google-doc
Introduction
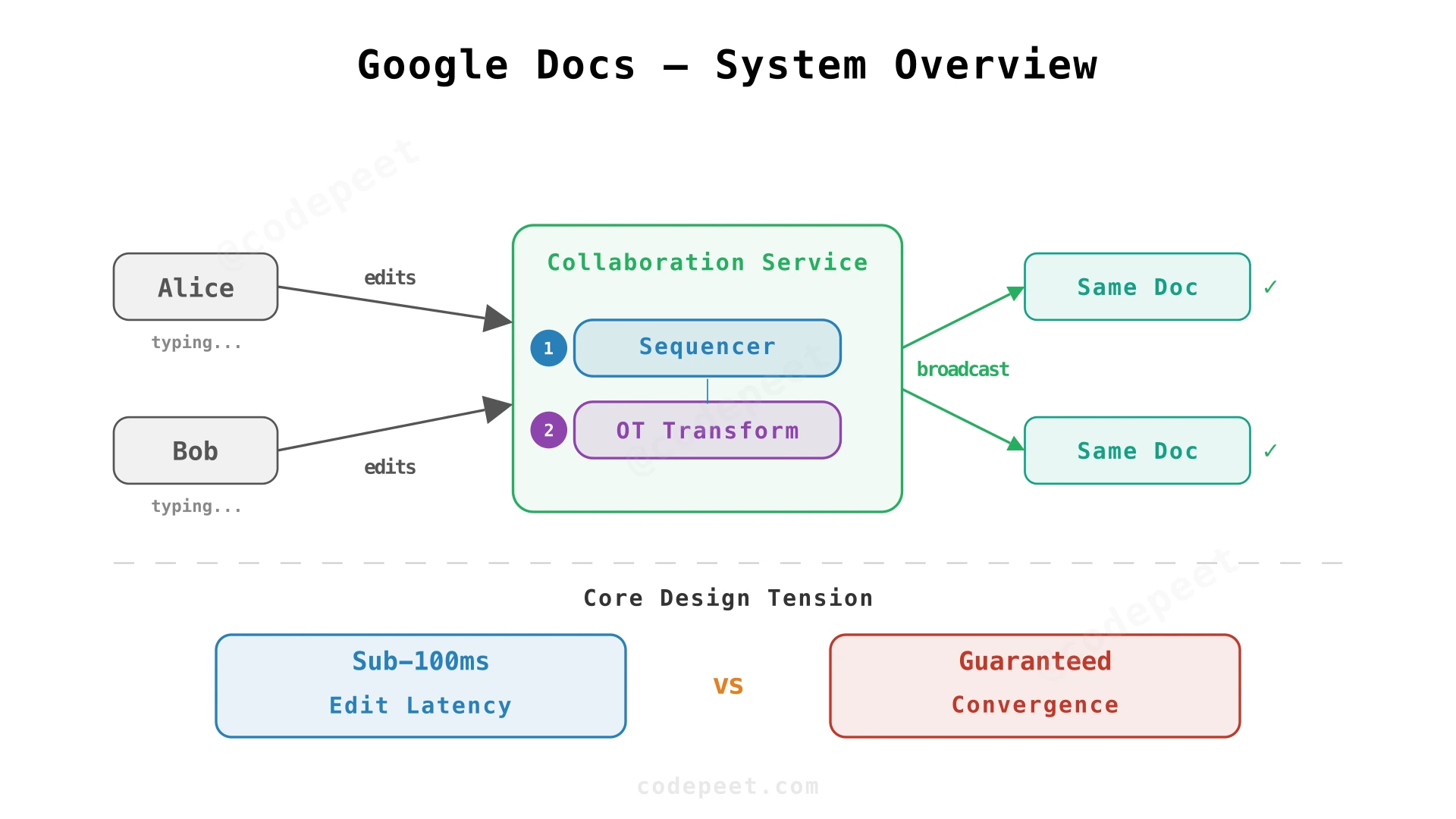
Google Docs is a collaborative document editor where multiple users simultaneously create, edit, and format text in real time. It sounds deceptively simple — it's just a text editor, right? But building a system like Google Docs requires solving some of the hardest problems in distributed systems:
-
Real-Time Collaboration — When Alice types "hello" at position 10 and Bob simultaneously deletes a word at position 5, both users must see the same final document. Every keystroke from every user must be merged into a consistent result within milliseconds. This is fundamentally a distributed consensus problem disguised as a text editor.
-
Concurrent Edit Convergence — Two users editing the same paragraph at the same time will produce conflicting operations. Unlike a database where you can lock a row, locking a paragraph would make the editor feel sluggish and defeat the purpose of real-time collaboration. The system must merge edits without locks while preserving each user's intent.
-
Mixed Durability Requirements — Document content and revision history are critical and must survive any failure. But cursor positions and selection highlights are ephemeral — if they're lost during a brief outage, nobody notices. The system must treat these two classes of data very differently.
The core challenge is the tension between speed (edits must appear instantly) and correctness (all users must converge to the same document). Most distributed systems can sacrifice one for the other. Google Docs needs both — sub-100ms edit propagation with mathematical guarantees that all replicas converge to an identical state.
At scale, the system serves ~1 million DAU, with documents supporting up to 100 concurrent editors. The read-to-write ratio is approximately 10:1 — most users are reading documents, while a smaller fraction are actively editing.
Functional Requirements
We extract verbs from the problem statement to identify core operations:
- "creates" and "edits" → Single-user document CRUD
- "streams" edits → Live edit streaming to collaborators
- "merges" concurrent operations → Concurrent edit convergence
- "shows" cursor positions → Cursor & selection presence
- "shares" with permissions → Sharing & access control
- "restores" earlier versions → Version history
Each verb maps to a functional requirement that forms a pipeline: create → edit → stream → merge → display.
-
Single-User Editing — Users can create, open, update, and delete their own documents in the browser. Changes persist across refreshes and sessions.
-
Live Edit Streaming — Edits made by one user appear to all other collaborators in near real time (sub-100ms perceived latency).
-
Concurrent Edit Convergence — Simultaneous edits from different users converge to the same final document state on all clients. No user's intent is silently dropped.
-
Cursor & Selection Presence — Users see collaborators' live cursor positions and text selections, with color-coded identity.
-
Sharing & Permissions — Users share documents with specific people or via link, with granular roles: owner, editor, commenter, viewer.
-
Version History — Users view previous revisions and restore a document to any earlier version.
Out of Scope
- Comments and suggestions workflow
- Offline editing and sync (discussed in deep dive)
- Full-text search across documents
- Rich formatting (tables, images, drawings)
- Enterprise admin policies and compliance
- Mobile-specific editor optimizations
Non-Functional Requirements
We extract adjectives and descriptive phrases to identify quality constraints:
- "real-time" and "low-latency" → Edits must arrive within ~100ms
- "consistent" → All replicas must converge to the same document state
- "durable" → Edits and revisions must never be lost
- "secure" → Every read/write must respect permissions
- "highly available" → Collaboration should continue during traffic spikes
| NFR | Target | Reasoning |
|---|---|---|
| Low Latency | <100ms edit propagation between collaborators | Users expect keystrokes to appear instantly — anything over 200ms feels laggy and breaks the collaborative flow |
| Convergence | All clients reach identical document state within seconds | Divergent documents are catastrophic — users would unknowingly work on different versions |
| Read-Your-Writes | User sees own edits immediately, even before sync | The editor must feel local. Waiting for server confirmation before showing your own keystroke is unacceptable |
| High Durability | Zero data loss for document content and revisions | Losing hours of collaborative work destroys trust. Documents are the product. |
| High Availability | 99.99% uptime during business hours | Docs is a productivity tool — downtime means teams can't work |
| Security | Permission check on every read/write operation | Documents contain sensitive data — a leaked document is a security incident |
Key insight: The system has two classes of data with different durability needs. Document content and revisions are critical — they must survive any failure. Cursor positions and presence are ephemeral — they can be dropped under load without affecting correctness. This boundary drives major architectural decisions.
