Design HashMap
Description
Design a HashMap data structure from scratch without using any built-in hash table libraries.
A HashMap stores key-value pairs and supports three core operations:
- put(key, value): Insert the pair
(key, value)into the map. If the key already exists, update its associated value to the new one. - get(key): Return the value mapped to the given key, or return
-1if the key does not exist in the map. - remove(key): Delete the key and its associated value from the map. If the key does not exist, do nothing.
Your task is to implement the MyHashMap class with these three methods, correctly handling insertions, lookups, updates, and deletions.
Examples
Example 1
Input:
["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"]
[[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]]
Output:
[null, null, null, 1, -1, null, 1, null, -1]
Explanation:
MyHashMap myHashMap = new MyHashMap();— Create an empty map.myHashMap.put(1, 1);— The map is now {1→1}.myHashMap.put(2, 2);— The map is now {1→1, 2→2}.myHashMap.get(1);— Returns 1 because key 1 maps to value 1.myHashMap.get(3);— Returns -1 because key 3 does not exist in the map.myHashMap.put(2, 1);— Key 2 already exists, so update its value from 2 to 1. The map is now {1→1, 2→1}.myHashMap.get(2);— Returns 1 because key 2 now maps to value 1 (after the update).myHashMap.remove(2);— Remove key 2. The map is now {1→1}.myHashMap.get(2);— Returns -1 because key 2 was removed.
Constraints
- 0 ≤ key, value ≤ 10^6
- At most 10^4 calls will be made to
put,get, andremove.
Editorial
Brute Force
Intuition
The simplest possible approach mirrors what we did for the HashSet problem but adapted for key-value pairs. Since keys range from 0 to 1,000,000, we can create an integer array of size 1,000,001 and use the key directly as the index.
Imagine a huge row of numbered mailboxes from 0 to 1,000,000. Each mailbox can hold one letter (the value). To store a value for key 42, just put the letter in mailbox 42. To retrieve it, open mailbox 42. To indicate a mailbox is empty, we store a special sentinel value like -1 (since all valid values are ≥ 0).
This is direct addressing — the key serves as the array index. It is extremely fast but wastes enormous memory because we allocate space for every possible key, even those we never use.
Step-by-Step Explanation
Let's trace through the operations from Example 1:
Step 1: Initialize an integer array data of size 1,000,001, all set to -1 (sentinel for "no mapping").
- data = [-1, -1, -1, -1, ...] (1,000,001 slots)
Step 2: put(1, 1) — Set data[1] = 1.
- data[1] is now 1. The map logically contains {1→1}.
Step 3: put(2, 2) — Set data[2] = 2.
- data[2] is now 2. The map contains {1→1, 2→2}.
Step 4: get(1) — Return data[1].
- data[1] = 1, which is not -1, so return 1.
Step 5: get(3) — Return data[3].
- data[3] = -1, meaning key 3 has no mapping. Return -1.
Step 6: put(2, 1) — Set data[2] = 1.
- data[2] was 2, now becomes 1. The value for key 2 is updated. Map: {1→1, 2→1}.
Step 7: get(2) — Return data[2].
- data[2] = 1. Return 1.
Step 8: remove(2) — Set data[2] = -1.
- data[2] is reset to sentinel. Map: {1→1}.
Step 9: get(2) — Return data[2].
- data[2] = -1. Return -1.
Direct Addressing Array — HashMap Operations — Watch how each put, get, and remove operation directly accesses the array at the key's index, using -1 as a sentinel for empty slots.
Algorithm
- Initialize: Create an integer array
dataof size 1,000,001, filled with -1 (sentinel value). - put(key, value): Set
data[key] = value. - get(key): Return
data[key]. If it equals -1, the key has no mapping. - remove(key): Set
data[key] = -1.
