Introduction to Ranking Functions
Introduction
Ranking functions are a powerful category of window functions that assign a numerical rank or position to each row based on a specified order. Unlike aggregate functions that summarize data, ranking functions help you understand where each row stands relative to others.
In this lesson, you will learn:
- What ranking functions are and why they matter
- The different types of ranking functions available
- When to use ranking functions in real-world scenarios
- How ranking functions differ from aggregate window functions
What Are Ranking Functions?
Ranking functions are a subset of window functions that assign a sequential number to each row based on the order you specify. They answer questions like:
- "What position does this product hold in terms of sales?"
- "Which customers are in the top 10 by order value?"
- "What is the relative standing of each employee's salary within their department?"
Key Characteristics
- Order-Dependent: Ranking functions require an ORDER BY clause within the window specification
- Non-Aggregating: They don't combine rows; they assign values to individual rows
- Partition-Aware: They can restart ranking within each partition (group)
- Deterministic: Given the same ordering, they produce consistent results
Visualization
Ranking Functions -- Introduction
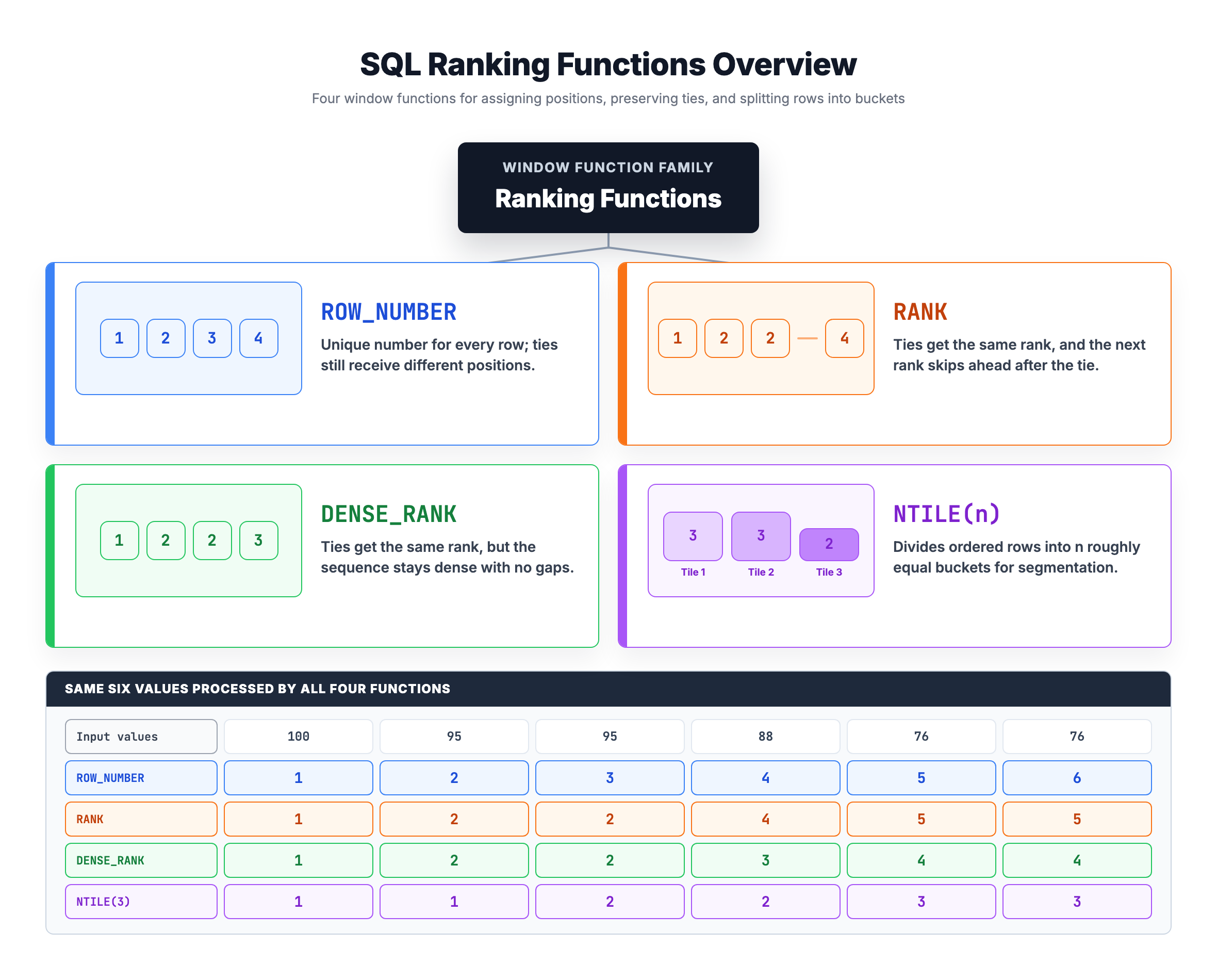
Types of Ranking Functions
SQL provides several ranking functions, each with slightly different behavior. Here's an overview:
| Function | Description | Handles Ties |
|---|---|---|
ROW_NUMBER() | Assigns unique sequential numbers (1, 2, 3, ...) | No gaps, unique values |
RANK() | Assigns rank with gaps for ties | Gaps after ties |
DENSE_RANK() | Assigns rank without gaps for ties | No gaps |
NTILE(n) | Divides rows into n equal buckets | Equal distribution |
PERCENT_RANK() | Returns relative rank as a percentage (0-1) | Percentage based |
CUME_DIST() | Returns cumulative distribution (0-1) | Cumulative percentage |
Quick Visual Example
Consider 4 employees with salaries: 100, 100, 90, 80
| Salary | ROW_NUMBER | RANK | DENSE_RANK |
|---|---|---|---|
| 100 | 1 | 1 | 1 |
| 100 | 2 | 1 | 1 |
| 90 | 3 | 3 | 2 |
| 80 | 4 | 4 | 3 |
Notice how each function handles the tied salaries of 100 differently.
