Implement Trie (Prefix Tree)
Description
A Trie (pronounced "try"), also called a prefix tree, is a tree-shaped data structure designed for efficiently storing and retrieving strings. Unlike a hash map that stores entire keys, a Trie stores strings character by character — each node represents a single character, and paths from the root to marked nodes spell out complete words.
Your task is to implement the Trie class with three operations:
Trie()— Initializes an empty Trie objectvoid insert(String word)— Inserts the stringwordinto the Trieboolean search(String word)— Returnstrueifwordwas previously inserted into the Trie,falseotherwiseboolean startsWith(String prefix)— Returnstrueif any previously inserted word starts with the givenprefix,falseotherwise
The key difference between search and startsWith: search requires an exact match (the word must have been inserted), while startsWith only requires that the prefix path exists in the Trie (some word starting with that prefix was inserted).
Examples
Example 1
Input:
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
Output: [null, null, true, false, true, null, true]
Explanation:
Trie()— Create an empty Trieinsert("apple")— Insert the word "apple" into the Trie. The path a→p→p→l→e is created, with the last node marked as end-of-word.search("apple")— Returnstrue. The path a→p→p→l→e exists and the last node is marked as an end-of-word.search("app")— Returnsfalse. The path a→p→p exists, but the node for the second 'p' is NOT marked as an end-of-word. "app" was never inserted.startsWith("app")— Returnstrue. The path a→p→p exists in the Trie (it's a prefix of "apple"). We don't care whether it's a complete word — just that the prefix path exists.insert("app")— Insert "app". The path a→p→p already exists, so we just mark the second 'p' node as end-of-word.search("app")— Returnstrue. Now the path a→p→p exists AND the last node is marked as end-of-word.
Constraints
- 1 ≤ word.length, prefix.length ≤ 2000
wordandprefixconsist only of lowercase English letters- At most 3 × 10⁴ calls in total will be made to
insert,search, andstartsWith
Editorial
Brute Force
Intuition
Before building a Trie, consider the simplest approach: just store all inserted words in a list.
- Insert: Append the word to the list. O(1).
- Search: Scan the entire list and check if any word matches. O(n·m) where n is the number of words and m is the average word length.
- StartsWith: Scan the entire list and check if any word starts with the given prefix. O(n·m).
This is like keeping a notebook where you write down every word. To search for a word, you flip through every page. To check a prefix, you flip through every page again, checking the beginning of each word.
The approach works but is painfully slow for repeated queries. With up to 30,000 operations and 2,000-character words, search and startsWith could each scan thousands of words per call.
Step-by-Step Explanation
Let's trace through the example operations:
Step 1: Initialize: words = []
Step 2: insert("apple"): Append "apple" to list. words = ["apple"].
Step 3: search("apple"): Scan list. words[0] = "apple" matches "apple". Return true.
Step 4: search("app"): Scan list. words[0] = "apple" ≠ "app". No match found. Return false.
Step 5: startsWith("app"): Scan list. Does "apple" start with "app"? Check: a=a, p=p, p=p. Yes! Return true.
Step 6: insert("app"): Append "app". words = ["apple", "app"].
Step 7: search("app"): Scan list. words[0] = "apple" ≠ "app". words[1] = "app" matches. Return true.
Each search/startsWith operation scans all stored words — O(n) per query.
Algorithm
- Maintain a list of all inserted words
- Insert: Append the word to the list
- Search: Iterate through the list; return true if any word equals the query
- StartsWith: Iterate through the list; return true if any word starts with the prefix
Code
#include <string>
#include <vector>
using namespace std;
class Trie {
public:
vector<string> words;
Trie() {}
void insert(string word) {
words.push_back(word);
}
bool search(string word) {
for (const string& w : words) {
if (w == word) return true;
}
return false;
}
bool startsWith(string prefix) {
for (const string& w : words) {
if (w.substr(0, prefix.size()) == prefix) return true;
}
return false;
}
};class Trie:
def __init__(self):
self.words = []
def insert(self, word: str) -> None:
self.words.append(word)
def search(self, word: str) -> bool:
for w in self.words:
if w == word:
return True
return False
def startsWith(self, prefix: str) -> bool:
for w in self.words:
if w.startswith(prefix):
return True
return Falseimport java.util.ArrayList;
import java.util.List;
class Trie {
private List<String> words;
public Trie() {
words = new ArrayList<>();
}
public void insert(String word) {
words.add(word);
}
public boolean search(String word) {
for (String w : words) {
if (w.equals(word)) return true;
}
return false;
}
public boolean startsWith(String prefix) {
for (String w : words) {
if (w.startsWith(prefix)) return true;
}
return false;
}
}Complexity Analysis
Time Complexity:
- Insert: O(1) amortized — just append to the list
- Search: O(n · m) — scan n words, each comparison takes up to m characters
- StartsWith: O(n · m) — scan n words, each prefix check takes up to min(m, p) characters where p is prefix length
Where n = number of inserted words, m = maximum word length.
