webhook
Introduction
A webhook is a user-defined HTTP callback. When an event occurs in System A, it sends an HTTP POST request to a pre-configured URL in System B — delivering the event data instantly, without System B ever asking for it. This "don't call us, we'll call you" model is the backbone of real-time integrations across the modern web.
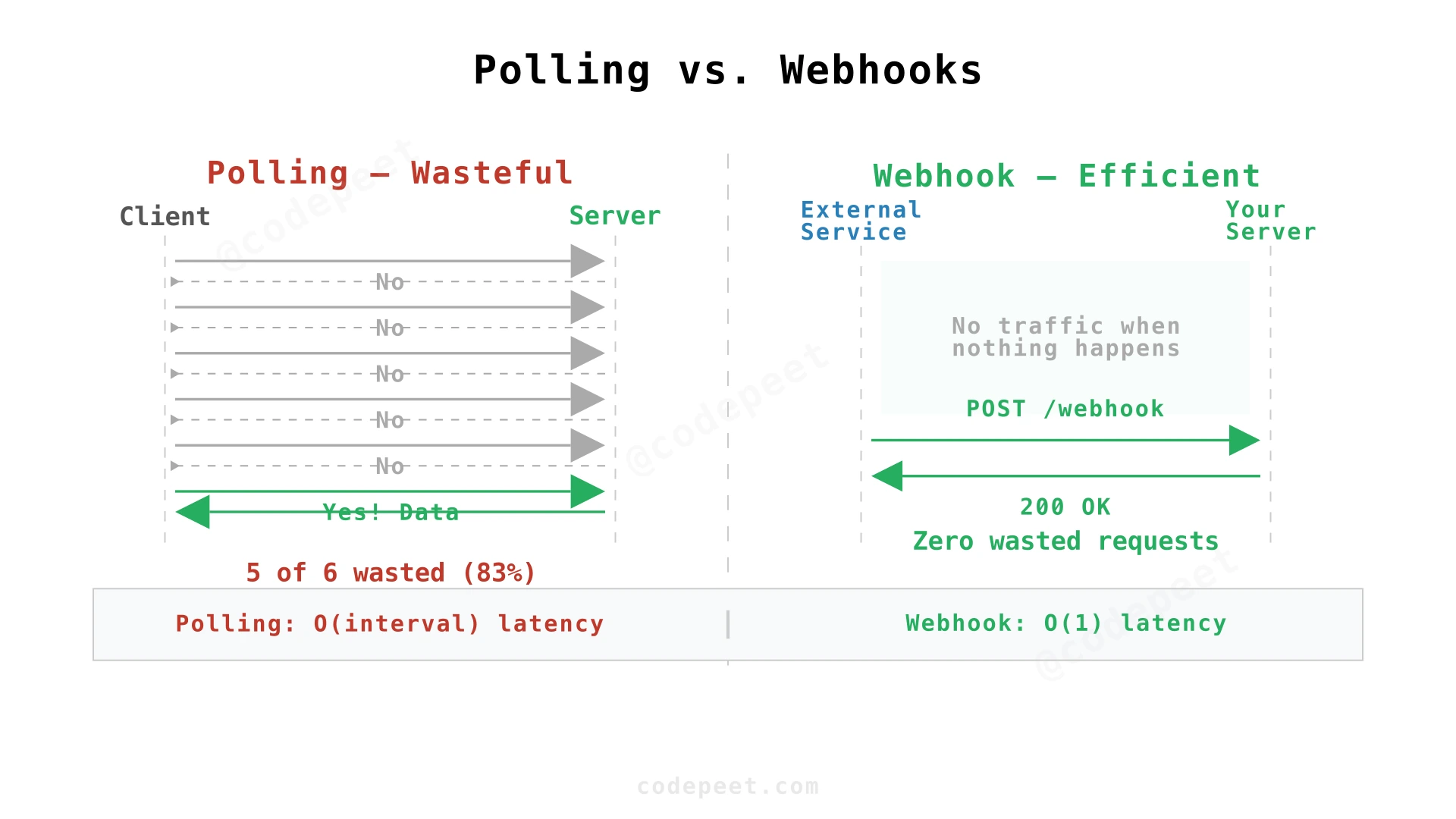
Polling vs. Webhooks — a fundamental trade-off:
| Approach | How It Works | Latency | Efficiency | Complexity |
|---|---|---|---|---|
| Polling | Client repeatedly asks "anything new?" at fixed intervals | Interval-bound (seconds to minutes) | Wasteful — 95%+ of requests return empty | Simple client, simple server |
| Long Polling | Client holds an open request; server responds when event occurs | Near real-time | Better than polling, but ties up connections | Moderate (connection management) |
| Webhooks | Server pushes event to client's URL when it happens | Real-time (milliseconds) | Optimal — zero wasted requests | Client must expose an endpoint |
Webhooks are used everywhere:
- Stripe sends
payment_intent.succeededwhen a charge completes - GitHub sends
pushevents when code is committed to a repository - Shopify sends
orders/createwhen a customer places an order - Twilio sends delivery receipts when an SMS is delivered
In each case, the provider (Stripe, GitHub) makes an HTTP POST to your server with event data. Your server processes the event and returns 200 OK. If your server fails to respond, the provider retries — typically with exponential backoff.
The engineering challenge is deceptively simple on the surface but hides real complexity:
- Reliability — What happens when your server is down? Events must not be lost.
- Idempotency — Retries mean the same event may arrive multiple times. Processing it twice would be catastrophic (e.g., charging a customer twice).
- Security — Anyone can send a POST request to your endpoint. How do you verify it came from the real provider and wasn't forged by an attacker?
- Ordering — Events may arrive out of order. An
invoice.paidevent might arrive beforeinvoice.created. - Throughput — During flash sales or viral events, webhook volume can spike 5-10× normal. Your handler must absorb the burst without dropping events.
LLD Connection: This problem connects to the Message Queue Low-Level Design, where you implement the producer-consumer pattern that decouples event ingestion from processing.
Functional Requirements
We extract the core operations from the problem statement:
- "receive" event notifications → ACCEPT incoming HTTP requests
- "execute" corresponding operations → PROCESS event payload
- "persist" original data and results → STORE for auditing/debugging
- "ensure" events are processed even when components fail → GUARANTEE at-least-once delivery
FR1 — Accept Event Notifications. The service exposes a webhook endpoint that receives HTTP POST requests from external providers (e.g., Stripe, GitHub, Shopify). Each request contains an event payload describing what happened. The service validates the request authenticity, acknowledges receipt immediately with 200 OK, and enqueues the event for asynchronous processing.
FR2 — Process Events Reliably. Each accepted event is processed exactly according to its type — updating records, triggering workflows, or notifying downstream systems. The original event data and processing results are persisted for tracking, auditing, and debugging. If any component fails mid-processing, the event is retried automatically until it succeeds or is moved to a dead letter queue for manual investigation.
- Webhook registration/subscription management — How providers register callback URLs (handled by provider's API)
- Outbound webhook delivery — Sending webhooks to external consumers (inverse problem)
- Business logic implementation — What happens after events are processed (domain-specific)
- Authentication/authorization — User identity management
Scale Requirements
| Metric | Value |
|---|---|
| Event volume | 1,000,000 events per day |
| Average event size | ~5 KB |
| Peak traffic multiplier | 5× normal (during flash sales, releases) |
| Latency target | < 200 ms end-to-end (event arrival → processing complete) |
| Data retention | 30 days for all events |
| Delivery guarantee | At-least-once processing |
Non-Functional Requirements
| Requirement | Target | Rationale |
|---|---|---|
| High Availability | 99.9% uptime | Missing events from Stripe = missed payments = revenue loss |
| Low Latency | < 200 ms end-to-end | Events must be processed before external provider times out (~5-30 sec) |
| At-Least-Once Processing | Zero event loss after acceptance | If we return 200 OK, we committed to processing the event |
| Idempotency | Duplicate events produce same result | Network retries from providers will send duplicates; processing twice = data corruption |
| Security | Verify event authenticity | Open endpoint is an attack surface; must validate HMAC signatures |
| Durability | 30-day event retention | Audit trail for debugging, compliance, and dispute resolution |
The critical insight: returning 200 OK is a contract. When we return 200, we tell the external provider "we received your event and will process it." If we lose the event after acknowledging it, the provider won't retry — and the event is gone forever. This is why at-least-once processing after acknowledgment is the most important non-functional requirement.
Resource Estimation
Traffic Estimation
| Metric | Normal | Peak (5×) |
|---|---|---|
| Events per day | 1,000,000 | 5,000,000 |
| Events per second (avg) | ~12/sec | ~58/sec |
| Events per second (peak burst) | ~58/sec | ~290/sec |
With 1M events/day: 1,000,000 / 86,400 ≈ 11.6 events/sec average.
Peak hours concentrate ~40% of daily traffic in 8 hours: 400,000 / 28,800 ≈ 14/sec normal peak.
Flash sale bursts (5× multiplier): 14 × 5 ≈ 70/sec sustained, with micro-bursts up to 290/sec.
Storage Estimation
| Data | Calculation | Result |
|---|---|---|
| Daily event storage | 1M events × 5 KB | 5 GB/day |
| 30-day retention | 5 GB × 30 | 150 GB |
| Processing results | ~1 KB per event × 1M × 30 | ~30 GB |
| Total storage (with overhead) | ~180 GB × 1.3 | ~235 GB |
Infrastructure Estimation
| Component | Requirement |
|---|---|
| Request handlers | 3+ instances behind load balancer (each handles ~100 req/sec) |
| Message queue | Managed service (SQS/Kafka) with replication |
| Queue consumers | 3-5 instances (each processes ~20 events/sec with DB writes) |
| Database | PostgreSQL with read replica, ~235 GB disk |
The system is I/O-bound, not CPU-bound — most time is spent waiting on network (receiving HTTP) and disk (writing to database). This means we can handle high throughput with relatively few compute instances.
