Longest Common Subsequence
Description
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string formed by selecting zero or more characters from the original string, without rearranging the order of the remaining characters. For instance, "ace" is a subsequence of "abcde" because you can remove 'b' and 'd' to get "ace", but "aec" is not a subsequence because the characters are not in the original order.
A common subsequence of two strings is any subsequence that appears in both strings. The longest common subsequence (LCS) is the common subsequence with the greatest length.
Your task is to find and return the length of this longest common subsequence.
Examples
Example 1
Input: text1 = "abcde", text2 = "ace"
Output: 3
Explanation: The longest common subsequence is "ace". We can find 'a' at position 0, 'c' at position 2, and 'e' at position 4 in text1, and all three appear in order in text2. No common subsequence of length 4 or more exists, so the answer is 3.
Example 2
Input: text1 = "abc", text2 = "abc"
Output: 3
Explanation: The two strings are identical, so the entire string "abc" is a common subsequence. Since the full string matches, the LCS length is 3.
Example 3
Input: text1 = "abc", text2 = "def"
Output: 0
Explanation: The two strings share no characters at all. Since no character from text1 appears in text2, there is no common subsequence, and the result is 0.
Constraints
- 1 ≤ text1.length, text2.length ≤ 1000
- text1 and text2 consist of only lowercase English characters.
Editorial
Brute Force
Intuition
The most natural way to think about this problem is to compare both strings character by character from the end (or from the beginning) and make choices at each step.
Imagine you are holding the two strings side by side and you start reading them from their last characters. At each position, you ask yourself a simple question: do the current characters match?
If they match, that character must be part of the LCS, so you include it and move both pointers backward to solve a smaller version of the same problem.
If they do not match, you have a decision to make — which pointer should you move? Maybe skipping the last character of the first string leads to a longer common subsequence, or maybe skipping the last character of the second string does. Since you do not know which choice is better, you try both options and take whichever gives the larger answer.
This is pure recursion: break the problem into smaller subproblems, solve them, and combine their results. It works correctly but explores many redundant paths.
Step-by-Step Explanation
Let's trace through with text1 = "abcde", text2 = "ace":
We call lcs("abcde", "ace"), comparing from the end using indices i and j.
Step 1: i=4, j=2. Compare text1[4]='e' with text2[2]='e'. They match! Include this character and recurse on lcs(i=3, j=1). LCS so far: +1.
Step 2: i=3, j=1. Compare text1[3]='d' with text2[1]='c'. They do not match. We must try two paths: skip text1[3] → lcs(i=2, j=1), and skip text2[1] → lcs(i=3, j=0).
Step 3 (Path A): i=2, j=1. Compare text1[2]='c' with text2[1]='c'. They match! Include this character and recurse on lcs(i=1, j=0). LCS from this path: +1.
Step 4 (Path A continued): i=1, j=0. Compare text1[1]='b' with text2[0]='a'. They do not match. Try lcs(i=0, j=0) and lcs(i=1, j=-1).
Step 5 (Path A, sub-path 1): i=0, j=0. Compare text1[0]='a' with text2[0]='a'. They match! Include it and recurse on lcs(i=-1, j=-1). LCS: +1.
Step 6 (Path A, sub-path 1): i=-1. Base case reached — one string is exhausted, return 0.
Step 7 (Path A, sub-path 2): i=1, j=-1. Base case — j is exhausted, return 0.
Step 8: Path A sub-path 1 returns 1 (from the 'a' match). Path A sub-path 2 returns 0. max(1, 0) = 1. Adding the 'c' match from Step 3: 1 + 1 = 2.
Step 9 (Path B): i=3, j=0. Compare text1[3]='d' with text2[0]='a'. No match. Try lcs(i=2, j=0) and lcs(i=3, j=-1).
Step 10 (Path B continued): Eventually, Path B finds at most the 'a' match, returning 1.
Step 11: Back at Step 2: max(Path A=2, Path B=1) = 2. Adding the 'e' match from Step 1: 1 + 2 = 3.
Result: LCS length = 3, corresponding to "ace".
Recursive Exploration of LCS("abcde", "ace") — Watch how the recursive approach branches at each mismatch, exploring both possibilities — skip a character from text1 or skip from text2 — and collapses when characters match.
