Word Search II
Description
You are given a two-dimensional grid of characters (called a board) with m rows and n columns, and a list of strings called words. Your task is to find and return all the words from the list that can be formed on the board.
A word is considered "found" on the board if you can trace it by starting at any cell and moving to horizontally or vertically adjacent cells (up, down, left, right), selecting one letter per cell. Each cell in the board may be used at most once per word — you cannot revisit a cell while constructing the same word.
Return the list of all words from the input list that exist on the board. The order of the returned words does not matter.
Examples
Example 1
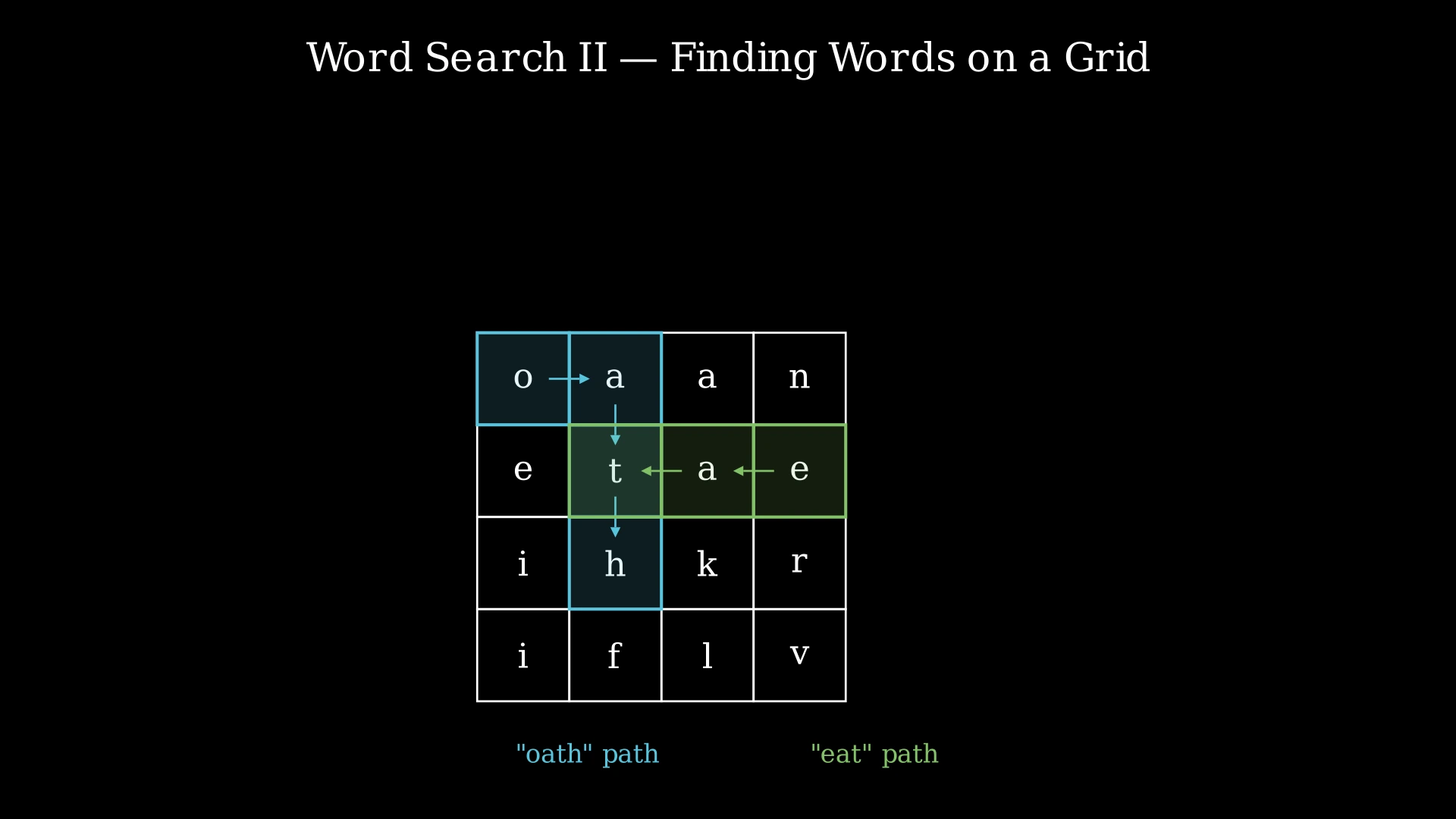
Input:
board = [["o","a","a","n"],
["e","t","a","e"],
["i","h","k","r"],
["i","f","l","v"]]
words = ["oath","pea","eat","rain"]
Output: ["eat", "oath"]
Explanation:
- "oath" can be formed by following the path: (0,0)→(1,0)→(1,1)→(2,1), tracing through o→a→t→h. Each move is to an adjacent cell, and no cell is reused.
