Design Add and Search Words Data Structure
Description
Design a data structure called WordDictionary that allows you to add words and then search for them, with the twist that search queries may contain the wildcard character '.' (a dot), which can match any single lowercase English letter.
You need to implement three operations:
WordDictionary()— Initializes the data structure.void addWord(word)— Stores a word made up of lowercase English letters so it can be looked up later.bool search(word)— Returnstrueif any previously added word matches the given search pattern, orfalseotherwise. The search pattern may include dots, and each dot can stand in for any single letter.
For example, if you add the words "bad", "dad", and "mad", then searching for ".ad" would return true because the dot can match 'b', 'd', or 'm', and all three words end with "ad". Searching for "pad" would return false because no added word matches exactly.
Examples
Example 1
Input:
["WordDictionary","addWord","addWord","addWord","search","search","search","search"]
[[],["bad"],["dad"],["mad"],["pad"],["bad"],[".ad"],["b.."]]
Output: [null, null, null, null, false, true, true, true]
Explanation:
WordDictionary()— An empty dictionary is created.addWord("bad")— The word "bad" is stored.addWord("dad")— The word "dad" is stored.addWord("mad")— The word "mad" is stored.search("pad")→false— No stored word matches "pad" exactly. The letters 'p', 'a', 'd' do not correspond to any added word.search("bad")→true— The word "bad" was added, and every character matches exactly.search(".ad")→true— The dot can stand for any letter. It matches 'b' in "bad", 'd' in "dad", and 'm' in "mad". At least one match exists, so the result istrue.search("b..")→true— The first character 'b' matches "bad". The two dots match 'a' and 'd'. So "bad" is a valid match.
Example 2
Input:
["WordDictionary","addWord","addWord","search","search","search"]
[[],["a"],["ab"],["a"],["."],["ab."]]
Output: [null, null, null, true, true, false]
Explanation:
addWord("a")andaddWord("ab")— Two words are stored.search("a")→true— Exact match for "a".search(".")→true— The dot can match any single letter. Since "a" is a stored word of length 1, it matches.search("ab.")→false— This pattern has length 3. We need a stored 3-letter word starting with "ab". Neither "a" (length 1) nor "ab" (length 2) has length 3, so no match exists.
Constraints
- 1 ≤ word.length ≤ 25
wordinaddWordconsists of lowercase English letters only.wordinsearchconsists of lowercase English letters or the dot character'.'.- There will be at most 2 dots in
wordforsearchqueries. - At most 10^4 calls will be made to
addWordandsearch.
Editorial
Brute Force
Intuition
The simplest way to solve this problem is to store every word we add in a list. When we need to search, we go through every word in the list and check if it matches the search pattern character by character.
For each stored word, we first check if its length matches the search pattern's length — if not, it cannot be a match. If the lengths are equal, we compare each character position: if the pattern has a regular letter, it must match exactly; if the pattern has a dot, it matches any letter.
Think of it like having a stack of flashcards with words written on them. When someone gives you a pattern like ".ad", you flip through every card one by one, checking if each word fits. For a card with "bad", you compare: dot matches 'b' ✓, 'a' matches 'a' ✓, 'd' matches 'd' ✓ — it's a match! You stop searching.
Step-by-Step Explanation
Let's trace through the example: add "bad", "dad", "mad", then search for ".ad".
Step 1: Add "bad" — our list becomes ["bad"].
Step 2: Add "dad" — our list becomes ["bad", "dad"].
Step 3: Add "mad" — our list becomes ["bad", "dad", "mad"].
Step 4: Search for ".ad". Start scanning the list.
Step 5: Compare pattern ".ad" with word "bad".
- Length check: len(".ad") = 3, len("bad") = 3 ✓
- Position 0: pattern is '.', matches any letter → matches 'b' ✓
- Position 1: pattern is 'a', word is 'a' → exact match ✓
- Position 2: pattern is 'd', word is 'd' → exact match ✓
- All characters match — return
true!
We found a match on the very first word, but in the worst case we'd scan all words and all characters.
Brute Force — Scanning Word List for Pattern Match — Watch how we compare the search pattern against each stored word character by character, with dots acting as wildcards.
Algorithm
- Maintain a list of all added words.
- addWord(word): Append the word to the list.
- search(pattern):
- For each word in the list:
- If
len(word) ≠ len(pattern), skip this word. - Compare character by character:
- If
pattern[i]is'.', it matches any character — continue. - If
pattern[i] ≠ word[i], this word does not match — break.
