Clone Graph
Description
Given a reference to a node in a connected undirected graph, return a deep copy (clone) of the entire graph.
Each node in the graph has two properties:
val(an integer) — the node's valueneighbors(a list of Node references) — the nodes directly connected to it
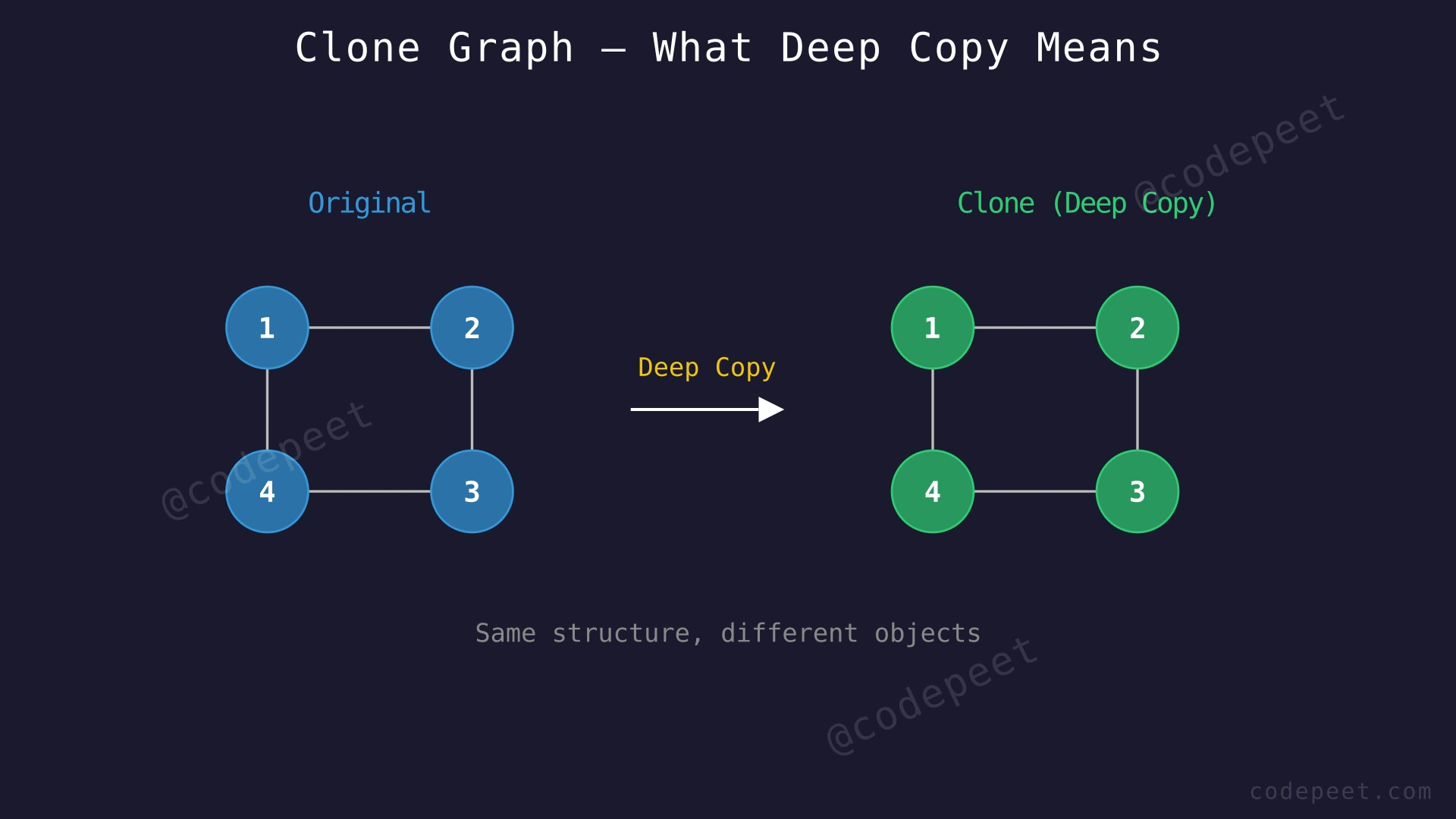
A deep copy means creating entirely new node objects with the same values and the same neighbor relationships. No node in the cloned graph should point to any node in the original graph — all references must be to the newly created clone nodes.
