Extra Characters in a String
Description
You are given a string s (0-indexed) and a list of words called dictionary. Your goal is to break the string s into one or more non-overlapping substrings, where each substring must be a word from dictionary.
It may not be possible to use every character in s as part of a dictionary word. Characters that are not covered by any chosen substring are called extra characters.
Return the minimum number of extra characters remaining after you break up s in the best possible way.
Note that the same dictionary word can be used multiple times when forming substrings.
Examples
Example 1
Input: s = "leetscode", dictionary = ["leet", "code", "leetcode"]
Output: 1
Explanation: We can break the string as "leet" (covering indices 0 through 3) and "code" (covering indices 5 through 8). The character 's' at index 4 is not part of any dictionary word, so it counts as one extra character. No arrangement can do better than 1 extra character, so we return 1.
Example 2
Input: s = "sayhelloworld", dictionary = ["hello", "world"]
Output: 3
Explanation: We can break the string using "hello" (indices 3 through 7) and "world" (indices 8 through 12). The characters 's', 'a', 'y' at indices 0, 1, and 2 are not covered by any dictionary word. That leaves 3 extra characters, which is the minimum possible.
Constraints
- 1 ≤ s.length ≤ 50
- 1 ≤ dictionary.length ≤ 50
- 1 ≤ dictionary[i].length ≤ 50
dictionary[i]andsconsist of only lowercase English lettersdictionarycontains distinct words
Editorial
Brute Force
Intuition
Imagine you are reading a sentence letter by letter, and you have a reference list of known words. At each position in the sentence, you face a choice: either the current character is not part of any known word (so it is "extra"), or you can try to match a word from your reference list starting at the current position.
The most straightforward idea is to try every possibility. Starting from the first character, we either skip it (counting it as extra) or attempt to match every word in the dictionary that begins at that position. Whichever choice we make, we move forward in the string and repeat the same decision-making process from the new position.
This naturally leads to a recursive approach: define a function solve(idx) that returns the minimum number of extra characters from position idx to the end of the string. At each call, we branch into all possible choices and take the one that gives the smallest count.
Step-by-Step Explanation
Let's trace through with s = "leetscode", dictionary = ["leet", "code", "leetcode"]:
Step 1: Call solve(0). We are at the start of the string. We have two options:
- Skip 'l' as extra → 1 + solve(1)
- Match "leet" (s[0:4] = "leet" is in dictionary) → solve(4)
- Note: "leetcode" does NOT match because s[0:8] = "leetscod" ≠ "leetcode"
Step 2: Explore the "leet" branch first: call solve(4). At index 4, s[4] = 's'. No dictionary word matches starting at index 4 ("leet" ≠ s[4:8]="scod", "code" ≠ "scod"). Only option:
- Skip 's' as extra → 1 + solve(5)
Step 3: Call solve(5). At index 5, s[5:9] = "code". Two options:
- Skip 'c' as extra → 1 + solve(6)
- Match "code" (s[5:9] = "code" is in dictionary) → solve(9)
Step 4: Call solve(9). Index 9 equals the length of the string ("leetscode" has 9 characters). Base case: return 0. No characters left, no extra characters.
Step 5: Back at solve(5): the "code" path gives solve(9) = 0. The "skip" path would give 1 + solve(6) which leads to more extras. solve(5) = min(1 + solve(6), 0) = 0.
Step 6: Back at solve(4): solve(4) = 1 + solve(5) = 1 + 0 = 1. The 's' at index 4 is the one extra character.
Step 7: Now explore the "skip" branch from solve(0): call solve(1). This leads to solve(1) → skip 'e' → solve(2) → skip 'e' → solve(3) → skip 't' → solve(4). Notice solve(4) is being computed AGAIN — this is redundant work!
Step 8: solve(1) eventually resolves through the chain of skips: solve(3) = 1 + solve(4) = 2, solve(2) = 1 + solve(3) = 3, solve(1) = 1 + solve(2) = 4.
Step 9: Back at solve(0): min("leet" path = solve(4) = 1, "skip" path = 1 + solve(1) = 5) = 1.
Result: The minimum number of extra characters is 1.
Brute Force Recursion — Exploring All Breakings of "leetscode" — Watch how the recursive approach explores different ways to break the string, branching at each position. Notice that solve(4) is computed twice — an overlapping subproblem.
