Interleaving String
Description
Given three strings s1, s2, and s3, determine whether s3 can be formed by interleaving s1 and s2.
An interleaving of two strings means you split each string into substrings and then weave them together in alternating fashion. The characters from s1 must appear in s3 in the same order they appear in s1, and likewise for s2. Every character from both strings must be used exactly once, and the combined length must equal the length of s3.
Think of it like shuffling two decks of cards together: you can interleave them in any pattern, but each deck's internal order must be preserved.
Examples
Example 1
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
Output: true
Explanation: One way to obtain s3 is to split s1 into "aa" + "bc" + "c" and s2 into "dbbc" + "a". Interleaving these gives "aa" + "dbbc" + "bc" + "a" + "c" = "aadbbcbcac". The relative order of characters from each original string is preserved.
Example 2
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc"
Output: false
Explanation: There is no way to split s1 and s2 and interleave them to produce "aadbbbaccc". No matter how you divide the strings, the character ordering cannot produce this result.
Example 3
Input: s1 = "", s2 = "", s3 = ""
Output: true
Explanation: Two empty strings interleaved produce an empty string.
Constraints
- 0 ≤ s1.length, s2.length ≤ 100
- 0 ≤ s3.length ≤ 200
- s1, s2, and s3 consist of lowercase English letters
Editorial
Brute Force - Recursion
Intuition
At each position in s3, we need to decide: does this character come from s1 or from s2? If we track how many characters we have consumed from each string so far — say i from s1 and j from s2 — then we are currently trying to match position i + j in s3.
This gives us a natural recursive structure. At each step, we check:
- If the current character in
s1(at indexi) matchess3[i+j], we can try consuming it froms1and recurse with(i+1, j). - If the current character in
s2(at indexj) matchess3[i+j], we can try consuming it froms2and recurse with(i, j+1). - If neither matches, this path is a dead end and we return false.
The base case is when we have consumed all characters from both strings (i == len(s1) and j == len(s2)). Since we already verified the total length matches, reaching this state means we have successfully matched all of s3.
One important early exit: if len(s1) + len(s2) ≠ len(s3), there is no possible interleaving and we can return false immediately.
Step-by-Step Explanation
Let's trace with s1 = "aa", s2 = "ab", s3 = "aaba".
Length check: 2 + 2 = 4 = len("aaba") ✓. Proceed.
Step 1: Start dfs(0, 0). We need s3[0] = 'a'. s1[0] = 'a' ✓ AND s2[0] = 'a' ✓. Both match! We must explore two branches.
Step 2: Branch 1 — take from s1. Call dfs(1, 0). Need s3[1] = 'a'. s1[1] = 'a' ✓, s2[0] = 'a' ✓. Again, both match. Two more branches.
Step 3: Branch 1.1 — take from s1 again. Call dfs(2, 0). Need s3[2] = 'b'. s1 is exhausted (i=2). s2[0] = 'a' ≠ 'b'. Dead end → return false.
Step 4: Branch 1.2 — take from s2 instead. Call dfs(1, 1). Need s3[2] = 'b'. s1[1] = 'a' ≠ 'b'. s2[1] = 'b' ✓. Only one option.
Step 5: Call dfs(1, 2). Need s3[3] = 'a'. s2 exhausted (j=2). s1[1] = 'a' ✓. Take from s1.
Step 6: Call dfs(2, 2). i=2 ≥ len(s1) and j=2 ≥ len(s2). Base case → return true! Branch 1 succeeds.
Step 7: Branch 2 — back at dfs(0, 0), take from s2 instead. Call dfs(0, 1). Need s3[1] = 'a'. s1[0] = 'a' ✓, s2[1] = 'b' ≠ 'a'. Only s1 matches.
Step 8: Call dfs(1, 1). Need s3[2] = 'b'. Wait — this is the SAME state (i=1, j=1) we already solved in Step 4! Without memoization, we recompute it from scratch.
Step 9: Recomputation of dfs(1, 1) → dfs(1, 2) → dfs(2, 2) → true. The entire subtree is traversed again. This is wasted work.
Step 10: Return true. The answer is correct, but we visited state (1, 1) twice. With longer strings, many states are revisited exponentially.
Recursive Exploration of dfs(i, j) for s1="aa", s2="ab", s3="aaba" — Watch how the recursion branches when both strings match, hits dead ends, and revisits the same subproblem (1,1) through different paths.
