Course Schedule II
Description
You are given a total of numCourses courses labeled from 0 to numCourses - 1. You are also given an array prerequisites where each element prerequisites[i] = [aᵢ, bᵢ] indicates that you must complete course bᵢ before you can take course aᵢ.
For example, the pair [0, 1] means you must finish course 1 before you can start course 0.
Return a valid ordering of all courses such that every prerequisite relationship is respected. If multiple valid orderings exist, return any one of them. If it is impossible to complete all courses — for instance, because of circular dependencies — return an empty array.
Examples
Example 1
Input: numCourses = 2, prerequisites = [[1, 0]]
Output: [0, 1]
Explanation: There are 2 courses in total. Course 1 requires course 0 as a prerequisite, so you must complete course 0 first. The only valid ordering is [0, 1].
Example 2
Input: numCourses = 4, prerequisites = [[1, 0], [2, 0], [3, 1], [3, 2]]
Output: [0, 2, 1, 3]
Explanation: There are 4 courses. Course 1 and course 2 both require course 0. Course 3 requires both course 1 and course 2. You must take course 0 first since it has no prerequisites. Then you can take course 1 and course 2 in either order. Finally, course 3 can be taken after both 1 and 2 are complete. Valid orderings include [0, 1, 2, 3] and [0, 2, 1, 3].
Example 3
Input: numCourses = 1, prerequisites = []
Output: [0]
Explanation: There is only one course and no prerequisites. The ordering is simply [0].
Constraints
- 1 ≤ numCourses ≤ 2000
- 0 ≤ prerequisites.length ≤ numCourses × (numCourses - 1)
- prerequisites[i].length == 2
- 0 ≤ aᵢ, bᵢ < numCourses
- aᵢ ≠ bᵢ
- All pairs [aᵢ, bᵢ] are distinct
Editorial
Brute Force
Intuition
The most straightforward way to think about this problem is: we need to find an ordering of courses where every course appears after all of its prerequisites. A naive approach is to simulate picking courses one at a time.
Imagine you have a to-do list of courses. At each step, you scan the entire list to find a course whose prerequisites have all been completed. You pick that course, mark it as done, and repeat. If at some point no available course can be found but courses remain, a circular dependency must exist and the task is impossible.
This is like standing at a buffet line where some dishes must be eaten before others. You look through the entire menu each time, find something you can eat now (all its required dishes already consumed), eat it, and look again. The repeated scanning is what makes this approach slow.
Step-by-Step Explanation
Let's trace through with numCourses = 4, prerequisites = [[1, 0], [2, 0], [3, 1], [3, 2]]:
Step 1: Initialize a set of completed courses = {} and result = []. Build prerequisite lists for each course: course 0 needs nothing, course 1 needs {0}, course 2 needs {0}, course 3 needs {1, 2}.
Step 2: Scan all 4 courses. Course 0 has no prerequisites → it is available. Pick course 0. Result = [0], completed = {0}.
Step 3: Scan all 4 courses again. Course 1 needs {0} — all in completed ✓. Pick course 1. Result = [0, 1], completed = {0, 1}.
Step 4: Scan all 4 courses again. Course 2 needs {0} — all in completed ✓. Pick course 2. Result = [0, 1, 2], completed = {0, 1, 2}.
Step 5: Scan all 4 courses again. Course 3 needs {1, 2} — all in completed ✓. Pick course 3. Result = [0, 1, 2, 3], completed = {0, 1, 2, 3}.
Step 6: All 4 courses placed. Return [0, 1, 2, 3].
Brute Force — Repeated Scanning for Available Courses — Watch how we repeatedly scan all courses to find one whose prerequisites are satisfied, picking available courses one at a time.