Code
class MyHashMap {
private:
vector<int> data;
public:
MyHashMap() {
data.assign(1000001, -1);
}
void put(int key, int value) {
data[key] = value;
}
int get(int key) {
return data[key];
}
void remove(int key) {
data[key] = -1;
}
};class MyHashMap:
def __init__(self):
self.data = [-1] * 1000001
def put(self, key: int, value: int) -> None:
self.data[key] = value
def get(self, key: int) -> int:
return self.data[key]
def remove(self, key: int) -> None:
self.data[key] = -1class MyHashMap {
private int[] data;
public MyHashMap() {
data = new int[1000001];
Arrays.fill(data, -1);
}
public void put(int key, int value) {
data[key] = value;
}
public int get(int key) {
return data[key];
}
public void remove(int key) {
data[key] = -1;
}
}Complexity Analysis
Time Complexity: O(1) per operation
Each of the three operations — put, get, and remove — performs a single array read or write at a known index. Array access by index is O(1).
Space Complexity: O(N) where N = 10^6 + 1
We allocate a fixed-size integer array of 1,000,001 elements regardless of how many key-value pairs are actually stored. Each element is an integer (typically 4 bytes), so this consumes approximately 4 MB of memory even when storing just a handful of mappings.
Why This Approach Is Not Efficient
The direct addressing approach achieves O(1) time per operation, but it suffers from severe space inefficiency.
With at most 10^4 operations, we can store at most 10^4 key-value pairs, yet we allocate space for 10^6 + 1 entries. Over 99% of the allocated memory goes unused. In real-world applications — where keys could be strings, UUIDs, or arbitrary objects — direct addressing is impossible because the key space is effectively infinite.
Additionally, this approach is fragile: it only works for non-negative integer keys within a pre-known range, and it uses -1 as a sentinel. If -1 were a valid value, the design would break.
The key insight: a proper hash map uses a hash function to compress the key space into a small number of buckets, and stores key-value pairs within each bucket using a linked list (chaining). This uses O(K) space where K is the number of stored entries, and achieves O(1) amortized time with a good hash function and bucket count.