Resource Estimation
Scale Assumptions
| Parameter | Value |
|---|---|
| Daily active users (DAU) | ~1 million |
| Average documents per user | ~10 |
| Average document size | ~100 KB |
| Concurrent editors per document (peak) | ~100 |
| Read:Write ratio | 10:1 |
| Peak traffic multiplier | 5× baseline |
| Edit frequency per active document | ~1 edit/sec (peak) |
Throughput
Read QPS (average):
Assume each active user opens 5 documents/day and makes 10 read requests per session (load, scroll, metadata):
Peak read QPS (5× multiplier):
Write throughput (edit operations):
Concurrent active documents with at least one editor:
This is the real challenge — 200K fine-grained edit operations per second across all documents, each needing ordering and transformation.
WebSocket connections:
At peak, ~200K users actively editing means ~200K concurrent WebSocket connections distributed across gateway nodes.
Storage
Document content:
Operation log (1 year, 100 bytes per op):
This is enormous — but operations are compacted into snapshots periodically. After compaction, retained storage is ~5-10% of raw ops.
Revision snapshots (periodic, ~1 per 100 ops):
Bandwidth
Inbound (edit operations):
Outbound (fanout — each edit broadcast to ~5 avg collaborators):
The fanout multiplier is the bandwidth driver. A hot document with 100 editors means each operation is fanned out 99× — this is why pub/sub with gateway-level batching is critical.
API Design
We derive API endpoints from the functional requirements. The system has two communication styles: REST for CRUD operations, and WebSocket for real-time collaboration.
# ── Document CRUD (REST) ─────────────────────────────────────
POST /api/documents
{ "title": "Project Plan" }
→ 201 Created
{
"document_id": "doc_abc123",
"title": "Project Plan",
"owner_id": "user_1",
"created_at": "2024-03-15T10:00:00Z"
}
GET /api/documents/{document_id}
→ 200 OK
{
"document_id": "doc_abc123",
"title": "Project Plan",
"head_revision_id": "rev_456",
"content": "...document body..."
}
# ── Submit Edit Operations ───────────────────────────────────
POST /api/documents/{document_id}/operations
{
"base_revision_id": "rev_456",
"operations": [
{ "type": "insert", "position": 10, "text": "hello " },
{ "type": "delete", "position": 25, "length": 5 }
]
}
→ 202 Accepted { "status": "queued" }
# ── Version History ──────────────────────────────────────────
GET /api/documents/{document_id}/revisions
→ 200 OK
{
"revisions": [
{ "revision_id": "rev_456", "author_id": "user_1",
"created_at": "2024-03-15T10:05:00Z" },
{ "revision_id": "rev_455", "author_id": "user_2",
"created_at": "2024-03-15T10:04:30Z" }
]
}
POST /api/documents/{document_id}/revisions/{revision_id}/restore
→ 200 OK { "new_revision_id": "rev_457", "status": "restored" }
# ── Permissions ──────────────────────────────────────────────
POST /api/documents/{document_id}/permissions
{
"principal_id": "user_2",
"role": "editor"
}
→ 200 OK { "status": "granted" }
GET /api/documents/{document_id}/permissions
→ 200 OK
{
"permissions": [
{ "principal_id": "user_1", "role": "owner" },
{ "principal_id": "user_2", "role": "editor" }
]
}WebSocket for Real-Time Collaboration
The collaboration channel uses WebSocket (WS /api/documents/{document_id}/collaborate) for bidirectional streaming:
| Direction | Message Type | Payload |
|---|---|---|
| Client → Server | operation | {base_revision_id, operations: [...]} |
| Server → Client | operation_applied | {revision_id, transformed_ops: [...]} |
| Client → Server | presence_update | {cursor_position, selection_range} |
| Server → Client | presence_broadcast | {user_id, cursor_position, color} |
| Server → Client | user_joined / user_left | {user_id, display_name} |
Why WebSocket over SSE? Collaborative editing requires bidirectional communication — clients both send edits and receive transformed edits. SSE is unidirectional (server → client only), so it would require a separate HTTP channel for sending edits, doubling the overhead.
Data Model
Four core entities drive the architecture. The key insight is that cursor presence is not a persisted entity — it's ephemeral state in the real-time layer.
Document — Core metadata for a document and pointer to its latest revision.
| Field | Type | Description |
|---|---|---|
document_id | string | Primary key (opaque, globally unique) |
title | string | Document title shown in UI |
owner_id | string | User who owns the document |
head_revision_id | string | FK to latest Revision |
updated_at | timestamp | Last modified time |
Operation — Atomic edit operation sent by a client.
| Field | Type | Description |
|---|---|---|
operation_id | string | Primary key |
document_id | string | FK to Document |
author_id | string | User who submitted the operation |
base_revision_id | string | Revision the op was based on |
payload | JSON | Insert/delete/format details |
sequence_number | int | Monotonic order within the document |
created_at | timestamp | Operation creation time |
Revision — Point-in-time version for history and restore.
| Field | Type | Description |
|---|---|---|
revision_id | string | Primary key |
document_id | string | FK to Document |
author_id | string | User who triggered this revision |
content_pointer | string | Pointer to snapshot in Object Storage |
created_at | timestamp | Revision creation time |
Permission — Access control entry defining who can access a document.
| Field | Type | Description |
|---|---|---|
document_id | string | FK to Document |
principal_id | string | User or group granted access |
role | enum | owner, editor, commenter, viewer |
share_token | string | Optional token for link sharing |
Relationships: Document → Operation is 1:many (append-only). Document → Revision is 1:many (periodic snapshots). Document → Permission is 1:many. Revision → Object Storage is 1:1 (snapshot blob).
Each service owns its data: Document Service owns Documents + Revisions, Collaboration Service owns Operations, Access Control Service owns Permissions.
High-Level Design
We build the architecture progressively, starting from single-user document CRUD and evolving through five iterations. Each step addresses a specific collaborative capability that the previous design lacks.
Step 1: Single-User Editing — Document CRUD with Durable Storage
The Starting Architecture
Start with the simplest case: one user creates a document and expects it to still exist after a refresh. This means we need a stable document identity and durable storage.
Document ID Generation
Use opaque, globally unique IDs (e.g., ULIDs or UUIDs) rather than sequential auto-increment. Sequential IDs expose document count and allow enumeration. Opaque IDs are safe for sharing links and work across distributed servers without coordination.
Metadata vs Content Split
Store document metadata (title, owner, timestamps) in a relational database and document bodies in object storage (S3, GCS). The access patterns are fundamentally different:
- Metadata is small, queried frequently (list user's docs, check ownership)
- Content is large, accessed on document open (read once, edit in real-time layer)
Splitting them keeps metadata queries fast and allows content storage to scale independently.
