Cheapest Flights Within K Stops
Description
You are given a network of n cities labeled from 0 to n - 1, connected by directed flights. Each flight is represented as [from, to, price], indicating a one-way flight from city from to city to with a ticket cost of price.
You are also given three integers src, dst, and k:
srcis the starting citydstis the destination citykis the maximum number of stops you can make (not countingsrcanddstthemselves)
Return the cheapest price from src to dst with at most k stops. If no such route exists, return -1.
Examples
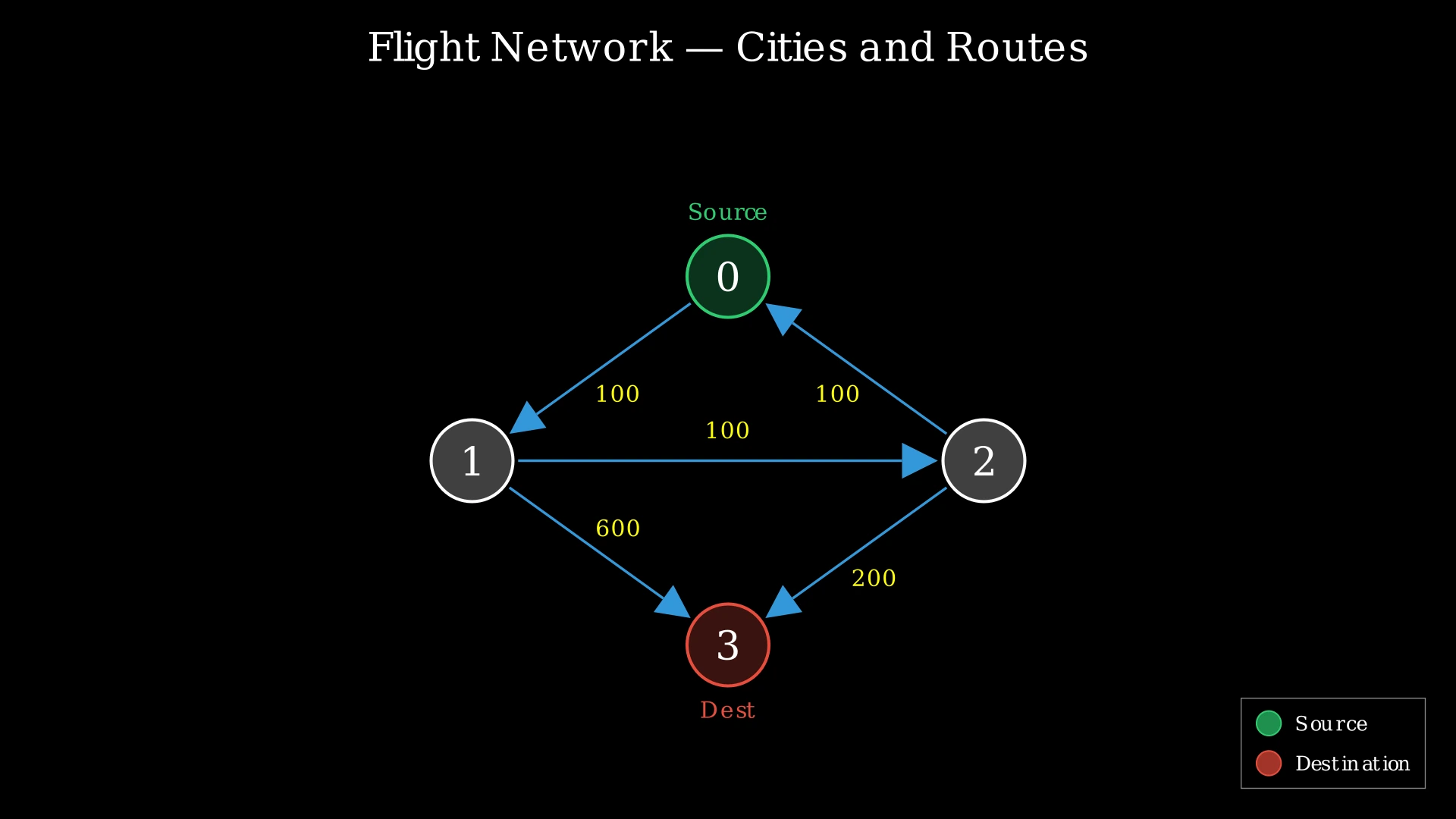
Example 1:
Input: n = 4, flights = [[0,1,100],[1,2,100],[2,0,100],[1,3,600],[2,3,200]], src = 0, dst = 3, k = 1
Output: 700
Explanation: The optimal path with at most 1 stop is 0 → 1 → 3 with cost 100 + 600 = 700. The path 0 → 1 → 2 → 3 costs only 100 + 100 + 200 = 400, but it uses 2 stops (cities 1 and 2), which exceeds k = 1.
