Subtree of Another Tree
Description
You are given the roots of two binary trees, called root and subRoot. Your task is to determine whether subRoot is a subtree of root.
A subtree of a binary tree is defined as a node within that tree along with all of its descendants. The original tree itself is also considered a valid subtree of itself.
Return true if there exists some node in root such that the subtree rooted at that node is structurally identical to subRoot (same shape and same node values). Return false otherwise.
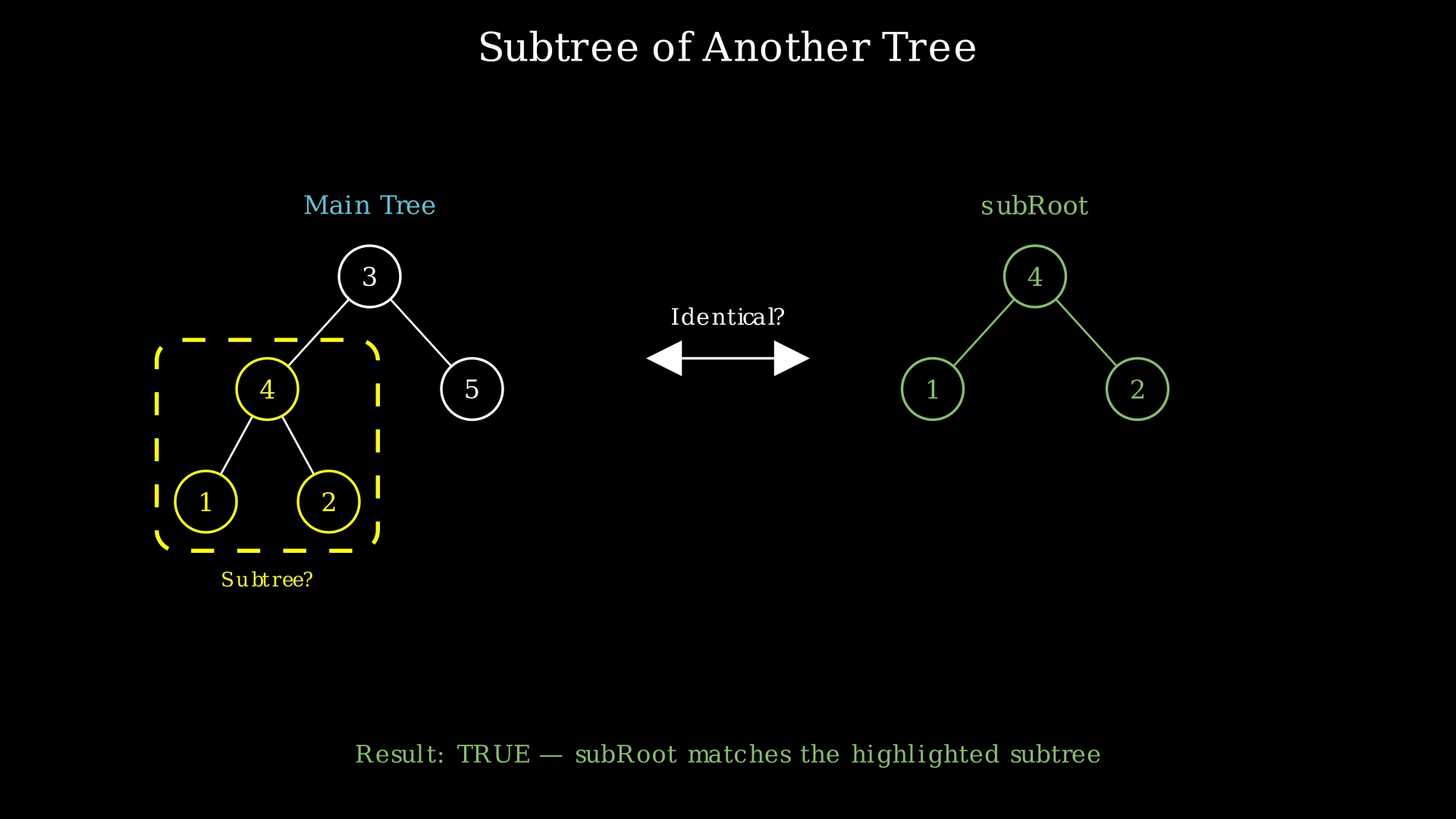
Examples
Example 1
Input: root = [3,4,5,1,2], subRoot = [4,1,2]
Output: true
Explanation: The node with value 4 in the root tree has two children: 1 on the left and 2 on the right. This exactly matches the structure and values of subRoot (root 4, left child 1, right child 2). Since we found a node in the main tree whose entire subtree is identical to subRoot, the answer is true.