Algorithm
- If len(s1) + len(s2) ≠ len(s3), return false immediately
- Define recursive function dfs(i, j):
a. If i ≥ len(s1) and j ≥ len(s2), return true (base case)
b. Let k = i + j (current position in s3)
c. If s1[i] == s3[k], try dfs(i+1, j). If it returns true, return true
d. If s2[j] == s3[k], try dfs(i, j+1). If it returns true, return true
e. Return false (neither character matched) - Return dfs(0, 0)
Code
#include <string>
using namespace std;
class Solution {
public:
bool isInterleave(string s1, string s2, string s3) {
if (s1.size() + s2.size() != s3.size()) return false;
return dfs(s1, s2, s3, 0, 0);
}
private:
bool dfs(const string& s1, const string& s2, const string& s3, int i, int j) {
if (i == (int)s1.size() && j == (int)s2.size()) return true;
int k = i + j;
if (i < (int)s1.size() && s1[i] == s3[k]) {
if (dfs(s1, s2, s3, i + 1, j)) return true;
}
if (j < (int)s2.size() && s2[j] == s3[k]) {
if (dfs(s1, s2, s3, i, j + 1)) return true;
}
return false;
}
};class Solution:
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
if len(s1) + len(s2) != len(s3):
return False
def dfs(i: int, j: int) -> bool:
if i >= len(s1) and j >= len(s2):
return True
k = i + j
if i < len(s1) and s1[i] == s3[k]:
if dfs(i + 1, j):
return True
if j < len(s2) and s2[j] == s3[k]:
if dfs(i, j + 1):
return True
return False
return dfs(0, 0)class Solution {
public boolean isInterleave(String s1, String s2, String s3) {
if (s1.length() + s2.length() != s3.length()) return false;
return dfs(s1, s2, s3, 0, 0);
}
private boolean dfs(String s1, String s2, String s3, int i, int j) {
if (i == s1.length() && j == s2.length()) return true;
int k = i + j;
if (i < s1.length() && s1.charAt(i) == s3.charAt(k)) {
if (dfs(s1, s2, s3, i + 1, j)) return true;
}
if (j < s2.length() && s2.charAt(j) == s3.charAt(k)) {
if (dfs(s1, s2, s3, i, j + 1)) return true;
}
return false;
}
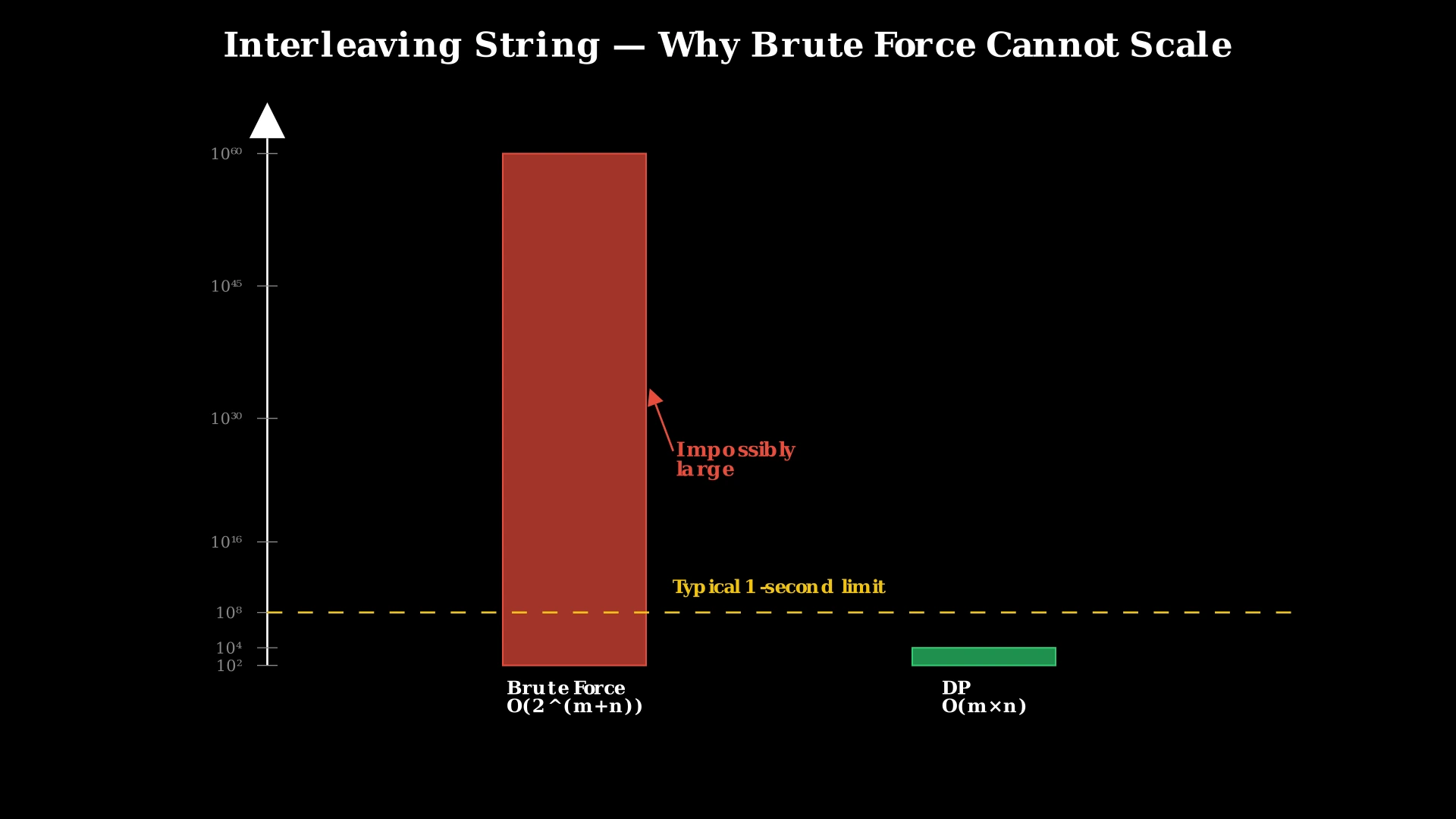
}Complexity Analysis
Time Complexity: O(2^(m+n))
In the worst case, every position in s3 could match both s1 and s2, causing the recursion to branch into two calls at each level. The maximum recursion depth is m + n (total characters to consume), giving an exponential 2^(m+n) call tree. Many of these calls compute the same (i, j) state redundantly.