Example 2:
Input: n = 3, flights = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 1
Output: 200
Explanation: The direct flight 0 → 2 costs 500. But taking the route 0 → 1 → 2 costs 100 + 100 = 200 with only 1 stop, which is within the limit. The cheaper route with 1 stop wins.
Example 3:
Input: n = 3, flights = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 0
Output: 500
Explanation: With k = 0, no stops are allowed — only direct flights. The only direct flight from 0 to 2 costs 500. The cheaper route 0 → 1 → 2 (cost 200) requires 1 stop, which exceeds the limit.
Constraints
2 <= n <= 1000 <= flights.length <= n * (n - 1) / 2flights[i].length == 30 <= from_i, to_i < nfrom_i != to_i1 <= price_i <= 10^4- There are no duplicate flights between any two cities
0 <= src, dst, k < nsrc != dst
Editorial
Brute Force
Intuition
The most straightforward approach is to explore every possible route from the source city to the destination city using Depth-First Search (DFS).
Imagine you're at an airport checking a departures board. You try every outgoing flight, and from each city you land at, you try every outgoing flight again — recursively exploring all paths. You keep track of two things: the total cost accumulated so far, and the number of stops you've made.
You prune any path that:
- Exceeds
kstops (invalid route) - Has already accumulated a higher cost than the best complete route you've found so far (no point continuing)
Whenever you reach the destination, you compare the total cost with your current best and update if cheaper. After exploring all paths, the best cost you found is the answer.
Step-by-Step
Let's trace through n = 3, flights = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 1:
Setup: Build adjacency list: {0: [(1,100), (2,500)], 1: [(2,100)]}. Initialize best_cost = ∞.
DFS Call 1: Start at city 0, cost=0, stops=-1.
- Try flight 0→1 (cost 100): Move to city 1, cost=100, stops=0.
DFS Call 2: At city 1, cost=100, stops=0.
- Try flight 1→2 (cost 100): Move to city 2, cost=200, stops=1.
DFS Call 3: At city 2 = destination! Total cost = 200 < ∞. Update best_cost = 200.
- Return (backtrack to DFS Call 2).
Back at DFS Call 2: No more flights from city 1. Backtrack to DFS Call 1.
Back at DFS Call 1: Try next flight 0→2 (cost 500): Move to city 2, cost=500, stops=0.
DFS Call 4: At city 2 = destination! Total cost = 500. But 500 > best_cost (200). No improvement.
- Return (backtrack to DFS Call 1).
Back at DFS Call 1: No more flights from city 0. DFS complete.
Result: best_cost = 200.
Code
class Solution {
public:
int ans;
void dfs(int node, int dst, int k, int cost,
vector<vector<pair<int,int>>>& adj) {
if (node == dst) {
ans = min(ans, cost);
return;
}
if (k < 0) return;
for (auto& [next, price] : adj[node]) {
if (cost + price < ans) {
dfs(next, dst, k - 1, cost + price, adj);
}
}
}
int findCheapestPrice(int n, vector<vector<int>>& flights,
int src, int dst, int k) {
vector<vector<pair<int,int>>> adj(n);
for (auto& f : flights)
adj[f[0]].push_back({f[1], f[2]});
ans = INT_MAX;
dfs(src, dst, k, 0, adj);
return ans == INT_MAX ? -1 : ans;
}
};class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]],
src: int, dst: int, k: int) -> int:
adj = defaultdict(list)
for u, v, w in flights:
adj[u].append((v, w))
self.best = float('inf')
def dfs(node, cost, stops):
if node == dst:
self.best = min(self.best, cost)
return
if stops < 0:
return
for nxt, price in adj[node]:
if cost + price < self.best:
dfs(nxt, cost + price, stops - 1)
dfs(src, 0, k)
return -1 if self.best == float('inf') else self.bestclass Solution {
int best = Integer.MAX_VALUE;
public int findCheapestPrice(int n, int[][] flights,
int src, int dst, int k) {
List<int[]>[] adj = new ArrayList[n];
for (int i = 0; i < n; i++)
adj[i] = new ArrayList<>();
for (int[] f : flights)
adj[f[0]].add(new int[]{f[1], f[2]});
dfs(adj, src, dst, k, 0);
return best == Integer.MAX_VALUE ? -1 : best;
}
void dfs(List<int[]>[] adj, int node, int dst,
int stops, int cost) {
if (node == dst) {
best = Math.min(best, cost);
return;
}
if (stops < 0) return;
for (int[] next : adj[node]) {
if (cost + next[1] < best)
dfs(adj, next[0], dst, stops - 1,
cost + next[1]);
}
}
}Complexity
Time Complexity: O(N^K) in the worst case. At each city, we can take up to N-1 outgoing flights, and we recurse up to K+1 levels deep. The pruning helps in practice but doesn't change the worst-case bound.