Algorithm
- Convert the dictionary list into a hash set for O(1) lookups
- Define a recursive function
solve(idx)that returns the minimum extra characters from indexidxto the end of the string - Base case: If
idxequals the length ofs, return 0 (no characters left) - Recursive case:
- Start with
result = 1 + solve(idx + 1)— assume the current character is extra - For each possible end position from
idx + 1tolen(s):- If the substring
s[idx:end]is in the dictionary:- Update
result = min(result, solve(end))— use the dictionary word with zero extra characters
- Update
- If the substring
- Start with
- Return
result - Call
solve(0)to get the answer
Code
class Solution {
public:
int minExtraChar(string s, vector<string>& dictionary) {
unordered_set<string> dict(dictionary.begin(), dictionary.end());
return solve(s, dict, 0);
}
private:
int solve(string& s, unordered_set<string>& dict, int idx) {
if (idx == (int)s.size()) return 0;
// Option 1: Skip current character as extra
int result = 1 + solve(s, dict, idx + 1);
// Option 2: Try to match a dictionary word starting at idx
for (int end = idx + 1; end <= (int)s.size(); end++) {
if (dict.count(s.substr(idx, end - idx))) {
result = min(result, solve(s, dict, end));
}
}
return result;
}
};class Solution:
def minExtraChar(self, s: str, dictionary: List[str]) -> int:
word_set = set(dictionary)
def solve(idx: int) -> int:
if idx == len(s):
return 0
# Option 1: Skip current character as extra
result = 1 + solve(idx + 1)
# Option 2: Try to match a dictionary word starting at idx
for end in range(idx + 1, len(s) + 1):
if s[idx:end] in word_set:
result = min(result, solve(end))
return result
return solve(0)class Solution {
private Set<String> dict;
public int minExtraChar(String s, String[] dictionary) {
dict = new HashSet<>(Arrays.asList(dictionary));
return solve(s, 0);
}
private int solve(String s, int idx) {
if (idx == s.length()) return 0;
// Option 1: Skip current character as extra
int result = 1 + solve(s, idx + 1);
// Option 2: Try to match a dictionary word starting at idx
for (int end = idx + 1; end <= s.length(); end++) {
if (dict.contains(s.substring(idx, end))) {
result = Math.min(result, solve(s, end));
}
}
return result;
}
}Complexity Analysis
Time Complexity: O(2^n)
At each position in the string, we make a choice: skip the character or match a word. In the worst case, every single character and every substring matches a dictionary word, leading to an exponential number of recursive branches. The recursion tree can have up to 2^n leaves, making this approach infeasible for larger inputs.
Space Complexity: O(n)
The maximum recursion depth is n (the length of the string), since each recursive call advances at least one position forward. The hash set for the dictionary takes O(L) space where L is the total length of all dictionary words, giving O(n + L) overall.
Why This Approach Is Not Efficient
The brute force recursion has exponential time complexity because it recomputes the same subproblems many times. As we saw in the trace, solve(4) was computed twice — once from the "leet" branch and once from the chain of skips through solve(1) → solve(2) → solve(3) → solve(4). For a longer string, this redundancy grows explosively.
The fundamental issue is overlapping subproblems: the answer for solve(idx) depends only on idx, yet we recompute it every time a different path in the recursion tree reaches the same index. With n possible indices, there are only n unique subproblems, but the brute force might solve each one exponentially many times.
This is a classic signal for dynamic programming. If we store the result of solve(idx) the first time we compute it and reuse it for all subsequent calls, we eliminate all redundant work. Even better, we can compute the solution iteratively from left to right in a bottom-up fashion, avoiding recursion entirely.