Algorithm
- Build a prerequisite set for each course from the input
- Maintain a
completedset and aresultlist - Repeat V times (once per course to be placed):
- Scan all courses 0 to V-1
- For each uncompleted course, check if all its prerequisites are in
completed - If found, add it to
resultandcompleted, break to next round - If no course found in a full scan, a cycle exists — return []
- Return
result
Code
class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
// Build prerequisite sets for each course
vector<unordered_set<int>> prereqs(numCourses);
for (auto& p : prerequisites) {
prereqs[p[0]].insert(p[1]);
}
vector<int> result;
vector<bool> completed(numCourses, false);
for (int round = 0; round < numCourses; round++) {
bool found = false;
for (int course = 0; course < numCourses; course++) {
if (completed[course]) continue;
// Check if all prerequisites are completed
bool canTake = true;
for (int pre : prereqs[course]) {
if (!completed[pre]) {
canTake = false;
break;
}
}
if (canTake) {
result.push_back(course);
completed[course] = true;
found = true;
break;
}
}
if (!found) return {}; // Cycle detected
}
return result;
}
};class Solution:
def findOrder(self, numCourses: int, prerequisites: list[list[int]]) -> list[int]:
# Build prerequisite sets for each course
prereqs = [set() for _ in range(numCourses)]
for a, b in prerequisites:
prereqs[a].add(b)
result = []
completed = set()
for _ in range(numCourses):
found = False
for course in range(numCourses):
if course in completed:
continue
# Check if all prerequisites are completed
if prereqs[course].issubset(completed):
result.append(course)
completed.add(course)
found = True
break
if not found:
return [] # Cycle detected
return resultclass Solution {
public int[] findOrder(int numCourses, int[][] prerequisites) {
// Build prerequisite sets for each course
Set<Integer>[] prereqs = new HashSet[numCourses];
for (int i = 0; i < numCourses; i++) {
prereqs[i] = new HashSet<>();
}
for (int[] p : prerequisites) {
prereqs[p[0]].add(p[1]);
}
int[] result = new int[numCourses];
boolean[] completed = new boolean[numCourses];
int idx = 0;
for (int round = 0; round < numCourses; round++) {
boolean found = false;
for (int course = 0; course < numCourses; course++) {
if (completed[course]) continue;
boolean canTake = true;
for (int pre : prereqs[course]) {
if (!completed[pre]) {
canTake = false;
break;
}
}
if (canTake) {
result[idx++] = course;
completed[course] = true;
found = true;
break;
}
}
if (!found) return new int[0]; // Cycle detected
}
return result;
}
}Complexity Analysis
Time Complexity: O(V × (V + E))
We run V rounds (one for each course to be placed). In each round, we scan up to V courses, and for each course, we check all its prerequisites. Across all courses, the total prerequisite checks per round sum to E. So each round costs O(V + E), and we do V rounds, giving O(V × (V + E)).
Space Complexity: O(V + E)
We store the prerequisite sets which together hold E entries, plus the completed array and result list of size V.
Why This Approach Is Not Efficient
The brute force rescans the entire course list V times, checking prerequisites from scratch each round. With V up to 2000 and E up to V × (V - 1) ≈ 4 × 10⁶, the worst-case cost is O(V × (V + E)) ≈ 2000 × 4 × 10⁶ = 8 × 10⁹ operations — far too slow.
The core waste: after completing a course, we do not propagate that information to its dependents. We blindly re-examine every course and every edge again. If we instead tracked how many unsatisfied prerequisites each course still has and updated that count as courses are completed, we could avoid redundant scanning entirely. This insight leads to the in-degree approach used in topological sorting.
Better Approach - DFS-Based Topological Sort
Intuition
Instead of repeatedly scanning for available courses, we can use depth-first search (DFS) to determine the ordering more efficiently. The idea rests on a key property of DFS: when we finish exploring a node (all its descendants are fully processed), that node can safely be placed at the end of the ordering.
Think of it like planning a road trip through a network of one-way roads. You pick a starting city, drive as far as you can following the roads, and once you hit a dead end (a city with no outgoing roads), you record that city. Then you backtrack and continue. The cities you record in reverse order form a valid travel plan.
To detect cycles (which make a valid ordering impossible), we use a three-color marking scheme:
- White (unvisited): The course has not been explored yet
- Gray (in progress): The course is currently being explored — we started its DFS but have not finished it
- Black (completed): The course and all its dependents are fully processed
If during DFS we encounter a gray node, we have found a cycle — a course indirectly depends on itself.
