Reconstruct Itinerary
Description
You are given a list of airline tickets where each ticket is represented as a pair [from, to], indicating a direct flight from the departure airport from to the arrival airport to.
Your task is to reconstruct the complete travel itinerary that uses every ticket exactly once, starting from the airport "JFK" (John F. Kennedy International Airport).
If multiple valid itineraries exist (i.e., more than one ordering of flights uses all tickets), return the itinerary that has the smallest lexical order when read as a single sequence of airport codes.
For example, the itinerary ["JFK", "LGA"] is lexicographically smaller than ["JFK", "LGB"] because "LGA" comes before "LGB" alphabetically.
You may assume that all tickets together form at least one valid itinerary — there is always a way to use every ticket exactly once.
Examples
Example 1
Input: tickets = [["MUC","LHR"],["JFK","MUC"],["SFO","SJC"],["LHR","SFO"]]
Output: ["JFK","MUC","LHR","SFO","SJC"]
Explanation: The journey starts at JFK. From JFK, the only available flight goes to MUC. From MUC, the only flight goes to LHR. From LHR, the only flight goes to SFO. From SFO, the only flight goes to SJC. All 4 tickets are used exactly once, forming a single chain: JFK → MUC → LHR → SFO → SJC.
Example 2
Input: tickets = [["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
Output: ["JFK","ATL","JFK","SFO","ATL","SFO"]
Explanation: There are multiple valid itineraries that use all 5 tickets. One possibility is ["JFK","SFO","ATL","JFK","ATL","SFO"], but ["JFK","ATL","JFK","SFO","ATL","SFO"] is lexicographically smaller because the second element "ATL" comes before "SFO" alphabetically. We return the lexicographically smallest valid itinerary.
Constraints
- 1 ≤ tickets.length ≤ 300
- tickets[i].length == 2
- from_i.length == 3
- to_i.length == 3
- from_i and to_i consist of uppercase English letters
- from_i ≠ to_i
- All tickets form at least one valid itinerary
Editorial
Brute Force
Intuition
Think of the airports as cities on a map and the tickets as one-way roads between them. You are standing at JFK and must drive along every road exactly once. The simplest idea is to try all possible routes and pick the one that is alphabetically smallest.
We model this as a directed graph where airports are nodes and tickets are directed edges. We need to find a path from JFK that traverses every edge exactly once.
The brute force strategy is DFS with backtracking: from the current airport, sort the available destinations alphabetically and try each one. If we reach a dead end (no unused tickets from the current airport) before using all tickets, we backtrack — undo the last flight and try the next destination.
Because we always try destinations in alphabetical order, the first complete path we find is guaranteed to be the lexicographically smallest valid itinerary.
Step-by-Step Explanation
Let's trace through Example 2: tickets = [["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
First, build a directed graph and sort each airport's destinations alphabetically:
- JFK → [ATL, SFO]
- ATL → [JFK, SFO]
- SFO → [ATL]
Step 1: Start at JFK. Path = [JFK]. We have 5 tickets to use. Sorted destinations from JFK: ATL, SFO. Try ATL first (lexicographically smallest).
Step 2: Fly JFK→ATL. Path = [JFK, ATL]. Tickets used: 1/5. From ATL, sorted unused destinations: JFK, SFO. Try JFK first.
Step 3: Fly ATL→JFK. Path = [JFK, ATL, JFK]. Tickets used: 2/5. From JFK, only unused ticket: JFK→SFO (JFK→ATL already used).
Step 4: Fly JFK→SFO. Path = [JFK, ATL, JFK, SFO]. Tickets used: 3/5. From SFO, only destination: ATL.
Step 5: Fly SFO→ATL. Path = [JFK, ATL, JFK, SFO, ATL]. Tickets used: 4/5. From ATL, only unused ticket: ATL→SFO (ATL→JFK already used).
Step 6: Fly ATL→SFO. Path = [JFK, ATL, JFK, SFO, ATL, SFO]. Tickets used: 5/5. All tickets consumed!