- "eat" can be formed by the path: (1,3)→(1,2)→(1,1), tracing through e→a→t. Again, all moves are to adjacent cells.
- "pea" cannot be formed — while 'p' does not even appear on the board.
- "rain" cannot be formed — although 'r' is at (2,3), 'a' is at (1,2) or (0,1)/(0,2), but there is no valid adjacent path spelling out the full word.
Example 2
Input:
board = [["a","b"],
["c","d"]]
words = ["abcb"]
Output: []
Explanation: The word "abcb" requires the path a→b→c→b. Starting at (0,0)='a', moving right to (0,1)='b', then down to (1,1)='d' — but that gives 'd', not 'c'. The path a(0,0)→b(0,1)→... cannot reach 'c' at (1,0) without going through non-adjacent cells. Even if we could reach 'c', we would need to return to 'b' at (0,1), but that cell was already used. So the word cannot be formed.
Constraints
- m == board.length
- n == board[i].length
- 1 ≤ m, n ≤ 12
- board[i][j] is a lowercase English letter.
- 1 ≤ words.length ≤ 3 × 10^4
- 1 ≤ words[i].length ≤ 10
- words[i] consists of lowercase English letters.
- All the strings of words are unique.
Editorial
Brute Force
Intuition
The most straightforward approach is to treat each word independently. For every word in the list, we search the entire board to see if that word can be formed.
For a single word, we try starting from every cell on the board. From each starting cell, if the first character matches, we perform a depth-first search (DFS), exploring all four neighboring directions (up, down, left, right). At each step, we check if the next character matches, mark the current cell as visited (to prevent reuse), and continue recursively. If we reach the end of the word, it is found. If we hit a dead end, we backtrack by unmarking the cell.
This is essentially the classic "Word Search" problem (LeetCode 79), repeated for every word in the list. Think of it like using a magnifying glass to trace each word separately on a letter grid — you start fresh for every word, scanning the entire board each time.
Step-by-Step Explanation
Let's trace the search for the word "eat" on the board:
o a a n
e t a e
i h k r
i f l v
Step 1: We need to find all cells containing 'e' (the first letter). 'e' appears at (1,0) and (1,3).
Step 2: Try starting DFS from (1,0) where board[1][0]='e'. Mark (1,0) as visited.
- Need next character 'a'. Check neighbors: (0,0)='o' ✗, (2,0)='i' ✗, (1,1)='t' ✗. No neighbor has 'a'. Dead end — backtrack, unmark (1,0).
Step 3: Try starting DFS from (1,3) where board[1][3]='e'. Mark (1,3) as visited.
- Need next character 'a'. Check neighbors: (0,3)='n' ✗, (2,3)='r' ✗, (1,2)='a' ✓. Move to (1,2).
Step 4: At (1,2), board[1][2]='a'. Mark (1,2) as visited.
- Need next character 't'. Check neighbors: (0,2)='a' ✗, (2,2)='k' ✗, (1,1)='t' ✓, (1,3) already visited. Move to (1,1).
Step 5: At (1,1), board[1][1]='t'. Mark (1,1) as visited.
- We have matched all 3 characters of "eat". The word is found!
Step 6: Add "eat" to the result list. Continue searching for remaining words.
We repeat this entire process for each of the W words in the list.
Brute Force DFS — Searching for "eat" on the Board — Watch how DFS explores the grid cell by cell, backtracking when a path fails, until it finds a valid path spelling out the word.
Algorithm
- Initialize an empty result list.
- For each word in the words list:
a. For each cell (r, c) in the board:- If
board[r][c]equals the first character of the word, start a DFS from (r, c).
b. DFS(r, c, index): - If
index == len(word), the word is fully matched — returntrue. - If (r, c) is out of bounds, or the cell is already visited, or
board[r][c] ≠ word[index], returnfalse. - Mark (r, c) as visited (e.g., replace with '#').
- Recursively call DFS on all 4 neighbors with
index + 1. - Unmark (r, c) (restore original character).
- Return
trueif any recursive call returnedtrue.
c. If any starting cell yieldstrue, add the word to results.