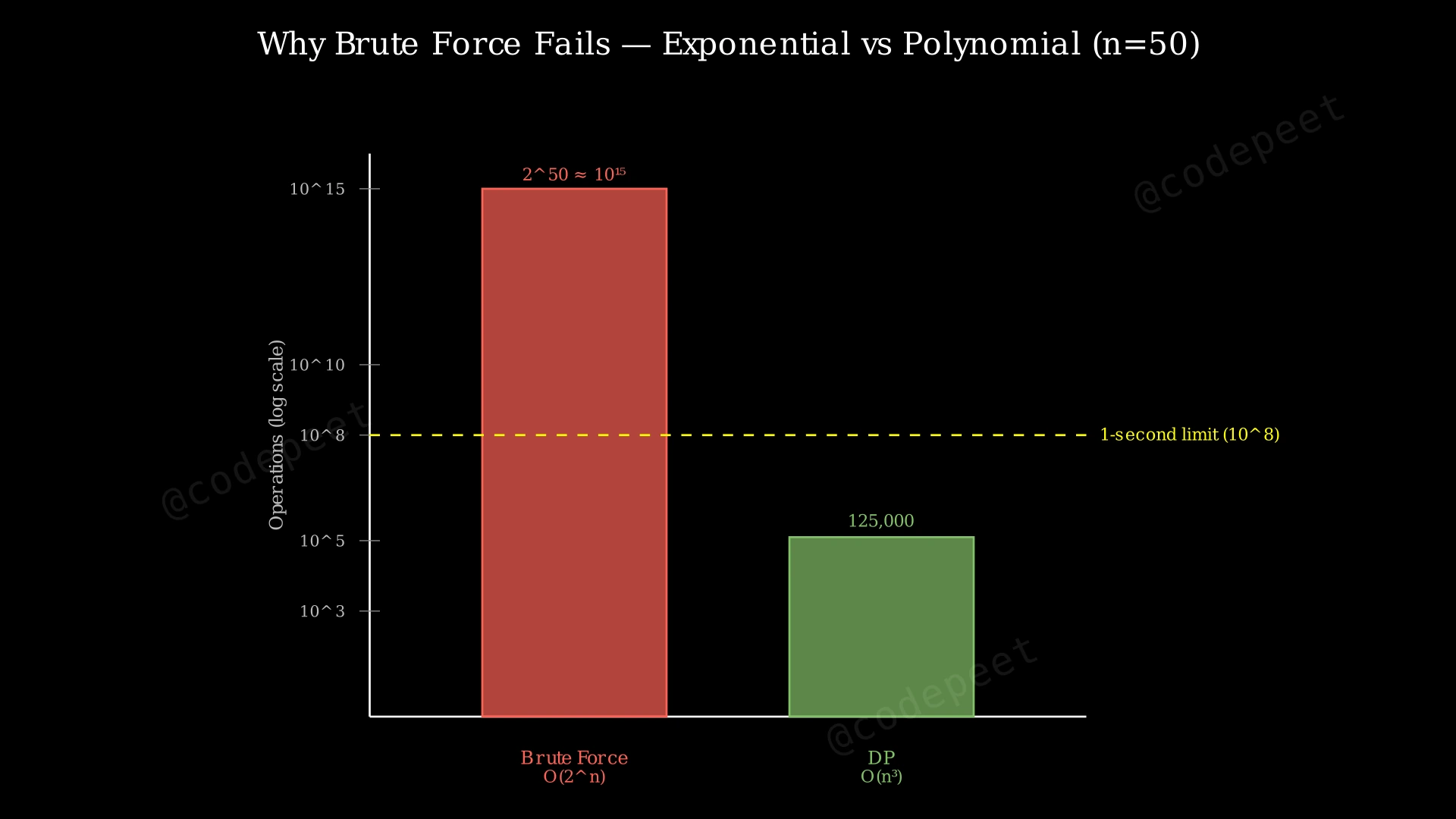
With n ≤ 50, the brute force's O(2^n) could require up to 2^50 ≈ 10^15 operations, far exceeding any reasonable time limit. A DP approach with O(n²) or O(n³) time handles n = 50 effortlessly.
Optimal Approach - Dynamic Programming
Intuition
The key insight from the brute force analysis is that the answer for any starting index depends only on the index itself — not on how we arrived there. This means we can build the solution incrementally.
Instead of thinking recursively from start to end, let us think iteratively. Define dp[i] as the minimum number of extra characters in the first i characters of s (i.e., the substring s[0..i-1]).
At each position i, we face a simple decision:
-
Treat the character at position
i-1as extra: Thendp[i] = dp[i-1] + 1. We carry forward the best solution for the firsti-1characters and add 1 because we are not using the current character in any word. -
End a dictionary word at position
i: For every possible starting positionj(where0 ≤ j < i), check if the substrings[j..i-1]is a dictionary word. If it is, thendp[i] = min(dp[i], dp[j])— we use zero extra characters for that word and carry forward the best solution for the firstjcharacters.
By filling the dp array from left to right, each entry builds on already-computed results. The final answer is dp[n] where n is the length of s.
This is similar to the classic "Word Break" problem, except instead of checking if the entire string can be segmented, we minimize the characters that cannot be covered.
Step-by-Step Explanation
Let's trace through with s = "leetscode", dictionary = ["leet", "code", "leetcode"]:
Step 1: Initialize dp array of size 10 (string length 9 + 1). Set dp[0] = 0 because an empty prefix has zero extra characters.
Step 2: Process i=1 (first character 'l'). Default: dp[1] = dp[0] + 1 = 1. Check if any substring ending at position 1 is in the dictionary: s[0:1] = "l" → not in dictionary. Final dp[1] = 1.