Data Model
The data model captures two key entities: the raw event received from the provider and the processing result produced by our system.
CREATE TABLE webhook_events (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
event_id VARCHAR(255) UNIQUE NOT NULL, -- Provider's unique event identifier (idempotency key)
event_type VARCHAR(100) NOT NULL, -- e.g., 'payment_intent.succeeded', 'order.created'
provider VARCHAR(50) NOT NULL, -- e.g., 'stripe', 'github', 'shopify'
payload JSONB NOT NULL, -- Raw event payload from provider
headers JSONB, -- Original HTTP headers (for debugging)
signature VARCHAR(512), -- HMAC signature from provider
received_at TIMESTAMP DEFAULT NOW(), -- When we received the event
status VARCHAR(20) DEFAULT 'pending', -- pending, processing, completed, failed, dead_letter
retry_count INTEGER DEFAULT 0,
last_error TEXT, -- Last processing error message
processed_at TIMESTAMP, -- When processing completed
expires_at TIMESTAMP DEFAULT NOW() + INTERVAL '30 days' -- TTL for retention policy
);
CREATE INDEX idx_events_event_id ON webhook_events(event_id); -- Fast idempotency lookup
CREATE INDEX idx_events_status ON webhook_events(status) WHERE status != 'completed'; -- Partial index for pending events
CREATE INDEX idx_events_provider_type ON webhook_events(provider, event_type); -- Filter by provider/type
CREATE INDEX idx_events_expires ON webhook_events(expires_at); -- TTL cleanup job
CREATE TABLE processing_results (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
event_id VARCHAR(255) REFERENCES webhook_events(event_id),
action_taken VARCHAR(200) NOT NULL, -- e.g., 'updated_payment_status', 'created_order'
result_data JSONB, -- Processing output details
duration_ms INTEGER, -- Processing time in milliseconds
created_at TIMESTAMP DEFAULT NOW()
);Key design decisions:
event_idas idempotency key: The provider's unique event identifier (e.g., Stripe'sevt_1MqLSbK...) is stored with a UNIQUE constraint. Before processing, we check if thisevent_idalready exists — if so, we skip processing and return success.JSONBfor payload: Events from different providers have different schemas. JSONB stores the raw payload without requiring a fixed schema, while still allowing efficient queries with GIN indexes.- Partial index on status: The
WHERE status != 'completed'clause means the index only covers pending/failed events — a small fraction of total rows. Queries for "events that need processing" are fast without indexing all 30M completed events. - TTL with
expires_at: A background job runs daily to delete events whereexpires_at < NOW(), enforcing the 30-day retention policy.
API Endpoints
The webhook service exposes a single inbound endpoint. External providers send events to this URL.
Receive Webhook Event
POST /webhook
Request Headers:
Content-Type: application/json
X-Webhook-Signature: sha256=5d7f3c8a1b... -- HMAC signature for verification
X-Webhook-Timestamp: 1710691200 -- Unix timestamp to prevent replay attacks
X-Event-Id: evt_1MqLSbKJFk9d2k -- Provider's unique event identifier
Request Body:
{
"event_id": "evt_1MqLSbKJFk9d2k",
"event_type": "payment_intent.succeeded",
"created_at": "2026-03-17T10:00:00Z",
"data": {
"object": {
"id": "pi_3MqLSbKJFk9d2k",
"amount": 5000,
"currency": "usd",
"status": "succeeded",
"customer": "cus_NffrFeUfNV2Hib"
}
}
}
Response (Success — 200 OK):
{
"status": "accepted",
"event_id": "evt_1MqLSbKJFk9d2k"
}
Response (Duplicate — 200 OK):
{
"status": "already_processed",
"event_id": "evt_1MqLSbKJFk9d2k"
}
Response (Invalid Signature — 401 Unauthorized):
{
"error": "invalid_signature",
"message": "HMAC signature verification failed"
}
| Status Code | Meaning |
|---|---|
200 OK | Event accepted and queued for processing |
401 Unauthorized | HMAC signature verification failed |
429 Too Many Requests | Rate limit exceeded |
500 Internal Server Error | Server failure — provider should retry |
Why always return 200 for duplicates? If the provider sent the same event twice (due to their retry logic) and we already processed it, returning 200 tells them "we've got it, stop retrying." Returning an error would cause them to keep retrying indefinitely.
Internal Endpoints (for monitoring/debugging)
GET /events/:event_id/status
Returns processing status, retry count, and result data for a specific event. Used by internal dashboards for debugging — not exposed to external providers.
High Level Design
We build the architecture incrementally, starting from the simplest possible design and evolving it as we discover problems that need solving.
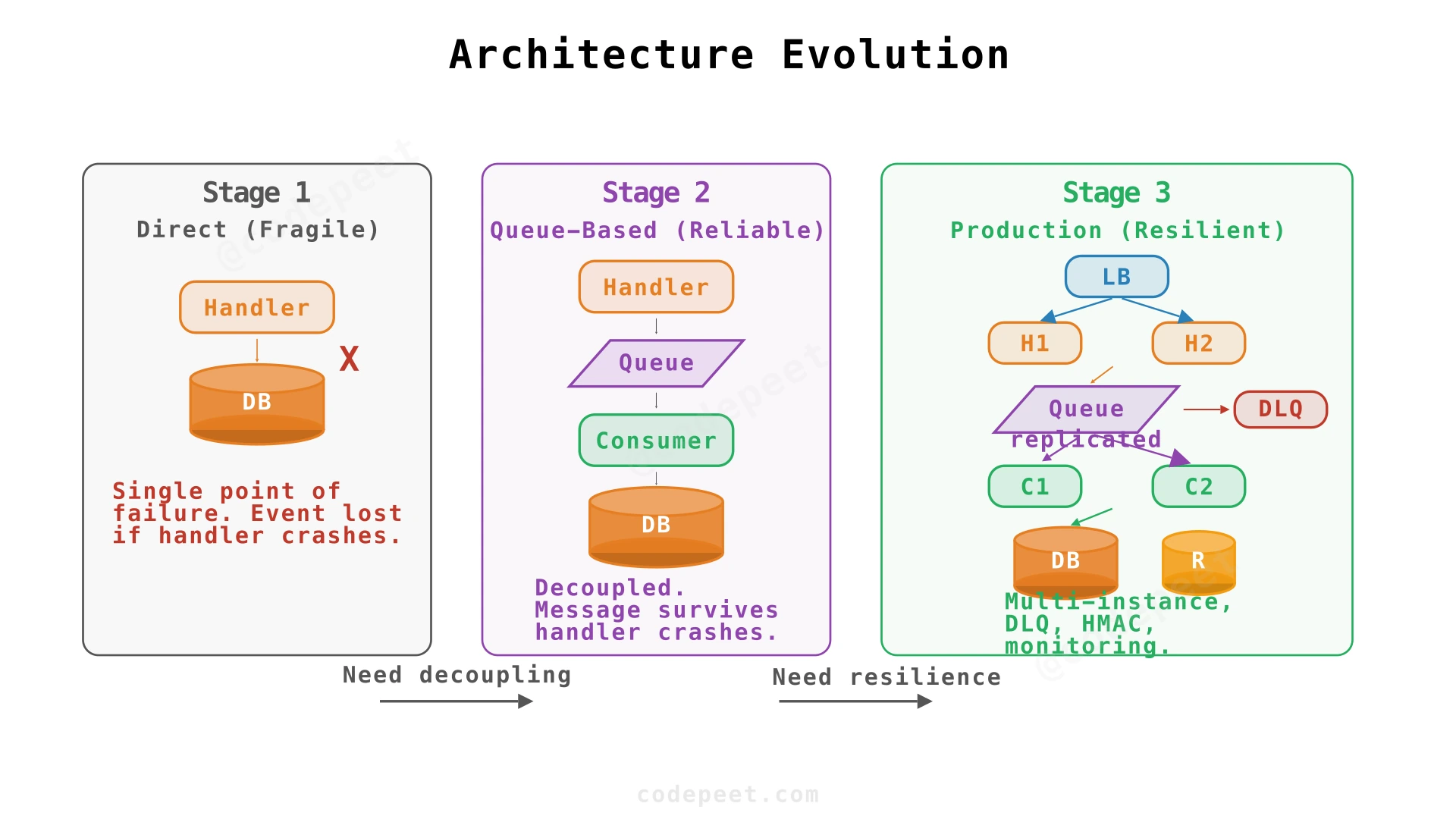
1. Basic Design — Direct Processing
Starting point: The most straightforward approach is a single service that receives the HTTP request, processes the event, writes to the database, and returns 200 OK.
The request handler does everything: validate the request, execute business logic (e.g., update payment status), write to the database, and respond.
