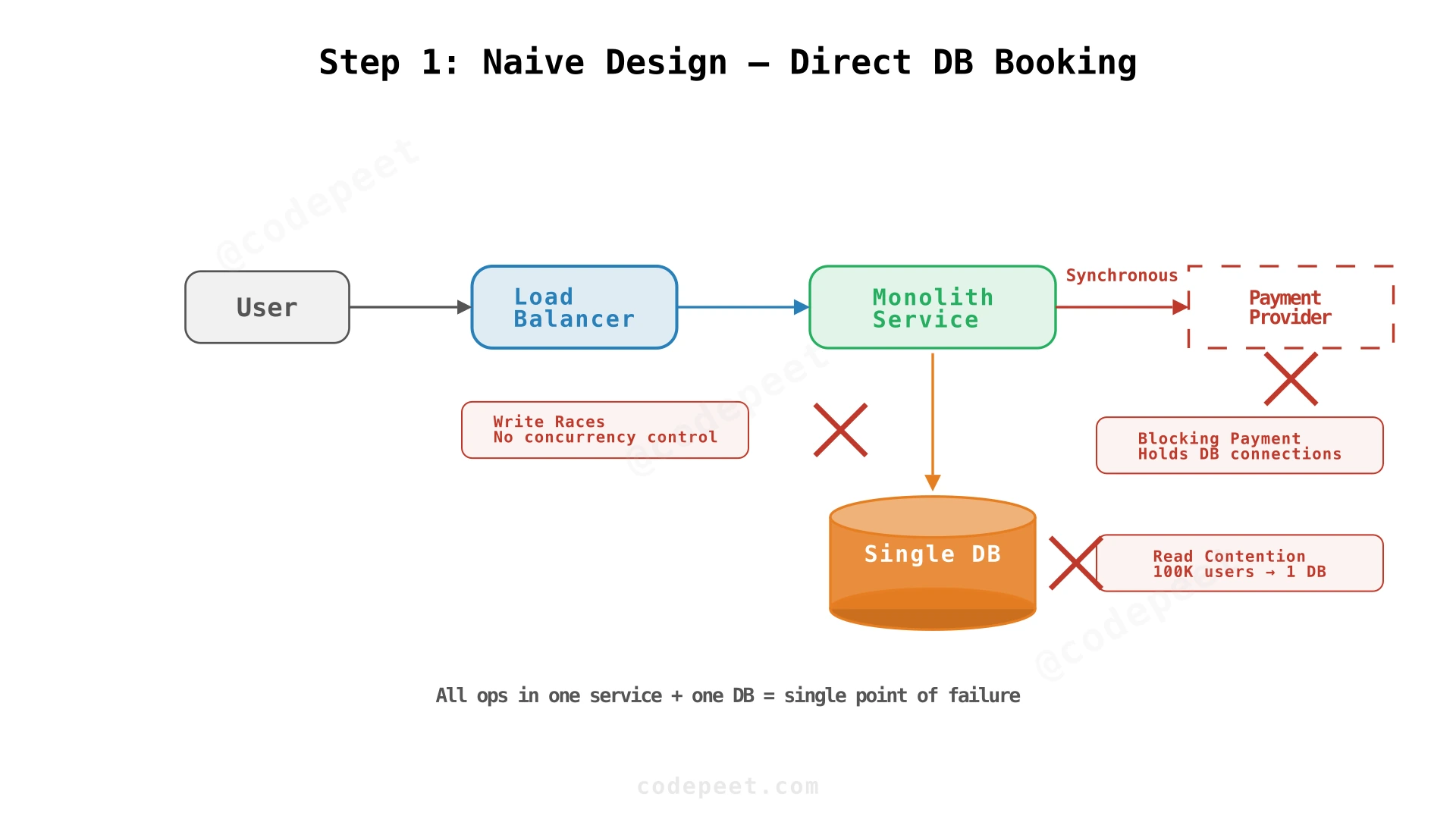
✅ Works for: Small venue with a few hundred seats and gradual ticket sales
❌ Fails at scale: Database is the bottleneck for both reads and writes. No caching, no queue, no separation of concerns. Double-booking possible without explicit locking. Synchronous payment blocks resources.
Step 2: Read/Write Path Separation — Caching + Booking Service
Separating Reads from Writes
The fundamental insight: reads and writes have completely different characteristics and should be handled by different infrastructure.
- Reads (event search, seat availability): high volume, tolerant of slight staleness (a seat showing as 'available' for an extra second is acceptable)
- Writes (reservation, booking): low volume but must be strictly consistent (no double-booking)
Read Path: Search Service + Cache
The Search Service handles all read operations. Event data and venue information changes infrequently, so it's cached aggressively:
- Event catalog → cached with long TTL (hours)
- Seat availability → cached with short TTL (seconds) in a Seat Cache (Redis or Memcached)
When a user opens the seat map, the Search Service reads from the Seat Cache. The cache is updated when seats are reserved or released. This offloads 95%+ of read traffic from the database.