Algorithm
- Define a recursive function
lcs(i, j)that returns the LCS length for text1[0..i] and text2[0..j] - Base case: If
i < 0orj < 0, return 0 (one string is exhausted) - Match: If
text1[i] == text2[j], return1 + lcs(i-1, j-1)— include this character - Mismatch: If
text1[i] != text2[j], returnmax(lcs(i-1, j), lcs(i, j-1))— try skipping each character and take the better result - Call
lcs(m-1, n-1)where m and n are the lengths of text1 and text2
Code
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
return lcs(text1, text2, text1.size() - 1, text2.size() - 1);
}
int lcs(string& s1, string& s2, int i, int j) {
// Base case: one string is exhausted
if (i < 0 || j < 0) return 0;
// Characters match — include in LCS
if (s1[i] == s2[j]) {
return 1 + lcs(s1, s2, i - 1, j - 1);
}
// Characters don't match — try both options
return max(lcs(s1, s2, i - 1, j), lcs(s1, s2, i, j - 1));
}
};class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
def lcs(i: int, j: int) -> int:
# Base case: one string is exhausted
if i < 0 or j < 0:
return 0
# Characters match — include in LCS
if text1[i] == text2[j]:
return 1 + lcs(i - 1, j - 1)
# Characters don't match — try both options
return max(lcs(i - 1, j), lcs(i, j - 1))
return lcs(len(text1) - 1, len(text2) - 1)class Solution {
public int longestCommonSubsequence(String text1, String text2) {
return lcs(text1, text2, text1.length() - 1, text2.length() - 1);
}
private int lcs(String s1, String s2, int i, int j) {
// Base case: one string is exhausted
if (i < 0 || j < 0) return 0;
// Characters match — include in LCS
if (s1.charAt(i) == s2.charAt(j)) {
return 1 + lcs(s1, s2, i - 1, j - 1);
}
// Characters don't match — try both options
return Math.max(lcs(s1, s2, i - 1, j), lcs(s1, s2, i, j - 1));
}
}Complexity Analysis
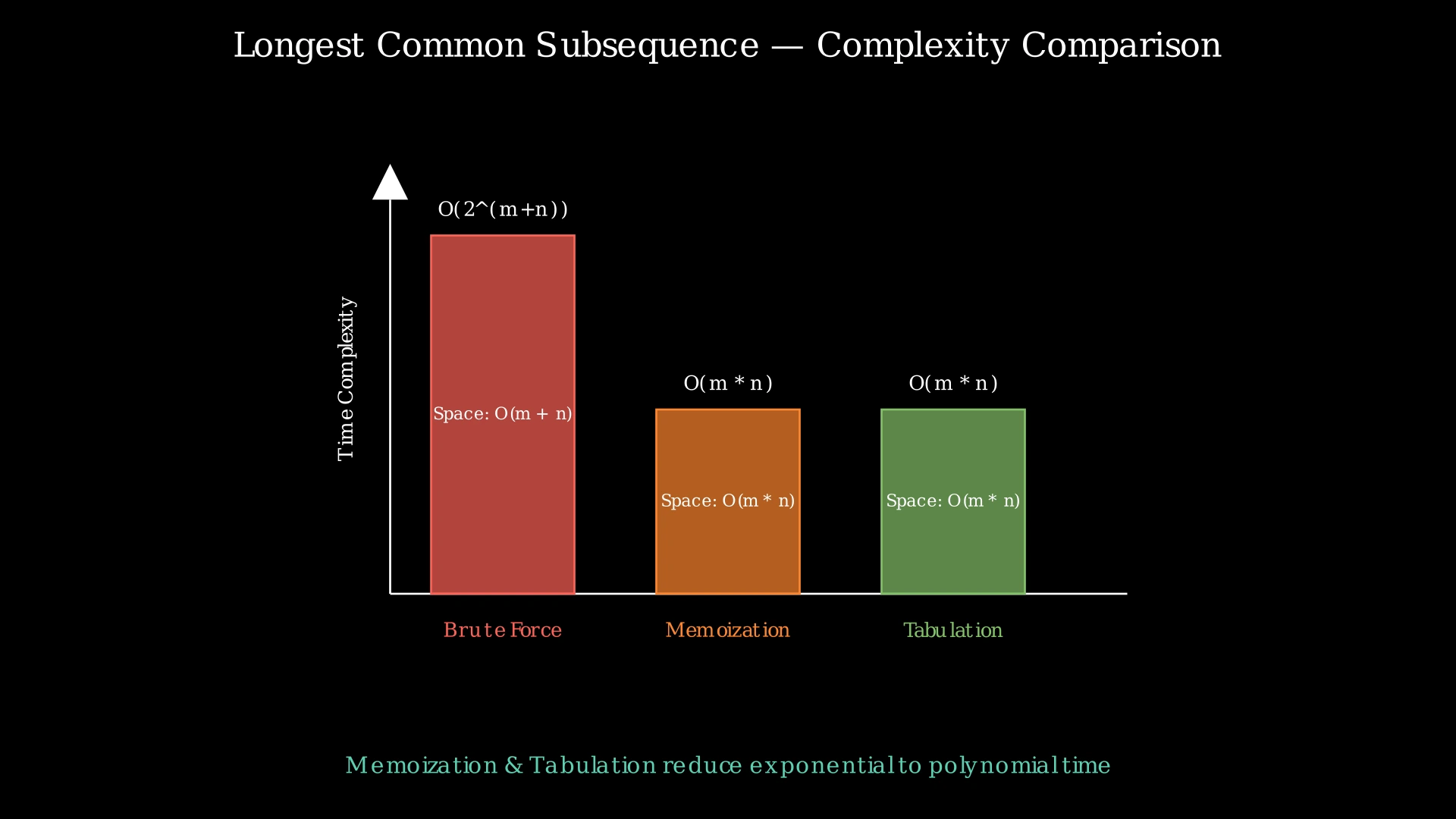
Time Complexity: O(2^min(m, n))
In the worst case (when no characters match), every call branches into two recursive calls. The recursion tree can grow exponentially. The depth of the tree is bounded by min(m, n), and at each level the number of nodes can double, leading to exponential time.
Space Complexity: O(m + n)
The recursion stack can go as deep as m + n in the worst case (when we alternate between reducing i and reducing j). Each stack frame uses constant space, so the total space is proportional to the sum of the string lengths.