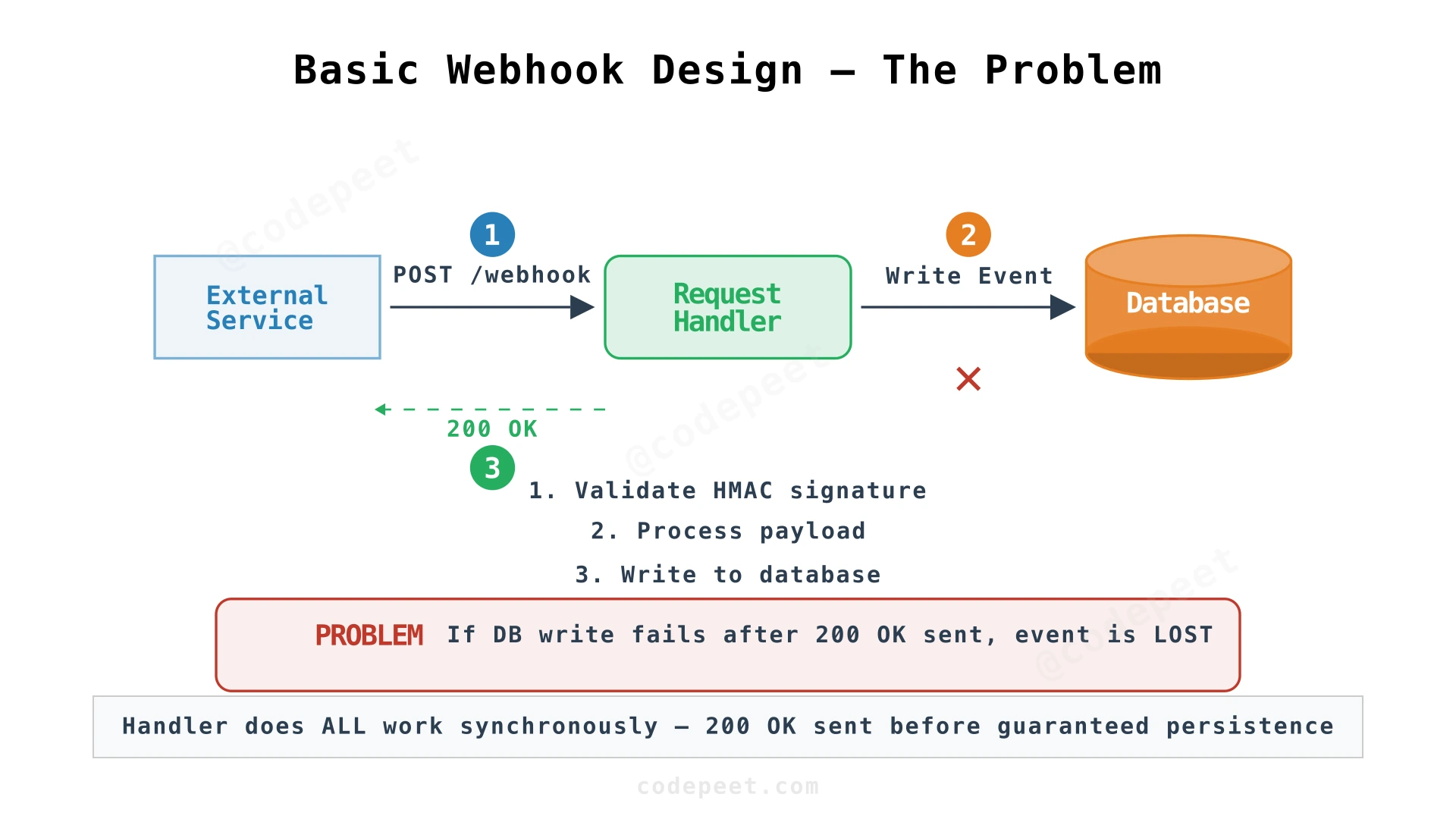
The critical flaw: The request handler has too many responsibilities — HTTP handling, business logic, database writes. If it crashes after processing but before the database write succeeds, the event is lost. Worse, if the handler is slow (heavy business logic), it blocks the HTTP response. External providers typically have aggressive timeouts (5-30 seconds). If we don't respond fast enough, the provider considers the delivery failed and retries — even though we might have already processed the event.
We need to separate concerns: accept the event quickly, then process it asynchronously.
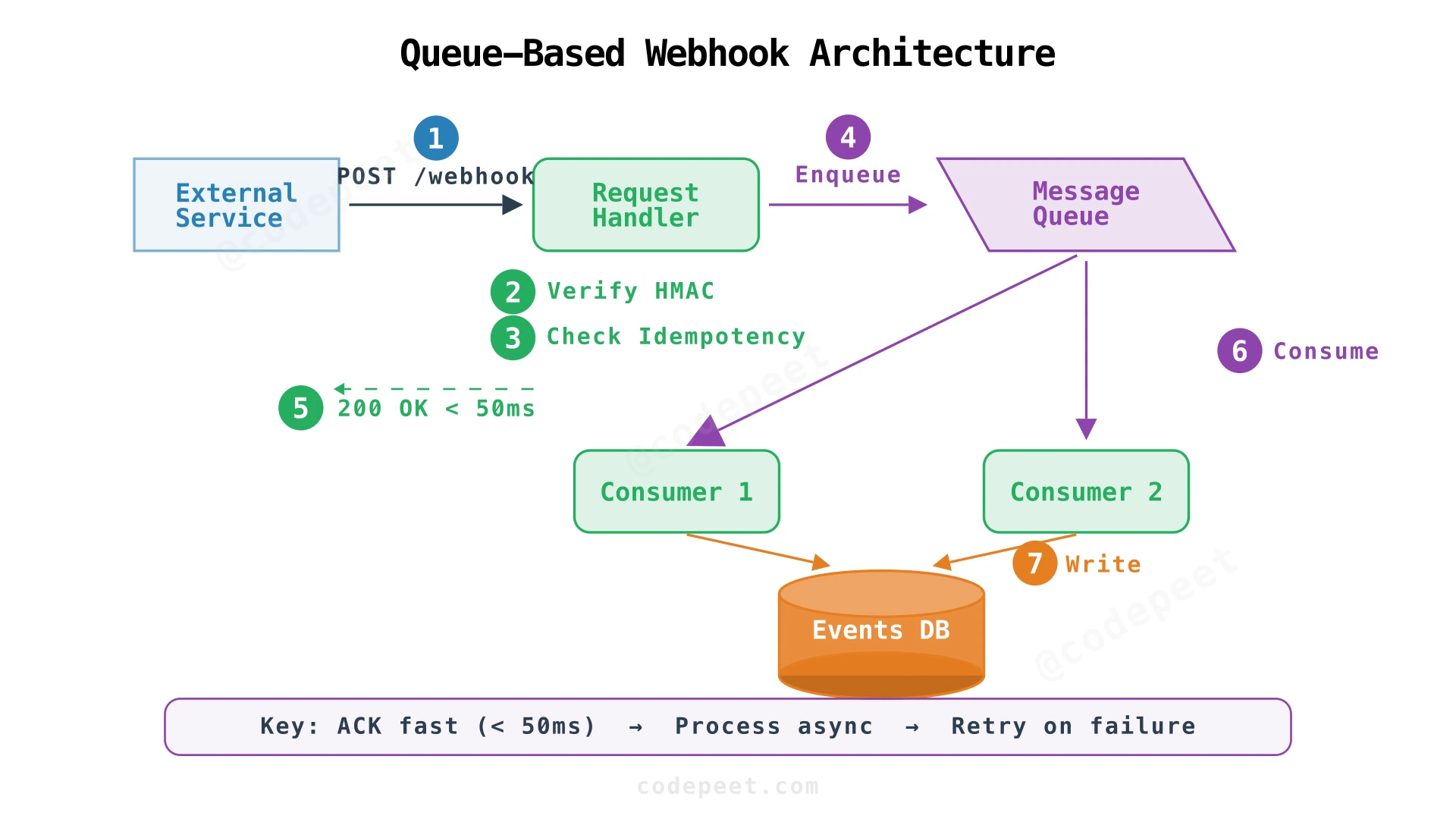
2. Message Queue for Reliability and Decoupling
The solution is a classic producer-consumer pattern with a message queue:
- Request Handler (producer): Receives HTTP, validates, enqueues event, returns
200 OK - Message Queue (buffer): Durably stores events until consumed
- Queue Consumer (consumer): Pulls events, processes them, writes results to database
This separation gives us three critical properties:
| Property | How the Queue Provides It |
|---|---|
| Fast acknowledgment | Handler returns 200 OK immediately after enqueue (~10 ms), not after processing (~200 ms) |
| Failure recovery | If a consumer crashes, the message stays in the queue and another consumer picks it up |
| Load buffering | During a 5× traffic spike, the queue absorbs the burst; consumers drain at their own pace |
Request Flow — Step by Step
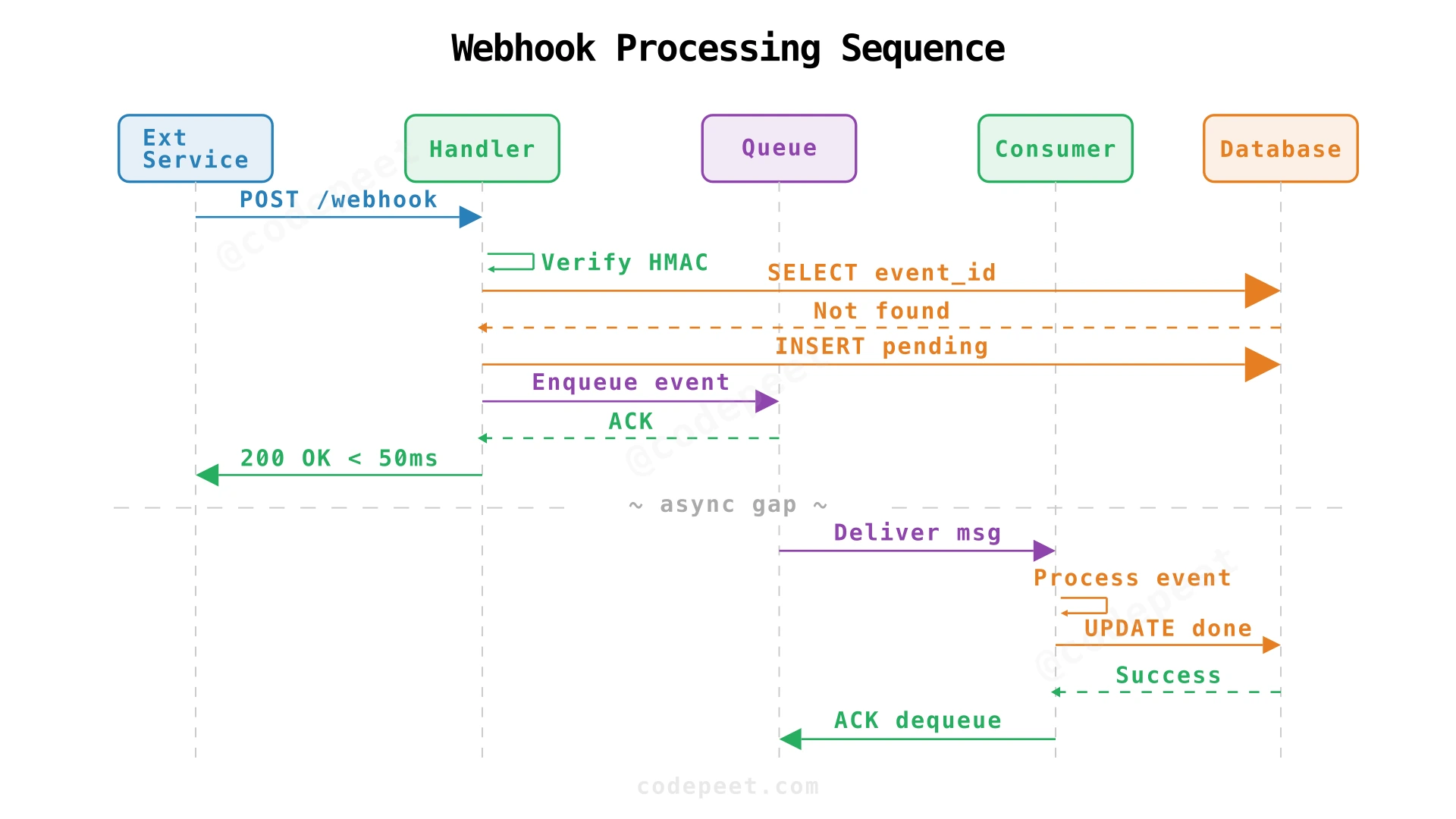
Step 1 — Event arrives. Stripe sends POST /webhook with event payload and HMAC signature in headers.