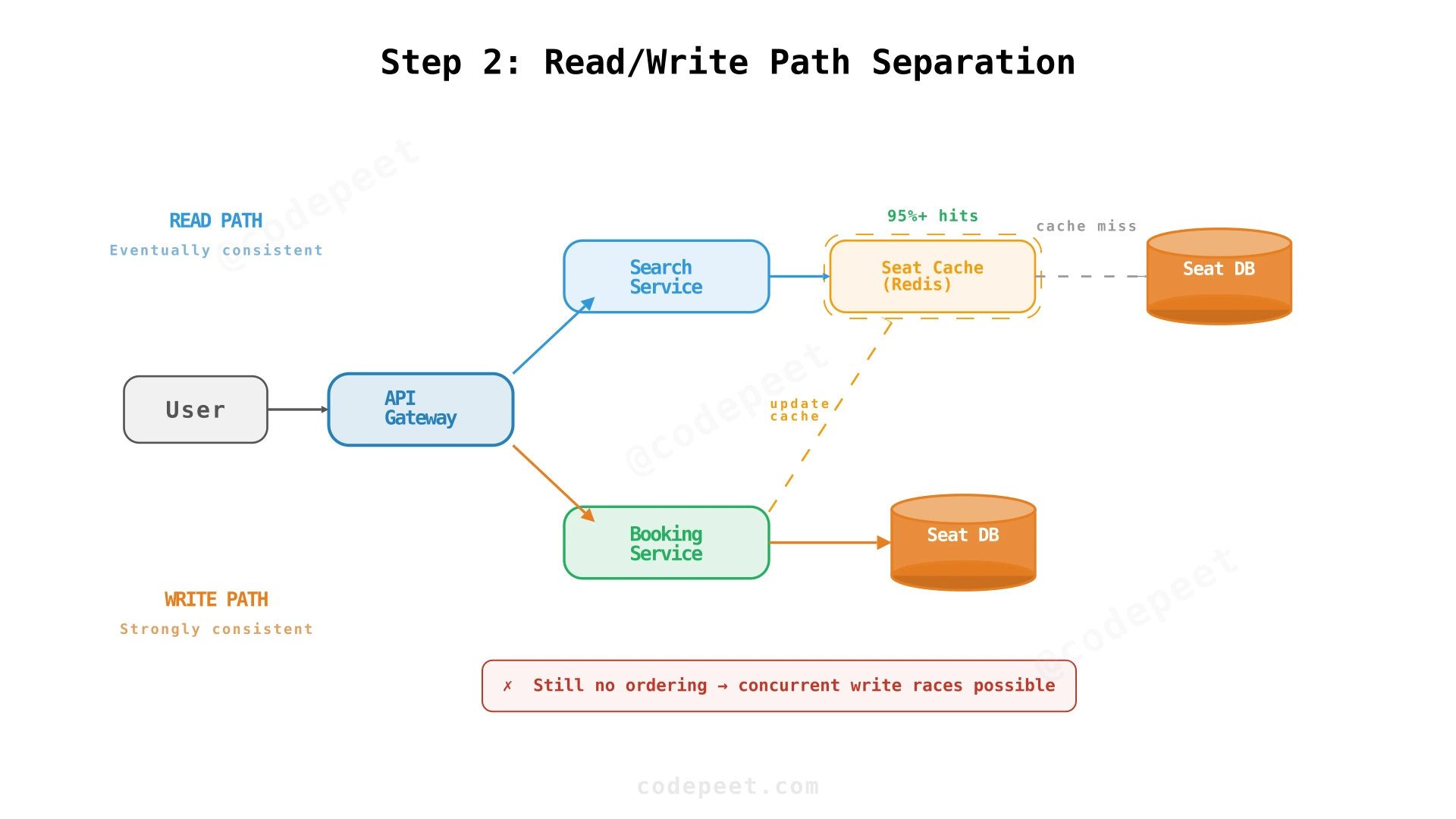
Write Path: Booking Service
The Booking Service handles all reservation and booking operations. When a user reserves a seat:
- Booking Service receives the reservation request
- Attempts to mark the seat as
reservedin the database - Updates the Seat Cache to reflect the new status
- Returns reservation details + payment link to the user
The Problem: Concurrent Write Races
Even with read/write separation, 20,000 concurrent booking attempts can still cause race conditions. Two users simultaneously read a seat as available, both attempt to reserve it, and both succeed — double booking.
✅ NFRs addressed: Read scalability via caching (burst traffic absorbed), separation of concerns
❌ Still missing: No ordering of write requests — race conditions on concurrent reservations. Synchronous payment still blocking. No reservation expiry mechanism. No waitlist.
Step 3: Ordered Queue + Asynchronous Payment Pipeline
Serializing Writes with a Message Queue
The write race problem from Step 2 has a clean solution: serialize all reservation requests through an ordered message queue.
Instead of the Booking Service writing directly to the database, it pushes reservation requests into a message queue (Kafka, SQS, or RabbitMQ). A Queue Consumer processes requests one at a time in FIFO order.
The Reservation Flow
- User clicks "Reserve" → Booking Service enqueues the request
- Booking Service immediately returns to the user: "Your seat is being reserved..." (spinner on UI)
- Queue Consumer picks up the request:
- Checks if the seat is still
availablein the database - If yes: marks it as
reserved, updates the cache, triggers payment flow - If no: rejects the request, notifies the user
- Checks if the seat is still
- The queue ensures first-come, first-served ordering — the first request enqueued wins
This eliminates write races by design: only one consumer processes reservations for a given seat at a time. The queue also acts as a buffer during traffic spikes — it absorbs burst writes that would otherwise overwhelm the database.