Step 3: Process i=2 (through 'e'). Default: dp[2] = dp[1] + 1 = 2. Check substrings: s[0:2]="le" → no, s[1:2]="e" → no. Final dp[2] = 2.
Step 4: Process i=3 (through 'e'). Default: dp[3] = dp[2] + 1 = 3. No matching substrings found. Final dp[3] = 3.
Step 5: Process i=4 (through 't'). Default: dp[4] = dp[3] + 1 = 4.
Step 6: Check substring s[0:4] = "leet" → FOUND in dictionary! dp[4] = min(4, dp[0]) = min(4, 0) = 0. The word "leet" covers all 4 characters perfectly with zero extras. Final dp[4] = 0.
Step 7: Process i=5 (through 's'). Default: dp[5] = dp[4] + 1 = 0 + 1 = 1. No dictionary word ends at position 5. The character 's' is extra. Final dp[5] = 1.
Step 8: Process i=6 through i=8. No dictionary words end at these positions. dp[6] = 2, dp[7] = 3, dp[8] = 4.
Step 9: Process i=9 (through final 'e'). Default: dp[9] = dp[8] + 1 = 5.
Step 10: Check substring s[5:9] = "code" → FOUND in dictionary! dp[9] = min(5, dp[5]) = min(5, 1) = 1. The word "code" covers positions 5-8, and dp[5] = 1 means one extra character ('s') before it.
Step 11: Final answer: dp[9] = 1. The optimal break is "leet" + (extra 's') + "code" with 1 extra character.
DP Table — Filling Minimum Extra Characters for "leetscode" — Watch how the dp array is filled left to right. Each cell represents the minimum extra characters for the prefix of that length. Key moments: dp[4] drops to 0 when 'leet' matches, and dp[9] drops to 1 when 'code' matches.
Algorithm
- Convert the dictionary list into a hash set for O(1) word lookups
- Create a dp array of size
n + 1and initializedp[0] = 0 - For each position
ifrom 1 ton:- Set
dp[i] = dp[i-1] + 1(default: treat character ati-1as extra) - For each starting position
jfrom 0 toi-1:- If substring
s[j:i]exists in the dictionary:- Update
dp[i] = min(dp[i], dp[j])
- Update
- If substring
- Set
- Return
dp[n]as the minimum number of extra characters
Code
class Solution {
public:
int minExtraChar(string s, vector<string>& dictionary) {
int n = s.size();
unordered_set<string> dict(dictionary.begin(), dictionary.end());
vector<int> dp(n + 1, 0);
for (int i = 1; i <= n; i++) {
// Default: treat s[i-1] as an extra character
dp[i] = dp[i - 1] + 1;
// Check all substrings ending at position i
for (int j = 0; j < i; j++) {
if (dict.count(s.substr(j, i - j))) {
dp[i] = min(dp[i], dp[j]);
}
}
}
return dp[n];
}
};class Solution:
def minExtraChar(self, s: str, dictionary: List[str]) -> int:
n = len(s)
word_set = set(dictionary)
dp = [0] * (n + 1)
for i in range(1, n + 1):
# Default: treat s[i-1] as an extra character
dp[i] = dp[i - 1] + 1
# Check all substrings ending at position i
for j in range(i):
if s[j:i] in word_set:
dp[i] = min(dp[i], dp[j])
return dp[n]class Solution {
public int minExtraChar(String s, String[] dictionary) {
int n = s.length();
Set<String> dict = new HashSet<>(Arrays.asList(dictionary));
int[] dp = new int[n + 1];
for (int i = 1; i <= n; i++) {
// Default: treat s[i-1] as an extra character
dp[i] = dp[i - 1] + 1;
// Check all substrings ending at position i
for (int j = 0; j < i; j++) {
if (dict.contains(s.substring(j, i))) {
dp[i] = Math.min(dp[i], dp[j]);
}
}
}
return dp[n];
}
}Complexity Analysis
Time Complexity: O(n³)
The outer loop runs n times. For each position i, the inner loop iterates up to i times (checking all starting positions j). For each pair (j, i), creating the substring s[j:i] takes O(i - j) time, and the hash lookup also processes O(i - j) characters for hashing. In the worst case, the total work across all pairs is O(n³). With n ≤ 50, this means at most 125,000 operations — extremely fast.
Space Complexity: O(n + L)
The dp array uses O(n) space. The hash set stores all dictionary words, requiring O(L) space where L is the total length of all words in the dictionary. Temporary substring creation uses O(n) space. Overall: O(n + L).