Space Complexity: O(m + n)
The recursion stack can grow as deep as m + n in the worst case, since each call consumes exactly one character from either s1 or s2. No additional data structures are used.
Why This Approach Is Not Efficient
The recursive solution explores an exponential number of paths because it does not remember results from previous calls. The state space of the problem is only (m+1) × (n+1) unique states — one for each combination of how many characters have been consumed from s1 and s2. But without memoization, the same state can be reached through many different orderings of decisions, and each time it is recomputed from scratch.
For example, the state (i=3, j=4) can be reached by consuming 3 from s1 then 4 from s2, or 2 from s1, then 4 from s2, then 1 more from s1, or countless other orderings. Each path triggers a fresh recursive exploration of the same subproblem.
With m and n up to 100, the brute force could theoretically explore 2^200 paths — far beyond any practical time limit. We need a way to solve each unique (i, j) state exactly once.
Optimal Approach - 2D Dynamic Programming
Intuition
The key insight from the brute force is that the entire problem can be described by just two numbers: how many characters we have used from s1 (call it i) and from s2 (call it j). The position in s3 is always i + j, so it is redundant. There are only (m+1) × (n+1) possible (i, j) states, and each depends on at most two smaller states.
This makes it a classic dynamic programming problem. We build a 2D table dp[i][j] where:
dp[i][j]= true if s3[0..i+j-1] can be formed by interleaving s1[0..i-1] and s2[0..j-1]
The base case is dp[0][0] = true — empty strings interleave to form empty.
For each cell, we check two transitions:
- From above: if s1[i-1] matches s3[i+j-1] and dp[i-1][j] is true, then we can extend a valid interleaving by one more character from s1
- From the left: if s2[j-1] matches s3[i+j-1] and dp[i][j-1] is true, then we can extend by one more character from s2
If either transition works, dp[i][j] = true. The answer is dp[m][n].