Why This Approach Is Not Efficient
The pure recursive approach has exponential time complexity O(2^min(m, n)). For strings of length 1000, this means potentially 2^1000 operations — a number far larger than the number of atoms in the observable universe.
The root cause is overlapping subproblems. The same pair (i, j) gets computed over and over again through different recursive paths. For example, lcs(2, 1) might be reached by first skipping text1[3] and then skipping text1[4], or by first skipping text1[4] and then skipping text1[3]. Both paths lead to the exact same subproblem, but the naive recursion solves it from scratch each time.
The key insight is that there are only m × n unique subproblems (one for each pair of indices). If we store the result of each subproblem after computing it once, we can avoid all the redundant work. This is the essence of memoization — caching previously computed results for instant retrieval.
Better Approach - Memoization (Top-Down DP)
Intuition
The memoization approach keeps the same recursive structure as the brute force but adds one crucial improvement: a memory table that stores the answer to every subproblem we have already solved.
Think of it like a student taking an exam who realizes they keep re-deriving the same intermediate results. A smart student would jot down the answer the first time they compute it, and simply look it up whenever the same question appears again.
We create a 2D table of size m × n (where m and n are the lengths of the two strings). Each cell memo[i][j] stores the LCS length for the substrings text1[0..i] and text2[0..j]. Before making any recursive call, we check if the answer is already in our memo table. If it is, we return it immediately in O(1) time instead of recomputing it.
This transforms the problem from exponential to polynomial: we compute each of the m × n subproblems exactly once, and each computation takes O(1) time (excluding the recursive calls which are also memoized). The total work becomes O(m × n).
Step-by-Step Explanation
Let's trace with text1 = "abcde", text2 = "ace" using a memo table initialized to -1:
Step 1: Call lcs(4, 2). memo[4][2] = -1 (not computed). Compare text1[4]='e' with text2[2]='e'. Match! Recurse lcs(3, 1).