Step 7: Return ["JFK","ATL","JFK","SFO","ATL","SFO"]. Since we tried alphabetical destinations first, this is the lexicographically smallest valid itinerary.
DFS Backtracking — Building the Itinerary from JFK — Watch how DFS explores flights in alphabetical order, marking each ticket as used, to build the lexicographically smallest valid itinerary.
Algorithm
- Sort all tickets so that destinations from each airport appear in alphabetical order
- Build an adjacency list graph from the sorted tickets
- Create a parallel
usedarray for each airport to track which tickets have been consumed - Initialize the path with
["JFK"] - Run DFS:
- If the path length equals (number of tickets + 1), all tickets are used — return
true - For each unused ticket from the current airport (in alphabetical order):
- Mark the ticket as used and append the destination to the path
- Recursively call DFS
- If DFS returns
true, propagate success upward - Otherwise, unmark the ticket and remove the destination (backtrack)
- If no destination leads to a complete itinerary, return
false
- If the path length equals (number of tickets + 1), all tickets are used — return
- Return the completed path
Code
class Solution {
public:
vector<string> findItinerary(vector<vector<string>>& tickets) {
sort(tickets.begin(), tickets.end());
unordered_map<string, vector<string>> graph;
unordered_map<string, vector<bool>> used;
for (auto& t : tickets) {
graph[t[0]].push_back(t[1]);
}
for (auto& [src, dests] : graph) {
used[src].assign(dests.size(), false);
}
vector<string> path = {"JFK"};
int n = tickets.size();
function<bool()> dfs = [&]() -> bool {
if ((int)path.size() == n + 1) return true;
string curr = path.back();
for (int i = 0; i < (int)graph[curr].size(); i++) {
if (!used[curr][i]) {
used[curr][i] = true;
path.push_back(graph[curr][i]);
if (dfs()) return true;
path.pop_back();
used[curr][i] = false;
}
}
return false;
};
dfs();
return path;
}
};class Solution:
def findItinerary(self, tickets: list[list[str]]) -> list[str]:
from collections import defaultdict
tickets.sort()
graph = defaultdict(list)
for src, dst in tickets:
graph[src].append(dst)
used = {}
for src in graph:
used[src] = [False] * len(graph[src])
path = ["JFK"]
def dfs():
if len(path) == len(tickets) + 1:
return True
curr = path[-1]
for i in range(len(graph[curr])):
if not used[curr][i]:
used[curr][i] = True
path.append(graph[curr][i])
if dfs():
return True
path.pop()
used[curr][i] = False
return False
dfs()
return pathclass Solution {
public List<String> findItinerary(List<List<String>> tickets) {
Collections.sort(tickets, (a, b) -> {
if (!a.get(0).equals(b.get(0)))
return a.get(0).compareTo(b.get(0));
return a.get(1).compareTo(b.get(1));
});
Map<String, List<String>> graph = new HashMap<>();
Map<String, boolean[]> used = new HashMap<>();
for (List<String> t : tickets) {
graph.computeIfAbsent(t.get(0), k -> new ArrayList<>()).add(t.get(1));
}
for (String key : graph.keySet()) {
used.put(key, new boolean[graph.get(key).size()]);
}
List<String> path = new ArrayList<>();
path.add("JFK");
dfs(graph, used, path, tickets.size());
return path;
}
private boolean dfs(Map<String, List<String>> graph,
Map<String, boolean[]> used,
List<String> path, int total) {
if (path.size() == total + 1) return true;
String curr = path.get(path.size() - 1);
if (!graph.containsKey(curr)) return false;
List<String> dests = graph.get(curr);
boolean[] usedArr = used.get(curr);
for (int i = 0; i < dests.size(); i++) {
if (!usedArr[i]) {
usedArr[i] = true;
path.add(dests.get(i));
if (dfs(graph, used, path, total)) return true;
path.remove(path.size() - 1);
usedArr[i] = false;
}
}
return false;
}
}Complexity Analysis
Time Complexity: O(E! × E) in the worst case, where E is the number of tickets (edges)
At each airport, the DFS may try up to deg(v) outgoing edges. In the worst case, the algorithm explores all possible orderings of edges before finding a valid complete path. The number of such orderings can be as large as the product of factorials of all node outdegrees, which is bounded by O(E!). At each step, extending and copying the path costs O(E). The initial sorting step is O(E log E), which is dominated by the DFS cost.