Step-by-Step Explanation
Let's trace through with numCourses = 4, prerequisites = [[1, 0], [2, 0], [3, 1], [3, 2]].
The adjacency list (prerequisite → dependent): 0 → [1, 2], 1 → [3], 2 → [3].
Step 1: Initialize all courses as WHITE (unvisited). Stack (for result) is empty.
Step 2: Start DFS from course 0 (first unvisited). Mark 0 as GRAY.
Step 3: Explore neighbor of 0 → course 1. Mark 1 as GRAY.
Step 4: Explore neighbor of 1 → course 3. Mark 3 as GRAY.
Step 5: Course 3 has no unvisited neighbors. Mark 3 as BLACK and push 3 onto the stack. Stack: [3].
Step 6: Backtrack to course 1. All neighbors of 1 are processed. Mark 1 as BLACK and push 1. Stack: [3, 1].
Step 7: Backtrack to course 0. Explore next neighbor → course 2. Mark 2 as GRAY.
Step 8: Explore neighbor of 2 → course 3. Course 3 is already BLACK (fully done), so skip it.
Step 9: Course 2 has no more unvisited neighbors. Mark 2 as BLACK and push 2. Stack: [3, 1, 2].
Step 10: Backtrack to course 0. All neighbors processed. Mark 0 as BLACK and push 0. Stack: [3, 1, 2, 0].
Step 11: All courses are visited. Reverse the stack: [0, 2, 1, 3]. This is a valid topological order.
DFS-Based Topological Sort — Three-Color Traversal — Watch how DFS explores the dependency graph using white/gray/black coloring, and builds the topological order by pushing finished nodes onto a stack.
Algorithm
- Build an adjacency list from prerequisites: for each pair [a, b], add edge b → a
- Initialize a color array: all courses are WHITE
- For each unvisited (WHITE) course, run DFS:
- Mark the course GRAY (in progress)
- For each neighbor: if WHITE → recurse; if GRAY → cycle detected, return []
- After all neighbors are processed, mark the course BLACK and push it onto a stack
- If no cycle was found, reverse the stack to get the topological order
- Return the reversed stack
Code
class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph(numCourses);
for (auto& p : prerequisites) {
graph[p[1]].push_back(p[0]);
}
// 0 = white, 1 = gray, 2 = black
vector<int> color(numCourses, 0);
vector<int> order;
bool hasCycle = false;
function<void(int)> dfs = [&](int node) {
if (hasCycle) return;
color[node] = 1; // gray
for (int neighbor : graph[node]) {
if (color[neighbor] == 1) {
hasCycle = true;
return;
}
if (color[neighbor] == 0) {
dfs(neighbor);
}
}
color[node] = 2; // black
order.push_back(node);
};
for (int i = 0; i < numCourses; i++) {
if (color[i] == 0) {
dfs(i);
if (hasCycle) return {};
}
}
reverse(order.begin(), order.end());
return order;
}
};class Solution:
def findOrder(self, numCourses: int, prerequisites: list[list[int]]) -> list[int]:
graph = [[] for _ in range(numCourses)]
for a, b in prerequisites:
graph[b].append(a)
# 0 = white, 1 = gray, 2 = black
color = [0] * numCourses
order = []
has_cycle = False
def dfs(node: int) -> None:
nonlocal has_cycle
if has_cycle:
return
color[node] = 1 # gray
for neighbor in graph[node]:
if color[neighbor] == 1:
has_cycle = True
return
if color[neighbor] == 0:
dfs(neighbor)
color[node] = 2 # black
order.append(node)
for i in range(numCourses):
if color[i] == 0:
dfs(i)
if has_cycle:
return []
return order[::-1]class Solution {
private List<List<Integer>> graph;
private int[] color;
private List<Integer> order;
private boolean hasCycle;
public int[] findOrder(int numCourses, int[][] prerequisites) {
graph = new ArrayList<>();
for (int i = 0; i < numCourses; i++) {
graph.add(new ArrayList<>());
}
for (int[] p : prerequisites) {
graph.get(p[1]).add(p[0]);
}
color = new int[numCourses]; // 0=white, 1=gray, 2=black
order = new ArrayList<>();
hasCycle = false;
for (int i = 0; i < numCourses; i++) {
if (color[i] == 0) {
dfs(i);
if (hasCycle) return new int[0];
}
}
Collections.reverse(order);
int[] result = new int[numCourses];
for (int i = 0; i < numCourses; i++) {
result[i] = order.get(i);
}
return result;
}
private void dfs(int node) {
if (hasCycle) return;
color[node] = 1;
for (int neighbor : graph.get(node)) {
if (color[neighbor] == 1) {
hasCycle = true;
return;
}
if (color[neighbor] == 0) {
dfs(neighbor);
}
}
color[node] = 2;
order.add(node);
}
}Complexity Analysis
Time Complexity: O(V + E)
Each course (vertex) is visited exactly once by DFS, and each prerequisite (edge) is examined exactly once. Building the adjacency list takes O(E). The total work is O(V + E).