Step 2: Call lcs(3, 1). memo[3][1] = -1 (not computed). Compare text1[3]='d' with text2[1]='c'. Mismatch. Need max(lcs(2,1), lcs(3,0)).
Step 3: Call lcs(2, 1). memo[2][1] = -1. Compare text1[2]='c' with text2[1]='c'. Match! Recurse lcs(1, 0).
Step 4: Call lcs(1, 0). memo[1][0] = -1. Compare text1[1]='b' with text2[0]='a'. Mismatch. Need max(lcs(0,0), lcs(1,-1)).
Step 5: Call lcs(0, 0). memo[0][0] = -1. Compare text1[0]='a' with text2[0]='a'. Match! Recurse lcs(-1,-1) → base case returns 0. So lcs(0,0) = 1. Store memo[0][0] = 1.
Step 6: lcs(1, -1) → base case returns 0. Back at lcs(1,0): max(1, 0) = 1. Store memo[1][0] = 1.
Step 7: Back at lcs(2,1): 1 + lcs(1,0) = 1 + 1 = 2. Store memo[2][1] = 2.
Step 8: Now compute lcs(3, 0) for the other branch of lcs(3,1). memo[3][0] = -1. Eventually resolves to 1 (only 'a' matches). Store memo[3][0] = 1.
Step 9: Back at lcs(3,1): max(lcs(2,1)=2, lcs(3,0)=1) = 2. Store memo[3][1] = 2.
Step 10: Back at lcs(4,2): 1 + lcs(3,1) = 1 + 2 = 3. Store memo[4][2] = 3.
Result: LCS length = 3. Only 9 unique subproblems were solved instead of the dozens the brute force explored.
Memoization Table — Top-Down Fill Pattern — Watch how the memoization table fills in as recursive calls resolve. Unlike bottom-up DP, the cells are filled in the order they are first needed, not left-to-right.
Algorithm
- Create a 2D memo table of size (m) × (n), initialized to -1
- Define recursive function
lcs(i, j)with memoization:- Base case: If
i < 0orj < 0, return 0 - Memo hit: If
memo[i][j] != -1, returnmemo[i][j]immediately - Match: If
text1[i] == text2[j], setmemo[i][j] = 1 + lcs(i-1, j-1) - Mismatch: Otherwise, set
memo[i][j] = max(lcs(i-1, j), lcs(i, j-1)) - Return
memo[i][j]
- Base case: If
- Call
lcs(m-1, n-1)and return the result
Code
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int m = text1.size(), n = text2.size();
vector<vector<int>> memo(m, vector<int>(n, -1));
return lcs(text1, text2, m - 1, n - 1, memo);
}
int lcs(string& s1, string& s2, int i, int j, vector<vector<int>>& memo) {
// Base case: one string is exhausted
if (i < 0 || j < 0) return 0;
// Return cached result if available
if (memo[i][j] != -1) return memo[i][j];
// Characters match — include in LCS
if (s1[i] == s2[j]) {
memo[i][j] = 1 + lcs(s1, s2, i - 1, j - 1, memo);
} else {
// Characters don't match — try both options
memo[i][j] = max(lcs(s1, s2, i - 1, j, memo),
lcs(s1, s2, i, j - 1, memo));
}
return memo[i][j];
}
};class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
m, n = len(text1), len(text2)
memo = [[-1] * n for _ in range(m)]
def lcs(i: int, j: int) -> int:
# Base case: one string is exhausted
if i < 0 or j < 0:
return 0
# Return cached result if available
if memo[i][j] != -1:
return memo[i][j]
# Characters match — include in LCS
if text1[i] == text2[j]:
memo[i][j] = 1 + lcs(i - 1, j - 1)
else:
# Characters don't match — try both options
memo[i][j] = max(lcs(i - 1, j), lcs(i, j - 1))
return memo[i][j]
return lcs(m - 1, n - 1)class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int m = text1.length(), n = text2.length();
int[][] memo = new int[m][n];
for (int[] row : memo) Arrays.fill(row, -1);
return lcs(text1, text2, m - 1, n - 1, memo);
}
private int lcs(String s1, String s2, int i, int j, int[][] memo) {
// Base case: one string is exhausted
if (i < 0 || j < 0) return 0;
// Return cached result if available
if (memo[i][j] != -1) return memo[i][j];
// Characters match — include in LCS
if (s1.charAt(i) == s2.charAt(j)) {
memo[i][j] = 1 + lcs(s1, s2, i - 1, j - 1, memo);
} else {
// Characters don't match — try both options
memo[i][j] = Math.max(lcs(s1, s2, i - 1, j, memo),
lcs(s1, s2, i, j - 1, memo));
}
return memo[i][j];
}
}Complexity Analysis
Time Complexity: O(m × n)
There are m × n unique subproblems (one for each pair of indices). Each subproblem is solved exactly once and cached in the memo table. Each individual subproblem takes O(1) time (a comparison and at most two lookups). Therefore, the total time is O(m × n).