Optimal Approach - Hash Function with Bucket Chaining
Intuition
A real hash map works like an apartment building with numbered floors. Every resident (key-value pair) is assigned a floor based on a formula: floor_number = key % total_floors. Multiple residents may end up on the same floor — this is a collision — but each floor has a hallway (linked list) where residents line up. When looking for someone, you go to their floor and walk down the hallway checking name tags.
The design has three components:
- Bucket array: An array of
bucket_countslots, each holding a list of (key, value) pairs. We choose a prime number like 769 for the bucket count to minimize clustering. - Hash function:
hash(key) = key % bucket_count. This maps any key to a bucket index. - Chaining: Each bucket stores a list of (key, value) tuples. On
put, we either update an existing key's value or append a new pair. Onget, we scan for the key. Onremove, we find and delete the pair.
The critical difference from a HashSet: each bucket stores pairs (key, value), not just keys. And put must handle the update case — if the key already exists, we overwrite its value rather than adding a duplicate.
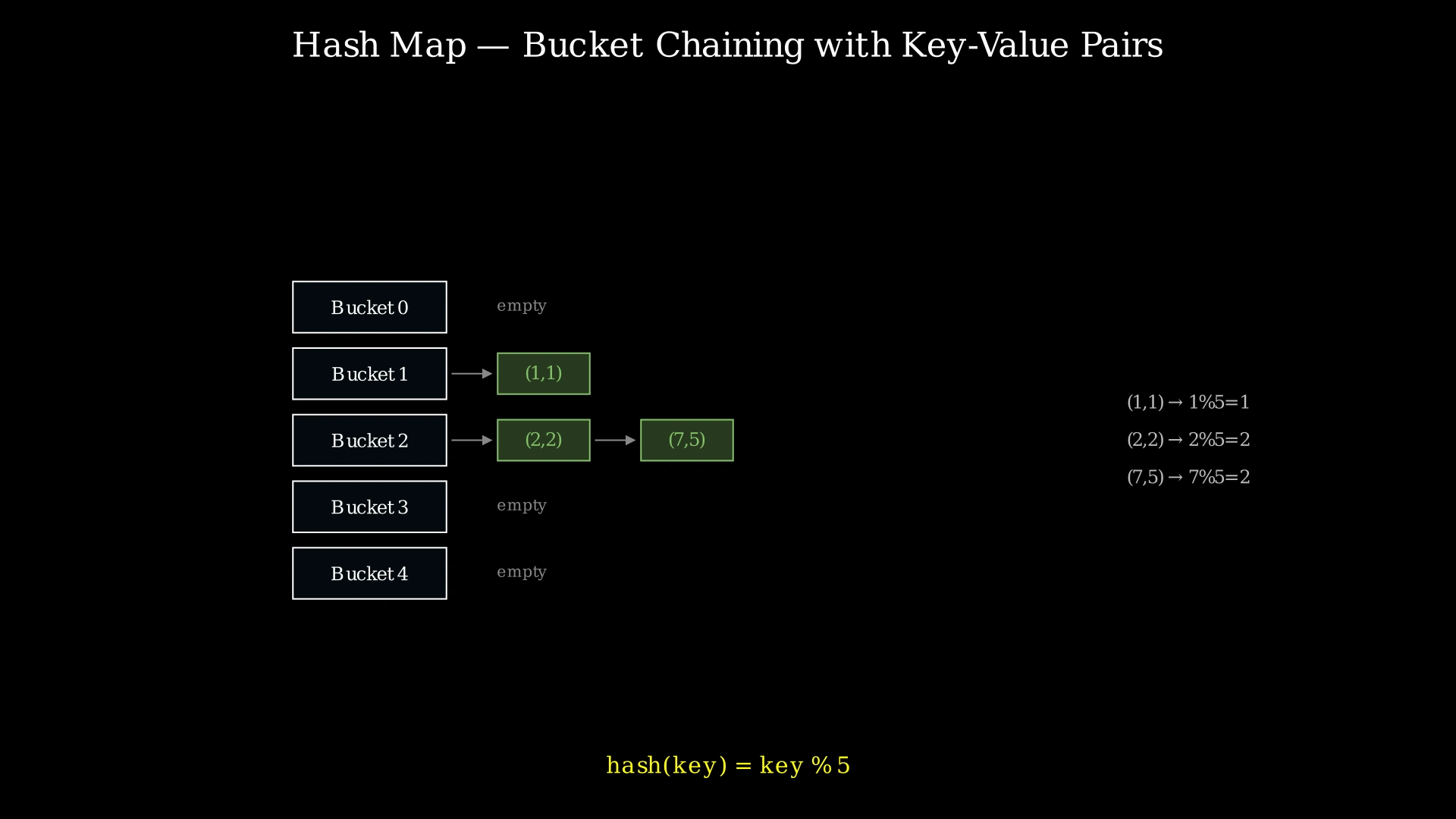
Step-by-Step Explanation
Let's trace through the Example 1 operations using bucket_count = 5 and hash(key) = key % 5:
Step 1: Initialize 5 empty buckets: [[], [], [], [], []].
Step 2: put(1, 1) — hash(1) = 1 % 5 = 1. Bucket 1 is empty, so append (1, 1).
- Buckets: [[], [(1,1)], [], [], []]
Step 3: put(2, 2) — hash(2) = 2 % 5 = 2. Bucket 2 is empty, so append (2, 2).
- Buckets: [[], [(1,1)], [(2,2)], [], []]
Step 4: get(1) — hash(1) = 1. Scan Bucket 1: [(1,1)]. Key 1 found! Return value 1.
Step 5: get(3) — hash(3) = 3. Scan Bucket 3: []. Empty bucket. Return -1.
Step 6: put(2, 1) — hash(2) = 2. Scan Bucket 2: [(2,2)]. Key 2 already exists with value 2. Update value to 1.
- Buckets: [[], [(1,1)], [(2,1)], [], []]
Step 7: get(2) — hash(2) = 2. Scan Bucket 2: [(2,1)]. Key 2 found! Return value 1 (the updated value).
Step 8: remove(2) — hash(2) = 2. Scan Bucket 2: [(2,1)]. Key 2 found. Remove the pair.
- Buckets: [[], [(1,1)], [], [], []]
Step 9: get(2) — hash(2) = 2. Scan Bucket 2: []. Empty. Return -1.