- If
- Return the result list.
Code
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
vector<string> result;
int m = board.size(), n = board[0].size();
for (const string& word : words) {
bool found = false;
for (int r = 0; r < m && !found; r++) {
for (int c = 0; c < n && !found; c++) {
if (board[r][c] == word[0]) {
if (dfs(board, word, r, c, 0)) {
result.push_back(word);
found = true;
}
}
}
}
}
return result;
}
private:
bool dfs(vector<vector<char>>& board, const string& word, int r, int c, int idx) {
if (idx == word.size()) return true;
if (r < 0 || r >= board.size() || c < 0 || c >= board[0].size()) return false;
if (board[r][c] != word[idx]) return false;
char temp = board[r][c];
board[r][c] = '#';
bool found = dfs(board, word, r + 1, c, idx + 1) ||
dfs(board, word, r - 1, c, idx + 1) ||
dfs(board, word, r, c + 1, idx + 1) ||
dfs(board, word, r, c - 1, idx + 1);
board[r][c] = temp;
return found;
}
};class Solution:
def findWords(self, board: list[list[str]], words: list[str]) -> list[str]:
m, n = len(board), len(board[0])
result = []
def dfs(r, c, idx, word):
if idx == len(word):
return True
if r < 0 or r >= m or c < 0 or c >= n:
return False
if board[r][c] != word[idx]:
return False
temp = board[r][c]
board[r][c] = '#'
found = (dfs(r + 1, c, idx + 1, word) or
dfs(r - 1, c, idx + 1, word) or
dfs(r, c + 1, idx + 1, word) or
dfs(r, c - 1, idx + 1, word))
board[r][c] = temp
return found
for word in words:
found = False
for r in range(m):
for c in range(n):
if board[r][c] == word[0] and dfs(r, c, 0, word):
result.append(word)
found = True
break
if found:
break
return resultimport java.util.ArrayList;
import java.util.List;
class Solution {
public List<String> findWords(char[][] board, String[] words) {
List<String> result = new ArrayList<>();
int m = board.length, n = board[0].length;
for (String word : words) {
boolean found = false;
for (int r = 0; r < m && !found; r++) {
for (int c = 0; c < n && !found; c++) {
if (board[r][c] == word.charAt(0)) {
if (dfs(board, word, r, c, 0)) {
result.add(word);
found = true;
}
}
}
}
}
return result;
}
private boolean dfs(char[][] board, String word, int r, int c, int idx) {
if (idx == word.length()) return true;
if (r < 0 || r >= board.length || c < 0 || c >= board[0].length) return false;
if (board[r][c] != word.charAt(idx)) return false;
char temp = board[r][c];
board[r][c] = '#';
boolean found = dfs(board, word, r + 1, c, idx + 1) ||
dfs(board, word, r - 1, c, idx + 1) ||
dfs(board, word, r, c + 1, idx + 1) ||
dfs(board, word, r, c - 1, idx + 1);
board[r][c] = temp;
return found;
}
}Complexity Analysis
Time Complexity: O(W × M × N × 4^L)
For each of the W words, we scan all M×N cells as potential starting points. From each starting cell, the DFS can branch into 4 directions at each level, and the maximum depth is L (the word length). So each word search takes O(M × N × 4^L). With W words, total is O(W × M × N × 4^L).
With W up to 3×10^4, M and N up to 12, and L up to 10, the worst case is enormous: 3×10^4 × 144 × 4^10 ≈ 4.5 × 10^12, which is far too slow.
Space Complexity: O(L)
The recursion stack goes at most L levels deep (the length of the word being searched). We modify the board in-place for visited tracking, so no extra grid is needed.
Why This Approach Is Not Efficient
The brute force searches for each word completely independently. If you have 30,000 words and a 12×12 board, you perform 30,000 separate DFS traversals across the grid. This is wildly redundant because:
-
Repeated work: Many words share common prefixes (e.g., "oath" and "oat" both start with "oat"). The brute force traces the same prefix path from scratch for each word.
-
No early termination: When exploring a path like "xyz..." on the board, the brute force has no way to know that no word in the list starts with "xyz". It continues the DFS even when the path is guaranteed to be a dead end for all words.
-
Per-word overhead: Each of the W words triggers a full M×N scan of starting cells.
Key insight: instead of searching for one word at a time, we should search for all words simultaneously. If we build a Trie from all words, we can traverse the board once and check at each cell whether the current path is a prefix of any word. If no word has the current prefix, we prune that path immediately — saving enormous amounts of work.