- If
- If all characters matched, return
true.
- If
- If no word matched, return
false.
- For each word in the list:
Code
#include <vector>
#include <string>
using namespace std;
class WordDictionary {
private:
vector<string> words;
public:
WordDictionary() {}
void addWord(string word) {
words.push_back(word);
}
bool search(string pattern) {
for (const string& word : words) {
if (word.size() != pattern.size()) continue;
bool match = true;
for (int i = 0; i < word.size(); i++) {
if (pattern[i] != '.' && pattern[i] != word[i]) {
match = false;
break;
}
}
if (match) return true;
}
return false;
}
};class WordDictionary:
def __init__(self):
self.words = []
def addWord(self, word: str) -> None:
self.words.append(word)
def search(self, pattern: str) -> bool:
for word in self.words:
if len(word) != len(pattern):
continue
match = True
for i in range(len(word)):
if pattern[i] != '.' and pattern[i] != word[i]:
match = False
break
if match:
return True
return Falseimport java.util.ArrayList;
import java.util.List;
class WordDictionary {
private List<String> words;
public WordDictionary() {
words = new ArrayList<>();
}
public void addWord(String word) {
words.add(word);
}
public boolean search(String pattern) {
for (String word : words) {
if (word.length() != pattern.length()) continue;
boolean match = true;
for (int i = 0; i < word.length(); i++) {
if (pattern.charAt(i) != '.' && pattern.charAt(i) != word.charAt(i)) {
match = false;
break;
}
}
if (match) return true;
}
return false;
}
}Complexity Analysis
Time Complexity:
addWord: O(1) — Appending to a list is constant time.search: O(N × M) where N is the number of stored words and M is the length of the search pattern. In the worst case, we compare every character of every stored word against the pattern.
Space Complexity: O(N × M)
We store all N words, each of average length M, in a flat list. No additional indexing or prefix sharing is used.
Why This Approach Is Not Efficient
The brute force approach performs O(N × M) work on every single search call. With up to 10^4 calls to addWord and search, and word lengths up to 25, the total work could reach 10^4 × 10^4 × 25 = 2.5 × 10^9 operations — far too slow.
The core problem is that we treat every word as independent. We re-examine words that share common prefixes (like "bad", "ban", "bat") without leveraging the fact that they all start with "ba". We also scan words of the wrong length even though we could skip them immediately.
Key insight: if we organize words by their shared prefixes in a tree structure (a Trie), we can follow specific branches for exact characters and only branch out when we encounter a dot. This eliminates redundant comparisons and turns the search into a traversal of a much smaller structure.
Optimal Approach - Trie with DFS
Intuition
A Trie (prefix tree) is a tree-shaped data structure where each path from the root to a marked node represents a stored word. Each node has up to 26 children (one per lowercase letter), and a flag indicating whether the path from root to this node forms a complete word.
When we add a word like "bad", we create a path: root → 'b' → 'a' → 'd' (marked as end-of-word). If we then add "ban", the path shares root → 'b' → 'a' and only branches at the third level to 'n' (also marked as end-of-word). This prefix sharing makes storage compact and lookup fast.
For searching, the challenge is handling dots. When we encounter a regular letter, we simply follow the corresponding child — if it does not exist, the word is not found. But when we encounter a dot, the dot could match any letter, so we must try all existing children at that level. This is naturally handled by depth-first search (DFS): for each dot, we recursively explore every non-null child and see if any path leads to a successful match.
Imagine a library where books are organized in sections by their first letter, then subsections by their second letter, and so on. Searching for "bad" means going directly to section 'b', subsection 'a', and looking for 'd'. Searching for ".ad" means visiting every top-level section, then going to subsection 'a' and looking for 'd' in each. You skip entire branches early if a path doesn't exist.