Example 2
Input: root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2]
Output: false
Explanation: At first glance, the node with value 4 in the root tree looks like it might match subRoot. However, in the root tree, the node 2 (right child of 4) has an additional left child with value 0. The subRoot's node 2 has no children. Because the subtree rooted at 4 in the main tree has an extra node that subRoot does not, they are not identical. No other node in the root tree matches subRoot either, so the answer is false.
Constraints
- 1 ≤ Number of nodes in root ≤ 2000
- 1 ≤ Number of nodes in subRoot ≤ 1000
- -10^4 ≤ root.val ≤ 10^4
- -10^4 ≤ subRoot.val ≤ 10^4
Editorial
Brute Force
Intuition
The most straightforward way to check if one tree is a subtree of another is to visit every single node in the main tree and ask: "If I treat this node as the root of its own little tree, does that tree look exactly like subRoot?"
Think of it like searching for a specific pattern in a book. You go page by page, paragraph by paragraph, and at each paragraph you compare it word-for-word against the pattern you are looking for. If every word matches, you found it. If even one word is different, you move on to the next paragraph and try again.
For trees, "comparing word-for-word" means checking that:
- Both nodes have the same value
- Their left subtrees are identical
- Their right subtrees are identical
This naturally leads to two recursive functions:
- One that traverses every node of the main tree (the "outer" search)
- One that checks whether two trees are structurally identical (the "inner" comparison)
Step-by-Step Explanation
Let's trace through with root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2].
The root tree looks like:
3
/ \
4 5
/ \
1 2
/
0
The subRoot tree:
4
/ \
1 2
Step 1: Start at root node 3. Ask: is the subtree rooted at 3 identical to subRoot? Compare node 3 vs node 4 — values differ (3 ≠ 4). Not identical.
Step 2: Move to left child, node 4. Ask: is the subtree rooted at 4 identical to subRoot? Compare node 4 vs node 4 — values match. Now recursively compare children.
Step 3: Compare left children: root's left child of 4 is node 1, subRoot's left child of 4 is node 1. Values match (1 == 1). Both node 1's have no children in subRoot. Check root's node 1 — no children either. Left subtrees match.
Step 4: Compare right children: root's right child of 4 is node 2, subRoot's right child of 4 is node 2. Values match (2 == 2). Now check node 2's children.
Step 5: In subRoot, node 2 has no children (both null). In root, node 2 has a left child with value 0. Compare: root has node 0, subRoot has null — mismatch! The subtree rooted at 4 is NOT identical to subRoot because of this extra node.
Step 6: Back up. Try right child of root (node 5). Compare node 5 vs subRoot's root node 4 — values differ (5 ≠ 4). Not identical.
Step 7: We have exhausted all candidate nodes in the root tree. No subtree matched subRoot. Return false.
Brute Force — DFS with Identity Check at Each Node — Watch how we visit each node in the main tree and attempt a full comparison against subRoot. The extra node 0 causes the match at node 4 to fail.