Space Complexity: O(n · m)
We store all n words, each up to length m. No sharing of common prefixes — the word "apple" and "app" each store their own complete string, even though they share the first 3 characters.
Why This Approach Is Not Efficient
The brute force list approach has O(n · m) for both search and startsWith. With up to 30,000 total operations and words up to 2,000 characters, the worst case could be billions of character comparisons.
The core problems:
- Repeated scanning: Every search re-scans the entire word list. We learn nothing from previous searches.
- No prefix sharing: The words "apple", "app", "apply" each store the common prefix "app" separately — wasting space.
- Linear matching: String comparison for each stored word is O(m) per word.
The Trie data structure solves all three problems:
- Direct traversal: Instead of scanning words, we follow a path character by character. Search and startsWith both take O(m) where m is the query length — independent of how many words are stored.
- Prefix sharing: Words sharing a common prefix share the same path in the tree. "apple", "app", "apply" all share the a→p→p path.
- O(m) operations: Insert, search, and startsWith all take O(m) — proportional only to the word/prefix length, not the number of stored words.
Optimal Approach - Trie Data Structure
Intuition
A Trie is a tree where each node represents a single character. The root node is empty (it represents the start before any character). Each node has up to 26 children (one per lowercase English letter), and a boolean flag isEnd that marks whether a complete word ends at that node.
Think of it like a phone tree menu system. Press 'a' → goes to the 'a' branch. Then press 'p' → goes to the 'p' child. Then 'p' again → goes to another 'p' child. At each point, you're navigating deeper into the tree. Some nodes are marked as "valid destinations" (complete words).
Insert: Walk down the tree character by character. If a child node for the current character doesn't exist, create it. After processing all characters, mark the final node as end-of-word.
Search: Walk down the tree character by character. If at any point the child node doesn't exist, the word was never inserted — return false. If we reach the end of the word, check the end-of-word flag. If it's true, the word exists. If false, the path exists but the word wasn't inserted (it's only a prefix of another word).
StartsWith: Identical to search, but we don't check the end-of-word flag. If we can walk the entire prefix without hitting a missing node, the prefix exists in the Trie.
All three operations traverse at most m characters (the length of the word/prefix), giving O(m) time per operation.