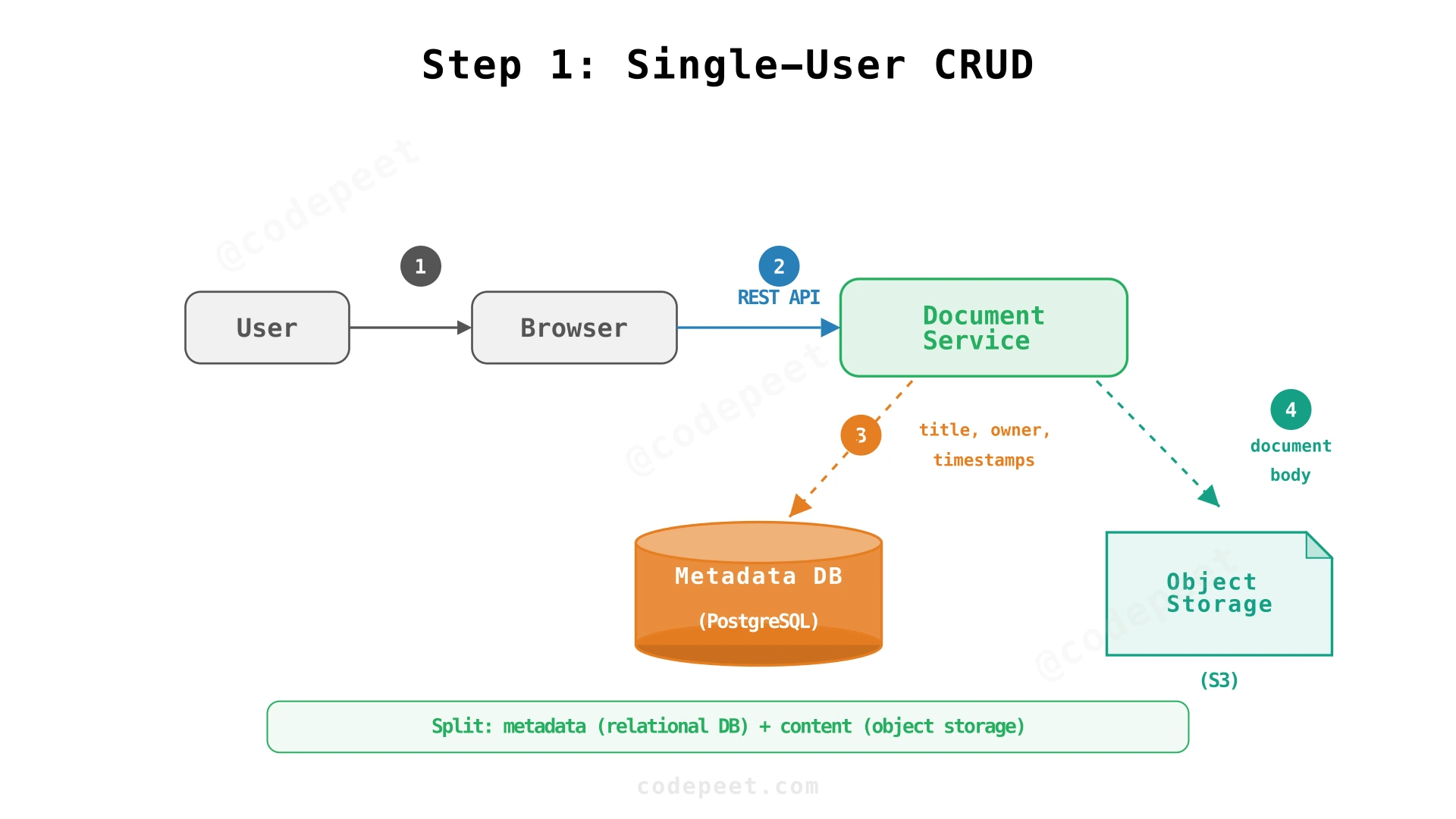
✅ Works for: A single user creating and editing their own documents
❌ Missing: No real-time collaboration — other users can't see edits until they refresh. No version history. No permissions. No concurrent edit handling.
Step 2: Live Edit Streaming — WebSocket + Pub/Sub Fanout
Adding Real-Time Communication
Single-user CRUD can't support collaboration. We need a live channel that streams edits as they happen. If we only poll every few seconds, the editor feels laggy and we waste requests when nothing changes.
Communication Protocol: WebSocket
WebSocket provides bidirectional, persistent connections. Clients send edits and receive other users' edits over the same channel. This is better than:
- Polling: wastes requests when nothing changes, adds latency
- SSE: server-to-client only — we'd need a separate channel for client edits
Fan-Out via Pub/Sub
With a single gateway server, broadcasting to all connected clients is trivial. But once we scale to multiple gateway instances, collaborators on different gateways won't receive updates. A pub/sub system (Redis Pub/Sub, Kafka) solves this:
- Client sends an edit → gateway forwards to the service layer
- Service persists the edit and publishes to the pub/sub topic for that document
- All gateway instances subscribed to that document's topic receive the update
- Each gateway broadcasts to its connected clients
The pub/sub layer decouples the edit pipeline from the delivery pipeline.
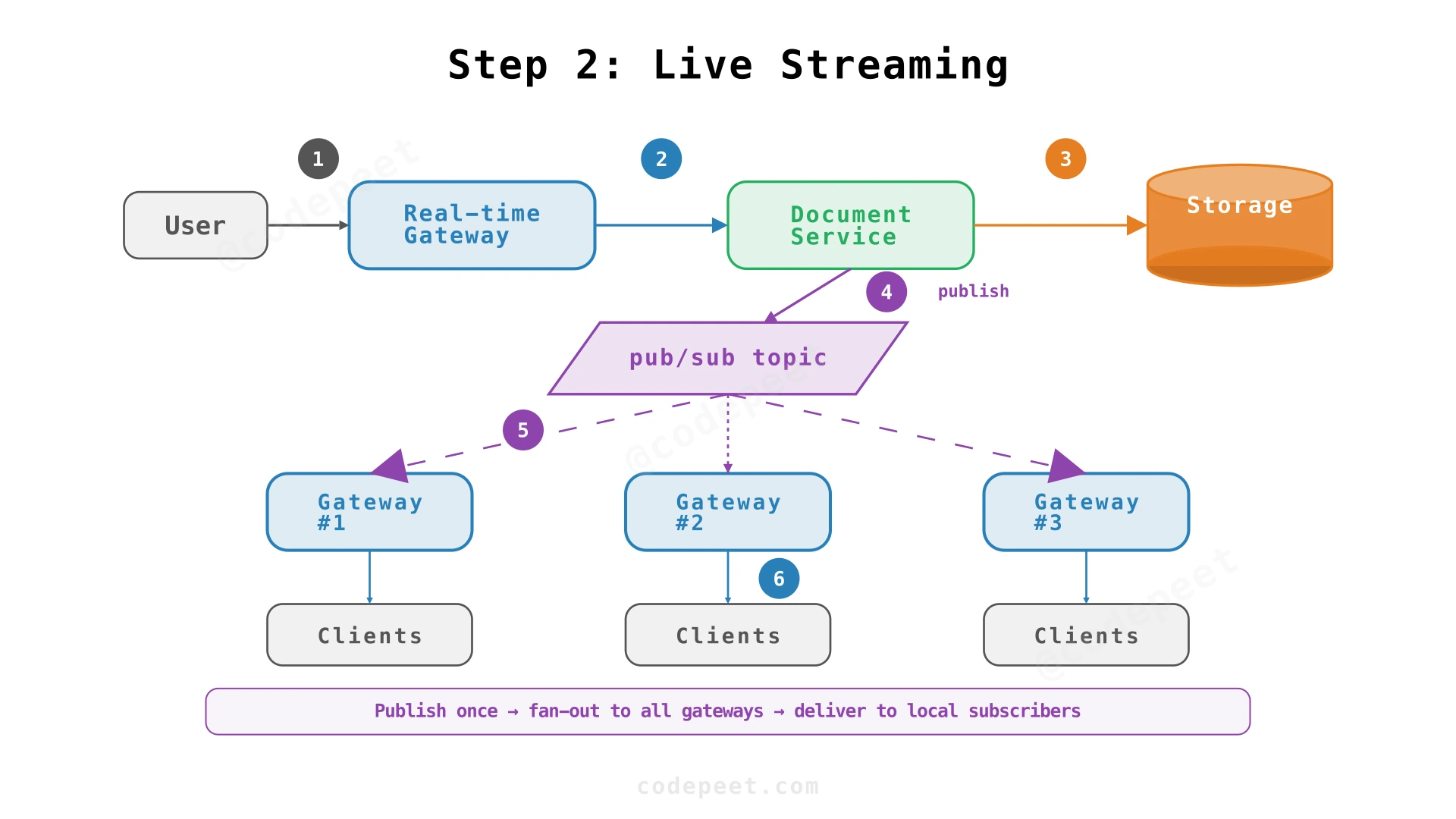
✅ NFRs addressed: Low-latency edit delivery via WebSocket, horizontal gateway scaling via pub/sub
❌ Still missing: No handling of concurrent edits — if Alice inserts at position 10 and Bob deletes at position 5 simultaneously, the positions are now wrong. Edits are delivered but not merged correctly.
Step 3: Concurrent Edit Convergence — Operational Transformation
Solving the Hardest Problem: Concurrent Edits
Live streaming isn't enough. If two users edit the same sentence at the same time, each client can end up with a different result. We need convergence — all replicas reach the same final state — not just fast delivery.