Space Complexity: O(V + E)
The adjacency list stores all E edges. The color array and output order list each use O(V). The DFS recursion stack can go up to O(V) deep in the worst case (a chain of courses). Total: O(V + E).
Why This Approach Is Not Efficient
The DFS-based topological sort is already O(V + E), which is asymptotically optimal for this problem — you must examine every vertex and every edge at least once. However, it has practical drawbacks:
-
Recursion overhead: DFS uses the call stack, which can be problematic for deep graphs. With V up to 2000 and potential chain structures (course 0 → 1 → 2 → ... → 1999), the recursion depth could reach 2000 — manageable but a concern in stack-limited environments.
-
Post-order reversal: The DFS naturally produces a reverse topological order, requiring an explicit reversal step. This is not a complexity issue but adds conceptual complexity.
-
Cycle detection is indirect: We detect cycles by spotting gray-to-gray edges during traversal. The BFS approach (Kahn's algorithm) detects cycles more naturally — if the output list is shorter than V, a cycle must exist.
Kahn's algorithm (BFS-based) avoids recursion entirely, processes nodes in topological order directly (no reversal needed), and has a cleaner cycle detection mechanism. While both are O(V + E), Kahn's is often preferred in practice for its iterative nature and clarity.
Optimal Approach - BFS Topological Sort (Kahn's Algorithm)
Intuition
Kahn's algorithm takes a beautifully intuitive approach: instead of diving deep into the graph, it peels the graph layer by layer from the outside in.
Imagine you are organizing a tournament bracket. Some matches must happen before others. You start by identifying all matches that have no dependencies — they can be played right away. Once those matches are completed, some new matches become available (their prerequisites are now satisfied). You keep processing newly available matches until either all matches are played (success) or no new matches can be started despite some remaining (a circular dependency).
The key data structure is the in-degree of each node — how many prerequisite edges point into it. A course with in-degree 0 has all prerequisites satisfied (or has none) and can be taken immediately. When we "complete" a course, we decrement the in-degree of all courses that depend on it. Any course whose in-degree drops to 0 becomes newly available.
This approach is iterative (no recursion), produces the topological order directly (no reversal), and detects cycles naturally (if the result has fewer than V courses, a cycle exists).