Space Complexity: O(E + V)
The graph adjacency list stores all E edges, and the used boolean arrays also take O(E) space. The recursion stack can go as deep as E levels (one level per ticket used). V is the number of unique airports.
Why This Approach Is Not Efficient
The brute force DFS with backtracking has a worst-case time complexity of O(E!), which is factorial in the number of tickets. With up to 300 tickets, E! is astronomically large — far beyond what any computer can process.
The fundamental problem is that the algorithm tries all possible orderings of tickets at each airport. When multiple airports have multiple outgoing flights, the number of candidate paths grows combinatorially. Even if many inputs are solved without backtracking, adversarial inputs can force the algorithm to explore a vast number of dead-end paths before finding the valid one.
Key insight: This problem is actually an Eulerian path problem — finding a path through a directed graph that visits every edge exactly once. Euler proved in the 18th century that such paths have special structural properties. An algorithm called Hierholzer's algorithm exploits these properties to find the Eulerian path in just O(E) time (after sorting), completely avoiding the exponential backtracking.
Optimal Approach - Hierholzer's Algorithm
Intuition
Instead of trying all paths and backtracking when stuck, we can use a mathematical insight: this problem is equivalent to finding an Eulerian path — a path that traverses every edge in a directed graph exactly once.
Hierholzer's algorithm finds Eulerian paths efficiently by building the path backwards using post-order DFS. Here is the core idea:
-
Sort destinations in reverse alphabetical order for each airport, then store them in a list. When we