The Problem Illustrated
Document state: "Hello World"
- Alice: insert
"Beautiful "at position 6 →"Hello Beautiful World" - Bob: delete
"World"(positions 6-10) →"Hello "
Without transformation, applying both operations naively could produce:
- On Alice's screen:
"Hello Beautiful "(Bob's delete removes part of her insert) - On Bob's screen:
"Hello Beautiful World"(Alice's insert before Bob's delete)
The documents have diverged. This is unacceptable.
Operational Transformation (OT)
OT solves this by transforming concurrent operations so they account for each other's effects. The Collaboration Service receives all operations and:
- Assigns a monotonic sequence number per document (the Sequencer)
- Compares each incoming operation's
base_revision_idagainst the current head - If the operation is based on a stale revision, transforms it against all operations that happened since that revision
- Appends the transformed operation to the Operation Log (append-only)
- Updates the document state and publishes the result to pub/sub
The key constraint: one sequencer per document. This ensures a total order of operations within a document. Different documents have independent sequencers — parallelism across documents, serialization within a document.
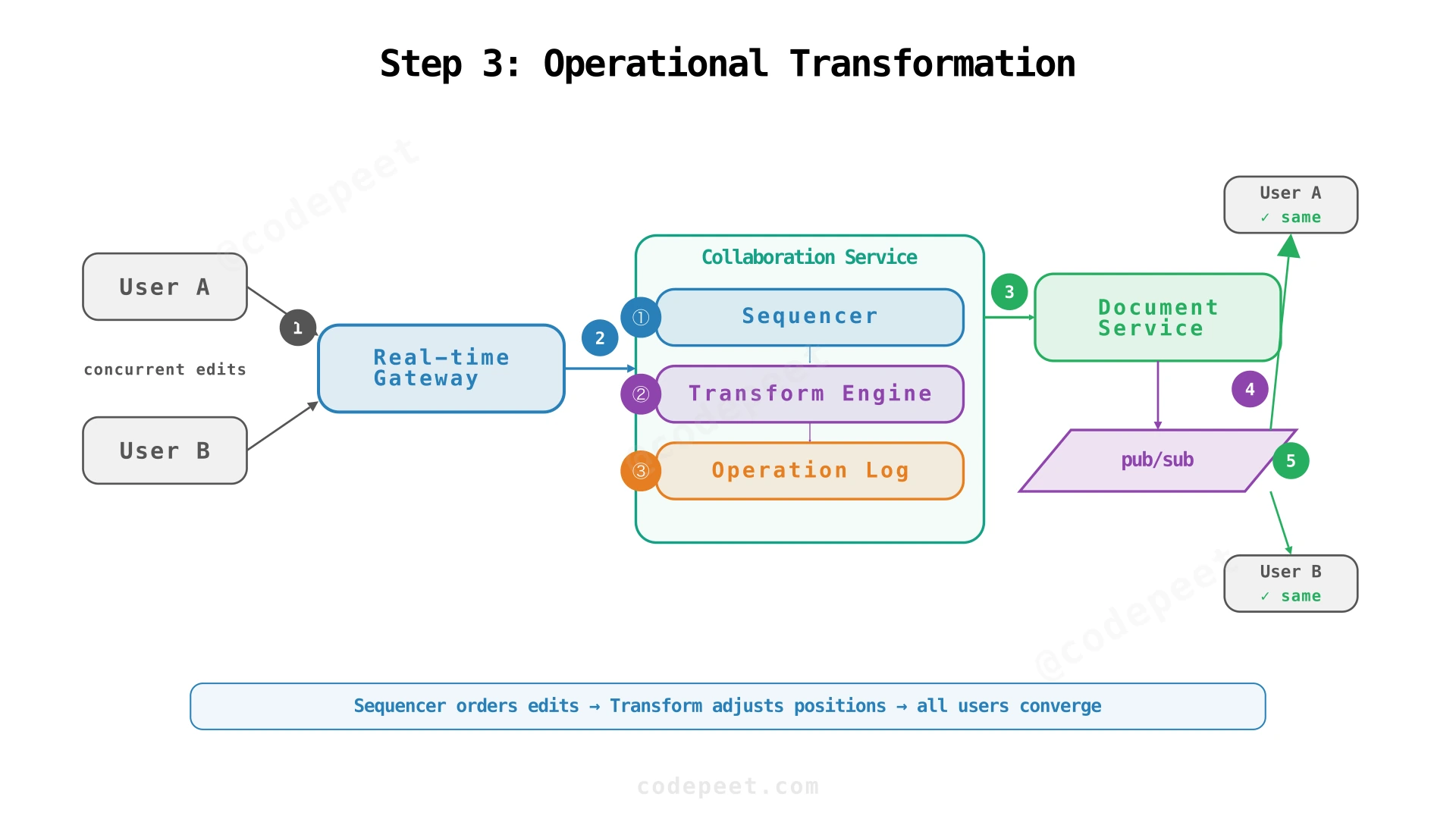
OT Transform Example
With OT, the server transforms Bob's delete to account for Alice's insert:
- Alice's insert at position 6 added 10 characters
- Bob's delete was at positions 6-10, but now those characters shifted right by 10
- Transformed delete: positions 16-20
Both clients end up with: "Hello Beautiful " — converged.
Why OT over CRDTs?
We already have a Collaboration Service in the middle of every edit — a natural ordering point. OT leverages this to keep client logic simple. CRDTs are better for offline-first scenarios (no central server needed), but add metadata complexity to every character.
✅ NFRs addressed: Convergence guaranteed by server-ordered OT, read-your-writes via optimistic local apply
❌ Still missing: No cursor presence (users can't see where others are editing). No permissions. No version history.
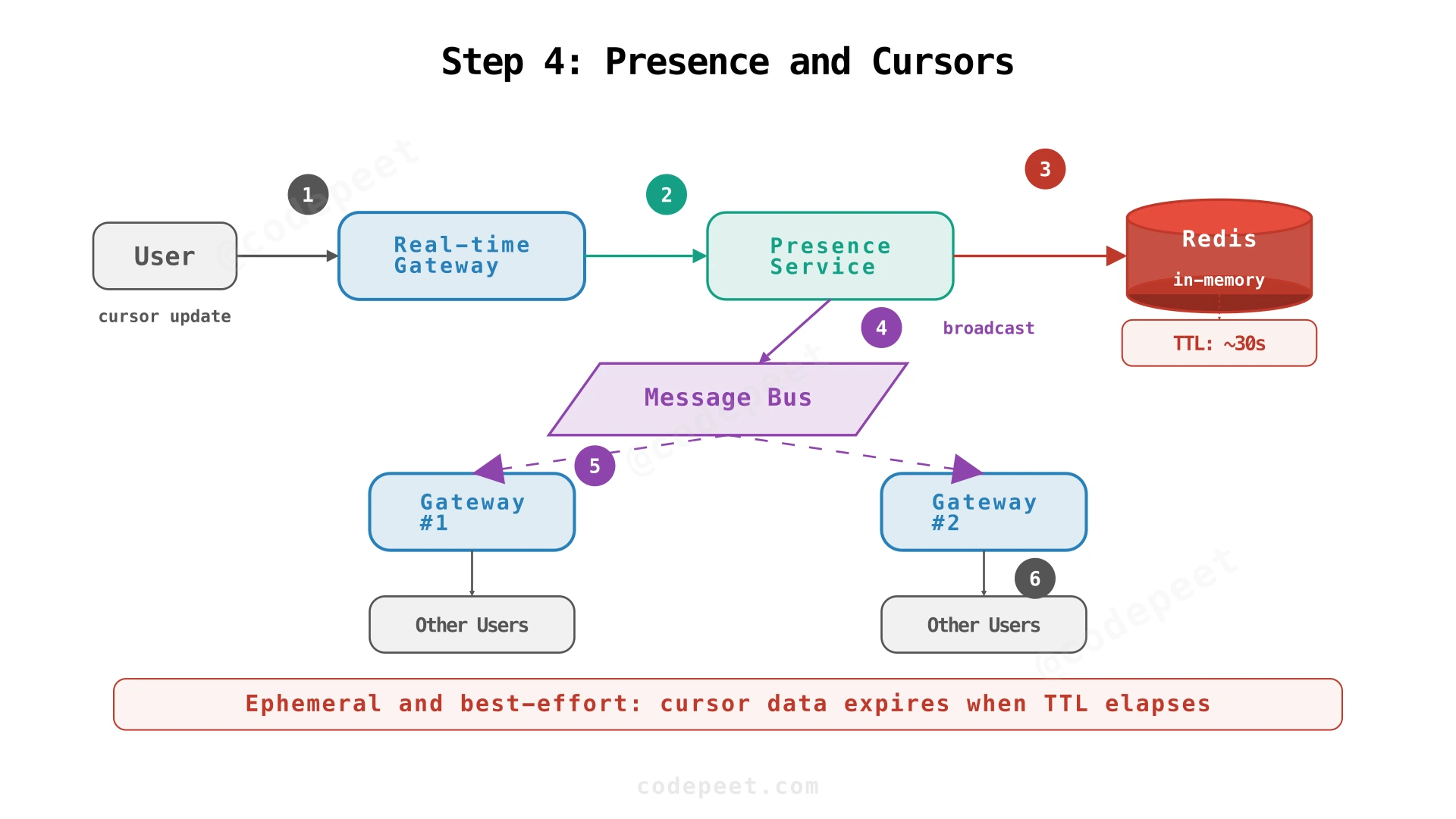
Step 4: Cursor & Selection Presence — Ephemeral State Layer
Presence: Not All Data Deserves Durability
Content syncing is working, but collaboration feels incomplete without seeing where other users are editing. Cursor updates are frequent (every keystroke) and short-lived (meaningless after a user disconnects). Treating them like durable edits wastes resources.