Space Complexity: O(N + E) for the adjacency list plus O(K) for the recursion stack depth. E is the number of flights.
Why This Approach Is Not Efficient
The DFS brute force explores an exponential number of paths. In the worst case with a dense graph, every city connects to every other city, giving O(N^K) paths to explore. With n ≤ 100 and k < 100, this can be astronomical.
The core problem: DFS doesn't share work between paths. If both path 0→1→3 and path 0→2→3 reach city 3, DFS explores the subpaths from city 3 independently each time, even though the work is identical.
Key insight: This is a shortest path problem with a twist — the path length is bounded by k stops. Standard shortest-path algorithms like Dijkstra are designed to avoid redundant exploration. If we modify Dijkstra to also track the number of stops used at each state, we can prune states that exceed the stop limit while leveraging the priority queue to always expand the cheapest state first.
Better Approach - Modified Dijkstra with Stop Tracking
Intuition
Standard Dijkstra finds the cheapest path in a weighted graph, but it ignores the stop constraint. A path might be cheapest overall but use too many stops, making it invalid.
The fix: treat each state as a (city, stops_used) pair. Reaching the same city with different stop counts are different states — one might be valid and the other not.
We maintain a min-heap ordered by cost. At each step, we pop the cheapest state and expand its neighbors. When we pop the destination city, that cost is guaranteed to be the cheapest valid route because the heap always gives us the minimum cost first.
We track dist[city][stops] to avoid re-processing states we've already found a cheaper way to reach. If the current cost is worse than the recorded best for this (city, stops) pair, we skip it.
Step-by-Step
Let's trace through n = 3, flights = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 1:
Setup: Build adjacency list. Initialize dist[city][stops] = ∞. Heap = [(cost=0, city=0, stops=-1)].
Step 1: Pop (0, city=0, stops=-1). City 0 ≠ dst. Stops=-1 < k=1, can extend. Explore neighbors.
Step 2: Relax edge 0→1 (cost 100). New cost = 0+100 = 100. dist[1][0] was ∞, update to 100. Push (100, city=1, stops=0) to heap.
Step 3: Relax edge 0→2 (cost 500). New cost = 0+500 = 500. dist[2][0] was ∞, update to 500. Push (500, city=2, stops=0) to heap.
Step 4: Pop (100, city=1, stops=0). City 1 ≠ dst. Stops=0 < k=1, can extend. Explore neighbors.
Step 5: Relax edge 1→2 (cost 100). New cost = 100+100 = 200. dist[2][1] was ∞, update to 200. Push (200, city=2, stops=1) to heap.
Step 6: Pop (200, city=2, stops=1). City 2 = dst! Return 200.
Note: (500, city=2, stops=0) is still in the heap but will never be popped because we already found a cheaper route.
Result: Cheapest price = 200. Path: 0 → 1 → 2 with 1 stop.
Initialize distances, set src=0 cost to 0, all others ∞ — Initialize distances, set src=0 cost to 0, all others ∞. Push (0, city=0, stops=-1) to min-heap.