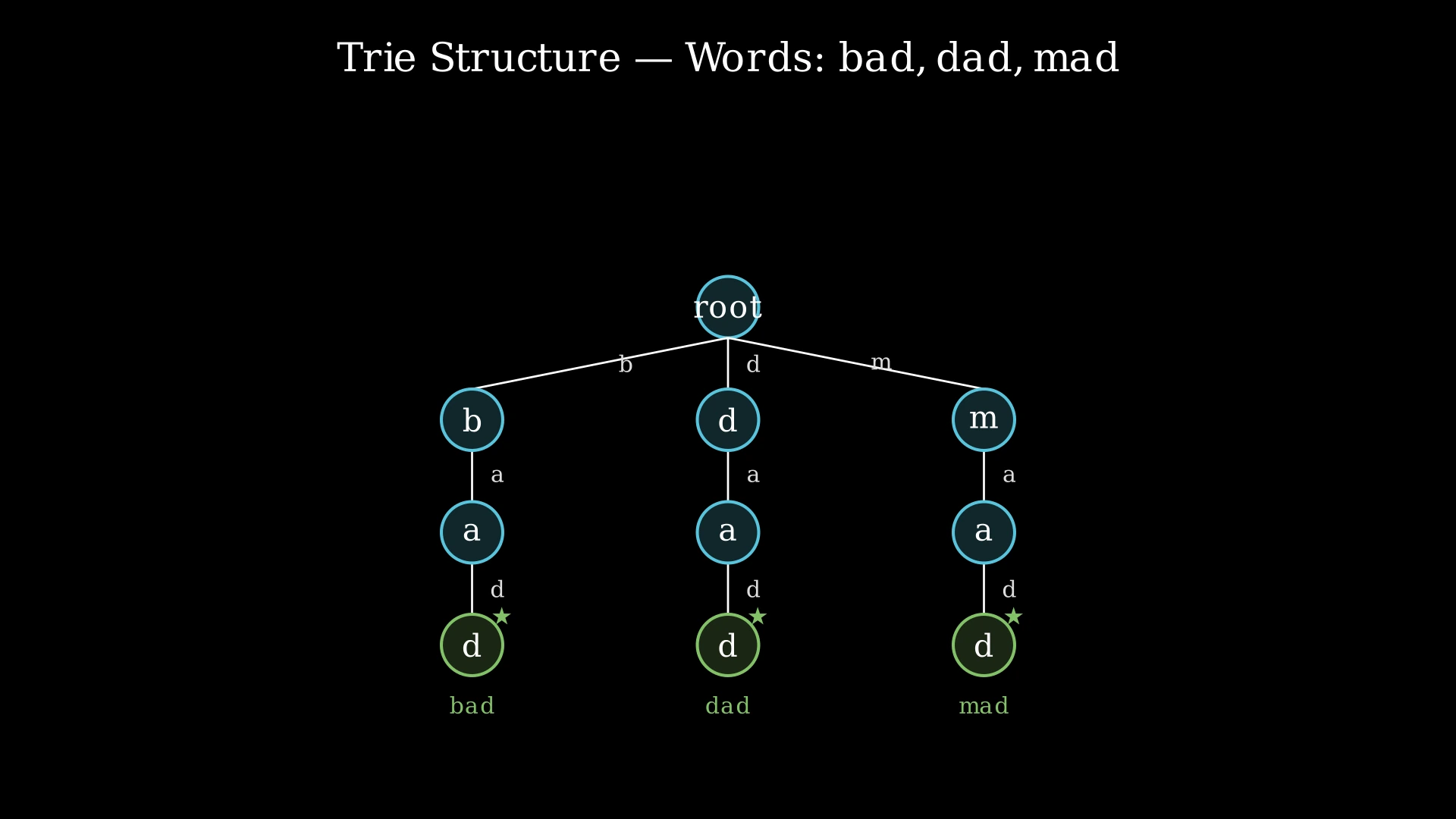
Step-by-Step Explanation
Let's trace through: add "bad", "dad", "mad", then search for ".ad".
Building the Trie:
Step 1: Add "bad" — Create path root → b → a → d (mark 'd' as end-of-word).
Step 2: Add "dad" — Create path root → d → a → d (mark 'd' as end-of-word). Root now has children at 'b' and 'd'.
Step 3: Add "mad" — Create path root → m → a → d (mark 'd' as end-of-word). Root now has children at 'b', 'd', and 'm'.
Searching for ".ad":
Step 4: Start DFS at root, index = 0. Pattern[0] = '.'. Since it's a dot, we must try all existing children of root: 'b', 'd', 'm'.
Step 5: Branch into child 'b' (trying first child). Now at the 'b' node, index = 1. Pattern[1] = 'a'. Check if 'b' node has child 'a' → yes. Move to the 'a' node.
Step 6: Now at the 'a' node (under 'b'), index = 2. Pattern[2] = 'd'. Check if 'a' node has child 'd' → yes. Move to the 'd' node.
Step 7: Now at the 'd' node (under 'b' → 'a'), index = 3. We have consumed all characters. Check is_end flag → true. This node marks the end of word "bad".