Asynchronous Payment
Payment is decoupled from the reservation. After a seat is reserved:
- Booking Service sends a payment link to the user (via SSE/notification)
- User completes payment through the external provider
- Payment provider sends a webhook to our Payment Service
- Payment Service records the transaction and notifies Booking Service
- Booking Service transitions the seat from
reservedtobooked - A message is sent to the queue to update the Seat Cache
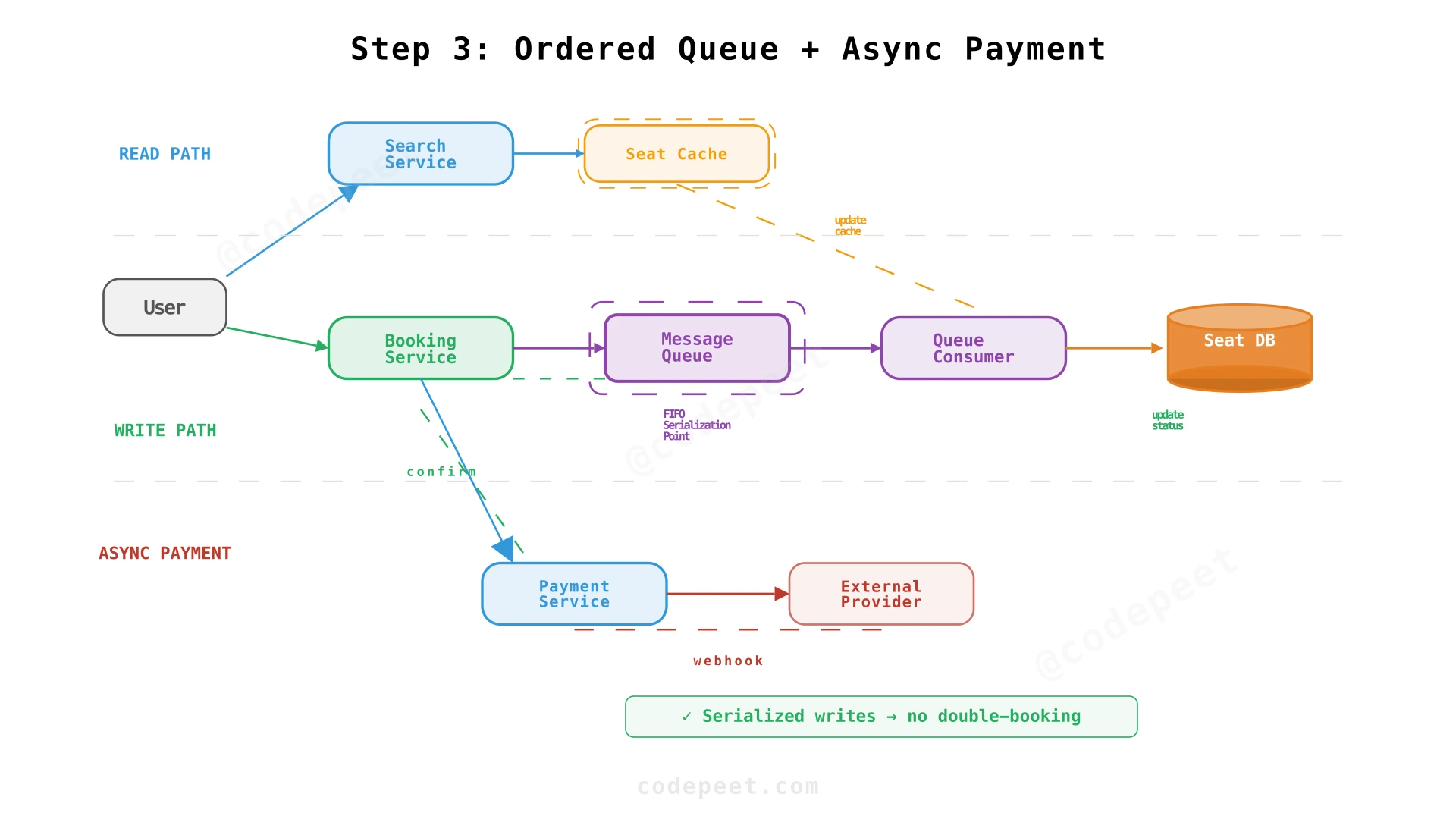
Why a Queue Instead of Database Locking?
Database-level locks (e.g., SELECT ... FOR UPDATE) also prevent double-booking, but they hold connections open under contention. With 20,000 concurrent requests for the same event, lock contention cascades into connection pool exhaustion and timeouts. The queue decouples admission from processing — the database sees a steady, manageable stream of writes regardless of how bursty the incoming traffic is.
The queue also provides natural fairness: requests are processed in arrival order. With database locking, the request that acquires the lock first wins — which may depend on network latency rather than user arrival time.
✅ NFRs addressed: No double-booking (serialized writes), first-come first-served ordering, async payment (no blocking resources), burst absorption
❌ Still missing: No reservation expiry — what if a user reserves but never pays? No notifications to users about reservation status. No waitlist. No protection against bots and unfair access.
Step 4: Complete Architecture — Reservation Expiry, Notifications, and Waitlist
Adding Expiry, Notifications, Waitlist, and Fair Access
The final architecture addresses the remaining gaps: reservation timeout, user notifications, waitlist management, and bot protection.