Code
class Solution {
public:
int findCheapestPrice(int n, vector<vector<int>>& flights,
int src, int dst, int k) {
vector<vector<pair<int,int>>> adj(n);
for (auto& f : flights)
adj[f[0]].push_back({f[1], f[2]});
// dist[city][stops+1] = best cost
vector<vector<int>> dist(n, vector<int>(k + 5, INT_MAX));
dist[src][0] = 0;
// min-heap: (cost, city, stops)
priority_queue<tuple<int,int,int>,
vector<tuple<int,int,int>>,
greater<>> pq;
pq.push({0, src, -1});
while (!pq.empty()) {
auto [cost, node, stops] = pq.top();
pq.pop();
if (node == dst) return cost;
if (stops == k) continue;
if (dist[node][stops + 1] < cost) continue;
for (auto& [next, price] : adj[node]) {
int nc = cost + price;
int ns = stops + 1;
if (nc < dist[next][ns + 1]) {
dist[next][ns + 1] = nc;
pq.push({nc, next, ns});
}
}
}
return -1;
}
};class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]],
src: int, dst: int, k: int) -> int:
adj = defaultdict(list)
for u, v, w in flights:
adj[u].append((v, w))
dist = [[float('inf')] * (k + 5) for _ in range(n)]
dist[src][0] = 0
heap = [(0, src, -1)] # (cost, city, stops)
while heap:
cost, node, stops = heapq.heappop(heap)
if node == dst:
return cost
if stops == k or dist[node][stops + 1] < cost:
continue
for nxt, price in adj[node]:
nc = cost + price
ns = stops + 1
if nc < dist[nxt][ns + 1]:
dist[nxt][ns + 1] = nc
heapq.heappush(heap, (nc, nxt, ns))
return -1class Solution {
public int findCheapestPrice(int n, int[][] flights,
int src, int dst, int k) {
List<int[]>[] adj = new ArrayList[n];
for (int i = 0; i < n; i++)
adj[i] = new ArrayList<>();
for (int[] f : flights)
adj[f[0]].add(new int[]{f[1], f[2]});
int[][] dist = new int[n][k + 5];
for (int[] row : dist)
Arrays.fill(row, Integer.MAX_VALUE);
dist[src][0] = 0;
// min-heap: [cost, city, stops]
PriorityQueue<int[]> pq =
new PriorityQueue<>((a, b) -> a[0] - b[0]);
pq.offer(new int[]{0, src, -1});
while (!pq.isEmpty()) {
int[] cur = pq.poll();
int cost = cur[0], node = cur[1], stops = cur[2];
if (node == dst) return cost;
if (stops == k) continue;
if (dist[node][stops + 1] < cost) continue;
for (int[] next : adj[node]) {
int nc = cost + next[1];
int ns = stops + 1;
if (nc < dist[next[0]][ns + 1]) {
dist[next[0]][ns + 1] = nc;
pq.offer(new int[]{nc, next[0], ns});
}
}
}
return -1;
}
}Complexity
Time Complexity: O((N + E) × K × log(N × K)) where N is the number of cities, E is the number of flights, and K is the maximum stops. Each (city, stops) state can be pushed to the heap once, giving O(N × K) states. Each heap operation costs O(log(N × K)).
Space Complexity: O(N × K) for the dist array tracking best costs per (city, stops) pair, plus O(N × K) for the heap in the worst case.
Why This Approach Is Not Efficient
Modified Dijkstra works correctly, but it has significant overhead:
-
State explosion: Tracking
(city, stops)pairs creates up toN × Kdistinct states. Each state may be pushed to the heap, leading toO(N × K)heap entries. -
Extra space: The 2D
dist[city][stops]table requiresO(N × K)space, compared to a simpler 1D array. -
Heap overhead: Each heap push/pop costs
O(log(N × K)). For large K values, this logarithmic factor adds up. -
Implementation complexity: Managing the
(cost, city, stops)tuples and the 2D distance table is error-prone. Off-by-one errors in stop counting are a common pitfall.
Key insight for improvement: The Bellman-Ford algorithm naturally controls the number of edges (and thus stops) through its iteration count. Instead of tracking stops as part of the state, we simply run exactly K+1 iterations of edge relaxation. After i iterations, the distance array contains the cheapest costs using at most i edges. This eliminates the need for a heap and reduces space to O(N).
Optimal Approach - Bellman-Ford with K+1 Iterations
Intuition
The Bellman-Ford algorithm is a perfect fit for this problem because it naturally controls the number of edges used in the shortest path through its iteration count.