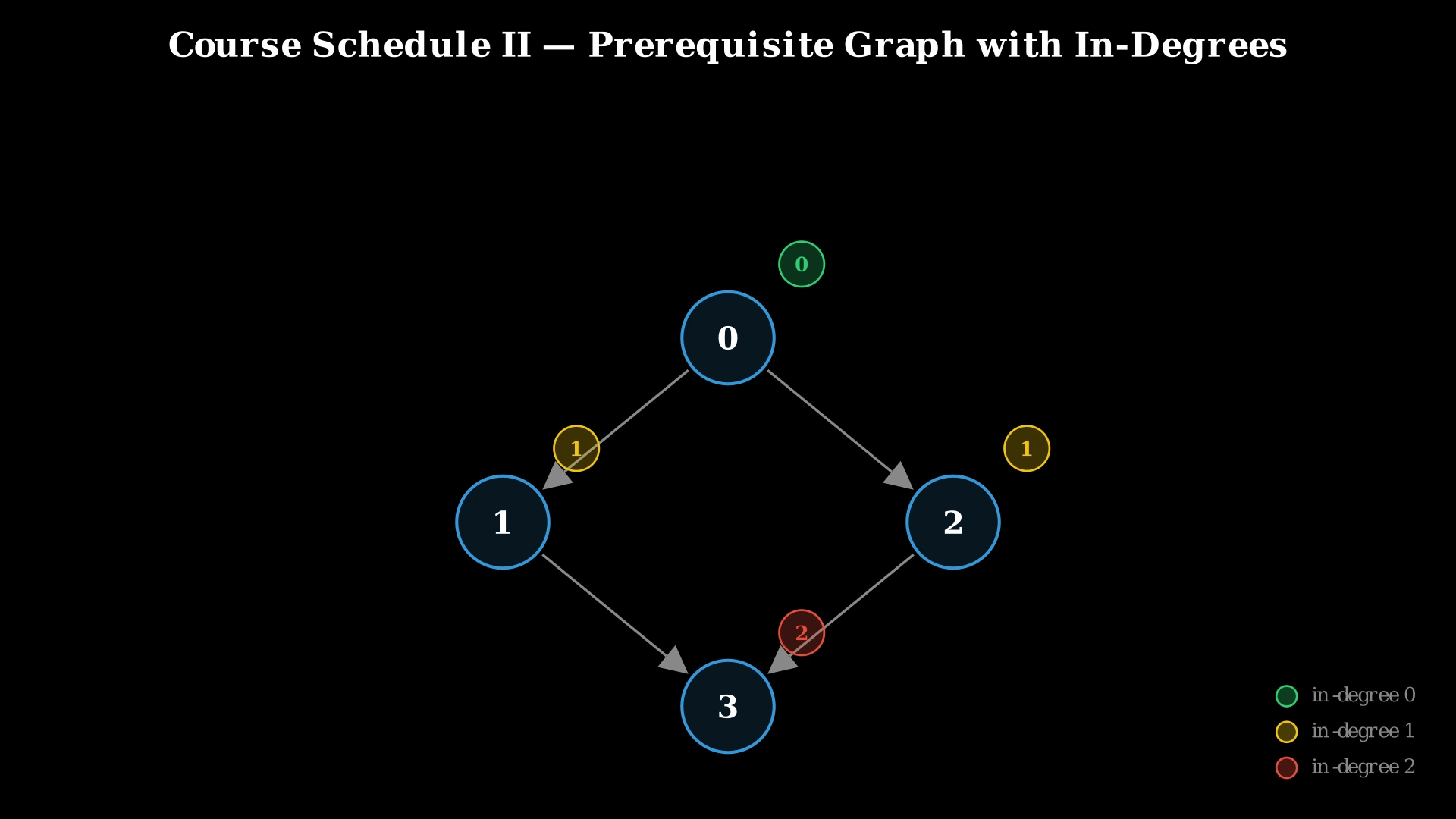
Step-by-Step Explanation
Let's trace through with numCourses = 4, prerequisites = [[1, 0], [2, 0], [3, 1], [3, 2]].
Build adjacency list: 0 → [1, 2], 1 → [3], 2 → [3].
Compute in-degrees: [0, 1, 1, 2].
Step 1: Initialize a queue with all courses having in-degree 0. Only course 0 qualifies. Queue: [0]. Result: [].
Step 2: Dequeue course 0. Add it to result. Result: [0]. Now process all courses that depend on 0: courses 1 and 2. Decrement their in-degrees: in-degree[1] = 1 - 1 = 0, in-degree[2] = 1 - 1 = 0. Both drop to 0, so enqueue both. Queue: [1, 2].