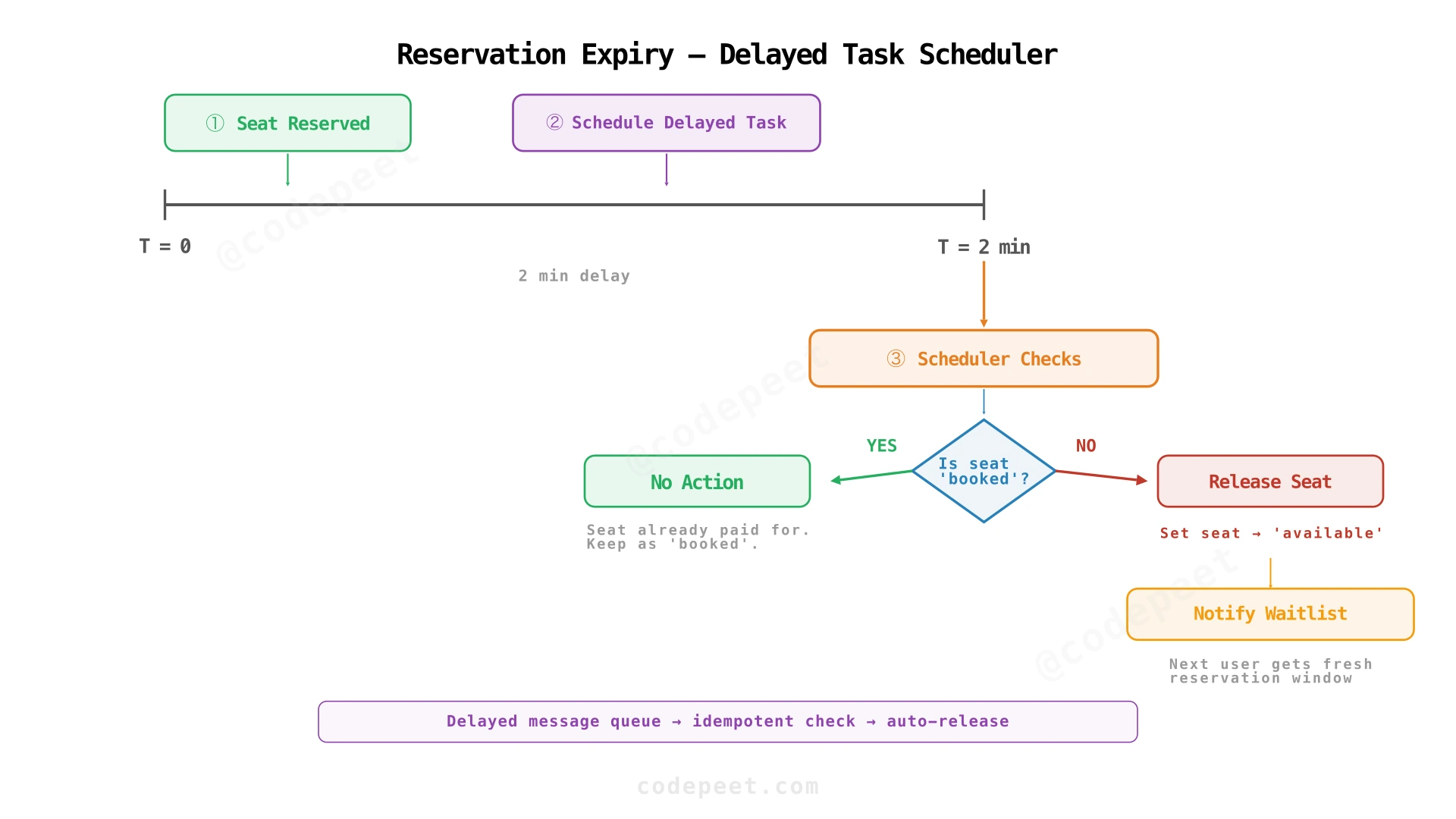
Reservation Expiry via Delayed Task Scheduler
When a seat is reserved, the system simultaneously schedules a delayed task (e.g., 2 minutes later). The Scheduler checks: is the seat now booked? If not, the reservation expired without payment — release it back to available.
Implementation options:
- Redis key with TTL: Set a key
reservation:{id}with a 2-minute TTL. On expiry, a notification triggers the release logic. - Delayed message queue: Send a message with a 2-minute delivery delay. When the consumer receives it, check the seat status.
- Scheduled task service: A cron-like service that polls for expired reservations every N seconds.
The delayed message queue approach is simplest and most reliable — it's idempotent (checking status before acting) and doesn't require polling.