For simplicity, each node's value equals its 1-based index (the first node has val = 1, the second has val = 2, etc.). The graph is represented as an adjacency list. You are given a reference to node 1 and must return the clone of node 1.
Examples
Example 1
Input: adjList = [[2, 4], [1, 3], [2, 4], [1, 3]]
Output: [[2, 4], [1, 3], [2, 4], [1, 3]]
Explanation: The graph has 4 nodes. Node 1's neighbors are nodes 2 and 4. Node 2's neighbors are nodes 1 and 3. Node 3's neighbors are nodes 2 and 4. Node 4's neighbors are nodes 1 and 3. The cloned graph has exactly the same structure — every node has the same value and the same neighbor connections — but all node objects are newly created, not shared with the original.
Example 2
Input: adjList = [[]]
Output: [[]]
Explanation: The graph has a single node with val = 1 and no neighbors. The clone is a single new node with val = 1 and an empty neighbor list.
Example 3
Input: adjList = []
Output: []
Explanation: The graph is empty — there are no nodes at all. Return null (or None/null depending on the language).
Constraints
- 0 ≤ number of nodes ≤ 100
- 1 ≤ Node.val ≤ 100
- Node.val is unique for each node
- There are no repeated edges and no self-loops in the graph
- The graph is connected and all nodes can be visited starting from the given node
Editorial
Brute Force
Intuition
The first instinct might be to traverse the graph and create a copy of each node as you encounter it. But graphs have a fundamental challenge that arrays and trees don't: cycles. An undirected graph always has cycles (every edge creates a path back), so if you naively follow neighbors, you'll visit the same node again and again, creating infinite copies.
The solution to this is a visited map — a hash map that maps each original node to its clone. Before cloning a node, check: "Have I already cloned this node?" If yes, return the existing clone. If no, create a new clone and record it in the map.
The most natural way to traverse a graph is Depth-First Search (DFS) using recursion. Start from the given node, clone it, then recursively clone each of its neighbors. The hash map ensures we never clone the same node twice and that all neighbor references point to clone nodes, not originals.
Think of it like copying a social network. You start with one person, copy their profile, then go to their first friend, copy that profile, go to that friend's first friend, and so on. The map is your checklist — "I already copied Alice, so when Bob's friend list includes Alice, I use the copy I already made."
Step-by-Step Explanation
Let's trace through with the graph from Example 1: adjList = [[2, 4], [1, 3], [2, 4], [1, 3]]
This is a 4-node graph: 1—2, 2—3, 3—4, 4—1 (a square/cycle).
Step 1: Start DFS from node 1. Node 1 is not in the map. Create clone of node 1 (val=1). Store in map: {1 → clone1}.
Step 2: Process neighbor 2 of node 1. Node 2 is not in the map. Create clone of node 2 (val=2). Store: {1 → clone1, 2 → clone2}.
Step 3: Process neighbor 1 of node 2. Node 1 IS in the map — return existing clone1. Add clone1 to clone2's neighbors.
Step 4: Process neighbor 3 of node 2. Node 3 is not in the map. Create clone of node 3 (val=3). Store: {1 → clone1, 2 → clone2, 3 → clone3}.
Step 5: Process neighbor 2 of node 3. Node 2 IS in the map — return existing clone2. Add clone2 to clone3's neighbors.
Step 6: Process neighbor 4 of node 3. Node 4 is not in the map. Create clone of node 4 (val=4). Store: {1 → clone1, 2 → clone2, 3 → clone3, 4 → clone4}.