Step 3: Dequeue course 1. Add it to result. Result: [0, 1]. Process dependents of 1: course 3. Decrement in-degree[3] = 2 - 1 = 1. Still > 0, so do not enqueue. Queue: [2].
Step 4: Dequeue course 2. Add it to result. Result: [0, 1, 2]. Process dependents of 2: course 3. Decrement in-degree[3] = 1 - 1 = 0. It drops to 0 → enqueue course 3. Queue: [3].
Step 5: Dequeue course 3. Add it to result. Result: [0, 1, 2, 3]. No dependents. Queue is now empty.
Step 6: Result length (4) equals numCourses (4) → no cycle. Return [0, 1, 2, 3].
Kahn's Algorithm — BFS Layer-by-Layer Topological Sort — Watch how Kahn's algorithm processes courses in BFS order, decrementing in-degrees and enqueueing courses as their prerequisites are fulfilled.
Algorithm
- Build an adjacency list: for each prerequisite [a, b], add edge b → a
- Compute the in-degree of every course (count incoming edges)
- Initialize a queue with all courses having in-degree 0 (no prerequisites)
- While the queue is not empty:
- Dequeue a course and append it to the result
- For each dependent course of the dequeued course:
- Decrement its in-degree by 1
- If its in-degree becomes 0, enqueue it
- If the result contains all numCourses courses, return it
- Otherwise, a cycle exists — return an empty array
Code
class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph(numCourses);
vector<int> inDegree(numCourses, 0);
for (auto& p : prerequisites) {
graph[p[1]].push_back(p[0]);
inDegree[p[0]]++;
}
queue<int> q;
for (int i = 0; i < numCourses; i++) {
if (inDegree[i] == 0) {
q.push(i);
}
}
vector<int> result;
while (!q.empty()) {
int course = q.front();
q.pop();
result.push_back(course);
for (int dependent : graph[course]) {
inDegree[dependent]--;
if (inDegree[dependent] == 0) {
q.push(dependent);
}
}
}
return result.size() == numCourses ? result : vector<int>();
}
};from collections import deque
class Solution:
def findOrder(self, numCourses: int, prerequisites: list[list[int]]) -> list[int]:
graph = [[] for _ in range(numCourses)]
in_degree = [0] * numCourses
for a, b in prerequisites:
graph[b].append(a)
in_degree[a] += 1
queue = deque()
for i in range(numCourses):
if in_degree[i] == 0:
queue.append(i)
result = []
while queue:
course = queue.popleft()
result.append(course)
for dependent in graph[course]:
in_degree[dependent] -= 1
if in_degree[dependent] == 0:
queue.append(dependent)
return result if len(result) == numCourses else []class Solution {
public int[] findOrder(int numCourses, int[][] prerequisites) {
List<List<Integer>> graph = new ArrayList<>();
int[] inDegree = new int[numCourses];
for (int i = 0; i < numCourses; i++) {
graph.add(new ArrayList<>());
}
for (int[] p : prerequisites) {
graph.get(p[1]).add(p[0]);
inDegree[p[0]]++;
}
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (inDegree[i] == 0) {
queue.offer(i);
}
}
int[] result = new int[numCourses];
int idx = 0;
while (!queue.isEmpty()) {
int course = queue.poll();
result[idx++] = course;
for (int dependent : graph.get(course)) {
inDegree[dependent]--;
if (inDegree[dependent] == 0) {
queue.offer(dependent);
}
}
}
return idx == numCourses ? result : new int[0];
}
}Complexity Analysis
Time Complexity: O(V + E)
Where V = numCourses and E = number of prerequisites. Building the graph takes O(E). Computing in-degrees takes O(V). In the BFS loop, each course is enqueued and dequeued exactly once (O(V)), and each edge is examined exactly once when decrementing in-degrees (O(E)). Total: O(V + E).
Space Complexity: O(V + E)
The adjacency list stores all E edges. The in-degree array and result array each use O(V). The queue can hold up to O(V) courses at once. Total: O(V + E).