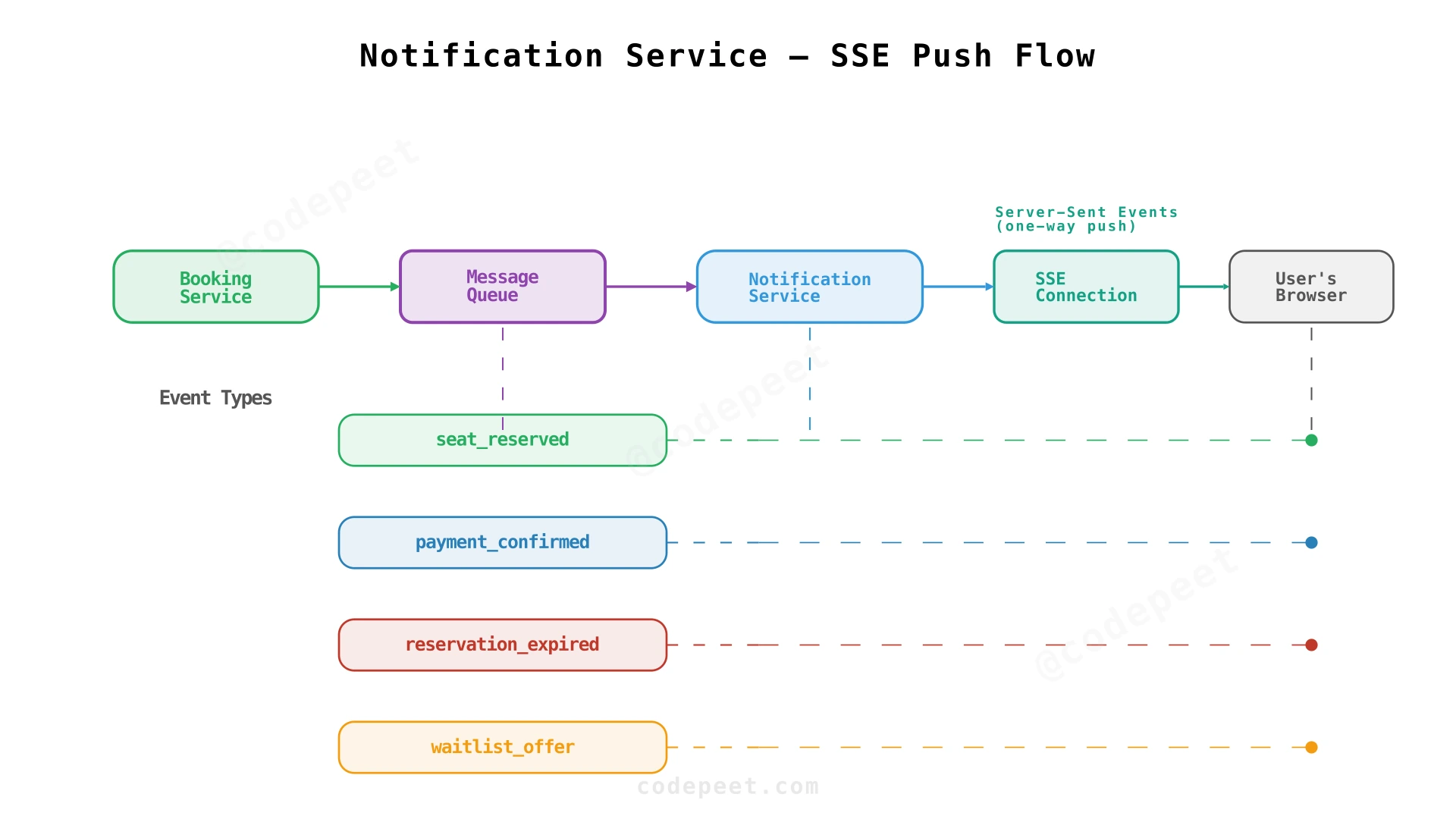
Notification Service
The Booking Service needs to notify users about:
- Seat is being reserved — proceed to payment
- Payment successful — booking confirmed
- Reservation expired — seat released
- Waitlist offer — it's your turn to reserve
This is done through a Notification Service that consumes events from the message queue and pushes updates to the user via Server-Sent Events (SSE). SSE is ideal here: communication is server-to-client only, and it works over standard HTTP — no WebSocket upgrade needed.
Waitlist Implementation
When a user tries to reserve an already-reserved seat, they can join a waitlist. The waitlist is a FIFO queue per seat (Redis list is ideal):
- Join:
LPUSH waitlist:{event_id}:{seat_id} {user_id} - Dequeue:
RPOP waitlist:{event_id}:{seat_id}→ returns the longest-waiting user
When a reservation expires (user didn't pay), the Scheduler releases the seat and immediately dequeues the next waitlisted user, giving them a fresh reservation window.
Fair Access and Bot Protection
During high-demand events, bots can monopolize the booking flow. Protections include:
- Virtual waiting room: Before on-sale time, users enter a queue. At on-sale, users are admitted in random or first-come order at a controlled rate.
- CAPTCHA/verification: Challenge users before allowing reservation to filter automated traffic.
- Rate limiting: Per-user and per-IP request limits.
- Lottery system: For extremely high-demand events, randomly select users who get the opportunity to purchase (used by some real-world ticketing systems).
- Time-slot allocation: Spread buying activity across intervals to prevent simultaneous request tsunamis.
NFR Scorecard
| NFR | Target | How It's Met |
|---|---|---|
| Strong Consistency | Zero double-bookings | Write path serialized through ordered message queue; Queue Consumer processes one seat reservation at a time; optimistic concurrency control as additional safeguard |
| High Availability | 99.99% during on-sale events | Read path served entirely from cache (Redis + CDN); write path decoupled via queue — Booking Service stays responsive even if Consumer is slow |
| Low Latency | <200ms reads, <500ms reservation | Seat Cache hit ratio >95%; reservation is an async queue push (<50ms); payment is fully async |
| Burst Scalability | 100K+ concurrent users | CDN absorbs static content; Seat Cache absorbs seat queries; message queue buffers write bursts; Search Service scales horizontally |
| Fairness | First-come, first-served | FIFO message queue guarantees ordering; virtual waiting room + CAPTCHA prevent bots; waitlist serves users in order |
| Reliability | No seat hoarding | Delayed task scheduler releases unpaid reservations after timeout; waitlist automatically offers to next user |
Deep Dives
How do you prevent double-booking?