Basic Syntax
All ranking functions follow a similar syntax pattern:
RANKING_FUNCTION() OVER (
[PARTITION BY column(s)]
ORDER BY column(s) [ASC|DESC]
)
Syntax Components
- RANKING_FUNCTION(): One of ROW_NUMBER, RANK, DENSE_RANK, NTILE, PERCENT_RANK, or CUME_DIST
- OVER (): Defines the window specification
- PARTITION BY (optional): Divides rows into groups; ranking restarts for each group
- ORDER BY (required): Determines the order for ranking
Important Note
Unlike aggregate window functions (SUM, COUNT, AVG), ranking functions require the ORDER BY clause. Without it, the ranking would be arbitrary and meaningless.
When to Use Ranking Functions
Ranking functions are essential for many common business scenarios:
1. Top-N Analysis
Find the top 5 products by revenue, top 10 customers by order count, etc.
2. Percentile Calculations
Determine which quartile or decile a value falls into.
3. Duplicate Detection
Identify and handle duplicate records by ranking them.
4. Pagination
Implement efficient pagination for large result sets.
5. Comparative Analysis
Compare each row's position within its group (e.g., salary rank within department).
6. Data Deduplication
Select the most recent or most relevant record from a group of duplicates.
Ranking vs Aggregate Window Functions
Let's compare ranking functions with aggregate window functions to understand when to use each:
| Aspect | Ranking Functions | Aggregate Window Functions |
|---|---|---|
| Purpose | Assign position/rank | Calculate aggregates |
| ORDER BY | Required | Optional |
| Output | Sequential numbers | Computed values |
| Example | "This is the 3rd highest sale" | "Total sales so far: 5000" |
Practical Comparison
-- Compare ranking vs aggregate window functions
SELECT
seller_id,
price,
-- Ranking function: position
ROW_NUMBER() OVER (ORDER BY price DESC) AS price_rank,
-- Aggregate function: running total
SUM(price) OVER (ORDER BY price DESC) AS running_total
FROM olist_order_items_dataset
LIMIT 10;The ranking function tells us the position, while the aggregate tells us a calculated value.
Practice
Let's explore ranking functions with a simple preview. Try this query to see how different ranking functions work on the same data:
-- Preview different ranking functions
SELECT
product_id,
price,
ROW_NUMBER() OVER (ORDER BY price DESC) AS row_num,
RANK() OVER (ORDER BY price DESC) AS rank_val,
DENSE_RANK() OVER (ORDER BY price DESC) AS dense_rank_val
FROM olist_order_items_dataset
LIMIT 20;Key Takeaways
Here's what you've learned about ranking functions:
- Definition: Ranking functions assign sequential numbers based on row order
- Requirement: ORDER BY is mandatory for ranking functions
- Types: ROW_NUMBER, RANK, DENSE_RANK, NTILE, PERCENT_RANK, CUME_DIST
- Tie Handling: Each function handles tied values differently
- Use Cases: Top-N analysis, duplicate detection, pagination, percentiles
Coming Up Next
In the following lessons, we'll dive deep into each ranking function:
- ROW_NUMBER for unique sequential numbering
- RANK and DENSE_RANK for ranking with tie handling
- NTILE for bucket distribution
- PERCENT_RANK and CUME_DIST for relative positioning