Optimal Approach - Trie + Backtracking
Intuition
Instead of searching for each word individually, we flip the problem: build a Trie containing all the target words, then traverse the board once, using the Trie to guide which paths are worth exploring.
Here is the key idea:
- Build a Trie from all words in the input list. Each path from root to a marked node represents a complete word.
- Start DFS from every cell on the board. At each cell, check if the current character matches any child in the current Trie node.
- Follow the Trie as you explore the board. If the Trie node has a child for the current board character, continue the DFS. If not, prune the path — no word can possibly be formed down this route.
- When you reach a Trie node marked as end-of-word, you have found a complete word. Add it to the result.
- Optimization — prune found words: Once a word is found, remove its end-of-word marker (and optionally prune leaf nodes) to avoid finding duplicates and reduce future search space.
Think of it like having a cheat sheet (the Trie) while playing a word-search puzzle. Instead of looking for one word at a time, you trace paths on the board and consult your cheat sheet at each step: "Is this prefix leading anywhere useful?" If not, you stop immediately and try a different direction.
Step-by-Step Explanation
Let's trace with board and words = ["oath", "pea", "eat", "rain"].
Phase 1: Build the Trie
Step 1: Insert "oath" → root → o → a → t → h (mark h as end, store word "oath").
Step 2: Insert "pea" → root → p → e → a (mark a as end, store word "pea").
Step 3: Insert "eat" → root → e → a → t (mark t as end, store word "eat").
Step 4: Insert "rain" → root → r → a → i → n (mark n as end, store word "rain").
The trie root now has children: 'o', 'p', 'e', 'r'.
Phase 2: DFS from each cell
Step 5: Start at cell (0,0)='o'. Trie root has child 'o' → enter it. Mark (0,0) visited.
Step 6: At (0,0), Trie node 'o' has child 'a'. Check neighbors: (0,1)='a' ✓. Move to (0,1), enter Trie child 'a'. Mark (0,1) visited.
Step 7: At (0,1), Trie node 'o→a' has child 't'. Check neighbors: (1,1)='t' ✓. Move to (1,1), enter Trie child 't'. Mark (1,1) visited.
Step 8: At (1,1), Trie node 'o→a→t' has child 'h'. Check neighbors: (2,1)='h' ✓. Move to (2,1), enter Trie child 'h'. Mark (2,1) visited.
Step 9: At (2,1), Trie node 'o→a→t→h' is marked as end-of-word with word "oath". Add "oath" to result! Remove end-of-word marker to avoid duplicates. Backtrack.
Step 10: Continue DFS from other cells. Eventually reach (1,3)='e'. Trie root has child 'e' → enter. Follow path e→a→t, find "eat". Add to result.
Step 11: "pea" — 'p' never appears on the board, so the Trie 'p' branch is never entered. "rain" — while 'r' exists at (2,3), the adjacent cells cannot spell out "rain" in sequence. Neither word is found.
Result: ["oath", "eat"]
Trie-Guided DFS — Finding "oath" on the Board — Watch how the DFS follows the Trie structure to efficiently trace the word "oath" through adjacent cells on the board, pruning paths that don't match any word prefix.
Algorithm
Phase 1 — Build the Trie:
- Create a Trie node class with a dictionary of children and an optional
wordfield. - For each word, insert it into the Trie character by character.
- At the end of each word, store the complete word string in the final Trie node.
Phase 2 — DFS with Trie guidance:
- Initialize an empty result list.
- For each cell (r, c) on the board:
- If the Trie root has a child matching
board[r][c], start a DFS.
- If the Trie root has a child matching
- DFS(r, c, trieNode):
- If (r, c) is out of bounds or visited, return.
- Let
char = board[r][c]. IftrieNodedoes not havecharas a child, return (prune). - Move to
childNode = trieNode.children[char]. - If
childNode.wordis not null, add it to results and setchildNode.word = null(prevent duplicates). - Mark (r, c) as visited.
- Recurse on all 4 neighbors with
childNode. - Unmark (r, c).
- Pruning optimization: If
childNodehas no remaining children, remove it fromtrieNode.childrento shrink the Trie.
- Return the result list.