Preventing Double Bookings
Double-booking is the cardinal sin of a ticketing system. This deep dive explores three complementary approaches at different layers.
Layer 1: Application-Level Serialization (Queue)
The ordered message queue is the primary defense. All reservation requests for a given event are routed to the same queue partition (partitioned by event_id). The consumer processes them sequentially. When it encounters a request for a seat that's already reserved, it rejects the request — no race condition possible.
This works because the queue is ordered and the consumer is single-threaded per partition. For systems handling multiple events simultaneously, each event gets its own partition — parallelism across events, serialization within an event.
Layer 2: Database-Level Pessimistic Locking
As a second line of defense (defense in depth), the Queue Consumer uses a pessimistic lock when updating the seat:
BEGIN TRANSACTION;
-- Acquire exclusive lock on the seat row
SELECT * FROM seats
WHERE seat_id = 'A-101' AND event_id = 'evt_ts_2024'
FOR UPDATE;
-- Check if still available
-- IF status = 'available' THEN:
UPDATE seats
SET status = 'reserved',
reserved_by = 'u_12345',
reserved_until = NOW() + INTERVAL '2 minutes'
WHERE seat_id = 'A-101'
AND status = 'available';
COMMIT;The FOR UPDATE lock prevents any other transaction from modifying this row until the current transaction commits. Even if (due to a bug) two consumers process the same seat concurrently, the lock serializes them at the database level.
Layer 3: Optimistic Concurrency Control
An alternative or complementary approach is optimistic locking with a version field:
UPDATE seats
SET status = 'reserved',
reserved_by = 'u_12345',
version = version + 1
WHERE seat_id = 'A-101'
AND status = 'available'
AND version = 42;
-- If 0 rows affected → someone else got there firstOptimistic locking is better for high-contention scenarios because it doesn't hold a lock while processing — it tries the update and handles failure. But for the ticketing use case where the queue already serializes writes, pessimistic locking in the Consumer is safe (no contention, since only one Consumer processes a given event's requests).
Distributed Locking (Redis)
A third option is a distributed lock using Redis (SET seat_lock:{seat_id} NX EX 30). This provides a lock outside the database, useful when multiple services need to coordinate.
However, for this use case, a distributed lock adds unnecessary complexity. The queue + database lock already guarantees exactly-once reservation. A Redis lock would be useful if you had multiple independent Booking Services writing directly to different databases (which our architecture avoids).
Recommendation: Queue-based serialization as the primary mechanism. Database-level pessimistic lock as defense in depth. Avoid distributed locks unless the architecture demands cross-service coordination.
Cache-Database Consistency
A subtle edge case: the Seat Cache shows a seat as available but the database has it as reserved. Two users see it as available, both submit reservation requests. The queue serializes them — only the first succeeds. The second gets rejected and can join the waitlist.
The cache is eventually consistent by design. It's updated after each reservation and release, but there's always a small window (milliseconds to seconds) where the cache lags behind the database. This is acceptable because the cache is not the source of truth — the database is, and the queue ensures only valid reservations succeed.
How do you implement a waitlist?
Waitlist Design
When a seat is already reserved, the user shouldn't just see "unavailable" — they should have a way to queue up. If the current holder doesn't complete payment, the next person in line gets a shot.
Data Structure: Redis List per Seat
A Redis list provides O(1) push/pop operations and natural FIFO ordering:
# User joins waitlist
redis.lpush(f"waitlist:{event_id}:{seat_id}", user_id)
# Check position
position = redis.lpos(f"waitlist:{event_id}:{seat_id}", user_id)
# When seat becomes available, dequeue next user
next_user = redis.rpop(f"waitlist:{event_id}:{seat_id}")
if next_user:
# Create reservation for next_user
create_reservation(event_id, seat_id, next_user)
# Notify via SSE
notify_user(next_user, "Your waitlisted seat is now available!")Waitlist Lifecycle
- User A reserves seat A-101 (status →
reserved) - User B tries to reserve A-101 → seat is taken → offered to join waitlist
- User B joins →
LPUSH waitlist:evt:A-101 user_B(position 1) - User C joins →
LPUSH waitlist:evt:A-101 user_C(position 2) - User A's reservation expires (didn't pay within 2 minutes)
- Scheduler releases seat A-101 → status back to
available - Scheduler dequeues User B →
RPOP waitlist:evt:A-101 - System creates a fresh reservation for User B with a new 2-minute window
- User B receives SSE notification: "Seat A-101 is available — complete payment now!"
Edge Cases
- What if User B's app is closed when they're dequeued? Send a push notification and give them a slightly longer window (e.g., 5 minutes instead of 2).
- What if the waitlist is very long? Show the user their position and a realistic estimate ("unlikely" if they're position 50 for a single seat).
- What if the user no longer wants the seat? Allow them to leave the waitlist (
LREM), which doesn't affect other users' positions.