Ephemeral Presence Store
Cursor state lives in an in-memory store (Redis) with TTL-based expiry. If a user's cursor updates stop arriving (disconnect, tab switch), the TTL expires and the cursor disappears from other users' screens. No database write, no cleanup job.
The Flow
- Client sends
presence_updateover WebSocket:{cursor_pos: 42, selection: [42, 50]} - Gateway forwards to the Presence Service
- Presence Service writes to the in-memory store with a 5-second TTL
- Presence Service broadcasts to other collaborators via pub/sub
Throttling and Coalescing
Cursor moves happen on every keystroke — potentially 10+ updates/second per user. To prevent flooding:
- Client-side throttle: batch cursor updates to 4-5/second
- Server-side coalesce: if multiple updates arrive for the same user before broadcast, only send the latest position
Presence is best-effort. Under load, dropping cursor updates is acceptable — the next update will correct the position. This is fundamentally different from edit operations, which must never be dropped.
✅ NFRs addressed: Low-latency presence updates, graceful degradation under load (presence is best-effort)
❌ Still missing: No access control — anyone with the document URL could potentially connect. No version history for recovery.
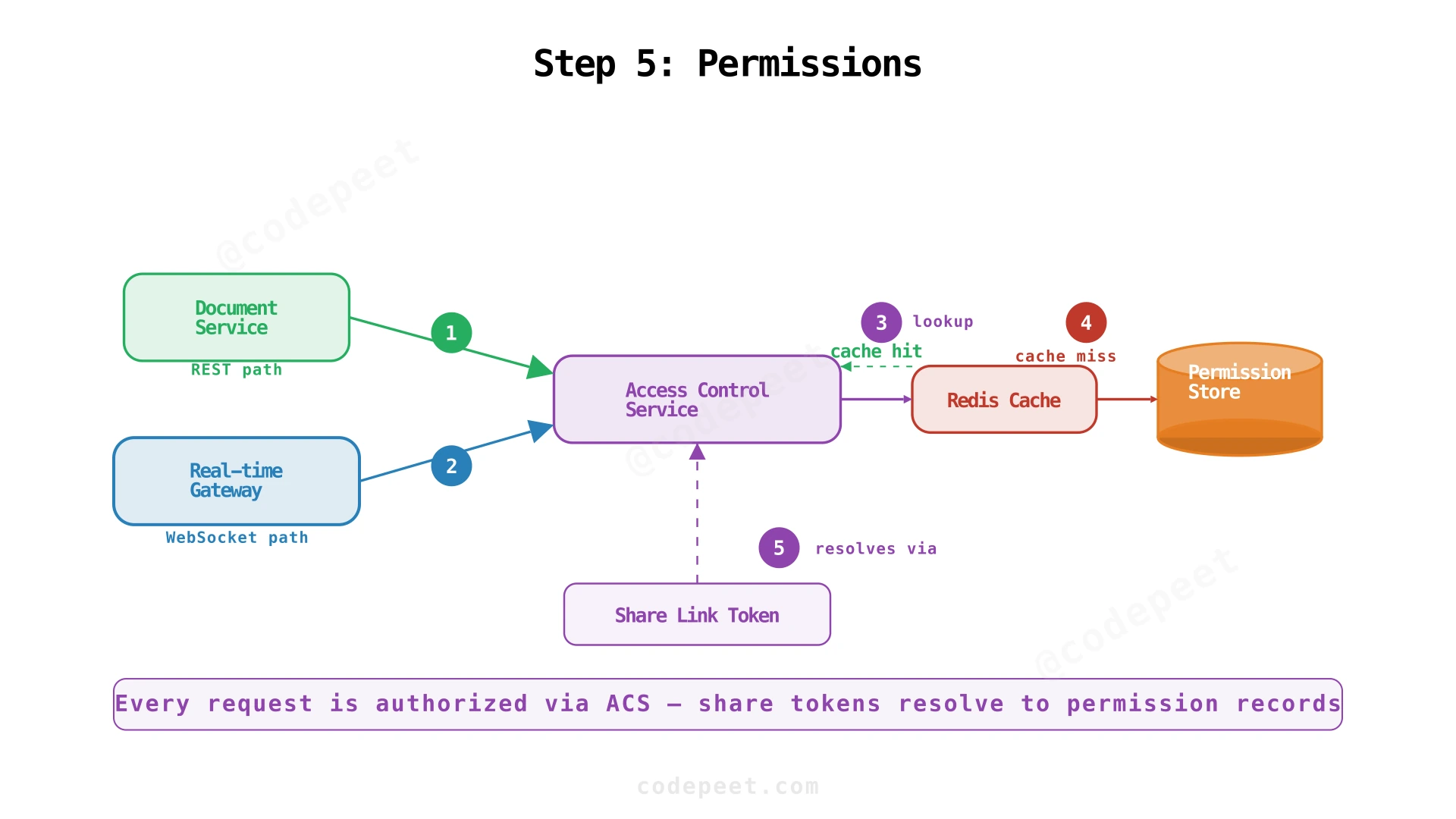
Step 5: Sharing & Permissions — Access Control Service
Securing Every Read and Write
Collaboration only works if access is controlled. Every read and write — including WebSocket messages — must check permissions.
Dedicated Access Control Service
Permissions live in a separate Access Control Service with its own store, rather than embedded in document metadata. This keeps permission checks fast and independent from document reads.
Permission Model
| Role | Read | Edit | Comment | Share | Delete |
|---|---|---|---|---|---|
| Viewer | ✅ | ❌ | ❌ | ❌ | ❌ |
| Commenter | ✅ | ❌ | ✅ | ❌ | ❌ |
| Editor | ✅ | ✅ | ✅ | ❌ | ❌ |
| Owner | ✅ | ✅ | ✅ | ✅ | ✅ |
Permission Checking Points
- Document open (REST): Document Service checks with Access Control Service before returning content
- WebSocket connect: Gateway checks permissions before upgrading the connection
- Edit operation: Collaboration Service verifies the user still has edit access before processing
- Share link: Maps a token → permission record with role and optional expiry
Caching Permissions
Permission checks happen on every operation. To avoid per-operation database queries, cache permission results with a short TTL (30-60 seconds). When permissions change (user revoked), the cache entry expires and the next check fetches the latest state.
✅ NFRs addressed: Security (every read/write is permission-checked), separation of concerns
❌ Still missing: No version history — users can't recover from accidental deletions or see what changed over time.