Hash Map with Bucket Chaining — Full Operation Trace — Watch how key-value pairs are stored in buckets via hashing, how put updates existing keys, and how remove deletes pairs from the chain.
Algorithm
- Initialize: Create an array of
bucket_countempty lists. Choose a prime number like 769 for the bucket count. - Hash function:
bucket_index = key % bucket_count. - put(key, value):
- Compute the bucket index.
- Scan the bucket's list for an existing pair with the same key.
- If found, update that pair's value.
- If not found, append a new (key, value) pair.
- get(key):
- Compute the bucket index.
- Scan the bucket's list for a pair with the matching key.
- If found, return the value. Otherwise, return -1.
- remove(key):
- Compute the bucket index.
- Scan the bucket's list for a pair with the matching key.
- If found, delete the pair. Otherwise, do nothing.
Code
class MyHashMap {
private:
static const int BUCKET_COUNT = 769;
vector<list<pair<int, int>>> buckets;
int hash(int key) {
return key % BUCKET_COUNT;
}
public:
MyHashMap() {
buckets.resize(BUCKET_COUNT);
}
void put(int key, int value) {
int idx = hash(key);
for (auto& p : buckets[idx]) {
if (p.first == key) {
p.second = value;
return;
}
}
buckets[idx].emplace_back(key, value);
}
int get(int key) {
int idx = hash(key);
for (auto& p : buckets[idx]) {
if (p.first == key) {
return p.second;
}
}
return -1;
}
void remove(int key) {
int idx = hash(key);
buckets[idx].remove_if([key](const pair<int, int>& p) {
return p.first == key;
});
}
};class MyHashMap:
def __init__(self):
self.bucket_count = 769
self.buckets = [[] for _ in range(self.bucket_count)]
def _hash(self, key: int) -> int:
return key % self.bucket_count
def put(self, key: int, value: int) -> None:
idx = self._hash(key)
for i, (k, v) in enumerate(self.buckets[idx]):
if k == key:
self.buckets[idx][i] = (key, value)
return
self.buckets[idx].append((key, value))
def get(self, key: int) -> int:
idx = self._hash(key)
for k, v in self.buckets[idx]:
if k == key:
return v
return -1
def remove(self, key: int) -> None:
idx = self._hash(key)
self.buckets[idx] = [(k, v) for k, v in self.buckets[idx] if k != key]class MyHashMap {
private static final int BUCKET_COUNT = 769;
private List<List<int[]>> buckets;
public MyHashMap() {
buckets = new ArrayList<>();
for (int i = 0; i < BUCKET_COUNT; i++) {
buckets.add(new LinkedList<>());
}
}
private int hash(int key) {
return key % BUCKET_COUNT;
}
public void put(int key, int value) {
int idx = hash(key);
for (int[] pair : buckets.get(idx)) {
if (pair[0] == key) {
pair[1] = value;
return;
}
}
buckets.get(idx).add(new int[]{key, value});
}
public int get(int key) {
int idx = hash(key);
for (int[] pair : buckets.get(idx)) {
if (pair[0] == key) {
return pair[1];
}
}
return -1;
}
public void remove(int key) {
int idx = hash(key);
buckets.get(idx).removeIf(pair -> pair[0] == key);
}
}Complexity Analysis
Time Complexity: O(N / K) per operation on average, where N is the number of stored key-value pairs and K is the bucket count.
With bucket_count = 769 and at most 10^4 operations, the average chain length per bucket is about 10^4 / 769 ≈ 13 elements. Scanning a chain of 13 elements is effectively constant. Under uniform hashing, this approaches O(1) amortized. In the worst case (all keys hash to the same bucket), operations degrade to O(N), but a prime bucket count makes this extremely unlikely.
Space Complexity: O(K + N) where K is the bucket count and N is the number of stored pairs.
We allocate K bucket lists upfront (769 in our implementation), and each of the N stored key-value pairs occupies one slot in some bucket's chain. This is dramatically more space-efficient than the direct addressing approach: with 100 stored pairs, we use roughly 769 + 100 ≈ 869 units of storage, versus 1,000,001 for the brute force array.