Step 2 — Signature verification. The handler computes HMAC-SHA256 over the request body using the shared secret key. If the computed hash doesn't match the signature in the header, return 401 Unauthorized.
Step 3 — Idempotency check. Query the database: does an event with this event_id already exist? If yes, return 200 OK with status: "already_processed". No further action needed.
Step 4 — Persist event record. Insert a new row in webhook_events with status: 'pending'. This creates the audit trail immediately.
Step 5 — Enqueue for processing. Push the event to the message queue. The queue durably stores the message.
Step 6 — Acknowledge to provider. Return 200 OK. Total time: ~10-50 ms. The provider knows we received the event.
Step 7 — Consumer processes event. A queue consumer pulls the message, executes the business logic (e.g., update payment status, trigger email), and writes the result to the database.
Step 8 — Acknowledge to queue. Only after the database write succeeds does the consumer ACK the message. If the consumer crashes before ACK, the message becomes visible again after a visibility timeout, and another consumer retries it.
This is the key reliability guarantee: The message stays in the queue until we prove (via database write + ACK) that processing succeeded. No event loss is possible after step 6.
3. Handling Failures at Every Layer
Each component in the pipeline can fail. The architecture must handle every failure mode without losing events.
Request Handler Failures
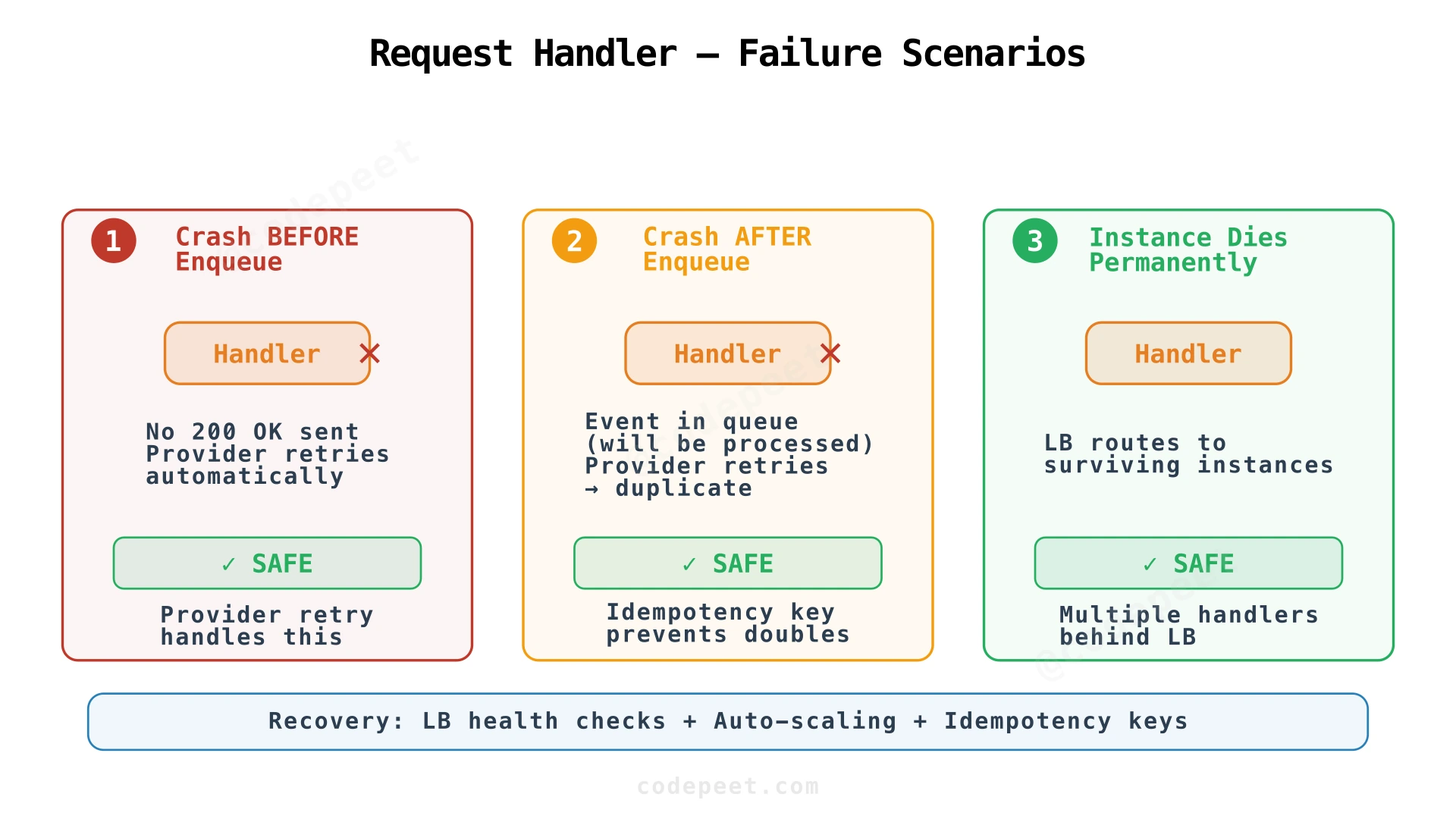
Before enqueue: If the handler crashes before enqueuing and returning 200 OK, the external provider never receives acknowledgment. The provider retries the delivery (typically 3-5 times with exponential backoff). Since we never saved the event, the retry is a fresh delivery — no data loss.
After enqueue, before response: The event is safely in the queue, but the provider didn't receive 200 OK. The provider retries and sends the event again. Our idempotency check catches the duplicate — the event_id already exists in the database — and we return 200 OK without reprocessing.
Message Queue Failures
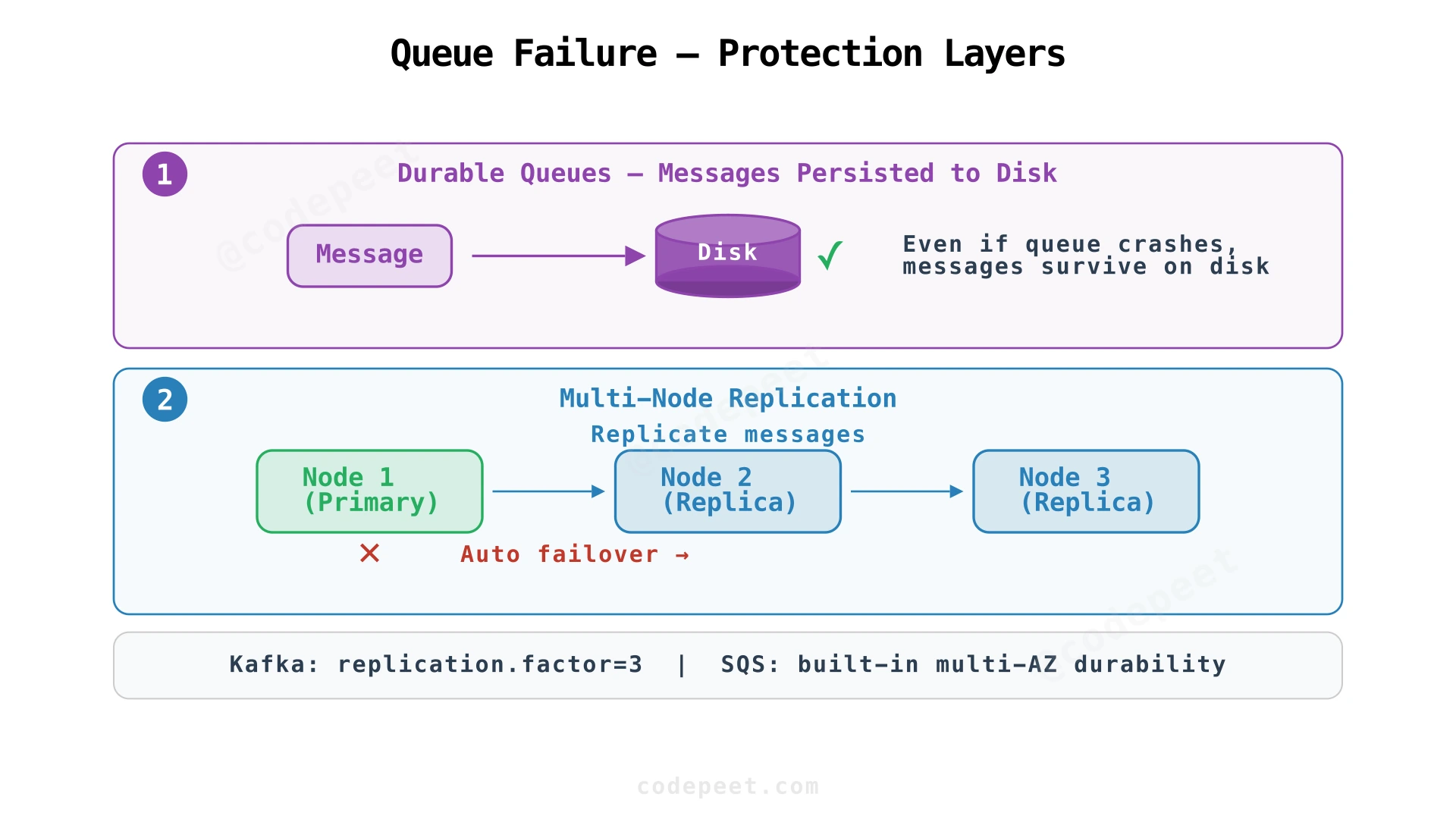
Durable queues persist messages to disk, surviving process crashes. Multi-node replication (Kafka's replication.factor=3, or SQS's built-in multi-AZ) ensures that even if an entire server dies, messages are preserved on other nodes.