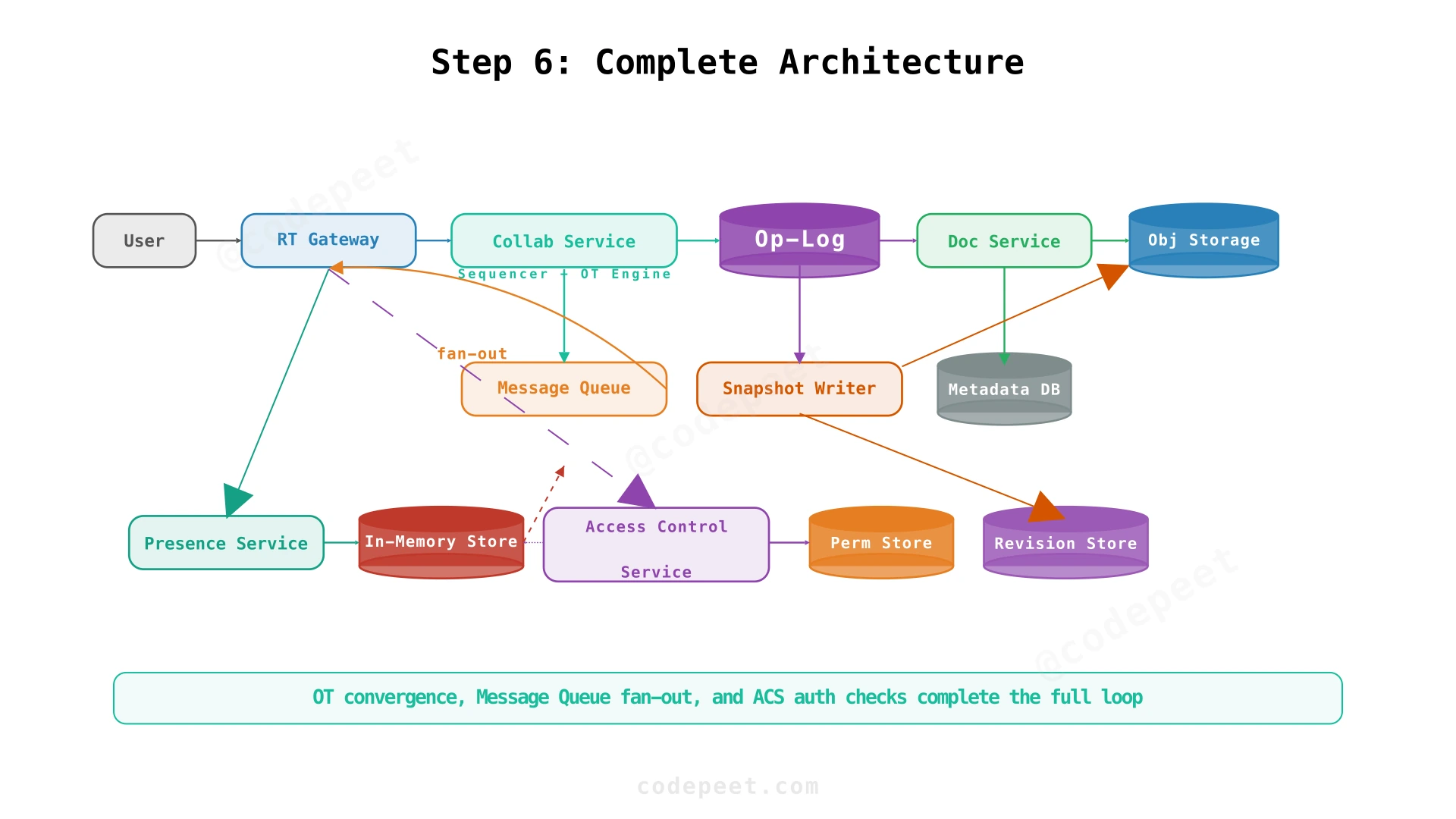
Step 6: Complete Architecture — Version History and Recovery
Adding Revision History and the Final Architecture
The final piece: users need to see what changed and recover from mistakes. Version history requires storing document states over time without exploding storage costs.
Hybrid Snapshots + Deltas
Three approaches, each with a flaw:
- Full snapshots only: fast restore, but 100KB × every edit = massive storage
- Deltas only: storage-efficient, but restoring version #1 of a document with 10,000 edits means replaying all 10,000 operations
- Hybrid (recommended): periodic snapshots (every N operations) with deltas in between
The Snapshot Writer runs as a background process:
- Monitors the Operation Log
- Every ~100 operations, compacts them into a full snapshot
- Writes the snapshot blob to Object Storage
- Creates a Revision record pointing to the snapshot
To restore version V:
- Find the nearest snapshot before V
- Replay deltas from that snapshot to V
- Maximum replay: 99 operations (bounded by snapshot interval)
Compaction and Retention
The Operation Log grows continuously. Compaction merges older operations into snapshots and discards the raw ops. Retention policy: keep all snapshots for 30 days, then downsample to weekly snapshots for the first year, and monthly snapshots thereafter.
NFR Scorecard
| NFR | Target | How It's Met |
|---|---|---|
| Low Latency | <100ms edit propagation | WebSocket for instant delivery; optimistic local apply (client shows own edits immediately); pub/sub for multi-gateway fanout |
| Convergence | All clients reach identical state | Per-document Sequencer assigns total order; OT transforms concurrent ops against each other; Operation Log is the source of truth |
| Read-Your-Writes | Immediate local feedback | Client applies own edits optimistically before server confirmation; server transform may adjust, but user sees their intent instantly |
| High Durability | Zero data loss for content | Operation Log is append-only and replicated; periodic snapshots to Object Storage; hybrid backup ensures bounded recovery time |
| High Availability | 99.99% uptime | Stateless gateway layer scales horizontally; Collaboration Service is sharded per document; Object Storage is inherently highly available |
| Security | Permission on every operation | Access Control Service checks on document open, WebSocket connect, and every edit operation; share link tokens with roles and expiry |
Deep Dives
How do you decide between OT and CRDTs for conflict resolution?
OT vs CRDTs: A Deep Comparison
This is one of the most frequently asked questions in a Google Docs interview. The answer depends on where you want complexity and what your product prioritizes.
Operational Transformation (OT)
A central service orders edits and rewrites (transforms) them so user intent is preserved.
- Server-side complexity, client stays lightweight
- Requires a central sequencer (ordering point)
- Used by: Google Docs (original), Microsoft Office Online
Conflict-free Replicated Data Types (CRDTs)
Each character carries metadata (a unique ID, position markers) so replicas can merge without a central order.
- Client-side complexity, no central coordination needed
- Great for offline-first and peer-to-peer collaboration
- Used by: Figma, Apple Notes, Notion (partial)
| Dimension | OT | CRDTs |
|---|---|---|
| Central server required | Yes (sequencer) | No |
| Client complexity | Low | High (metadata per character) |
| Offline support | Poor (needs server for ordering) | Excellent |
| Convergence guarantee | Server-ordered | Mathematical (commutative operations) |
| Metadata overhead | Low | High (unique IDs per character) |
| Tombstone management | Not needed | Requires garbage collection |
| Correctness proofs | Difficult (transform functions are complex) | Easier (algebraic properties) |
Our Choice: With a centralized Collaboration Service and online-first workflow, OT fits better. We already operate a sequencer — OT leverages it to keep client logic simpler. If offline-first becomes a primary requirement, CRDTs become more attractive despite their metadata overhead.
How do you order operations per document?
Per-Document Sequencer Design
All clients must apply edits in the same sequence. The ordering mechanism is the heart of the collaboration engine.
Three Ordering Strategies
- Client timestamps: Sort by client-provided timestamps. Fails due to clock skew — two clients with 500ms clock difference produce different ordering.
- Global sequencer: One sequencer for all documents. Correct but becomes a bottleneck — every edit across all documents must go through a single point.
- Per-document sequencer (recommended): Each document gets its own independent ordering stream. Correctness is local to a document, and the system scales by sharding documents across sequencer instances.