pop()from the end of the list, we get the lexicographically smallest available destination. -
Perform DFS from JFK. At each airport, repeatedly pop the smallest destination and recurse. Keep going until the current airport has no more outgoing edges.
-
When an airport runs out of outgoing edges (a dead end in the DFS), append it to the result. This is the post-order step — we record an airport only after we have exhausted all paths from it.
-
Reverse the result at the end. Since we recorded airports as we backtracked from dead ends, the reversed list gives the correct forward itinerary.
The magic is that post-order recording naturally handles the tricky cases where a naive greedy approach would get stuck. Dead-end airports get recorded first, and the path 'wraps around' them correctly when reversed.
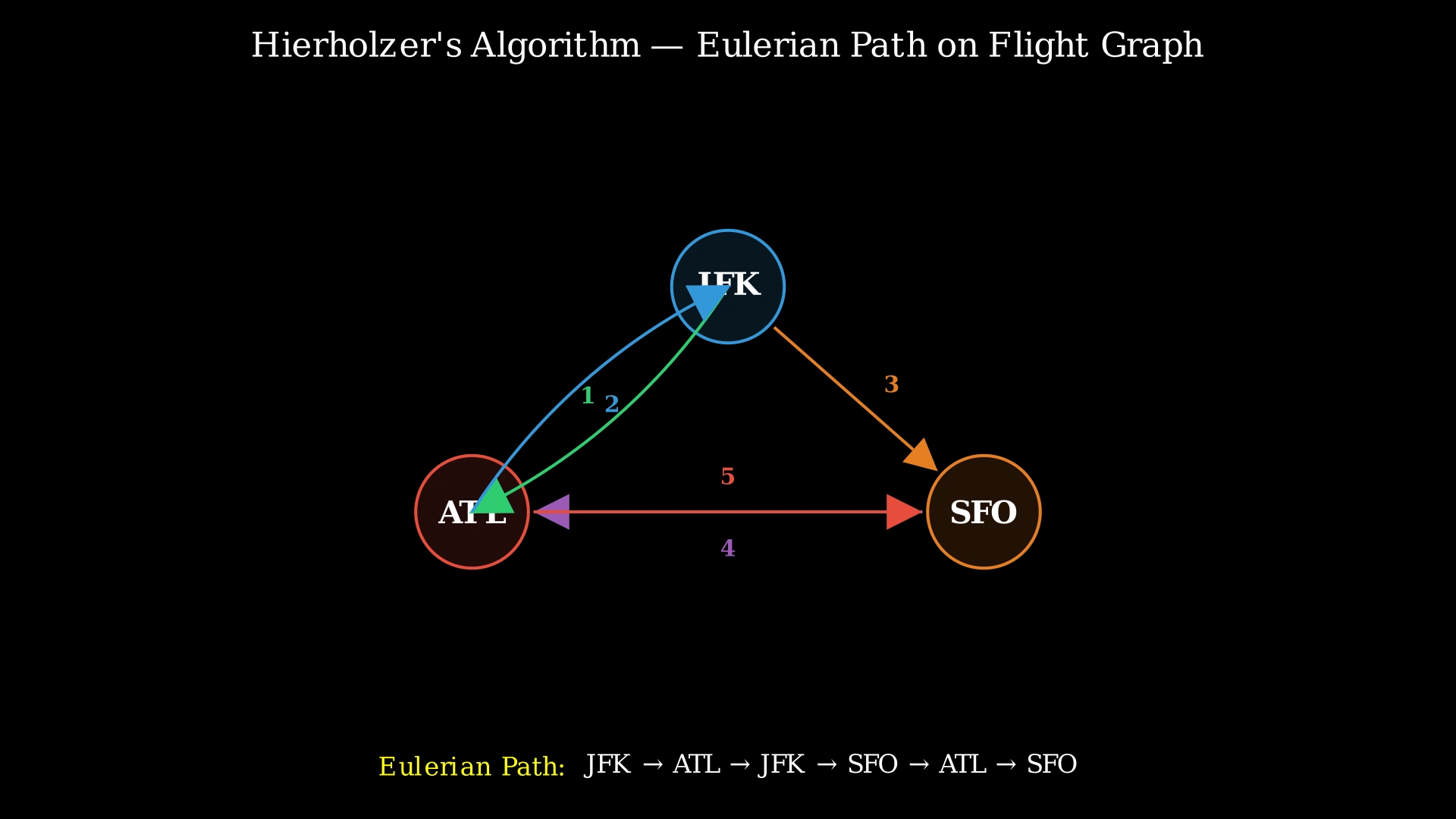
Step-by-Step Explanation
Let's trace Hierholzer's algorithm on Example 2: tickets = [["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
Step 1: Sort tickets in reverse alphabetical order and build adjacency lists. After building:
- JFK: [SFO, ATL] — pop() gives ATL (lex smallest)
- ATL: [SFO, JFK] — pop() gives JFK (lex smallest)
- SFO: [ATL] — pop() gives ATL
Step 2: Start DFS("JFK"). Pop ATL from JFK's list → traverse JFK→ATL. Call DFS("ATL").
Step 3: DFS("ATL"): Pop JFK from ATL's list → traverse ATL→JFK. Call DFS("JFK").
Step 4: DFS("JFK"): Pop SFO from JFK's list (last remaining) → traverse JFK→SFO. Call DFS("SFO").
Step 5: DFS("SFO"): Pop ATL from SFO's list → traverse SFO→ATL. Call DFS("ATL").
Step 6: DFS("ATL"): Pop SFO from ATL's list (last remaining) → traverse ATL→SFO. Call DFS("SFO").
Step 7: DFS("SFO"): No outgoing edges left — dead end! Append "SFO" to result. result = [SFO]. Return.
Step 8: Back to DFS("ATL"): No more outgoing edges. Append "ATL" to result. result = [SFO, ATL]. Return.