Algorithm
- Define a helper function
isIdentical(node1, node2)that checks if two trees are structurally identical:- If both nodes are null, return true (both empty trees are identical)
- If one is null and the other is not, return false
- If values differ, return false
- Recursively check left subtrees AND right subtrees
- Define the main function
isSubtree(root, subRoot):- If root is null, return false (empty tree has no subtrees matching a non-empty subRoot)
- If
isIdentical(root, subRoot)returns true, return true - Otherwise, recursively check
isSubtree(root.left, subRoot)ORisSubtree(root.right, subRoot)
- Return the result
Code
class Solution {
public:
bool isSubtree(TreeNode* root, TreeNode* subRoot) {
if (!root) return false;
if (isIdentical(root, subRoot)) return true;
return isSubtree(root->left, subRoot) ||
isSubtree(root->right, subRoot);
}
private:
bool isIdentical(TreeNode* node1, TreeNode* node2) {
if (!node1 && !node2) return true;
if (!node1 || !node2) return false;
if (node1->val != node2->val) return false;
return isIdentical(node1->left, node2->left) &&
isIdentical(node1->right, node2->right);
}
};class Solution:
def isSubtree(self, root: Optional[TreeNode], subRoot: Optional[TreeNode]) -> bool:
if not root:
return False
if self.is_identical(root, subRoot):
return True
return (self.isSubtree(root.left, subRoot) or
self.isSubtree(root.right, subRoot))
def is_identical(self, node1: Optional[TreeNode], node2: Optional[TreeNode]) -> bool:
if not node1 and not node2:
return True
if not node1 or not node2:
return False
if node1.val != node2.val:
return False
return (self.is_identical(node1.left, node2.left) and
self.is_identical(node1.right, node2.right))class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
if (root == null) return false;
if (isIdentical(root, subRoot)) return true;
return isSubtree(root.left, subRoot) ||
isSubtree(root.right, subRoot);
}
private boolean isIdentical(TreeNode node1, TreeNode node2) {
if (node1 == null && node2 == null) return true;
if (node1 == null || node2 == null) return false;
if (node1.val != node2.val) return false;
return isIdentical(node1.left, node2.left) &&
isIdentical(node1.right, node2.right);
}
}Complexity Analysis
Time Complexity: O(m × n)
Where m is the number of nodes in the root tree and n is the number of nodes in subRoot. In the worst case, for each of the m nodes in the root tree, we perform an identity check that visits up to n nodes. This happens when many nodes in the root tree have the same value as subRoot's root, forcing us into deep comparisons repeatedly.
Space Complexity: O(m + n)
The space is consumed by the recursion stack. In the worst case (a completely skewed tree), the DFS recursion on the root tree goes m levels deep. The identity check at each node can add up to n levels. However, since these are not simultaneous at their worst, the space is bounded by O(m + n). For balanced trees, this reduces to O(log m + log n).
Why This Approach Is Not Efficient
The brute force approach performs redundant work. Every time we find a node in the root tree whose value matches subRoot's root, we launch a full O(n) comparison. If the root tree has many nodes with the same value as subRoot's root, we repeatedly compare large portions of the trees.
With constraints of up to 2000 nodes in root and 1000 nodes in subRoot, the worst case is 2,000 × 1,000 = 2,000,000 operations. While this is manageable for the given constraints, it does not scale well.
The core inefficiency is that we treat each subtree comparison independently — we gain no information from one failed comparison that could help the next. If we could represent each tree as a string and use efficient string matching, we could solve the problem in linear time.
Key insight: if we serialize both trees into strings (using preorder traversal with null markers), the subtree check becomes a substring search problem. A substring search can be done in O(m + n) using algorithms like KMP, instead of the O(m × n) brute force comparisons.
Optimal Approach - Tree Serialization with String Matching
Intuition
Here is a powerful observation: two trees are identical if and only if their serialized representations are the same. If we convert both trees into strings using the same traversal order (say, preorder) and include markers for null children, then checking whether subRoot is a subtree of root reduces to checking whether subRoot's string appears inside root's string.
Imagine you have two documents. Instead of comparing them paragraph by paragraph (brute force), you could convert both to plain text and use a search function (like Ctrl+F) to find one inside the other. That search function uses smart algorithms under the hood (like KMP) that avoid redundant comparisons.
For tree serialization to work correctly, we must include null markers. Without them, different tree structures could produce the same string. For instance, both a left-skewed and right-skewed tree with the same values would serialize identically. Including nulls as a special character (like #) disambiguates the structure.