Space Complexity: O(m × n)
The memo table requires m × n space. Additionally, the recursion stack can go as deep as m + n in the worst case. Since m × n dominates m + n for large inputs, the overall space complexity is O(m × n).
Why This Approach Is Not Efficient
While memoization reduces the time complexity from exponential to O(m × n), it still has drawbacks that make it suboptimal compared to a bottom-up approach:
-
Recursion overhead: Each of the m × n subproblems involves a function call with stack frame allocation. For strings of length 1000, that means up to 1,000,000 function calls, each with overhead for pushing/popping the call stack.
-
Stack overflow risk: With m and n up to 1000, the recursion depth can reach up to 2000. Some environments have limited stack sizes, and deep recursion can cause stack overflow errors.
-
Cache inefficiency: The top-down approach fills cells in an unpredictable order dictated by the recursion path. This leads to poor CPU cache performance compared to a systematic row-by-row traversal.
A bottom-up dynamic programming approach eliminates all these issues by building the table iteratively, filling it in a predictable order with no recursion overhead. It also opens the door to space optimization, since we only need the previous row to compute the current row.
Optimal Approach - Bottom-Up DP (Tabulation)
Intuition
Instead of starting from the full strings and breaking them down recursively, we flip the approach entirely: start from the smallest subproblems and build up to the answer.
Imagine filling out a grid where each row represents a prefix of text1 and each column represents a prefix of text2. The cell at position (i, j) stores the LCS length for the first i characters of text1 and the first j characters of text2.
We fill this grid row by row, left to right. At each cell, the decision is the same as before:
- If the characters match (text1[i-1] == text2[j-1]), the LCS grows by 1 compared to the diagonal cell (both strings one character shorter): dp[i][j] = dp[i-1][j-1] + 1.
- If they do not match, the LCS is the better of two options: ignoring the current character of text1 (look at the cell above: dp[i-1][j]) or ignoring the current character of text2 (look at the cell to the left: dp[i][j-1]).
The beauty of this approach is that by the time we need any cell's value, all of its dependencies have already been computed. No recursion, no stack, no redundant work. The answer sits in the bottom-right corner of the completed grid: dp[m][n].
Step-by-Step Explanation
Let's trace through with text1 = "abcde", text2 = "ace":
We create a DP table of size 6×4 (m+1 rows, n+1 columns). Row 0 and column 0 are all zeros (base cases: LCS with an empty string is 0).
Step 1: Fill dp[1][1]. text1[0]='a', text2[0]='a'. Match! dp[1][1] = dp[0][0] + 1 = 0 + 1 = 1.
Step 2: Fill dp[1][2]. text1[0]='a', text2[1]='c'. No match. dp[1][2] = max(dp[0][2], dp[1][1]) = max(0, 1) = 1.
Step 3: Fill dp[1][3]. text1[0]='a', text2[2]='e'. No match. dp[1][3] = max(dp[0][3], dp[1][2]) = max(0, 1) = 1.
Step 4: Fill dp[2][1]. text1[1]='b', text2[0]='a'. No match. dp[2][1] = max(dp[1][1], dp[2][0]) = max(1, 0) = 1.
Step 5: Fill dp[2][2]. text1[1]='b', text2[1]='c'. No match. dp[2][2] = max(dp[1][2], dp[2][1]) = max(1, 1) = 1.