Code
#include <vector>
#include <string>
#include <unordered_map>
using namespace std;
struct TrieNode {
unordered_map<char, TrieNode*> children;
string word = "";
};
class Solution {
public:
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
TrieNode* root = new TrieNode();
// Build Trie
for (const string& w : words) {
TrieNode* node = root;
for (char c : w) {
if (node->children.find(c) == node->children.end()) {
node->children[c] = new TrieNode();
}
node = node->children[c];
}
node->word = w;
}
vector<string> result;
int m = board.size(), n = board[0].size();
for (int r = 0; r < m; r++) {
for (int c = 0; c < n; c++) {
dfs(board, r, c, root, result);
}
}
return result;
}
private:
void dfs(vector<vector<char>>& board, int r, int c, TrieNode* node, vector<string>& result) {
if (r < 0 || r >= board.size() || c < 0 || c >= board[0].size()) return;
char ch = board[r][c];
if (ch == '#' || node->children.find(ch) == node->children.end()) return;
TrieNode* child = node->children[ch];
if (!child->word.empty()) {
result.push_back(child->word);
child->word = "";
}
board[r][c] = '#';
dfs(board, r + 1, c, child, result);
dfs(board, r - 1, c, child, result);
dfs(board, r, c + 1, child, result);
dfs(board, r, c - 1, child, result);
board[r][c] = ch;
// Pruning: remove leaf nodes
if (child->children.empty()) {
node->children.erase(ch);
}
}
};class TrieNode:
def __init__(self):
self.children = {}
self.word = None
class Solution:
def findWords(self, board: list[list[str]], words: list[str]) -> list[str]:
# Build Trie
root = TrieNode()
for word in words:
node = root
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.word = word
m, n = len(board), len(board[0])
result = []
def dfs(r, c, node):
if r < 0 or r >= m or c < 0 or c >= n:
return
char = board[r][c]
if char == '#' or char not in node.children:
return
child = node.children[char]
if child.word is not None:
result.append(child.word)
child.word = None # avoid duplicates
board[r][c] = '#' # mark visited
dfs(r + 1, c, child)
dfs(r - 1, c, child)
dfs(r, c + 1, child)
dfs(r, c - 1, child)
board[r][c] = char # restore
# Pruning: remove childless nodes
if not child.children:
del node.children[char]
for r in range(m):
for c in range(n):
dfs(r, c, root)
return resultimport java.util.*;
class TrieNode {
Map<Character, TrieNode> children = new HashMap<>();
String word = null;
}
class Solution {
private List<String> result = new ArrayList<>();
public List<String> findWords(char[][] board, String[] words) {
// Build Trie
TrieNode root = new TrieNode();
for (String w : words) {
TrieNode node = root;
for (char c : w.toCharArray()) {
node.children.putIfAbsent(c, new TrieNode());
node = node.children.get(c);
}
node.word = w;
}
int m = board.length, n = board[0].length;
for (int r = 0; r < m; r++) {
for (int c = 0; c < n; c++) {
dfs(board, r, c, root);
}
}
return result;
}
private void dfs(char[][] board, int r, int c, TrieNode node) {
if (r < 0 || r >= board.length || c < 0 || c >= board[0].length) return;
char ch = board[r][c];
if (ch == '#' || !node.children.containsKey(ch)) return;
TrieNode child = node.children.get(ch);
if (child.word != null) {
result.add(child.word);
child.word = null;
}
board[r][c] = '#';
dfs(board, r + 1, c, child);
dfs(board, r - 1, c, child);
dfs(board, r, c + 1, child);
dfs(board, r, c - 1, child);
board[r][c] = ch;
// Pruning
if (child.children.isEmpty()) {
node.children.remove(ch);
}
}
}Complexity Analysis
Time Complexity: O(M × N × 4 × 3^(L-1))
We start DFS from each of the M×N cells. From each cell, the first step can go in 4 directions, but subsequent steps can only go in 3 directions (we cannot revisit the cell we came from). The DFS depth is at most L (maximum word length). This gives O(M × N × 4 × 3^(L-1)) in the worst case.
Critically, the Trie provides early pruning: if a prefix does not exist in the Trie, the DFS terminates immediately for that branch. In practice, this reduces the explored paths dramatically compared to brute force. The progressive pruning of found words further shrinks the Trie over time, making later searches even faster.
With M, N ≤ 12 and L ≤ 10, the upper bound is 144 × 4 × 3^9 ≈ 11.3 million, which is very manageable.
Space Complexity: O(W × L + L)
The Trie stores all W words of average length L, requiring O(W × L) space in the worst case (no shared prefixes). The recursion stack uses O(L) space. In practice, shared prefixes reduce the Trie's actual memory footprint significantly.