Queue Consumer Failures
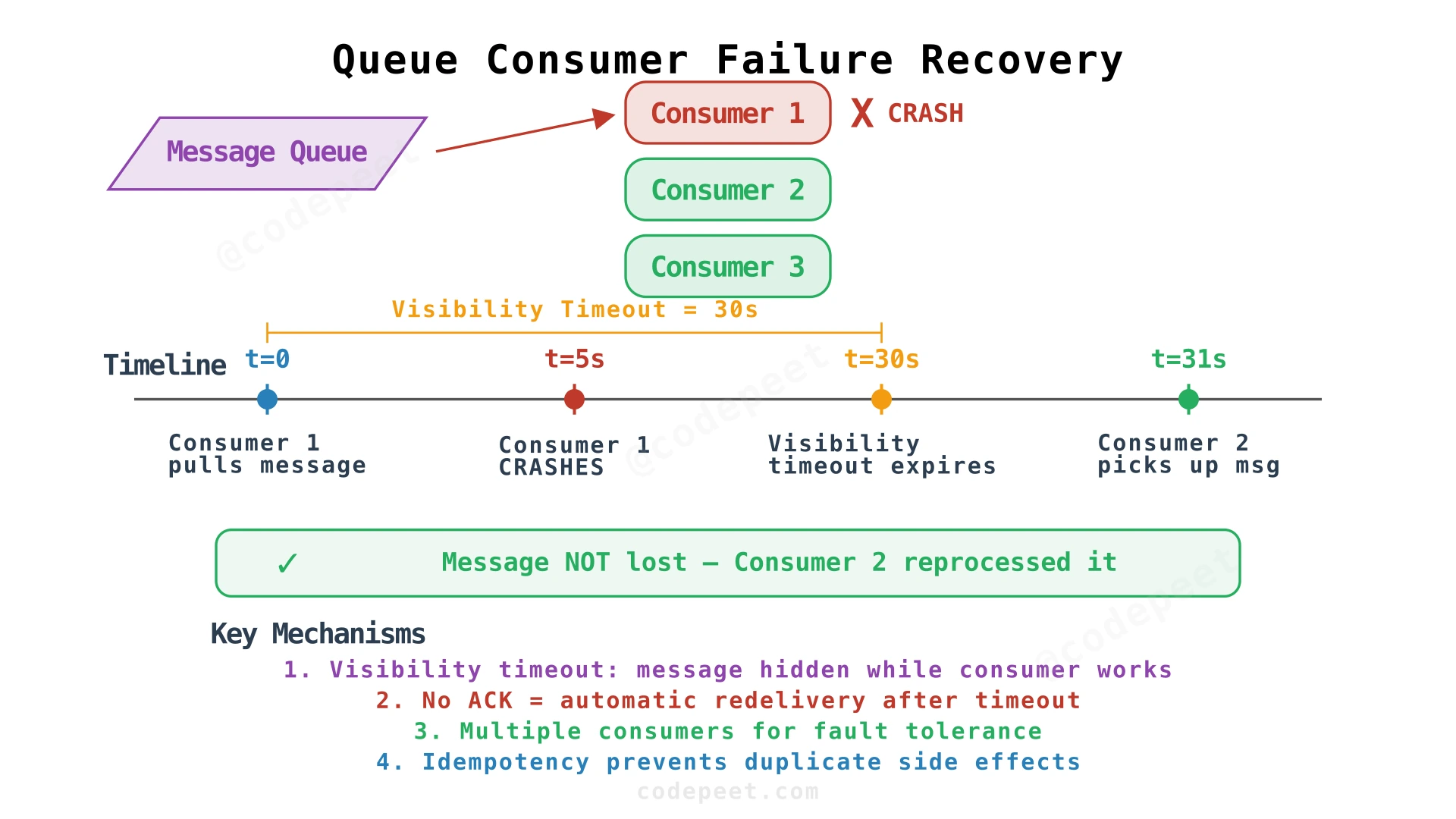
The message queue uses a visibility timeout mechanism. When a consumer pulls a message, the message becomes invisible to other consumers for a configured period (e.g., 30 seconds). If the consumer successfully processes the event and ACKs within this window, the message is permanently deleted. If the consumer crashes, the visibility timeout expires and the message reappears — allowing another consumer to pick it up.
This is why consumer-side idempotency is critical. The same event may be delivered to multiple consumers (if the first consumer was slow or crashed). Each consumer must check the event_id before executing business logic to avoid duplicate processing.
Database Failures
Database failures are handled with standard resilience patterns:
- Write retries with exponential backoff — If the first write fails, retry after 100 ms, then 200 ms, 400 ms, etc. Most transient failures (connection timeout, deadlock) resolve within a few retries.
- Database replication with automatic failover — A standby replica promotes to primary if the primary fails. The application reconnects to the new primary within seconds.
- Consumer waits for DB recovery — If the database is down for an extended period, the consumer stops ACKing messages. Messages accumulate in the queue (which has much higher capacity than the DB). When the database recovers, consumers drain the backlog.
4. Complete Architecture
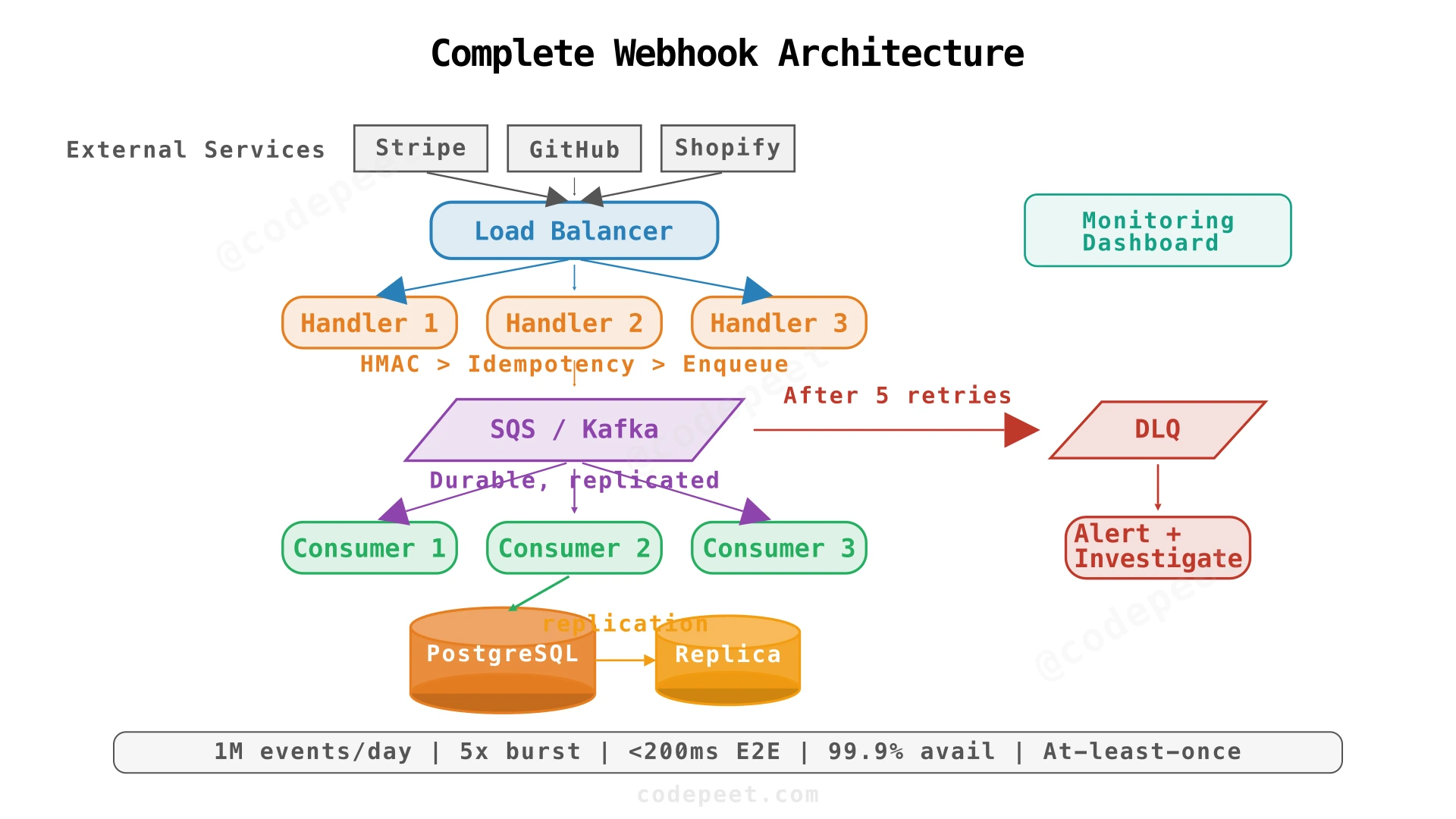
Component Ownership & Scaling
| Component | Responsibility | Scaling Strategy | Failure Mode |
|---|---|---|---|
| Load Balancer | Route requests, health checks | Managed (ALB/NLB) | Multi-AZ automatic |
| Request Handlers | HMAC verification, idempotency check, enqueue | Horizontal (add instances) | LB routes away from dead instances |
| Message Queue | Durable event buffering | Managed (SQS/Kafka) | Multi-AZ replication |
| Queue Consumers | Event processing, DB writes | Horizontal (add consumers) | Visibility timeout + redelivery |
| Database | Event & result storage | Vertical + read replicas | Automatic failover to standby |
| Dead Letter Queue | Capture poison messages | Same as main queue | Alert + manual investigation |
Dead Letter Queue (DLQ)
After a configurable number of retry attempts (e.g., 5), a message moves to the dead letter queue. This prevents a single malformed event from blocking the entire pipeline. Common DLQ scenarios:
- Malformed payload — Provider sent invalid JSON that can't be parsed
- Missing handler — Event type has no registered processor
- Persistent downstream failure — External API that the processor calls is permanently down
- Bug in consumer code — Logic error that crashes on specific event patterns
A monitoring alert fires when the DLQ receives messages. Engineers investigate, fix the root cause, and replay the events from the DLQ back into the main queue.