How do you ensure fair access during high-demand events?
Fair Access and Virtual Waiting Rooms
When 10 million fans refresh the page at exactly 10:00 AM for a Taylor Swift concert with 80,000 seats, the system faces a thundering herd problem. Without protection, the first few hundred milliseconds determine everything — and bots are faster than humans.
Virtual Waiting Room
Before the on-sale time, users enter a virtual queue (like a checkout line). The system works like this:
- Users arrive at the event page before on-sale time and click "Join Queue"
- Each user gets a random queue position (lottery-based) or a first-come position (arrival-based)
- At on-sale time, the system admits users in controlled batches (e.g., 1,000 users every 5 seconds)
- Admitted users can browse available seats and make reservations
- Users still in the queue see their position and estimated wait time
The waiting room is typically implemented as a separate lightweight service (or even a CDN-level gate) that sits in front of the API Gateway. It serves a static waiting page to queued users and only routes admitted users to the actual Booking Service.
Why Random Position?
Arrival-based ordering (first to click "Join" gets position 1) rewards fast internet connections and bots. A randomized lottery at on-sale time gives everyone who joined before on-sale an equal chance, regardless of when they clicked (as long as it was before the cutoff). This is fairer and simulates a physical venue where doors open simultaneously.
Bot Protection Stack
| Layer | Mechanism | What It Catches |
|---|---|---|
| Network | Rate limiting per IP + per user ID | Rapid-fire reservation attempts |
| Application | CAPTCHA before reservation | Automated scripts without browser |
| Behavioral | Device fingerprinting + interaction patterns | Sophisticated bots that solve CAPTCHAs |
| Business | Purchase limits per user/account | Scalpers buying bulk tickets |
| Monitoring | Anomaly detection on request patterns | Coordinated bot networks |
Time-Slot Allocation
For extremely high-demand events, split the available inventory across multiple time slots (e.g., 10:00 AM, 10:15 AM, 10:30 AM). Each slot opens a portion of seats. This spreads the traffic spike into three smaller peaks, each manageable by the system. Users are assigned a time slot when they join the waiting room.
How do you scale for hot events without over-provisioning?
Hot Event Scaling Strategy
Most events see modest traffic — a local theater show or a minor league game. But a Taylor Swift or Beyoncé concert can spike traffic 100× within seconds. If you provision for peak Taylor Swift traffic all the time, you're wasting 99% of your infrastructure budget most of the time.
Traffic Tiers
Classify events into traffic tiers based on expected demand:
| Tier | Examples | Expected Peak Concurrent | Strategy |
|---|---|---|---|
| Standard | Local theater, comedy shows | <1,000 | Shared infrastructure |
| High | Popular bands, sports playoffs | 10K-50K | Pre-scaled, dedicated cache |
| Mega | Taylor Swift, World Cup | 100K-10M+ | Dedicated cluster + waiting room |
Pre-Scaling for Mega Events
For known mega events, the system pre-scales before the on-sale time:
- Cache warming: Pre-populate the Seat Cache with the entire venue layout before on-sale. No cache misses during the initial rush.
- Queue partitioning: Create dedicated queue partitions for the mega event. Standard events share a common partition pool.
- Read replica scaling: Spin up additional read replicas for the event's database shard 30 minutes before on-sale.
- CDN pre-staging: Push static event assets (venue map, images, seat layouts) to CDN edge nodes in advance.
- Auto-scaling triggers: Set aggressive auto-scaling rules that trigger on queue depth rather than CPU (queue depth reacts faster to traffic spikes).
Geographic Sharding
Events are naturally geographic — a concert in LA is only relevant to users in the western US (mostly). Shard the Seat DB by geographic region:
- North America West, North America East, Europe, Asia-Pacific
- Each region has its own Search Service, Seat Cache, and queue infrastructure
- Global events (e.g., World Cup finals) are handled by a dedicated global cluster
This contains blast radius — a traffic spike for an LA concert doesn't affect users browsing events in London.
Post-Event Cleanup
After on-sale completes (usually within 30-60 minutes), automatically scale down the dedicated infrastructure. Set an auto-cleanup timer to decommission extra replicas and cache entries after a cooling period.
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions for staff+ conversations.
Event Sourcing for Seat Inventory
Context: Instead of updating seat status in-place (available → reserved → booked), what if you stored every state transition as an immutable event? The current status is derived by replaying events.
Discussion Points:
- Append-only event log guarantees full audit trail (who reserved, when, from which IP, what happened)
- Replay events to rebuild the Seat Cache after a crash — no stale data
- Temporal queries: "What was seat A-101's status at 10:00:03 AM?" — trivial with event sourcing, impossible with in-place updates
- Tradeoff: event replay is slower than a simple status read. Snapshot the current state periodically to bound replay time.
- CQRS natural fit: the event store is the write model, the Seat Cache is the read model. They evolve independently.
Multi-Region Active-Active for Global Events
Context: A World Cup final has fans buying tickets from every continent simultaneously. A single region can't serve all of them with low latency. But seat inventory is a shared, strongly-consistent resource. How do you go multi-region?
Discussion Points:
- Reads can be served from local replicas per region (eventual consistency acceptable for seat availability)
- Writes must be routed to a single leader region for inventory consistency
- Alternatively: partition inventory by section — Region A processes sections 1-10, Region B processes sections 11-20. Each region is the leader for its partition.