Step 9: Back to DFS("SFO"): No more outgoing edges. Append "SFO" to result. result = [SFO, ATL, SFO]. Return.
Step 10: Back to DFS("JFK"): No more outgoing edges. Append "JFK" to result. result = [SFO, ATL, SFO, JFK]. Return.
Step 11: Back to DFS("ATL"): No more outgoing edges. Append "ATL" to result. result = [SFO, ATL, SFO, JFK, ATL]. Return.
Step 12: Back to DFS("JFK") (root): No more outgoing edges. Append "JFK" to result. result = [SFO, ATL, SFO, JFK, ATL, JFK]. Return.
Step 13: Reverse the result: [JFK, ATL, JFK, SFO, ATL, SFO]. This is the Eulerian path — the lexicographically smallest itinerary.
Hierholzer's Algorithm — Post-Order DFS on Flight Graph — Watch how Hierholzer's algorithm traverses every edge, then builds the itinerary backwards by appending airports to the result during the post-order backtracking phase.
Algorithm
- Sort all tickets in reverse alphabetical order
- Build an adjacency list graph from the sorted tickets (append each destination to its source's list)
- Initialize an empty result list
- Define a recursive DFS function that takes an airport:
- While the airport has remaining outgoing edges:
- Pop the last destination from the list (which is the lexicographically smallest due to reverse sorting)
- Recursively call DFS on that destination
- After all outgoing edges are exhausted, append the current airport to the result (post-order)
- While the airport has remaining outgoing edges:
- Call DFS starting from
"JFK" - Reverse the result list and return it as the itinerary
Code
class Solution {
public:
vector<string> findItinerary(vector<vector<string>>& tickets) {
unordered_map<string, vector<string>> graph;
sort(tickets.begin(), tickets.end(), greater<>());
for (auto& t : tickets) {
graph[t[0]].push_back(t[1]);
}
vector<string> result;
function<void(const string&)> dfs = [&](const string& airport) {
while (!graph[airport].empty()) {
string next = graph[airport].back();
graph[airport].pop_back();
dfs(next);
}
result.push_back(airport);
};
dfs("JFK");
reverse(result.begin(), result.end());
return result;
}
};class Solution:
def findItinerary(self, tickets: list[list[str]]) -> list[str]:
from collections import defaultdict
graph = defaultdict(list)
for src, dst in sorted(tickets, reverse=True):
graph[src].append(dst)
result = []
def dfs(airport: str) -> None:
while graph[airport]:
next_airport = graph[airport].pop()
dfs(next_airport)
result.append(airport)
dfs("JFK")
return result[::-1]class Solution {
private Map<String, PriorityQueue<String>> graph = new HashMap<>();
private LinkedList<String> result = new LinkedList<>();
public List<String> findItinerary(List<List<String>> tickets) {
for (List<String> t : tickets) {
graph.computeIfAbsent(t.get(0), k -> new PriorityQueue<>()).add(t.get(1));
}
dfs("JFK");
return result;
}
private void dfs(String airport) {
PriorityQueue<String> dests = graph.get(airport);
while (dests != null && !dests.isEmpty()) {
dfs(dests.poll());
}
result.addFirst(airport);
}
}Complexity Analysis
Time Complexity: O(E log E), where E is the number of tickets (edges)
The dominant cost is sorting the tickets, which takes O(E log E). The DFS itself visits each edge exactly once — each pop() removes one edge and each airport is appended to the result exactly once, so the traversal is O(E). The total is O(E log E) + O(E) = O(E log E). For the Java variant using a PriorityQueue, each insert and poll operation costs O(log E), and there are E of each, giving O(E log E) overall — the same complexity.
Space Complexity: O(E)
The adjacency list stores all E edges across all airports. The result list holds E + 1 entries (one more than the number of edges, since it includes the starting airport). The recursion stack can go up to E levels deep in the worst case (a single long chain of flights). Therefore the total space usage is O(E).