How it works:
- Maintain a
distarray wheredist[i]= cheapest cost to reach cityifromsrc. - Run exactly
K+1iterations (sinceKstops means at mostK+1flights). - In each iteration, try to relax every edge: if going through flight
(u → v, price)gives a cheaper path tov, updatedist[v].
Why K+1 iterations?
- After 1 iteration: knows best costs using at most 1 flight (direct flights)
- After 2 iterations: knows best costs using at most 2 flights (1 stop)
- After
K+1iterations: knows best costs using at mostK+1flights (Kstops)
Critical detail — the backup array: Before each iteration, we copy dist into a backup array and read from backup when relaxing. This prevents "chaining" within a single iteration — without the backup, updating dist[1] and then using the updated dist[1] to update dist[2] in the same iteration would effectively use 2 flights in 1 iteration, violating the stop constraint.
Step-by-Step
Let's trace through n = 3, flights = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 1:
Setup: dist = [0, ∞, ∞]. We need K+1 = 2 iterations.
Iteration 1 (direct flights):
backup = [0, ∞, ∞](snapshot before this round)- Flight [0,1,100]:
dist[1] = min(∞, backup[0] + 100) = min(∞, 100) = 100✓ improved - Flight [1,2,100]:
dist[2] = min(∞, backup[1] + 100) = min(∞, ∞+100) = ∞✗ can't use (city 1 not yet reached in backup) - Flight [0,2,500]:
dist[2] = min(∞, backup[0] + 500) = min(∞, 500) = 500✓ improved - After iteration 1:
dist = [0, 100, 500]
Iteration 2 (paths with 1 stop):
backup = [0, 100, 500](snapshot)- Flight [0,1,100]:
dist[1] = min(100, backup[0] + 100) = min(100, 100) = 100✗ no improvement - Flight [1,2,100]:
dist[2] = min(500, backup[1] + 100) = min(500, 200) = 200✓ improved! Path 0→1→2 costs 200 - Flight [0,2,500]:
dist[2] = min(200, backup[0] + 500) = min(200, 500) = 200✗ no improvement - After iteration 2:
dist = [0, 100, 200]
Result: dist[2] = 200. Cheapest price with at most 1 stop is 200.
Initialize dist array: src=0 has cost 0, all others ∞ — Initialize dist array: src=0 has cost 0, all others ∞. Need K+1 = 2 iterations.
Code
class Solution {
public:
int findCheapestPrice(int n, vector<vector<int>>& flights,
int src, int dst, int k) {
const int INF = 1e9;
vector<int> dist(n, INF);
dist[src] = 0;
for (int i = 0; i <= k; i++) {
vector<int> backup(dist);
for (auto& f : flights) {
int u = f[0], v = f[1], w = f[2];
if (backup[u] < INF)
dist[v] = min(dist[v], backup[u] + w);
}
}
return dist[dst] >= INF ? -1 : dist[dst];
}
};class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]],
src: int, dst: int, k: int) -> int:
INF = float('inf')
dist = [INF] * n
dist[src] = 0
for _ in range(k + 1):
backup = dist.copy()
for u, v, w in flights:
if backup[u] < INF:
dist[v] = min(dist[v], backup[u] + w)
return -1 if dist[dst] == INF else dist[dst]class Solution {
public int findCheapestPrice(int n, int[][] flights,
int src, int dst, int k) {
final int INF = (int) 1e9;
int[] dist = new int[n];
Arrays.fill(dist, INF);
dist[src] = 0;
for (int i = 0; i <= k; i++) {
int[] backup = dist.clone();
for (int[] f : flights) {
int u = f[0], v = f[1], w = f[2];
if (backup[u] < INF)
dist[v] = Math.min(dist[v],
backup[u] + w);
}
}
return dist[dst] >= INF ? -1 : dist[dst];
}
}Complexity
Time Complexity: O((K + 1) × E) where K is the maximum number of stops and E is the number of flights. We run K + 1 iterations, and in each iteration we relax all E edges. Each relaxation is O(1). With K < 100 and E ≤ 4950, this is at most ~500,000 operations.
Space Complexity: O(N) where N is the number of cities. We maintain two arrays of size N — the dist array and its backup copy. No adjacency list, no heap, no 2D table needed.