How It Works
- Client sends operation with
base_revision_id(the last revision it saw) - The sequencer checks: is
base_revision_idthe current head?- Yes: assign next sequence number, append to log
- No: transform the operation against all ops since
base_revision_id, then assign and append
- Broadcast the (possibly transformed) operation to all clients
Sharding
Sequencers are sharded by document_id. A consistent hash ring maps each document to a sequencer instance. If a sequencer instance fails, the document is reassigned to another instance. In-flight operations may need to be replayed from the Operation Log.
class PerDocumentSequencer:
def __init__(self, document_id):
self.document_id = document_id
self.current_seq = 0 # monotonic counter
self.op_log = [] # append-only
def process_operation(self, op, base_revision):
# Find ops that happened since client's base revision
concurrent_ops = [
o for o in self.op_log
if o.seq > base_revision
]
# Transform against each concurrent op
transformed = op
for concurrent in concurrent_ops:
transformed = ot_transform(transformed, concurrent)
# Assign sequence number and persist
self.current_seq += 1
transformed.seq = self.current_seq
self.op_log.append(transformed)
return transformedHow do you scale a hot document with 100+ concurrent editors?
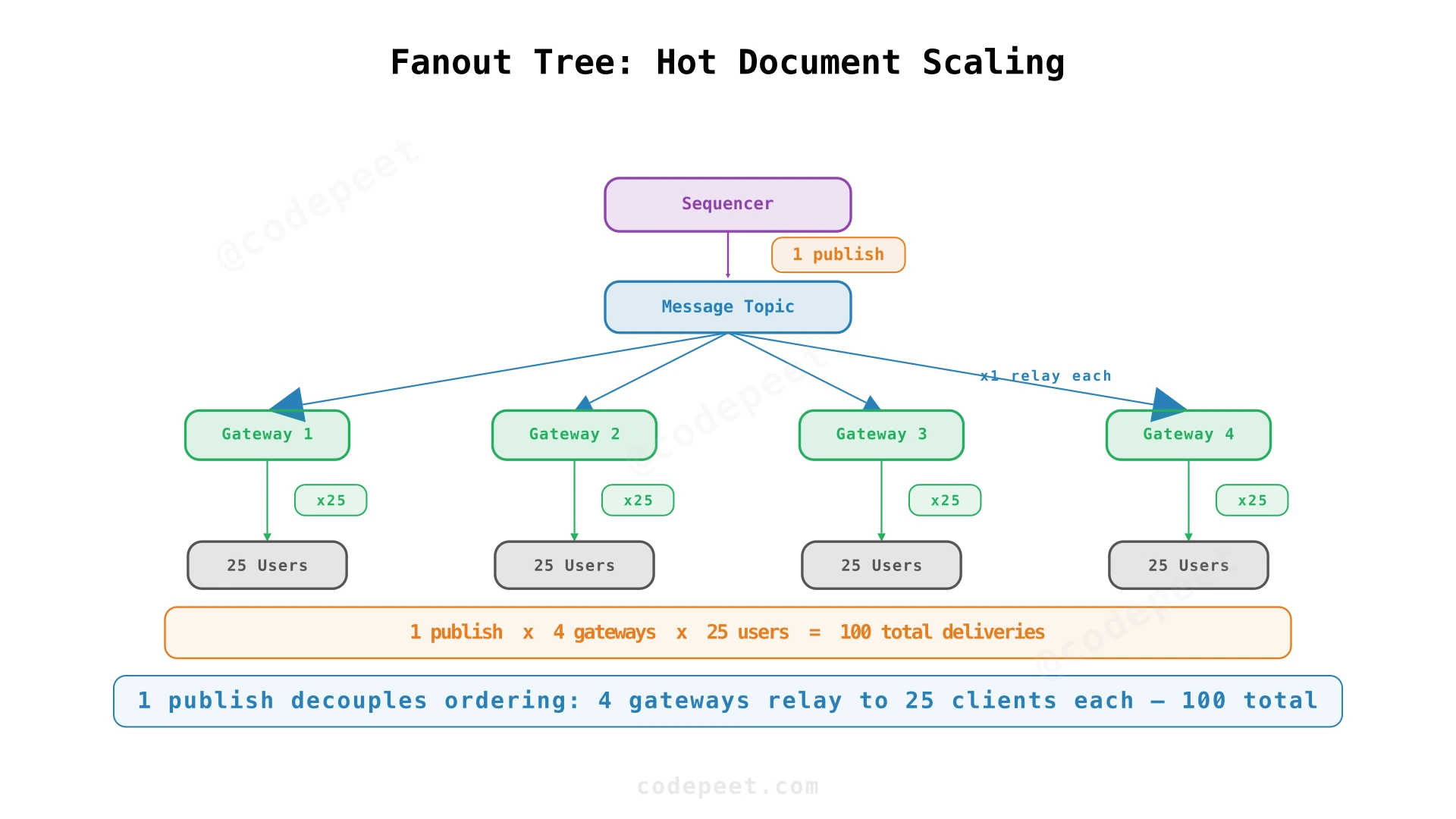
Hot Document Scaling
A single document with 100 concurrent editors creates a fanout hotspot. The sequencer must stay single-threaded per document (for ordering correctness), but it can't also handle 100× fanout for every operation.
The Problem: Fanout Amplification
With 100 editors, each producing ~1 op/sec:
- Sequencer processes 100 ops/sec (manageable)
- But each op must be broadcast to 99 other users
- That's 100 × 99 = 9,900 outbound messages/sec per document
If the sequencer handles fanout directly, it becomes I/O bound on outbound messages rather than the ordering logic.
Solution: Fanout Tree
Separate ordering from delivery:
- The sequencer publishes each ordered operation once to a pub/sub topic
- Multiple gateway nodes subscribe to the topic
- Each gateway relays the operation to its connected clients (a subset of the 100 editors)
- The total fanout is distributed across gateways
If 4 gateway nodes each serve 25 clients, each gateway sends 25 messages per operation — the fanout is parallelized across gateways.
Backpressure
If a gateway is slow (network issue, overloaded), it falls behind on the pub/sub topic. Backpressure ensures the slow gateway doesn't block the sequencer or other gateways. The slow gateway's clients may see a brief delay, but the system continues operating.
How do you store revisions efficiently?
Hybrid Revision Storage
Revision storage balances restore speed vs storage cost:
| Strategy | Storage Cost | Restore Speed | Tradeoff |
|---|---|---|---|
| Full snapshots only | High (100KB × every revision) | Instant | Massive storage for active docs |
| Deltas only | Low (just ops) | Slow (replay all ops) | Version #1 of a 10K-edit doc requires replaying all 10K ops |
| Hybrid (recommended) | Moderate | Bounded | Max replay = snapshot interval |
Snapshot Interval Tuning
The snapshot interval controls the tradeoff:
- Snapshot every 50 ops → max 49 ops to replay, more storage
- Snapshot every 500 ops → max 499 ops to replay, less storage
For a 100KB document, each snapshot costs ~100KB. At 1 edit/sec, a snapshot every 100 ops creates one snapshot every ~2 minutes:
For 1M documents with active edits (10% of total), that's ~8.6 TB/day before retention policies kick in.
Compaction
After creating a snapshot, the operations between the previous snapshot and the new one can be discarded from the live Operation Log. They're already captured in the snapshot. This keeps the Operation Log bounded.
Retention policy: All snapshots for 30 days → weekly snapshots for 1 year → monthly snapshots indefinitely.
How do offline edits reconcile on reconnect?
Offline Reconciliation
Offline editing creates a divergent history. The client has a local branch of operations that the server hasn't seen, while the server has accepted operations from other collaborators that the offline client hasn't seen.
Queue and Rebase Strategy
- While offline, the client queues operations in a local log
- On reconnect, the client sends its
base_revision_id(last known server revision) and all queued operations - The server identifies the divergence point and transforms the client's operations against everything that happened since
- The transformed operations are applied to the server state
- The server sends back the transformed result + all operations the client missed
This is essentially a rebase (like in Git): the client's branch is replayed on top of the server's latest state.
Conflict Copy Fallback
If the offline period was very long (thousands of operations diverged), transformation may produce semantically unexpected results. In this case, create a conflict copy — a separate document with the user's offline changes — and let the user manually merge. This is the same approach Google Docs uses for extended offline periods.
How do you meet low-latency collaboration across regions?