- Cross-region write latency (100-200ms) acceptable? Or does it cause timeout cascades during peak?
- Conflict resolution: what if a section's leader region goes down mid-sale? Failover time vs data consistency trade-off.
Idempotency and the Payment-Booking Race
Context: The payment webhook from Stripe arrives but the booking confirmation message to the queue is lost due to a network glitch. The seat is marked booked in the payment system but still reserved in the Seat DB. The scheduler fires and releases it. Now the user paid but their seat is gone.
Discussion Points:
- Idempotent payment webhook handler: use the
payment_idas a deduplication key. Processing the same webhook twice is a no-op. - Outbox pattern: the Payment Service writes the booking confirmation to an outbox table in the same transaction as recording the payment. A separate reader publishes to the queue. No dual-write risk.
- Reservation release should check the payment status before releasing — the scheduler queries the Payment Service before acting.
- Compensating transactions: if the seat was released after payment, automatically issue a refund + notify the user with apology.
Level Expectations
| Dimension | |||
|---|---|---|---|
| Requirements | Identify core FRs: search events, view seats, reserve, book. Mention no double-booking. Basic scale numbers. | Define NFRs precisely: consistency vs availability tension, burst scalability requirements, read/write ratio implications. Reservation expiry as a requirement. | Challenge assumptions — is first-come-first-served the right model? Argue for lottery-based access. Identify the payment-booking race as a distributed systems problem. |
| High-Level Design | Draw basic flow: User → Service → DB. Mention caching for reads. Understand that writes need some form of locking. | Separate read/write paths. Introduce message queue for write serialization. Design async payment with webhooks. Reservation expiry via scheduler. | Event sourcing for audit trail, CQRS for read/write model separation, virtual waiting rooms as a first-class component, geographic sharding for blast radius containment. |
| Consistency | Mention that double-booking is bad. Suggest database constraints or locking. | Explain pessimistic vs optimistic locking tradeoffs. Design queue-based serialization. Understand cache-DB consistency gap. | Multi-layer defense (queue + DB lock + version check). Outbox pattern for payment-booking atomicity. Compensating transactions for failure recovery. |
| Scalability | Mention caching and load balancing. | Design for 100× traffic spikes: CDN, cache warming, queue buffering. Explain read replica strategy. | Pre-scaling playbook for mega events. Traffic tier classification. Geographic sharding. Cost optimization via auto-scaling with queue-depth triggers. |
| Real-Time | Mention the user needs to know their seat status. | Choose SSE for server-to-client updates. Design notification flow through message queue. Handle reservation countdown on client. | SSE scaling across multiple server instances with a pub/sub backplane. Graceful degradation when notification service is overloaded — batch updates vs individual pushes. |
Interview Cheatsheet
Core Architecture in 60 Seconds
"Read path → cache, write path → queue. The read side (event search, seat availability) is served entirely from cache (Redis + CDN). The write side (reservation, booking) goes through an ordered message queue that serializes requests — first-come, first-served, zero double-bookings."
"Reservation is a temporary hold. User reserves a seat → 2-minute payment window. Queue Consumer marks it reserved in the DB and cache. If payment doesn't arrive, a delayed task scheduler releases it back to available."
"Payment is asynchronous. Booking Service sends a payment link. External provider sends a webhook on success. Payment Service records it, Booking Service transitions seat to booked. Outbox pattern ensures no message loss."
"Waitlist for fairness. If a seat is taken, the user joins a FIFO Redis list. When a reservation expires, the next waitlisted user gets a fresh window. Notification via SSE."
"Virtual waiting room for mega events. Before on-sale, users enter a queue. At on-sale time, users are admitted in controlled batches. Lottery randomization for fairness. CAPTCHA and rate limiting for bot protection."
Key Trade-offs to Mention
| Trade-off | Option A | Option B | When to Choose |
|---|---|---|---|
| Double-booking prevention | Queue serialization | Database locking | Queue for high concurrency (buffering); DB lock as defense in depth |
| Locking strategy | Pessimistic (FOR UPDATE) | Optimistic (version check) | Pessimistic when single consumer; optimistic for concurrent consumers |
| Seat map freshness | Real-time SSE push | Short-TTL cache + poll | SSE for on-sale events; polling for standard browsing |
| Queue ordering | Lottery (random) | FIFO (arrival) | Lottery for fairness; FIFO when arrival order matters |
| Notification channel | SSE (unidirectional) | WebSocket (bidirectional) | SSE for server-push-only; WebSocket if client needs to send frequent messages |
| Reservation expiry | Redis TTL | Delayed queue message | Redis TTL for simplicity; delayed queue for reliability and idempotency |
Common Mistakes to Avoid
- ❌ Calling a payment provider synchronously while holding a database lock — blocks resources for seconds per reservation
- ❌ Using the cache as the source of truth for seat availability — cache lag means it's eventually consistent, not strongly consistent
- ❌ Ignoring reservation expiry — seats get locked forever if users don't pay
- ❌ No plan for traffic spikes — "just add more servers" isn't a strategy when traffic goes from 1K to 10M in 1 second
- ❌ Skipping the waiting room for high-demand events — bots win, real fans lose
- ❌ Forgetting about the payment-booking race condition — if the webhook and the scheduler race, the user can pay but lose their seat