Deep Dive Questions
How do we secure the webhook endpoint against forged requests?
Our webhook endpoint is a publicly accessible URL. Anyone who discovers it can send fake events — spoofing payment confirmations, fabricating order updates, or flooding us with garbage data. We need multiple layers of defense.
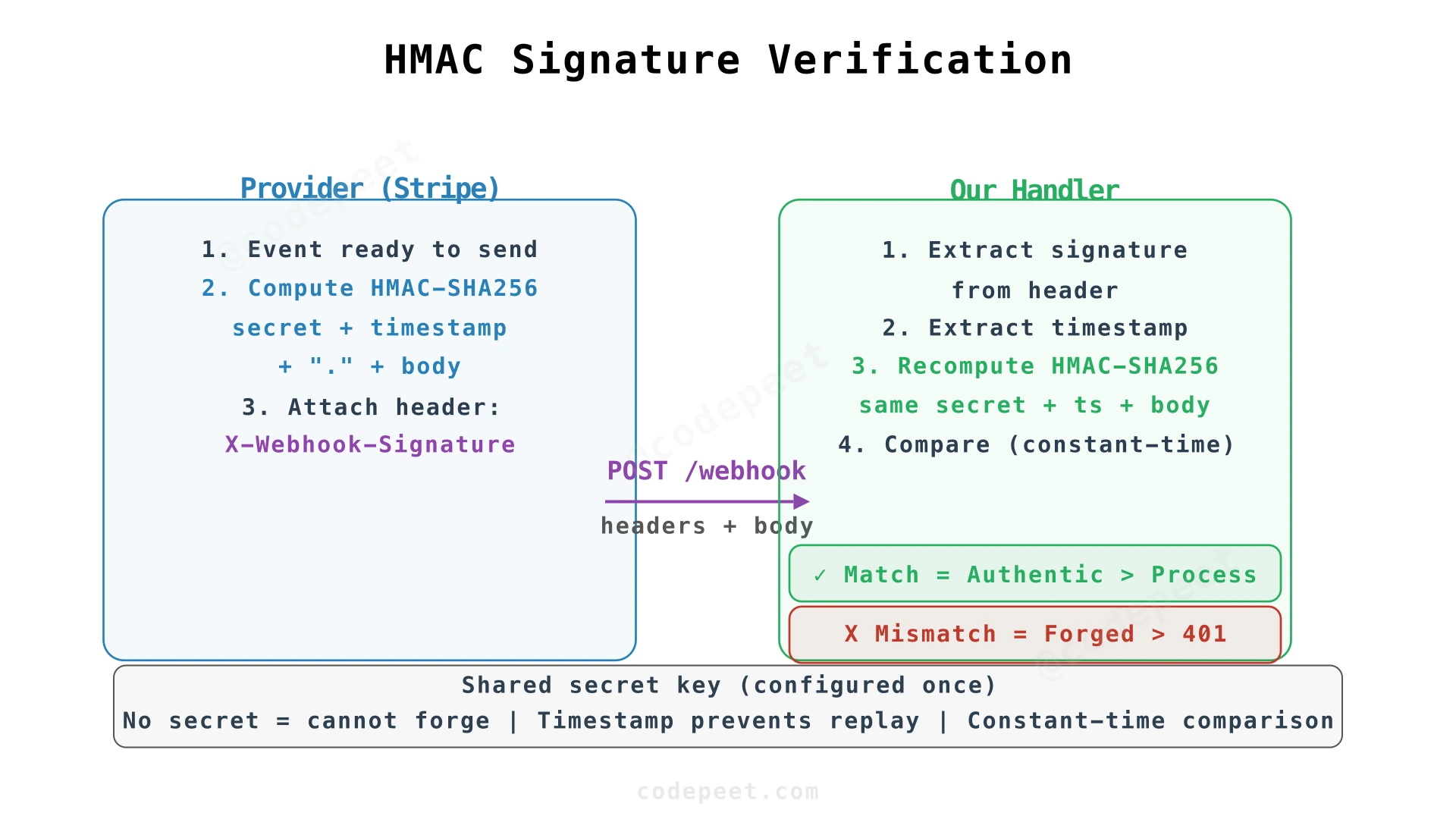
Layer 1: HMAC Signature Verification
The webhook provider (e.g., Stripe) and our service share a secret key (configured during webhook registration). When the provider sends an event:
- The provider computes
HMAC-SHA256(secret_key, request_body)and includes the hash in theX-Webhook-Signatureheader - Our handler computes the same HMAC using the shared secret and the received body
- If the hashes match, the request is authentic — only someone with the secret key could produce that signature
import hmac
import hashlib
WEBHOOK_SECRET = os.environ["WEBHOOK_SECRET"] # Shared secret, stored securely
def verify_signature(request_body: bytes, signature_header: str, timestamp: str) -> bool:
"""Verify the HMAC signature on an incoming webhook request."""
# Construct the signed payload: timestamp + "." + body
# Including timestamp prevents replay attacks
signed_payload = f"{timestamp}.".encode() + request_body
# Compute expected signature
expected = hmac.new(
WEBHOOK_SECRET.encode(),
signed_payload,
hashlib.sha256,
).hexdigest()
# Constant-time comparison prevents timing attacks
return hmac.compare_digest(f"sha256={expected}", signature_header)Why hmac.compare_digest instead of ==? Regular string comparison short-circuits on the first differing character. An attacker could measure response times to deduce the expected signature one character at a time (timing attack). compare_digest takes constant time regardless of where strings differ.
Why include the timestamp? Without it, an attacker who intercepts a valid request could replay it later. By requiring the timestamp to be within a window (e.g., ±5 minutes), we reject stale requests.
Layer 2: IP Allowlisting
Configure the load balancer or firewall to accept webhook requests only from known provider IP ranges. Stripe publishes their webhook IP addresses; so does GitHub and Shopify.
| Provider | IP Range Documentation |
|---|---|
| Stripe | Published in Stripe docs, updated periodically |
| GitHub | Available via GET https://api.github.com/meta |
| Shopify | Published in Shopify docs |
Limitation: Provider IPs can change. IP allowlisting is a defense-in-depth measure — not a primary authentication mechanism. Always use HMAC verification as the primary check.
Layer 3: Rate Limiting
Set rate limits per IP or per API key to prevent denial-of-service attacks:
- Normal provider traffic: ~12 events/sec average, ~70/sec peak → set limit at 200/sec per provider IP
- Abuse traffic: If any source exceeds 200/sec, return
429 Too Many Requests
Rate limiting protects against both malicious flooding and buggy providers that accidentally send duplicate events in loops.
Defense Summary
| Layer | Protects Against | Implementation |
|---|---|---|
| HMAC Signatures | Forged/spoofed requests | Compute + constant-time compare in handler |
| Timestamp validation | Replay attacks (old captured requests) | Reject if timestamp > 5 min old |
| IP Allowlisting | Requests from unauthorized sources | Load balancer/firewall rules |
| Rate Limiting | DoS attacks, buggy providers | Token bucket per source IP |
How do we handle duplicate webhook deliveries?
Duplicate events are inevitable, not exceptional. They occur from:
- Provider retries — Provider didn't receive
200 OK(network issue) and resends - Consumer retries — Consumer crashed mid-processing; message redelivered after visibility timeout
- Intentional replay — Provider resends events after an outage recovery
Without idempotency, processing the same payment_intent.succeeded event twice charges the customer twice. Processing the same order.created event twice creates two orders.