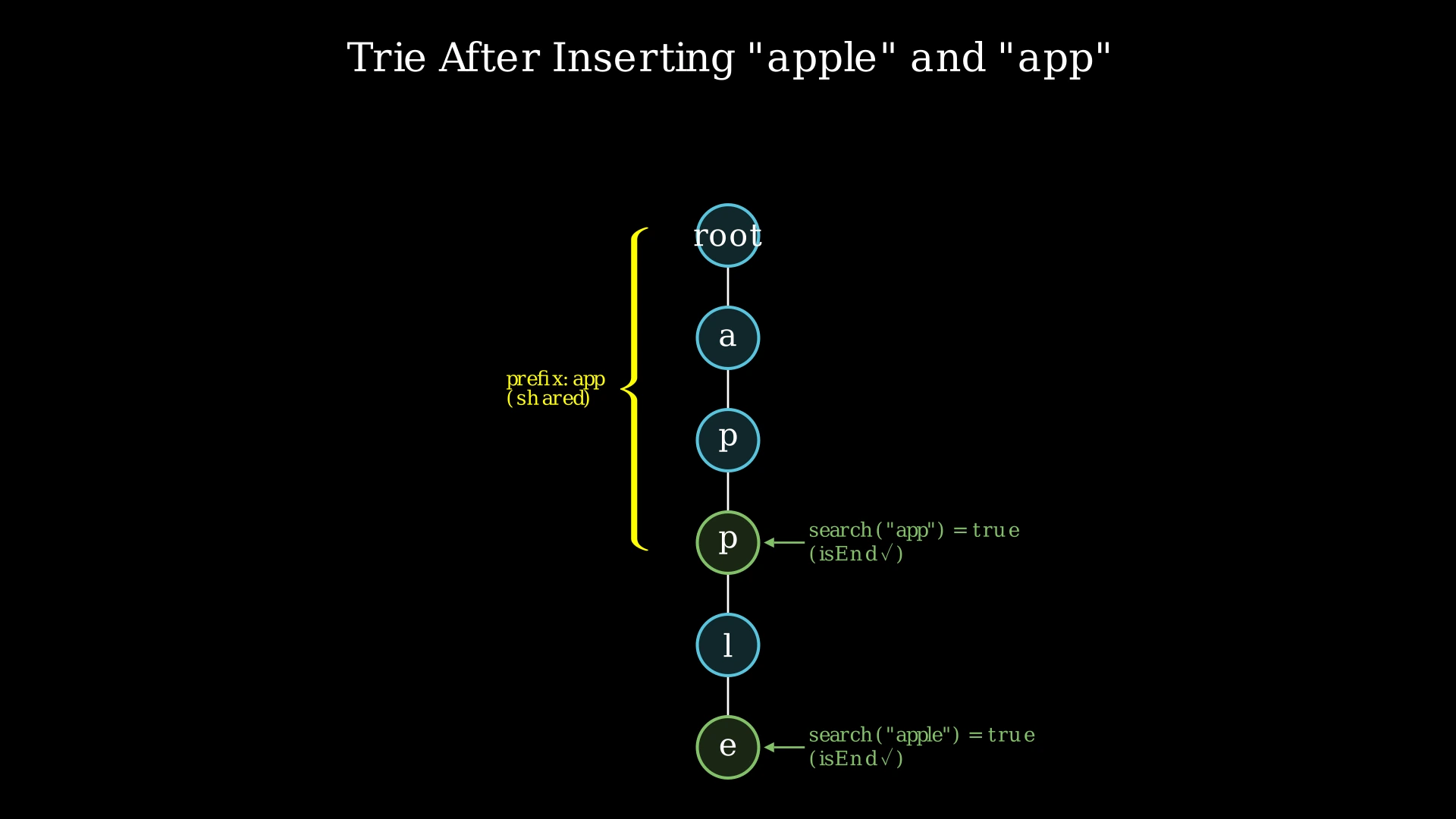
Step-by-Step Explanation
Let's trace all operations from the example:
Step 1: Create Trie. Root node with 26 null children and isEnd = false.
Step 2: insert("apple"):
- Character 'a': root has no 'a' child → create node. Move to 'a' node.
- Character 'p': 'a' has no 'p' child → create node. Move to 'p' node.
- Character 'p': first 'p' has no 'p' child → create node. Move to second 'p' node.
- Character 'l': second 'p' has no 'l' child → create node. Move to 'l' node.
- Character 'e': 'l' has no 'e' child → create node. Move to 'e' node.
- Mark 'e' node as isEnd = true. Word "apple" stored.
Step 3: search("apple"):
- Walk a→p→p→l→e. All nodes exist. Final node 'e' has isEnd = true. Return true.
Step 4: search("app"):
- Walk a→p→p. All nodes exist. Final node (second 'p') has isEnd = false. "app" was never inserted as a complete word. Return false.
Step 5: startsWith("app"):
- Walk a→p→p. All nodes exist. We don't check isEnd — just that the prefix path exists. Return true.
Step 6: insert("app"):
- Walk a→p→p. All nodes already exist (shared prefix with "apple"). No new nodes created.
- Mark second 'p' node as isEnd = true. Word "app" now stored.
Step 7: search("app"):
- Walk a→p→p. Final node (second 'p') now has isEnd = true. Return true.