We also need separators between node values (like commas) to prevent ambiguity between multi-digit numbers. For example, without separators, nodes [1, 2] and [12] could be confused.
Step-by-Step Explanation
Let's trace through with root = [3,4,5,1,2], subRoot = [4,1,2].
Root tree:
3
/ \
4 5
/ \
1 2
subRoot:
4
/ \
1 2
Step 1: Serialize the root tree using preorder traversal (node → left → right), with # for null nodes and , as separator.
- Visit 3 → write ",3"
- Visit 4 → write ",4"
- Visit 1 → write ",1"
- 1's left is null → write ",#"
- 1's right is null → write ",#"
- Visit 2 → write ",2"
- 2's left is null → write ",#"
- 2's right is null → write ",#"
- Visit 5 → write ",5"
- 5's left is null → write ",#"
- 5's right is null → write ",#"
- Result: rootStr = ",3,4,1,#,#,2,#,#,5,#,#"
Step 2: Serialize subRoot the same way.
- Visit 4 → write ",4"
- Visit 1 → write ",1"
- 1's left is null → write ",#"
- 1's right is null → write ",#"
- Visit 2 → write ",2"
- 2's left is null → write ",#"
- 2's right is null → write ",#"
- Result: subStr = ",4,1,#,#,2,#,#"
Step 3: Check if subStr is a substring of rootStr.
- rootStr = ",3,4,1,#,#,2,#,#,5,#,#"
- subStr = ",4,1,#,#,2,#,#"
- Scanning rootStr... found subStr starting at index 2!
Step 4: subStr is a substring of rootStr → subRoot IS a subtree of root. Return true.
Tree Serialization and Substring Search — Watch how both trees are serialized into strings using preorder traversal with null markers, then the substring search finds subRoot's string inside root's string.
Algorithm
- Define a helper function
serialize(node)that converts a tree to a string:- If node is null, return ",#"
- Otherwise, return "," + node.val + serialize(node.left) + serialize(node.right)
- Serialize the root tree → rootStr
- Serialize the subRoot tree → subStr
- Check if subStr is a substring of rootStr
- If yes, return true (subRoot is a subtree)
- If no, return false
Important detail: Each node's value is preceded by a comma delimiter. This prevents false matches between multi-digit numbers (e.g., distinguishing node "12" from nodes "1" followed by "2").
Code
class Solution {
public:
bool isSubtree(TreeNode* root, TreeNode* subRoot) {
string rootStr = serialize(root);
string subStr = serialize(subRoot);
return rootStr.find(subStr) != string::npos;
}
private:
string serialize(TreeNode* node) {
if (!node) return ",#";
return "," + to_string(node->val) +
serialize(node->left) +
serialize(node->right);
}
};class Solution:
def isSubtree(self, root: Optional[TreeNode], subRoot: Optional[TreeNode]) -> bool:
root_str = self.serialize(root)
sub_str = self.serialize(subRoot)
return sub_str in root_str
def serialize(self, node: Optional[TreeNode]) -> str:
if not node:
return ",#"
return ("," + str(node.val) +
self.serialize(node.left) +
self.serialize(node.right))class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
String rootStr = serialize(root);
String subStr = serialize(subRoot);
return rootStr.contains(subStr);
}
private String serialize(TreeNode node) {
if (node == null) return ",#";
return "," + node.val +
serialize(node.left) +
serialize(node.right);
}
}Complexity Analysis
Time Complexity: O(m + n)
Serializing the root tree takes O(m) time (visiting each of its m nodes once). Serializing subRoot takes O(n) time. The substring search, using an efficient algorithm like KMP, takes O(m + n) time. Note that Python's in operator and Java's contains method use optimized implementations that perform well in practice, though their worst case could be O(m × n) without KMP. For a guaranteed O(m + n) solution, you would use KMP explicitly.
Space Complexity: O(m + n)
We store two serialized strings: one of length proportional to m (root tree) and one of length proportional to n (subRoot). The recursion stack during serialization also uses O(m) or O(n) space in the worst case (skewed tree), but this is dominated by the string storage.