Idempotency Key Strategy
Every webhook event has a unique identifier assigned by the provider (e.g., Stripe's evt_1MqLSbKJFk9d2k). We use this as an idempotency key:
async def handle_webhook(request: Request) -> Response:
body = await request.body()
event_data = json.loads(body)
event_id = event_data["event_id"]
# Step 1: Check if we've seen this event before
existing = await db.fetch_one(
"SELECT id, status FROM webhook_events WHERE event_id = $1", event_id
)
if existing:
# Already seen — skip processing, return success so provider stops retrying
return Response({"status": "already_processed", "event_id": event_id}, status=200)
# Step 2: Insert with UNIQUE constraint as safety net
try:
await db.execute(
"""INSERT INTO webhook_events (event_id, event_type, provider, payload, status)
VALUES ($1, $2, $3, $4, 'pending')""",
event_id, event_data["event_type"], event_data.get("provider", "unknown"),
json.dumps(event_data),
)
except UniqueViolationError:
# Race condition: another handler inserted between our SELECT and INSERT
return Response({"status": "already_processed", "event_id": event_id}, status=200)
# Step 3: Enqueue for async processing
await queue.enqueue({"event_id": event_id, "payload": event_data})
return Response({"status": "accepted", "event_id": event_id}, status=200)Why check-then-insert instead of just INSERT with ON CONFLICT? The SELECT first is cheaper than catching exceptions on every request. 99% of events are new — the SELECT returns "not found" and we proceed. The UNIQUE constraint is a safety net for the rare race condition where two handlers receive the same event simultaneously.
Consumer-Side Idempotency
The handler-side check prevents duplicate enqueueing. But messages can still be delivered twice to consumers (visibility timeout expiry, queue retry). Consumers must also be idempotent:
async def process_event(message: dict):
event_id = message["event_id"]
# Atomic status update: only succeeds if status is still 'pending'
rows_updated = await db.execute(
"""UPDATE webhook_events SET status = 'processing'
WHERE event_id = $1 AND status = 'pending'""",
event_id,
)
if rows_updated == 0:
# Already processing or completed by another consumer
return
try:
result = await execute_business_logic(message["payload"])
await db.execute(
"""UPDATE webhook_events SET status = 'completed', processed_at = NOW()
WHERE event_id = $1""",
event_id,
)
await db.execute(
"""INSERT INTO processing_results (event_id, action_taken, result_data, duration_ms)
VALUES ($1, $2, $3, $4)""",
event_id, result.action, json.dumps(result.data), result.duration_ms,
)
except Exception as e:
await db.execute(
"""UPDATE webhook_events SET status = 'failed', retry_count = retry_count + 1,
last_error = $2 WHERE event_id = $1""",
event_id, str(e),
)
raise # Re-raise so queue doesn't ACK — message will be redeliveredThe key line is WHERE event_id = $1 AND status = 'pending'. This is an atomic compare-and-swap. If two consumers try to process the same event simultaneously, only one succeeds in changing the status from 'pending' to 'processing'. The other gets rows_updated = 0 and exits immediately.
Queue-Level Deduplication
Some message queues offer built-in deduplication:
| Queue | Deduplication Feature |
|---|---|
| AWS SQS FIFO | Content-based deduplication within 5-minute window |
| Apache Kafka | enable.idempotence=true on producer prevents duplicate publishes |
| RabbitMQ | No built-in; implement at application level |
Queue deduplication is a defense-in-depth addition — it reduces duplicates but doesn't eliminate them (e.g., messages delivered across the deduplication window). Application-level idempotency is still required.
How do we handle events that arrive out of order?
Webhook providers send events independently. Network latency, retry timing, and provider-side batching can cause events to arrive in a different order than they occurred. For example:
- Stripe sends
invoice.createdat 10:00:00 - Stripe sends
invoice.paidat 10:00:05 - Due to a network retry,
invoice.paidarrives at our service at 10:00:06 invoice.createdarrives at 10:00:08
If our processor blindly processes events in arrival order, it would try to mark an invoice as "paid" before it exists in our database.
Strategy 1: Fetch Latest State from Source of Truth
Instead of relying on event data to update local state, fetch the current state from the provider's API when processing each event:
async def process_invoice_event(event: dict):
invoice_id = event["data"]["object"]["id"]
event_type = event["event_type"]
# Don't trust the event payload for state — fetch latest from Stripe
latest_invoice = await stripe_client.get_invoice(invoice_id)
# Upsert with the latest data regardless of event order
await db.execute(
"""INSERT INTO invoices (id, status, amount, updated_at)
VALUES ($1, $2, $3, $4)
ON CONFLICT (id) DO UPDATE SET
status = EXCLUDED.status,
amount = EXCLUDED.amount,
updated_at = EXCLUDED.updated_at
WHERE invoices.updated_at < EXCLUDED.updated_at""",
latest_invoice.id,
latest_invoice.status,
latest_invoice.amount,
latest_invoice.updated_at,
)The WHERE invoices.updated_at < EXCLUDED.updated_at clause ensures we never overwrite newer data with older data. If invoice.paid (newer timestamp) was processed first, and invoice.created (older timestamp) arrives later, the UPDATE silently does nothing because the existing updated_at is already newer.
Strategy 2: Timestamp-Based Conflict Resolution
When you can't call the provider's API (rate limits, latency concerns), use the event's timestamp to determine ordering:
async def process_event_with_timestamp(event: dict):
event_id = event["event_id"]
entity_id = event["data"]["object"]["id"]
event_timestamp = parse_datetime(event["created_at"])
# Check if we already have a more recent event for this entity
latest = await db.fetch_one(
"""SELECT event_timestamp FROM entity_state
WHERE entity_id = $1 ORDER BY event_timestamp DESC LIMIT 1""",
entity_id,
)
if latest and latest.event_timestamp >= event_timestamp:
# This event is older than what we already processed — skip it
await db.execute(
"""UPDATE webhook_events SET status = 'skipped_stale'
WHERE event_id = $1""",
event_id,
)
return
# Process the event — it's the newest we've seen for this entity
await apply_event_to_state(entity_id, event)Key Takeaways
- Never assume event order. Design processing logic that produces correct results regardless of arrival sequence.
- Use the provider's API as the source of truth. Event payloads are notifications, not authoritative state updates.
- Timestamp-based conflict resolution works when provider API calls are impractical. The
WHERE updated_at < new_timestamppattern prevents stale overwrites. - Log skipped events. When an out-of-order event is skipped, mark it as
skipped_stalein the database for debugging — don't silently drop it.
How do we design a robust retry strategy with exponential backoff?
When event processing fails, we need to retry — but naively retrying immediately can overwhelm a struggling dependency. If the database is temporarily overloaded and 1,000 events fail simultaneously, immediately retrying all 1,000 creates a thundering herd that makes the situation worse.
Exponential Backoff with Jitter
The standard approach: increase the delay between retries exponentially, and add random jitter to prevent synchronized retries.
delay = min(base_delay × 2^attempt + random_jitter, max_delay)
import random
MAX_RETRIES = 5
BASE_DELAY_SEC = 1.0
MAX_DELAY_SEC = 60.0
def calculate_retry_delay(attempt: int) -> float:
"""Calculate delay with exponential backoff + full jitter."""
# Exponential: 1s, 2s, 4s, 8s, 16s
exponential = BASE_DELAY_SEC * (2 ** attempt)
# Cap at max delay
capped = min(exponential, MAX_DELAY_SEC)
# Full jitter: random value between 0 and capped delay
# This spreads retries uniformly, preventing thundering herd
return random.uniform(0, capped)
# Example retry schedule:
# Attempt 0: 0 - 1 sec (immediate to 1s)
# Attempt 1: 0 - 2 sec
# Attempt 2: 0 - 4 sec
# Attempt 3: 0 - 8 sec
# Attempt 4: 0 - 16 sec
# After 5 failures → Dead Letter QueueWhy Full Jitter Over Equal Jitter?
| Strategy | Formula | Problem |
|---|---|---|
| No jitter | base × 2^attempt | All failed events retry at exactly the same time → thundering herd |
| Equal jitter | base × 2^attempt / 2 + random(0, base × 2^attempt / 2) | Better, but retries still clustered around midpoint |
| Full jitter | random(0, base × 2^attempt) | Retries spread uniformly across the entire window → optimal load distribution |
AWS's analysis shows full jitter provides the best overall throughput when many clients retry against a shared resource.
Dead Letter Queue (DLQ) Policy
After MAX_RETRIES failed attempts, the event moves to the dead letter queue. The consumer must not keep retrying — the event is likely a poison message (malformed data, unhandled event type, persistent downstream failure). Retrying forever would waste resources and potentially block the queue.
| Retry Attempt | Delay (approx.) | Cumulative Wait |
|---|---|---|
| 1 | ~0.5 sec | ~0.5 sec |
| 2 | ~1 sec | ~1.5 sec |
| 3 | ~2 sec | ~3.5 sec |
| 4 | ~4 sec | ~7.5 sec |
| 5 | ~8 sec | ~15.5 sec |
| → DLQ | Event moves to dead letter queue | Alert triggered |
Total time before DLQ: ~15-30 seconds. Fast enough to catch transient failures (network blip, DB failover) but not so aggressive that it overwhelms recovering systems.
AWS SQS doesn't support per-message retry delays natively. The workaround is to use the visibility timeout as a retry mechanism:
- Consumer pulls message, attempts processing, fails
- Consumer calls
ChangeMessageVisibilitywith the calculated backoff delay - Message becomes invisible for that duration, then reappears for the next attempt
Alternatively, use SQS's built-in redrive policy:
{
"maxReceiveCount": 5,
"deadLetterTargetArn": "arn:aws:sqs:us-east-1:123456789:webhook-dlq"
}
After 5 receives without successful deletion, SQS automatically moves the message to the DLQ.