Step 7: Process neighbor 1 of node 4. Node 1 IS in the map — return clone1. Add clone1 to clone4's neighbors.
Step 8: Process neighbor 3 of node 4. Node 3 IS in the map — return clone3. Add clone3 to clone4's neighbors. Node 4 fully processed.
Step 9: Backtrack to node 3 — clone3's neighbors now complete: [clone2, clone4].
Step 10: Backtrack to node 2 — clone2's neighbors now complete: [clone1, clone3].
Step 11: Back to node 1, process neighbor 4. Node 4 IS in the map — return clone4. Add clone4 to clone1's neighbors. clone1's neighbors: [clone2, clone4].
Result: Return clone1. All four clone nodes are connected identically to the original graph.
DFS Cloning — Recursive Deep Copy with Hash Map — Watch how DFS recursively visits each node, creates a clone, and uses a hash map to avoid re-cloning nodes encountered through cycles.
Algorithm
- If the input node is null, return null
- Create a hash map
clonedmapping original nodes to their clones - Define a recursive function
dfs(node):
a. Ifnodeis already incloned, returncloned[node]
b. Create a new clone node with the same value
c. Store the clone incloned[node] = clone
d. For each neighbor ofnode:- Recursively call
dfs(neighbor) - Add the returned clone to the current clone's neighbor list
e. Return the clone
- Recursively call
- Call
dfs(given_node)and return the result
Code
#include <vector>
#include <unordered_map>
using namespace std;
class Node {
public:
int val;
vector<Node*> neighbors;
Node() { val = 0; neighbors = vector<Node*>(); }
Node(int _val) { val = _val; neighbors = vector<Node*>(); }
Node(int _val, vector<Node*> _neighbors) { val = _val; neighbors = _neighbors; }
};
class Solution {
unordered_map<Node*, Node*> cloned;
public:
Node* cloneGraph(Node* node) {
if (!node) return nullptr;
// If already cloned, return the existing clone
if (cloned.find(node) != cloned.end()) {
return cloned[node];
}
// Create a new clone
Node* clone = new Node(node->val);
cloned[node] = clone;
// Recursively clone all neighbors
for (Node* neighbor : node->neighbors) {
clone->neighbors.push_back(cloneGraph(neighbor));
}
return clone;
}
};class Node:
def __init__(self, val=0, neighbors=None):
self.val = val
self.neighbors = neighbors if neighbors is not None else []
class Solution:
def cloneGraph(self, node: 'Node') -> 'Node':
if not node:
return None
cloned = {}
def dfs(original):
# If already cloned, return existing clone
if original in cloned:
return cloned[original]
# Create a new clone
clone = Node(original.val)
cloned[original] = clone
# Recursively clone all neighbors
for neighbor in original.neighbors:
clone.neighbors.append(dfs(neighbor))
return clone
return dfs(node)import java.util.*;
class Node {
public int val;
public List<Node> neighbors;
public Node() { val = 0; neighbors = new ArrayList<>(); }
public Node(int val) { this.val = val; neighbors = new ArrayList<>(); }
public Node(int val, ArrayList<Node> neighbors) { this.val = val; this.neighbors = neighbors; }
}
class Solution {
private Map<Node, Node> cloned = new HashMap<>();
public Node cloneGraph(Node node) {
if (node == null) return null;
// If already cloned, return existing clone
if (cloned.containsKey(node)) {
return cloned.get(node);
}
// Create a new clone
Node clone = new Node(node.val);
cloned.put(node, clone);
// Recursively clone all neighbors
for (Node neighbor : node.neighbors) {
clone.neighbors.add(cloneGraph(neighbor));
}
return clone;
}
}Complexity Analysis
Time Complexity: O(V + E)
Where V is the number of vertices (nodes) and E is the number of edges. Each node is visited exactly once (the hash map prevents revisiting), and for each node we process all its edges. Since every edge is processed from both endpoints in an undirected graph, total edge processing is 2E, but that's still O(E).