Global Latency and Multi-Region
Collaborators in Tokyo and New York editing the same document face a fundamental constraint: network latency between these regions is ~150ms round-trip. The OT sequencer, which must be a single ordering point per document, can't exist in both regions simultaneously.
Per-Document Home Region
Each document is assigned a home region where its sequencer runs. This is typically the region of the document creator, or can be migrated to the region with the most active editors.
- Users near the home region: connect to a local gateway → edit→ local sequencer → ~10ms round trip
- Users far from the home region: connect to a local gateway → edit forwarded to home region sequencer → ~150ms round trip
The gateway layer is fully distributed — users always connect to their nearest gateway. But the sequencer for their document may be in another region.
Mitigations for Cross-Region Latency
- Optimistic local apply: the client applies its own edits immediately (before server confirmation). The OT transform will adjust if needed, but the user never feels the 150ms delay for their own keystrokes.
- Read replica caching: document snapshots and metadata are replicated to all regions. Opening a document is always fast (local read). Only active editing goes through the home region.
- Home region migration: if all editors move to a different region, migrate the sequencer to reduce latency.
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions for staff+ conversations.
Intent Preservation vs Position Preservation in OT
Context: OT transforms operations to preserve user intent. But what counts as "intent"? If Alice inserts a word at position 10, and Bob deletes the sentence containing position 10, should Alice's inserted word survive in the void, or should it be deleted along with the sentence?
Discussion Points:
- Position-based OT preserves the character's position — the insert survives even if the surrounding context is gone
- Intent-based OT considers the semantic context — if the sentence was deleted, the insert into that sentence should arguably be deleted too
- Google Docs uses position-based OT (simpler, predictable) but this can produce "orphaned" text that seems out of place
- Tree-based CRDTs (like Peritext) can model richer intent by attaching edits to structural elements
- Tradeoff: richer intent preservation requires more complex client logic and more metadata per operation
Operation Log as an Event Sourced System
Context: The Operation Log is already an append-only sequence of events. Can we treat the entire system as event-sourced? The document state is derived by replaying operations from the log. The Revision Store is a materialized view.
Discussion Points:
- The Operation Log is the source of truth. Document state is a projection (materialized view) of the log.
- Snapshots are checkpoints that bound replay time — equivalent to event sourcing snapshots.
- Schema evolution: what happens when the operation format changes? Old operations in the log need to be interpretable by new code (upcasting).
- Exactly-once processing: if the Snapshot Writer crashes mid-compaction, it must resume without creating duplicate snapshots (idempotent processing).
- Retention: the raw Operation Log holds legal liability (every edit with author and timestamp). GDPR compliance may require the ability to delete operations by a specific user.
Zero-Downtime Sequencer Migration
Context: The per-document sequencer is a single point of ordering — not a single point of failure (it can be rebuilt from the Operation Log), but migrating it (e.g., during home region change or load rebalancing) without interrupting active collaboration is non-trivial.
Discussion Points:
- During migration, there's a brief window where the old sequencer is draining and the new sequencer is starting. Operations arriving during this window must not be lost or double-processed.
- Approach 1: Fence the old sequencer (stop accepting new ops), drain in-flight ops, transfer the current sequence number + recent op log to the new instance, then activate.
- Approach 2: Dual-write during migration — both sequencers accept ops, with the new one replaying from the Operation Log to catch up before taking over.
- Client impact: WebSocket connections may need to reconnect to a new gateway route. The client should buffer local ops and replay after reconnection.
- Consensus-based approach: use a Raft group for the sequencer (3 replicas, leader election). Migration becomes a leader transfer. Higher complexity but near-zero downtime.
Level Expectations
| Dimension | |||
|---|---|---|---|
| Requirements | Identify core FRs: create, edit, share documents. Mention real-time streaming. Basic scale numbers. | Define NFRs: convergence vs latency tension, read-your-writes consistency, durability requirements for edits vs ephemeral nature of presence. | Challenge requirements — should offline editing be in scope? Argue for/against CRDTs based on product direction. Identify the Operation Log as an event-sourced audit trail with GDPR implications. |
| High-Level Design | Draw client → service → database. Mention WebSocket for real-time updates. Separate metadata and content storage. | Design the full edit pipeline: WebSocket → Collaboration Service → OT Sequencer → Operation Log → pub/sub fanout. Separate ephemeral presence from durable edits. Permission checks on every path. | Event sourcing with Operation Log. CQRS for read/write model separation. Zero-downtime sequencer migration. Per-document home region with cross-region latency mitigation. |
| Convergence | Mention that concurrent edits could conflict. Suggest some form of conflict resolution. | Explain OT vs CRDTs with concrete tradeoffs. Design the per-document sequencer. Show how the transform function works with an example. | Discuss intent preservation vs position preservation. Analyze OT correctness properties (TP1, TP2). Consider tree-based CRDTs for richer structure. |
| Scalability | Mention load balancing and horizontal scaling. | Design fanout tree for hot documents. Explain operation log compaction. WebSocket connection distribution across gateways. | Cost analysis of snapshot intervals. Geographic sharding of sequencers. Automatic home region migration based on editor distribution. |
| Real-Time | Say "use WebSocket" for live updates. | Explain pub/sub fanout across gateway instances. Design ephemeral presence with TTL. Throttle and coalesce cursor updates. | Analyze cross-region latency impact. Design optimistic local apply with server correction. Graceful degradation under pub/sub backpressure. |
Interview Cheatsheet
Core Architecture in 60 Seconds
"Three coupled paths. The edit path handles low-latency streaming and convergence — WebSocket to gateway, Collaboration Service with per-document sequencer and OT transforms, pub/sub fanout back to all clients. The durability path stores operations in an append-only log and periodically compacts them into snapshots in object storage. The control path enforces permissions on every read/write while keeping cursor presence as ephemeral best-effort state."
"Convergence, not speed, is the hard part. WebSockets make edits fast, but the real challenge is guaranteeing every client sees the same document. The per-document sequencer assigns a total order. OT transforms concurrent operations against each other. The Operation Log is the source of truth."
"Two classes of data. Document content and revision history are correctness-critical — survives any failure. Cursor presence is ephemeral — allowed to drop under load. This durability boundary drives the architecture: persistent Operation Log + Object Storage for edits, in-memory Redis with TTL for presence."
"Version history = snapshot + delta. Periodic snapshots to Object Storage with deltas between them. Restore any version by loading the nearest snapshot and replaying at most N deltas. Compaction keeps the Operation Log bounded."
Key Trade-offs to Mention
| Trade-off | Option A | Option B | When to Choose |
|---|---|---|---|
| Conflict resolution | OT (server-ordered) | CRDTs (peer-to-peer) | OT when you have a central service; CRDTs for offline-first |
| Communication | WebSocket (bidirectional) | SSE (unidirectional) | WebSocket for collaborative editing; SSE for read-only feeds |
| Fanout | Direct broadcast | Pub/sub tree | Direct for single gateway; pub/sub for multi-instance deployment |
| Presence storage | Persistent DB | Ephemeral Redis + TTL | Always ephemeral — presence is not worth the durability cost |
| Revision storage | Full snapshots | Deltas only | Hybrid — periodic snapshots with deltas between them |
| Sequencer scope | Global (all docs) | Per-document | Per-document — decouples documents, scales horizontally |
| Permission caching | No cache (always check) | Short-TTL cache | Cache with 30-60s TTL — permission changes are infrequent |
Common Mistakes to Avoid
- ❌ Optimizing for transport speed before proving correctness — WebSocket is fast but convergence under concurrent writes is the actual hard problem
- ❌ Treating presence and edits with equal durability — cursor state is ephemeral and safe to drop; edits must never be lost
- ❌ Using a global sequencer for all documents — creates a bottleneck that limits total system throughput to one ordering point
- ❌ Storing full snapshots for every edit — storage explodes; use hybrid snapshot + delta approach
- ❌ Forgetting permission checks on the WebSocket path — REST endpoints check permissions but the real-time channel bypasses them
- ❌ Ignoring cross-region latency — optimistic local apply masks it for the user's own keystrokes but other users' edits still have ~150ms delay