Step 8: Return true. The word "bad" matches the pattern ".ad". No need to explore the 'd' or 'm' branches.
Trie DFS Search — Pattern ".ad" Matching — Watch how the trie is built character by character, then how DFS explores branches when encountering a wildcard dot, finding a match through the 'b' branch.
Algorithm
Trie Node Structure:
- Each node has an array of 26 children (for 'a' through 'z') and a boolean
is_endflag.
addWord(word):
- Start at the root node.
- For each character
cin the word:- Compute index =
c - 'a'. - If
children[index]is null, create a new trie node. - Move to
children[index].
- Compute index =
- Mark the current node's
is_endastrue.
search(pattern):
- Call a recursive DFS helper:
dfs(pattern, index, node). - Base case: if
index == len(pattern), returnnode.is_end. - If
pattern[index]is a regular letter:- If the corresponding child does not exist, return
false. - Otherwise, recurse on the child with
index + 1.
- If the corresponding child does not exist, return
- If
pattern[index]is'.':- For each non-null child in the current node:
- Recursively call
dfs(pattern, index + 1, child). - If any call returns
true, returntrue.
- Recursively call
- If no child yields a match, return
false.
- For each non-null child in the current node:
Code
#include <string>
#include <vector>
using namespace std;
class TrieNode {
public:
TrieNode* children[26];
bool isEnd;
TrieNode() {
for (int i = 0; i < 26; i++) children[i] = nullptr;
isEnd = false;
}
};
class WordDictionary {
private:
TrieNode* root;
bool dfs(const string& word, int index, TrieNode* node) {
if (index == word.size()) {
return node->isEnd;
}
char c = word[index];
if (c == '.') {
for (int i = 0; i < 26; i++) {
if (node->children[i] && dfs(word, index + 1, node->children[i])) {
return true;
}
}
return false;
} else {
int idx = c - 'a';
if (!node->children[idx]) return false;
return dfs(word, index + 1, node->children[idx]);
}
}
public:
WordDictionary() {
root = new TrieNode();
}
void addWord(string word) {
TrieNode* node = root;
for (char c : word) {
int idx = c - 'a';
if (!node->children[idx]) {
node->children[idx] = new TrieNode();
}
node = node->children[idx];
}
node->isEnd = true;
}
bool search(string word) {
return dfs(word, 0, root);
}
};class TrieNode:
def __init__(self):
self.children = {}
self.is_end = False
class WordDictionary:
def __init__(self):
self.root = TrieNode()
def addWord(self, word: str) -> None:
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end = True
def search(self, word: str) -> bool:
def dfs(index: int, node: TrieNode) -> bool:
if index == len(word):
return node.is_end
char = word[index]
if char == '.':
for child in node.children.values():
if dfs(index + 1, child):
return True
return False
else:
if char not in node.children:
return False
return dfs(index + 1, node.children[char])
return dfs(0, self.root)class TrieNode {
TrieNode[] children;
boolean isEnd;
TrieNode() {
children = new TrieNode[26];
isEnd = false;
}
}
class WordDictionary {
private TrieNode root;
public WordDictionary() {
root = new TrieNode();
}
public void addWord(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.isEnd = true;
}
public boolean search(String word) {
return dfs(word, 0, root);
}
private boolean dfs(String word, int index, TrieNode node) {
if (index == word.length()) {
return node.isEnd;
}
char c = word.charAt(index);
if (c == '.') {
for (int i = 0; i < 26; i++) {
if (node.children[i] != null && dfs(word, index + 1, node.children[i])) {
return true;
}
}
return false;
} else {
int idx = c - 'a';
if (node.children[idx] == null) return false;
return dfs(word, index + 1, node.children[idx]);
}
}
}Complexity Analysis
Time Complexity:
-
addWord: O(M) where M is the length of the word. We traverse the trie one level per character, creating nodes as needed. Each level takes O(1) work. -
search(no dots): O(M) — we follow a single path through the trie, one character at a time. Each step is O(1). -
search(with dots): O(26^K × M) in the worst case, where K is the number of dot characters. Each dot forces us to explore up to 26 branches. With at most 2 dots (per the constraints), this is O(26^2 × M) = O(676 × M), which is effectively O(M).
Space Complexity: O(N × M × 26)
Each trie node stores an array of 26 children pointers. In the worst case (no shared prefixes), we create one node per character per word, so the total number of nodes is up to N × M. Each node uses O(26) space for its children array. In practice, prefix sharing significantly reduces the actual memory usage.