What observability do we need for a webhook processing pipeline?
A webhook pipeline processes events from external systems — systems we don't control. When something goes wrong, we need to identify whether the issue is on our side (handler bug, DB outage) or the provider's side (malformed payload, changed API). Observability is critical because webhook failures are often silent — no user is clicking a button and seeing an error page.
Key Metrics to Track
| Metric | What It Measures | Alert Threshold |
|---|---|---|
| Ingestion rate | Events received per second | < 50% of expected baseline for > 5 min (provider may be down) |
| Queue depth | Messages waiting in queue | > 10,000 (consumers can't keep up) |
| Processing latency (P50, P95, P99) | Time from enqueue to DB write | P99 > 500 ms |
| Error rate | Failed processing attempts / total | > 5% over 5-minute window |
| DLQ ingestion rate | Events moving to dead letter queue | > 0 (any DLQ event warrants investigation) |
| Retry rate | Messages redelivered / total consumed | > 10% (indicates systematic failures) |
| Signature rejection rate | HMAC verification failures / total | > 1% (possible secret rotation issue or attack) |
| Consumer lag | Difference between newest message and consumer's current position | > 60 seconds |
Structured Logging for Every Event
Each event should produce a log trail that allows full reconstruction of its lifecycle:
{
"timestamp": "2026-03-17T10:00:00.123Z",
"level": "INFO",
"event_id": "evt_1MqLSbKJFk9d2k",
"event_type": "payment_intent.succeeded",
"provider": "stripe",
"stage": "processing_complete",
"duration_ms": 45,
"action_taken": "updated_payment_status",
"retry_count": 0,
"trace_id": "abc123-def456"
}Dashboard Layout
A webhook monitoring dashboard should answer three questions at a glance:
- Is the system healthy? — Ingestion rate, processing latency, error rate. Green/yellow/red indicators.
- Is there a backlog? — Queue depth, consumer lag. If the queue is growing, consumers need scaling.
- Are there poison messages? — DLQ count, top error categories. Which event types are failing and why?
Alerting Strategy
| Severity | Condition | Response |
|---|---|---|
| P1 (page) | DLQ receiving events | Investigate immediately — events failing permanently |
| P1 (page) | Queue depth > 50K and growing | Consumers offline or DB down — immediate scaling/investigation |
| P2 (ticket) | Error rate > 5% for > 10 min | Systematic failure — check downstream dependencies |
| P3 (log) | Signature rejection spike | Possible secret rotation or attack — check provider status |
| P3 (log) | Ingestion rate drops > 50% | Provider may be experiencing an outage |
Staff-Level Discussion Topics
The following topics contain open-ended architectural questions designed for staff+ conversations where you demonstrate systems thinking, trade-off analysis, and cross-cutting architectural decisions.
Achieving Exactly-Once Processing Semantics
Context: Your webhook pipeline guarantees at-least-once processing. But "at-least-once" means some events may be processed twice. For payment events, duplicate processing means double-charging customers. Product demands "exactly-once" guarantees.
Discussion Points:
- Why is true exactly-once delivery impossible in distributed systems? How does the Two Generals' Problem apply here?
- How do you achieve exactly-once semantics (not delivery) using idempotency? What's the difference?
- What are the trade-offs between database-level idempotency (UNIQUE constraints) vs application-level idempotency (idempotency key cache)?
- How do you handle the case where the event was successfully processed but the status update to "completed" failed? The next retry will re-process it.
- Can you use database transactions spanning the event processing and status update to achieve atomicity? What are the limitations?
- How would you implement an idempotency key TTL that balances memory usage against deduplication window?
Multi-Provider Webhook Architecture
Context: Your platform integrates with 15 different webhook providers (Stripe, GitHub, Shopify, Twilio, SendGrid, etc.). Each provider has a different payload format, signature scheme, retry policy, and event taxonomy. The codebase is becoming unmaintainable with provider-specific if/else chains everywhere.
Discussion Points:
- How do you design a provider-agnostic webhook processing framework? What abstractions make sense?
- How do you handle different authentication schemes? (HMAC-SHA256 for Stripe, HMAC-SHA1 for GitHub, basic auth for others)
- How do you normalize different event schemas into a common internal format?
- How do you handle provider-specific quirks? (Different retry intervals, different header names for signatures, different timestamp formats)
- What testing strategy ensures that changes for one provider don't break another?
- How do you handle provider API version changes that alter webhook payload formats?
Scaling Webhook Processing to 100× Current Volume
Context: Your platform grows from 1M events/day to 100M events/day. The current architecture (single queue, PostgreSQL for all events) is hitting limits. Database write throughput is maxed out, query performance degrades with 3 billion rows, and the single queue becomes a bottleneck.
Discussion Points:
- How do you partition the message queue? By provider? By event type? By tenant? What are the trade-offs?
- When does PostgreSQL stop being appropriate for event storage? What alternatives exist? (TimescaleDB, Cassandra, DynamoDB, S3 + Athena)
- How do you implement a tiered storage strategy? (Hot: recent 24h in fast DB, Warm: 7 days in standard DB, Cold: 30 days in object storage)
- How do you handle the thundering herd problem when a provider sends 10M events in 1 minute after an outage?
- What queue partitioning strategy ensures fair processing across providers while preventing one noisy provider from starving others?
- How do you monitor and autoscale consumers based on queue depth, processing latency, and error rates?
Disaster Recovery and Data Consistency
Context: Your primary database fails during a flash sale. The message queue has 50,000 unprocessed events. Your disaster recovery plan needs to handle this scenario without losing events or creating duplicates.
Discussion Points:
- What happens to in-flight messages when the database is unavailable? How do consumers behave?
- How do you design the system so that queue messages survive a complete database rebuild?
- What's the recovery procedure after a database failover? How do you verify no events were lost?
- How do you reconcile state between the queue (events in flight), the database (events partially processed), and the provider (events already acknowledged)?
- Should you implement a "replay" capability to re-process events from a specific time window? How?
- How do you test disaster recovery procedures without impacting production?
Level Expectations
| Dimension | Mid-Level (L4) | Senior (L5) | Staff (L6) |
|---|---|---|---|
| Requirements & Estimation | List basic features (accept events, persist); identify availability as NFR | Quantify traffic (events/sec), storage (GB), compute; define at-least-once guarantee | SLA definition; cost analysis; multi-provider normalization strategy |
| Architecture | Basic handler → database; mention a queue | Queue-based async pipeline; dead letter queue; separate handler and consumer roles | Partitioned queues; tiered storage; multi-region replication; graceful degradation |
| Security | Mention HMAC verification | Implement HMAC with timestamp + constant-time comparison; IP allowlisting; rate limiting | Threat modeling; secret rotation strategy; zero-trust between services |
| Reliability | "Use a queue for reliability" | Idempotency at handler and consumer level; exponential backoff with jitter; visibility timeout mechanics | Exactly-once semantics discussion; reconciliation procedures; DR planning |
| Observability | Basic logging | Structured logging per event lifecycle; key metrics (queue depth, error rate, latency percentiles) | Full alerting strategy; SLO-based monitoring; cross-provider correlation dashboards |
Summary
Key Design Decisions
Message Queue for Decoupling. The handler's only job is to validate, persist the raw event, and enqueue. Business logic runs asynchronously in consumers. This separation gives us fast acknowledgment (~50 ms), failure isolation, and independent scaling of ingestion vs processing.
At-Least-Once with Idempotency. The queue guarantees at-least-once delivery; application-level idempotency (provider's event_id as unique key + atomic status updates) ensures duplicate processing is harmless. True exactly-once delivery is impossible in distributed systems — idempotency is the practical solution.
HMAC Signature Verification. Every request is authenticated using the shared secret before any processing. Constant-time comparison prevents timing attacks. Timestamp validation prevents replay attacks. IP allowlisting and rate limiting provide defense in depth.
Exponential Backoff with Full Jitter. Failed events retry with increasing delays (1s → 2s → 4s → 8s → 16s) plus random jitter to prevent thundering herd. After 5 failures, events move to the dead letter queue for human investigation.
Fetch Latest State for Ordering. Out-of-order events are handled by fetching current state from the provider's API rather than trusting event payload. Timestamp-based conflict resolution (WHERE updated_at < new_timestamp) prevents stale overwrites when API calls are impractical.
Architecture Principles Applied
| Principle | Application |
|---|---|
| Separation of concerns | Handler does HTTP + enqueue; Consumer does business logic + persistence |
| Fail-safe defaults | Return 200 OK only after successful enqueue; ACK message only after DB write |
| Defense in depth | HMAC + IP allowlist + rate limiting for security; handler + consumer idempotency for deduplication |
| Async over sync | Event processing decoupled from HTTP response; provider gets fast 200 OK regardless of processing time |
| Design for failure | Every component failure mode has a recovery path; no single failure loses an event |
Common Pitfalls
| Pitfall | Why It Fails | Better Approach |
|---|---|---|
| Synchronous processing in handler | Slow processing → timeout → provider retries → duplicate events | Enqueue immediately, process async |
| No idempotency check | Provider retry delivers duplicate → event processed twice | Use event_id as idempotency key with UNIQUE constraint |
| Immediate retry on failure | 1,000 events fail → 1,000 immediate retries → overwhelm DB | Exponential backoff with full jitter |
== for signature comparison | Timing attack reveals expected signature character by character | hmac.compare_digest for constant-time comparison |
| Trust event payload for state | Out-of-order events corrupt local state | Fetch latest from provider API or use timestamp-based resolution |
| No dead letter queue | Poison message blocks queue forever | Move to DLQ after N failures; alert for investigation |
Return 200 before enqueue | Handler crashes after 200 but before enqueue → event lost forever | Return 200 only after successful enqueue + DB insert |