Trie Operations — Insert, Search, and StartsWith — Watch the Trie grow as words are inserted character by character, then see how search walks the tree and checks the end-of-word flag, while startsWith only checks path existence.
Algorithm
TrieNode structure:
children: array of 26 pointers (one per letter a-z), all initially nullisEnd: boolean, initially false
Insert(word):
- Start at the root node
- For each character c in word:
- If
current.children[c]is null, create a new TrieNode - Move to
current.children[c]
- If
- Mark
current.isEnd = true
Search(word):
- Start at the root node
- For each character c in word:
- If
current.children[c]is null, return false (path doesn't exist) - Move to
current.children[c]
- If
- Return
current.isEnd(true only if this exact word was inserted)
StartsWith(prefix):
- Start at the root node
- For each character c in prefix:
- If
current.children[c]is null, return false - Move to
current.children[c]
- If
- Return true (the prefix path exists, regardless of isEnd)
Code
#include <string>
using namespace std;
class TrieNode {
public:
TrieNode* children[26];
bool isEnd;
TrieNode() {
isEnd = false;
for (int i = 0; i < 26; i++) {
children[i] = nullptr;
}
}
};
class Trie {
private:
TrieNode* root;
public:
Trie() {
root = new TrieNode();
}
void insert(string word) {
TrieNode* curr = root;
for (char c : word) {
int index = c - 'a';
if (curr->children[index] == nullptr) {
curr->children[index] = new TrieNode();
}
curr = curr->children[index];
}
curr->isEnd = true;
}
bool search(string word) {
TrieNode* curr = root;
for (char c : word) {
int index = c - 'a';
if (curr->children[index] == nullptr) {
return false;
}
curr = curr->children[index];
}
return curr->isEnd;
}
bool startsWith(string prefix) {
TrieNode* curr = root;
for (char c : prefix) {
int index = c - 'a';
if (curr->children[index] == nullptr) {
return false;
}
curr = curr->children[index];
}
return true;
}
};class TrieNode:
def __init__(self):
self.children = {}
self.is_end = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word: str) -> None:
curr = self.root
for char in word:
if char not in curr.children:
curr.children[char] = TrieNode()
curr = curr.children[char]
curr.is_end = True
def search(self, word: str) -> bool:
curr = self.root
for char in word:
if char not in curr.children:
return False
curr = curr.children[char]
return curr.is_end
def startsWith(self, prefix: str) -> bool:
curr = self.root
for char in prefix:
if char not in curr.children:
return False
curr = curr.children[char]
return Trueclass TrieNode {
TrieNode[] children;
boolean isEnd;
TrieNode() {
children = new TrieNode[26];
isEnd = false;
}
}
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode curr = root;
for (char c : word.toCharArray()) {
int index = c - 'a';
if (curr.children[index] == null) {
curr.children[index] = new TrieNode();
}
curr = curr.children[index];
}
curr.isEnd = true;
}
public boolean search(String word) {
TrieNode curr = root;
for (char c : word.toCharArray()) {
int index = c - 'a';
if (curr.children[index] == null) {
return false;
}
curr = curr.children[index];
}
return curr.isEnd;
}
public boolean startsWith(String prefix) {
TrieNode curr = root;
for (char c : prefix.toCharArray()) {
int index = c - 'a';
if (curr.children[index] == null) {
return false;
}
curr = curr.children[index];
}
return true;
}
}Complexity Analysis
Time Complexity:
- Insert: O(m) — where m is the length of the word. We traverse m characters, creating at most m new nodes.
- Search: O(m) — traverse at most m nodes along the path.
- StartsWith: O(p) — where p is the length of the prefix. Same traversal logic as search.
All operations are proportional only to the word/prefix length, completely independent of the number of stored words. Compare this with the brute force O(n·m) per query.
Space Complexity: O(T)
Where T is the total number of characters across all inserted words in the worst case. Each character may create one new TrieNode. However, because common prefixes are shared, the actual space is often much less. Each TrieNode stores 26 pointers (for the fixed-size children array), so the per-node cost is O(26) = O(1). Total space is O(N) where N is the number of nodes created.
In the worst case (no shared prefixes), N equals the total length of all words. In the best case (all words share a long prefix), N can be significantly smaller.