Space Complexity: O(V)
The hash map stores V entries (one per node). The recursion stack can go up to V deep in the worst case (a graph shaped like a long chain). The cloned graph itself uses O(V + E) space, but that's the output and typically not counted.
Why This Approach Is Not Efficient
The DFS approach is actually optimal in terms of time complexity — O(V + E) is the best possible since we must visit every node and edge at least once. However, it has a practical limitation: recursion depth.
For large graphs with up to 100 nodes, DFS could create a recursion stack 100 levels deep. While this is fine for the given constraints, in general:
- A graph with thousands of nodes could cause a stack overflow in languages with limited recursion depth (like Python's default 1000-level limit)
- Each recursive call adds overhead (function call, local variables on the stack)
- The traversal order is determined by the call stack, which is harder to control
An iterative approach using BFS with an explicit queue avoids the recursion stack entirely. It processes nodes level by level, uses heap memory (which is much larger than stack memory), and gives us explicit control over the traversal order. The time and space complexity remain the same, but the approach is more robust for large inputs.
Optimal Approach - BFS with Hash Map
Intuition
Instead of diving deep with recursion, we can process the graph level by level using a queue (BFS). The idea is:
- Clone the starting node and put it in the queue
- While the queue is not empty, dequeue a node
- For each of its neighbors:
- If the neighbor hasn't been cloned, clone it, store it in the map, and enqueue it
- Add the clone of the neighbor to the current clone's neighbor list
This is like copying a city map by starting at one intersection, copying all the roads from that intersection, then moving to each connected intersection and copying its roads. You keep a checklist (the hash map) so you never copy the same intersection twice.
BFS naturally handles cycles because we check the map before processing any neighbor. If a neighbor is already cloned, we simply link to the existing clone without enqueuing it again.
Step-by-Step Explanation
Let's trace through with adjList = [[2, 4], [1, 3], [2, 4], [1, 3]] (same graph as Example 1):
Step 1: Clone node 1 → create clone1. Store in map: {1 → clone1}. Enqueue node 1. Queue: [1].
Step 2: Dequeue node 1. Process its neighbors: [2, 4].
Step 3: Neighbor 2 is not in map → clone it → create clone2. Store: {1 → clone1, 2 → clone2}. Enqueue node 2. Add clone2 to clone1's neighbors. Queue: [2].
Step 4: Neighbor 4 is not in map → clone it → create clone4. Store: {1 → clone1, 2 → clone2, 4 → clone4}. Enqueue node 4. Add clone4 to clone1's neighbors. Queue: [2, 4]. clone1's neighbors: [clone2, clone4] ✓
Step 5: Dequeue node 2. Process its neighbors: [1, 3].
Step 6: Neighbor 1 IS in map → add clone1 to clone2's neighbors. Do not enqueue.
Step 7: Neighbor 3 is not in map → clone it → create clone3. Store. Enqueue node 3. Add clone3 to clone2's neighbors. Queue: [4, 3]. clone2's neighbors: [clone1, clone3] ✓
Step 8: Dequeue node 4. Process its neighbors: [1, 3].
Step 9: Neighbor 1 IS in map → add clone1 to clone4's neighbors. Neighbor 3 IS in map → add clone3 to clone4's neighbors. Queue: [3]. clone4's neighbors: [clone1, clone3] ✓
Step 10: Dequeue node 3. Process its neighbors: [2, 4].
Step 11: Neighbor 2 IS in map → add clone2 to clone3's neighbors. Neighbor 4 IS in map → add clone4 to clone3's neighbors. Queue: []. clone3's neighbors: [clone2, clone4] ✓
Result: Queue empty. Return clone1. All nodes cloned and linked correctly.
BFS Cloning — Iterative Level-by-Level Deep Copy — Watch how BFS processes nodes level by level using a queue, cloning each node exactly once and linking neighbors through the hash map.