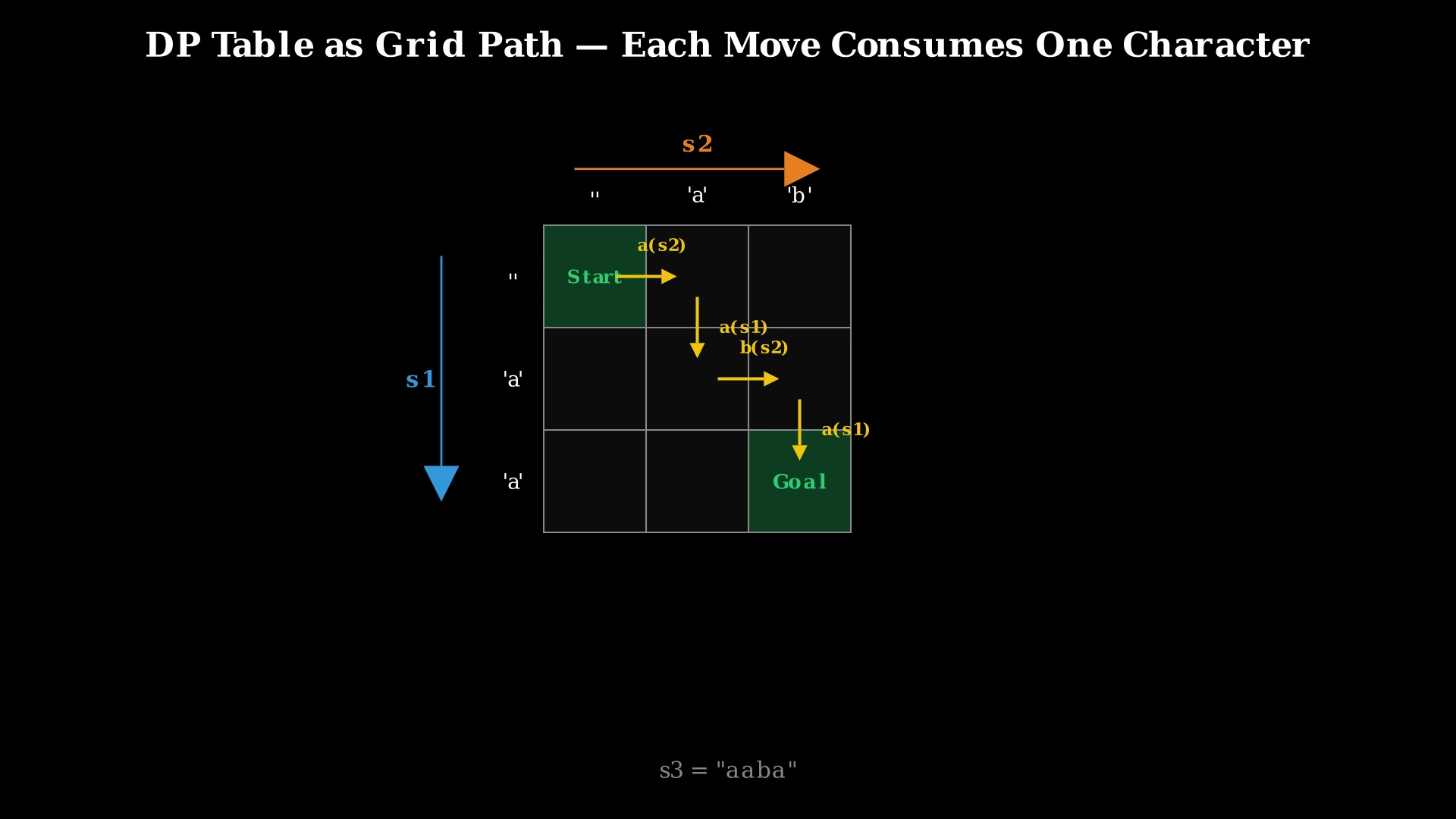
Visualizing the DP table as a grid, the problem becomes: can we find a path from the top-left corner (0,0) to the bottom-right corner (m,n) moving only right or down, where each move corresponds to matching a character from the appropriate string?
Step-by-Step Explanation
Let's trace the DP table for s1 = "aa", s2 = "ab", s3 = "aaba".
Table dimensions: (m+1) × (n+1) = 3 × 3. Rows represent characters consumed from s1, columns from s2.
Step 1: dp[0][0] = true. Base case: empty + empty = empty ✓.
Step 2: dp[0][1]. Only consuming from s2. s2[0]='a', s3[0]='a'. Match ✓ and dp[0][0]=true → dp[0][1] = true.
Step 3: dp[0][2]. s2[1]='b', s3[1]='a'. 'b' ≠ 'a'. Chain broken → dp[0][2] = false.
Step 4: dp[1][0]. Only consuming from s1. s1[0]='a', s3[0]='a'. Match ✓ and dp[0][0]=true → dp[1][0] = true.
Step 5: dp[1][1]. k = 1+1-1 = 1, s3[1]='a'. From above: s1[0]='a'=='a' ✓ and dp[0][1]=true → true. dp[1][1] = true.
Step 6: dp[1][2]. k = 2, s3[2]='b'. From above: s1[0]='a'≠'b'. From left: s2[1]='b'=='b' ✓ and dp[1][1]=true → true. dp[1][2] = true.