Step 6: Fill dp[2][3]. text1[1]='b', text2[2]='e'. No match. dp[2][3] = max(dp[1][3], dp[2][2]) = max(1, 1) = 1.
Step 7: Fill dp[3][1]. text1[2]='c', text2[0]='a'. No match. dp[3][1] = max(dp[2][1], dp[3][0]) = max(1, 0) = 1.
Step 8: Fill dp[3][2]. text1[2]='c', text2[1]='c'. Match! dp[3][2] = dp[2][1] + 1 = 1 + 1 = 2.
Step 9: Fill dp[3][3]. text1[2]='c', text2[2]='e'. No match. dp[3][3] = max(dp[2][3], dp[3][2]) = max(1, 2) = 2.
Step 10: Fill dp[4][1]. text1[3]='d', text2[0]='a'. No match. dp[4][1] = max(dp[3][1], dp[4][0]) = max(1, 0) = 1.
Step 11: Fill dp[4][2]. text1[3]='d', text2[1]='c'. No match. dp[4][2] = max(dp[3][2], dp[4][1]) = max(2, 1) = 2.
Step 12: Fill dp[4][3]. text1[3]='d', text2[2]='e'. No match. dp[4][3] = max(dp[3][3], dp[4][2]) = max(2, 2) = 2.
Step 13: Fill dp[5][1]. text1[4]='e', text2[0]='a'. No match. dp[5][1] = max(dp[4][1], dp[5][0]) = max(1, 0) = 1.
Step 14: Fill dp[5][2]. text1[4]='e', text2[1]='c'. No match. dp[5][2] = max(dp[4][2], dp[5][1]) = max(2, 1) = 2.
Step 15: Fill dp[5][3]. text1[4]='e', text2[2]='e'. Match! dp[5][3] = dp[4][2] + 1 = 2 + 1 = 3.
Result: dp[5][3] = 3. The LCS of "abcde" and "ace" has length 3.
Bottom-Up DP Table — Filling Row by Row — Watch how the DP table fills systematically from top-left to bottom-right. Each cell depends only on the cell above, to the left, or diagonally above-left — all of which are already computed.
Algorithm
- Create a 2D DP table of size (m+1) × (n+1), initialized to 0
- For each row i from 1 to m:
- For each column j from 1 to n:
- If
text1[i-1] == text2[j-1](characters match):dp[i][j] = dp[i-1][j-1] + 1
- Else (characters do not match):
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
- If
- For each column j from 1 to n:
- Return
dp[m][n]— the bottom-right cell contains the LCS length
Code
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int m = text1.size(), n = text2.size();
// Create DP table with base cases (row 0 and col 0 are 0)
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
// Fill the table row by row
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (text1[i - 1] == text2[j - 1]) {
// Characters match — extend LCS from diagonal
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// No match — take the better of excluding either character
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
};class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
m, n = len(text1), len(text2)
# Create DP table with base cases (row 0 and col 0 are 0)
dp = [[0] * (n + 1) for _ in range(m + 1)]
# Fill the table row by row
for i in range(1, m + 1):
for j in range(1, n + 1):
if text1[i - 1] == text2[j - 1]:
# Characters match — extend LCS from diagonal
dp[i][j] = dp[i - 1][j - 1] + 1
else:
# No match — take the better of excluding either character
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[m][n]class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int m = text1.length(), n = text2.length();
// Create DP table with base cases (row 0 and col 0 are 0)
int[][] dp = new int[m + 1][n + 1];
// Fill the table row by row
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
// Characters match — extend LCS from diagonal
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// No match — take the better of excluding either character
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
}Complexity Analysis
Time Complexity: O(m × n)
We iterate through every cell of the DP table exactly once. The table has (m+1) × (n+1) cells, and filling each cell requires O(1) work (one comparison and at most one max operation). With m and n up to 1000, this means at most 1,000,000 operations — well within time limits.
Space Complexity: O(m × n)
The DP table requires (m+1) × (n+1) space to store all intermediate results. This can be further optimized to O(min(m, n)) by observing that each row only depends on the immediately previous row, so we can use just two rows (or even one row with careful indexing). However, the standard tabulation approach uses the full 2D table for clarity.