Algorithm
- If the input node is null, return null
- Create a hash map
clonedmapping original nodes to their clones - Clone the starting node, store it in the map, and enqueue it
- While the queue is not empty:
a. Dequeue a nodecurrent
b. For each neighbor ofcurrent:- If the neighbor is NOT in the map:
- Clone it, store in map, and enqueue it
- Add
cloned[neighbor]tocloned[current]'s neighbor list
- If the neighbor is NOT in the map:
- Return
cloned[starting_node]
Code
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
class Node {
public:
int val;
vector<Node*> neighbors;
Node() { val = 0; neighbors = vector<Node*>(); }
Node(int _val) { val = _val; neighbors = vector<Node*>(); }
Node(int _val, vector<Node*> _neighbors) { val = _val; neighbors = _neighbors; }
};
class Solution {
public:
Node* cloneGraph(Node* node) {
if (!node) return nullptr;
unordered_map<Node*, Node*> cloned;
queue<Node*> q;
// Clone the starting node
cloned[node] = new Node(node->val);
q.push(node);
while (!q.empty()) {
Node* current = q.front();
q.pop();
for (Node* neighbor : current->neighbors) {
// If neighbor not yet cloned, clone and enqueue
if (cloned.find(neighbor) == cloned.end()) {
cloned[neighbor] = new Node(neighbor->val);
q.push(neighbor);
}
// Link the cloned neighbor
cloned[current]->neighbors.push_back(cloned[neighbor]);
}
}
return cloned[node];
}
};from collections import deque
class Node:
def __init__(self, val=0, neighbors=None):
self.val = val
self.neighbors = neighbors if neighbors is not None else []
class Solution:
def cloneGraph(self, node: 'Node') -> 'Node':
if not node:
return None
cloned = {}
queue = deque()
# Clone the starting node
cloned[node] = Node(node.val)
queue.append(node)
while queue:
current = queue.popleft()
for neighbor in current.neighbors:
# If neighbor not yet cloned, clone and enqueue
if neighbor not in cloned:
cloned[neighbor] = Node(neighbor.val)
queue.append(neighbor)
# Link the cloned neighbor
cloned[current].neighbors.append(cloned[neighbor])
return cloned[node]import java.util.*;
class Node {
public int val;
public List<Node> neighbors;
public Node() { val = 0; neighbors = new ArrayList<>(); }
public Node(int val) { this.val = val; neighbors = new ArrayList<>(); }
public Node(int val, ArrayList<Node> neighbors) { this.val = val; this.neighbors = neighbors; }
}
class Solution {
public Node cloneGraph(Node node) {
if (node == null) return null;
Map<Node, Node> cloned = new HashMap<>();
Queue<Node> queue = new LinkedList<>();
// Clone the starting node
cloned.put(node, new Node(node.val));
queue.add(node);
while (!queue.isEmpty()) {
Node current = queue.poll();
for (Node neighbor : current.neighbors) {
// If neighbor not yet cloned, clone and enqueue
if (!cloned.containsKey(neighbor)) {
cloned.put(neighbor, new Node(neighbor.val));
queue.add(neighbor);
}
// Link the cloned neighbor
cloned.get(current).neighbors.add(cloned.get(neighbor));
}
}
return cloned.get(node);
}
}Complexity Analysis
Time Complexity: O(V + E)
Where V is the number of nodes and E is the number of edges. Each node is dequeued exactly once from the queue, and for each node we iterate through its neighbor list. The total work across all iterations is proportional to the sum of all neighbor lists, which equals 2E (each edge appears in two adjacency lists). So the total time is O(V + 2E) = O(V + E).
Space Complexity: O(V)
The hash map stores one entry per node (V entries). The queue holds at most V nodes simultaneously (in the worst case of a star graph where all nodes are neighbors of the center). Unlike DFS, there is no recursion stack — all memory is on the heap, making this approach safer for large graphs.