Step 7: dp[2][0]. s1[1]='a', s3[1]='a'. Match ✓ and dp[1][0]=true → dp[2][0] = true.
Step 8: dp[2][1]. k = 2, s3[2]='b'. From above: s1[1]='a'≠'b'. From left: s2[0]='a'≠'b'. Neither works → dp[2][1] = false.
Step 9: dp[2][2]. k = 3, s3[3]='a'. From above: s1[1]='a'=='a' ✓ and dp[1][2]=true → true. dp[2][2] = true.
Result: dp[2][2] = true. "aaba" IS a valid interleaving of "aa" and "ab".
Filling the 2D DP Table for s1="aa", s2="ab", s3="aaba" — Watch how the DP table fills cell by cell, with each cell depending on the cell above (taking from s1) or to the left (taking from s2).
Algorithm
- If len(s1) + len(s2) ≠ len(s3), return false
- Create a 2D boolean table dp of size (m+1) × (n+1), initialized to false
- Set dp[0][0] = true (base case)
- Fill first row: for j = 1 to n, dp[0][j] = (s2[j-1] == s3[j-1]) AND dp[0][j-1]
- Fill first column: for i = 1 to m, dp[i][0] = (s1[i-1] == s3[i-1]) AND dp[i-1][0]
- Fill remaining cells: for i = 1 to m, for j = 1 to n:
- from_above = (s1[i-1] == s3[i+j-1]) AND dp[i-1][j]
- from_left = (s2[j-1] == s3[i+j-1]) AND dp[i][j-1]
- dp[i][j] = from_above OR from_left
- Return dp[m][n]
Code
#include <string>
#include <vector>
using namespace std;
class Solution {
public:
bool isInterleave(string s1, string s2, string s3) {
int m = s1.size(), n = s2.size();
if (m + n != (int)s3.size()) return false;
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
dp[0][0] = true;
for (int j = 1; j <= n; j++) {
dp[0][j] = dp[0][j - 1] && (s2[j - 1] == s3[j - 1]);
}
for (int i = 1; i <= m; i++) {
dp[i][0] = dp[i - 1][0] && (s1[i - 1] == s3[i - 1]);
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
int k = i + j - 1;
dp[i][j] = (dp[i - 1][j] && s1[i - 1] == s3[k]) ||
(dp[i][j - 1] && s2[j - 1] == s3[k]);
}
}
return dp[m][n];
}
};class Solution:
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
m, n = len(s1), len(s2)
if m + n != len(s3):
return False
dp = [[False] * (n + 1) for _ in range(m + 1)]
dp[0][0] = True
for j in range(1, n + 1):
dp[0][j] = dp[0][j - 1] and s2[j - 1] == s3[j - 1]
for i in range(1, m + 1):
dp[i][0] = dp[i - 1][0] and s1[i - 1] == s3[i - 1]
for i in range(1, m + 1):
for j in range(1, n + 1):
k = i + j - 1
dp[i][j] = (dp[i - 1][j] and s1[i - 1] == s3[k]) or \
(dp[i][j - 1] and s2[j - 1] == s3[k])
return dp[m][n]class Solution {
public boolean isInterleave(String s1, String s2, String s3) {
int m = s1.length(), n = s2.length();
if (m + n != s3.length()) return false;
boolean[][] dp = new boolean[m + 1][n + 1];
dp[0][0] = true;
for (int j = 1; j <= n; j++) {
dp[0][j] = dp[0][j - 1] && s2.charAt(j - 1) == s3.charAt(j - 1);
}
for (int i = 1; i <= m; i++) {
dp[i][0] = dp[i - 1][0] && s1.charAt(i - 1) == s3.charAt(i - 1);
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
int k = i + j - 1;
dp[i][j] = (dp[i - 1][j] && s1.charAt(i - 1) == s3.charAt(k)) ||
(dp[i][j - 1] && s2.charAt(j - 1) == s3.charAt(k));
}
}
return dp[m][n];
}
}Complexity Analysis
Time Complexity: O(m × n)
We fill a table with (m+1) × (n+1) cells. Each cell is computed in O(1) time — just two comparisons and lookups. Total: O(m × n).
Space Complexity: O(m × n)
The 2D boolean table uses (m+1) × (n+1) space. This can be optimized to O(min(m, n)) by observing that each row only depends on the previous row and the current row, so we can use a single 1D array of size n+1 (or m+1), updating it in place from left to right. The follow-up question hints at this optimization.